一、 贷款批准预测数据集
1. 数据探索与理解
prompt 1:
这是训练数据,目的是贷款批准预测数据集上训练的深度学习模型生成的数据,旨在使用借款人信息预测贷款批准结果,它通过模拟真实贷款审批场景,帮助金融机构评估借款人风险。
请展示训练基本信息(数据维度、特征类型、缺失值情况)

prompt 2:
请生成数据集的描述性统计摘要

prompt 3:
在这些变量中,请识别数值型和分类型变量

prompt 4:
请检查目标变量(贷款批准状态)的分布情况
 prompt 5:
prompt 5:
请分析各特征的数据质量和异常值
prompt 6:

prompt 7:
请问要如何处理这些异常值?

prompt 8:
请按如下方法处理:
1. person_age(年龄)
当前方法: 设定18-100岁范围,超出部分删除或替换 评估: ✅ 合适,但需要优化 改进建议:
保留18-85岁作为更合理的范围(考虑贷款业务实际)
对于异常值建议使用中位数替换而非删除,避免数据丢失
可以创建异常值标识特征,保留异常信息
2. person_income(收入)
当前方法: 分位数截断 + 对数变换 评估: ✅ 很好的方法 改进建议:
建议使用99%分位数进行截断,保留更多正常的高收入样本
对数变换前建议先处理0值(加小常数或使用log1p)
可以考虑按地区或行业分层处理,避免一刀切
3. person_emp_length(工作年限)
当前方法: 设定0-50年范围 评估: ✅ 合适,但可以更精细 改进建议:
考虑与年龄的逻辑关系:工作年限不应超过(年龄-16)
对于负值和缺失值,建议使用0填充(表示无工作经验)
创建工作经验分组特征(0年、1-5年、6-15年、16+年)
4. loan_amnt(贷款金额)
当前方法: 业务规则 + 分位数截断 评估: ✅ 合适 改进建议:
结合收入水平设定动态上限(如不超过年收入的10倍)
考虑贷款类型的影响(不同类型贷款金额范围不同)
使用99.5%分位数截断,保留合理的大额贷款
5. loan_int_rate(贷款利率)
当前方法: 设定合理范围 + 分位数截断 评估: ✅ 合适,需要结合市场情况 改进建议:
根据数据收集时间设定历史合理范围(如2%-30%)
考虑利率与风险等级的关系,异常高利率可能有业务含义
可以标记而非直接截断极端利率
6. loan_percent_income(贷款占收入比例)
当前方法: 设定0%-100%范围 评估: ⚠️ 需要修正 改进建议:
关键问题:贷款占收入比例可能合理超过100%(如购房贷款)
建议设定0%-500%的范围,或使用99%分位数截断
重点关注0值的处理(可能表示高收入或数据错误)
7. cb_person_cred_hist_length(信用历史长度)
当前方法: 保持原状 评估: ✅ 合适 改进建议:
检查是否存在负值或超过年龄的情况
建议最大值不超过(年龄-18)岁

2. 特征分析与可视化
prompt 9:
请针对借款人特征进行单变量分析:
年龄分布及其与贷款批准的关系
收入水平分布(包括年收入、月收入等相关指标)
工作年限分布及稳定性分析
房屋拥有情况分析
其他重要特征的分布情况

prompt 10:
请做双变量分析
各特征与贷款批准结果的相关性分析
收入与年龄的交互效应分析
工作年限与收入的关系
房屋拥有情况对批准率的影响
使用相关性热力图展示特征间关系

prompt 11:
现在引入test数据集,请查看两个数据集的基本信息(形状、特征、数据类型) 检查train和test的特征一致性,确认test集是否包含目标变量
prompt 12:

prompt 12:
基于您的情况,下一步的关键任务是解决特征一致性问题。这是一个严重的数据预处理问题,必须立即解决。
🚨 当前问题分析
核心问题: Train集有19列,Test集只有12列,说明:Train数据已经进行了特征工程(衍生了7个新特征)
Test数据还是原始状态
两个数据集无法直接用于建模请立即执行下面的步骤
步骤1:诊断特征差异
首先明确哪些是原始特征,哪些是衍生特征:
步骤2:重新统一处理
关键决策: 需要重新对两个数据集进行同步的特征工程
有两种选择:
选择A(推荐): 重新加载原始train数据,与test数据一起处理
选择B: 基于现有train数据,反向工程出test数据的特征
步骤3:创建统一处理流程
确保所有特征工程步骤在两个数据集上完全相同地执行
⚠️重要提醒
绝对不能做的事:不能删除train中的衍生特征来"匹配"test
不能单独为test创建不同的特征工程逻辑
不能忽略这个问题直接建模必须做的事:
确保特征工程的完全一致性
验证处理后两个数据集的特征匹配
检查数据分布的一致性请先执行特征对比分析,然后我们根据具体的特征差异来制定详细的修复方案。这一步完成后,才能继续进行EDA和建模工作。

prompt 13:
请验证数据分布的一致性

prompt 14:
请继续对train数据进行多变量分析
不同特征组合对贷款批准的综合影响
识别高风险和低风险借款人群体
分析特征交互作用

3. 风险评估分析
prompt 15:
现在进行风险评估分析,请重点分析以下风险因素:
识别导致贷款拒绝的主要因素
分析不同收入水平的批准率差异
评估年龄对贷款批准的影响模式
工作稳定性(工作年限)的风险指示作用
资产状况(房屋拥有)的风险缓解效果

4. 机器学习建模
prompt 16:
为了构建贷款批准预测模型,请先进行数据预处理
处理缺失值(填充策略选择和justification)
特征编码(分类变量处理)
特征标准化/归一化
特征选择和工程

prompt 17:
请进行特征选择和工程

prompt 18:
现在进行模型开发,数据集划分train集和test集
请尝试以下算法:逻辑回归(baseline模型)
随机森林
梯度提升树(如XGBoost、LightGBM)
支持向量机
神经网络

prompt 19:
尝试使用XGBoost模型

prompt 20:
继续使用LightGBM模型
prompt 21:
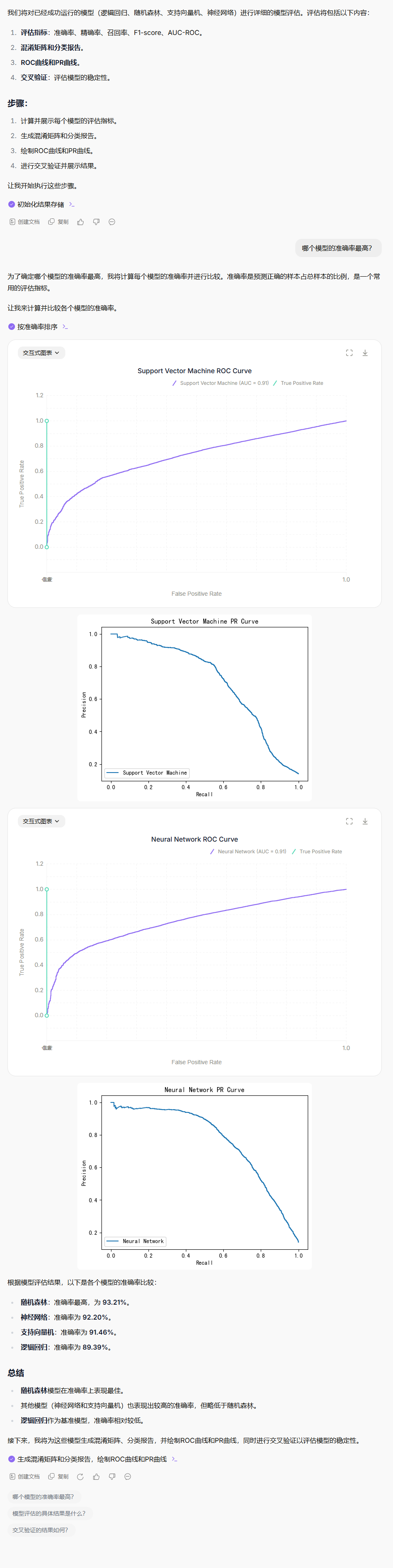
在现有的模型中,请进行模型评估,
使用适当的评估指标(准确率、精确率、召回率、F1-score、AUC-ROC)
生成混淆矩阵和分类报告
绘制ROC曲线和PR曲线
交叉验证评估模型稳定性

prompt 22:
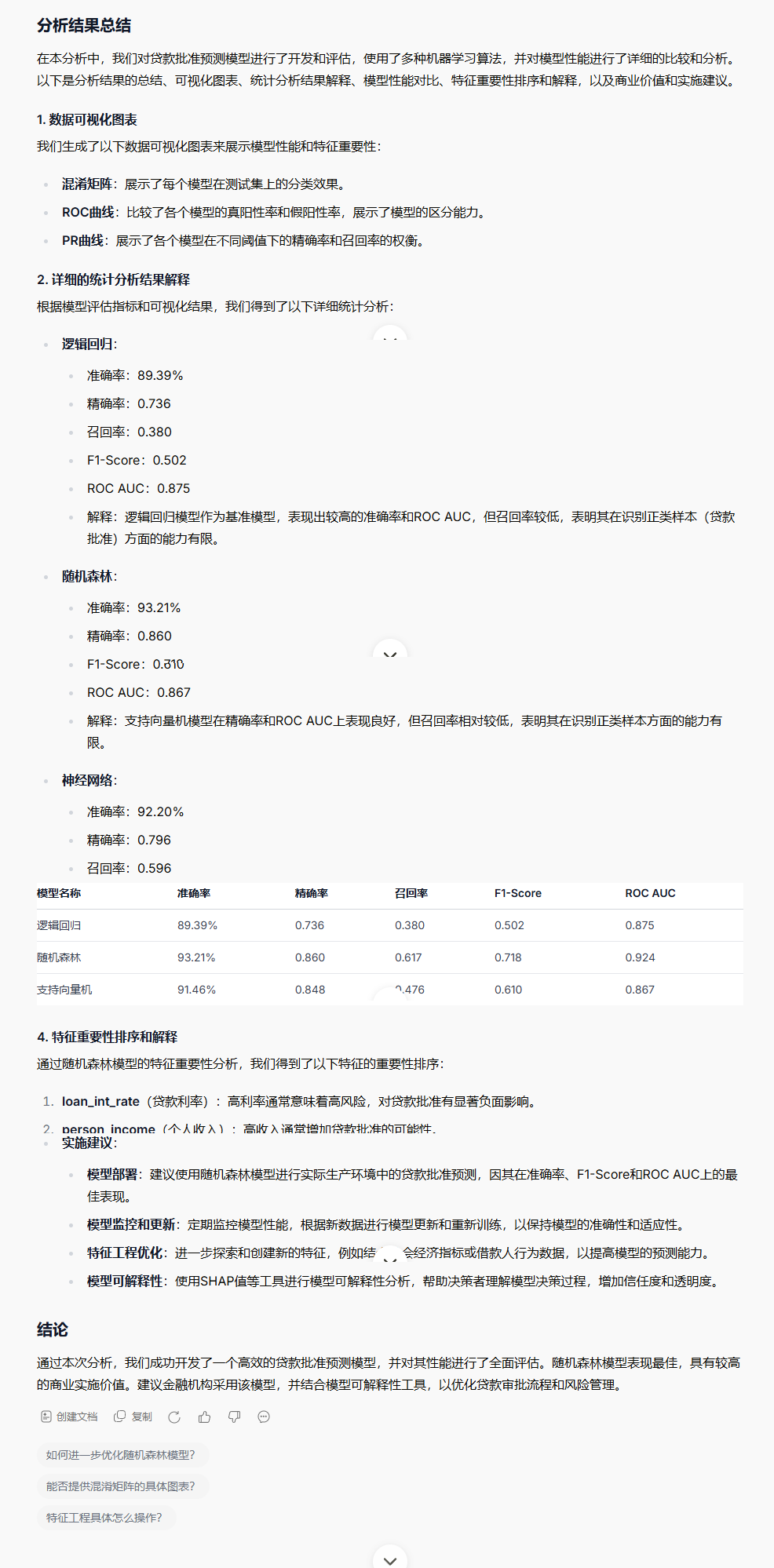
请总结上面的分析结果,
请做结果展示并确保分析结果包含:清晰的数据可视化图表(使用seaborn/matplotlib)
详细的统计分析结果解释
模型性能对比表格
特征重要性排序和解释
商业价值和实施建议







和WordPiece 是什么)



、提示词模板(PromptTemplate))


:AER内核处理流程梳理)




:BERT实战-基于Pytorch Lightning的文本分类模型)