文章目录
- 引言
- 正文
- 结束语
引言
陪女朋友出门,我大概有两个小时左右的空闲时间,遂带上电脑,翻了下论文列表,选择了这篇文章做一个简读。
因为这一年负责时序系统的存储引擎和计算引擎演进,而Compaction又是串联读写的核心组件,其Trade off就成了对于性能来讲非常重要的事情,所以sigmod2025的这篇文章我一直很期待。
吐槽下知乎只有文章,想法(字数限制50)这两种内容输出的形式,我其实希望发一篇总结,但没有文章那么正式,又比想法更加复杂,公司内部的知识平台有笔记这种内容输出形式,就很符合我的需求。
问了下LLM,得到的答案是这样的:
- 知乎的核心价值:作为中文互联网高质量问答社区,其内容需具备公共讨论价值和长期复用性。问题(结构化问答)、文章(深度解析)、想法(轻量观点)均服务于这一目标。
- 笔记的潜在冲突:笔记通常偏向个人化、碎片化、非结构化内容(如摘抄、待办清单),与知乎“公共知识库”的定位不符,易稀释内容质量。
仔细思考后发现我想输出的内容仍旧属于文章范畴,且具备公共讨论价值和长期复用性,不单单是碎片化的个人内容,遂完成了这篇简读文章,但是没有加入到从一到无穷大的专栏中,而是另起炉灶,重新创建一个专栏,收录后续的非正式文章。
这半年其实算下来也有十几篇有意思的论文我都写了笔记,但是够不上从一到无穷大的文章思考水平,遂全部在草稿箱吃灰,后续都可以放在问津集中来。
正文
Compaction is the key operation of the LSM-tree. Compacting aggressively leads to higher write amplification while reducing read amplification. Compacting lazily reduces write amplification but can hurt query performance.
文章的一个观点很有意思,以前的工作主要集中在写放大和读放大之间的权衡上,假设更高的WA会导致较低的写入性能。但是,LSM 树应用程序通常会经历稳定且适度的写入流,并且它只优先考虑顶级刷新,以避免由于写入停止而导致数据丢失。
例如,Meta已经证明,在实际工作负载中,最高写入速度约为45 MB/s。鉴于现代 NVMe SSD 提供超过 2 GB/s 的写入带宽。论文的实验表明,Compaction和查询之间剩余 CPU 和 I/O 资源的分布不会影响 LSM 树的写入性能。因此Compaction策略的目标是优化查询性能。
论文的实验主要关注Compaction和查询处于同机,所以需要联合优化,因为Compaction和读取作会争夺来自同一剩余池的 CPU 和 I/O 资源。
所以,论文的实际建模为:给定稳定的 LSM 树写入流(以恒定的刷新速度),如何设计压缩策略以最大化平均查询吞吐量?
Compaction的本质是投入计算和 I/O 来减少sort run的数量,从而使未来的查询能够探测更少的sort run。但是,这种效果是暂时的,因为会不断生成新的sort run。Compacion的未来收益取决于其对瞬时查询吞吐量的影响以及该影响的持续时间。
论文还观察到 Compaction的时机对于确定其影响的持续时间至关重要,在下一次Global Compaction(我们叫Full Compaction)之前执行Compaction越早,平均查询吞吐量的后续收益就越大。这是因为较早的Compaction可以在较长的时间内减少查询开销,从而大大增加后续从Compaction中受益的查询数量。
因此,理想的设计应该在不同时间采用不同的Compaction策略。这意味着同一level 的 sort run 应该具有不同的大小,因为它们是在不同的时间创建的,所以level的概念变得模糊,因为 LSM 树不再具有相同大小的sort run。
自然积极的Compaction策略可以最大化查询性能,但是其会占用资源,进而影响查询。
这就是文章的核心思路:从投资的视角设计Compaction
We view compaction as a form of investment.
Compaction’s write amplification is the cost of the investment
and the increased instantaneous query throughput is the immediate return.
Maximizing average query performance means maximizing the accumulated return from each investment.
A compaction’s accumulated return might be less than the opportunity cost.
文章提出了EcoTune Algorithm:该策略在给定客户端确定的恒定写入速度的情况下,在Compaction中优化平均查询吞吐量。
平均查询性能通过Compaction的成本和累积回报来建模。Compaction的成本可以根据涉及的数据量轻模,并且每次压缩的成本是独立的。累积回报的建模比较复杂,因为需要考虑其查询速度的即时改进以及这种改进将持续多长时间。
从立即回报到累积回报。最佳Compaction策略旨在最大化其累积收益,同时最大限度地降低其成本。文章分析了Compaction对查询速度的直接影响与其成本之间的关系。在Compaction中,LSM 树的数据布局和查询吞吐量是动态变化的,因此压缩的影响会随着时间的推移而逐渐减弱。要分析Compaction的累积回报,还必须考虑其影响会持续多久。
文章的一个观点是:越早进行Compaction,累积的未来回报就越大。当 LSM 树远离Full Compaction时,将多个sort run压缩为一个可以提高较长时间的查询速度。当 LSM 树接近Full compaction时,Compaction 产生的好处越小,因为新创建的sort run不会被长时间查询。由于时间的影响,具有相同成本的两个Compaction可能具有非常不同的累积收益。因此,在Compaction开始时,应该更积极地合并sort run。随着接近 full Compaction,compacion 策略应该变得更加懒惰。
其策略设计的核心称为Three-Level Generalization.
最佳压缩策略的积极性应该随着时间的推移而改变。换句话说,每个sort run的大小取决于其创建时间,而不是限制为 L 允许的大小。因此,没有大小相等的sort run。由于level的概念来自 L 允许的大小,因此不再有level的定义。而是将 LSM 树视为一组sort run,类似于RocksDB universal compaction。
因为合并小的sort run和之前一样,因此我们根据sort run对查询速度的影响将sort run重新划分为三个逻辑级别:
- top level:多个相同大小的sort run
- main level:多个不同大小的sort run
- last level:一个sort run
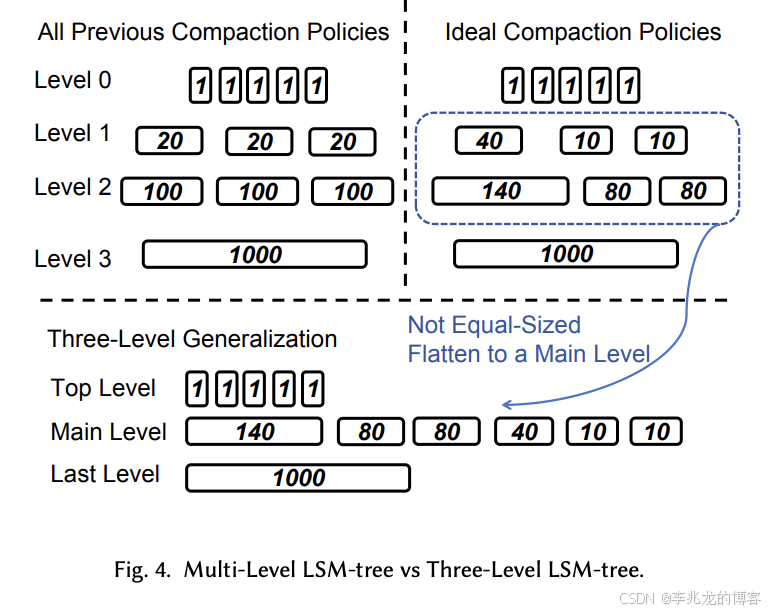
对于Three-Level Generalization,有三种后台任务:
- flush from memory to the top level
- compaction from the top level to the main level (TMC)
- compaction within the main level (MLC).
EcoTune Algorithm就是在main level的压缩策略,其对于最佳的定义是:两次full compactions之间查询的平均吞吐量最高。
算法的具体实现有兴趣的读者可以参考原论文的4.3节,这篇文章的目的是搞清楚问题和建模方法,具体的解决方法对于泛读论文来讲反而不太重要。
结束语
这篇论文对于Compaction其实不需要在意写放大的观察非常具有洞察力,在云环境下我们将Compaction,Ingester和查询引擎完全分离的做法导致Compaction策略的思考与单机的Compaction完全不同。
而且当介质变成对象存储时,写放大很多时候也不是考虑的重点,因为读写带宽是分离的,当存在带宽风险时一般都会分桶,此时Compaction就更不应该将写放大作为首要思考因素了,当然我们面对的问题和论文中的完全不一样,但是其对问题建模的方式非常值得学习。
Investment View,只学计算机可没法说出这样的话,跨界的知识储备对个人还是非常重要的,很多时候可以提供更为创新的视角。

|SVM-几何距离)
![[每日随题11] 贪心 - 数学 - 区间DP](http://pic.xiahunao.cn/[每日随题11] 贪心 - 数学 - 区间DP)
)






)





)


