目录
一、LRU 是什么?Cache是什么?
二、LRU Cache的实现
三、源码
一、LRU 是什么?Cache是什么?
LRU 是 "Least Recently Used" 的缩写,意思是“最近最少使用”。它是一种常用的 缓存(Cache)替换算法。
缓存(Cache)就像一个临时的“中转站”或“快速工作台”,它的作用是解决两个速度差异很大的设备之间数据交换的“瓶颈”问题。
例如
- CPU 和内存之间: 我们电脑的 CPU 速度非常快,而主内存(通常用 DRAM 技术)相对较慢。为了不让 CPU 总是“等”内存,就在它们之间加了一个高速缓存(通常用更快的 SRAM 技术)。CPU 会优先从这个高速缓存里找数据,大大提升了效率。
- 内存和硬盘之间:硬盘速度比内存慢得多,操作系统会在内存里开辟一块区域作为硬盘的缓存,存放最近读写过的数据。
- 硬盘和网络之间: 当你浏览网页时,浏览器会把看过的图片、网页文件等暂时保存在硬盘上的 “Internet 临时文件夹”或“网络缓存” 里。下次再访问同一个网站,浏览器就可以直接从本地缓存加载,而不必每次都从慢速的网络重新下载,让网页打开更快。
总之,LRU 是管理缓存空间的一种策略(当缓存满了,优先淘汰最久没被用过的数据)。而缓存本身,则是解决不同速度设备间协作效率问题的关键设计,存在于计算机系统的多个层级。Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选 并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用 的内容替换掉。其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内 最久没有使用过的内容。
二、LRU Cache的实现
实现LRU Cache的方法和思路很多,但是要保持高效实现O(1)的put和get,且其涉及到两个核心问题:快速访问数据和维护数据的使用顺序,那么使用双向链表和 哈希表的搭配是最高效和经典的。使用双向链表是因为双向链表可以实现任意位置O(1)的插入和 删除(维护数据使用顺序),使用哈希表是因为哈希表的增删查改也是O(1)和快速访问。
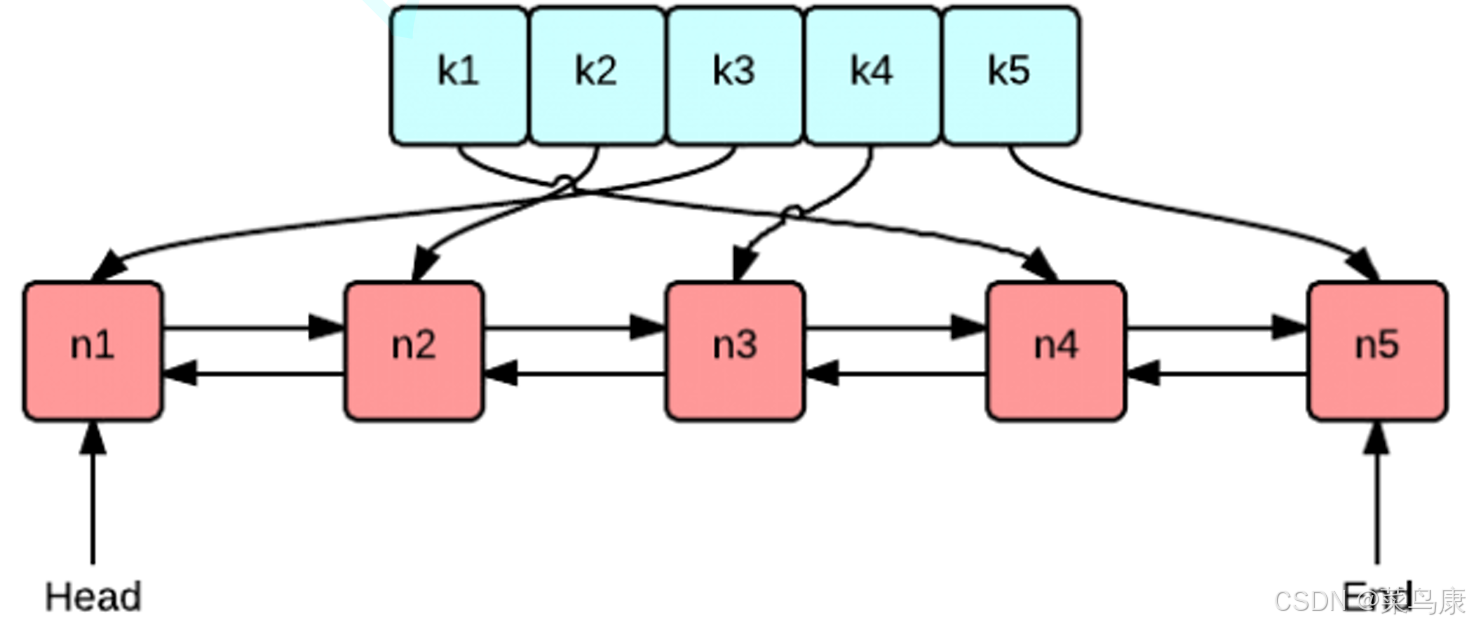
算法的思想:缓存容量有限,当缓存满了时,优先淘汰最久未被访问的数据,保留最近使用过的数据。
核心的数据结构:
- 哈希表:用于 O(1) 时间 快速查询、插入、删除键值对。
- 双向链表:用于维护数据的访问顺序:
- 最近访问的或者新插入的放在链表头部。
- 最久未访问的放在链表尾部。
- 当缓存满时,直接删除链表尾部的数据。
接下来借助一个 OJ 题来帮助实现 LRU Cache 算法。题目描述、示例提示如下


题目分析:
题目中要求函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
题目要求我们实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。使用双向链表和哈希表的搭配是最高效和经典的。
//hash做到查找更新/插入是O(1)unordered_map<int, LtIter> _hashmap;//LRU 默认链表尾部的是最久未被使用的list<pair<int, int>> _LRUList;但是只有这些是远远不够的,更新的时候其实复杂度是O(N),更新的情况就是调用put先在哈希表里面查找到key是已存在的,那然后我们要修改,哈希表里面我找到这个就可以直接修改。 但是,在list里也要修改,因为我们替换的时候找最久未被使用的那个值就是要从list里面找。 但是要修改list的话我们知不知道当前要修改的这个元素是list里面的哪一个元素? 是不知道的,所以还得遍历list去找。找到之后更新一下,然后把它移到头部去,更新顺序。
所以接下来我们就需要一个设计:
还是list和unordered_map搭配。 list里面呢还是存key-value的键值对pair。然后哈希表里面key还是要存的,但是不再像上面写的那样直接存key对应的数据value,而是存这个key对应的元素在list里面的对应的迭代器。(那这样真正的数据就只存在list里面)
那这样的话如果更新的话,首先我们在哈希表里面找到key,然后通过它里面存的该元素在list中的迭代器,就可以直接修改list里面存放的数据。
private:typedef list<pair<int,int>>::iterator LtIter;//hash做到查找更新/插入是O(1)unordered_map<int, LtIter> _hashmap;//LRU 默认链表尾部的是最久未被使用的list<pair<int, int>> _LRUList;size_t _capacity;//缓存的容量控制,当缓存大小超过此值时,需要淘汰最久未使用的元素构造函数:
class LRUCache {
public:LRUCache(int capacity):_capacity(capacity){}get() 方法实现:
int get(int key) {auto ret=_hashmap.find(key);if(ret!=_hashmap.end()){LtIter it=ret->second;//获取哈希表中存储的链表迭代器//将it对应的结点转移到链表头部_LRUList.splice(_LRUList.begin(),_LRUList,it);//操作是 O(1) 时间复杂度的,因为它只修改指针而不需要复制数据return it->second->second;}return -1;
}上面的splice接口功能如下:它可以把一个链表的一部分转移到另一个链表(当然也可以是同一个链表直接进行转移) 所以我们就可以直接调用splice将这个结点转移到list的头部。

put()接口的实现:
put的话呢无非就两种操作 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。 当然插入的时候需要判断: 如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字,然后插入新值。 另外不论是插入还是更新,都应该把插入或更新的值放到链表头部。
void put(int key, int value) {auto ret=_hashmap.find(key);//如果找到,更新值if(ret!=_hashmap.end()){LtIter it=ret->second;it->second=value;//将it对应的结点转移到链表头部_LRUList.splice(_LRUList.begin(),_LRUList,it);}else//找不到,插入{//如果满了需要先删除最久未使用的值if(_capacity==_hashmap.size()){pair<int,int> back=_LRUList.back();_hashmap.erase(back.first);_LRUList.pop_back();}//插入_LRUList.push_front(make_pair(key,value));_hashmap[key]=_LRUList.begin();}
}三、源码
class LRUCache {
public:LRUCache(int capacity):_capacity(capacity){}int get(int key) {auto ret=_hashmap.find(key);if(ret!=_hashmap.end()){LtIter it=ret->second;//将it对应的结点转移到链表头部_LRUList.splice(_LRUList.begin(),_LRUList,it);return it->second;}return -1;}void put(int key, int value) {auto ret=_hashmap.find(key);//如果找到,更新值if(ret!=_hashmap.end()){LtIter it=ret->second;it->second=value;//将it对应的结点转移到链表头部_LRUList.splice(_LRUList.begin(),_LRUList,it);}else//找不到,插入{//如果满了需要先删除最久未使用的值if(_capacity==_hashmap.size()){pair<int,int> back=_LRUList.back();_hashmap.erase(back.first);_LRUList.pop_back();}//插入_LRUList.push_front(make_pair(key,value));_hashmap[key]=_LRUList.begin();}}
private:typedef list<pair<int,int>>::iterator LtIter;//hash做到查找更新/插入是O(1)unordered_map<int, LtIter> _hashmap;//LRU 默认链表尾部的是最久未被使用的list<pair<int, int>> _LRUList;size_t _capacity;
};感谢阅读!
:绘图)






)



![[GESP202309 四级] 2023年9月GESP C++四级上机题题解,附带讲解视频!](http://pic.xiahunao.cn/[GESP202309 四级] 2023年9月GESP C++四级上机题题解,附带讲解视频!)

)



:Spring Boot + AI +DeepSeek实现智能合同数据问答助手(附完整源码))

![[sqlserver] 分析SQL Server中执行效率较低的SQL语句](http://pic.xiahunao.cn/[sqlserver] 分析SQL Server中执行效率较低的SQL语句)