导语
RabbitMQ 作为开源消息队列的标杆产品,凭借灵活的路由机制与高可用设计,支撑着海量业务场景的消息流转。而经典队列(Classic Queue) 作为 RabbitMQ 最基础、应用最广泛的队列类型,其底层存储机制直接决定了消息处理的性能边界与可用性上限。
理解经典队列的存储架构,不仅是掌握 RabbitMQ 核心原理的关键,更为生产环境的运维优化提供了理论支撑。本文将从文件目录结构、存储格式定义、读写流程到运维实践策略,全面解析经典队列的底层存储实现逻辑,帮助读者深入理解其在消息生命周期管理中的核心作用。
经典队列介绍
RabbitMQ 作为一款历史悠久的开源消息队列,被广泛应用于各个领域。在 RabbitMQ 中,用户使用虚拟主机(Vhost)隔离资源,交换机负责路由消息,队列则是消息存储的最小单元。
用户通过客户端与 RabbitMQ 的服务端建立连接后,基于通道(Channel)实现消息的高效交互:生产者经过通道将消息发送至交换机,由交换机按绑定规则路由至目标队列;消费者则通过通道从队列中拉取消息,完成业务逻辑处理。
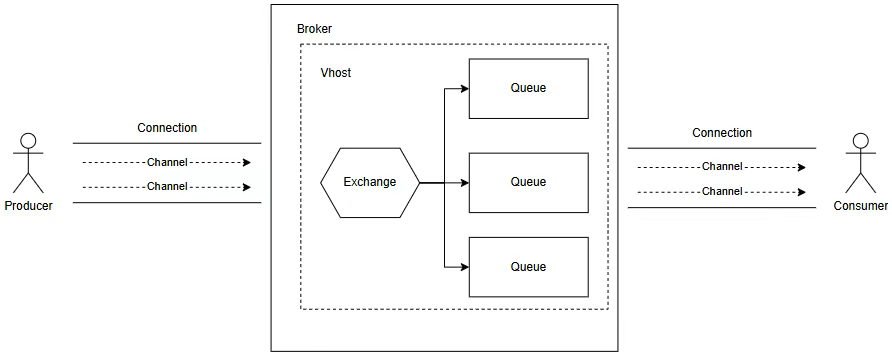
在这一过程中,队列作为消息生命周期的核心载体,衍生出三种差异化实现:
-
经典队列(Classic Queue):采用轻量级索引与共享存储架构,在单机性能与存储效率间取得平衡,适用于高吞吐非强一致性场景;
-
仲裁队列(Quorum Queue):基于 Raft 协议实现多副本强一致性,保障关键业务数据不丢失,适用于金融交易、订单管理等关键业务;
-
流队列(Stream Queue):以日志结构存储消息流,支持回溯消费与持久化流处理,适用于实时数据分析场景。
经典队列作为使用频率最高的队列,了解它的存储机制对于理解其可用性和性能至关重要,接下来将从存储架构、文件格式、读写流程等维度,深入解析经典队列的底层实现逻辑。
存储架构解析
目录结构
RabbitMQ 通过虚拟主机(Vhost)实现资源隔离,每个 Vhost 有独立的物理存储目录,其典型结构如下:
vhost_name/
├── msg_store_persistent/ # 共享存储目录,存储大消息
│ ├── 0.rdq # 共享存储文件
│ └── 1.rdq # 支持文件滚动
└── queues/ # 队列专属存储目录└── queue_name/ # 单个队列目录├── queue_name.qi # 队列索引文件└── queue_name.qs # 队列存储文件
msg_store_* 是共享存储目录,顾名思义是这个 Vhost 下所有队列共享的存储。由于 Exchange 可能会将同一条消息路由到不同的队列,而将同一条消息存储多次会增加磁盘空间占用,因此经典队列会将大小超过某个阈值的消息存储在共享存储下,通过引用计数来管理这部分消息。
每个队列在 queues 目录下都有属于自己的目录,队列目录下主要有两类文件:
-
队列存储:名称为 *.qs 的文件,负责存储这个队列中消息大小小于这个阈值的消息。
-
队列索引:名称为 *.qi 的文件,负责存储消息元数据和消息所在位置。队列索引存储了消息的偏移或唯一标识,通过它们可以定位到消息在队列存储或共享存储中的位置,索引文件中的 Entry 和存储文件中的 Entry 因此在逻辑上构成了一对一的映射关系。
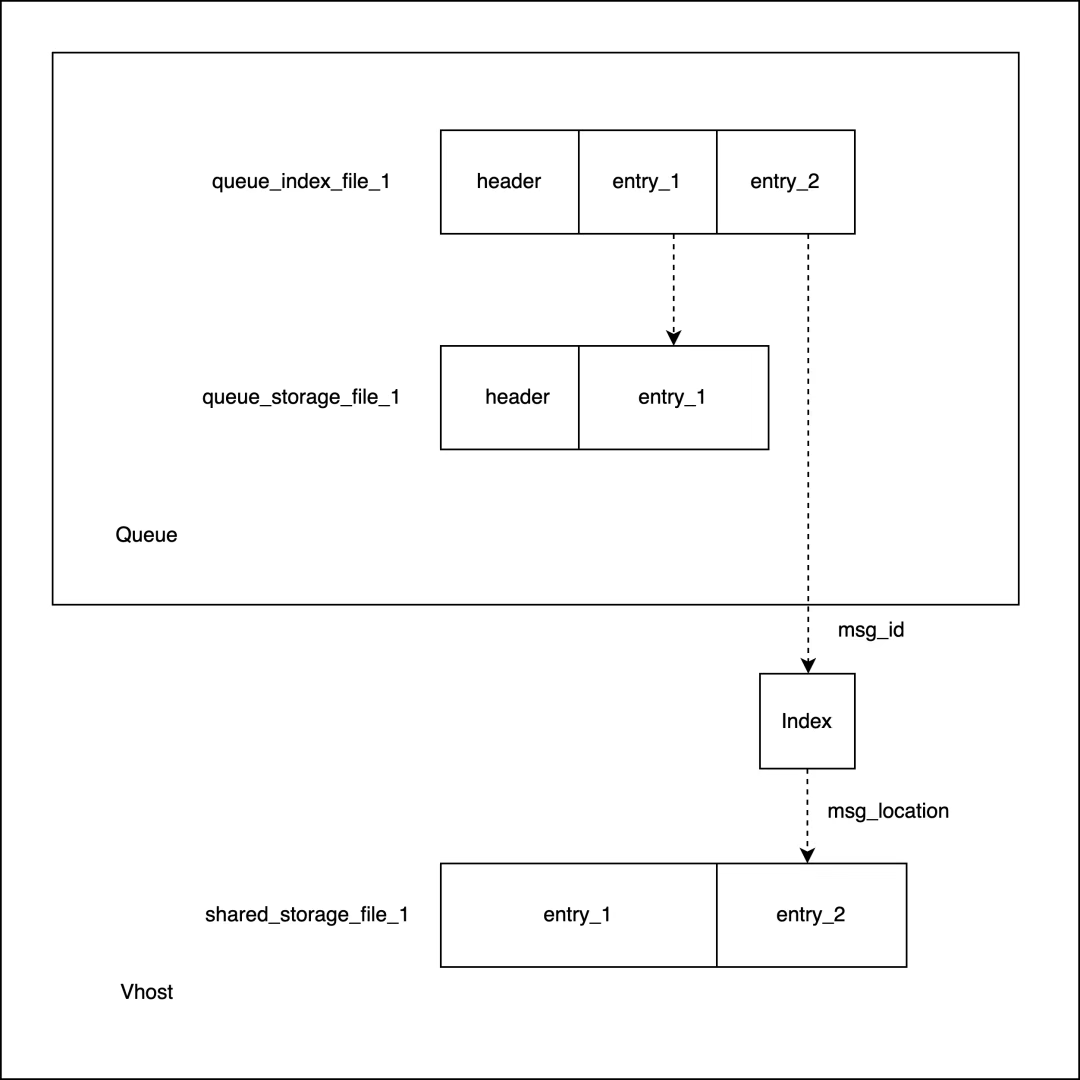
队列索引
队列索引文件由一个 Header 和若干 Entry 组成,Entry 的数量由 classic_queue_index_v2_segment_entry_count 这一参数控制,默认为4096。Entry 有两种类型:Publish Entry 和 Ack Entry。
生产者将消息成功发送到队列后会产生一个 Publish Entry,队列将这条消息投递给消费者并且得到消费者确认后会使用 Ack Entry 覆盖原来的 Publish Entry,代表这条消息可以被删除。
Publish Entry 存储了这条消息的元数据,包括 MsgId、SeqId、存储位置、消息属性和是否持久化的标识。
MsgId 是 RabbitMQ 为每条消息随机生成的 GUID,用来确定消息在共享存储的位置。
SeqId 是这条消息在队列中的序号,用来决定消息在队列索引和队列存储中的位置。
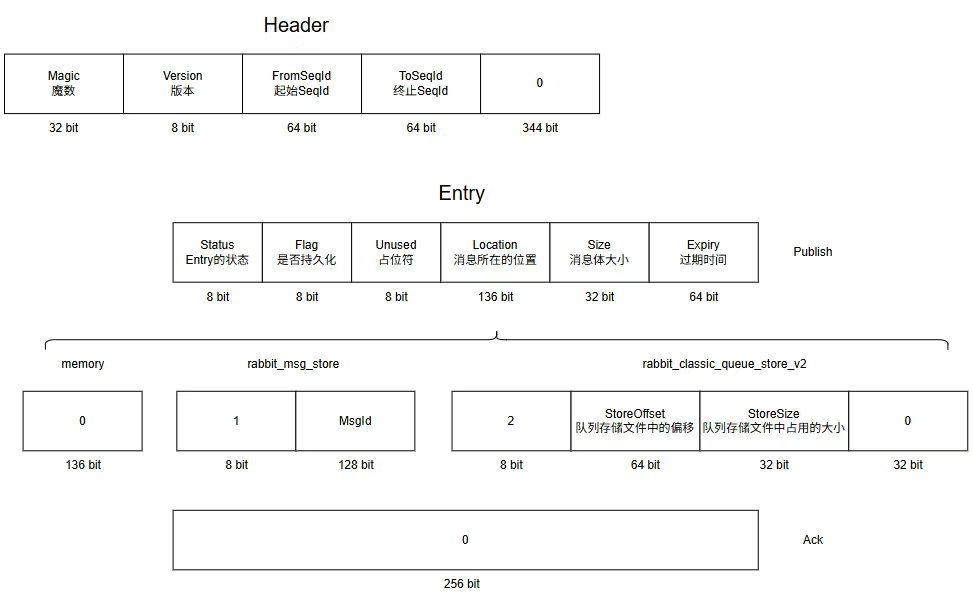
队列存储
队列存储文件和索引文件是一对一的关系,当队列删除它的索引文件时,也会删除对应的存储文件。队列存储文件的结构与索引文件类似,也是由 Header 和 Entry 构成。Header 和 Entry 的具体组成如下所示。

共享存储
ETS 是 Erlang 内置的单机 KV 存储,共享存储使用 ETS 维护了两个组件:
-
Index:是 MsgId 到消息位置的映射。
-
FileSummary:文件到文件统计信息的映射。
经典队列在读取消息时通过索引文件中的 Publish Entry 获取到 MsgId 后还需要从 Index 中获取消息的具体位置,包括这条消息所在的文件、偏移以及它的引用计数。相同 MsgId 的多条消息只会被写入一次,删除消息时,它的引用计数会被减一。文件统计信息中记录了文件中有效数据的数量,这在整理文件时会被用到。
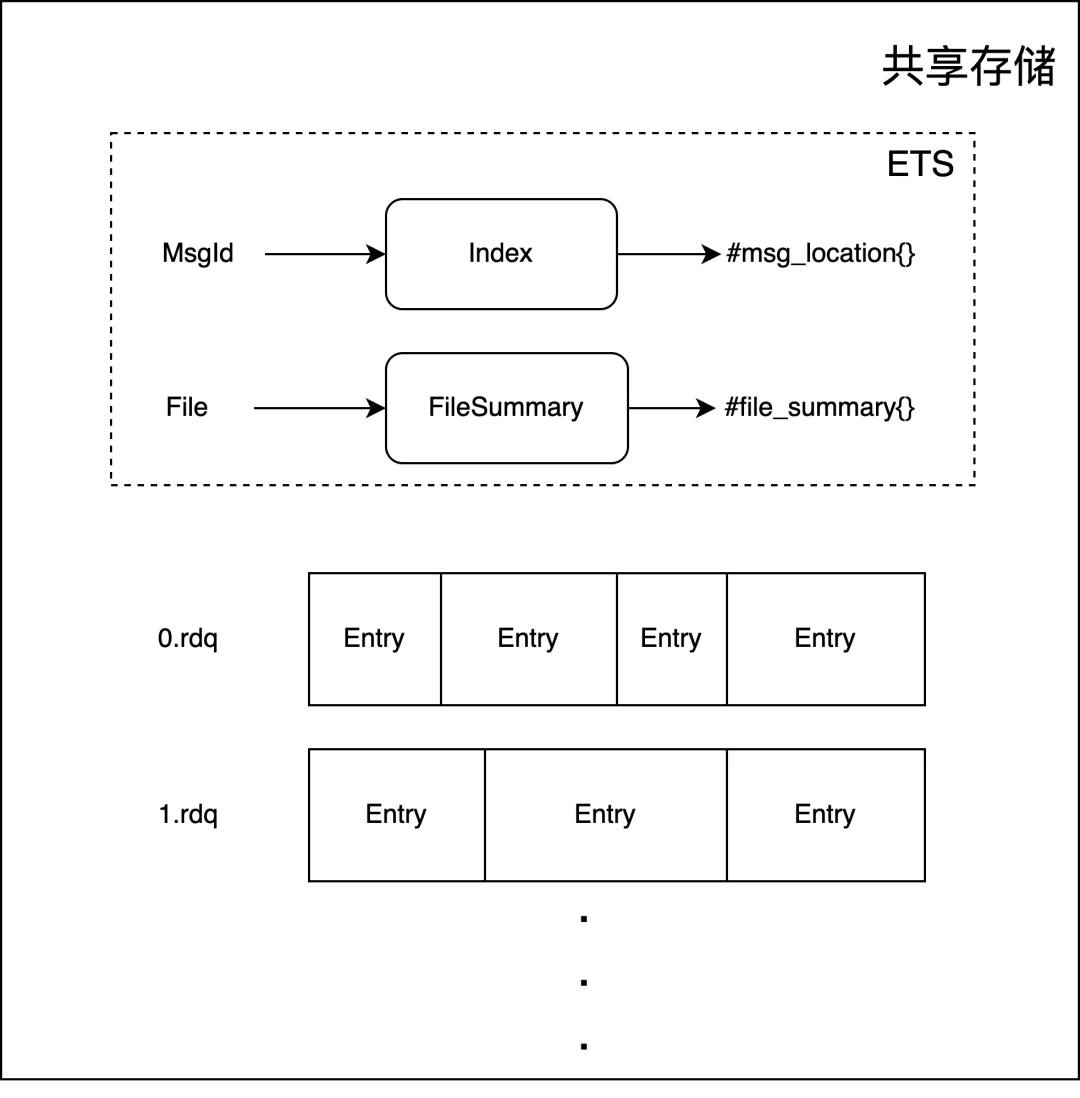
共享存储文件的大小由参数 msg_store_file_size_limit 控制,默认为16MB。每个文件由若干个 Entry 组成,每个 Entry 的具体组成如下所示。

核心工作流程
消息写入
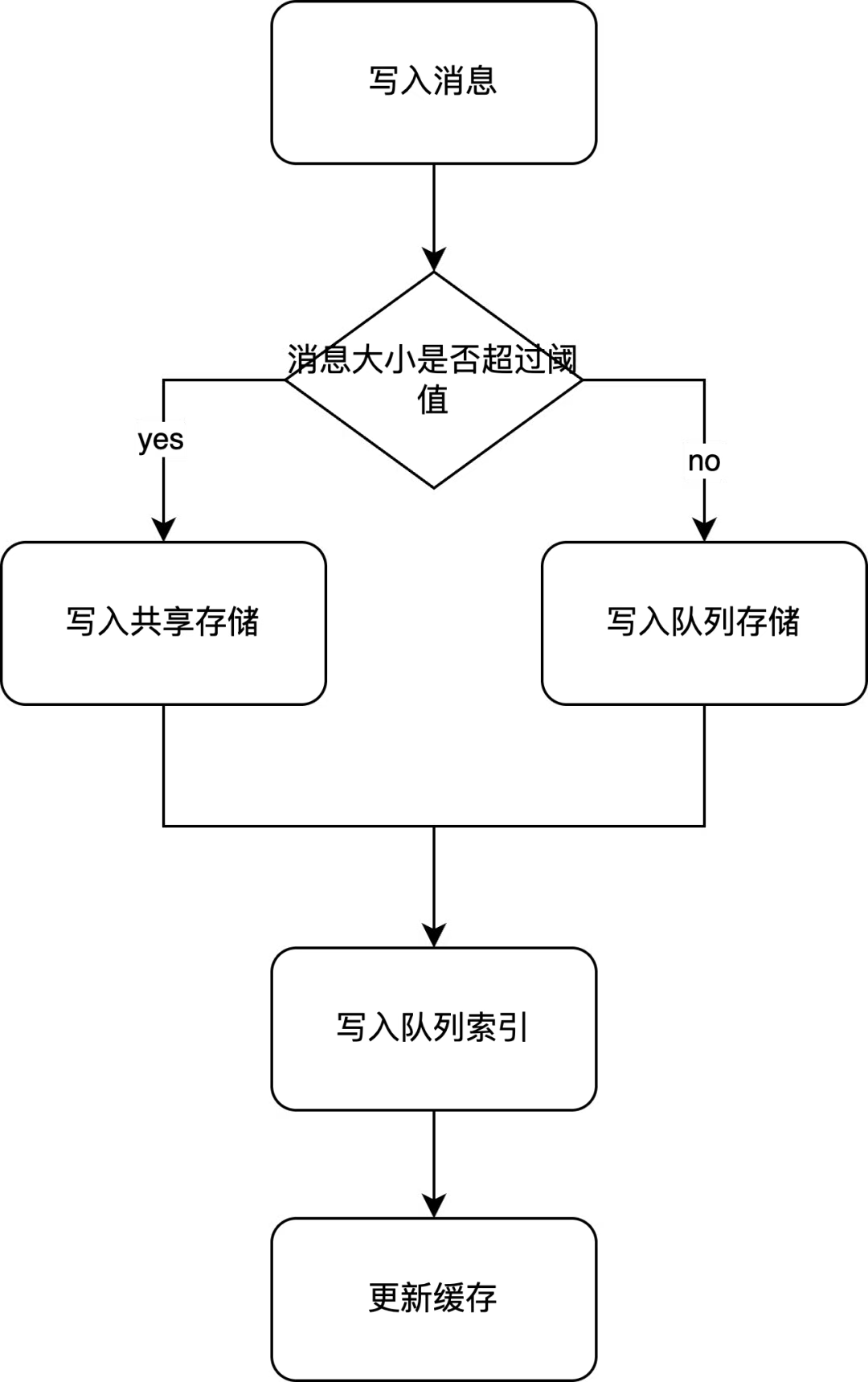
RabbitMQ 根据消息大小决定将消息写入到哪个存储。如果消息大小大于或等于某个值(由参数 queue_index_embed_msgs_below 控制,默认为4KB),RabbitMQ 会将其存于共享存储中,否则会存于队列存储中。
将消息写入存储时会直接写到内部缓冲区:
-
队列存储内部的缓冲区大小由参数 classic_queue_store_v2_max_cache_size 控制,默认为512KB。
-
共享存储内部的缓冲区大小则固定为1MB。将消息写入到共享存储时除了需要写入到缓冲区外,还需要更新它内部的 Index 和 FileSummary 组件。
缓冲区大小超过限制后会 Flush 其中的数据,值得注意的是,Flush 时不会调用 Fsync,而是调用 Write 将数据写入到操作系统的 Page Cache 上。这种方式通过牺牲数据安全性以获得更低的延迟,如果需要更强的数据安全性应使用仲裁队列。
存储写入完成后需要在队列索引文件中写入 Publish Entry,此时消息被认为成功写入了。之后还要更新内存中的消息缓存,以加速消息读取。
消息读取
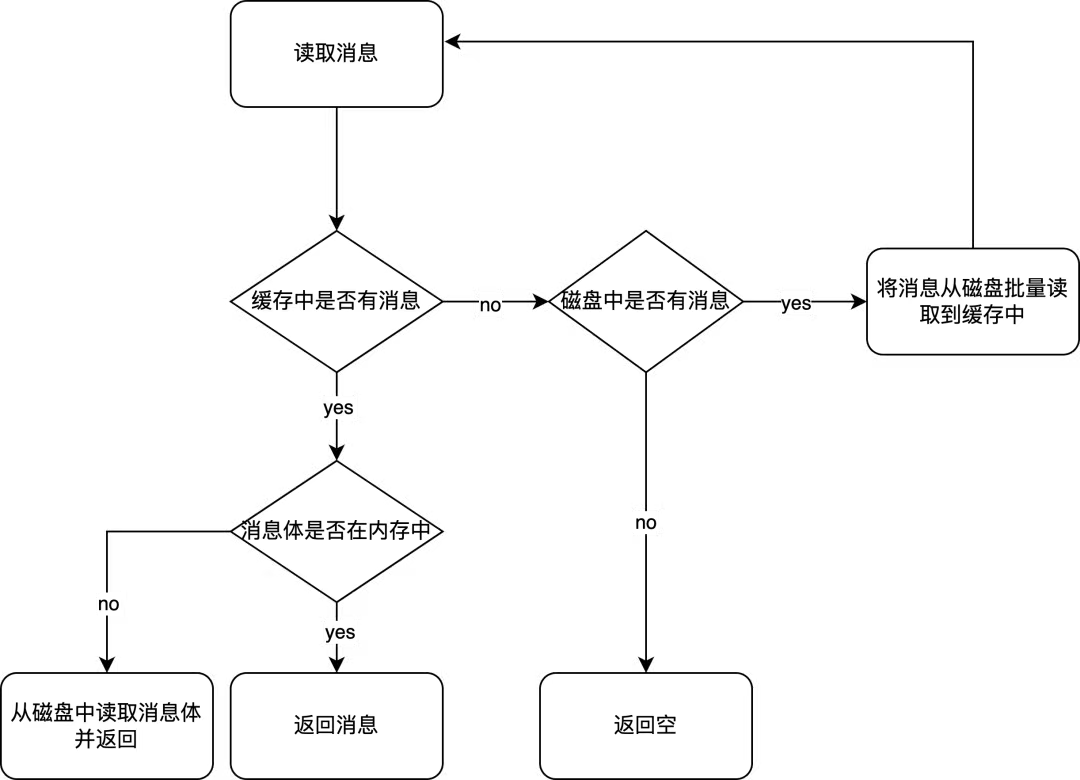
经典队列在内存中维护了专门的缓存来提升读取性能,底层存储会根据队列的消费速率批量读取不超过2048条消息到缓存中。读取消息时会先检查缓存中是否有这条消息,如果有则直接返回,否则会先将消息批量读取到缓存。
将消息从磁盘批量读取到内存中需要先到队列索引中读取元数据,然后分别到队列存储和共享存储中读取消息体,并将它们组装到一起。即便缓存中有消息,但是实际的消息体仍然可能不在缓存中,因为过大(>12KB)过少(<10条)的消息的消息体并不会被读到缓存里,需要在投递消息时逐条去磁盘中读取消息体。
文件整理
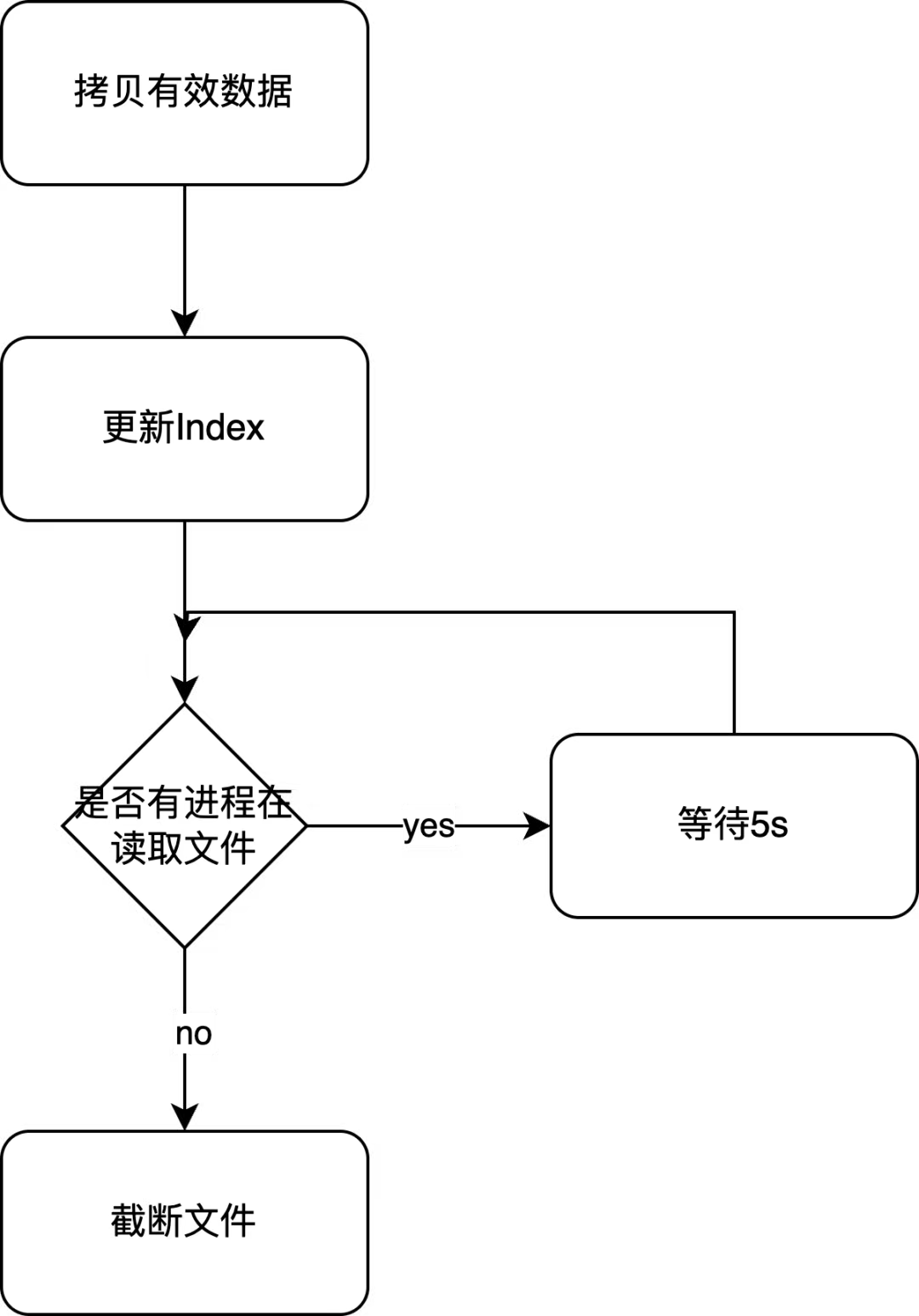
共享存储会定时整理有效数据占比低于一半的文件以回收空间。整个过程分为三步:
- 将文件末尾的有效数据拷贝到文件前面的无效数据处。
- 更新 Index 组件。
- 在没有进程读取文件后截断文件。
RabbitMQ 会将文件中的无效数据置0,称为空洞(blank holes)。在文件整理时,RabbitMQ 从最后一条有效消息开始查看其是否能填补前面的空洞,如果可以就将其拷贝到前面,如果它比前面的任何一个空洞都大,那么这一次的文件整理将无法释放任何空间,这是为了防止意外覆盖被移动过的消息。Index 组件中存储了消息的位置,拷贝完成后需要更新对应消息的位置。在没有进程读取文件后就可以截断这个文件以节省磁盘空间。
运维实践
发送确认
为了提高消息发送的可靠性,我们推荐用户打开发送确认(Confirm)。RabbitMQ 会在将消息从缓冲区 Flush 到磁盘后向客户端发送 Confirm,此时生产者可以认为这条消息已经被成功发送到队列。
消费确认
为了提高消息消费的可靠性,我们推荐用户打开手动确认(Manual Ack)。RabbitMQ 在收到 Ack后会写入 Entry 到队列索引中,只有在索引文件中的所有 Publish Entry 全部被 Ack 后,才会删除该文件。如果消费者在发送 Ack 前宕机了,RabbitMQ 会重复投递这条消息,确保消息能真正被消费掉。未被客户端 Ack 的消息会堆积在内存中,如果数量过多则可能触发内存水位限制,甚至导致服务端 OOM。因此在用户打开手动确认后,我们建议用户设置一次最多能预取(prefetch count)的消息数量,避免大量消息堆积在客户端和服务端内存中。
保证队列尽可能短
保持生产和消费速率一致可以减少消息堆积。RabbitMQ 会在发现索引文件中的消息全部被消费后删除索引文件和对应的存储文件,这样可以减少磁盘空间占用。队列的堆积数量少意味着多数读取都可以从缓存中直接读取到消息体,从而提升读取性能。
总结
本文全面探讨了 RabbitMQ 经典队列的底层存储机制,包括其整体架构、实现原理及运维实践。经典队列的底层存储由队列索引和消息存储两大模块构成,其中消息存储又细分为共享存储和队列存储,通过精心设计的文件结构和内存管理策略,实现了高效的消息读写与存储管理。文章详细解析了队列索引、消息存储(包括共享存储和队列存储)的文件结构,介绍了消息读取与写入的流程,以及文件整理的逻辑。在运维实践方面,强调了发送确认、消费确认与保持队列尽可能短的重要性,并给出了相应的配置建议。希望通过本文的介绍,可以帮助大家深入理解 RabbitMQ 经典队列的底层存储机制,为实际应用中的性能优化与故障排查提供有力支持。
)




 v3.0.2 新特性 为非类npm环境引入 globalTypesPath 选项)






)


线性表(上):SeqList 顺序表)

)
)
