文章目录
- 线性回归基本概念
- 随机梯度下降
- 矢量化加速
- 正态分布和平方损失
- 极大似然估计
- 线性回归实现
- 从0开始
- **`torch.no_grad()`的两种用途**
- **为什么需要 `l.sum().backward()`?**
- 调用现成库
- softmax回归
- 图像数据集
- 从0开始实现softmax
- 利用框架API实现
课程学习自李牧老师B站的视频和网站文档
https://zh-v2.d2l.ai/chapter_preliminaries
线性回归基本概念
线性模型可以看作单层神经网络,由多个输入得到一个输出
线性回归可以解决预测多少的问题
适用问题:
- 数值预测:
- 预测连续值,如房价(基于面积、位置等)、股票价格(基于历史数据)、温度预测(基于时间和天气因素)。
- 示例:用房屋面积和卧室数预测房价。
- 趋势分析:
- 分析变量之间的线性趋势,如销售额随广告投入的增长。
- 示例:研究学习时间对考试成绩的影响。
- 因果关系探索:
- 初步评估输入特征对输出的影响(如广告支出对销售额的贡献)。
- 示例:分析肥料用量对作物产量的关系。
- 数据标准化:
- 用线性回归拟合基线(如去趋势数据),用于时间序列分析。
- 示例:移除季节性影响后的销售预测。
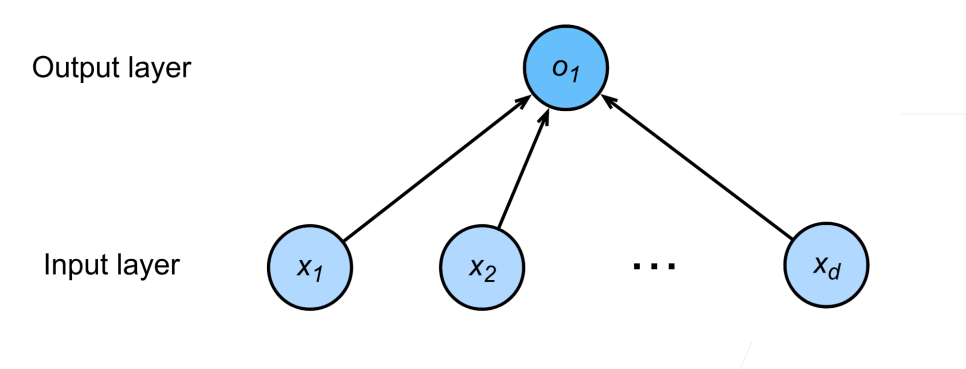


下面两组参数分别表示求一个损失均值,期望可以最小化损失的w和b

解析解

随机梯度下降
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。 但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降

公式表示梯度的原先的w减去均值乘上学习率
批量大小和学习率(沿着梯度走多长的方向)都是预先指定的
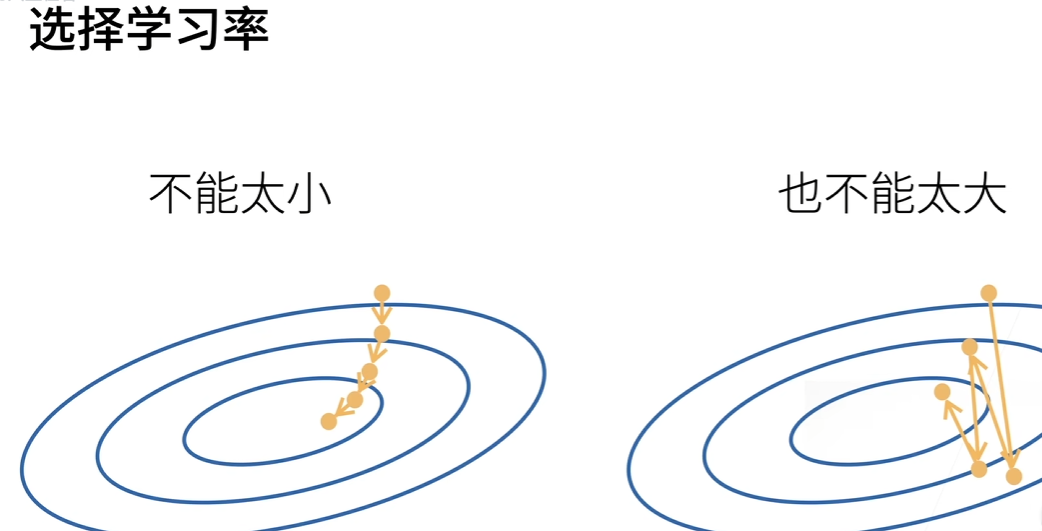
训练过程中不断更新的参数叫超参数,调参是选择超参数的过程
矢量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。 为了实现这一点,需要我们对计算进行矢量化, 从而利用线性代数库,而不是在Python中编写开销高昂的for循环。
什么是矢量化?
- 矢量化(vectorization)是指用向量或矩阵操作替代循环,特别是在计算中同时处理多个数据点。这是一种利用现代处理器(如 CPU 或 GPU)并行计算能力的技巧。
import numpy as np
import time
import torch
import math
class Timer: """记录多次运行时间"""def __init__(self):self.times = []self.start()def start(self):"""启动计时器"""self.tik = time.time()def stop(self):"""停止计时器并将时间记录在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def avg(self):"""返回平均时间"""return sum(self.times) / len(self.times)def sum(self):"""返回时间总和"""return sum(self.times)def cumsum(self):"""返回累计时间"""return np.array(self.times).cumsum().tolist()n=10000
a=torch.ones([n])
b=torch.ones([n])c=torch.zeros([n])
time1=Timer()
for i in range(n):c[i]=a[i]+b[i]
print(f"{time1.stop()} sec")time2=Timer()
d=a+b
print(f"{time2.stop()} sec")

正态分布和平方损失

极大似然估计
什么是极大似然估计?
- 极大似然估计是一种统计方法,用于根据观测数据找到最可能产生这些数据的模型参数。简单说,就是从数据“反推”出最合理的参数值。

线性回归实现
从0开始
因为感觉应该也不会从头开始写函数,所以就只分析一下背后的原理不做实现了
生成数据集没什么好说的,注意,features中的每一行都包含一个二维数据样本, labels中的每一行都包含一维标签值(一个标量)
def synthetic_data(w, b, num_examples): #@save"""生成y=Xw+b+噪声"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
在下面的代码中,我们定义一个data_iter函数, 该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))# 这些样本是随机读取的,没有特定的顺序random.shuffle(indices)for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]
yield用于实现一个 生成器(Generator),它的核心作用是:
按批次(batch)逐个返回数据和标签,而不是一次性返回所有数据。
在我们开始用小批量随机梯度下降优化我们的模型参数之前, 我们需要先有一些参数。 在下面的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重, 并将偏置初始化为0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
初始化参数后每次更新参数时计算梯度,然后从梯度减小的方向更新梯度
定义线性回归模型:
def linreg(X, w, b): #@save"""线性回归模型"""return torch.matmul(X, w) + b
定义损失函数:
def squared_loss(y_hat, y): #@save"""均方损失"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
定义优化算法:在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。 接下来,朝着减少损失的方向更新我们的参数。每 一步更新的大小由学习速率lr决定
def sgd(params, lr, batch_size): #@save"""小批量随机梯度下降"""with torch.no_grad():for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_()
params: 模型参数列表(如 [w, b]),每个参数是张量且带有 .grad属性。
with torch.no_grad():
-
作用:禁用梯度计算上下文,确保参数更新时不会记录梯度(避免干扰后续反向传播)
-
除以
batch_size:梯度是批次内样本梯度的总和,除以批次大小得到平均梯度(保证不同批次大小下的稳定性)。也叫梯度归一化,因为pytorch默认对批次内样本梯度求和
param.grad.zero_()
- 清空梯度:将当前参数的梯度置零,避免下一次反向传播时梯度累加
那么到这里,数值初始化,损失计算,优化函数都搞定了,就可以开始训练了
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_lossfor epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
torch.no_grad()的两种用途
- 参数更新时(
sgd内):避免更新操作被记录到计算图中。 - 评估时:禁用梯度以节省内存和计算资源。
为什么需要 l.sum().backward()?
-
PyTorch 的
backward()需要标量输入。如果l是形状为(batch_size, 1)的张量,必须先求和或均值转为标量。 -
梯度计算逻辑:
对每个样本的损失求梯度后,PyTorch 默认对批次内梯度求和(
sum),因此后续需手动除以batch_size(在sgd中实现)。
调用现成库
接下来try一try调用框架现成的库
同样先生成数据
true_w=torch.tensor([3,-3.4])
true_b=3.2
x,y=synthetic_data(true_w,true_b,1000)
读取数据可以调用现成的数据迭代器来进行,同时可以指定样本batch的大小,以及是否打乱数据
DataLoader其实本质上就是一个迭代器
def load_array(data_arrays,batch_size,is_train=True):dataset=data.TensorDataset(*data_arrays)return data.DataLoader(dataset,batch_size,shuffle=is_train)batch_size=10
data_iter=load_array((x,y),batch_size)
print(next(iter(data_iter)))
对于标准深度学习模型,我们可以使用框架的预定义好的层。这使我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。 我们首先定义一个模型变量net,它是一个Sequential类的实例。 Sequential类将多个层串联在一起。 当给定输入数据时,Sequential实例将数据传入到第一层, 然后将第一层的输出作为第二层的输入,以此类推。
单层神经网络就是全连接层,在PyTorch中,全连接层在Linear类中定义。 值得注意的是,我们将两个参数传递到nn.Linear中。 第一个指定输入特征形状,即2,第二个指定输出特征形状,输出特征形状为单个标量,因此为1。
from torch import nn
net=nn.Sequential(nn.Linear(2,1))
指定每个权重参数应该从均值为0、标准差为0.01的正态分布中随机采样, 偏置参数将初始化为零。
net[0].weight.data.normal_(0,0.01)
net[0].bias.data.fill_(0)
损失函数和优化算法同样有现成的
loss=nn.MSELoss()
trainer=torch.optim.SGD(net.parameters(),lr=0.03)
接下来开始训练,使用模型net计算输出,之前生成的优化算法trainer更新结果
num_epochs=3
for epoch in range(num_epochs):for x,y in data_iter:l=loss(net(x),y)trainer.zero_grad()l.backward()trainer.step()l=loss(net(X),Y)print(f'epoch {epoch + 1}, loss {l:f}')
完整代码
from operator import ne
import numpy as np
import torch
from torch.utils import data
def synthetic_data(w, b, num_examples): #@save"""生成y=Xw+b+噪声"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))
true_w=torch.tensor([3,-3.4])
true_b=3.2
X,Y=synthetic_data(true_w,true_b,1000)def load_array(data_arrays,batch_size,is_train=True):dataset=data.TensorDataset(*data_arrays)return data.DataLoader(dataset,batch_size,shuffle=is_train)batch_size=10
data_iter=load_array((X,Y),batch_size)from torch import nn
net=nn.Sequential(nn.Linear(2,1))net[0].weight.data.normal_(0,0.01)
net[0].bias.data.fill_(0)loss=nn.MSELoss()
trainer=torch.optim.SGD(net.parameters(),lr=0.01)num_epochs=5
for epoch in range(num_epochs):for x,y in data_iter:l=loss(net(x),y)trainer.zero_grad()l.backward()trainer.step()l=loss(net(X),Y)print(f'epoch {epoch + 1}, loss {l:f}')
softmax回归
用于解决分类的问题,预测图片中物品是哪一类
什么是置信度?
- 置信度(confidence)表示模型对某个预测结果的“把握程度”,通常是一个介于 0 到 1 之间的值。数值越高,模型越认为预测正确。

对分类进行编码

softmax本质上也是一个根据输入计算得到输出的单层网络
什么是全连接层?
- 全连接层(Fully Connected Layer, FC Layer)是神经网络中的一种层级结构,每个神经元都与前一层的所有神经元相连,像一张“全网”联系的网络,用于整合和变换特征。
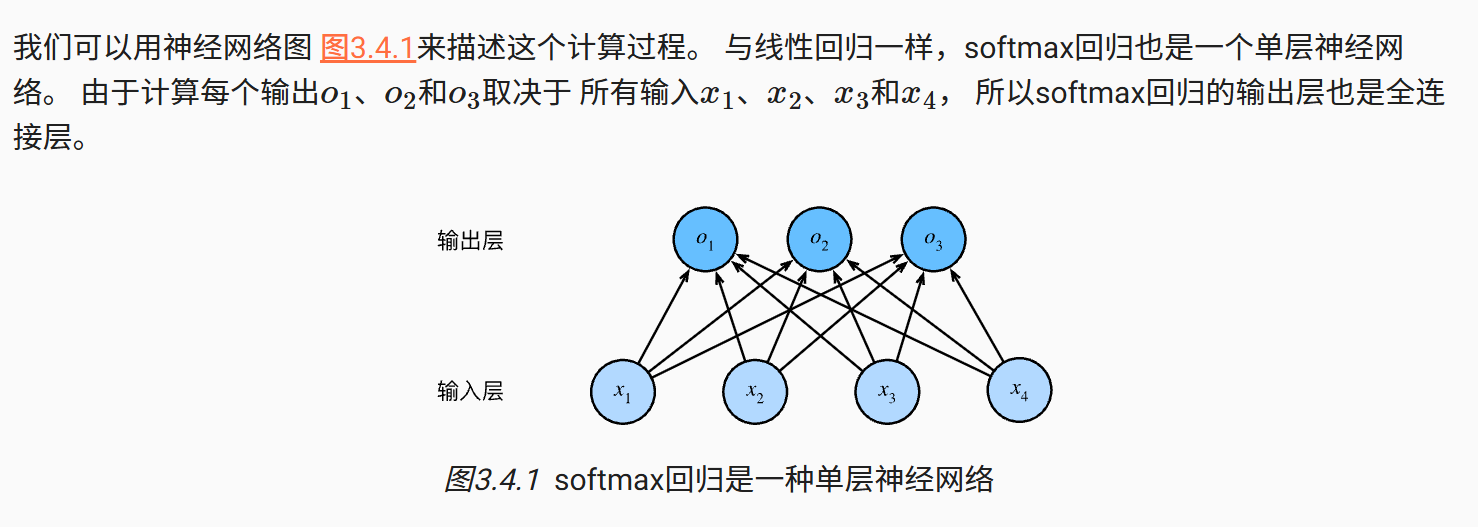
要将输出视为概率,我们必须保证在任何数据上的输出都是非负的且总和为1。 此外,我们需要一个训练的目标函数,来激励模型精准地估计概率。 例如, 在分类器输出0.5的所有样本中,我们希望这些样本是刚好有一半实际上属于预测的类别。 这个属性叫做校准(calibration)。
接下来对预测的概率值做一个处理,使其非负且总和为1

第一个公式描述的是给定x的前提下所有标签的连乘概率,每一次事件都会对结果产生影响,MLE(最大似然估计)就是要最大化这个概率
第二个公式是取对数,将乘法转换为加法,最大值改为求最小值
第三个公式描述的是损失函数


图像数据集
图像数据集使用Fashion-MNIST数据集
-
像素值范围:
- 在计算机中,一张图像由像素(Pixel)组成,每个像素的颜色通常用数值表示。
- 对于 8位灰度图像(如FashionMNIST),每个像素的取值范围是
[0, 255]:0表示纯黑色,255表示纯白色,- 中间值表示不同深浅的灰色。
- 对于彩色图像(如RGB),每个通道(红、绿、蓝)的取值范围也是
[0, 255]。
-
归一化(Normalization):
- 归一化是指将数据缩放到一个固定的范围(这里是
[0, 1])。 transforms.ToTensor()会自动将像素值从[0, 255]除以255,转换到[0, 1]。
- 归一化是指将数据缩放到一个固定的范围(这里是
-
灰度图像(Grayscale Image):
- 是一种单通道图像,每个像素只有一个数值表示亮度(没有颜色信息)。
- 数值范围通常是
[0, 255]:0:纯黑色,255:纯白色,- 中间值:灰色(如
128是中灰色)。
-
FashionMNIST 数据集是灰度图像,每张图片大小为
28x28像素,像素值范围[0, 255]。 -
通过
ToTensor()转换后:- 形状从
(28, 28)变为(1, 28, 28)(添加了通道维度)。 - 像素值从
[0, 255]缩放到[0, 1]。
- 形状从
先下载数据
trans=transforms.ToTensor()
mnist_train=torchvision.datasets.FashionMNIST(root='./data',train=True,transform=trans,download=True
)
mnist_test=torchvision.datasets.FashionMNIST(root='./data',train=False,transform=trans,download=True
)
再展示图片
import re
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
import matplotlib.pyplot as plttrans=transforms.ToTensor()
mnist_train=torchvision.datasets.FashionMNIST(root='./data',train=True,transform=trans,download=True
)
mnist_test=torchvision.datasets.FashionMNIST(root='./data',train=False,transform=trans,download=True
)
def get_fashion_mnist_labels(labels): """返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_fashion_mnist(imgs,num_rows,num_cols,title=None,scale=1.5):figsize=(num_cols * scale, num_rows* scale)_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax,img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):ax.imshow(img.numpy())else:ax.imshow(img)ax.axes.get_xaxis().set_visible(False) ax.axes.get_yaxis().set_visible(False)if title:ax.set_title(title[i])plt.show()return axes
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_fashion_mnist(X.reshape(18, 28, 28), 2, 9, title=get_fashion_mnist_labels(y))接下来通过内置数据迭代器来读取小批量数据
batch_size = 256
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=4)
综合下载数据并返回迭代器
def load_data_fashion_mnist(batch_size, resize=None): #@save"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
从0开始实现softmax
将28*28的图像展平后得到784的向量,也就是一个w,而我们有十个输出,所以有10个w
所以权重将构成一个784*10的矩阵
num_inputs = 784
num_outputs = 10W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)

def softmax(X):X_exp = torch.exp(X)partition = X_exp.sum(1, keepdim=True)return X_exp / partition # 这里应用了广播机制
定义模型:其实就是将数据转换为w*x+b
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
在分类问题中,最常用的损失函数就是交叉熵函数
- 分类任务需要模型输出 “属于某一类的概率”(如“这张图是猫的概率是90%”)。
- 交叉熵直接衡量 预测概率分布 和 真实标签分布 的差异,完美匹配这一需求。

具体实现
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])cross_entropy(y_hat, y)
softmax求精度,就是把预测值跟真实值作比较,最后用正确数/总数,下面描述的其实是怎么得到预测值的一个过程

利用框架API实现
我们还是一样先读取数据
def load_data_fashion_mnist(batch_size, resize=None): """下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
进行w和b的初始化
net=nn.Sequential(nn.Flatten(),nn.Linear(784, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, mean=0, std=0.01)nn.init.constant_(m.bias, 0)net.apply(init_weights)

模型训练代码
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import numpy as np# 1. 数据加载函数
def load_data_fashion_mnist(batch_size):"""下载Fashion-MNIST数据集并返回数据加载器"""transform = transforms.ToTensor()train_data = datasets.FashionMNIST(root="./data", train=True, transform=transform, download=True)test_data = datasets.FashionMNIST(root="./data", train=False, transform=transform, download=True)return (DataLoader(train_data, batch_size, shuffle=True, num_workers=0), # Windows必须设为0DataLoader(test_data, batch_size, shuffle=False, num_workers=0))# 2. 模型定义
def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)nn.init.zeros_(m.bias)net = nn.Sequential(nn.Flatten(),nn.Linear(784, 10)
)
net.apply(init_weights)# 3. 训练工具
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)def accuracy(y_hat, y):"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.sum())class Accumulator:"""用于累加多个指标"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def __getitem__(self, idx):return self.data[idx]# 4. 可视化类(适配普通Python脚本)
class Animator:def __init__(self, xlabel='epoch', legend=None, figsize=(8, 4)):self.fig, self.ax = plt.subplots(figsize=figsize)self.xlabel = xlabelself.legend = legendself.lines = Noneplt.show(block=False) # 非阻塞显示def update(self, x, y_values):"""更新图表数据"""if self.lines is None:# 第一次调用时创建线条self.lines = []for _ in range(len(y_values)):line, = self.ax.plot([], [])self.lines.append(line)if self.legend:self.ax.legend(self.lines, self.legend)self.ax.grid()# 更新每条线的数据for line, y in zip(self.lines, y_values):x_data = list(line.get_xdata())y_data = list(line.get_ydata())x_data.append(x)y_data.append(y)line.set_data(x_data, y_data)# 调整坐标轴范围self.ax.relim()self.ax.autoscale_view()self.ax.set_xlabel(self.xlabel)self.fig.canvas.draw()plt.pause(0.01) # 短暂暂停让GUI更新# 5. 训练和评估函数
def train_epoch(net, train_iter, loss, optimizer):"""训练一个epoch"""metric = Accumulator(3) # 训练损失总和,训练准确度总和,样本数for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)optimizer.zero_grad()l.backward()optimizer.step()metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0]/metric[2], metric[1]/metric[2] # 平均损失,准确率def evaluate_accuracy(net, data_iter):"""评估模型在数据集上的准确率"""net.eval() # 评估模式metric = Accumulator(2) # 正确预测数,总预测数with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]def train(net, train_iter, test_iter, loss, num_epochs, optimizer):"""完整训练过程"""animator = Animator(xlabel='epoch', legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_loss, train_acc = train_epoch(net, train_iter, loss, optimizer)test_acc = evaluate_accuracy(net, test_iter)animator.update(epoch + 1, (train_loss, train_acc, test_acc))plt.show(block=True) # 训练结束后保持窗口显示# 6. 主程序
if __name__ == '__main__':# 参数设置batch_size = 256num_epochs = 10# 加载数据train_iter, test_iter = load_data_fashion_mnist(batch_size)# 开始训练print("开始训练...")train(net, train_iter, test_iter, loss, num_epochs, optimizer)print("训练完成!")# 保存模型torch.save(net.state_dict(), 'fashion_mnist_model.pth')print("模型已保存到 fashion_mnist_model.pth")
后面写的有点草率,一直学一个东西会疲劳,先调整一下再回来接着学


![[每日随题10] DP - 重链剖分 - 状压DP](http://pic.xiahunao.cn/[每日随题10] DP - 重链剖分 - 状压DP)





现已发布,包括许多针对ASP.NET Core的重要改进!)




技术全景:原理、实现与前沿应用深度解析)





