一、NLTK_介绍
NLTK(Natural Language Toolkit,自然语言处理工具包),一个主要用于清洗和处理英文文本的Python工具包。它有很多的功能,我们主要使用的是它的分词功能,之前讲过中文分词是比较复杂的,但是英文分词只需要按照空格分割就好了,英文分词的重点是词形还原,自定义词组等等这些需求。英文的它会随着单复数、时态、人称等等发生拼写的变化。我们在分词的时候就要还原这个单词的原型。
安装:
pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
下载语料库
import nltk nltk.download()下载
punkt,averaged_perceptron_tagger,averaged_perceptron_tagger_eng,wordnet,stopwords
二、分词
# 导入NLTK的分词工具
from nltk import word_tokenize# 待处理的英文文本
text = '''
I have my own name. They all say it's a nice name. I'd like to know what your name is.
'''# 使用word_tokenize进行分词
tokens = word_tokenize(text)# 将所有单词转为小写
res = [i.lower() for i in tokens]# 输出结果
print(res)
['i', 'have', 'my', 'own', 'name', '.', 'they', 'all', 'say', 'it', "'s", 'a', 'nice', 'name', '.', 'i', "'d", 'like', 'to', 'know', 'what', 'your', 'name', 'is', '.']三、词形还原
NLTK可以将英文中的动词,名词,形容词等词形还原为原型
# 词形还原
from nltk.stem import WordNetLemmatizer
# 创建词形还原对象
wnl = WordNetLemmatizer()
# 词形还原,需要传入词和词形
print(wnl.lemmatize('better', pos='a'))
print(wnl.lemmatize('saddest', pos='a'))words = ['cars', 'men',"running","ate","saddest","fancier"]
pos_tags = ['n','n','v','v','a','a']for i in range(len(words)):print(words[i]+"--->"+ wnl.lemmatize(words[i],pos_tags[i]))
四、Text对象
Text是NLTK中一个非常有用的对象,它提供了一种方便的方式来处理和分析文本数据。他可以进行文本统计,词频可视化,文本搜索等等文本操作。
from nltk.text import Text
from nltk import word_tokenize
text='''
I have my own name. They all say it's a nice name. I'd like to know what your name is.
'''
# 分词
tokens = nltk.word_tokenize(text)# 创建Text对象
text = nltk.Text(tokens)# 词频统计
print(text.count('to'))# 计算每个单词的频率
fdist = text.vocab()
print(fdist.most_common(10)) # 输出前10个最频繁的词# 查找某个单词的上下文
print(text.concordance('nice'))# 绘制词频个分布图
text.plot(5) # 绘制前5个最频繁的词
1
[('name', 3), ('.', 3), ('I', 2), ('have', 1), ('my', 1), ('own', 1), ('They', 1), ('all', 1), ('say', 1), ('it', 1)]
Displaying 1 of 1 matches:
e my own name . They all say it 's a nice name . I 'd like to know what your n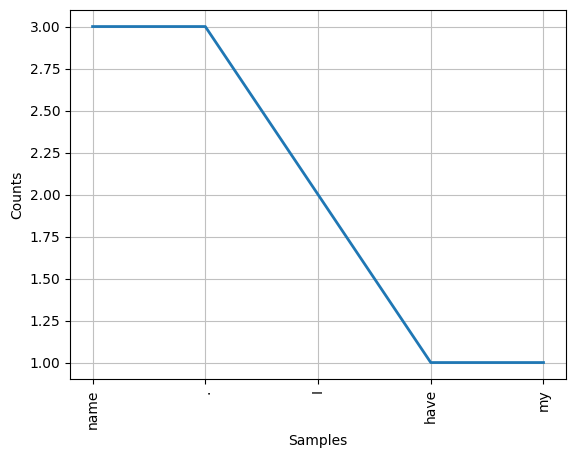
五、停用词
# 导入NLTK库中的停用词语料库
from nltk.corpus import stopwords# 打印所有可用的停用词语言列表
print(stopwords.fileids()) # 输出例如['arabic', 'azerbaijani', 'danish'...]# 获取英语停用词列表
english_stopwords = stopwords.words('english') # 获取英语停用词列表
print(english_stopwords) # 打印输出英语停用词,如['i', 'me', 'my'...]'''
中文注释说明:
1. stopwords.fileids() - 查看NLTK支持的所有停用词语言
2. stopwords.words('language') - 获取指定语言的停用词列表
3. 英语停用词包含"a", "the", "is"等常见但对语义分析无重要意义的词汇
'''过滤停用词
text = '''
I have my own name. They all say it's a nice name. I'd like to know what your name is.
'''# 使用word_tokenize对文本进行分词
tokenize = word_tokenize(text)# 创建不重复的小写单词集合
tokenize_word = set({i.lower() for i in tokenize})# 过滤停用词,只保留非停用词
[i for i in tokenize_word if i.lower() not in english_stopwa]'''
代码功能说明:
1. 定义了一个英文文本字符串
2. 使用word_tokenize将文本分割成单词列表
3. 通过集合推导式生成不重复的小写单词集合
4. 最后使用列表推导式过滤掉停用词,只保留有实际意义的词汇六、词性标注
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tagtext = "It's a leading platform for building Python programs to work with human language data."
tokens = word_tokenize(text) # 分词
tags = pos_tag(tokens) # 词性标注print(tags)| POS Tag | 指代 |
|---|---|
| CC | 并列连词 |
| CD | 基数词 |
| DT | 限定符 |
| EX | 存在词 |
| FW | 外来词 |
| IN | 介词或从属连词 |
| JJ | 形容词 |
| JJR | 比较级的形容词 |
| JJS | 最高级的形容词 |
| LS | 列表项标记 |
| MD | 情态动词 |
| NN | 名词单数 |
| NNS | 名词复数 |
| NNP | 专有名词 |
| PDT | 前置限定词 |
| POS | 所有格结尾 |
| PRP | 人称代词 |
| PRP$ | 所有格代词 |
| RB | 副词 |
| RBR | 副词比较级 |
| RBS | 副词最高级 |
| RP | 小品词 |
| UH | 感叹词 |
| VB | 动词原型 |
| VBD | 动词过去式 |
| VBG | 动名词或现在分词 |
| VBN | 动词过去分词 |
| VBP | 非第三人称单数的现在时 |
| VBZ | 第三人称单数的现在时 |
| WDT | 以wh开头的限定词 |
七、分块功能
英文中的词组数量非常多,很难全部表示出来,但英文的词组构成有一定规律,比如动词短语是动词+名词,形容词短语是形容词+名词。NLTK 提供了正则表达式分块的方式来识别和构建自定义词组。
我们可以定义的正则表达式来匹配和组合文本中的词汇,从而创建自定义的词组。
from nltk.tokenize import word_tokenize
from nltk import pos_tag, RegexpParser# 示例文本
text = "The quick brown fox jumped over the lazy dog."# 分词和词性标注
tokens = word_tokenize(text)
tagged = pos_tag(tokens)# 定义名词短语规则
grammar = """NP: {<DT>?<JJ>*<NN>} # 名词短语
"""# 创建语法分析器
parser = RegexpParser(grammar)
tree = parser.parse(tagged)# 打印结果
data = tree.pretty_print()# 提取并输出词组,查找所有名词短语
for subtree in tree.subtrees(filter=lambda t: t.label() == 'NP'):print(' '.join([token for token, pos in subtree.leaves()]))















![[设计模式]C++单例模式的几种写法以及通用模板](http://pic.xiahunao.cn/[设计模式]C++单例模式的几种写法以及通用模板)


添加背景音乐)
