Redis 数据结构
String 字符串
基本命令表
| 命令 | 执行效果 | 时间复杂度 |
|---|---|---|
| set key value [key value…] | 设置 key 的值是 value | O(k), k 是键个数 |
| get key | 获取 key 的值 | O(1) |
| del key [key …] | 删除指定的 key | O(k), k 是键个数 |
| mset key value [key value …] | 批量设置指定的 key 和 value | O(k), k 是键个数 |
| mget key [key …] | 批量获取 key 的值 | O(k), k 是键个数 |
| incr key | 指定的 key 的值 +1 | O(1) |
| decr key | 指定的 key 的值 -1 | O(1) |
| incrby key n | 指定的 key 的值 +n | O(1) |
| decrby key n | 指定的 key 的值 -n | O(1) |
| incrbyfloat key n | 指定的 key 的值 +n(浮点数) | O(1) |
| append key value | 指定的 key 的值追加 value | O(1) |
| strlen key | 获取指定 key 的值的长度 | O(1) |
| setrange key offset value | 覆盖指定 key 的从 offset 开始的部分值 | O(n),n 是字符串长度,通常视为 O(1) |
| getrange key start end | 获取指定 key 的从 start 到 end 的部分值 | O(n),n 是字符串长度,通常视为 O(1) |
SET 命令
将 string 类型的 value 设置到 key 中。如果 key 之前存在,则覆盖,无论原来的数据类型是什么。之前关于此 key 的 TTL 也全部失效。
SET 命令支持多种选项来影响它的行为:
- EX seconds——使用秒作为单位设置 key 的过期时间。
- PX milliseconds——使用毫秒作为单位设置 key 的过期时间。
- NX——只在 key 不存在时才进行设置,即如果 key 之前已经存在,设置不执行。
- XX——只在 key 存在时才进行设置,即如果 key 之前不存在,设置不执行。
注意:由于带选项的 SET 命令可以被 SETNX、SETEX、PSETEX 等命令代替,所以之后的版本中,Redis 可能进行合并。
Hash 哈希
几乎所有的主流编程语言都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组、映射。在 Redis 中,哈希类型是指值本身又是一个键值对结构,形如 key = “key”,value = { {field1, value1 }, …, {fieldN, valueN } }。
哈希类型中的映射关系通常称为 field-value,用于区分 Redis 整体的键值对(key-value),注意这里的 value 是指 field 对应的值,不是键(key)对应的值,请注意 value 在不同上下文的作用。
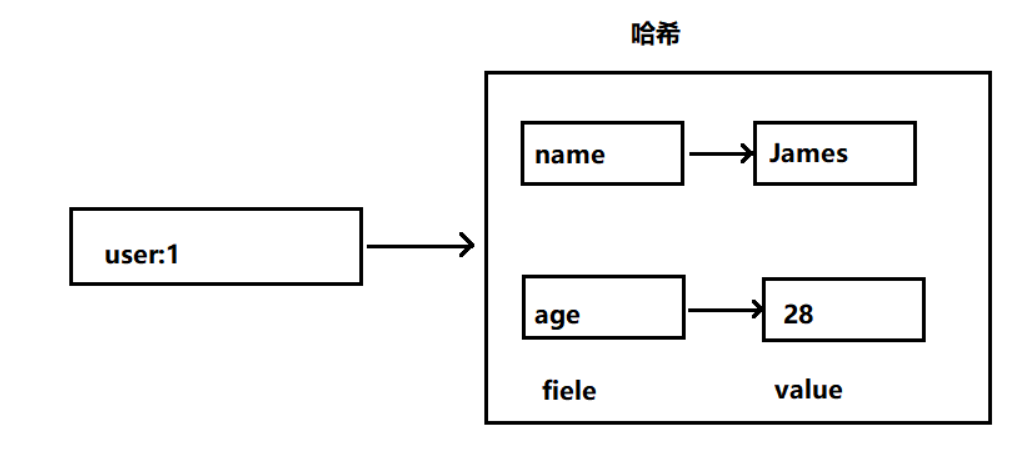
基本命令表
| 命令 | 执行效果 | 时间复杂度 |
|---|---|---|
| hset key field value | 设置值 | O(1) |
| hget key field | 获取值 | O(1) |
| hdel key field [field …] | 删除 field | O(k), k 是 field 个数 |
| hlen key | 计算 field 个数 | O(1) |
| hgetall key | 获取所有的 field-value | O(k), k 是 field 个数 |
| hmget key field [field …] | 批量获取 field-value | O(k), k 是 field 个数 |
| hmset key field value [field value …] | 批量设置 field-value | O(k), k 是 field 个数 |
| hexists key field | 判断 field 是否存在 | O(1) |
| hkeys key | 获取所有的 field | O(k), k 是 field 个数 |
| hvals key | 获取所有的 value | O(k), k 是 field 个数 |
| hsetnx key field value | 设置值,但必须在 field 不存在时才能设置成功 | O(1) |
| hincrby key field n | 对应 field-value +n | O(1) |
| hincrbyfloat key field n | 对应 field-value +n(浮点数) | O(1) |
| hstrlen key field | 计算 value 的字符串长度 | O(1) |
注意:
在使用 HGETALL 时,如果哈希元素个数比较多,会存在阻塞 Redis 的可能。如果开发人员只需要获取部分 field,可以使用 HMGET,如果一定要获取全部 field,可以尝试使用 HSCAN 命令,该命令采用渐进式遍历哈希类型。
List 列表
列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。
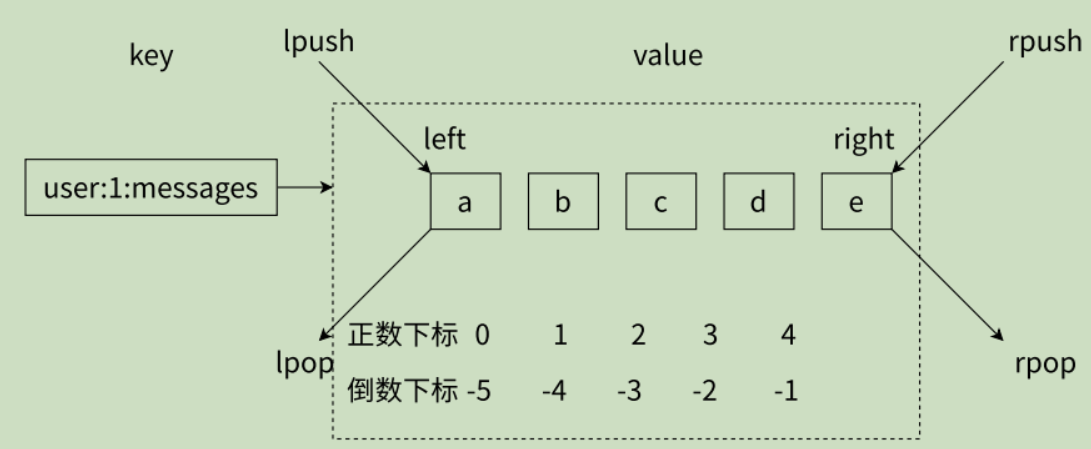
特点:
- 第一、列表中的元素是有序的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表,例如要获取第 5 个元素,可以执行
lindex user:1:messages 4;获取倒数第 1 个元素,lindex user:1:messages -1即可。 - 第二、区分获取和删除的区别,例如
lrem 1 b是从列表中把从左数遇到的前 1 个 b 元素删除,这个操作会导致列表的长度变化;但执行lindex 4只会获取元素,列表长度不变。 - 第三、列表中的元素是允许重复的。
阻塞版本命令
blpop 和 brpop 是 lpop 和 rpop 的阻塞版本,和对应非阻塞版本的作用基本一致,除了:
- 在列表中有元素的情况下,阻塞和非阻塞表现是一致的。但如果列表中没有元素,非阻塞版本会立即返回 nil,但阻塞版本会根据 timeout 阻塞一段时间,期间 Redis 可以执行其他命令,但执行该命令的客户端会表现为阻塞状态。
- 命令中如果设置了多个键,那么会从左向右进行遍历键,一旦有一个键对应的列表中可以弹出元素,命令立即返回。
- 如果多个客户端同时对一个键执行 pop,则最先执行命令的客户端会得到弹出的元素。
列表不为空时:
lpop user:1:messages 得到 x 元素
blpop user:1:messages 得到 x 元素
两者行为一致列表为空时,且 5 秒内没有新元素加入:
lpop user:1:messages 立即得到 nil
blpop user:1:messages 5 执行命令 5 秒后得到 nil
两者行为不一致列表为空时,且 5 秒内有新元素加入:
lpop user:1:messages 立即得到 nil
blpop user:1:messages 5 执行命令,直到新元素加入,得到新元素
两者行为不一致
基本列表命令
| 操作类型 | 命令 | 时间复杂度 |
|---|---|---|
| 添加 | rpush key value [value …] | O(k),k 是元素个数 |
| lpush key value [value …] | O(k),k 是元素个数 | |
| linsert key before/after pivot value | O(n),n 是 pivot 距离头尾的距离 | |
| 查找 | lrange key start end | O(s+n),s 是 start 偏移量,n 是 start 到 end 的范围 |
| lindex key index | O(n),n 是索引的偏移量 | |
| llen key | O(1) | |
| 删除 | lpop key | O(1) |
| rpop key | O(1) | |
| lrem key count value | O(k),k 是元素个数 | |
| ltrim key start end | O(k),k 是元素个数 | |
| 修改 | lset key index value | O(n),n 是索引的偏移量 |
| 阻塞操作 | blpop key [key …] timeout | O(1) |
| brpop key [key …] timeout | O(1) |
Set 集合
集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中:1)元素之间是无序的;2)元素不允许重复。一个集合中最多可以存储 2^32 - 1 个元素。Redis 除了支持集合内的增删查改操作,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多问题。
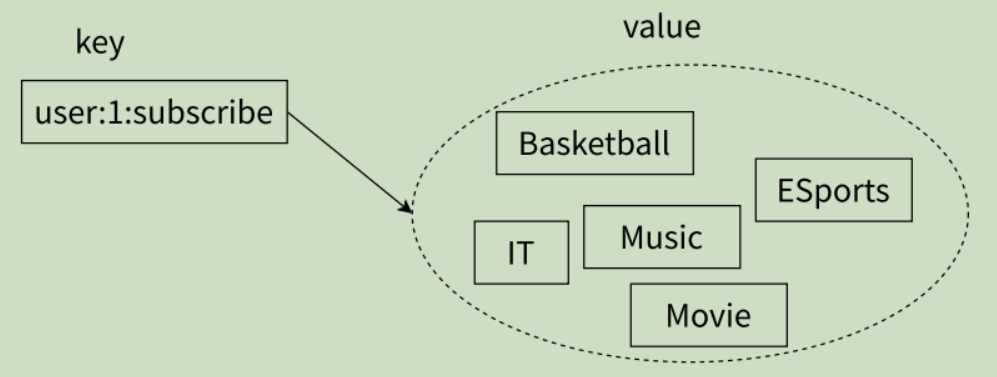
SPOP
从 set 中删除并返回一个或者多个元素。注意,由于 set 内的元素是无序的,所以取出哪个元素实际是未定义行为,即可以看作随机的。
基本命令表
| 命令 | 描述 | 时间复杂度 |
|---|---|---|
| SADD key member [member …] | 向集合添加一个或多个成员 | O(1)(单个元素),批量添加时为 O(k),k 是成员个数 |
| SCARD key | 获取集合的成员数 | O(1) |
| SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 | O(1) |
| SMEMBERS key | 返回集合中的所有成员 | O(N),其中 N 为集合中的成员数量 |
| SPOP key [count] | 移除并返回集合中的一个随机成员;如果指定了 count,则返回多个随机成员 | O(1)(单个元素),指定 count 时为 O(count) |
| SREM key member [member …] | 从集合中移除一个或多个成员 | O(N),其中 N 为被删除的成员数量 |
| SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合 | O(1) |
| SDIFF key [key …] | 返回第一个集合与其他集合之间的差异(差集) | O(N),其中 N 为所有集合中成员的总数量 |
| SDIFFSTORE destination key [key …] | 返回给定所有集合的差集并存储在 destination 中 | O(N),其中 N 为所有集合中成员的总数量 |
| SINTER key [key …] | 返回所有给定集合的交集 | O(N*M),其中 N 为最小集合中元素的数量,M 为参数中集合的数量 |
| SINTERSTORE destination key [key …] | 返回所有给定集合的交集并存储在 destination 中 | O(N*M),其中 N 为最小集合中元素的数量,M 为参数中集合的数量 |
| SUNION key [key …] | 返回所有给定集合的并集 | O(N),其中 N 为所有集合中成员的总数量 |
| SUNIONSTORE destination key [key …] | 返回所有给定集合的并集并存储在 destination 中 | O(N),其中 N 为所有集合中成员的总数量 |
| SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素 | O(1)(每次调用),完整迭代为 O(N) |
Zset 有序集合
有序集合保留了集合不能有重复成员的特点,但与集合不同的是,有序集合中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,这使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据而是用这个分数。
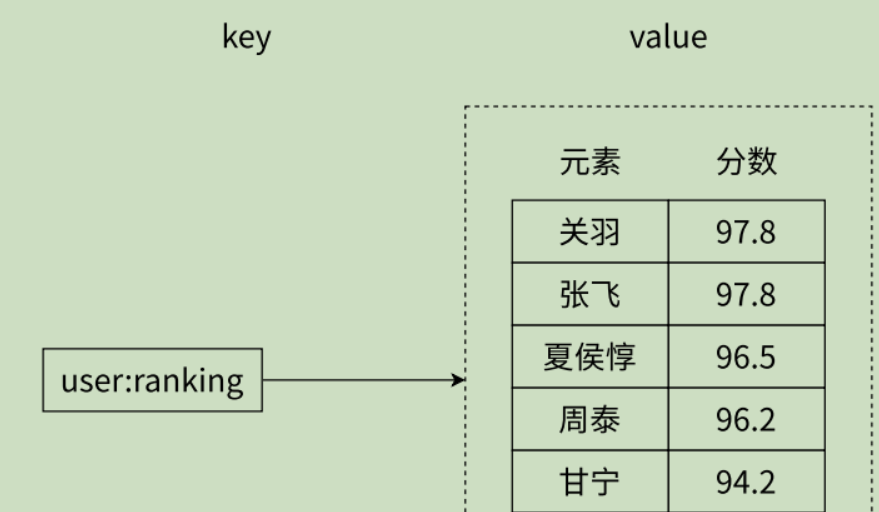
有序集合中的元素是不能重复的,但分数允许重复。类比于一次考试之后,每个人一定有一个唯一的分数,但分数允许相同。
ZADD 命令
添加或者更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负极限也是合法的。
ZADD 的相关选项:
- XX:仅仅用于更新已经存在的元素,不会添加新元素。
- NX:仅用于添加新元素,不会更新已经存在的元素。
- CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。
- INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定一个元素和分数。
基本命令表
| 命令 | 描述 | 时间复杂度 |
|---|---|---|
| ZADD key score member [score member …] | 添加一个或多个成员到有序集合,或者更新已存在成员的分数。 | O(k * log(n)),其中 k 是添加的成员个数,n 是当前有序集合的元素个数。 |
| ZCARD key | 获取有序集合的成员数。 | O(1) |
| ZSCORE key member | 返回有序集中,成员的分数值。 | O(1) |
| ZRANK key member | 返回有序集中指定成员的排名(从 0 开始,按分数升序)。 | O(log(n)),其中 n 是当前有序集合的元素个数。 |
| ZREVRANK key member | 返回有序集中指定成员的排名(从 0 开始,按分数降序)。 | O(log(n)),其中 n 是当前有序集合的元素个数。 |
| ZREM key member [member …] | 移除有序集合中的一个或多个成员。 | O(k * log(n)),其中 k 是删除的成员个数,n 是当前有序集合的元素个数。 |
| ZINCRBY key increment member | 为有序集中成员的分数加上增量 increment。 | O(log(n)),其中 n 是当前有序集合的元素个数。 |
| ZRANGE key start end [WITHSCORES] | 返回有序集中指定区间内的成员,按分数从低到高排序。 | O(k + log(n)),其中 k 是获取的成员个数,n 是当前有序集合的元素个数。 |
| ZREVRANGE key start end [WITHSCORES] | 返回有序集中指定区间内的成员,按分数从高到低排序。 | O(k + log(n)),其中 k 是获取的成员个数,n 是当前有序集合的元素个数。 |
| ZRANGEBYSCORE key min max [WITHSCORES] | 返回所有成员的分数在 [min, max] 范围内的成员,按分数从低到高排序。 | O(k + log(n)),其中 k 是获取的成员个数,n 是当前有序集合的元素个数。 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回所有成员的分数在 [max, min] 范围内的成员,按分数从高到低排序。 | O(k + log(n)),其中 k 是获取的成员个数,n 是当前有序集合的元素个数。 |
| ZCOUNT key min max | 计算分数在 [min, max] 范围内的成员数量。 | O(log(n)),其中 n 是当前有序集合的元素个数。 |
| ZREMRANGEBYRANK key start end | 移除有序集合中给定的排名区间的所有成员。 | O(k + log(n)),其中 k 是移除的成员个数,n 是当前有序集合的元素个数。 |
| ZREMRANGEBYSCORE key min max | 移除有序集合中所有分数在 [min, max] 范围内的成员。 | O(k + log(n)),其中 k 是移除的成员个数,n 是当前有序集合的元素个数。 |
| ZINTERSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的交集,并将结果存储在新的有序集合中。 | O(n * k) + O(m * log(m)),其中 n 是输入集合中的最小元素个数,k 是集合个数,m 是目标集合元素个数。 |
| ZUNIONSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的并集,并将结果存储在新的有序集合中。 | O(n) + O(m * log(m)),其中 n 是输入集合的总元素个数,m 是目标集合元素个数。 |

)
与定时爬取网站→邮件通知(价格监控原型))








)


相同体坐标转化)

获取端口异常)

:PyCharm 安装教程)
