贝叶斯的核心思想就是,谁的概率高就归为哪一类。
贝叶斯推论
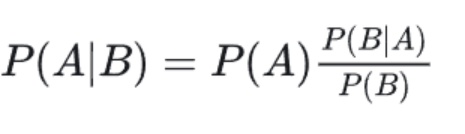
P(A):先验概率。即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B):后验概率。即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B):可能性函数。这是一个调整因子,使得预估概率更接近真实概率。
1、朴素贝叶斯实现鸢尾花分类
from sklearn.naive_bayes import MultionmialNB
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_irisx,y = load_iris(return_X_y=True)x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)
model = MultionmialNB()
model.fit(x_train,y_train)#训练模型(统计先验概率)
score = model.score(x_test,y_test)
print(score)#0.6666666666666666x_new=[[5,5,4,2],[1,1,4,3]]
y_predict = model.predict(x_new)
print(y_predict)#[1 2]2、朴素贝叶斯实现葡萄酒数据集分类
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine
x,y = load_wine(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25,random_state=42)
model = MultinomialNB()
model.fit(x_train,y_train)
print(model.score(x_test,y_test))#0.9111111111111111x_new = [[1,1,2,1,1,2,1,1,1,1,2,1,1]]
print(model.predict(x_new))#[1]


、主机虚拟机(Windows、Ubuntu)、手机(笔记本热点),三者进行相互ping通)















)