目录
一、从 RNN 到 DRNN:为什么需要 “深度”?
二、DRNN 的核心结构
1. 时间维度:循环传递
2. 空间维度:多层隐藏层
3. 双向 DRNN(Bidirectional DRNN)
三、DRNN 的关键挑战与优化
1. 梯度消失 / 爆炸
2. 训练不稳定
3. 计算复杂度
四、DRNN 的典型应用场景
五、DRNN 与其他模型的对比
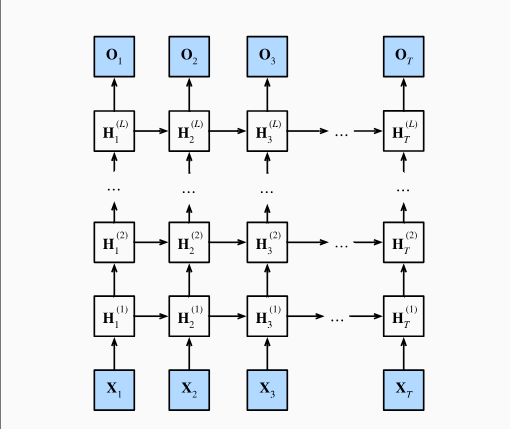
六、深度循环神经网络结构图
七、完整代码
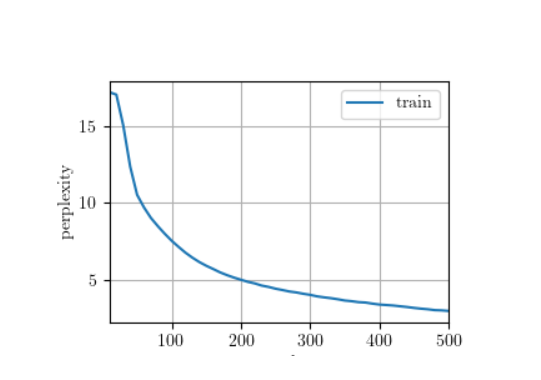
八、实验结果
深度循环神经网络(Deep Recurrent Neural Networks, DRNN)是循环神经网络(RNN)的深度扩展形式,其核心是在序列数据处理中引入多层隐藏结构,以捕捉更复杂的时序特征和层次化信息。相较于浅层 RNN,DRNN 能处理更复杂的序列任务(如长文本理解、语音识别、视频分析等),因为它可以分层提取从低级到高级的特征(如语音中的 “声波→音素→单词→语义”)。
一、从 RNN 到 DRNN:为什么需要 “深度”?
要理解 DRNN,需先明确 RNN 的基础逻辑:RNN 通过隐藏状态(hidden state) 保存历史信息,实现对序列数据(如文本、语音、视频帧)的建模。但其局限性在于:
- 浅层 RNN(单隐藏层)只能捕捉单一层次的时序特征,难以处理包含多尺度结构的复杂序列(如语言中 “字母→词→短语→句子” 的层级关系);
- 对于长序列或高维度输入(如视频帧的像素级数据),浅层网络的特征提取能力不足,容易出现 “欠拟合”。
DRNN 的核心改进是在时间步内堆叠多个隐藏层,让每一层专注于提取不同层次的特征(低层处理局部细节,高层处理抽象全局信息)。例如:在语音识别中,底层可能提取声波的频率特征,中层转换为音素特征,高层聚合为单词或语义。
二、DRNN 的核心结构
DRNN 的 “深度” 体现在同一时间步内的多层隐藏层堆叠,结合时间维度的循环结构,形成 “空间深度 + 时间循环” 的复合模型。其基本结构可拆解为以下要素:
1. 时间维度:循环传递
与 RNN 一致,DRNN 在时间上展开,每个时间步的输入依赖前序时间步的信息。设序列输入为 (T 为序列长度),则第 t 时间步的处理与
相关。
2. 空间维度:多层隐藏层
在每个时间步 t 内,DRNN 包含 L 个隐藏层(),层与层之间垂直堆叠:
- 第 1 层(底层)接收当前时间步的输入
和上一时间步第 1 层的隐藏状态
,输出
;
- 第 2 层接收第 1 层的输出
,输出
;
- ...
- 第 L 层(顶层)输出最终隐藏状态
,用于预测或后续任务(如分类、生成)。
以数学公式表示(假设使用 LSTM/GRU 作为隐藏层单元,缓解梯度问题): 对于第 l 层(),第 t 时间步的隐藏状态
计算为:
其中:
(第 0 层为输入层);
可为 LSTM、GRU 或改进的门控单元(避免基础 RNN 的梯度消失)。
3. 双向 DRNN(Bidirectional DRNN)
为同时利用 “过去” 和 “未来” 的信息(如语音识别中需结合上下文判断当前单词),DRNN 可扩展为双向结构:
- 正向层(Forward Layer):从序列起始到结束传递信息(利用过去);
- 反向层(Backward Layer):从序列结束到起始传递信息(利用未来);
- 最终输出为正向顶层和反向顶层的隐藏状态拼接(
)。
三、DRNN 的关键挑战与优化
深层结构虽提升特征能力,但也带来训练难度,核心挑战及解决方案如下:
1. 梯度消失 / 爆炸
- 问题:深层网络中,反向传播时梯度需经过多层传递,易因链式法则导致梯度衰减(消失)或放大(爆炸),尤其时间维度的循环会加剧这一问题。
- 解决方案:
- 用LSTM/GRU 替代基础 RNN:门控机制(输入门、遗忘门、输出门)可控制信息流动,减少梯度衰减;
- 梯度裁剪(Gradient Clipping):当梯度 norm 超过阈值时,缩放梯度至阈值内,避免爆炸;
- 优化器选择:Adam、RMSprop 等自适应学习率优化器可动态调整梯度更新幅度,缓解消失。
2. 训练不稳定
- 问题:深层网络中,不同层的学习速度差异大(低层可能饱和,高层仍未收敛),导致整体性能波动。
- 解决方案:
- 初始化策略:采用 Xavier/Glorot 初始化(针对 sigmoid/tanh 激活)或 He 初始化(针对 ReLU),使各层梯度方差相近;
- 时序归一化(Layer Normalization for Sequences):在循环层内对隐藏状态做归一化(避免批量归一化在时序数据中的分布偏移问题),稳定训练。
3. 计算复杂度
- 问题:深层 + 长序列会导致计算量激增(时间复杂度
,L 为层数,T 为序列长度,N 为隐藏单元数)。
- 解决方案:
- 简化隐藏层单元(如用轻量级 GRU 替代 LSTM);
- 截断长序列(如按固定长度分段);
- 量化训练(低精度计算)。
四、DRNN 的典型应用场景
DRNN 的多层特征提取能力使其在复杂序列任务中表现突出,典型场景包括:
-
语音识别 从原始声波(连续序列)中分层提取特征:底层处理频谱特征,中层转换为音素,高层聚合为单词,最终输出文本。双向 DRNN 结合 CTC( Connectionist Temporal Classification)损失,可实现端到端语音识别。
-
机器翻译 处理长句子时,DRNN 的深层结构可捕捉 “词→短语→句法结构→语义” 的多层关系,配合注意力机制(如 Encoder-Decoder 框架中的深度循环编码器),提升翻译准确性。
-
视频行为分析 视频帧序列中,底层提取像素 / 运动特征,中层识别局部动作(如 “挥手”),高层判断全局行为(如 “打招呼”)。DRNN 可建模帧间依赖,实现行为分类或预测。
-
情感分析(长文本) 长文本的情感依赖多层上下文(如 “虽然… 但是…” 的转折),DRNN 通过深层隐藏状态捕捉远距离语义关联,提升情感极性判断精度。
五、DRNN 与其他模型的对比
| 模型 | 核心优势 | 局限性 |
|---|---|---|
| 浅层 RNN | 计算简单,适合短序列 | 无法捕捉多层次特征 |
| DRNN | 多层特征提取,适合复杂序列 | 训练复杂,计算量大 |
| Transformer | 并行计算(自注意力),长依赖建模 | 对短序列效率低,需大量数据 |
| 深度 CNN+RNN | 结合空间特征(CNN)与时序特征(RNN) | 难以处理变长序列的动态依赖 |
六、深度循环神经网络结构图
七、完整代码
"""
文件名: 9.3 从零实现深度循环神经网络(DRNN)
作者: 墨尘
日期: 2025/7/16
项目名: dl_env
备注:
"""# -------------------------------------------------------------------------------------------------------- 基础工具库导入 ------------------------------------------------------------------------------
import collections # 用于统计词频(构建词表时需统计每个词元出现的次数)
import random # 随机抽样生成训练数据(增加数据随机性,提升模型泛化能力)
import re # 文本清洗(通过正则表达式过滤非目标字符)
import requests # 下载数据集(从网络获取《时间机器》文本数据)
from pathlib import Path # 文件路径处理(创建目录、检查文件是否存在等)
from d2l import torch as d2l # 深度学习工具库(提供训练辅助、可视化等功能)
import math # 数学运算(计算困惑度等指标)
import torch # PyTorch框架(核心深度学习库,提供张量运算、自动求导等)
from torch import nn # 神经网络模块(提供损失函数、层定义等)
from torch.nn import functional as F # 函数式API(提供激活函数、one-hot编码等工具)# 图像显示相关库(解决中文和符号显示问题)
import matplotlib.pyplot as plt
import matplotlib.text as text# --------------------------------------------------------------------------------------------------------核心解决方案:解决文本显示问题 --------------------------------------------------------------------------------------------------------
def replace_minus(s):"""解决Matplotlib中Unicode减号(U+2212)显示为方块的问题原理:将特殊减号替换为普通ASCII减号('-'),确保所有环境都能正常显示"""if isinstance(s, str): # 仅处理字符串类型return s.replace('\u2212', '-') # 替换Unicode减号为ASCII减号return s # 非字符串直接返回# 重写matplotlib的Text类的set_text方法,实现全局生效
original_set_text = text.Text.set_text # 保存原始方法(避免覆盖后无法恢复)def new_set_text(self, s):s = replace_minus(s) # 先处理减号return original_set_text(self, s) # 调用原始方法设置文本text.Text.set_text = new_set_text # 应用重写后的方法(所有文本显示都会经过此处理)# -------------------------- 字体配置(确保中文和数学符号正常显示)--------------------------
plt.rcParams["font.family"] = ["SimHei"] # 设置中文字体(SimHei支持中文显示,避免中文乱码)
plt.rcParams["text.usetex"] = True # 使用LaTeX渲染文本(提升数学符号显示美观度)
plt.rcParams["axes.unicode_minus"] = True # 确保负号正确显示(避免负号显示为方块)
plt.rcParams["mathtext.fontset"] = "cm" # 数学符号使用Computer Modern字体(LaTeX标准字体,更专业)
d2l.plt.rcParams.update(plt.rcParams) # 让d2l库的绘图工具继承上述配置(保持显示一致性)# --------------------------------------------------------------------------------------------------------数据处理模块 ------------------------------------------------------------------------------# -------------------------- 1. 读取数据 --------------------------
def read_time_machine():"""下载并读取《时间机器》数据集,返回清洗后的文本行列表作用:获取原始文本数据并预处理,为后续词元化做准备"""data_dir = Path('./data') # 数据存储目录(当前目录下的data文件夹)data_dir.mkdir(exist_ok=True) # 目录不存在则创建(exist_ok=True避免重复创建报错)file_path = data_dir / 'timemachine.txt' # 数据集文件路径# 检查文件是否存在,不存在则下载if not file_path.exists():print("开始下载时间机器数据集...")# 从d2l官方地址下载文本(《时间机器》是经典数据集,适合语言模型训练)response = requests.get('http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt')# 写入文件(utf-8编码确保兼容多种字符)with open(file_path, 'w', encoding='utf-8') as f:f.write(response.text)print(f"数据集下载完成,保存至: {file_path}")# 读取文件并清洗文本with open(file_path, 'r', encoding='utf-8') as f:lines = f.readlines() # 按行读取(每行作为列表元素)print(f"文件读取成功,总行数: {len(lines)}")if len(lines) > 0:print(f"第一行内容: {lines[0].strip()}") # 打印首行验证是否正确读取# 清洗规则:# 1. re.sub('[^A-Za-z]+', ' ', line):保留字母,其他字符(如数字、符号)替换为空格# 2. strip():去除首尾空格# 3. lower():转小写(统一大小写,减少词元数量)# 4. 过滤空行(if line.strip()确保仅保留非空行)cleaned_lines = [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines if line.strip()]print(f"清洗后有效行数: {len(cleaned_lines)}") # 清洗后非空行数量(去除纯空格行)return cleaned_lines# -------------------------- 2. 词元化与词表构建 --------------------------
def tokenize(lines, token='char'):"""将文本行转换为词元列表(词元是文本的最小处理单位)参数:lines: 清洗后的文本行列表(如["abc def", "ghi jkl"])token: 词元类型('char'字符级/'word'单词级)返回:词元列表(如字符级:[['a','b','c',' ','d','e','f'], ...])作用:将文本拆分为模型可处理的最小单元(词元),字符级适合简单语言模型"""if token == 'char':# 字符级词元化:将每行拆分为单个字符列表(包括空格,如"abc"→['a','b','c'])return [list(line) for line in lines]elif token == 'word':# 单词级词元化:按空格拆分每行(需确保文本已用空格分隔单词,如"abc def"→['abc','def'])return [line.split() for line in lines]else:raise ValueError('未知词元类型:' + token)class Vocab:"""词表类:实现词元与索引的双向映射,用于将文本转换为模型可处理的数字序列核心功能:将字符串形式的词元转换为整数索引(模型只能处理数字),同时支持索引转词元(用于生成文本)"""def __init__(self, tokens, min_freq=0, reserved_tokens=None):"""构建词表参数:tokens: 词元列表(可嵌套,如[[token1, token2], [token3]])min_freq: 最低词频阈值(低于此值的词元不加入词表,减少词汇量)reserved_tokens: 预留特殊词元(如分隔符、填充符等,模型可能需要的特殊标记)"""if reserved_tokens is None:reserved_tokens = [] # 默认为空(无预留词元)# 统计词频:# 1. 展平嵌套列表([token for line in tokens for token in line])# 2. 用Counter计数(得到{词元: 出现次数}字典)counter = collections.Counter([token for line in tokens for token in line])# 按词频降序排序(便于后续按频率筛选,高频词优先保留)self.token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)# 初始化词表:# <unk>(未知词元)固定在索引0(所有未见过的词元都映射到<unk>)# followed by预留词元(如用户指定的特殊标记)self.idx_to_token = ['<unk>'] + reserved_tokens# 构建词元到索引的映射(字典,便于快速查询)self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}# 按词频添加词元(过滤低频词)for token, freq in self.token_freqs:if freq < min_freq:break # 低频词不加入词表(提前终止,提升效率)if token not in self.token_to_idx: # 避免重复添加预留词元(如预留词元已在列表中)self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1 # 索引为当前长度-1(保持连续)def __len__(self):"""返回词表大小(词元总数,用于模型输入/输出维度设置)"""return len(self.idx_to_token)def __getitem__(self, tokens):"""词元→索引(支持单个词元或词元列表)未知词元返回<unk>的索引(0),确保模型输入始终有效"""if not isinstance(tokens, (list, tuple)):# 单个词元:查字典,默认返回<unk>的索引(0)return self.token_to_idx.get(tokens, self.unk)# 词元列表:递归转换每个词元(如['a','b']→[2,3])return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):"""索引→词元(支持单个索引或索引列表,用于将模型输出转换为文本)"""if not isinstance(indices, (list, tuple)):# 单个索引:直接查列表(如2→'a')return self.idx_to_token[indices]# 索引列表:递归转换每个索引(如[2,3]→['a','b'])return [self.idx_to_token[index] for index in indices]@propertydef unk(self):"""返回<unk>的索引(固定为0,便于统一处理未知词元)"""return 0# -------------------------- 3. 数据迭代器(随机抽样) --------------------------
def seq_data_iter_random(corpus, batch_size, num_steps):"""随机抽样生成批量子序列(生成器),用于模型训练的批量输入原理:从语料中随机截取多个长度为num_steps的子序列,组成批次(避免模型学习到固定的句子顺序)参数:corpus: 词元索引序列(1D列表,如[1,3,5,2,...],所有文本的词元索引拼接而成)batch_size: 批量大小(每个批次包含的子序列数,影响训练效率和内存占用)num_steps: 子序列长度(时间步,即模型一次处理的序列长度,如35表示一次输入35个词元)返回:生成器,每次返回(X, Y):X: 输入序列(batch_size, num_steps),模型的输入Y: 标签序列(batch_size, num_steps),是X右移一位的结果(模型需要预测的下一个词元)"""# 检查数据是否足够生成至少一个子序列(子序列长度+1,因Y是X右移1位,需多1个元素)if len(corpus) < num_steps + 1:raise ValueError(f"语料库长度({len(corpus)})不足,需至少{num_steps + 1}")# 随机偏移起始位置(0到num_steps-1),增加数据随机性(避免每次从固定位置开始)corpus = corpus[random.randint(0, num_steps - 1):]# 计算可生成的子序列总数:# (语料长度-1) // num_steps(-1是因Y需多1个元素,每个子序列需num_steps+1个元素)num_subseqs = (len(corpus) - 1) // num_stepsif num_subseqs < 1:raise ValueError(f"无法生成子序列(语料库长度不足)")# 生成所有子序列的起始索引(间隔为num_steps,如0, num_steps, 2*num_steps...)initial_indices = list(range(0, num_subseqs * num_steps, num_steps))random.shuffle(initial_indices) # 打乱起始索引,实现随机抽样(核心:避免子序列顺序固定)# 计算可生成的批次数:子序列总数 // 批量大小(确保每个批次有batch_size个子序列)num_batches = num_subseqs // batch_sizeif num_batches < 1:raise ValueError(f"子序列数量({num_subseqs})不足,需至少{batch_size}个")# 生成批量数据for i in range(0, batch_size * num_batches, batch_size):# 当前批次的起始索引(从打乱的索引中取batch_size个,如i=0时取前batch_size个)indices = initial_indices[i: i + batch_size]# 输入序列X:每个子序列从indices[j]开始,取num_steps个元素(如indices[j]=0→[0:35])X = [corpus[j: j + num_steps] for j in indices]# 标签序列Y:每个子序列从indices[j]+1开始,取num_steps个元素(X右移1位,如[1:36])Y = [corpus[j + 1: j + num_steps + 1] for j in indices]# 转换为张量返回(便于模型处理,PyTorch模型输入需为张量)yield torch.tensor(X), torch.tensor(Y)# -------------------------- 4. 数据加载函数(关键修复:返回可重置的迭代器) --------------------------
def load_data_time_machine(batch_size, num_steps):"""加载《时间机器》数据,返回数据迭代器生成函数和词表修复点:返回迭代器生成函数(而非一次性迭代器),确保训练时可重复生成数据(每个epoch重新抽样)参数:batch_size: 批量大小num_steps: 子序列长度(时间步)返回:data_iter: 迭代器生成函数(调用时返回新的迭代器,每次调用重新抽样)vocab: 词表对象(用于词元与索引的转换)"""lines = read_time_machine() # 读取清洗后的文本行tokens = tokenize(lines, token='char') # 字符级词元化(每个字符为词元,适合简单语言模型)vocab = Vocab(tokens) # 构建词表(根据词元生成索引映射)# 将所有词元转换为索引(展平为1D序列,如[[ 'a', 'b' ], [ 'c' ]]→[2,3,4])corpus = [vocab[token] for line in tokens for token in line]print(f"语料库长度: {len(corpus)}(词元索引总数)")# 定义迭代器生成函数:每次调用生成新的随机抽样迭代器(确保每个epoch数据不同)def data_iter():return seq_data_iter_random(corpus, batch_size, num_steps)return data_iter, vocab # 返回生成函数和词表# -------------------------------------------------------------------------------------------------------- 模型构建模块 ------------------------------------------------------------------------------
# -------------------------- 5. 自定义RNNModel类(解决d2l.RNNModel缺失问题) --------------------------
class RNNModel(nn.Module):"""自定义循环神经网络模型类,替代d2l.RNNModel,适配多层LSTM"""def __init__(self, rnn_layer, vocab_size):super(RNNModel, self).__init__()self.rnn = rnn_layer # 多层LSTM层(nn.LSTM)self.vocab_size = vocab_size # 词表大小self.num_hiddens = self.rnn.hidden_size # 隐藏层维度(从LSTM层获取)# 输出层:将LSTM的隐藏状态映射到词表维度(用于预测下一个词元)self.dense = nn.Linear(self.num_hiddens, vocab_size)def forward(self, inputs, state):"""前向传播:处理输入并返回输出和状态参数:inputs: 输入序列(batch_size, num_steps),元素为词元索引state: 初始隐藏状态((H_0, C_0),由begin_state生成)返回:output: 所有时间步的输出(batch_size * num_steps, vocab_size)state: 最终隐藏状态((H_t, C_t))"""# 1. 输入处理:转换为one-hot编码并转置为(num_steps, batch_size, vocab_size)X = F.one_hot(inputs.T.long(), self.vocab_size).type(torch.float32)# 2. LSTM前向传播:X为输入,state为初始状态# - output: (num_steps, batch_size, num_hiddens),所有时间步的顶层隐藏状态# - state: (H_t, C_t),最终的隐藏状态和记忆元output, state = self.rnn(X, state)# 3. 输出层映射:将隐藏状态转换为词表分布# - output.reshape(-1, output.shape[2]): 展平为(num_steps*batch_size, num_hiddens)# - 经dense层后得到(num_steps*batch_size, vocab_size)output = self.dense(output.reshape(-1, output.shape[2]))return output, statedef begin_state(self, batch_size, device):"""生成初始隐藏状态(LSTM需要两个初始状态:隐状态H和记忆元C)"""# LSTM的初始状态形状为:(num_layers, batch_size, num_hiddens)return (torch.zeros((self.rnn.num_layers, batch_size, self.num_hiddens), device=device),torch.zeros((self.rnn.num_layers, batch_size, self.num_hiddens), device=device))# -------------------------- 6. RNN模型包装类 --------------------------
class RNNModelScratch: # @save"""从零实现的RNN模型包装类,统一模型调用接口(适配训练和预测流程)"""def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):"""参数:vocab_size: 词表大小(输入/输出维度)num_hiddens: 隐藏层维度(记忆元/隐状态的维度)device: 计算设备get_params: 参数初始化函数(如get_lstm_params)init_state: 状态初始化函数(如init_lstm_state)forward_fn: 前向传播函数(如lstm)"""self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device) # 模型参数(通过get_params获取)self.init_state, self.forward_fn = init_state, forward_fn # 状态初始化和前向传播函数def __call__(self, X, state):"""模型调用接口(前向传播入口,兼容PyTorch的调用方式)参数:X: 输入序列(batch_size, num_steps),元素为词元索引(未编码的原始输入)state: 初始隐藏状态((H_0, C_0))返回:y_hat: 输出(num_steps*batch_size, vocab_size),所有时间步的输出拼接state: 最终隐藏状态((H_t, C_t))"""# 处理输入:# 1. X.T:转置为(num_steps, batch_size)(便于逐时间步处理,时间步在前)# 2. F.one_hot:转换为one-hot编码(num_steps, batch_size, vocab_size),将索引转为向量# 3. type(torch.float32):转换为浮点型(适配后续矩阵运算,权重为浮点型)X = F.one_hot(X.T, self.vocab_size).type(torch.float32)# 调用前向传播函数(如lstm)计算输出和新状态return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):"""获取初始隐藏状态(调用初始化函数,封装状态初始化逻辑)"""return self.init_state(batch_size, self.num_hiddens, device)# -------------------------------------------------------------------------------------------------------- 文本生成与训练模块 ------------------------------------------------------------------------------
# -------------------------- 7. 预测函数(文本生成) --------------------------
def predict_ch8(prefix, num_preds, net, vocab, device): # @save"""根据前缀生成后续字符(文本生成,验证模型学习效果)参数:prefix: 前缀字符串(如"time traveller",模型基于此生成后续内容)num_preds: 要生成的字符数net: 训练好的LSTM模型vocab: 词表(用于词元与索引的转换)device: 计算设备返回:生成的字符串(前缀+预测字符,如前缀"ti"生成"time...")"""# 初始化状态(批量大小为1,因仅生成一条序列,无需并行)state = net.begin_state(batch_size=1, device=device)# 记录输出索引:初始为前缀首字符的索引(将前缀转换为索引序列)outputs = [vocab[prefix[0]]]# 辅助函数:获取当前输入(最后一个输出的索引,形状(1,1),符合模型输入格式)def get_input():return torch.tensor([outputs[-1]], device=device).reshape((1, 1))# 预热期:用前缀更新模型状态(不生成新字符,仅让模型"记住"前缀的信息)for y in prefix[1:]:_, state = net(get_input(), state) # 前向传播,更新状态(忽略输出,因只需状态)outputs.append(vocab[y]) # 记录前缀字符的索引(确保outputs包含完整前缀)# 预测期:生成num_preds个字符for _ in range(num_preds):y, state = net(get_input(), state) # 前向传播,获取输出和新状态(y是当前时间步的输出)# 取概率最大的字符索引(贪婪采样:简单策略,选择模型认为最可能的下一个字符)outputs.append(int(y.argmax(dim=1).reshape(1)))# 将索引转换为字符,拼接成字符串返回(完成从索引到文本的转换)return ''.join([vocab.idx_to_token[i] for i in outputs])# -------------------------- 8. 梯度裁剪(防止梯度爆炸) --------------------------
def grad_clipping(net, theta): # @save"""裁剪梯度(将梯度L2范数限制在theta内),防止梯度爆炸(RNN训练中常见问题)原理:若梯度范数超过阈值theta,则按比例缩小所有梯度,确保训练稳定参数:net: 模型(自定义模型或nn.Module)theta: 梯度阈值(如1.0,根据经验设置)"""# 获取需要梯度更新的参数if isinstance(net, nn.Module):# 若为PyTorch官方Module,直接取parameters(包含所有需要梯度的参数)params = [p for p in net.parameters() if p.requires_grad]else:# 若为自定义模型(如RNNModelScratch),取params属性(存储模型参数)params = net.params# 计算所有参数梯度的L2范数(平方和开根号)norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta: # 若范数超过阈值,按比例裁剪(保持梯度方向不变,缩小幅度)for param in params:param.grad[:] *= theta / norm# -------------------------- 9. 训练函数 --------------------------
def train_epoch_ch8(net, train_iter_fn, loss, updater, device, use_random_iter):"""训练一个周期(单轮遍历数据集)参数:net: LSTM模型train_iter_fn: 迭代器生成函数(调用后返回新迭代器,每个epoch重新生成数据)loss: 损失函数(如CrossEntropyLoss,计算预测与标签的差距)updater: 优化器(如SGD,用于更新模型参数)device: 计算设备use_random_iter: 是否使用随机抽样(影响状态处理方式:随机抽样时状态独立,无需传递)返回:ppl: 困惑度(perplexity,语言模型性能指标,越低表示模型越好)speed: 训练速度(词元/秒,衡量训练效率)"""state, timer = None, d2l.Timer() # 初始化状态和计时器(timer用于计算训练速度)metric = d2l.Accumulator(2) # 累加器:(总损失, 总词元数),用于计算平均损失batches_processed = 0 # 记录处理的批次数量(验证是否有数据被处理)# 关键修复:每次训练都通过函数生成新的迭代器(避免迭代器被提前消费,确保每个epoch数据不同)train_iter = train_iter_fn()# 遍历批量数据(每个X, Y是一个批次)for X, Y in train_iter:batches_processed += 1# 初始化状态:# - 首次迭代时需初始化(state为None)# - 随机抽样时,每个批次的序列独立(无上下文关联),需重新初始化if state is None or use_random_iter:state = net.begin_state(batch_size=X.shape[0], device=device)else:# 非随机抽样时,分离状态(切断梯度回流到之前的批次,避免梯度计算依赖过长导致爆炸)if isinstance(net, nn.Module) and not isinstance(state, tuple):state.detach_() # 单个状态直接detach(如GRU只有隐状态)else:for s in state: # 多个状态(如LSTM有隐状态和记忆元)逐个detachs.detach_()# 处理标签:# Y.T.reshape(-1):转置后展平为(num_steps*batch_size,)(与输出y_hat的形状匹配)# 输出y_hat的形状是(num_steps*batch_size, vocab_size),标签需为1D张量y = Y.T.reshape(-1)# 将输入和标签移到目标设备(GPU/CPU,确保与模型参数在同一设备)X, y = X.to(device), y.to(device)# 前向传播:获取输出和新状态y_hat, state = net(X, state)# 计算损失(mean()是因损失函数可能返回每个样本的损失,取平均得到批次损失)l = loss(y_hat, y.long()).mean()# 反向传播与参数更新:if isinstance(updater, torch.optim.Optimizer):# 若为PyTorch优化器(如SGD)updater.zero_grad() # 清零梯度(避免梯度累积)l.backward() # 反向传播计算梯度grad_clipping(net, 1) # 裁剪梯度(阈值1,防止梯度爆炸)updater.step() # 更新参数else:# 若为自定义优化器(如d2l的sgd函数)l.backward()grad_clipping(net, 1)updater(batch_size=1) # 假设批量大小为1的更新(简化实现)# 累加总损失和总词元数(用于计算平均损失)# metric[0] += l * y.numel():总损失=批次损失×词元数(因l是平均损失)# metric[1] += y.numel():总词元数=累加每个批次的词元数量metric.add(l * y.numel(), y.numel())# 检查是否有批次被处理(避免空迭代导致的错误)if batches_processed == 0:print("警告:没有处理任何训练批次!")return float('inf'), 0# 计算困惑度(perplexity = exp(平均损失),语言模型专用指标,与交叉熵损失正相关)# 平均损失 = 总损失 / 总词元数,exp后得到困惑度(完美模型困惑度=1)# 速度 = 总词元数 / 训练时间(词元/秒,衡量训练效率)return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()def train_ch8(net, train_iter_fn, vocab, lr, num_epochs, device, use_random_iter=False):"""训练模型(多周期,整合单周期训练逻辑,输出训练过程和结果)参数:net: LSTM模型train_iter_fn: 迭代器生成函数vocab: 词表lr: 学习率(控制参数更新幅度)num_epochs: 训练周期数(遍历数据集的次数,影响模型收敛程度)device: 计算设备use_random_iter: 是否使用随机抽样(默认False,即顺序抽样)"""loss = nn.CrossEntropyLoss() # 交叉熵损失(适用于分类任务,此处为词元预测,多分类问题)# 动画器:可视化训练过程(实时绘制困惑度随周期变化的曲线,直观观察模型收敛情况)animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化优化器:if isinstance(net, nn.Module):# 若为PyTorch Module,使用SGD优化器(随机梯度下降,适合简单模型)updater = torch.optim.SGD(net.parameters(), lr)else:# 若为自定义模型,使用d2l的sgd函数(简化的随机梯度下降实现)updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)# 定义预测函数:根据前缀"time traveller"生成50个字符(验证模型学习效果)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 多周期训练for epoch in range(num_epochs):# 训练一个周期,返回困惑度和速度ppl, speed = train_epoch_ch8(net, train_iter_fn, loss, updater, device, use_random_iter)# 每10个周期打印一次预测结果(观察生成文本质量变化,判断模型是否学到有意义的模式)if (epoch + 1) % 10 == 0:print(f"epoch {epoch + 1} 预测: {predict('time traveller')}")animator.add(epoch + 1, [ppl]) # 记录困惑度,更新动画# 训练结束后输出最终结果(总结模型性能)print(f'最终困惑度 {ppl:.1f}, 速度 {speed:.1f} 词元/秒 {device}')print(f"time traveller 预测: {predict('time traveller')}") # 用"time traveller"前缀生成文本print(f"traveller 预测: {predict('traveller')}") # 用"traveller"前缀生成文本# -------------------------- 主程序 --------------------------
# -------------------------- 主程序 --------------------------
if __name__ == '__main__':# 超参数设置batch_size, num_steps = 32, 35 # 批量大小、时间步(与原代码一致)train_iter, vocab = load_data_time_machine(batch_size, num_steps) # 加载数据# 深度LSTM模型参数(核心改装:增加num_layers=2实现深层结构)vocab_size = len(vocab) # 输入/输出维度=词表大小num_hiddens = 256 # 每层隐藏状态维度num_layers = 2 # 隐藏层数量(深度为2,实现DRNN)device = d2l.try_gpu() # 自动选择设备(GPU优先)# 改装1:使用PyTorch官方nn.LSTM构建多层LSTM# nn.LSTM参数说明:# - input_size: 输入特征维度(此处为词表大小)# - hidden_size: 每层隐藏状态维度# - num_layers: 隐藏层数量(>=2即深度循环网络)lstm_layer = nn.LSTM(input_size=vocab_size,hidden_size=num_hiddens,num_layers=num_layers)# 改装2:使用d2l.RNNModel封装多层LSTM(适配训练框架)# d2l.RNNModel是d2l库中封装的循环神经网络模型类,兼容nn.LSTM/GRU等官方层# 功能:处理输入编码、连接输出层(将隐藏状态映射到词表维度)model = RNNModel(rnn_layer=lstm_layer, # 多层LSTM层vocab_size=vocab_size # 词表大小(输出层维度))model = model.to(device) # 将模型移动到目标设备# 训练深度LSTM模型(使用原有训练函数,兼容nn.Module类型模型)num_epochs, lr = 500, 0.12 # 训练周期、学习率(与原代码一致)train_ch8(model, train_iter, vocab, lr, num_epochs, device)plt.show(block=True) # 显示训练过程可视化图表八、实验结果




——默认成员函数)








(指针的深入理解与应用))


网页进行交互)
)

)