ICLR 2025
- 尽管 LoRA 有诸多优势,但近期研究表明,它在大规模训练数据集和复杂任务(如数学推理和代码生成)中,仍然落后于全参数微调(FFT)
- 一个合理的解释是:低秩约束限制了 LoRA 的表达能力
- Biderman 等(2024)实证发现,FFT 所需的有效秩比典型的 LoRA 配置高出 10 到 100 倍
- Zeng 与 Lee(2024)则从理论上证明:Transformer 网络若要逼近一个同规模的模型,其所需秩至少为模型维度的一半
- 尽管可训练参数数量受限,导致表达能力受限,但近期研究仍然指出 LoRA 参数中存在冗余性
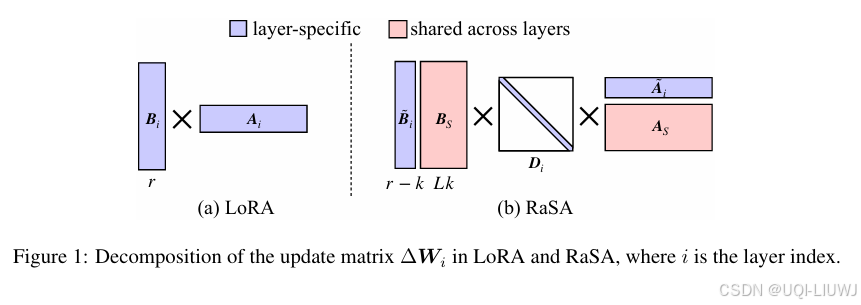
- ——>基于以上两点观察,论文提出了 Rank-Sharing Low-Rank Adaptation(RaSA),一种通过在层间部分共享秩来提升 LoRA 表达能力的方法


完整指南)



![[实战]巴特沃斯滤波器全流程解析:从数学原理到硬件实现](http://pic.xiahunao.cn/[实战]巴特沃斯滤波器全流程解析:从数学原理到硬件实现)

详解 + Python实现)

安装包免费免激活版下载 附图文详细安装教程)
(补题))

![[Linux]git_gdb](http://pic.xiahunao.cn/[Linux]git_gdb)
)
)
 的封装)
)

