阻塞队列
通过数据结构的学习,我们都知道了队列是一种“先进先出”的数据结构。阻塞队列,是基于普通队列,做出扩展的一种特殊队列。
特点
1、线程安全的
2、具有阻塞功能:1、如果针对一个已经满了的队列进行入队列,此时入队列操作就会阻塞,一直阻塞到队列不满(其他线程出队列元素)之后。2、如果针对一个已经空了的队列进行出队列,此时出队列操作就会阻塞,一直阻塞到队列不空(其他线程入队列元素)之后。
基于阻塞队列我们能够实现“生产者消费者模型”。
生产者消费者模型
什么是生产者消费者模型呢?
举个生活中的例子:
包饺子的流程:
1、和面(一般都是一个人(线程),没办法多个人(线程)完成)
2、擀饺子皮
3、包饺子(2和3都是可以多个人(线程)完成的)
现在有A、B、C三位老铁,共同完成包饺子的任务,擀面杖,一般一个家庭中只有一个擀面杖,所以会发生,三个线程同时去竞争这个擀面杖,A老铁拿到擀面杖擀皮了,B、C就需要阻塞等待,所以,包饺子的流程非常适合多线程的方式来实现,即A和完面,B负责擀皮,A(此时A已经释放了擀面杖)、C负责包饺子。B擀一个皮,A或者C就能包一个饺子……
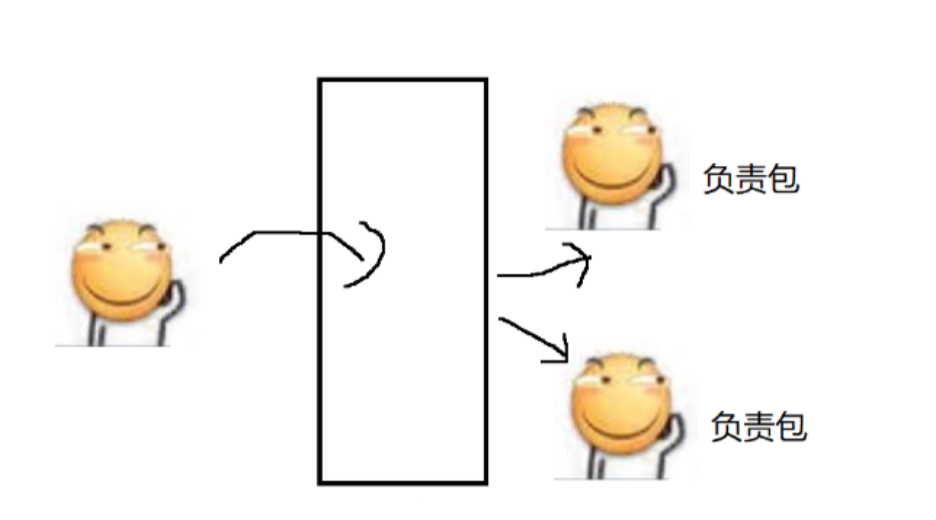
这里的分工协作,就构成了生产者消费者模型,擀饺子皮的线程就是生产者(生产饺子皮),擀完一个饺子皮 ,饺子皮数目+1,另外两个包饺子的线程,就是消费者(消费饺子皮),包完一个饺子,饺子皮数量-1。
中间的桌子就起到了“传递饺子皮”的效果,这个桌子的角色就相当于“阻塞队列”。
假设:擀饺子皮的线程速度非常快,而包饺子的人包的很慢。就会导致桌子上的饺子皮越来越多,一直这样下去,桌子上的饺子皮就会满了。此时擀饺子皮的人就得停下来等等,等这两个包饺子皮的人,用掉一些饺子皮,再接着擀……
反之,擀饺子皮的非常慢,包饺子的人包得非常快,就会导致桌子上的饺子皮所剩无几,一直这样下去,桌子上就没有饺子皮了。此时包饺子的人就得等一等,等擀饺子皮的人擀出饺子皮,再接着包……
上述例子,大概模拟了生产者消费者模型。
作用
1、解耦合
引入生产者消费者模型,就可以更好地做到“解耦合”。
耦合度:代码中不同的模块,类函数之间相互依赖,相互关联的紧密程度。
耦合度低:模块之间的关联关系弱,相互影响小。一个模块的修改不容易影响其他模块,各个模块之间可以相对独立进行开发……
耦合度高:模块之间的关联关系强,一个模块的修改往往会导致其他多个模块也需要相应的修改,代码的维护和扩展难度大……
在实际开发中,我们追求的是“高内聚,低耦合”,此时就可以使用阻塞队列降低耦合度。
实际开发中,经常会涉及到“分布式系统”:服务器整个功能不是由一个服务器全部完成的,而是每个服务器负责一部分功能,通过服务器之间的网络通信,最终完成整个功能。
图示: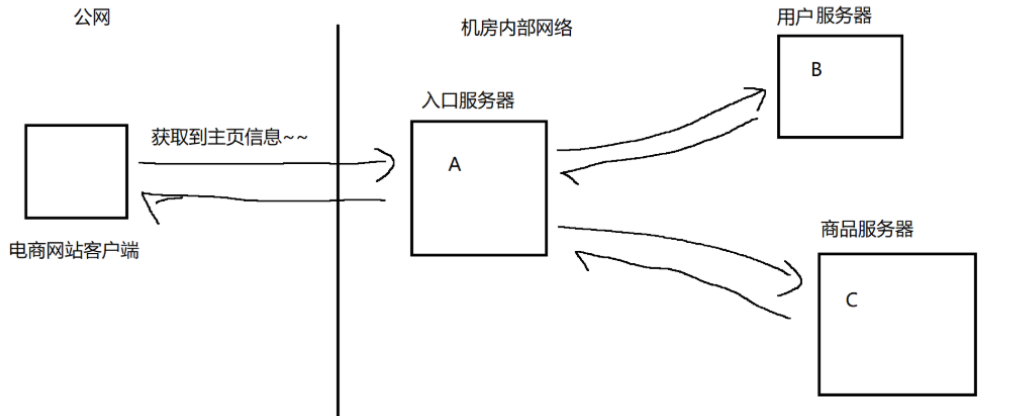
上述模型中:A和B、A和C之间的耦合度是比较强的,A代码中需要涉及到一些和B相关的操作,B的代码中也涉及到一些和A的操作。同样,A的代码中需要涉及和C的操作,C的代码也涉及到和A的操作。此时,如果B或者A“挂了”,此时对A的影响就很大,A可能也就跟着“挂”了。
此时,就可以引入阻塞队列来降低A、B、C三者间的耦合度从而降低上述事故发生的概率。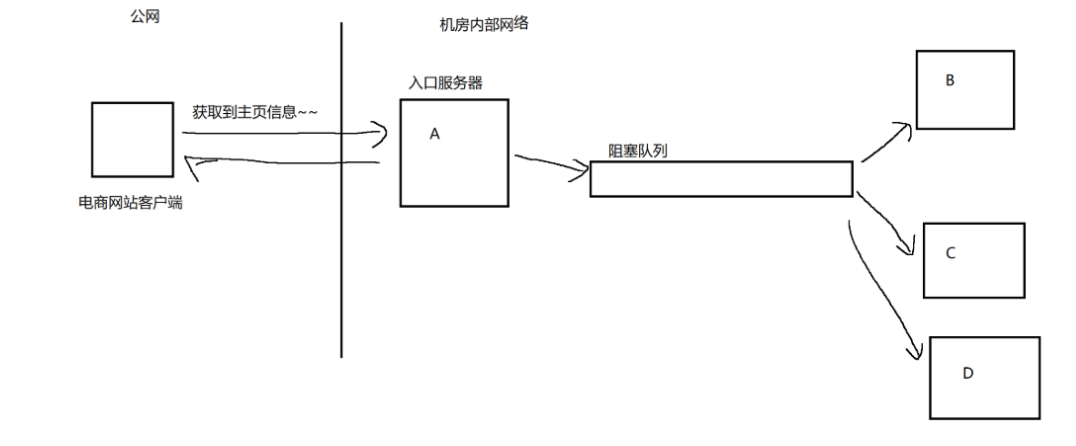
引入阻塞队列后,A和B、A和C之间就都不是直接交互的了,而是通过队列在中间进行传话。此时,A只需要和队列交互就可以了,同理,B、C中的代码也是跟队列交互就可以了。
如果B、C“挂了”,对于A的影响是微乎其微的……假设后续要增加一个D,A的代码是不用发生任何变化的。
引入生产者消费者模型,降低耦合度之后,也是需要付出一些代价的:需要加机器,引入更多的硬件资源。
1、上述描述的阻塞队列,并非是简单的数据结构,而是基于这个数据结构实现的服务器程序,又被部署到单独的主机上了。我们称这种为“消息队列”(message queue,简称“mq”)。
2、整个系统的结构更复杂了,需要维护的服务器更多了。
3、效率问题:引入中间的“阻塞队列”,请求从A发出到B收到,B返回响应到A都需要花费一定的时间。
2、削峰填谷
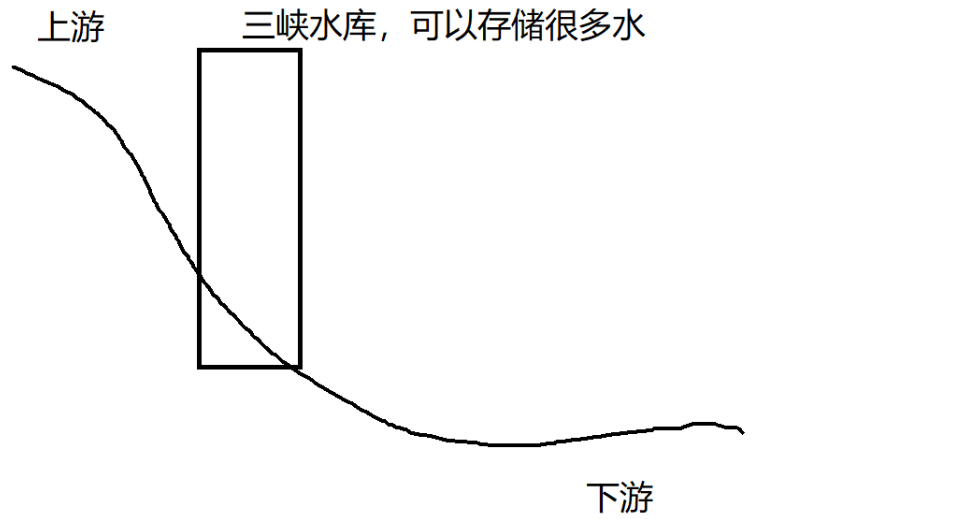
三峡水坝,是一项非常厉害的工程。
它的一项功能,就是能使上游的水按照一定的速率向下游排放。
如图所示:
如果上游的降雨量突然增大,那上游的水就会以一个极快的速度冲向下游,对中下游,造成很大的危害。三峡工程,在中间建立了一个水库。
有了这个水库之后,即使上游的水非常湍急,但是在中游也被三峡大坝给拦住了,三峡大坝本身就是一个水库,可以存储很多的水,然后,我们就可以进行调控,使得三峡按照一定的速率,往下游防水。上游降雨骤增,三峡大坝就可以关闸蓄水;上游降雨骤减,三峡大坝就可以开闸放水。从而达到削峰填谷的效果。(此处的峰和谷,都不是长时间持续的,而是短时间内出现的)。

回到开发之中: 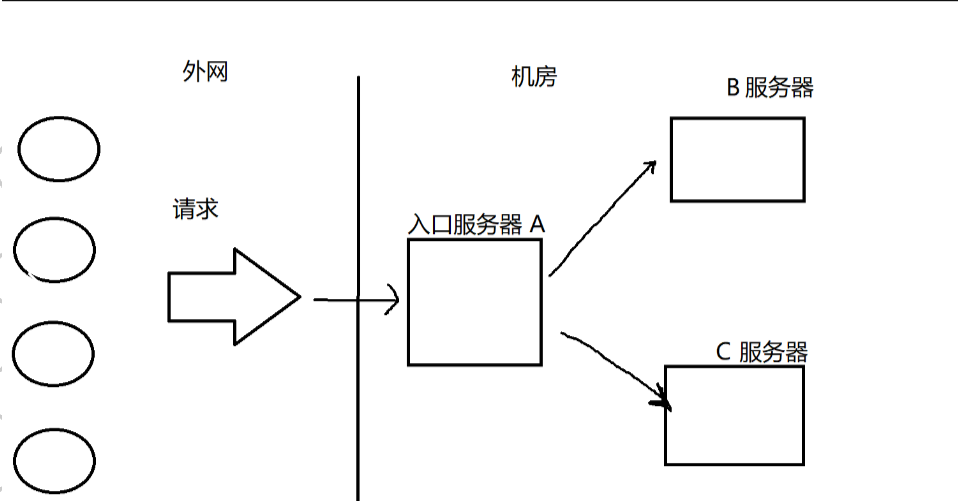
上面是一个分布式系统的大致模型,我们需要考虑的是,当外网的请求突然增多时,即A接收到的请求骤增,此时A的压力就会变大,但因为A做的工作比较简单,每个请求消耗的资源是比较少的,但是B和C多久不一定了,他们的压力也会变大,假设B是用户服务器,需要从数据库中找到对应的用户信息,C是商品服务器,也需要从数据库中找到对应的商品,还需要进行一些匹配和过滤工作等等
A的抗压能力比较强,B、C的抗压能力比较弱(他们需要完成的工作更加复杂,每个请求消耗的资源更多),因此一旦外界的请求出现突发的峰值,就可能导致B、C服务器直接挂掉了……
那当请求多的时候,服务器为什么会挂掉呢?
服务器处理每个请求,都是需要消耗硬件资源的(包括但不限于CPU、内存、网络带宽……)即使一个请求消耗的资源比较少,但也无法承受住,同时会有很多的请求,加到一起来,这样消耗的总资源就多了。上述任何一种硬件资源达到瓶颈,服务器都会挂(用户发出请求,服务器无响应)
我们就可以使用阻塞队列/消息队列来尽量避免突发的高请求导致的服务器过载~~(阻塞队列:是以数据结构的视角命名。消息队列:是基于阻塞队列实现服务器程序的视角命名的)…… 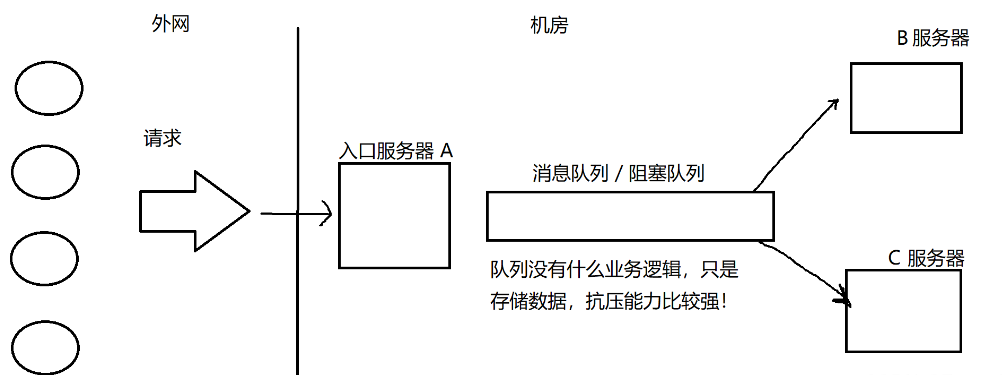
当在A与B、C之间添加一个阻塞队列之后,因为阻塞队列的特性,即使外界请求出现峰值,也是由阻塞队列来承担峰值的请求,B和C(下游)仍然可以按照之前的速度来获取请求,这样就可以有效防止B和C被峰值冲击导致服务器“挂掉”。
但是当请求太多的时候,接收请求的服务器(即A服务器)也是可能会挂的。请求一直往上增加,A肯定也会有顶不住的时候,此时可以在A的前面再添加一个阻塞队列,但当请求进一步增加,队列也是可能挂的(我们可以引入更多的硬件资源,以避免上述情况)。
BolockingQueue的使用
Java标准库中提供了线程的阻塞队列的数据结构:
BolockingQueue是一个interface(接口) ,下面有三个具体的实现类: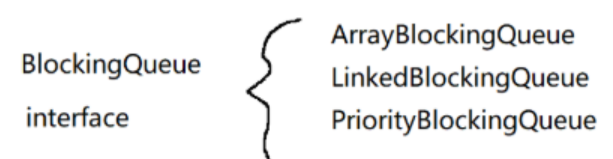
代码示例:
public class ThreadDemo28 {public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue = new ArrayBlockingQueue<>(100);//带阻塞功能的queue.put("aaa");String elem = queue.take();System.out.println("elem:"+elem);String elem1 = queue.take();//阻塞System.out.println("elem:"+elem);//没有阻塞的获取队首元素的方法}
}
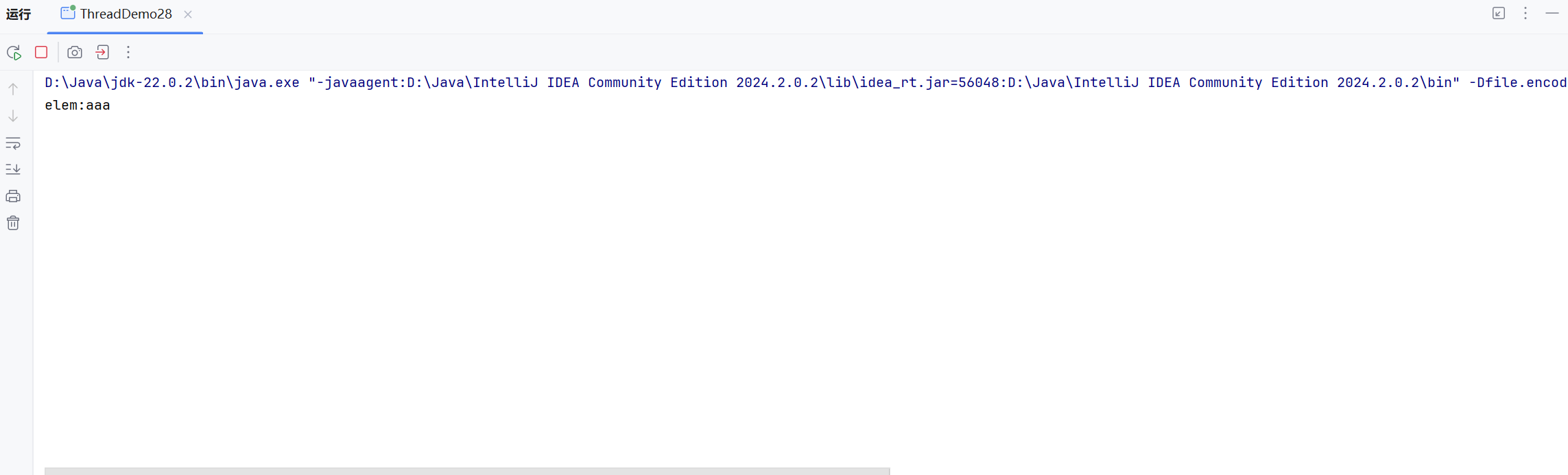 可以看到此时,打印“aaa”之后,进程并没有结束,说明在取出第2个元素时发生了阻塞。
可以看到此时,打印“aaa”之后,进程并没有结束,说明在取出第2个元素时发生了阻塞。
注意:使用put和offer一样都是入队列,但是put是带有阻塞功能的,offer是没有阻塞功能的(队列满了则返回false),take方法是用来出队列的,也是带有阻塞功能的。但是在阻塞队列中,并没有提供带有阻塞功能的获取队首元素的方法。
实现一个BlockingQueue
我们可以基于数组来实现队列的数据结构(环形队列)。
环形队列有两个引用:head(指向头)和tail(指向尾)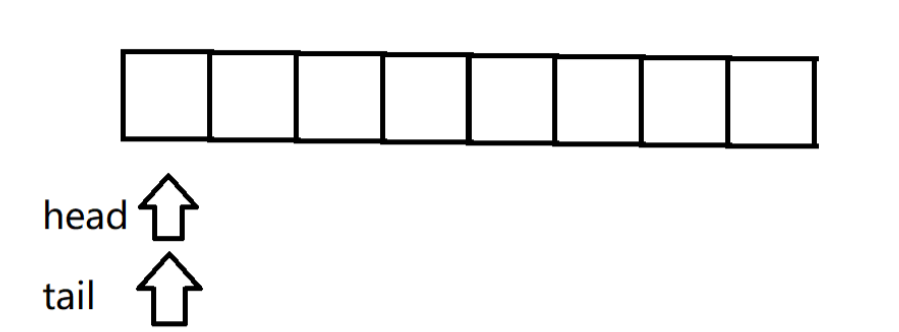
每次插入数据的时候,将数据插入tail的位置,然后tail往后走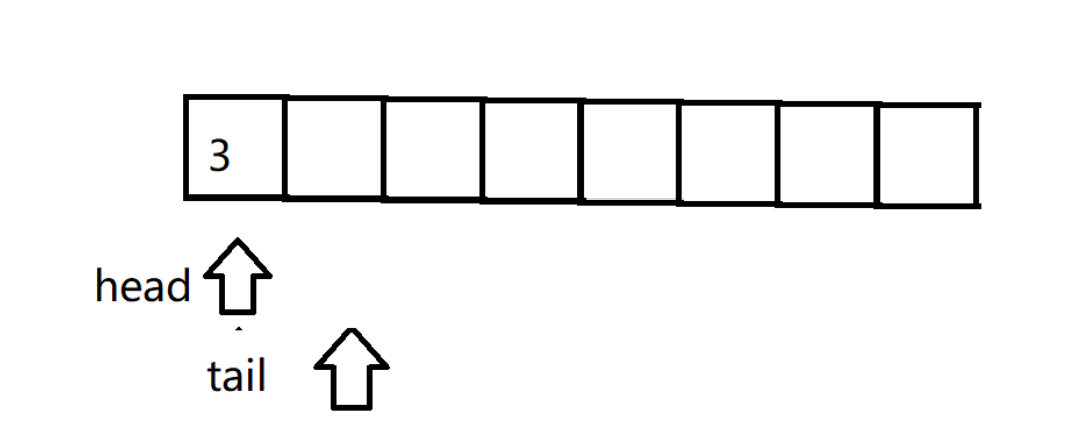
一直走到数组满了之后 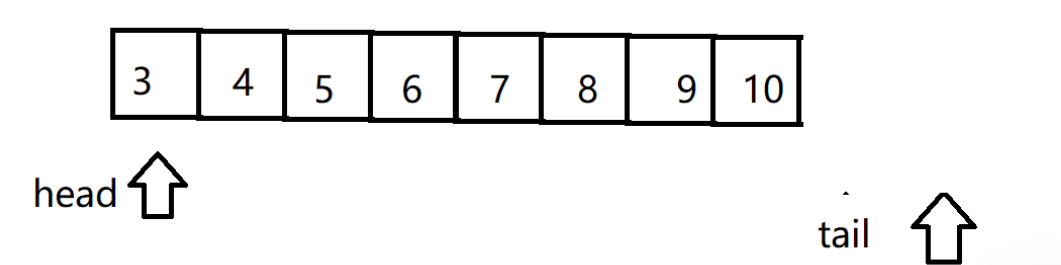
因为我们要实现的是环形队列,所以要判断队列是否为满,有两种方法:
1、浪费一个格子,tail至多走到head的前一个位置。
2、引入size变量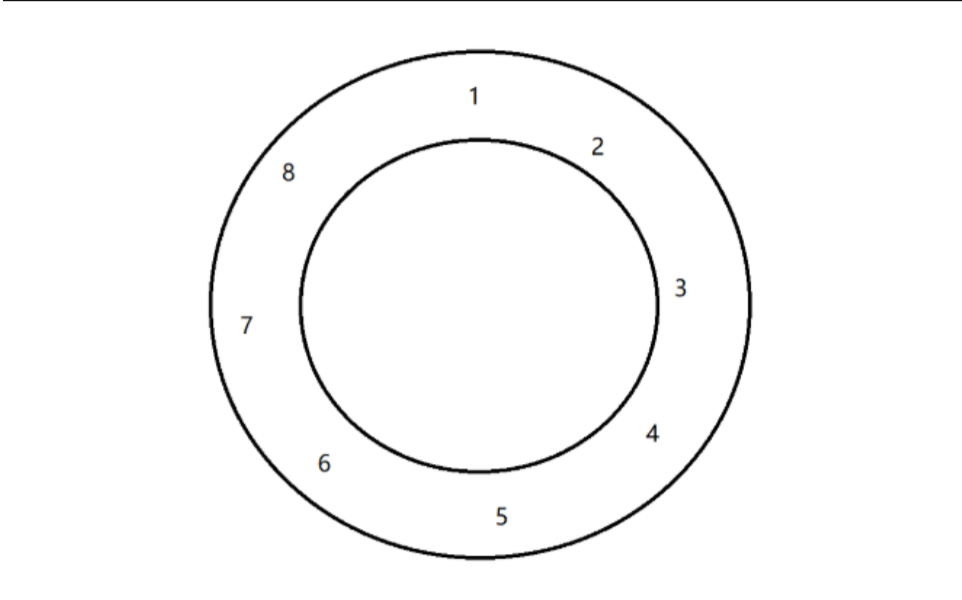
代码实现:
1、成员变量和构造方法
class MyBlockingQueue2{private String[] elem = null;private int head = 0;private int tail = 0;private int size = 0;public MyBlockingQueue2(int capcity){elem = new String[capcity];}
}2、 put方法和take方法
put方法的初始代码(使用size来判断队列是否为满):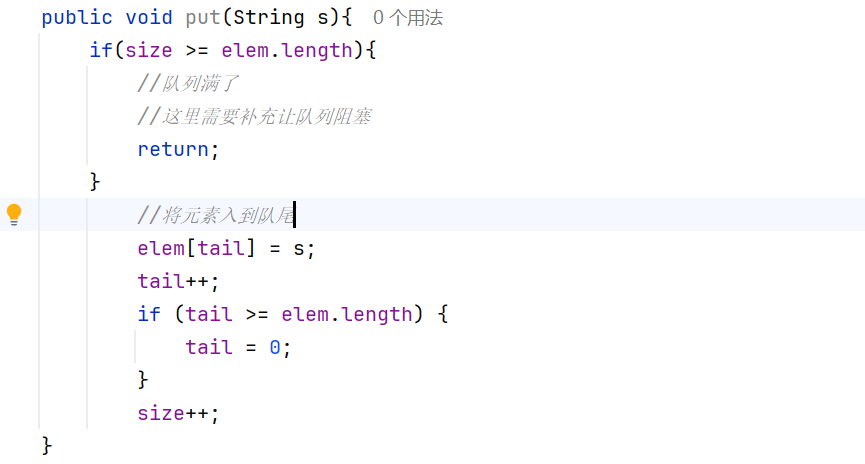
在put方法中判断是否未满,是有两种写法的,一种就是像我们上面写的那样if(tail >= elems.length)让tail = 0,另一种是tail = tail % elems.length(如果tail < elems.length,此时求余的值,就是tail原来的值,如果tail==elems.length,求余的值就是0).
上述两种方法都能完成我们的任务,那如何评价某个代码好还是不好呢?
1、开发效率(代码是否容易被理解,可读性高不高)
2、运行效率(代码的执行速度快不快)
分析上面两种代码,从可读性上看,if语句,只要是个程序员,绝大多数都认识if条件,但不认识%,还是有可能的,尤其是在不同的编程语言中,%的作用还可能不太一样。从运行效率上看,if是条件跳转语句(执行速度快),大多数情况下,并不会触发赋值。但是%,本质上是触发运算指令,除法运算本身属于比较低效的指令(CPU更擅长计算+、-),而且第二种代码是百分之百触发赋值操作的,运行效率会低一些。
综上,使用if是更好的方法。
解决线程安全问题——引入锁
前面if语句中需要阻塞的代码先不考虑,后面的代码全都是针对数组进行写操作,是线程不安全的,一定要加上锁。

那么向上面这样加锁,就线程安全了吗?
模拟调度过程,如图所示:
如果这个此时这个数组只剩下最后一个位置了: 所以我们synchronized需要加在最外面的括号中的,这样就和加到方法上的本质是一样的:
所以我们synchronized需要加在最外面的括号中的,这样就和加到方法上的本质是一样的: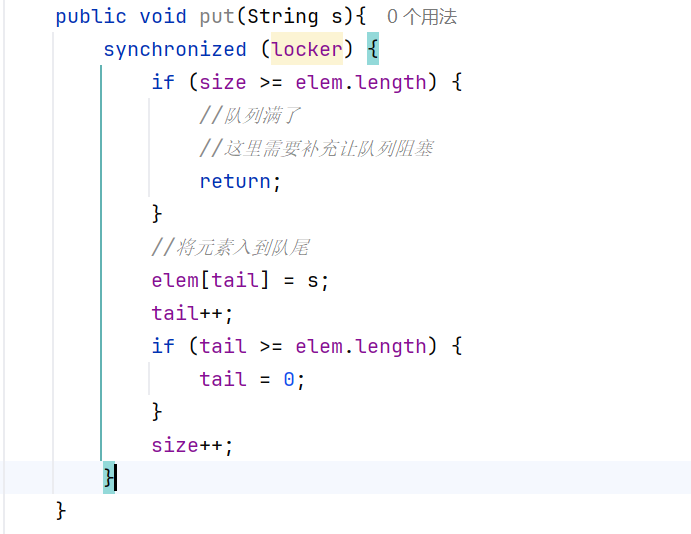
使得当前代码能够阻塞:
说到阻塞,我们就想到了可以用之前的wait来实现阻塞。 巧了,此处的wait正好在锁内部,可以使用当前的锁对象来wait。
光有wait还不够,还需要其他线程对wait进行唤醒(队列如果没有满,就可以进行唤醒操作了)。那什么时候队列不满了呢?出队成功不就是队列不满了嘛~~
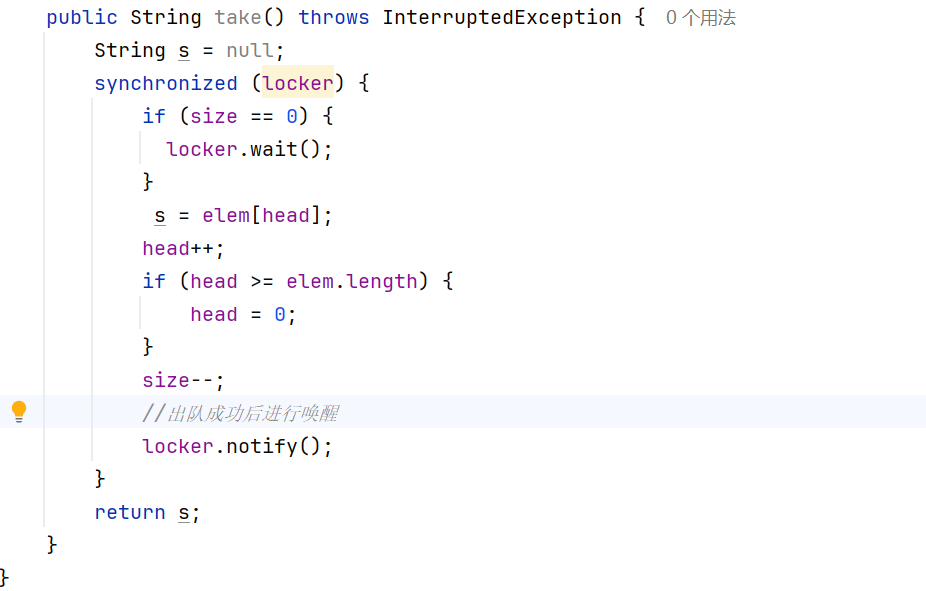
此时,我们就可以根据刚才的put方法来实现take方法,并在出队成功后对put方法中的wait进行唤醒;同理在入队成功后在put方法中对take方法中的wait进行唤醒。
take方法:
put方法 :
这样看起来,我们的代码是不是就大功告成了呢?
并没有,我们期望的情况是这样的: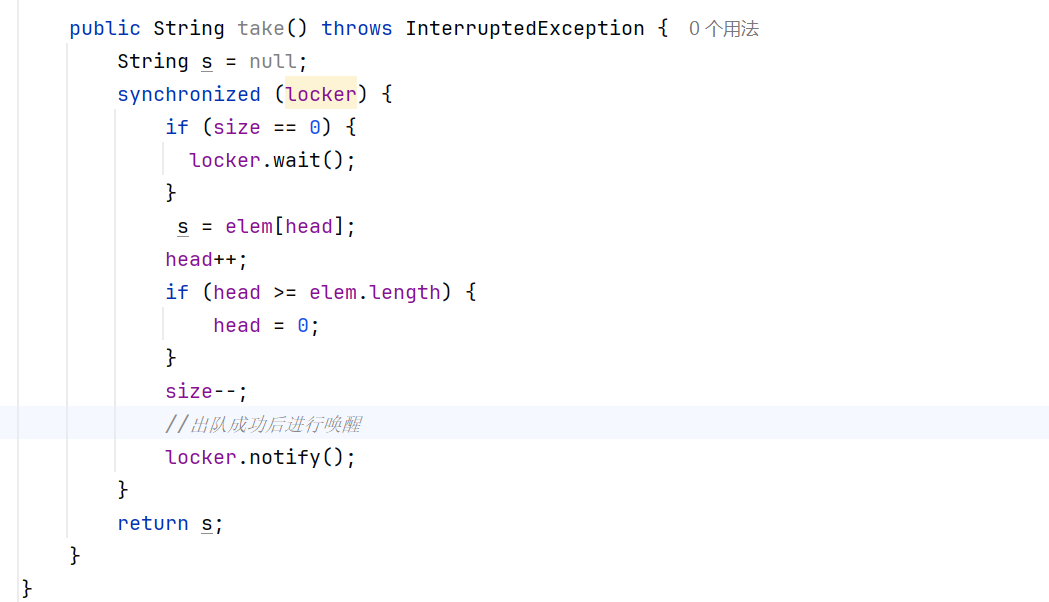
但是,不同线程之间,put和take方法的notify可能会不正确地将错误的wait给唤醒。
比如下面这种情况:A线程中,入队列的唤醒操作,把B线程中入队列的wait唤醒了。
第一步,两个put都进入了if语句,且进入了阻塞等待(进入wait后会有一步操作是释放锁,所以可能出现两个线程都能进行put这个操作)。
第二步,另一个线程执行了take方法,唤醒了其中一个put,然后这个put继续往下添加元素,添加完后又执行了一步notify,将另一个put方法唤醒了(这个put方法本应该继续阻塞等待的)。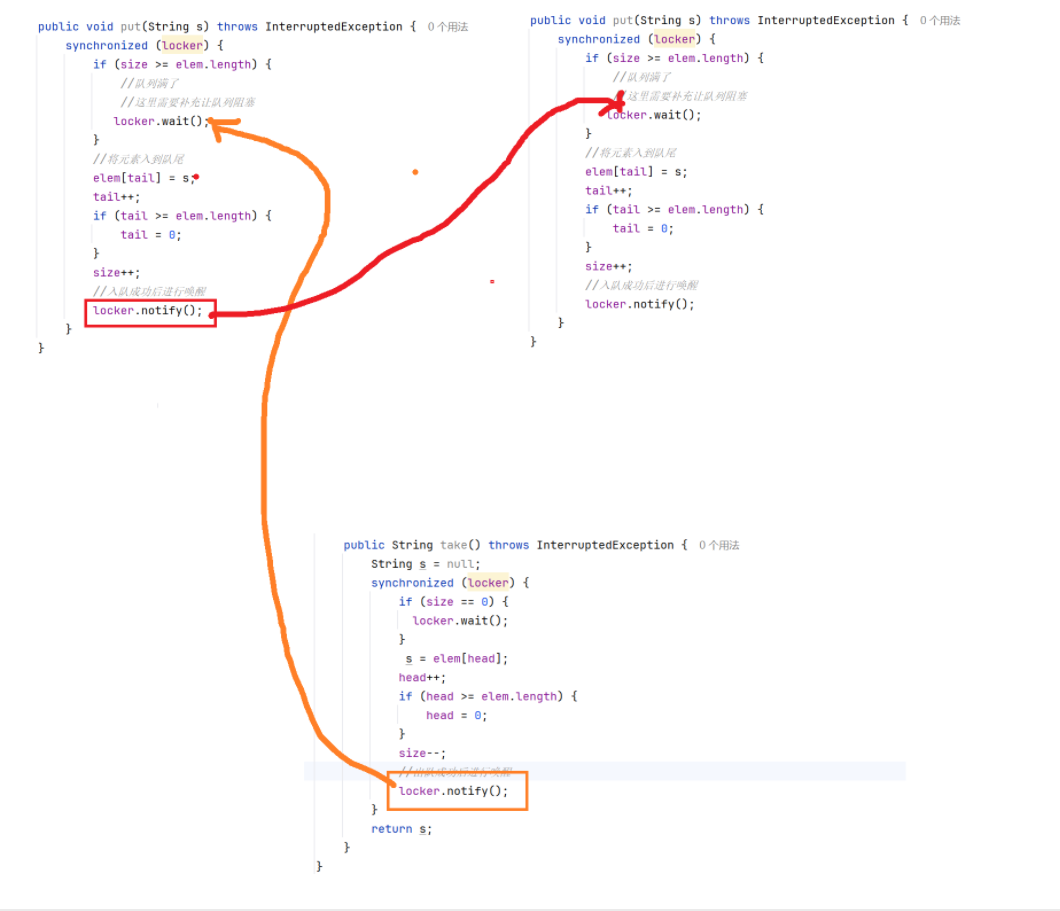
如上面这种情况,就是不符合我们预期的bug,并且好像还很难处理,如果我们使用两个不同的锁对象来解决,又无法实现锁竞争。那我们要如何解决呢?我们可以将if改为while,这意味着wait唤醒之后,需要再判定一次条件。如果再次判断条件,发现队列还是满的,那也就是说在wait等待的过程中,已经有其他线程进行了插入,此时就要继续阻塞等待。
Java标准库中也建议,wait要搭配while循环进行使用。
完整代码:
class MyBlockingQueue2{private String[] elem = null;private int head = 0;private int tail = 0;private int size = 0;private Object locker = new Object();public MyBlockingQueue2(int capcity){elem = new String[capcity];}public void put(String s) throws InterruptedException {synchronized (locker) {while (size >= elem.length) {//队列满了//这里需要补充让队列阻塞locker.wait();}//将元素入到队尾elem[tail] = s;tail++;if (tail >= elem.length) {tail = 0;}size++;//入队成功后进行唤醒locker.notify();}}public String take() throws InterruptedException {String s = null;synchronized (locker) {while (size == 0) {locker.wait();}s = elem[head];head++;if (head >= elem.length) {head = 0;}size--;//出队成功后进行唤醒locker.notify();}return s;}
}使用刚才实现的BlockQueue,写一个简单的生产者消费者模型
在实际的开发中,生产者消费者模型,往往是多个生产者和多个消费者。这里的生产者和消费者往往不仅仅是一个线程,也可能是一个独立的服务器程序,甚至是一组服务器程序...但最核心的仍然是阻塞队列,使用 synchronized 和 wiat / notify 达到线程安全和阻塞的目的。
如下代码,t1是生产者,t2是消费者,我们可以通过sleep来控制他们的生产速度和消费速度。
public static void main(String[] args) {MyBlockingQueue2 queue2 = new MyBlockingQueue2(1000);Thread t1 = new Thread(()->{int count = 0;while (true){try {System.out.println("生产元素:"+count);queue2.put(String.valueOf(count));Thread.sleep(1000);count++;} catch (InterruptedException e) {throw new RuntimeException(e);}}});Thread t2 = new Thread(()->{while (true){try {String s = queue2.take();System.out.println("消费元素:"+s);} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();t2.start();}运行结果如下: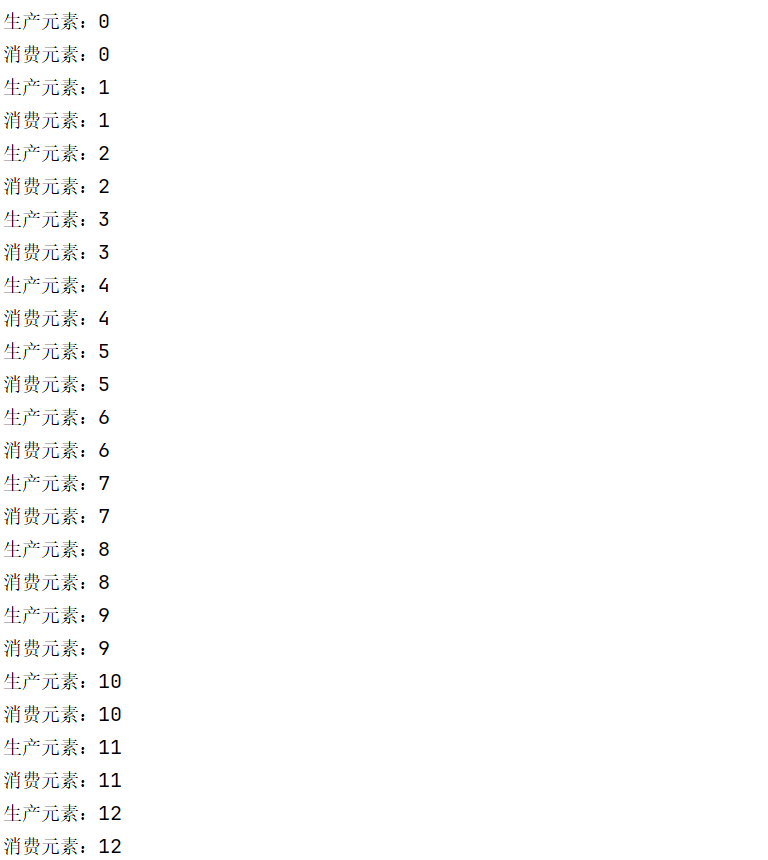










)
)


)




