前言
因为经常对图像要做数据清洗,又很费时间去重新写一个,我一直在想能不能写一个通用的脚本或者制作一个可视化的界面对文件夹图像做批量的修改图像大小、重命名、划分数据训练和验证集等等。这里我先介绍一下我因为写过的一些脚本,然后我们对其进行绘总,并制作成一个可视化界面。
脚本
获取图像路径
我们需要一个函数去读取文件夹下的所有文件,获取其文件名,而关于这一部分我很早以前就做过了,详细可以看这里:解决Python读取图片路径存在转义字符
import osdef get_image_path(path):imgfile = []file_list = os.listdir(path)for i in file_list:new_path = os.path.join(path, i).replace("\\", "/")_, file_ext = os.path.splitext(new_path)if file_ext[1:] in ('bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp', 'pfm'):imgfile.append(new_path)return natsorted(imgfile)if __name__=="__main__":images_path = r'E:\PythonProject\img_processing_techniques_main\document\images'images_path_list = get_image_path(images_path)print(images_path_list)我们在这里进行了重命名,请以此篇为准。
批量修改图像大小
def modify_images_size(target_path, target_hwsize, save_path=None):"""批量修改图像大小"""h, w = target_hwsizeimages_paths = get_image_path(target_path)os.makedirs(save_path, exist_ok=True)for i, one_image_path in enumerate(images_paths):try:image = Image.open(one_image_path)resized_image = image.resize((w, h))base_name = os.path.basename(one_image_path)if save_path is not None:new_path = os.path.join(save_path, base_name)else:new_path = one_image_pathresized_image.save(new_path)print(f"Resized {one_image_path} to {new_path}")except Exception as e:print(f"Error resizing {one_image_path}: {e}")这里的脚本用于图像的批量修改,如果不给保存路径,那么就会修改本地的文件,我们是不推荐这里的,最好还是做好备份。
划分数据集与验证集
def split_train_val_txt(target_path, train_ratio=.8, val_ratio=.2, onlybasename=False):"""如果 train_ratio + val_ratio = 1 表示只划分训练集和验证集, train_ratio + val_ratio < 1表示将剩余的比例划分为测试集"""assert train_ratio + val_ratio <= 1test_ratio = 1. - (train_ratio + val_ratio)images_paths = get_image_path(target_path)num_images = len(images_paths)num_train = round(num_images * train_ratio)num_val = num_images - num_train if test_ratio == 0 else math.ceil(num_images * val_ratio)num_test = 0 if test_ratio == 0 else num_images - (num_train + num_val)with open(os.path.join(target_path, 'train.txt'), 'w') as train_file, \open(os.path.join(target_path, 'val.txt'), 'w') as val_file, \open(os.path.join(target_path, 'test.txt'), 'w') as test_file:for i, image_path in enumerate(images_paths):if onlybasename:image_name, _ = os.path.splitext(os.path.basename(image_path))else:image_name = image_pathif i < num_train:train_file.write(f"{image_name}\n")elif i < num_train + num_val:val_file.write(f"{image_name}\n")else:test_file.write(f"{image_name}\n")print(f"Successfully split {num_images} images into {num_train} train, {num_val} val, and {num_test} test.")
我在这里修改了划分测试集的逻辑,根据划分比例来评判,以免出现使用向上取整或向下取整导致出现的问题(测试集比例不为0,验证集比例按照向上取整划分)。
复制图像到另外一个文件夹
def copy_images_to_directory(target_path, save_folder, message=True):"""复制整个文件夹(图像)到另外一个文件夹"""try:os.makedirs(save_folder, exist_ok=True)source_path = get_image_path(target_path)for img_path in source_path:base_file_name = os.path.basename(img_path)destination_path = os.path.join(save_folder, base_file_name)shutil.copy2(img_path, destination_path)if message:print(f"Successfully copied folder: {img_path} to {save_folder}")except Exception as e:print(f"Error copying folder, {e}")这个本来是一个小功能,但是我想的是有时候如果要做每张图的匹配,可以修改为将符合条件的路径复制到目标文件夹中。修改也只需加一个列表的判断即可。
获取数据集的均值标准化
def get_dataset_mean_std(train_data):train_loader = DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for im, _ in train_loader:for d in range(3):mean[d] += im[:, d, :, :].mean()std[d] += im[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())def get_images_mean_std(target_path):images_paths = get_image_path(target_path)num_images = len(images_paths)mean_sum = np.zeros(3)std_sum = np.zeros(3)for one_image_path in images_paths:pil_image = Image.open(one_image_path).convert("RGB")img_asarray = np.asarray(pil_image) / 255.0individual_mean = np.mean(img_asarray, axis=(0, 1))individual_stdev = np.std(img_asarray, axis=(0, 1))mean_sum += individual_meanstd_sum += individual_stdevmean = mean_sum / num_imagesstd = std_sum / num_imagesreturn mean.astype(np.float32), std.astype(np.float32)都是相同的方法获取RGB图像的均值标准化,我们更建议直接使用第二个。
批量修改图像后缀名
def modify_images_suffix(target_path, format='png'):"""批量修改图像文件后缀"""images_paths = get_image_path(target_path)for i, one_image_path in enumerate(images_paths):base_name, ext = os.path.splitext(one_image_path)new_path = base_name + '.' + formatos.rename(one_image_path, new_path)print(f"Converting {one_image_path} to {new_path}")这里仅仅是修改图像的后缀,至于这种强力的修改是否会对图像的格式造成影响我们不做考虑。
批量重命名图像
def batch_rename_images(target_path,save_path,start_index=None,prefix=None,suffix=None,format=None,num_type=1,
):"""重命名图像文件夹中的所有图像文件并保存到指定文件夹:param target_path: 目标文件路径:param save_path: 文件夹的保存路径:param start_index: 默认为 1, 从多少号开始:param prefix: 重命名的通用格式前缀, 如 rename001.png, rename002.png...:param suffix: 重命名的通用格式后缀, 如 001rename.png, 002rename.png...:param format (str): 新的后缀名,不需要包含点(.):param num_type: 数字长度, 比如 3 表示 005:param message: 是否打印修改信息"""os.makedirs(save_path, exist_ok=True)images_paths = get_image_path(target_path)current_num = start_index if start_index is not None else 1for i, image_path in enumerate(images_paths):image_name = os.path.basename(image_path)name, ext = os.path.splitext(image_name)if format is None:ext = extelse:ext = f'.{format}'padded_i = str(current_num).zfill(num_type)if prefix and suffix:new_image_name = f"{prefix}{padded_i}{suffix}{ext}"elif prefix:new_image_name = f"{prefix}{padded_i}{ext}"elif suffix:new_image_name = f"{padded_i}{suffix}{ext}"else:new_image_name = f"{padded_i}{ext}"new_path = os.path.join(save_path, new_image_name)current_num += 1print(f"{i + 1} Successfully rename {image_path} to {new_path}")shutil.copy(image_path, new_path)print("Batch renaming and saving of files completed!")我们在这里添加了重命名的功能,其实发现很多都可以套在这里面来,所以后面我们修改过后会做成ui进行显示。
完整脚本
下面是我经过测试后的一个脚本,大家可以直接拿去使用。
import os
import math
import torch
import numpy as np
from PIL import Image
import shutil
from torch.utils.data import DataLoader
from natsort import natsorteddef get_image_path(path):imgfile = []file_list = os.listdir(path)for i in file_list:new_path = os.path.join(path, i).replace("\\", "/")_, file_ext = os.path.splitext(new_path)if file_ext[1:] in ('bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp', 'pfm'):imgfile.append(new_path)return natsorted(imgfile)def modify_images_size(target_path, target_hwsize, save_path=None):"""批量修改图像大小"""h, w = target_hwsizeimages_paths = get_image_path(target_path)os.makedirs(save_path, exist_ok=True)for i, one_image_path in enumerate(images_paths):try:image = Image.open(one_image_path)resized_image = image.resize((w, h))base_name = os.path.basename(one_image_path)if save_path is not None:new_path = os.path.join(save_path, base_name)else:new_path = one_image_pathresized_image.save(new_path)print(f"Resized {one_image_path} to {new_path}")except Exception as e:print(f"Error resizing {one_image_path}: {e}")def split_train_val_txt(target_path, train_ratio=.8, val_ratio=.2, onlybasename=False):"""如果 train_ratio + val_ratio = 1 表示只划分训练集和验证集, train_ratio + val_ratio < 1表示将剩余的比例划分为测试集"""assert train_ratio + val_ratio <= 1test_ratio = 1. - (train_ratio + val_ratio)images_paths = get_image_path(target_path)num_images = len(images_paths)num_train = round(num_images * train_ratio)num_val = num_images - num_train if test_ratio == 0 else math.ceil(num_images * val_ratio)num_test = 0 if test_ratio == 0 else num_images - (num_train + num_val)with open(os.path.join(target_path, 'train.txt'), 'w') as train_file, \open(os.path.join(target_path, 'val.txt'), 'w') as val_file, \open(os.path.join(target_path, 'test.txt'), 'w') as test_file:for i, image_path in enumerate(images_paths):if onlybasename:image_name, _ = os.path.splitext(os.path.basename(image_path))else:image_name = image_pathif i < num_train:train_file.write(f"{image_name}\n")elif i < num_train + num_val:val_file.write(f"{image_name}\n")else:test_file.write(f"{image_name}\n")print(f"Successfully split {num_images} images into {num_train} train, {num_val} val, and {num_test} test.")def copy_images_to_directory(target_path, save_folder):"""复制整个文件夹(图像)到另外一个文件夹"""try:os.makedirs(save_folder, exist_ok=True)source_path = get_image_path(target_path)for img_path in source_path:base_file_name = os.path.basename(img_path)destination_path = os.path.join(save_folder, base_file_name)shutil.copy2(img_path, destination_path)print(f"Successfully copied folder: {img_path} to {save_folder}")except Exception as e:print(f"Error copying folder, {e}")def get_dataset_mean_std(train_data):train_loader = DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for im, _ in train_loader:for d in range(3):mean[d] += im[:, d, :, :].mean()std[d] += im[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())def get_images_mean_std(target_path):images_paths = get_image_path(target_path)num_images = len(images_paths)mean_sum = np.zeros(3)std_sum = np.zeros(3)for one_image_path in images_paths:pil_image = Image.open(one_image_path).convert("RGB")img_asarray = np.asarray(pil_image) / 255.0individual_mean = np.mean(img_asarray, axis=(0, 1))individual_stdev = np.std(img_asarray, axis=(0, 1))mean_sum += individual_meanstd_sum += individual_stdevmean = mean_sum / num_imagesstd = std_sum / num_imagesreturn mean.astype(np.float32), std.astype(np.float32)def modify_images_suffix(target_path, format='png'):"""批量修改图像文件后缀"""images_paths = get_image_path(target_path)for i, one_image_path in enumerate(images_paths):base_name, ext = os.path.splitext(one_image_path)new_path = base_name + '.' + formatos.rename(one_image_path, new_path)print(f"Converting {one_image_path} to {new_path}")def batch_rename_images(target_path,save_path,start_index=None,prefix=None,suffix=None,format=None,num_type=1,
):"""重命名图像文件夹中的所有图像文件并保存到指定文件夹:param target_path: 目标文件路径:param save_path: 文件夹的保存路径:param start_index: 默认为 1, 从多少号开始:param prefix: 重命名的通用格式前缀, 如 rename001.png, rename002.png...:param suffix: 重命名的通用格式后缀, 如 001rename.png, 002rename.png...:param format (str): 新的后缀名,不需要包含点(.):param num_type: 数字长度, 比如 3 表示 005:param message: 是否打印修改信息"""os.makedirs(save_path, exist_ok=True)images_paths = get_image_path(target_path)current_num = start_index if start_index is not None else 1for i, image_path in enumerate(images_paths):image_name = os.path.basename(image_path)name, ext = os.path.splitext(image_name)if format is None:ext = extelse:ext = f'.{format}'padded_i = str(current_num).zfill(num_type)if prefix and suffix:new_image_name = f"{prefix}{padded_i}{suffix}{ext}"elif prefix:new_image_name = f"{prefix}{padded_i}{ext}"elif suffix:new_image_name = f"{padded_i}{suffix}{ext}"else:new_image_name = f"{padded_i}{ext}"new_path = os.path.join(save_path, new_image_name)current_num += 1print(f"{i + 1} Successfully rename {image_path} to {new_path}")shutil.copy(image_path, new_path)print("Batch renaming and saving of files completed!")
if __name__=="__main__":images_path = r'E:\PythonProject\img_processing_techniques_main\document\images'images_path_list = get_image_path(images_path)save_path =r'./save_path'# modify_images_size(images_path, (512, 512), save_path)# print(images_path_list)# split_train_val_txt(images_path, .8, .2)# copy_images_to_directory(images_path, save_folder='./save_path2')# mean, std = get_images_mean_std(images_path)# print(mean, std)# modify_images_suffix('./save_path2')BatchVision的可视化设计
我将前面的一些脚本制作成了一个批量文件处理系统 BatchVision,可实现批量修改图像大小,划分训练集和验证集,以及批量重命名,其他的一些小功能例如灰度化处理和计算均值标准化。
完整项目请看此处:UI-Design-System-Based-on-PyQt5
这里通过网盘链接分享的离线使用文件exe,无需安装环境: BatchVision
我们设计的可视化界面如下图所示:
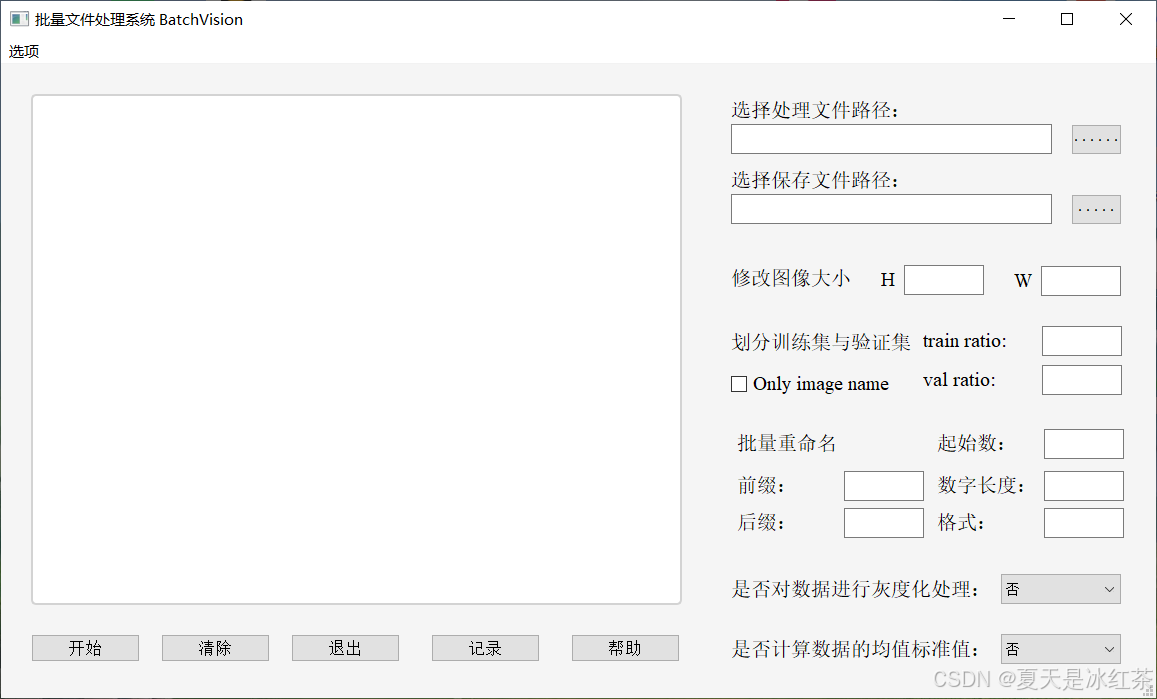
其中的一些设定我都是经过严格的判断,如果还有问题可以联系我修改。



详细解读)















