Dual-Space Knowledge Distillation for Large Language Models
发表:EMNLP 2024
机构:Beijing Key Lab of Traffic Data Analysis and Mining
连接:https://aclanthology.org/2024.emnlp-main.1010.pdf
代码:GitHub - songmzhang/DSKD: Repo for the EMNLP'24 Paper "Dual-Space Knowledge Distillation for Large Language Models". A general white-box KD framework for both same-tokenizer and cross-tokenizer LLM distillation.
Abstract
知识蒸馏(Knowledge Distillation, KD)被认为是一种有前景的方案,可以通过将大型语言模型(LLMs)中的知识迁移到较小的模型中,从而实现模型压缩。在这个过程中,白盒知识蒸馏方法通常通过最小化两个模型输出分布之间的距离,以传递尽可能多的知识。然而,在当前的白盒KD框架中,这些输出分布来自各自模型独立的输出空间,即它们使用各自的预测头。我们认为,这种空间差异会导致教师模型与学生模型在表示层面和分布层面上的相似性较低。此外,这种差异也阻碍了使用不同词汇表的模型之间的知识蒸馏,而这在当前的LLMs中是很常见的现象。为了解决这些问题,我们提出了一种双空间知识蒸馏(Dual-Space Knowledge Distillation, DSKD)框架,该框架统一了两个模型的输出空间以实现知识蒸馏。在DSKD的基础上,我们进一步开发了一种跨模型注意力机制(cross-model attention mechanism),该机制可以在词汇表不同的情况下自动对齐两个模型的表示。因此,我们的框架不仅兼容现有框架中常用的各种距离函数(例如KL散度),还支持任何两个LLMs之间的知识蒸馏,无论它们是否使用相同的词汇表。在任务无关的指令跟随基准测试中,实验结果表明:与当前白盒KD框架(无论使用哪种距离函数)相比,DSKD取得了显著更好的性能,同时也优于现有用于不同词汇表LLMs之间蒸馏的方法。
1 Introduction
现有的大型语言模型(LLMs)由于其庞大的模型容量,在各种任务中展现出了强大的泛化能力(Chowdhery 等,2023;Touvron 等,2023;OpenAI,2023)。基于对“扩展法则”(scaling law,Kaplan 等,2020)的信念,当前LLMs的参数规模不断扩展,以追求更高的智能水平。然而,参数规模的不断增长也带来了现实场景中部署成本高昂的问题。为了解决这一问题,知识蒸馏(Knowledge Distillation,KD;Hinton 等,2015)被认为是一种前景广阔的解决方案,能够在可接受的性能损失下压缩大型模型。
在KD过程中,大模型通常作为教师模型,向一个较小的模型(即学生模型)提供监督信号,从而将其知识和能力传递给轻量级的学生模型。
目前,用于LLMs的KD算法主要有两种框架:黑盒KD和白盒KD。黑盒KD使用教师模型生成的解码序列作为学生模型的训练数据,并直接在one-hot标签上优化交叉熵损失(Kim 和 Rush,2016;Fu 等,2023;Li 等,2023)。相比之下,白盒KD方法通常通过最小化教师与学生的输出分布之间的距离(例如KL散度),在理论上能够传递更多信息,且通常比黑盒KD表现更优(Wen 等,2023;Gu 等,2023;Ko 等,2024)。尽管白盒KD框架展现出了其优势,但该框架下的教师和学生的输出分布来自不同的输出空间,因为它们是由各自不同的预测头生成的。
在本研究的开始阶段,我们首先揭示了该框架中由于输出空间不一致所导致的两个固有局限:
-
教师-学生相似性低:当前框架通常在表示层面和分布层面都导致教师与学生之间的相似性较低(见第2.2.1节);
-
需要相同词汇表:当前白盒KD框架的一个关键前提是教师模型与学生模型应使用相同的词汇表,而在当今各种LLMs中,这一点却很难满足(见第2.2.2节)。
针对这些限制,我们提出了一个新的白盒KD框架,称为双空间知识蒸馏(Dual-Space Knowledge Distillation,DSKD)。该框架与现有的白盒KD框架同样简单,但可以解决由空间差异所带来的问题。具体来说,DSKD通过将教师模型/学生模型的输出隐藏状态投影到对方的表示空间,实现了输出空间的统一。在此统一空间中,可以使用共享的预测头生成两个模型的输出分布,从而使它们位于相同的输出空间。
特别地,对于使用不同词汇表的模型,我们进一步提出了一种跨模型注意力机制(Cross-Model Attention,CMA),可自动对齐两个采用不同分词方式的序列中的token。与当前框架一样,DSKD也兼容现有的各种分布距离函数,包括KL散度、JS散度等。同时,借助CMA机制,我们可以将两个LLMs的输出分布转换成相同的形状,从而使我们的框架具有更强的通用性,能够应用于任何两个使用不同词汇表的LLMs之间的蒸馏任务。
我们在指令跟随类基准任务上对该框架进行了评估,涵盖了教师模型与学生模型使用相同和不同词汇表的两种设置。实验结果表明,对于使用相同词汇表的LLMs,我们的DSKD框架在多种距离函数下显著优于当前白盒KD框架;而对于使用不同词汇表的LLMs,DSKD结合CMA机制后,超过了所有现有的蒸馏方法。
总结来说,我们的主要贡献如下:
-
我们从实证角度揭示了当前白盒KD框架由于输出空间不一致而限制了教师与学生之间的相似性;
-
为解决该问题,我们提出了一个新的白盒KD框架——双空间知识蒸馏(DSKD),通过统一教师与学生输出分布的输出空间,提升了蒸馏效果;
-
在DSKD基础上,我们进一步开发了跨模型注意力机制,以支持不同词汇表的LLMs之间的知识蒸馏;
-
实验结果表明,我们的DSKD框架在多种距离函数下显著优于当前白盒KD框架,并超越了所有现有的用于不同词汇表LLMs之间的蒸馏方法。
2 Background and Preliminary Study
2.1 Current Framework for White-Box KD

2.2 Limitations of the Current Framework
2.2.1 Low Teacher-Student Similarity
在当前的白盒知识蒸馏(KD)框架中,公式 (2) 中的两个输出分布是通过两个模型各自的预测头,从各自的输出空间中计算得出的。接着,通过最小化两者的距离来优化学生模型的分布,使其逼近教师模型的分布。然而,我们认为这一做法从两个方面限制了教师与学生模型之间最终的相似性:
-
表征层面(representation):分布是通过输出隐藏状态经过预测头计算得到的,如果两个模型的预测头不同,即使分布非常接近,其对应的隐藏状态也未必相似;
-
分布层面(distribution):如果教师和学生的输出隐藏状态不相似,那么它们之间的分布距离在优化过程中也难以达到理论上的最小值。
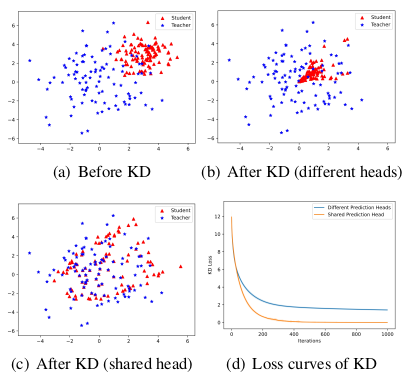
我们通过一个模拟实验验证了上述猜想。在该实验中,我们随机初始化两组二维向量(其中一组可训练,另一组冻结),它们具有不同的均值和方差,分别表示学生和教师模型的输出隐藏状态(如图1(a)所示)。此外,我们设置了两个预测头,分别将这两组向量转化为概率分布。接着,我们选择KL散度作为距离函数 D(⋅∥⋅)\mathcal{D}(\cdot \| \cdot)D(⋅∥⋅),使用公式 (2) 中的损失函数 LkdL_{kd}Lkd 模拟蒸馏过程,共进行1000次迭代。之后我们重新绘制两组向量,并在整个过程中记录损失变化曲线,见图1。
首先,我们模拟当前白盒KD框架的过程,即使用由不同预测头产生、来自不同输出空间的分布。图1(b)的结果表明,在这种设置下,学生的隐藏状态在结构上与教师的隐藏状态有明显差异,说明二者相似性较低。
作为对比,我们将两者的输出空间统一,即让学生和教师共享同一个预测头,并重复上述蒸馏过程。如图1(c)所示,在这种设置下,学生的隐藏状态与教师的隐藏状态更为接近,二者相似性显著提升。这一结果表明,当前KD框架在表征层面上可能导致子最优的教师-学生相似性,而更优的替代方案是统一教师和学生的分布输出空间。
随后,我们将上述两种设置的模拟实验各重复100次,并绘制它们的平均损失曲线,如图1(d)所示。正如我们所预期的,使用不同预测头时,KL散度在收敛后仍然明显高于理论最小值(即0);而共享预测头时,KL散度收敛更快,最终也更接近于最小值。这充分说明了当前KD框架在分布层面上也限制了两个模型之间的相似性。
除了KL散度外,我们还用其他距离函数(例如反向KL散度、JS散度等)重复了该模拟实验。结果详见附录A.1,支持上述结论。此外,我们在附录A.2中提供了该模拟实验的伪代码以展示更多细节。
2.2.2 Dependency on the Same Vocabulary

3 Methodology
本节介绍我们为解决当前白盒知识蒸馏(white-box KD)框架所存在问题而提出的解决方案。我们首先在第 §3.1 中介绍我们提出的新蒸馏框架。然后在 §3.2 中提出一种跨模型注意力机制(cross-model attention mechanism),用于扩展我们的框架以支持词表不同的大语言模型(LLMs)。
3.1 Dual-Space Knowledge Distillation Framework
受到 §2.2.1 中观察结果的启发,我们设计了双空间知识蒸馏(DSKD)框架。其核心思想是统一公式(2)中两个分布的输出空间。为此,我们将教师/学生模型的输出隐藏状态投影到对方的表示空间中,使得两个模型可以通过同一个预测头输出分布,并实现在统一输出空间下的蒸馏。
下面我们将详细介绍如何在学生空间和教师空间中进行投影和知识蒸馏。
在学生空间中的蒸馏

在教师空间中的蒸馏

3.2 Cross-Model Attention Mechanism

4 Experiments
4.1 Experimental Setup
数据集:我们在多个指令跟随类数据集上评估了所提出的 DSKD 框架,数据集设置遵循 Gu 等人(2023)的方案。具体而言,我们使用由 Gu 等人处理过的 databricks-dolly-15k 数据集进行知识蒸馏实验,该数据集包含约 11k 条训练样本,1k 条验证样本,和 500 条测试样本。此外,为了更全面的评估,我们还选取了以下额外测试集:Self-Instruct(SelfInst)、Vicuna-Evaluation(VicunaEval)、Super Natural Instructions(S-NI)和 Unnatural Instructions(UnNI)。
模型选择:学生模型包括 GPT2-120M(Radford 等, 2019)和 TinyLLaMA-1.1B(Zhang 等, 2024)。对于 GPT2-120M,我们分别使用与学生模型词表相同或不同的教师模型 GPT2-1.5B 和 Qwen1.5-1.8B(Bai 等, 2023)。对于 TinyLLaMA-1.1B,我们选择词表相同或不同的教师模型 LLaMA2-7B(Touvron 等, 2023)和 Mistral-7B(Jiang 等, 2023)。
训练与评估:在 GPT2 上进行蒸馏时,我们对教师和学生模型进行全参数微调。在 TinyLLaMA 上,我们采用 LoRA 微调方式训练教师和学生模型。温度系数 τ\tauτ 被设为 2.0,基于验证集上的性能调优。我们方法中所有投影器均为线性层,因此仅引入极少量额外参数(例如,在 GPT2 上应用 DSKD 仅增加约 2M 参数)。在评估阶段,我们从模型中采样响应,重复 5 次并设不同随机种子。最终性能通过 Rouge-L(Lin, 2004)指标评估生成响应与人工标注响应之间的相似度。更多细节参见附录 B。
4.2 Baselines
我们在两种设置下,将我们的框架与现有方法进行对比:
词表相同下的知识蒸馏:在该设置中,我们将 DSKD 与当前的白盒知识蒸馏方法在以下距离函数下进行对比:
-
KL:由 Hinton 等人(2015)提出的标准 KL 散度。
-
RKL:反向 KL 散度,即交换 KL 中的两个分布。
-
JS:Jensen-Shannon 散度,KL 的对称变体。
-
SKL:Ko 等人(2024)提出的偏置 KL,调整学生分布为 λp+(1−λ)qθ\lambda p + (1 - \lambda) q_\thetaλp+(1−λ)qθ。
-
SRKL:Ko 等人(2024)提出的偏置 RKL,调整教师分布为 λqθ+(1−λ)p\lambda q_\theta + (1 - \lambda) pλqθ+(1−λ)p。
-
AKL:Wu 等人(2024)提出的 KL 与 RKL 的自适应融合。
词表不同下的知识蒸馏:我们还将带有跨模型注意力机制(CMA)的 DSKD 与支持词表不同的蒸馏方法进行比较:
-
MinCE:Wan 等人(2024)提出的方法,通过动态规划对齐不同模型的 logit,最小化 token 序列的编辑距离。
-
ULD:Boizard 等人(2024)提出的方法,用 Wasserstein 距离的闭式解替代 KL 散度,以克服对相同分词器的依赖。
此外,我们还在两种设置下将 DSKD 与黑盒知识蒸馏方法(序列级蒸馏,SeqKD;Kim 和 Rush, 2016)进行了比较。但我们未对比基于 on-policy 的方法,如 ImitKD(Lin 等, 2020)、GKD(Agarwal 等, 2024)、MiniLLM(Gu 等, 2023)和 DistiLLM(Ko 等, 2024),因为本工作专注于更通用的 off-policy 场景。
4.3 Results
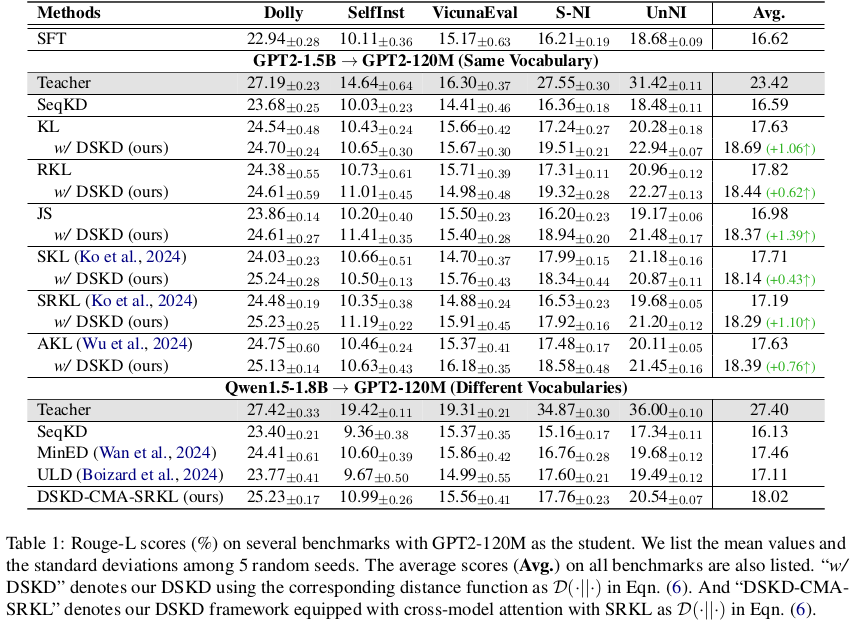
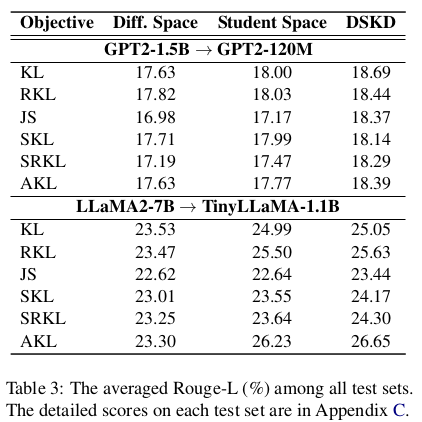
词表相同下的蒸馏:相关结果见表 1 和表 2 的上半部分。首先,所有白盒蒸馏方法的性能均优于黑盒蒸馏方法 SeqKD,表明 token 级别的分布能比单一目标 token 传递更多知识。进一步地,我们的 DSKD 框架在多种距离函数下显著优于现有白盒蒸馏方法(无论是 GPT2 还是 TinyLLaMA)。这表明:
-
一方面,我们提出的在统一输出空间下进行蒸馏的 DSKD 框架是有效的;
-
另一方面,该框架对各种蒸馏距离函数表现出良好的兼容性。
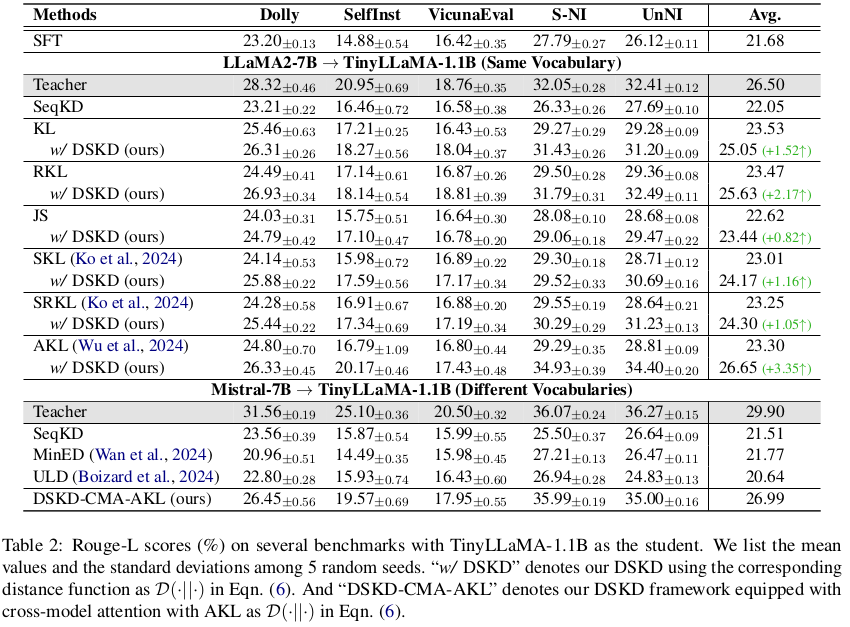
词表不同下的蒸馏:见表 1 和表 2 的下半部分。正如 §2.2.2 所述,此设置的关键挑战在于处理由于词表大小和分词策略不同所导致的分布不匹配问题。面对该挑战,现有方法通常预设粗略的对齐机制,因此性能受限,落后于词表相同时的蒸馏方法。相比之下,我们提出的 CMA 机制可以自动学习对齐方式,使得 DSKD 的性能优于现有方法。特别是,在该设置下的教师模型通常更强,因此 DSKD-CMA 有时甚至能超越词表相同时的性能(例如表 2 中的 DSKD-CMA-AKL)。这表明我们的框架在面对更强教师模型时,即使词表不同,也有潜力训练出更优秀的学生模型。
5 Analysis
5.1 KD in Different Spaces vs. Unified Space

5.2 Evaluation via GPT-4
我们还使用 GPT-4 对比评估了 DSKD 和当前的白盒 KD 框架。具体来说,我们从 Dolly 测试集中随机抽取了 100 个指令,分别用通过 DSKD 和当前 KD 框架训练得到的 TinyLLaMA 模型生成响应。随后,我们利用 GPT-4 判断哪一个响应更优,并将胜率绘制在图 2 中。
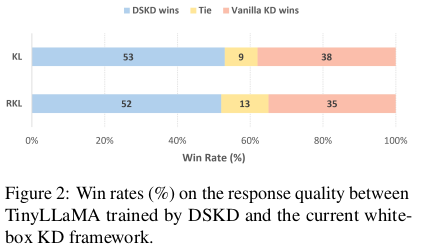
结果显示,在大多数情况下,无论使用 KL 散度还是反向 KL 散度(RKL),我们的 DSKD 方法都优于当前的蒸馏框架。其他距离函数的完整结果可参考附录 D。
5.3 Representation Similarity between the Teacher and the Student
在仿真实验中,我们发现当前的 KD 框架会导致教师与学生之间的表示相似性有限(如图 1(b) 所示)。因此,我们评估了这一现象在真实 KD 场景中是否也成立。由于教师与学生模型的隐藏状态维度通常不同,我们比较的是两者的表示结构相似性,而非具体的隐藏状态。
具体来说,我们使用输出隐藏状态之间的余弦相似度(cosine similarity)和标准化内积(normalized inner product)来表示一个模型的表示结构(见附录 E 的公式 (16) 和 (17))。随后,我们计算两种表示结构之间的 L1 距离来衡量它们的相似性,距离越小代表结构越相似(详细计算过程见附录 E 的公式 (18) 和 (19))。我们在 1000 条训练样本上统计了教师与学生之间的结构平均距离,并将其绘制在图 3 中。
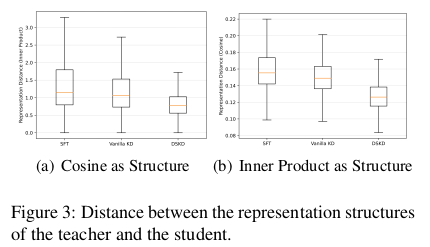
结果表明,在两种表示结构下,相比于不使用蒸馏的微调方法(SFT),当前的 KD 框架(Vanilla KD)仅能稍微减少教师与学生之间的结构距离。而我们的 DSKD 方法显著缩小了这一距离,表明 DSKD 能够有效提升学生与教师之间的表示结构相似性。
6 Related Work
语言模型的白盒知识蒸馏(White-Box KD for Language Models)
语言模型的白盒知识蒸馏(KD)框架起源于 Hinton 等人(2015)提出的标准知识蒸馏方法。随着预训练语言模型(PLMs)在各类自然语言处理任务中的广泛应用,许多知识蒸馏方法在这一框架下被提出,用以压缩 PLMs 的庞大参数规模(Sun 等, 2019;Sanh 等, 2019;Sun 等, 2020;Jiao 等, 2020)。除了最小化分布之间的距离外,还有基于特征的蒸馏方法,旨在从教师模型的中间隐藏状态和注意力图中提取知识(Jiao 等, 2020;Wang 等, 2020;2021b)。此外,白盒 KD 也广泛应用于文本生成任务,如神经机器翻译(Tan 等, 2019;Wang 等, 2021a;Zhang 等, 2023)和文本摘要(Chen 等, 2020;Liu 等, 2021)。
随着大语言模型(LLMs)在各类任务中占据主导地位,已有若干针对 LLM 的 KD 技术被提出(Gu 等, 2023;Ko 等, 2024;Wu 等, 2024;Xu 等, 2024)。与这些遵循当前白盒 KD 框架的工作不同,我们的研究对该框架固有的局限性提出质疑,并提出了一个更为简单、高效且通用的知识蒸馏框架作为替代方案
共享预测头的知识蒸馏(KD with the Shared Prediction Head)
在已有的 KD 研究中,SimKD(Chen 等, 2022)也提出了通过共享教师模型的预测头进行知识蒸馏,这一方式与我们 DSKD 中在教师空间进行 KD 的过程较为相似。然而,SimKD 的目标是将教师模型的预测头直接赋予学生模型,这会导致学生模型在蒸馏之后变得更大,推理成本也随之上升。相比之下,我们的 DSKD 仅利用这一过程来传递教师的表示信息,对学生模型的原始规模没有任何影响。
7 Conclusion
在本研究中,我们首先揭示了当前白盒大语言模型(LLM)知识蒸馏(KD)框架存在的两个局限性:一是导致学生模型与教师模型之间的表示相似性较低,二是要求教师与学生模型使用相同的词表。为了解决这两个问题,我们提出了一种新颖的白盒知识蒸馏框架,称为双空间知识蒸馏(Dual-Space Knowledge Distillation,DSKD),该框架在蒸馏过程中统一了教师与学生的输出空间。
在此基础上,我们进一步设计了一种跨模型注意力机制(Cross-Model Attention),以解决不同 LLM 之间的词表不匹配问题,从而使我们的 DSKD 框架能够支持任意两个 LLM 之间的知识蒸馏,无论它们的词表是否一致。
在多个指令跟随类基准数据集上的实验结果表明,我们的 DSKD 框架在多种距离函数下都显著优于当前的白盒 KD 框架。同时,在词表不同的模型间蒸馏场景下,DSKD 也优于所有现有的 KD 方法。














如何使用网络文件系统NFS)


)
学习笔记)
