1 项目介绍
项目架构如下:
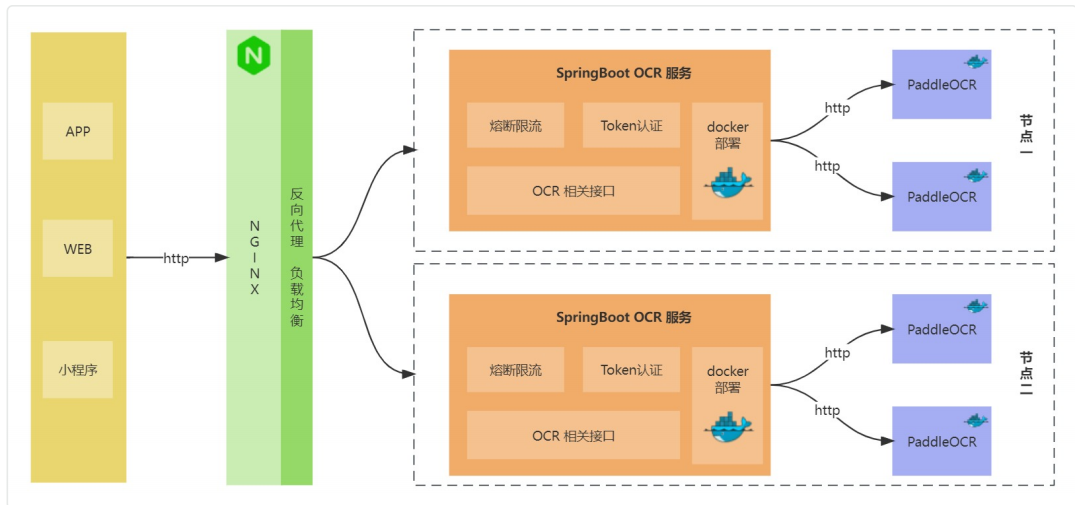
- APP/WEB/⼩程序为OCR识别接⼝调⽤端,调⽤OCR接⼝,实现OCR功能。本项⽬我们只实现Android APP开发。
- Nginx反向代理和负载均衡功能,通过Nginx实现对外⽹暴露接⼝,对内负载均衡SpringBoot实现的OCR服务。
- OCR服务通过Springboot实现,主要功能是提供具体的OCR接⼝实现,其流程是调⽤内部PaddleOCR服务,解析和处理返回结果,最终返回结果给接⼝调⽤者。为了稳定性和安全性,添加了熔断限流、Token认证功能。为了⽅便部署,会以Docker形式部署该服务。
- PaddleOCR是OCR识别的具体实现,会提供⼀个OCR识别接⼝,供内部调⽤。由于不同的部署⽅式(普通部署和paddleocr serving⽅式部署),PaddleOCR在普通部署⽅式下,⽆法利⽤CPU多核(Servering⽅式不存在该问题),因此会在同⼀个服务器部署多个实例,解决CPU利⽤率差以提升性能。为了⽅便PaddleOCR部署,会以Docker形式部署。后边会讲解普通⽅式部署和Servering⽅式部署,如何构建docker镜像及部署流程。
2 python开发PaddleOCR内部接口
2.1 安装 Flask
pip install flask==3.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple2.2 编写简单Flask接口进行测试
新建python文件,编写接口如下:
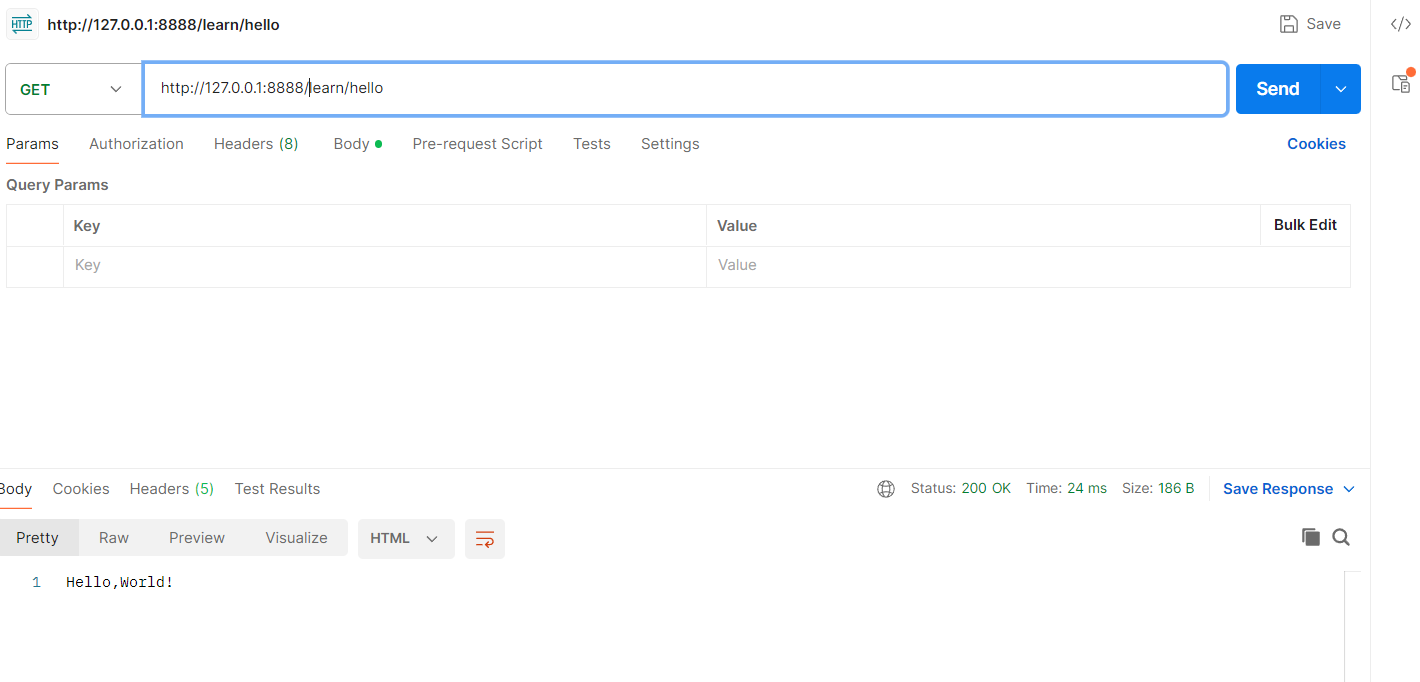
@app.route("/learn/hello")
def hello_world():return "Hello,World!"结果如下:
接口代码如下:
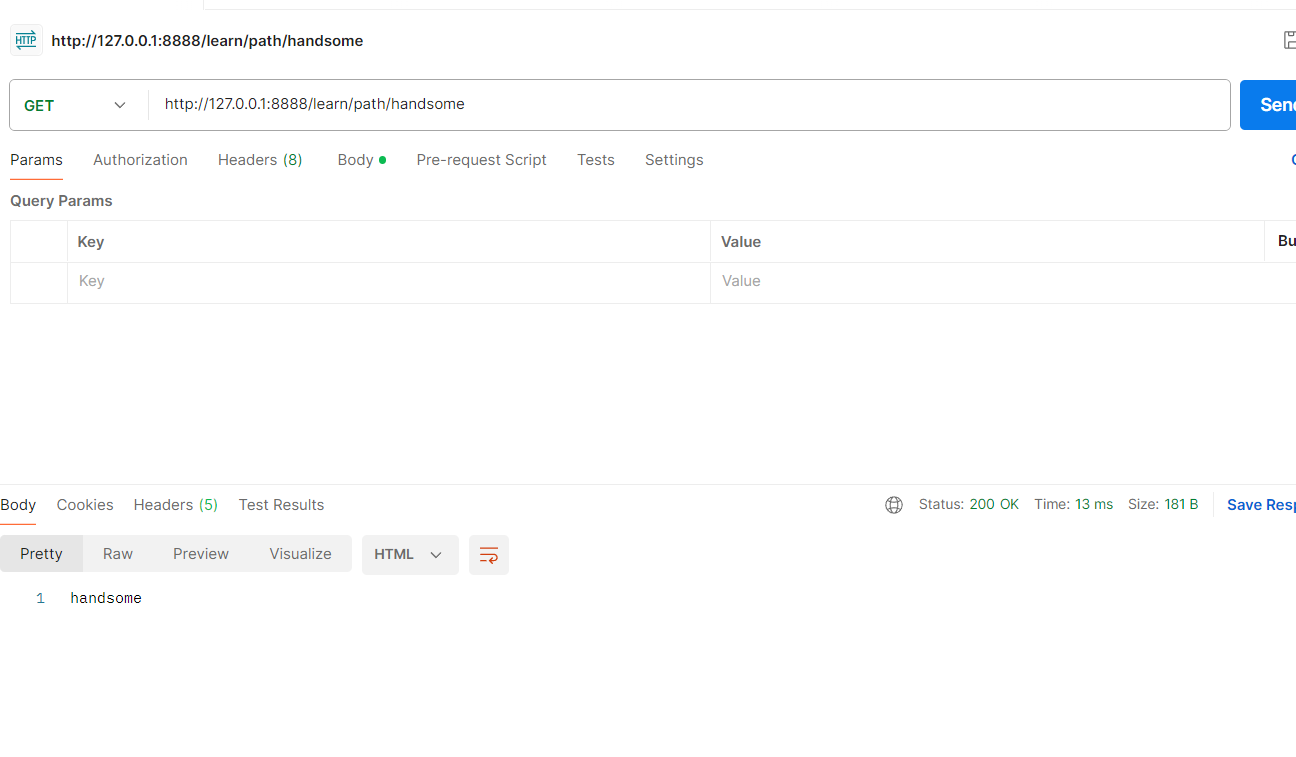
@app.route("/learn/path/<string:name>")
def learn_path(name):return name结果如下:
接口代码如下:
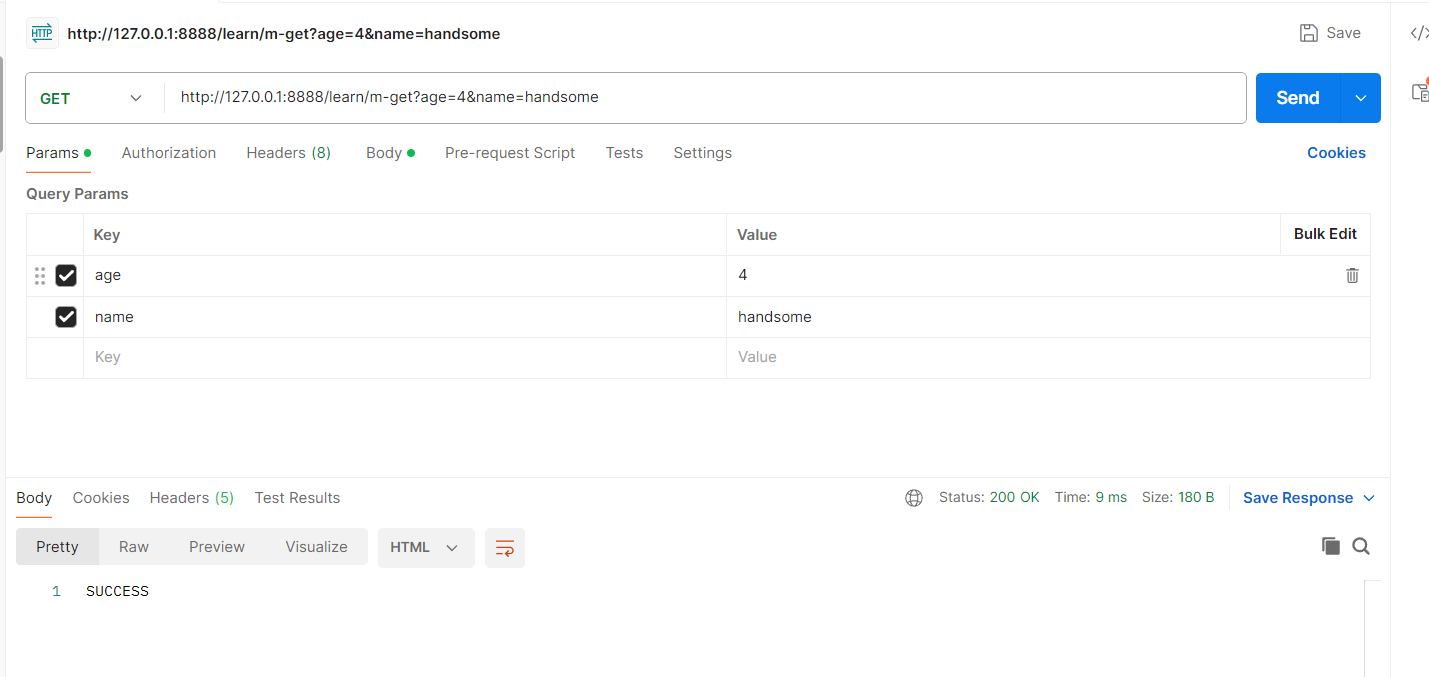
@app.route("/learn/m-get", methods=["GET"])
def learn_get_method():age = request.args.get("age")name = request.args.get("name")logging.info("learn m-get age 是:%s, name是:%s", age, name)return "SUCCESS", 200结果如下:
接口代码如下:
# 通过POST方式获取参数,参数时jsOn符中
@app.route("/learn/m-post", methods=["POST"])
def learn_post_method():data = request.datalogging.info("learn post-m data :%s", data)data = json.loads(data)age = data["age"]name = data["name"]logging.info("learn post-m age:%s name:%s", age, name)return jsonify(data), 200结果如下:
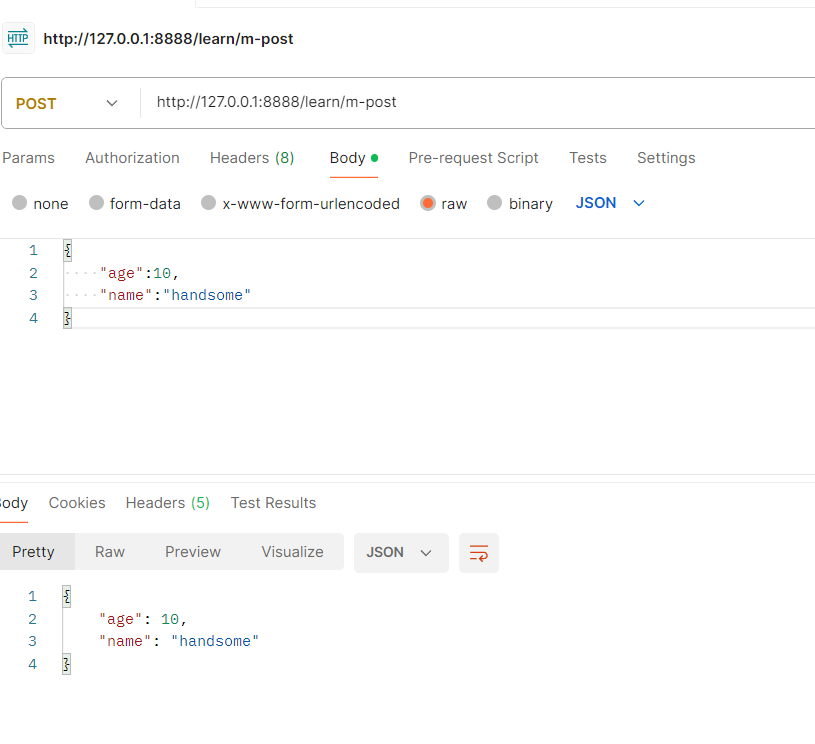
上面都成功说明Flask没问题。
完整代码如下:
import json
import logging
from flask import Flask, request, jsonifydef init_log():# 设置打印到控制台的格式和等级logging.basicConfig(format='%(asctime)s %(filename)s %(levelname)s %(message)s', datefmt='%a %d %b %Y %H:%M:%S',level=logging.INFO)# 设置输出到的文件和编码file_handler = logging.FileHandler("ocr.log", encoding="utf-8")# 设置输出等级file_handler.setLevel(logging.INFO)# 设置输出到文件的日志格式file_handler.setFormatter(logging.Formatter('%(asctime)s %(filename)s %(levelname)s %(message)s'))logger = logging.getLogger()logger.handlers.append(file_handler)init_log()# name是python中的特殊变量,如果文件作为主程序执行(例如直接技行),那么..name.的值就是_main_-,如果是被其它模块引入,那么__name-就是模块名称
app = Flask(__name__)@app.route("/learn/hello")
def hello_world():return "Hello,World!"@app.route("/learn/path/<string:name>")
def learn_path(name):return name@app.route("/learn/m-get", methods=["GET"])
def learn_get_method():age = request.args.get("age")name = request.args.get("name")logging.info("learn m-get age 是:%s, name是:%s", age, name)return "SUCCESS", 200# 通过POST方式获取参数,参数时jsOn符中
@app.route("/learn/m-post", methods=["POST"])
def learn_post_method():data = request.datalogging.info("learn post-m data :%s", data)data = json.loads(data)age = data["age"]name = data["name"]logging.info("learn post-m age:%s name:%s", age, name)return jsonify(data), 200if __name__ == '__main__':# 接收所有的IP请求,debug=True表示代列修改web容器公业启app.run(host='0.0.0.0', debug=True, port=8888)
2.3 Flask集成PaddleOCR
检测+⽅向分类器+识别全流程,只需要下⾯三⾏代码
#导⼊依赖
from paddleocr import PaddleOCR
#创建PaddleOCR对象,只需要在初始化时执⾏⼀次该语句
ocr = PaddleOCR(use_angle_cls=True, det=False, use_gpu=False)
#识别图⽚返回结果,cls=True 表示识别旋转180度的⽂字,如果没有⽂字旋转180度,那么
#可以cls=False,这样会提升性能,旋转90度和270度也能够识别
result = ocr.ocr(imgPath, cls=True)完整的PaddleOCR内部接口开发如下:
下⾯这段python代码主要是实现:通过flask创建web容器,并通过/ocr 接⼝调⽤ paddleocr进⾏图⽚识别,并通过json格式返回识别结果。
import json
import logging
from flask import Flask, request, jsonify
from paddleocr import PaddleOCRdef init_log():# 设置打印到控制台的格式和等级logging.basicConfig(format='%(asctime)s %(filename)s %(levelname)s %(message)s', datefmt='%a %d %b %Y %H:%M:%S',level=logging.INFO)# 设置输出到的文件和编码file_handler = logging.FileHandler("ocr.log", encoding="utf-8")# 设置输出等级file_handler.setLevel(logging.INFO)# 设置输出到文件的日志格式file_handler.setFormatter(logging.Formatter('%(asctime)s %(filename)s %(levelname)s %(message)s'))logger = logging.getLogger()logger.handlers.append(file_handler)init_log()# name 是python中的特殊变量,如果文件作为主程序执行(例如直接执行),那么__name__的值就是__main__,如果是被其它模块引入,那么__name__就是模块名称
app = Flask(__name__)# 创建一个PaddleOCR对象,使用方向识别器,不使用gpu进行技术,通过cpu进行计算。PaddleOCR我们只需要初始化一次,会将模型加载到内存,会将相关模型下载如果是第一次使用
ocr = PaddleOCR(usr_angle_cls=True, use_gpu=False)# 通过POST方法识别图片,传入参数为图片的路径
@app.route("/ocr", methods=["POST"])
def learn_post_method():try:data = json.loads(request.data)img_path = data["imgPath"]logging.info("ocr imgPath : %s", img_path)ocr_result = ocr.ocr(img_path)return jsonify({"code": 0, "msg": "ok", "data": ocr_result}), 200except Exception as e:logging.error("ocr error: %s", str(e))ocr_result = {"code": -1, "msg": str(e)}return jsonify(ocr_result), 200if __name__ == '__main__':# 可以返回中文字符app.config['JSON_AS_ASCII'] = False# 接收所有的IP请求,debug=True表示代码修改web容器会重启app.run(host='0.0.0.0', debug=True, port=8888)
- import 表示导⼊整个module(模块),⼀个.py⽂件就是⼀个module
- from A import B 表示导⼊A模块中的B(可以为⽅法、类)
- flask是python实现的web框架,类似Tomcat
- 如果是json格式的请求数据,则是采⽤request.data来获取请求体的字符串。
- 如果是form表单的请求体,那么则可以使⽤request.form来获取参数。
- 如果是url参数,例如:url?param1=xx¶m2=xx,那么则可以使⽤request.args来获取参数。
- 如果需要区分GET\POST请求⽅法,则可以使⽤request.method来进⾏判断区分
- 参考:https://cloud.tencent.com/developer/article/1539199,解释的很清楚
- @app.route 声明⼀个接⼝,指定请求⽅法和U请求路径
- 作为 Python 的内置变量,__name__它是每个 Python 模块必备的属性,但它的值取决于你是如何执⾏这段代码。通过__name__变量,可以判断出这时代码是被直接运⾏,还是被导⼊到其他程序中去了。当直接执⾏⼀段脚本的时候,这段脚本的 __name__变量等于 '__main__',当这段脚本被导⼊其他程序的时候,__name__ 变量等于脚本本身的名字。
接口测试,如下:
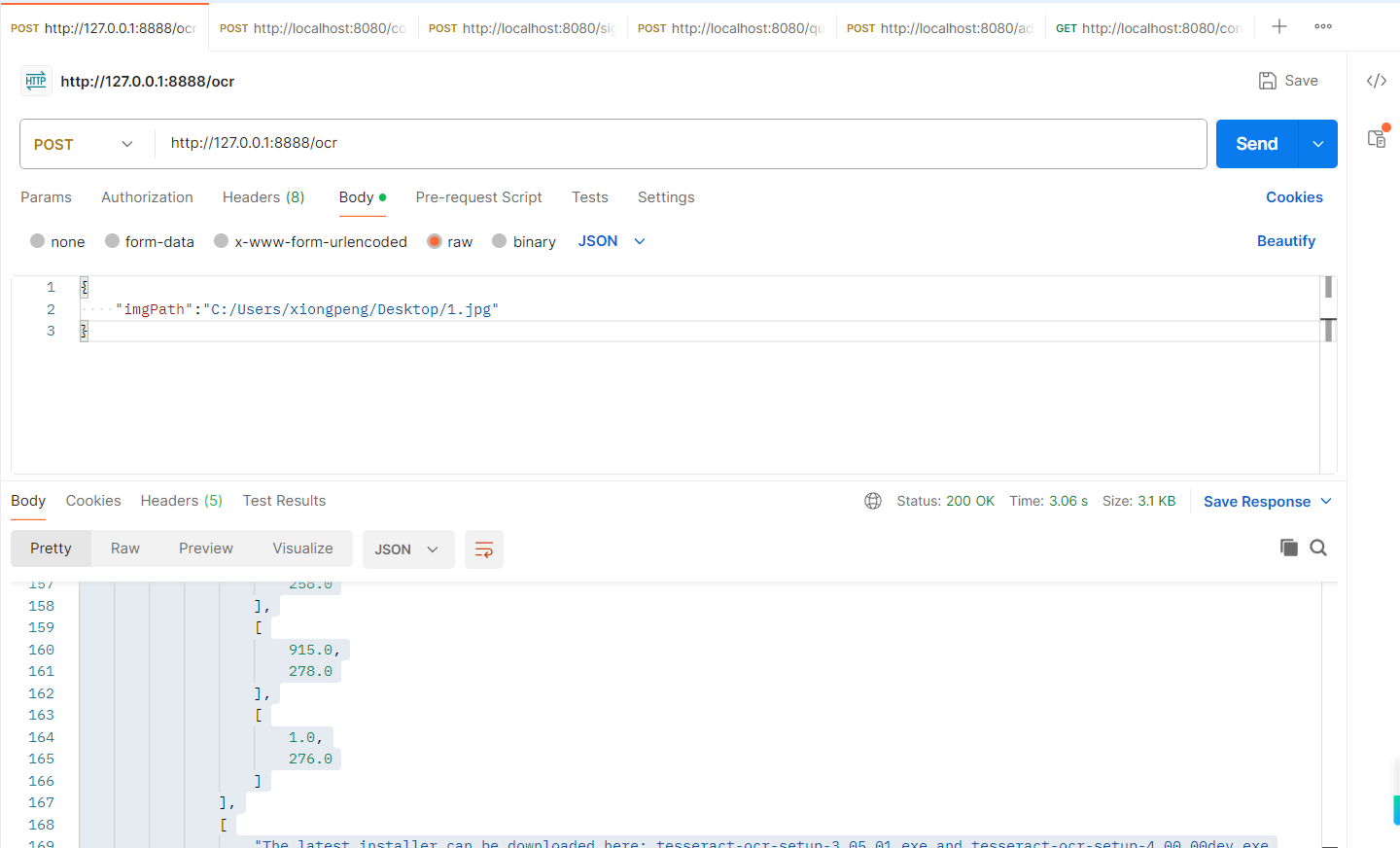
结果如下:
{"code": 0,"data": [[[[[1.0,12.0],[222.0,12.0],[222.0,35.0],[1.0,35.0]],["2.安装tesseract-ocr",0.9961034059524536]],[[[4.0,55.0],[384.0,54.0],[384.0,72.0],[4.0,73.0]],["OCR(OpticalCharacterRecognition,光学字符识别)软件",0.9673566222190857]],[[[1.0,88.0],[382.0,87.0],[382.0,103.0],[1.0,104.0]],["安装包含两个部分:ORC引擎本身以及对应语言的训练数据",0.9957185387611389]],[[[0.0,155.0],[389.0,153.0],[389.0,172.0],[0.0,174.0]],["githubttt址:https://github.com/tesseract-ocr/tesseract",0.9804431200027466]],[[[0.0,186.0],[576.0,187.0],[576.0,207.0],[0.0,206.0]],["You can either Install Tesseract via pre-built binary package or build it from source.",0.9568857550621033]],[[[1.0,221.0],[86.0,224.0],[85.0,241.0],[1.0,239.0]],["windows:",0.9869498014450073]],[[[1.0,256.0],[915.0,258.0],[915.0,278.0],[1.0,276.0]],["The latest installer can be downloaded here: tesseract-ocr-setup-3.05.01.exe and tesseract-ocr-setup-4.00.00dev.exe (experimental).",0.9753488898277283]]]],"msg": "ok"
}

















)
