在今天的文章中,我将参考文章 “使用 Elastic 和 LM Studio 的 Herding Llama 3.1” 来部署 Qwen3 大模型。据测评,这是一个非常不错的大模型。我们今天尝试使用 LM Studio 来对它进行部署,并详细描述如何结合 Elasticsearch 来对它进行使用。

关于 LM Studio
LM Studio 是本地大型语言模型 (LLM) 的浏览器/IDE,专注于使本地 AI 变得有价值且易于访问,同时为开发人员提供构建平台。
用户考虑本地 LLMs 的原因有很多,但其中最主要的是能够在不放弃对你或你公司的数据主权的情况下利用 AI。其他原因包括:
- 增强数据隐私和安全性
- 减少威胁检测的延迟
- 获得运营优势
- 在现代威胁环境中保护你的组织
LM Studio 提供统一的界面,用于本地发现、下载和运行领先的开源模型,如 Llama 3.1、Phi-3 和 Gemini。使用 LM Studio 本地托管的模型允许 SecOps 团队使用 Elastic AI Assistant 来帮助提供警报分类、事件响应等方面的情境感知指导。所有这些都不需要组织连接到第三方模型托管服务。
在本地电脑中部署阿里 Qwen3 大模型及连接到 Elasticsearch
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么我们可以参考如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
特别值得注意的是,我们选择 “Elastic Stack 8.x/9.x 安装” 安装指南。在本次的练习中,我们将使用最新的 Elastic Stack 9.0.1。
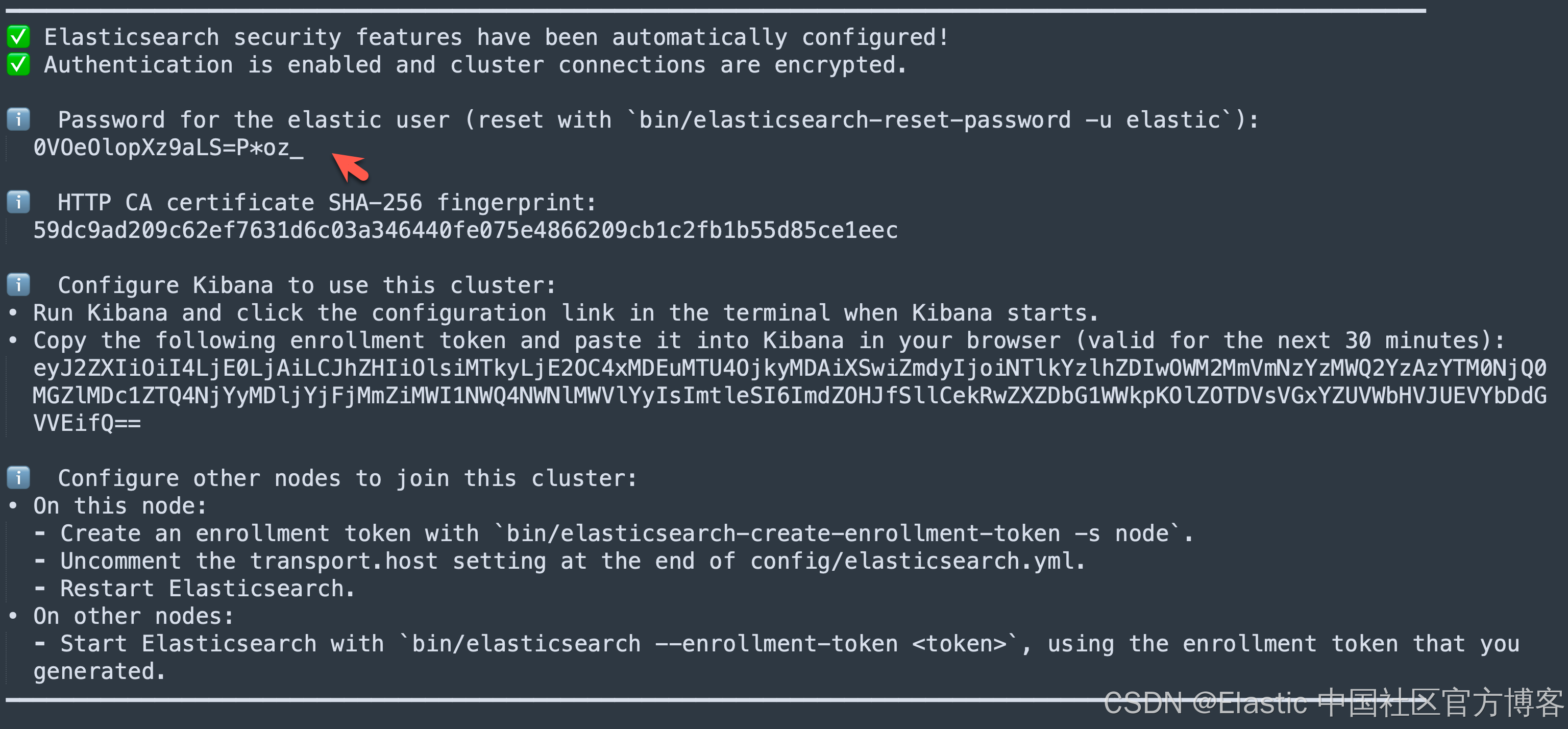
我们记下上面的密码,并在下面的代码中进行使用。
另外,为了能够使得我们避免警告,我们在 Kibana 中针对 xpack.encryptedSavedObjects.encryptionKey 进行设置。这个也是我们需要使用 Playground 所必须的。详细布置也可以参考文章 “Elasticsearch:使用 Playground 与你的 PDF 聊天”。 我们在 terminal 中打入如下的命令:
bin/kibana-encryption-keys generate$ pwd
/Users/liuxg/elastic/kibana-9.0.1
$ bin/kibana-encryption-keys generate
## Kibana Encryption Key Generation UtilityThe 'generate' command guides you through the process of setting encryption keys for:xpack.encryptedSavedObjects.encryptionKeyUsed to encrypt stored objects such as dashboards and visualizationshttps://www.elastic.co/guide/en/kibana/current/xpack-security-secure-saved-objects.html#xpack-security-secure-saved-objectsxpack.reporting.encryptionKeyUsed to encrypt saved reportshttps://www.elastic.co/guide/en/kibana/current/reporting-settings-kb.html#general-reporting-settingsxpack.security.encryptionKeyUsed to encrypt session informationhttps://www.elastic.co/guide/en/kibana/current/security-settings-kb.html#security-session-and-cookie-settingsAlready defined settings are ignored and can be regenerated using the --force flag. Check the documentation links for instructions on how to rotate encryption keys.
Definitions should be set in the kibana.yml used configure Kibana.Settings:
xpack.encryptedSavedObjects.encryptionKey: 6f1fdc6da9e4cdb8558fc8b4d3fe1048
xpack.reporting.encryptionKey: a22c866f356cda8097ad1b9befc56a25
xpack.security.encryptionKey: f4d6361ebd74b385c6ed722244985321我们必须把正在运行的 Kibana 停止再运行上面的命令。我们把上面最后面显示的设置拷贝到 config/kibana.yml 文件的最后面,并保存。然后重新启动 Kibana。
启动白金试用功能
为了能够创建 OpenAI 连接器,我们需要打开白金版试用功能:




这样我们的白金版试用功能就设置好了。有了这个我们在下面就可以创建 OpenAI 的连接器了。
安装 ES 向量模型
在我们的搜索中,我们需要使用一个嵌入向量模型来针对数据进行向量化。在本次练习中,我们使用 ES。这也是 Elasticsearch 自带的模型。我们需要对它进行配置:





从上面的显示中,我们已经成功地把 .multilingual-e5-small 模型部署到我们的 Elasticsearch 中了。
我们可以在 Kibana 中进行查看:
GET _inference
我们可以看到一个叫做 .multilingual-e5-small-elasticsearch 的 inference id 已经生成。
如何设置 LM Studio
下载并安装最新版本的 LM Studio。
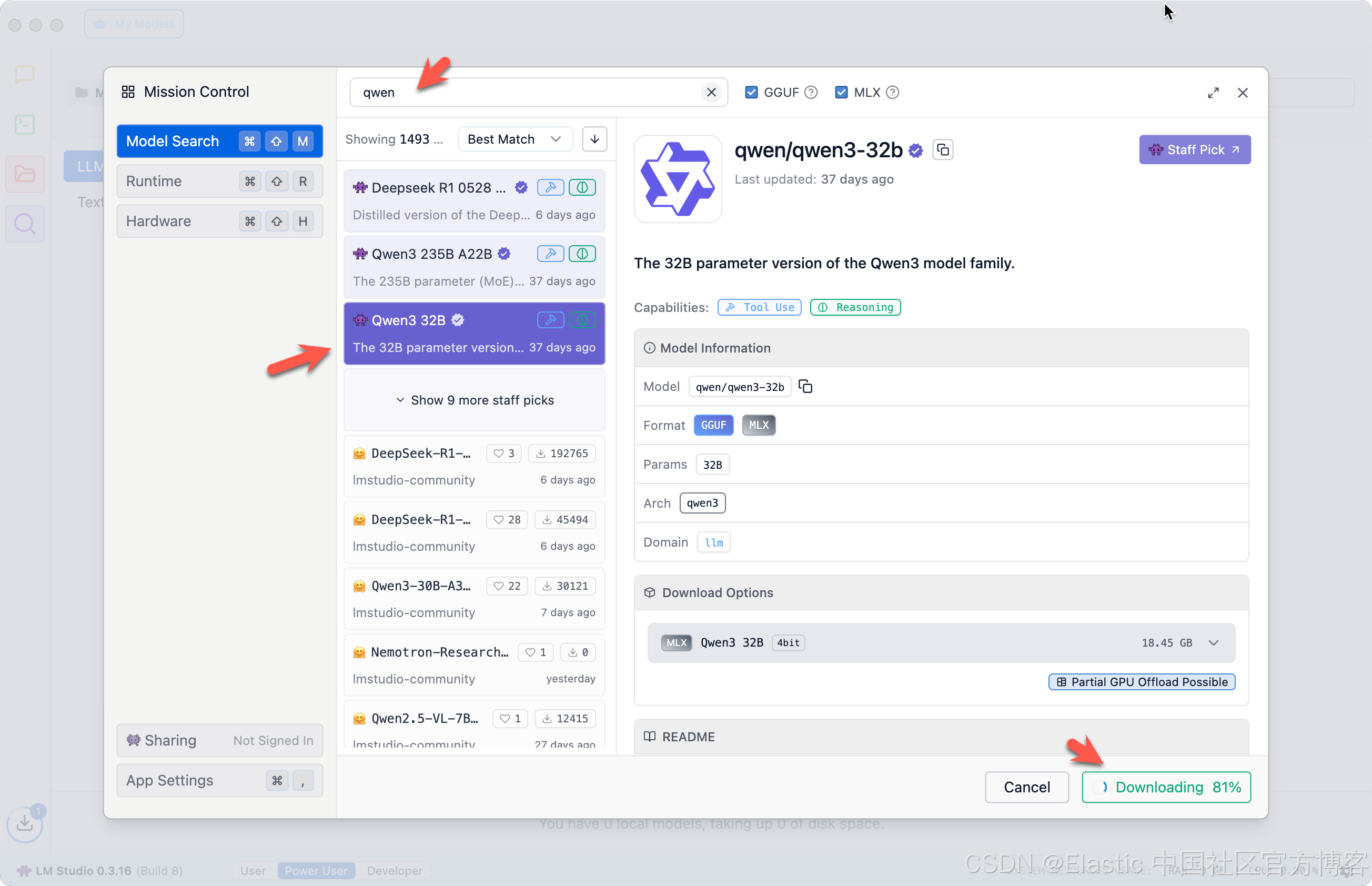
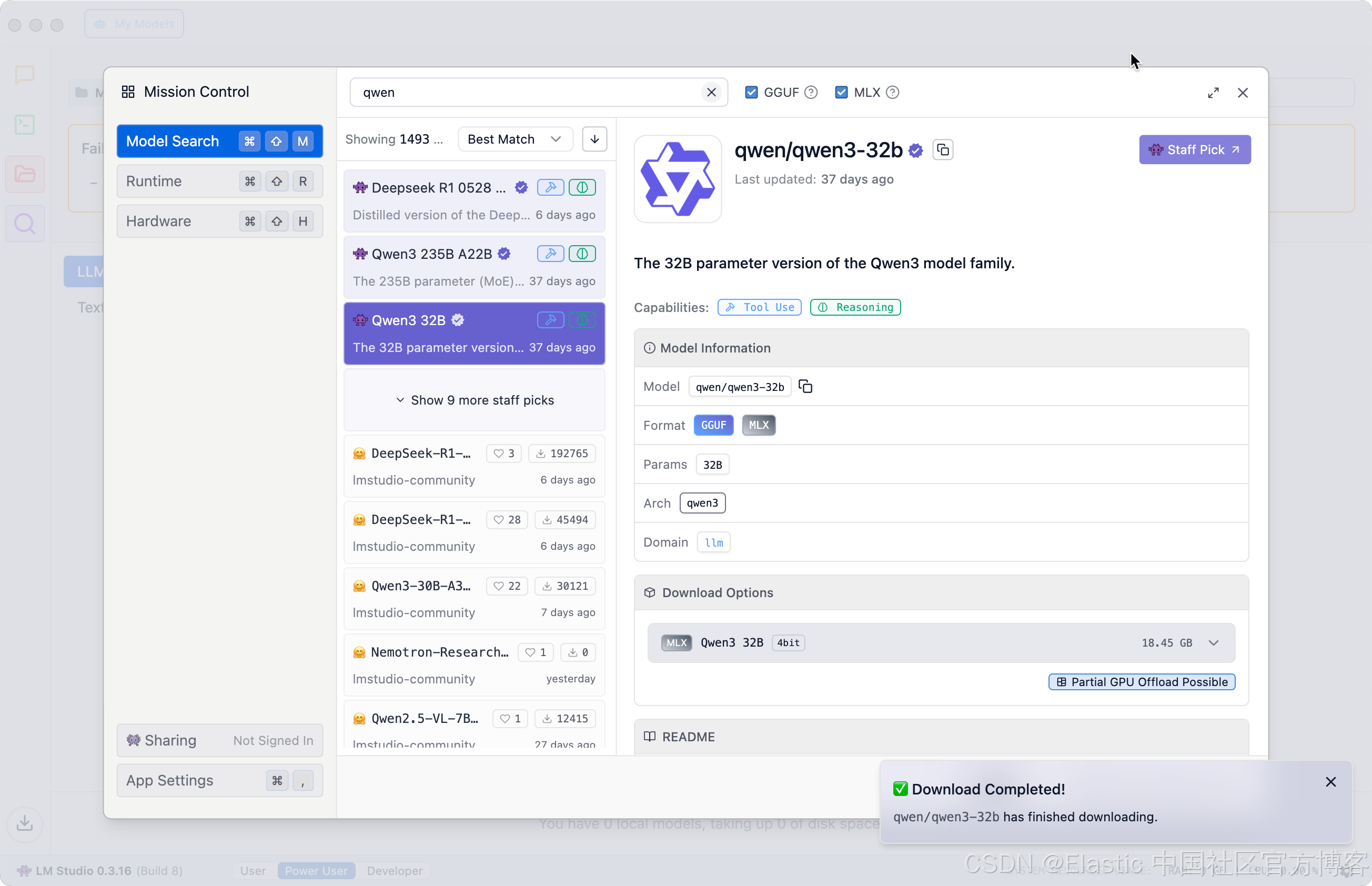
在下载完毕后,经过 checksum 验证,我们最终可以看到上面的画面。
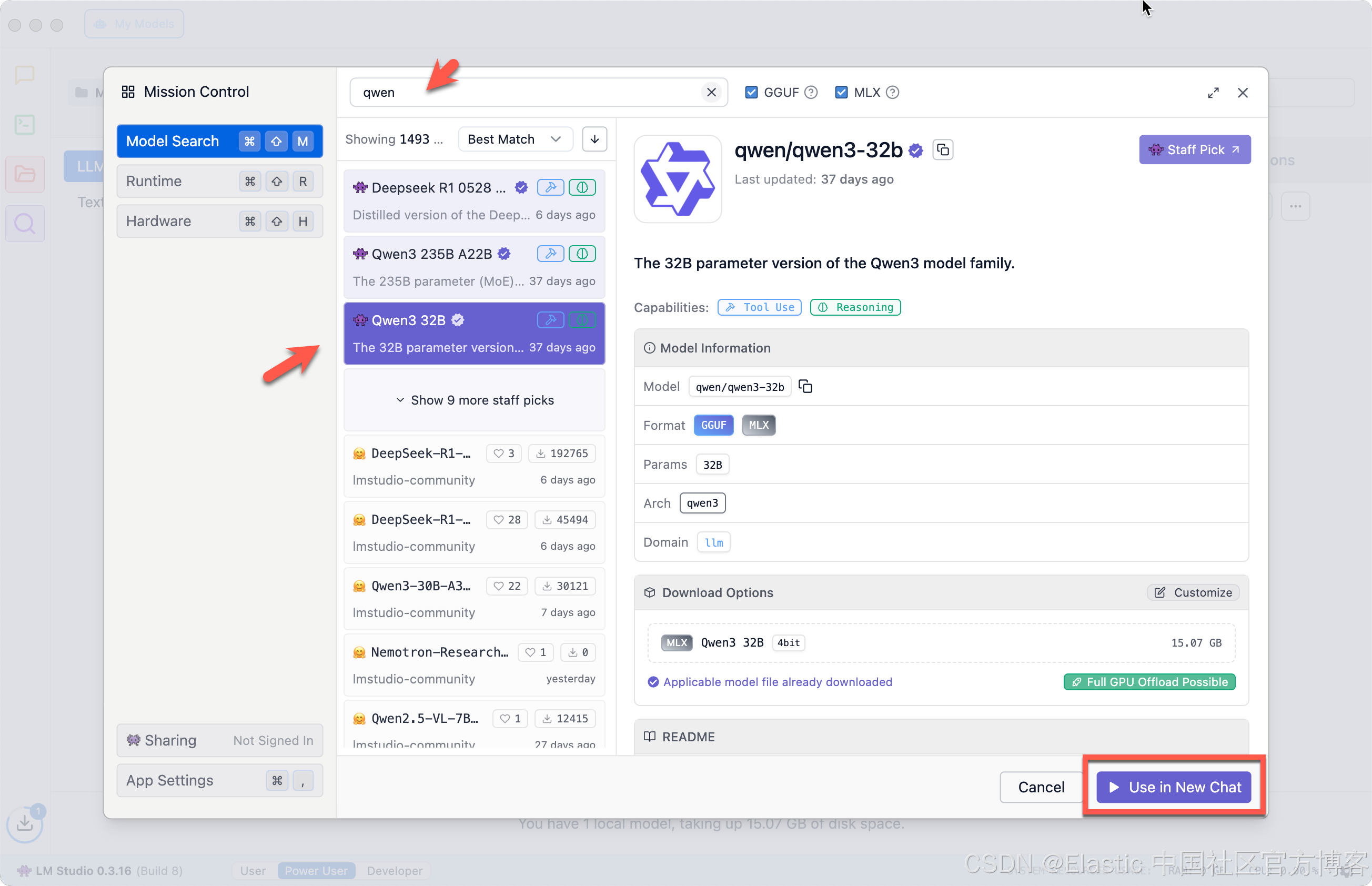
在 Discover 界面搜索 “Qwen”,并下载安装。如上所示,Qwen3 共有 18.45 GB,所以在下载之前,确保你有足够的电脑硬盘容量来对它进行安装。我们点击 “Use in New Chat”:
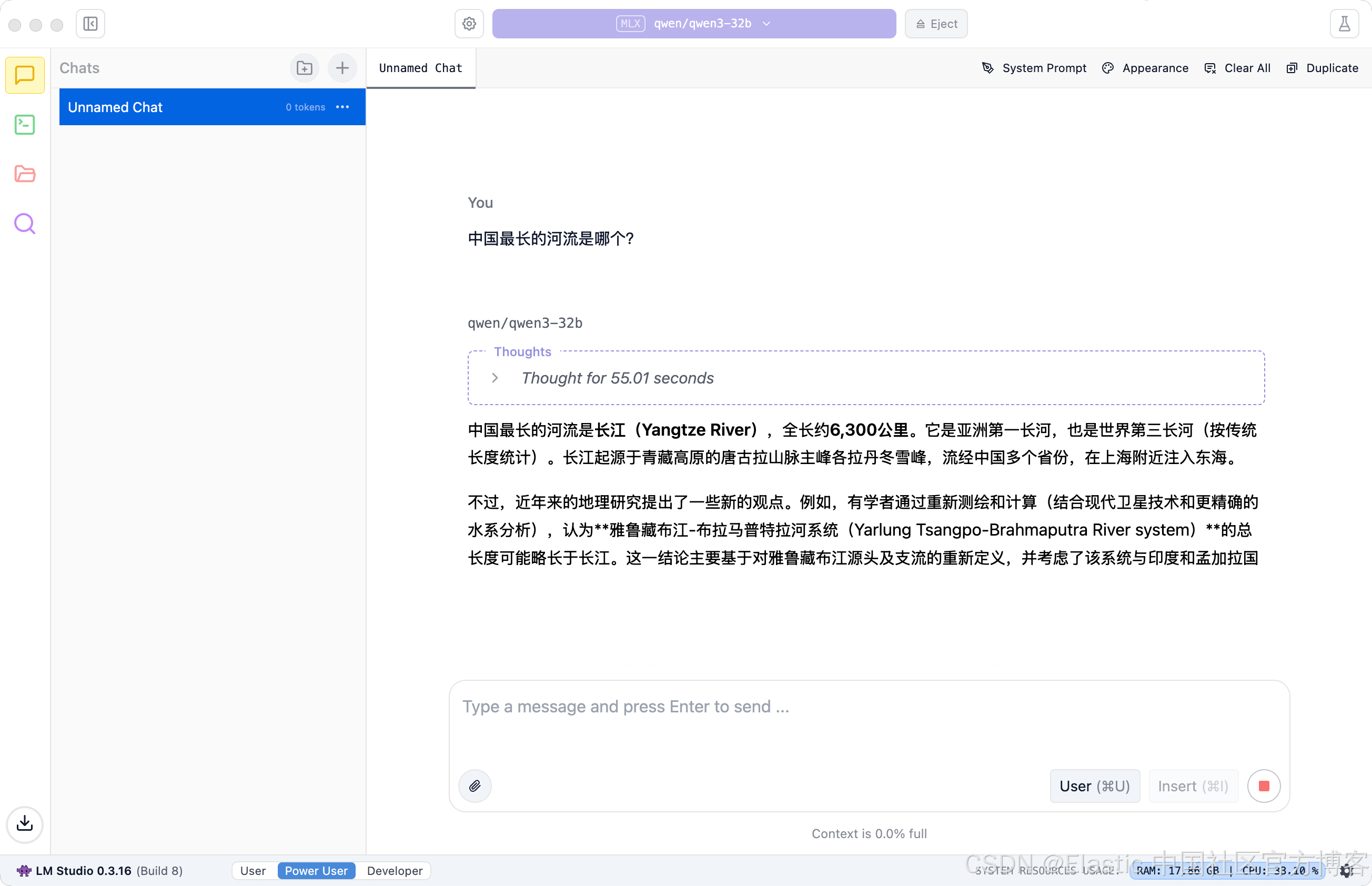
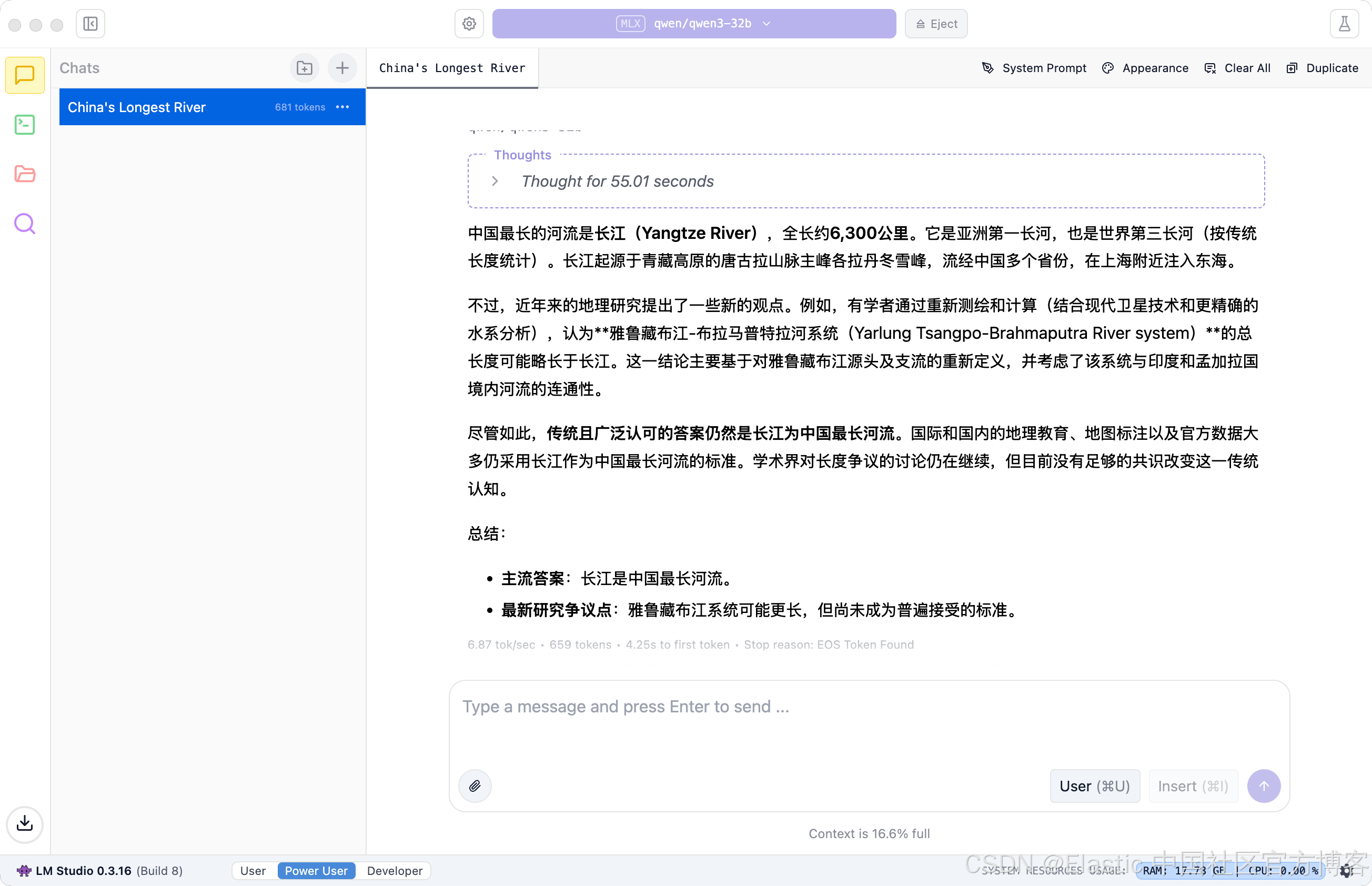
在上面,我们提出问题 “中国最长的河流是哪个?”。它最终给出了答案:
我们接下来验证一下它的英文能力:
What is the longest river in China?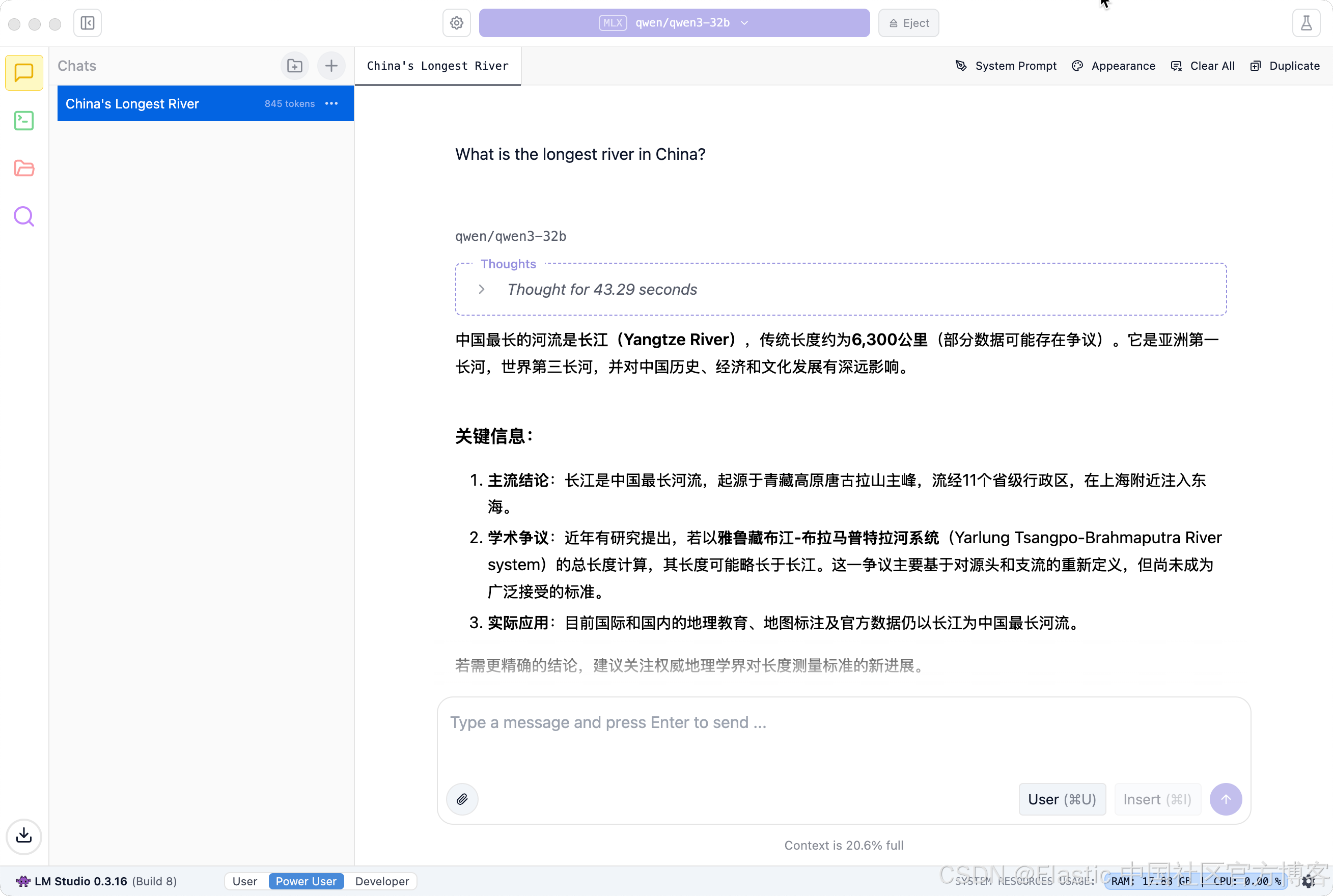
很有意思的是它给出的结果是以中文的形式。这个是和 DeepSeek 及 ChatGPT 有不同的地方。通常在 DeepSeek 中,如果我们的提问是以英文形式的,那么你得到的答案就是英文格式的。
注意:由于模型是在本地电脑部署的。这个依赖于你自己的电脑算力。有时给出的结果有点慢,但是需要大家的耐心等待!
我们接下来进入 “My Models" 来进行验证:
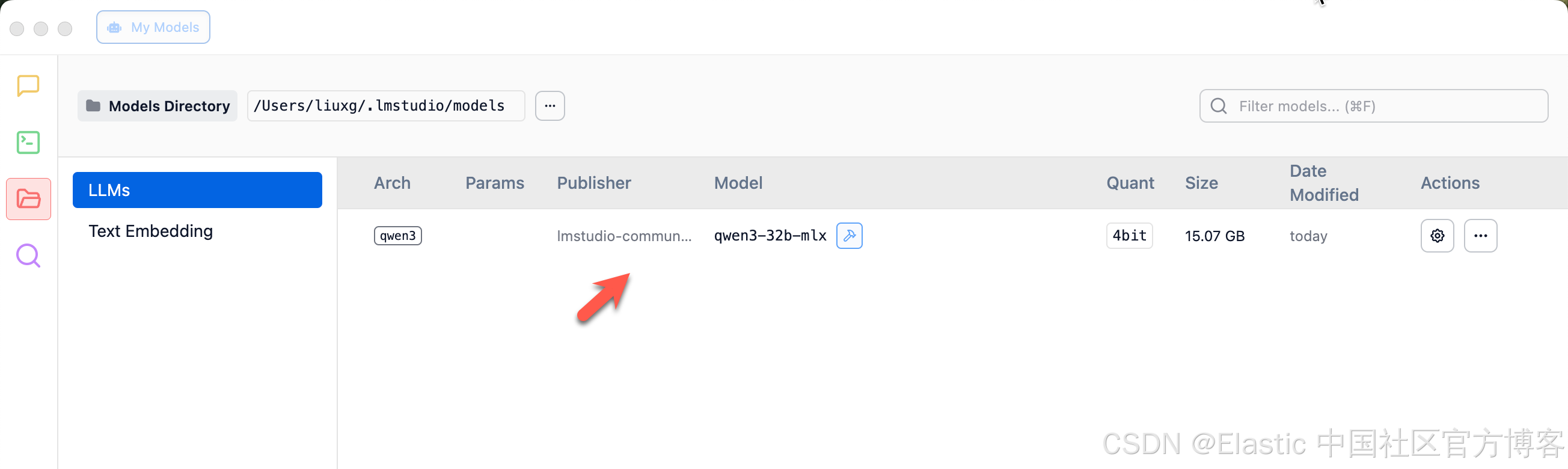
我们可以看到 qwen 已经被成功地安装了。
我们接下来打开 Developer 窗口,我们可以看到 qwen 的接口 API:
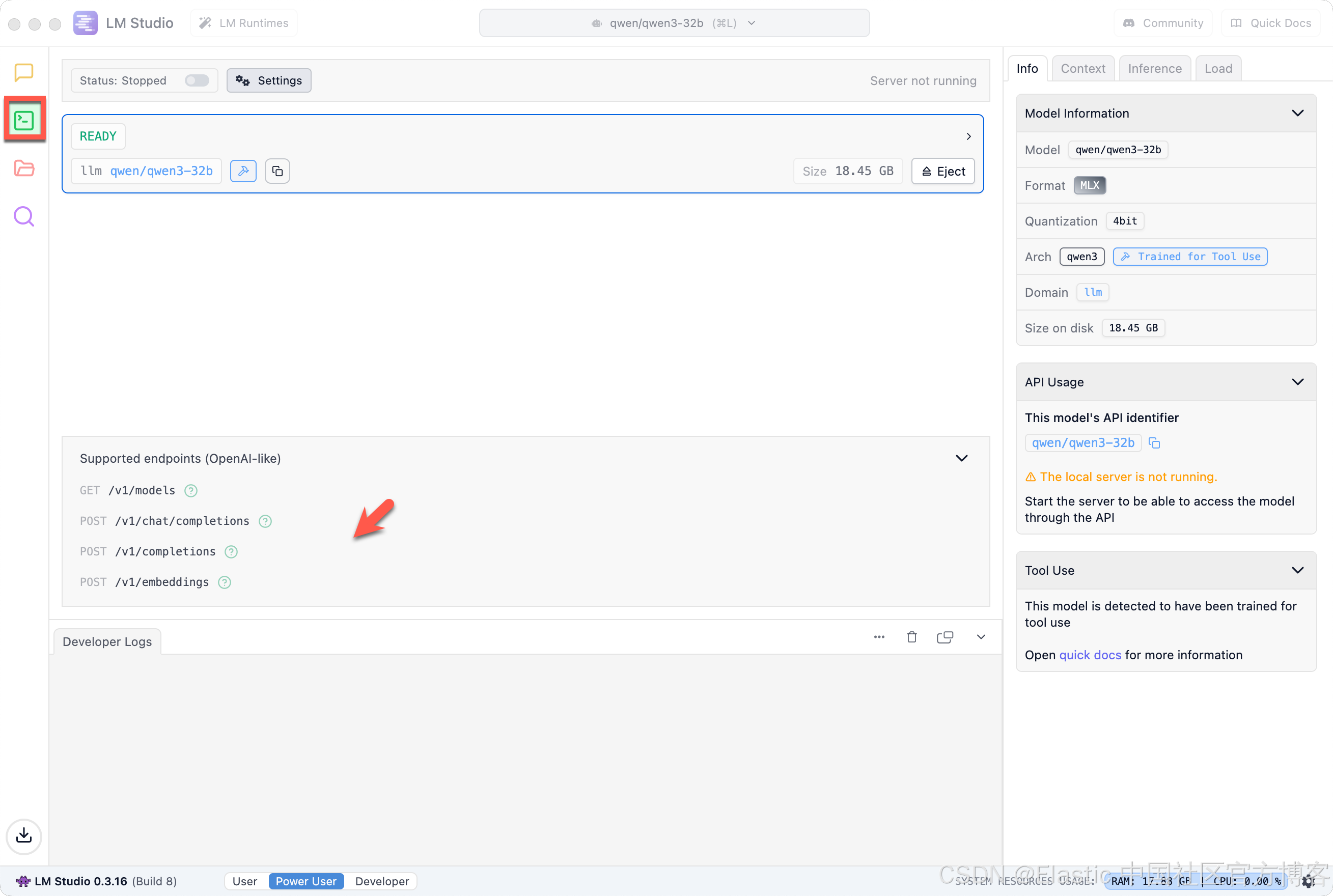
我们将在下面的练习中进行使用。同时我们注意到它的接口是以 Open AI 的格式来进行提供的。我们对本地服务器做如下的配置:
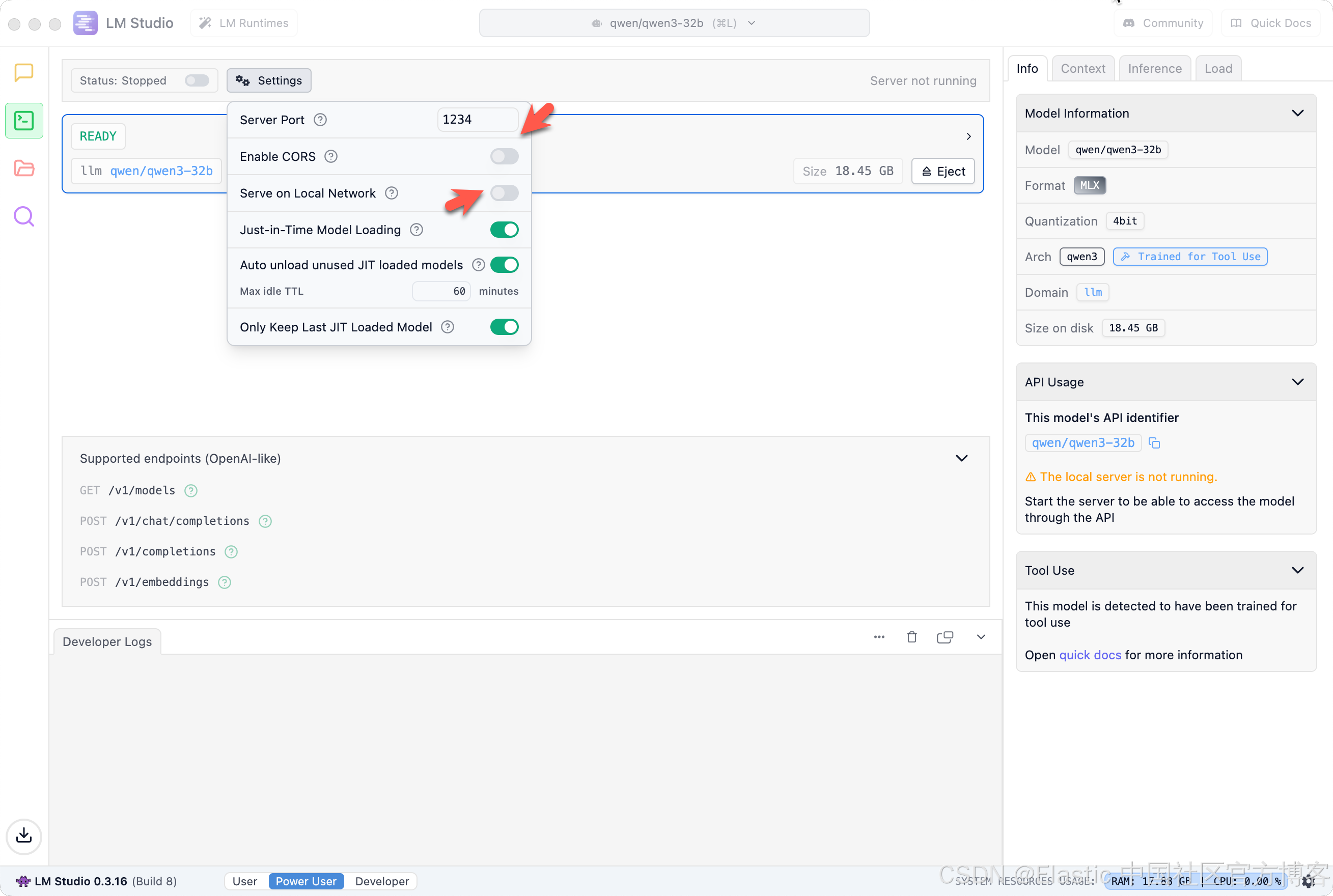
打开上面的两个配置:
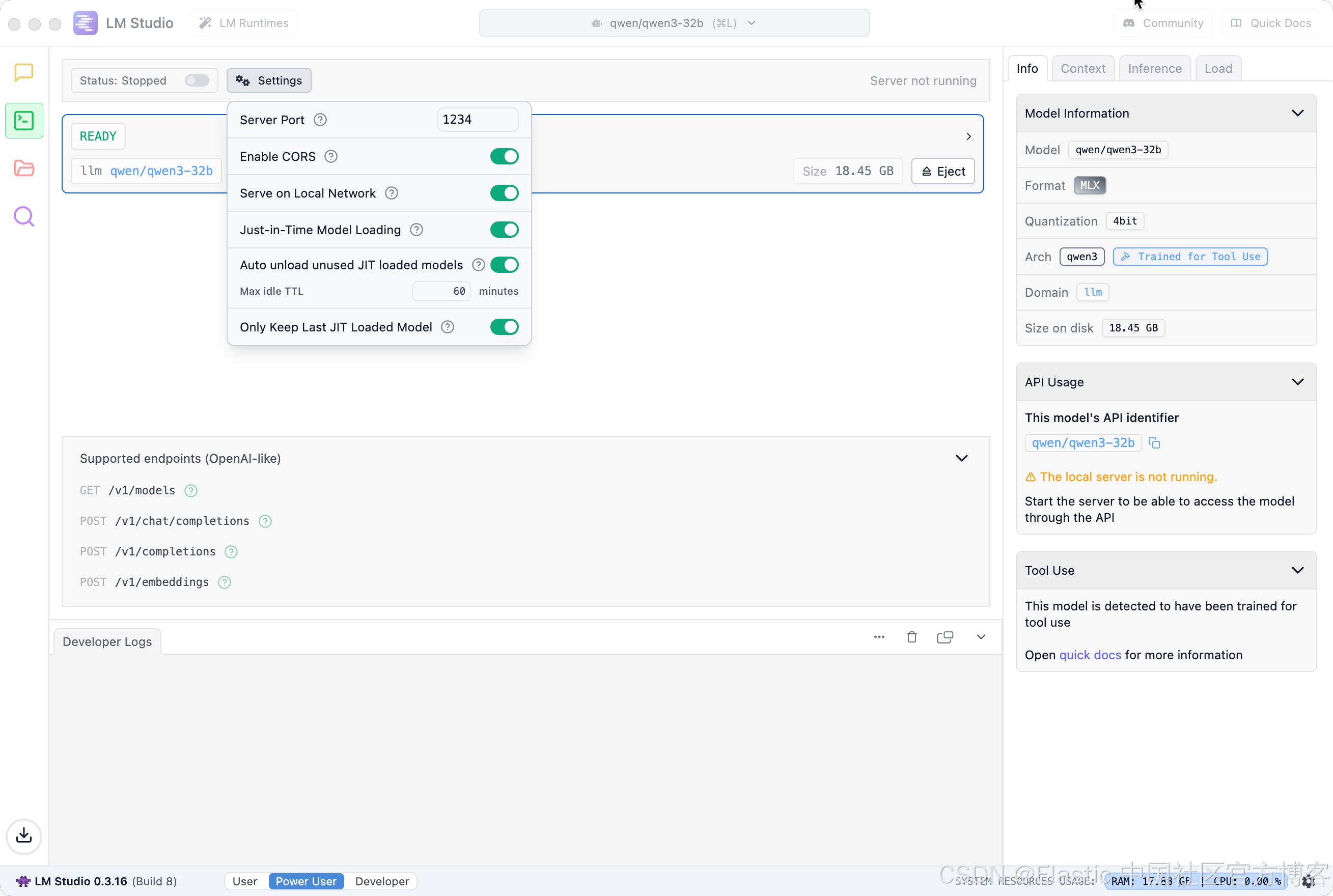
我们还需要同时打开这个本地服务器:
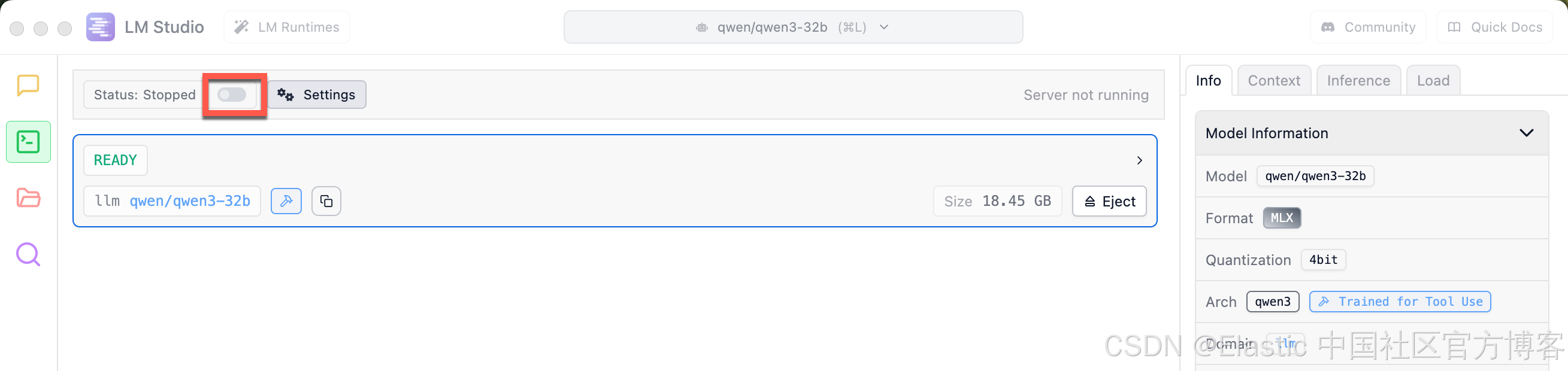
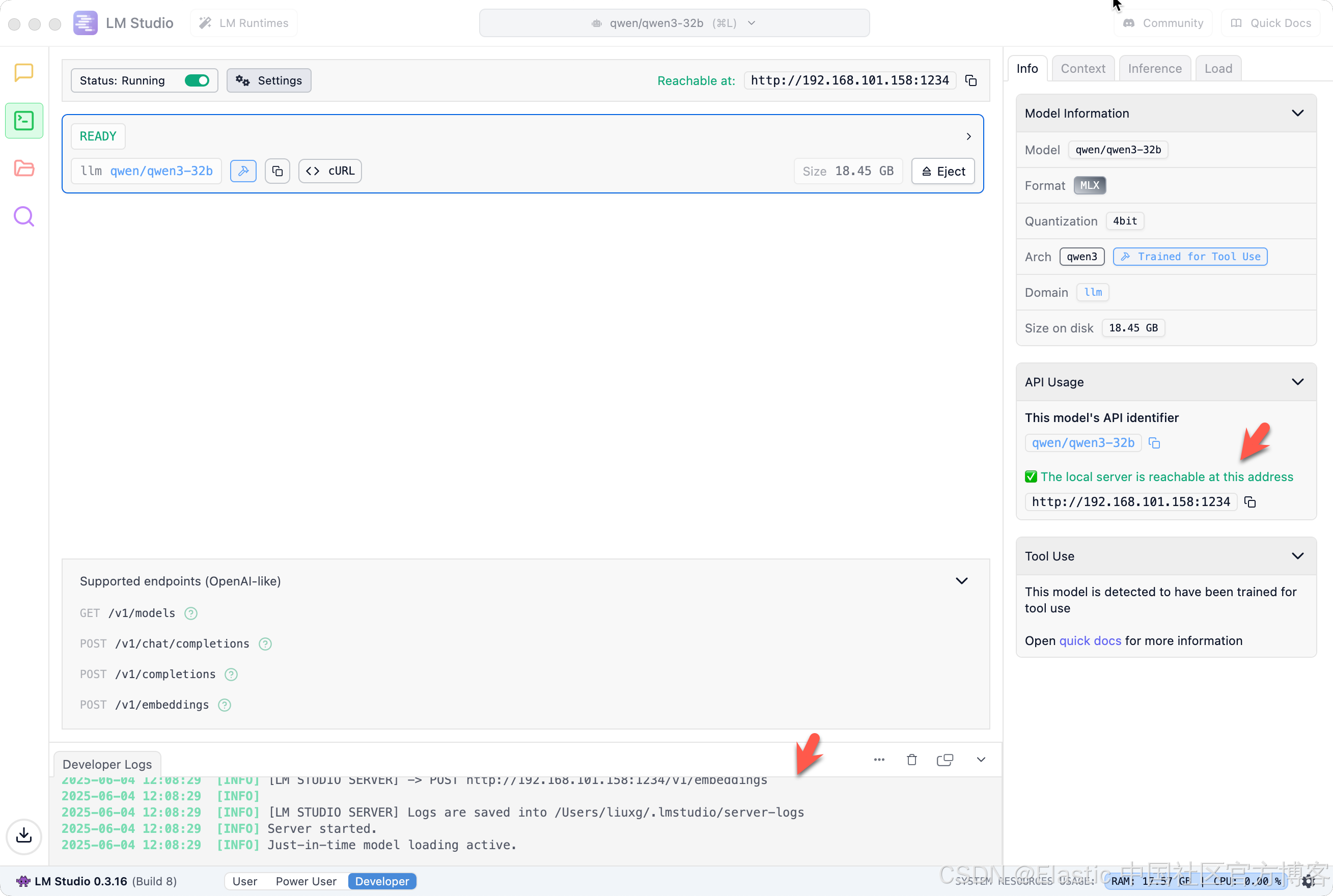
一旦打开,我们可以看到日志,并看到服务器的状态已经发生改变。
我们可以通过如下的方式来获得本地电脑的 IP 地址:
ifconfig | grep inet | grep 192$ ifconfig | grep inet | grep 192inet 192.168.101.158 netmask 0xffffff00 broadcast 192.168.101.255注:如果你的 qwen3 不是和你自己的 Elasticsearch 处于同一个机器上,那么你需要使用到上面的私有地址(在同一局域网里)
我们可以通过如下的命令来验证我们的服务器接口:
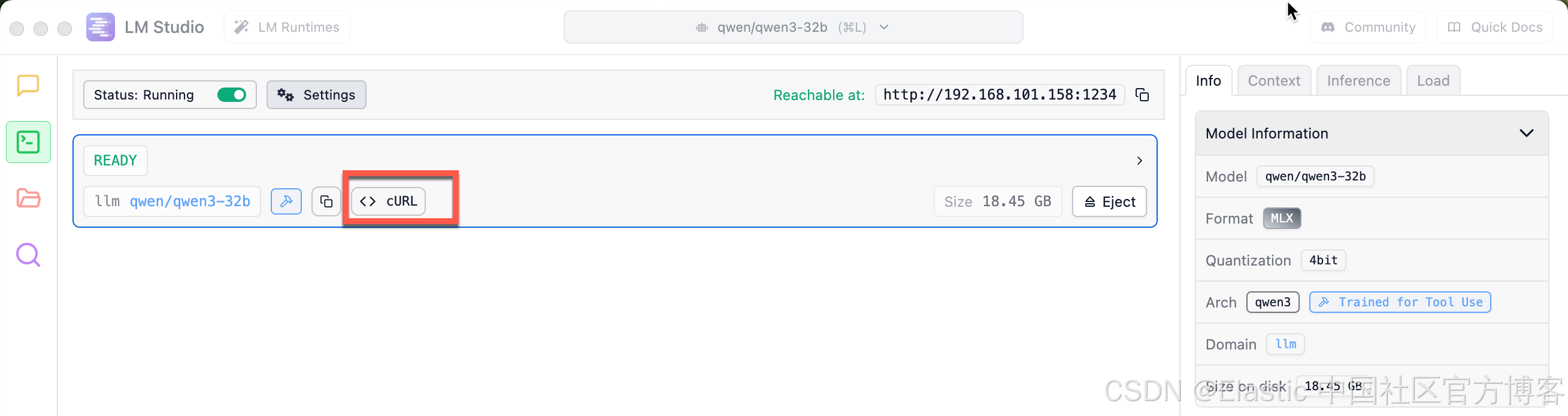
拷贝上面的 cURL 命令:
curl http://localhost:1234/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "qwen/qwen3-32b","messages": [{ "role": "system", "content": "Always answer in rhymes. Today is Thursday" },{ "role": "user", "content": "What day is it today?" }],"temperature": 0.7,"max_tokens": -1,"stream": false
}'我们可以直接在电脑的 terminal 中打入上面的命令:
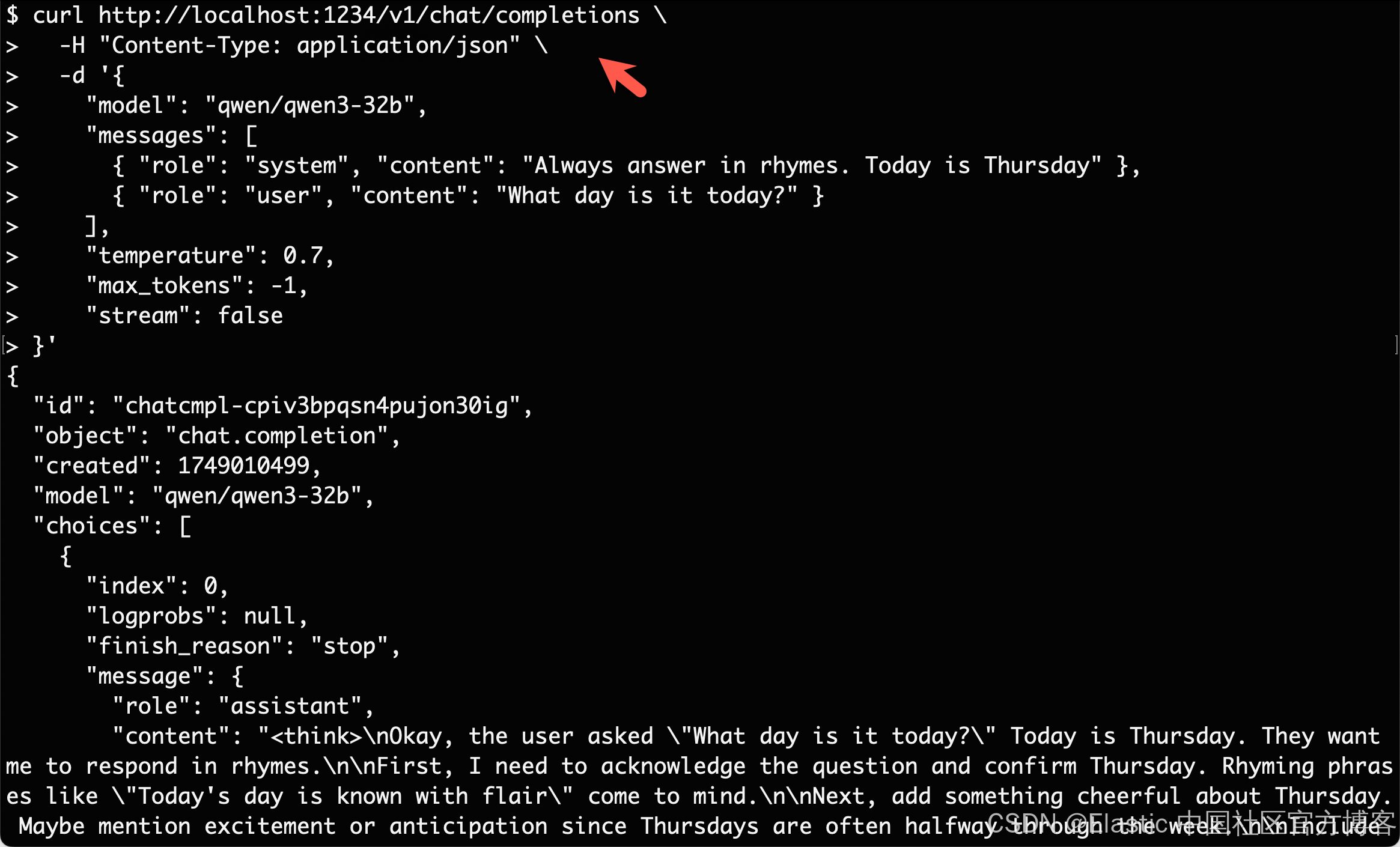
我们得到了一个相关的结果。我们接下来稍微修改一下我们的问题:
curl http://localhost:1234/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "qwen/qwen3-32b","messages": [{ "role": "system", "content": "You are a helpful AI Assistant that uses the following context to answer questions only use the following context. \n\nContext: 小明今天早上和妈妈一起去上学"},{ "role": "user", "content": "小明今天和谁一起去上学的?" }],"temperature": 0.7,"max_tokens": -1,"stream": false
}'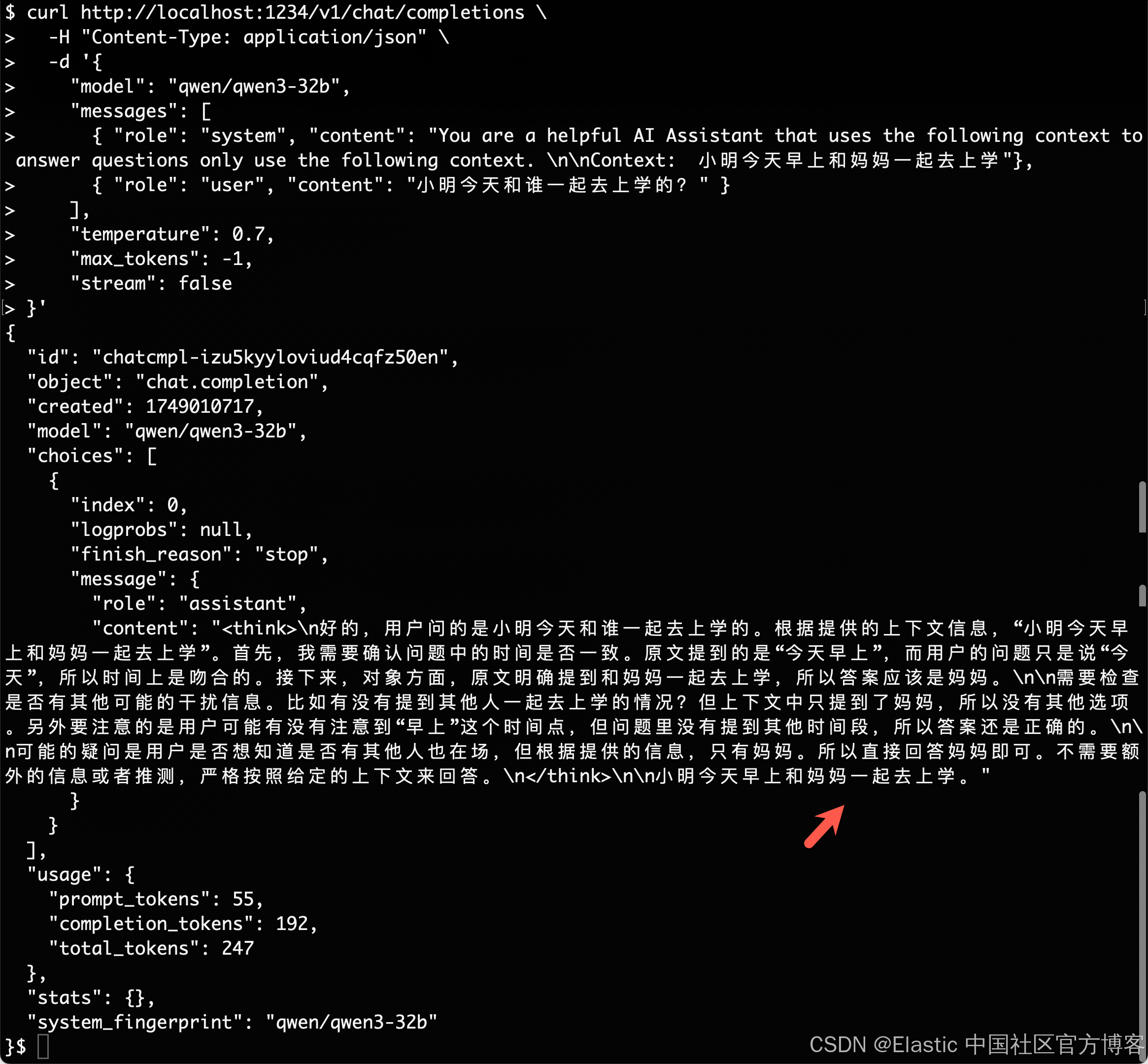
很显然,它具备一定的推理能力。我们得到了我们想要的答案。
在 Kibana 中创建连接到 Qwen 的连接器
我们按照如下的步骤来进行:
使用以下设置配置连接器:
- Connector name:qwen3
- 选择 OpenAI provider:other (OpenAI Compatible Service)
- URL:http://localhost:1234/v1/chat/completions
- 调整到你的 qwen3 的正确路径。如果你从容器内调用,请记住替换 host.docker.internal 或等效项
- 默认模型:qwen/qwen3-32b
- API 密钥:编造一个,需要输入,但值无关紧要
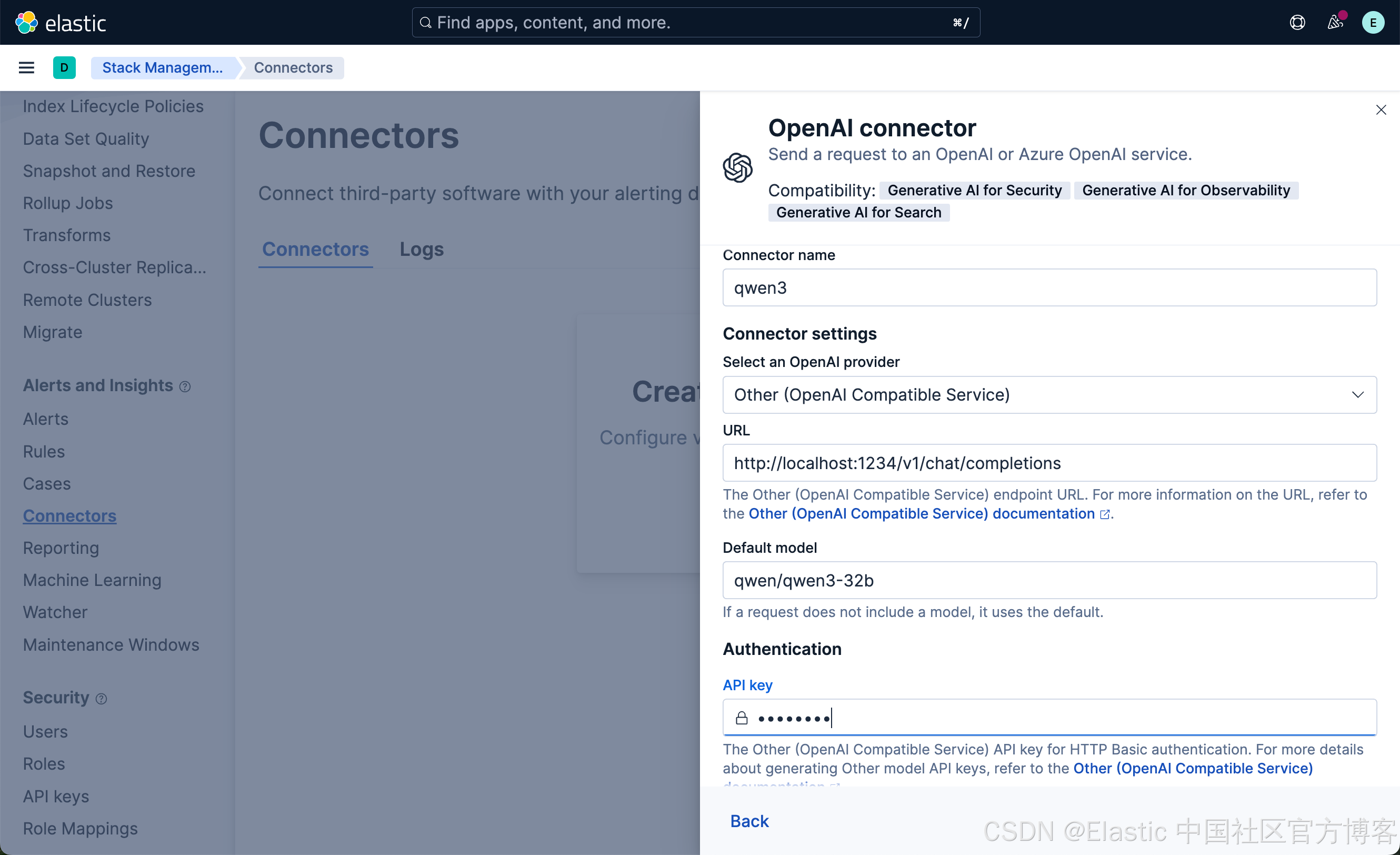
点击 Save 按钮:
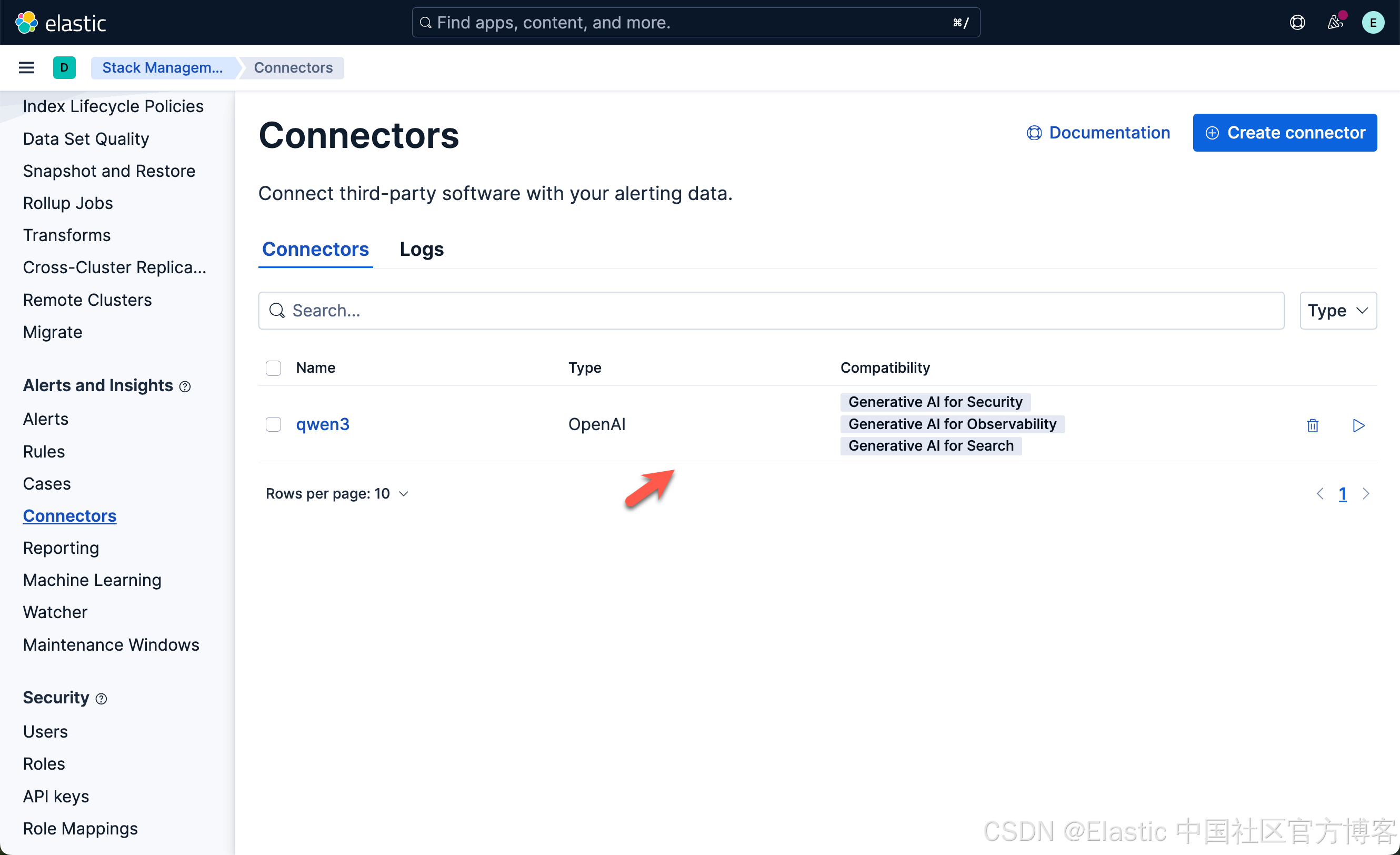
就这样,我们成功地创建了一个叫做 qwen3 的 OpenAI 连接器。
将嵌入向量的数据导入 Elasticsearch
如果你已经熟悉 Playground 并设置了数据,则可以跳至下面的 Playground 步骤,但如果你需要一些快速测试数据,我们需要确保设置了 _inference API。从 8.17 开始,机器学习分配是动态的,因此要下载并打开 e5 多语言密集向量,我们只需在 Kibana Dev 工具中运行以下命令即可。
GET /_inferencePOST /_inference/text_embedding/.multilingual-e5-small-elasticsearch
{"input": "are internet memes about deepseek sound investment advice?"
}如果你还没有这样做,这将触发从 Elastic 的模型存储库下载 e5 模型。在上面的安装部分,我们已经成功地部署了 es 模型,所以执行下面的命令时,不会触发下载模型。我们从右边的输出中可以看到文字被转换后的向量表示。
接下来,让我们加载一本公共领域的书作为我们的 RAG 上下文。这是从 Project Gutenberg 下载 “爱丽丝梦游仙境” 的地方:链接。将其保存为 .txt 文件。
$ pwd
/Users/liuxg/data/alice
$ wget https://www.gutenberg.org/cache/epub/11/pg11.txt
--2025-02-10 16:59:19-- https://www.gutenberg.org/cache/epub/11/pg11.txt
Resolving www.gutenberg.org (www.gutenberg.org)... 152.19.134.47
Connecting to www.gutenberg.org (www.gutenberg.org)|152.19.134.47|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 174357 (170K) [text/plain]
Saving to: ‘pg11.txt’pg11.txt 100%[=====================================>] 170.27K 304KB/s in 0.6s 2025-02-10 16:59:21 (304 KB/s) - ‘pg11.txt’ saved [174357/174357]等下载完文件后,我们可以使用如下的方法来上传文件到 Elasticsearch 中:
我们或者使用如下的方法:



选择刚刚下好的文件:
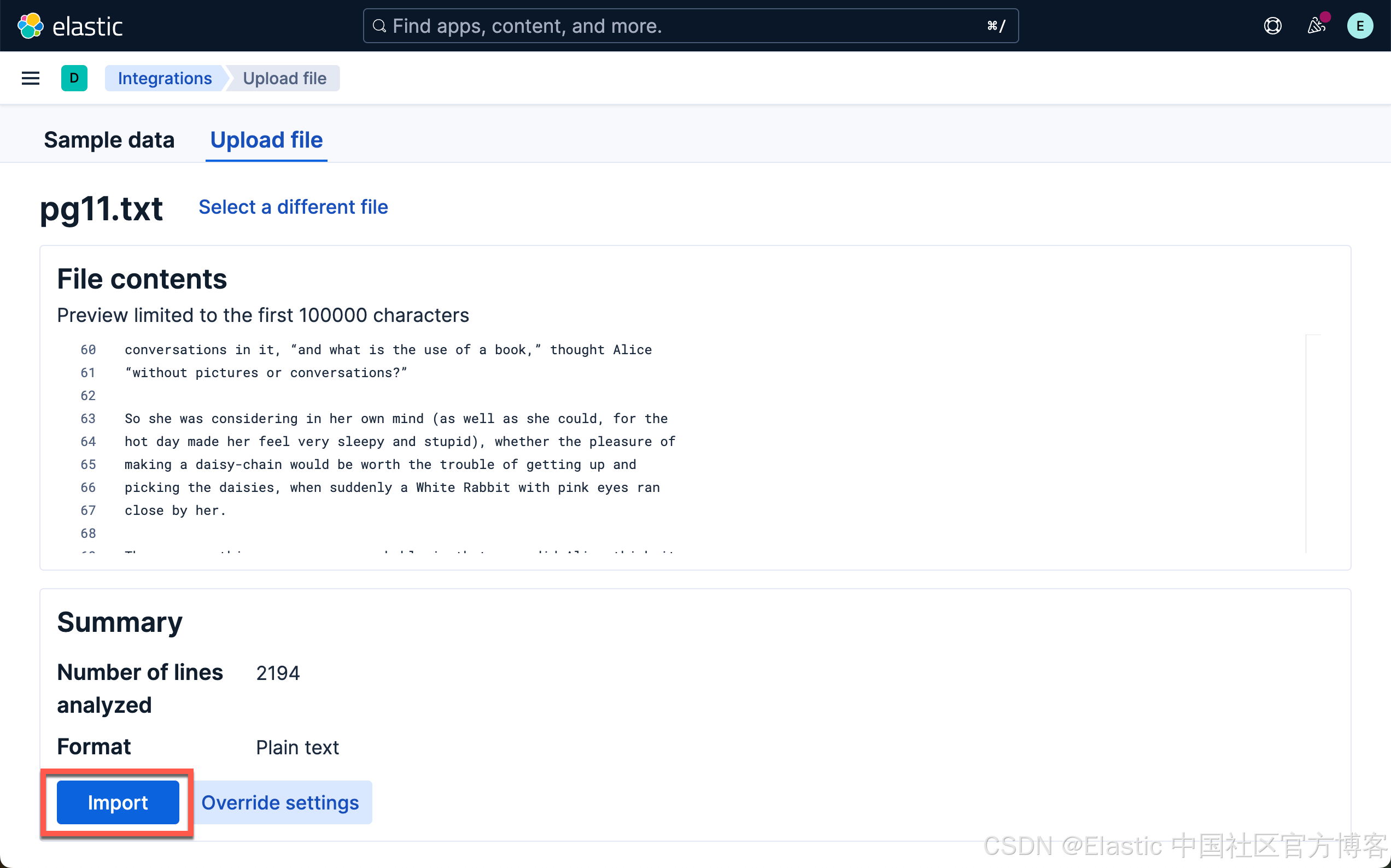
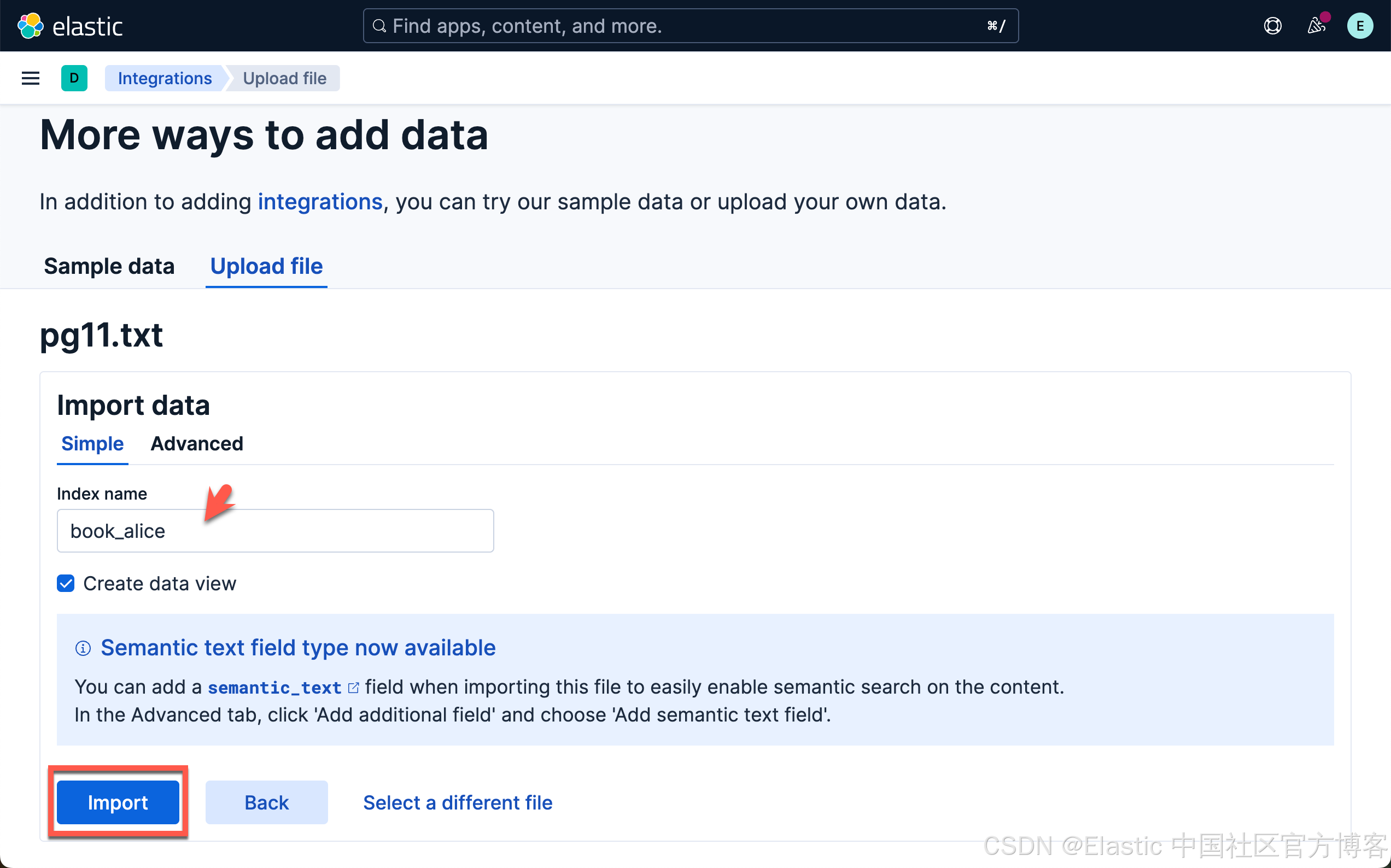
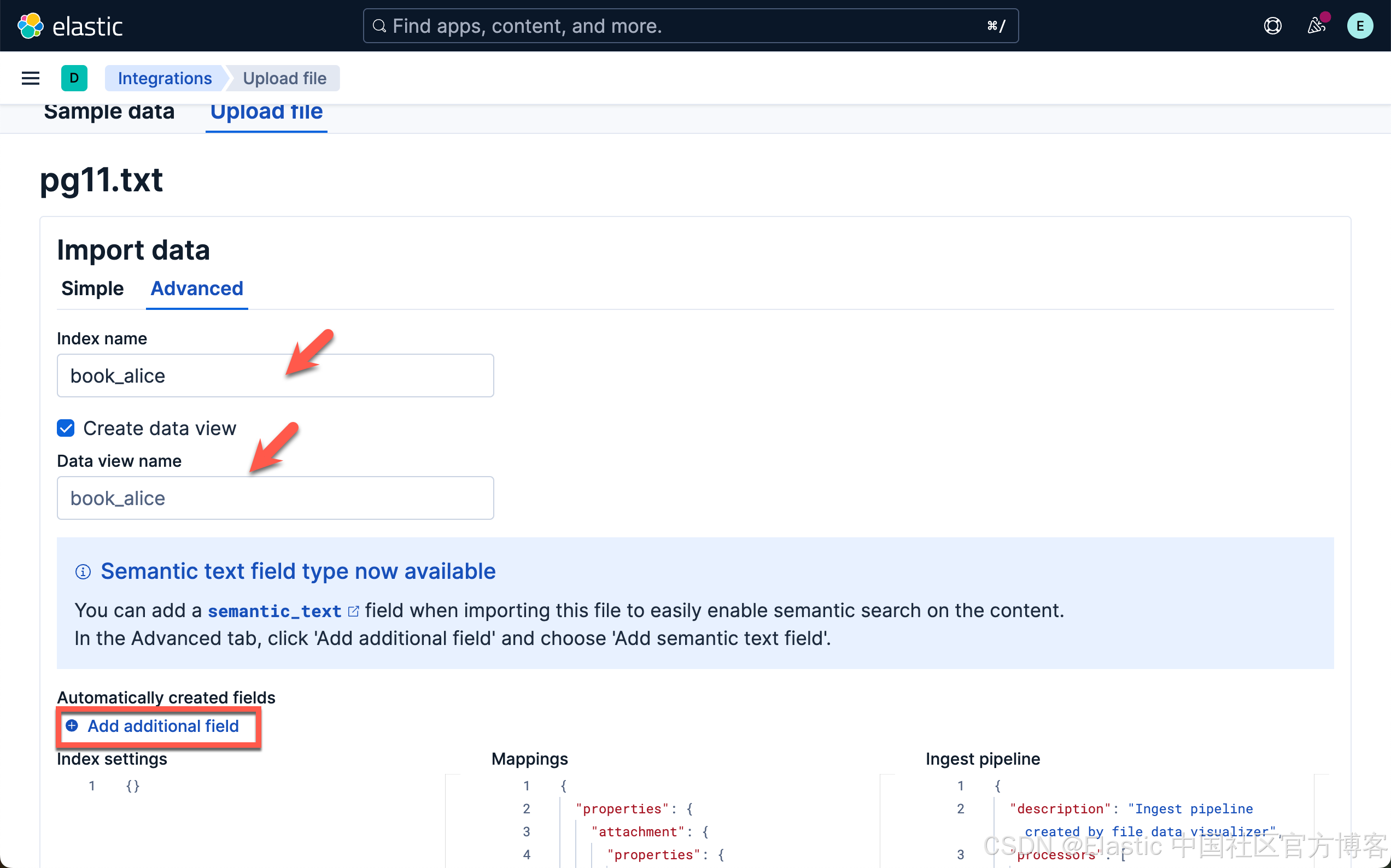
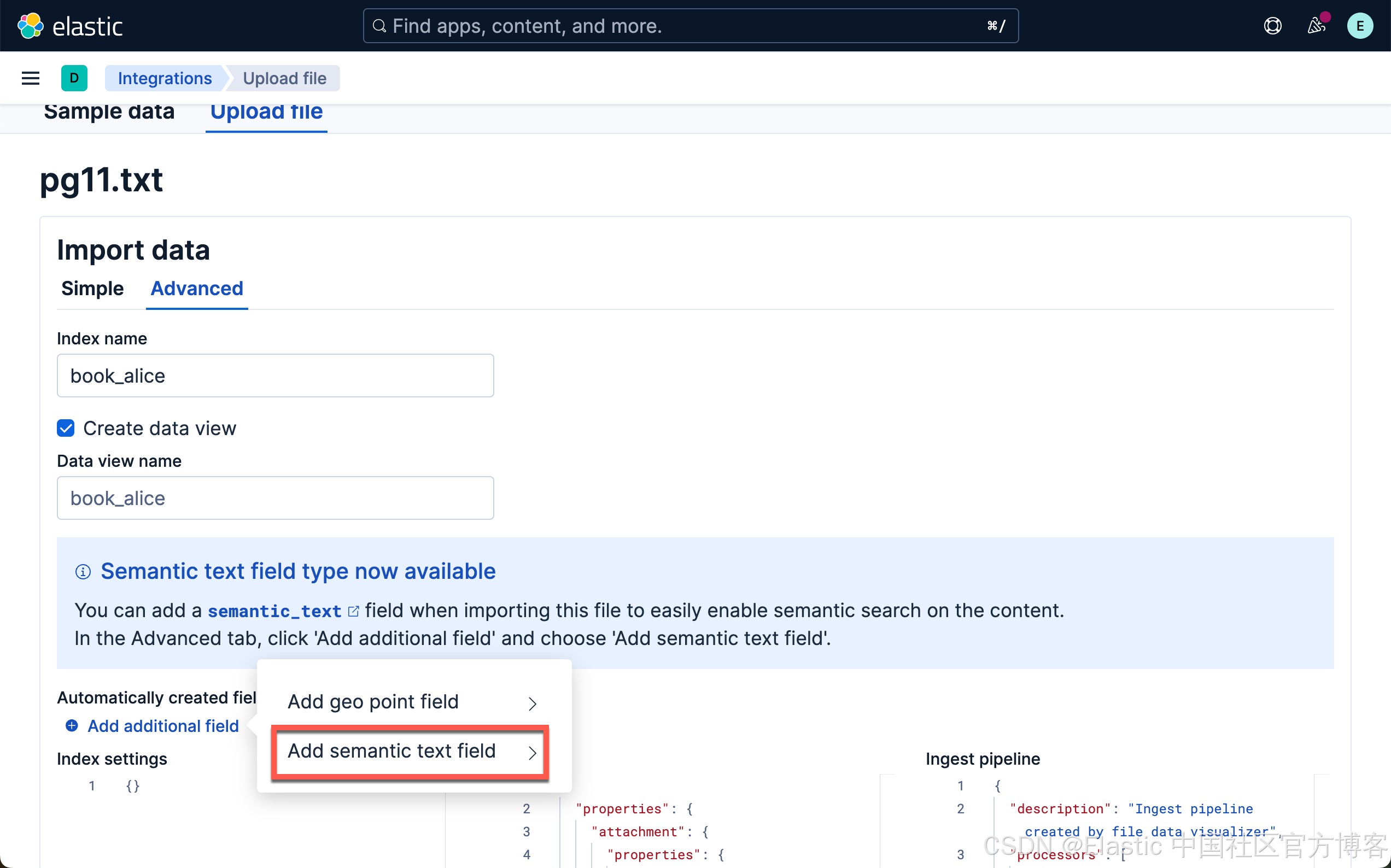
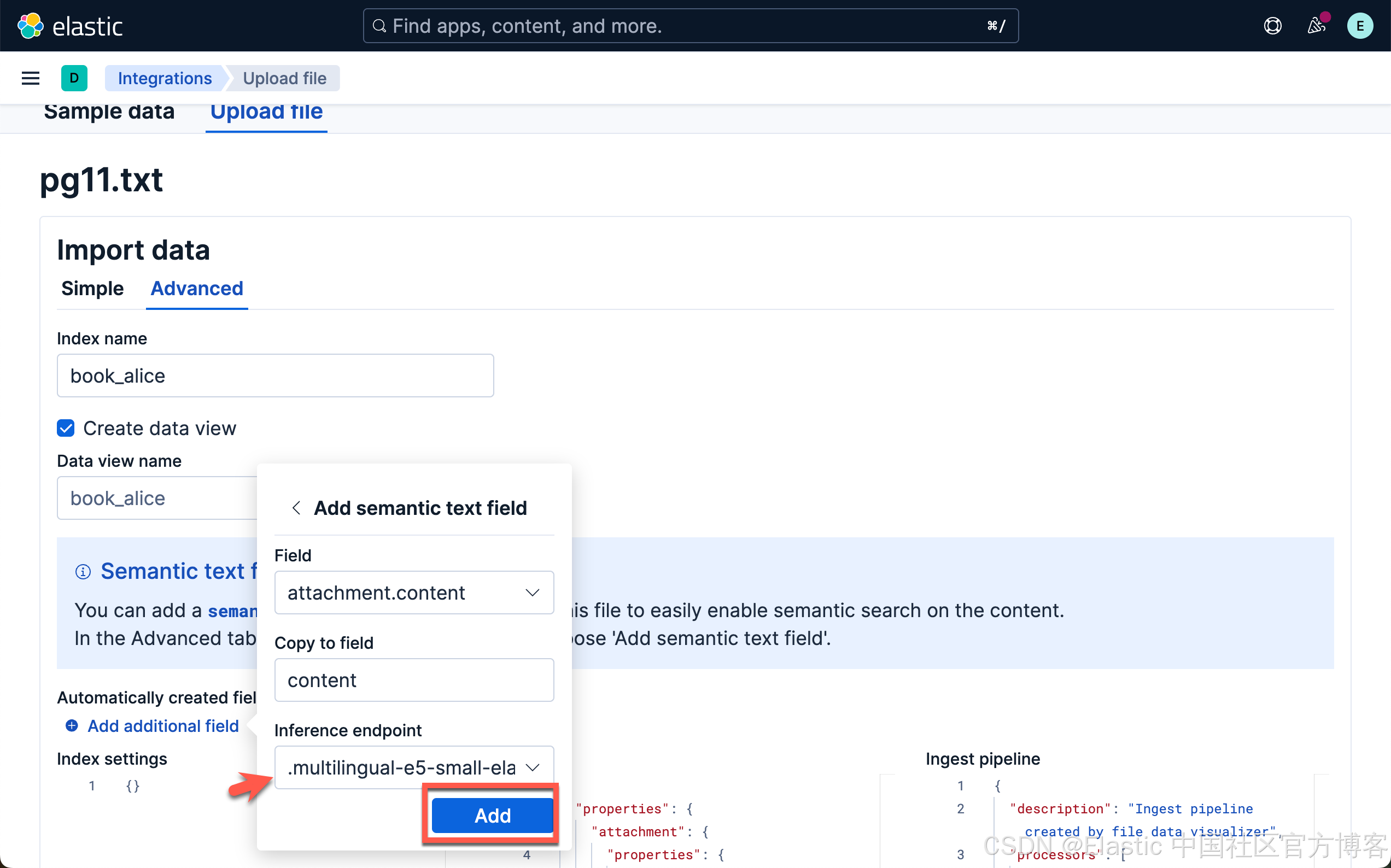
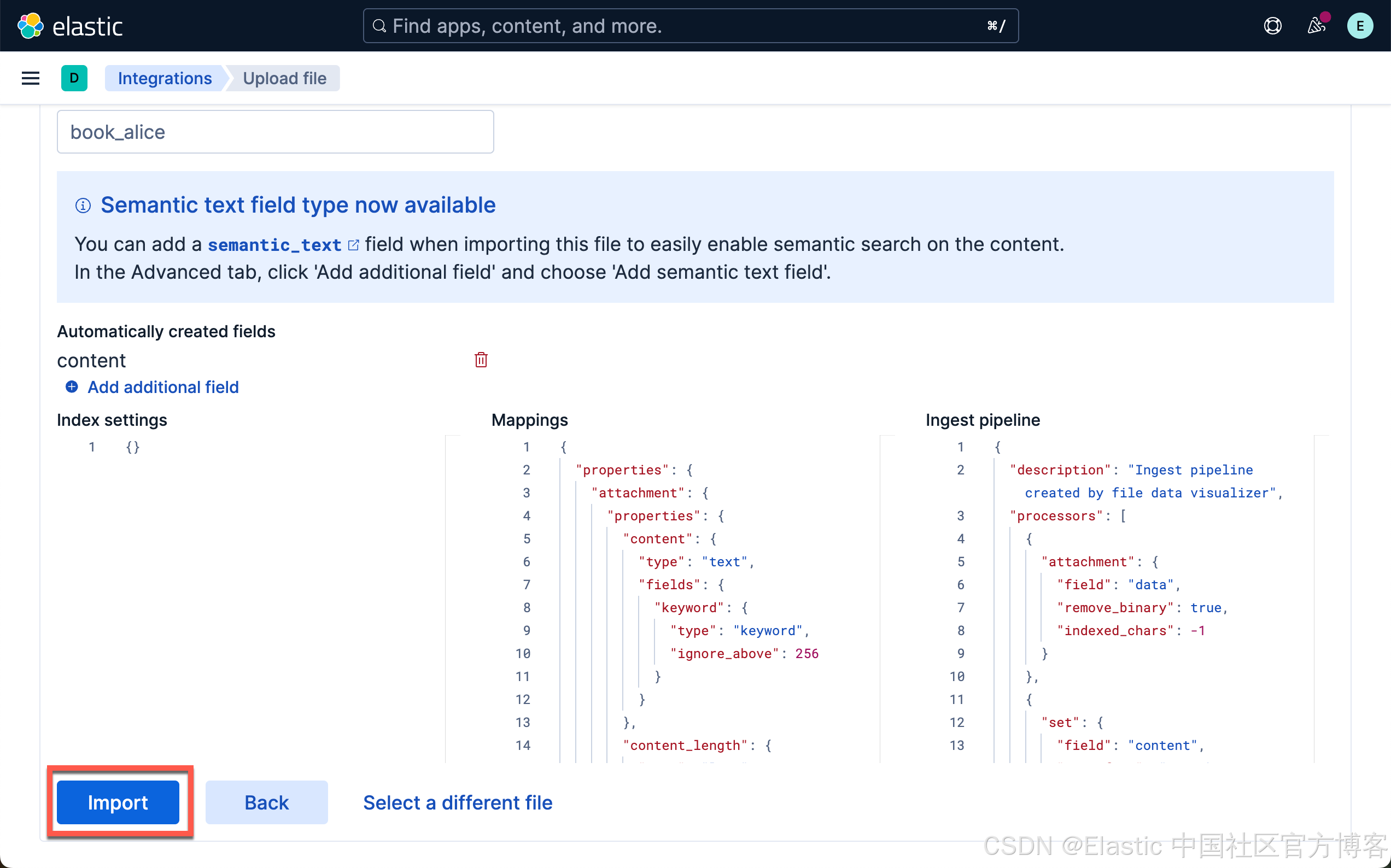
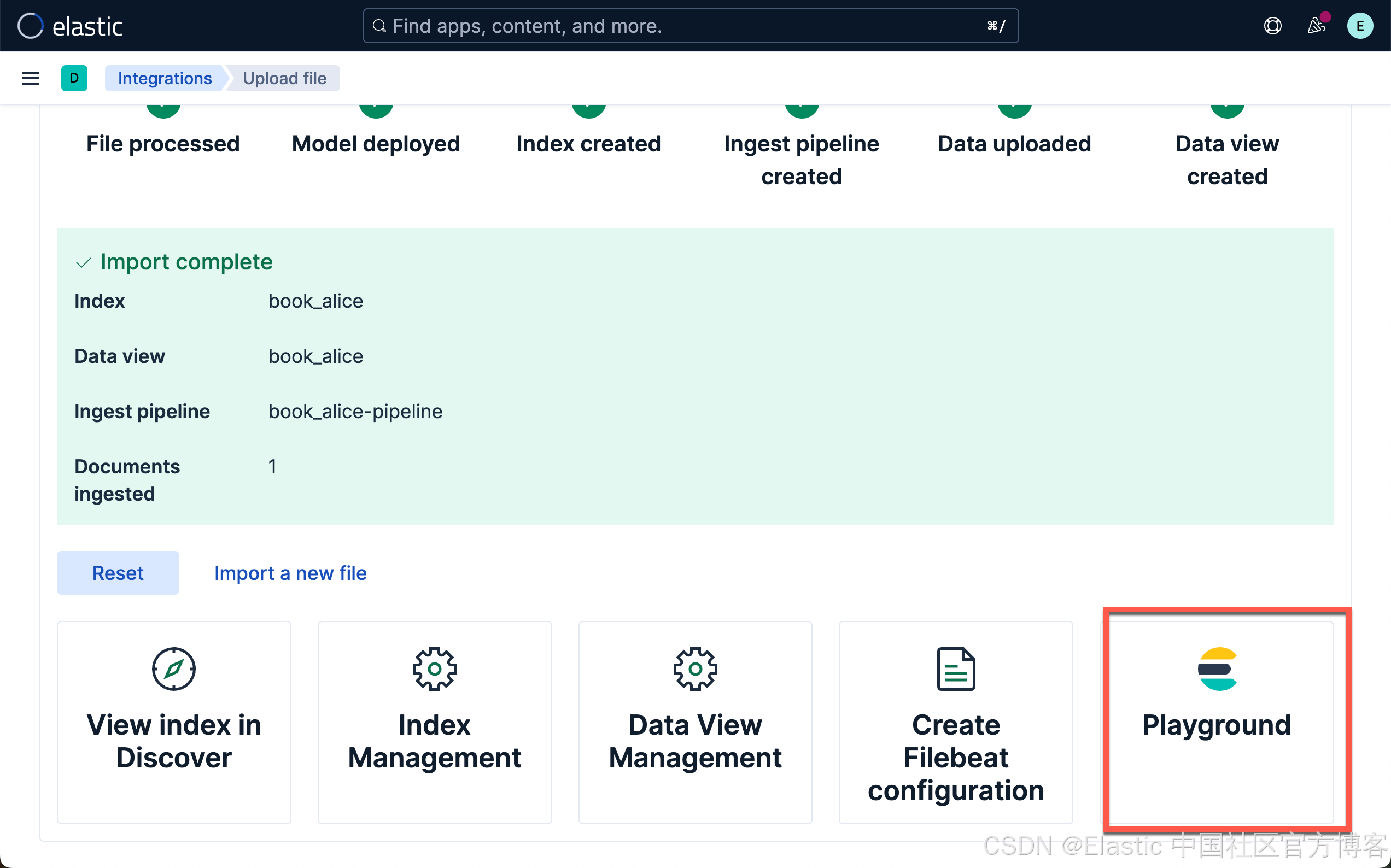
当加载和推理完成后,我们就可以前往 Playground 了。
在 Playground 中测试 RAG
在 Kibana 中导航到 Elasticsearch > Playground。可以在此处找到 Playground 的详细指南。
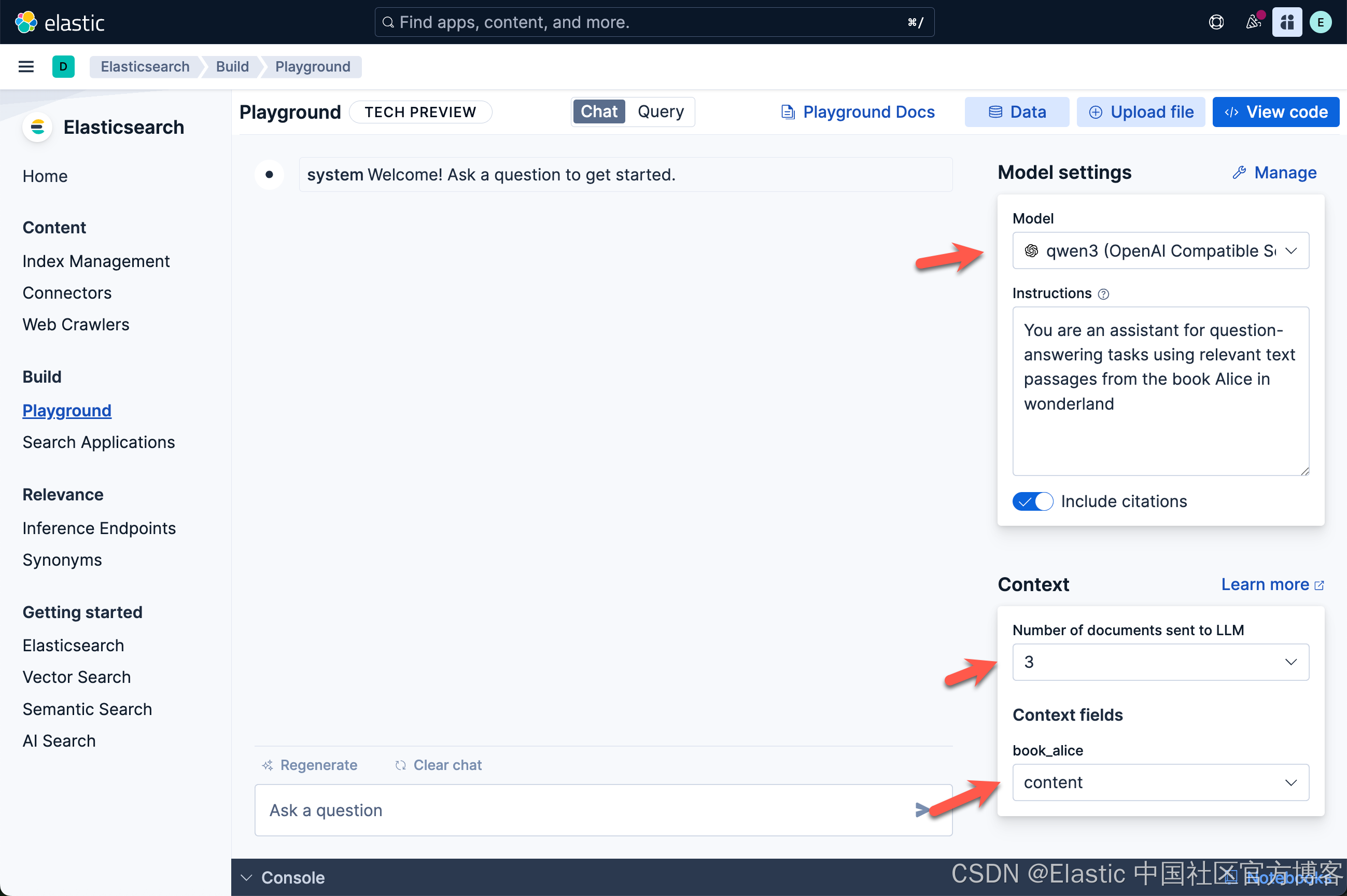
在我们的 Playground 设置中,我们输入了以下系统提示 “You are an assistant for question-answering tasks using relevant text passages from the book Alice in wonderland - 你是使用《爱丽丝梦游仙境》一书中的相关文本段落进行问答任务的助手”,并接受其他默认设置。
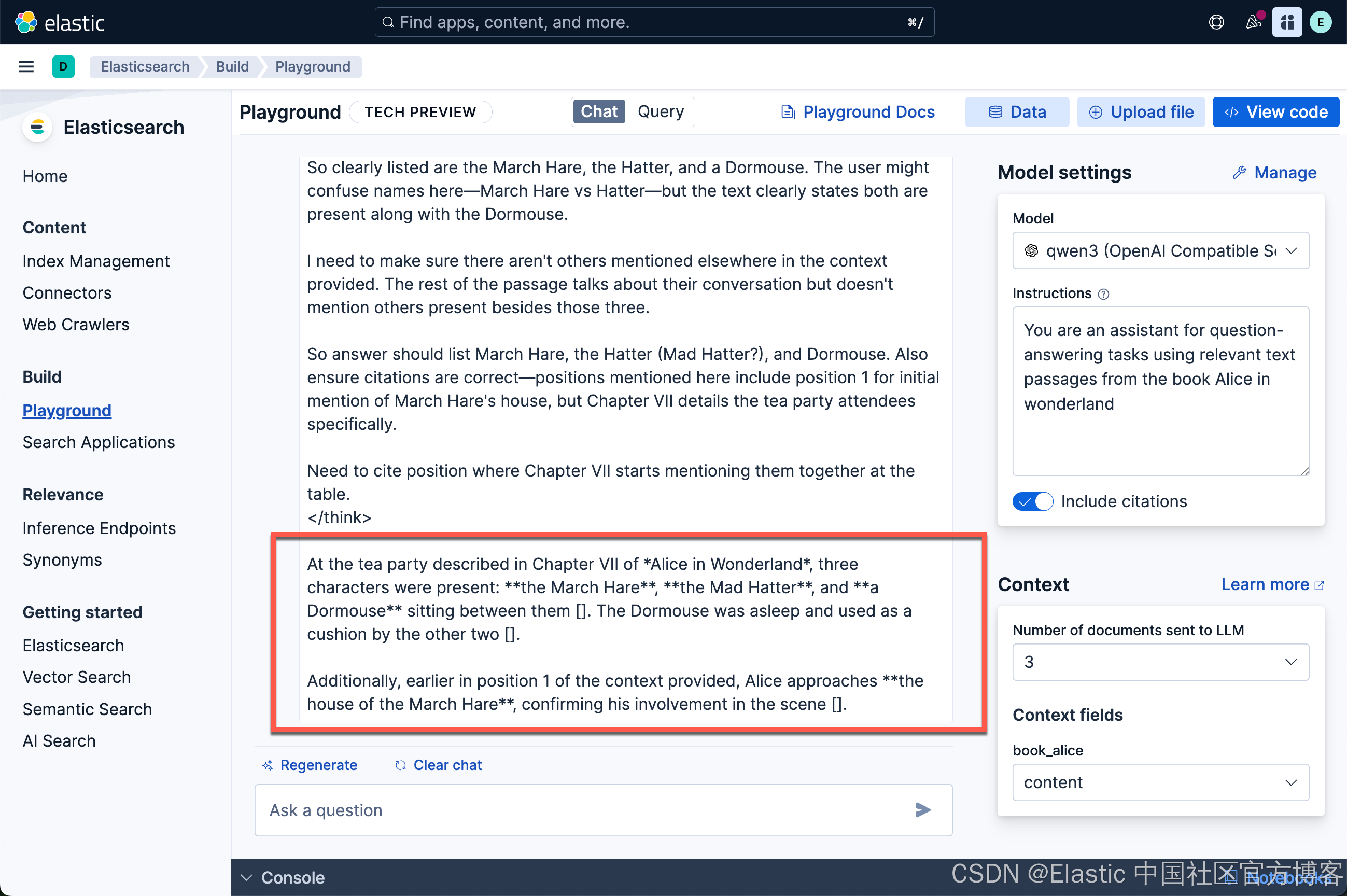
对于 “Who was at the tea party? - 谁参加了茶话会?”这个问题
我们尝试使用中文来提问:
谁参加了茶话会?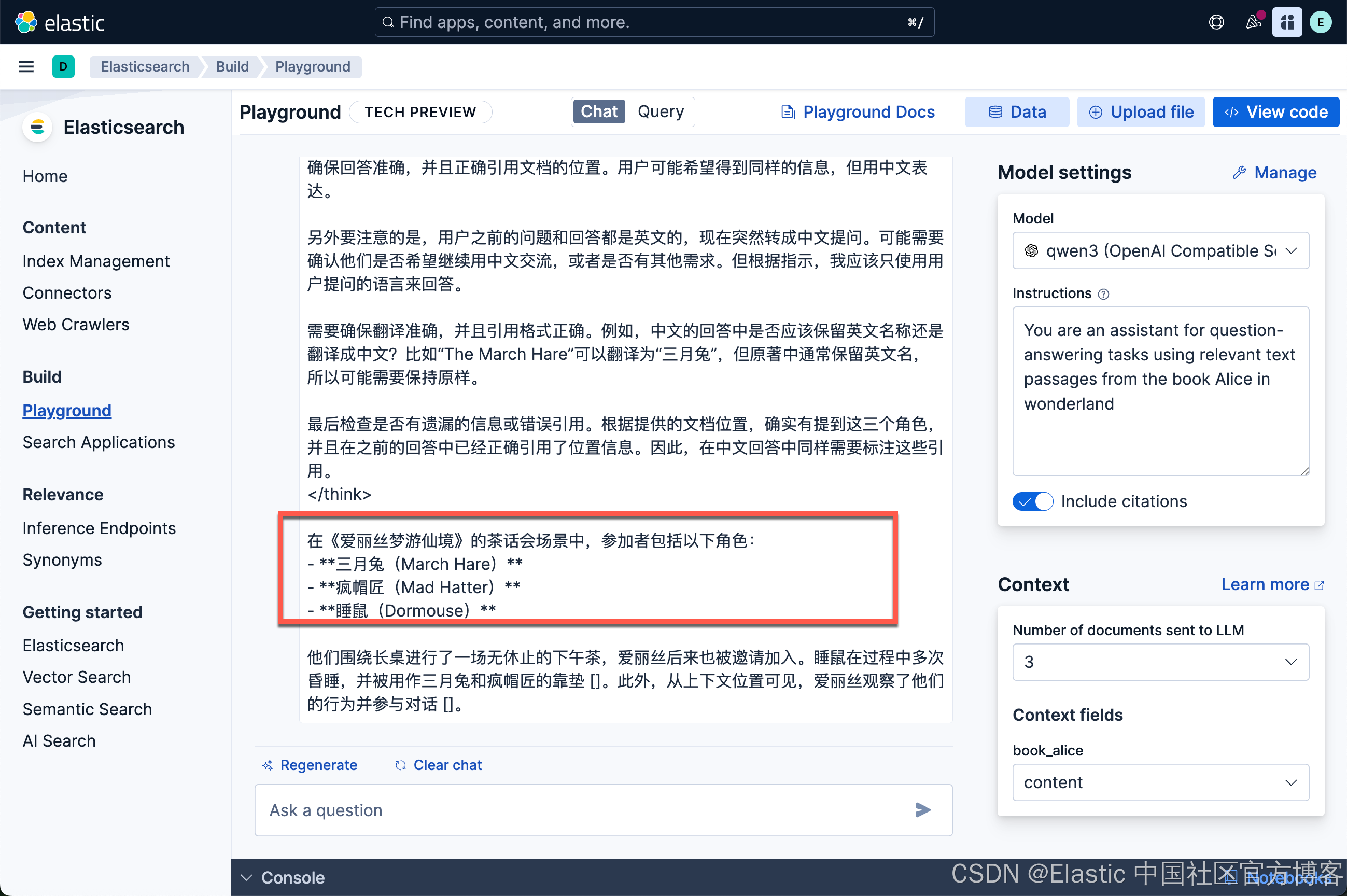
从上面的输出中我们看到了我们希望的答案。我们可以详细查看原文,在如下的位置可以看到我们想要的答案:

非常好! Qwen3 能够针对我们的英文和中文进行回答问题。 给出了我们想要的中文答案。
如果大家对如何使用代码来实现上述查询,你可以点击 Playground 的右上角的 View code 来得到一个初始的代码。然后我们可以做响应的修改。在这里我就不赘述了。对于感兴趣的开发者,可以参考我的另外一篇文章 “Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用” 来查看实现的方法。
祝大家学习 Qwen3 愉快!

)




先进技术)












