基于Flask实现的医疗保险欺诈识别监测模型
项目截图

项目简介
社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的重要手段。但是,有些人为了获得不当利益,利用各种途径收集医疗保险参保人员的医保卡,通过医保卡到医院进行虚假诊疗, 或通过编造病历、诊疗过程,套取医保基金,不仅危害社会,也让自己走上犯罪的道路,终是害人害己客户期望达到的效果。
(1)对给定的16000条数据集进行分析处理,并进行多维特征信息分析,提取出能够描述影响医疗保险欺诈的特征因子集合。
(2)利用特征因子的筛选成果,结合AI相关算法,构建医疗保险欺诈识别模型,经过训练后的模型可输出医疗保险欺诈的检测结果,并强调模型的准确性和可解释性。
(3)尝试从业务实践角度描述模型提供的业务价值,并结合领域知识探索、拓展和丰富系统的附加价值。
:
这是一个基于机器学习的医疗保险欺诈识别监测系统,旨在通过先进的数据分析和人工智能技术,有效识别和监测医疗保险中的欺诈行为。该系统具有以下特点:
-
数据处理能力:
- 支持3σ异常值处理
- 使用线性回归进行特征选择
- 采用PCA主成分降维
- 实现SMOTE过采样技术
- 支持交叉验证
-
核心功能:
- 数据上传和预处理
- 模型训练和评估
- 欺诈行为预测
- 可视化分析展示
-
技术特点:
- 基于Flask的Web应用
- 支持多种机器学习模型
- 提供友好的用户界面
- 实时预测和结果展示
启动教程
环境要求
- Python 3.x
- Flask
- pandas
- scikit-learn
- 其他依赖包(可通过requirements.txt安装)
安装步骤
- 创建虚拟环境:
python -m venv venv
- 激活虚拟环境:
- Windows:
venv\Scripts\activate
- Linux/Mac:
source venv/bin/activate
- 安装依赖:
pip install -r requirements.txt
运行应用
- 启动服务器:
python app.py
- 访问应用:
- 打开浏览器
- 访问
http://localhost:5000
使用说明
-
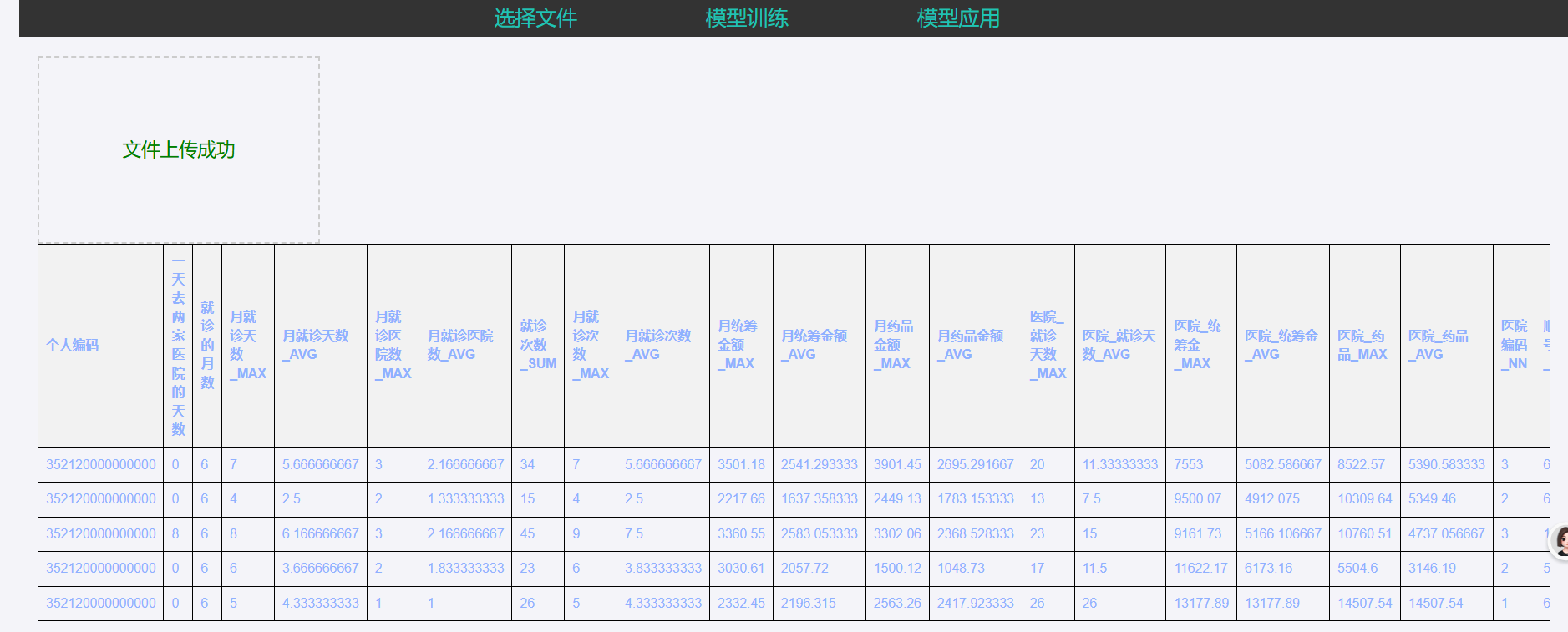
数据上传:
- 点击上传按钮
- 选择CSV格式的数据文件
- 系统会自动显示数据预览
-
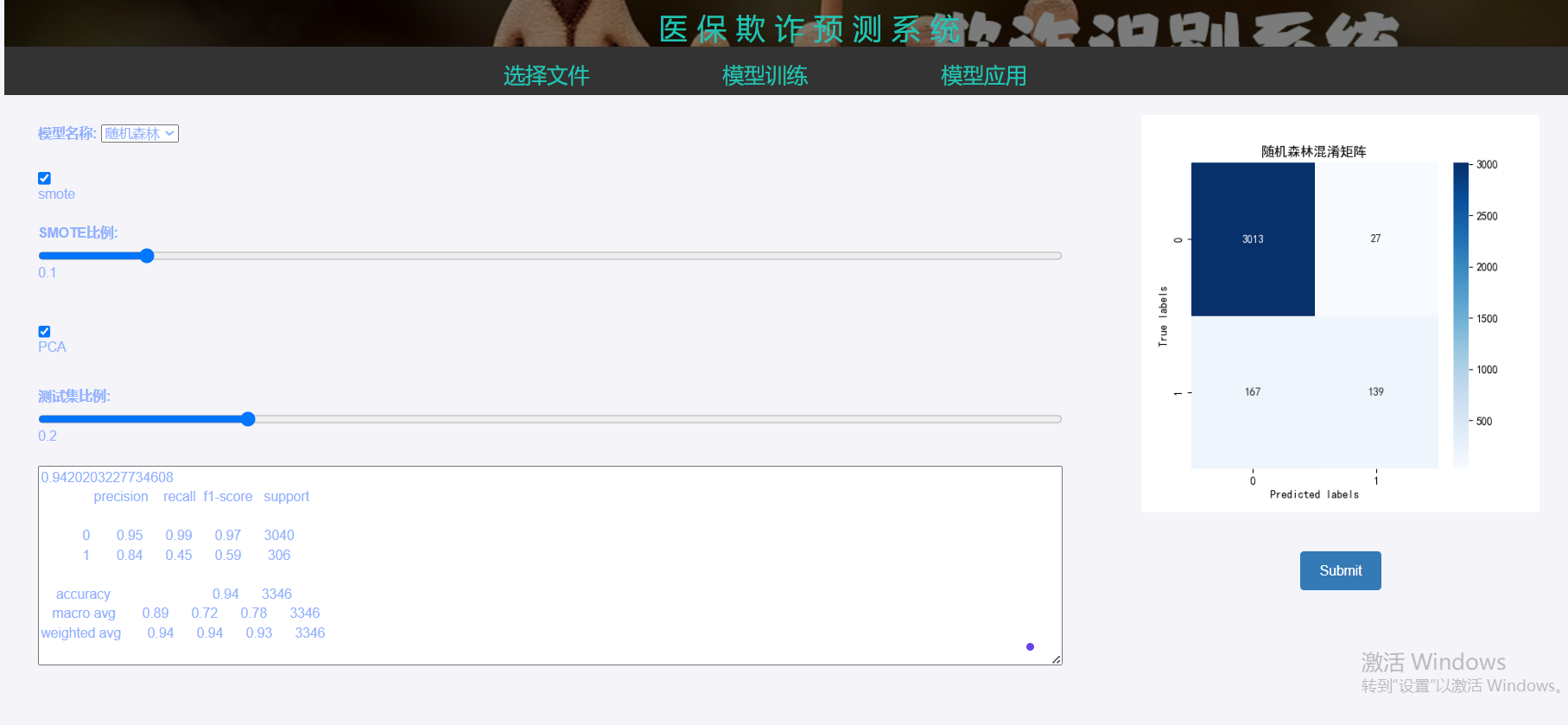
模型训练:
- 选择模型类型
- 配置训练参数(如SMOTE采样、PCA降维等)
- 点击训练按钮开始模型训练
-
预测分析:
- 输入待预测的数据
- 选择已训练的模型
- 获取预测结果
注意事项
- 确保上传的数据格式正确(CSV格式)
- 数据文件编码建议使用GBK
- 训练参数需要根据实际数据特点进行调整
- 预测结果仅供参考,建议结合人工审核
这个系统主要面向医疗保险行业,帮助提高欺诈识别的效率和准确性,为医保基金的安全保驾护航。












)





![【题解-洛谷】B4292 [蓝桥杯青少年组省赛 2022] 路线](http://pic.xiahunao.cn/【题解-洛谷】B4292 [蓝桥杯青少年组省赛 2022] 路线)
:MySQL数据存储的揭秘)