一、OCI
名为OCI,全称 Open Container Initiative/开放容器倡议,其目的主要是为了制定容器技术的通用技术标准。目前主要有两种标准:
1、容器运行时标准 (runtime spec)
2、容器镜像标准(image spec)
二、docker的架构
1、组成
docker1.11版之后由单体分为了5大组成部分(解耦)
1、docker-client:客户端命令
2、dockerd守护进程:全称docker daemon,主要提供客户端命令接口,
3、containerd服务:
containerd独立负责容器运行时的生命周期(如创建、启动、停止、暂停、信号处理、删除),其他一些比如镜像构建、存储卷管理、日志操作都是dockerd(docker daemon)的一些模块管理
4、containerd-shim:
该进程由containerd服务创建
每创建一个容器,都会启动一个containerd-shim进程,然后由该进程调用runc来具体创建容器
5、runc:
最早期docker只是把Runc单拿出来捐赠给了OCI来作为容器运行时的标准,
即runc造出来的容器自然就符合OCI标准,使用runc创造出来的就是一个符合oci规范的标准容器
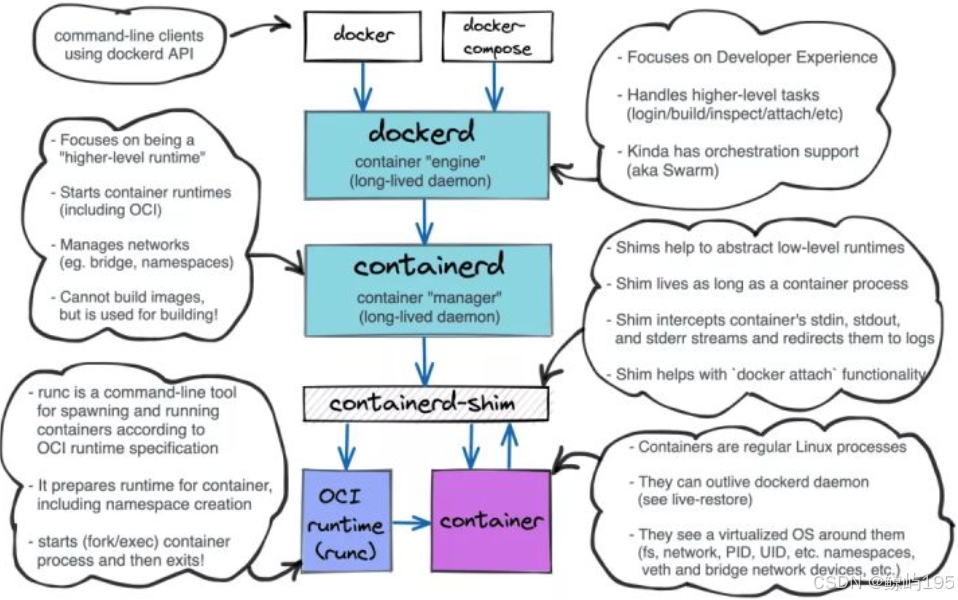
2、为何需要有containerd-shim
- Runc创建出的容器需要依赖于某个进程或服务,如果容器直接依赖于containerd服务那意味着,一台机器上启动的多个容器都统一依附于containerd
- 一旦containernd退出,该主机上的所有容器都跟着一起退出了
于是引入了containerd-shim进程这种设计,由该进程调用runc来创建容器,容器创建出来之后就依赖于该进程
并且该进程虽然是由containerd服务创建的,但是containerd-shim进程是1号进程的父进程
即containerd只负责创建containerd-shim这个进程,创建出来之后containerd-shim进程就与containerd服务无关了
所以说,此时containerd服务挂掉了,根本影响不到containerd-shim进程
containerd-shim进程作为容器的依赖它不出问题就影响不到容器
ps:live-restore就是基于该设计而来。
3、containerd、containerd-shim及容器进程的关系
层级:
dockerd服务
containerd服务
containerd-shim进程---》runc(只是一个功能,造完容器就消失)--->容器的1号进程
containerd-shim进程---》runc--->容器的1号进程
containerd-shim进程---》runc--->容器的1号进程
依赖关系:
dockerd服务没有依赖,它爹是1号进程
containerd服务没有依赖,它爹是1号进程
chontainerd-shim是由containerd创建的,但是containerd-shim它爹是1号进程,
强调:
containerd创出出containerd-shim进程之后,这个shim进程与containerd就无关了
所以containerd-shim也没有依赖
容器内的1号进程是有依赖,依赖于containerd-shim
1、容器内的1号进程的父进程是containerd-shim,容器一旦结束,进入僵尸进程状 态,会由containerd-shim来负责回收
2、容器的一些如stdin、fd等都需要依赖于containerd-shim管理
所以containerd-shim一旦结束,容器就跟着一块完蛋了
4、runtime
runtime翻译为容器运行时,指的就是用来管理镜像或者容器的服务端软件
runtime分为两大类
- high-level runtime:比如docker、containerd、podman等,支持更多高级功能(如镜像管理和gRPC / Web API),对于高级别运行时来说,他们是通过调用低级别运行时来管理容器(可以简单的理解为高级别是在低级别基础上的上层封装),一般可以是runc作为低级别运行时
- low-level runtime: 比如lxc、runc、gvisor、kata等,只涉及到容器运行的一些基础细节,比如namespace创建、cgroup设置
通常提到的都是低等级的runtime
containerd------是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性,containerd 可以负责干下面这些事情:
- 管理容器的生命周期(从创建容器到销毁容器)
- 拉取/推送容器镜像
- 存储管理(管理镜像及容器数据的存储)
- 调用 runc 运行容器(与 runc 等容器运行时交互)
- 管理容器网络接口及网络
三、k8s与docker
- 1.20版本之后k8s可以找直接和containerd通信,1.20开始放弃docker支持,containerd已经由docker的一部分演变为一个独立的组件,可以对接多种服务
- 从 k8s 的角度看,选择 containerd作为运行时的组件,它调用链更短,组件更少,更稳定,占用节点资源更少
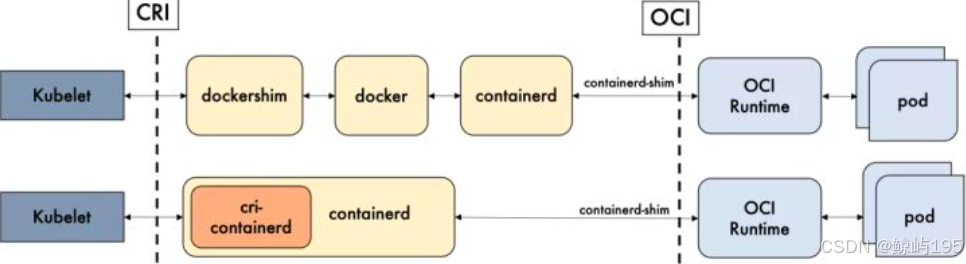
- k8s不能直接与docker通信,只能与CRI运行时通信,要与 Docker 通信就必须使用桥接服务(dockershim)
- docker比k8s发布的早,Dockershim -直都是 Kubernetes 为了兼容 Docker 获得市场采取的临时产案(决定)
- k8s在过去因为 Docker 的热门而选择它,现在又因为高昂的维护成本而放弃它,对于已经统治市场的k8s来说,Docker的支持显得非常鸡肋,移除代码也就顺理成章
- 在集群中运行的容器运行时往往不需要docker这么复杂的功能,k8s需要的只是 CRI 中定义的那些接口
- 对于正式生产环境还是建议采用兼容CRI的containerd之类底层运行时。
四、docker中的cpu与gpu
定义
cpu:擅长逻辑控制,串行运算,cpu就好像一个老教授,老教授的特点是啥数学题都能算
gpu:擅长大规模的并发计算机,gpu就好像是一群只会算简单的加减法的小学生
要想启动一个容器使用gpu需要具备哪些条件:
1、宿主机上必须插一块gpu卡
2、宿主机上需要为该gpu卡安装驱动程序
3、安装官方的容器引擎,例如docker容器引擎
4、配套安装一个nvidia-container-runtime(对runc的扩展)
5、启动容器采用参数--gpus指定启动gpu,
或者修改配置文件把默认的runc替换为nvidia-container-runtime这样就不用加--gpus参数启动,容器默认都能访问gpu
强调:容器环境内必须有cuda环境才行(有cuda环境容器内的系统才能调用GPU)cuda 编程模型
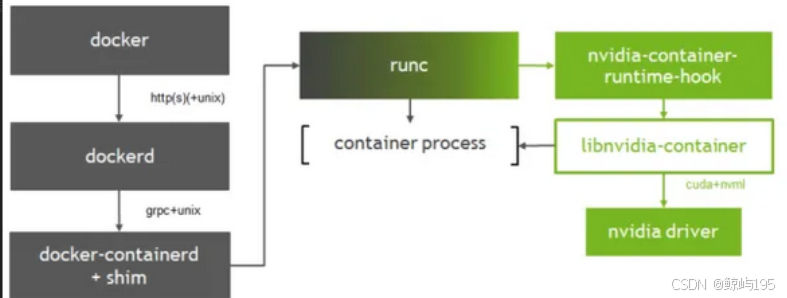
- 创建容器:docker -> dockerd-> containerd-> containerd-shim->runc-> container-process
- 创建GPU容器:docker-> dockerd-> containerd-> containerd-shim->nvidia-container-runtime -> nvidia-container-runtime.hook -> libnvidia-container-> runc-> container->process
实现
docker19.03之前还需要安装nvidia-docker,之后只用安装nvidia-container-runtime即可使用
#下载对应GPU驱动#安装nvidia-container-runtime
#在https://nvidia.github.io/nvidia-container-runtime/查看并添加源并直接安装
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-runtime.repo
sudo yum install nvidia-container-runtime#检查安装
docker run --help | grep -i gpus--gpus gpu-request GPU devices to add to the container ('all' to pass all GPUs)#强调采用的镜像里必须包含cuda
docker run -it --rm --gpus all nvidia/cuda:9.0-base nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |#操作
所有显卡都对容器可见:
docker run --gpus all --name 容器名 -d -t 镜像id
只有显卡1对容器可见:
docker run --gpus="1" --name 容器名 -d -t 镜像id如果不指定 --gpus ,运行nvidia-smi 会提示Command not found注意:
1. 显卡驱动在所有方式中,都要先安装好,容器是不会有显卡驱动的,一台物理机的显卡只对应一个显卡驱动,当显卡驱动安装好后(即使未安装cuda),也可以使用命令nvidia-smi
2. nvidia-smi显示的是显卡驱动对应的cuda版本,nvcc -V 显示的运行是cuda的版本
启动容器时,容器如果想使用gpu,镜像里必须有cuda环境,就是说,针对想使用gpu的容器,镜像在制作时必须吧cuda环境打进去下面三个参数代表的都是是容器内可以使用物理机的所有gpu卡--gpus allNVIDIA_VISIBLE_DEVICES=all--runtime=nvidaNVIDIA_VISIBLE_DEVICES=2 只公开两个gpu,容器内只能用两个gpu举例如下:
# 使用所有GPU
$ docker run --gpus all nvidia/cuda:9.0-base nvidia-smi# 使用两个GPU
$ docker run --gpus 2 nvidia/cuda:9.0-base nvidia-smi# 指定GPU运行
$ docker run --gpus '"device=1,2"' nvidia/cuda:9.0-base nvidia-smi
$ docker run --gpus '"device=UUID-ABCDEF,1"' nvidia/cuda:9.0-base nvidia-smi

![[密码学实战]C语言使用SDF库构建国密算法RESTful服务(五)](http://pic.xiahunao.cn/[密码学实战]C语言使用SDF库构建国密算法RESTful服务(五))

![push [特殊字符] present](http://pic.xiahunao.cn/push [特殊字符] present)

)









: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)


