概叙
实战:Java web应用性能分析之【Arthas性能分析trace监控后端性能】-CSDN博客
在优化方面,可以采取以下步骤:
- 性能分析工具:使用Arthas或Async Profiler进行实时诊断,定位耗时的方法调用。这可以帮助精确找到瓶颈所在,而不是仅依靠日志推测。
- 优化JSON处理:检查请求体和响应体的数据大小,优化DTO结构,移除不必要的字段。同时,可以切换为更高效的序列化库,比如替换默认的Jackson为Fastjson,或者调整Jackson的配置以提升性能。
- 连接池预热:在应用启动时主动初始化数据库连接,避免首次请求时建立连接的耗时。这在之前的回答中已经提供了MyBatis的预热方法,用户可以参考实施。
- JVM预热:通过模拟请求触发JIT编译。
- 缓存预热:启动时加载高频数据到缓存。
- 懒加载优化:将部分初始化移到启动阶段。
- 异步日志记录:确保日志记录是异步的,避免同步写日志阻塞请求处理。使用Logback或Log4j2的异步Appender配置,将日志写入队列后由后台线程处理。
- 事务优化:检查Service方法的事务配置,确保@Transactional注解的范围合理,避免在事务中包含非数据库操作。对于只读操作,可以设置readOnly=true以提升性能。
- 精简拦截器逻辑:审查所有Filter和Interceptor的实现,移除不必要的操作,特别是避免在Filter中进行复杂的计算或同步IO操作。确保这些组件的逻辑尽可能高效。
关键优化点总结
- 缓存预热:启动时主动加载高频数据,避免首次查询穿透数据库。
- 连接池预热:初始化时建立最小空闲连接,减少首次SQL延迟。
- JVM预热:通过模拟请求触发JIT编译,加速热点方法。
- 批量操作:合并单次插入为批量操作,减少事务开销。
- DTO转换优化:用MapStruct生成编译期代码,替代反射拷贝。
本文主要介绍了Log4j2框架的核心原理、实践应用以及一些实用的小Tips,力图揭示Log4j2这一强大日志记录工具在现代分布式服务架构运维中的关键作用。
一、 背景
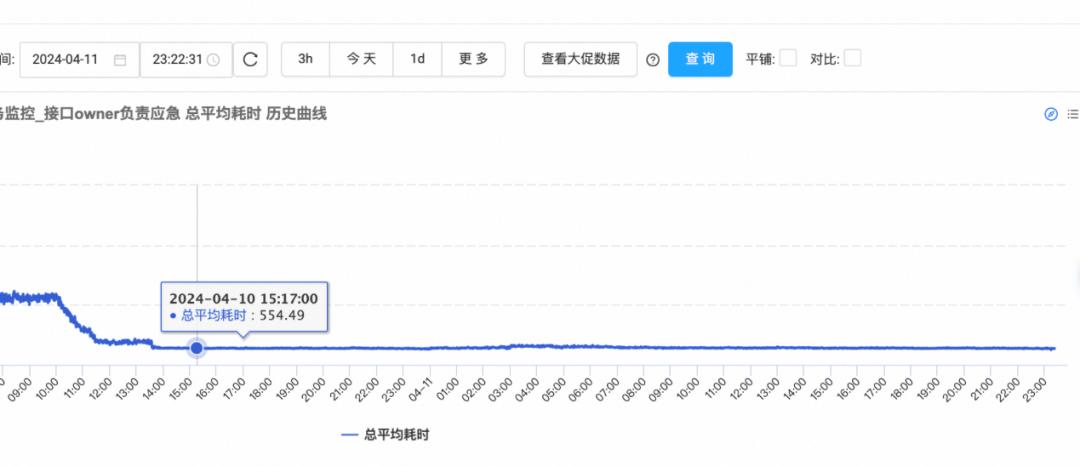
2024年4月的一个宁静的夜晚,正当大家忙完一天的工作准备休息时,应急群里“咚咚咚”开始报警,提示我们余利宝业务的赎回接口成功率下降。
通过Monitor监控发现,该接口的耗时已经超过了网关配置的超时阈值(2s),我们临时调整超时阈值止血后,就在排查问题的根因。具体排查过程不是我这篇文章的重点,故忽略,但最终我们发现最近上线新加的相邻两行的日志中,时间相差近1.5s,难道这就是问题的根源吗?
后来,我们去掉了这两行日志后紧急发布,事实证明我们的思路是对的。
紧急发布后,该接口的耗时由之前的2s左右,优化到了600ms左右。后来我们分析发现:该接口在打印日志时,由于要实现日志脱敏,故在Logger.info入口处实现了脱敏功能,但是大日志脱敏比较耗时,从而导致该接口的同步调用耗时激增到1.5s左右(后面我们会说如何解决这个问题)。我的天呐,一行日志竟是性能优化的金钥匙!!!
但这里有一个问题,我们是去掉了日志的打印,侵入了业务,同时该应用还是用的log4j的日志框架,log4j原生框架是不支持日志异步化的,因此要从根本上业务无侵入的解决因日志而导致的性能问题,需要熟悉log4j2的框架原理。
二、原理
2.1 Log4j2的优势
-
性能: Log4j2使用基于Lambda的异步记录器,显著提高了日志记录的速度,减少了日志操作对应用性能的影响。相比之下,Logback虽然也支持异步记录,但实现上不如Log4j2高效。通过减少对象创建、高效的字符串处理和池化技术,Log4j2在高并发场景下表现更佳。
-
配置灵活性: 支持多种配置方式,包括XML、JSON、YAML、properties文件,甚至编程式配置,提供更大的灵活性。动态重新配置能力,允许在不重启应用的情况下修改日志配置。
-
插件架构: Log4j2采用插件架构,几乎所有组件(如Appenders、Layouts、Filters)都是可插拔的,易于扩展和自定义。内置丰富的插件库,开箱即用,简化集成过程。
-
内存和资源管理: 更高效的内存管理,减少内存泄漏的风险,尤其是在大量日志输出时。支持垃圾回收友好的设计,比如基于Disrupter的RingBuffer等数据结构减少GC压力。
-
可靠性: 强大的故障恢复机制,如重试和备用Appenders,确保日志能够被记录下来,即使主要的日志输出目的地不可用。
-
先进的特性:
-
-
支持条件日志记录(Conditionals),可以根据运行时条件决定是否记录日志。
-
自动重新加载配置文件变化,无需重启应用。
-
支持JMX监控和管理日志系统状态。
-
-
与SLF4J的集成:虽然这不是特有优势,但Log4j2提供了与SLF4J(Simple Logging Facade for Java)的良好集成,使得从其他日志框架迁移更加平滑。
总的来说,Log4j2的设计更现代化,强调高性能、易用性和灵活性,特别是在大规模分布式系统和高性能应用中表现突出。而Logback和Log4j 1.x虽有各自的优点,但在这些方面逐渐显得力不从心。至于Java Util Logging (JUL),它是Java标准库的一部分,但功能相对基础,配置和扩展性不如Log4j2和Logback灵活。
2.2 Log4j2的结构
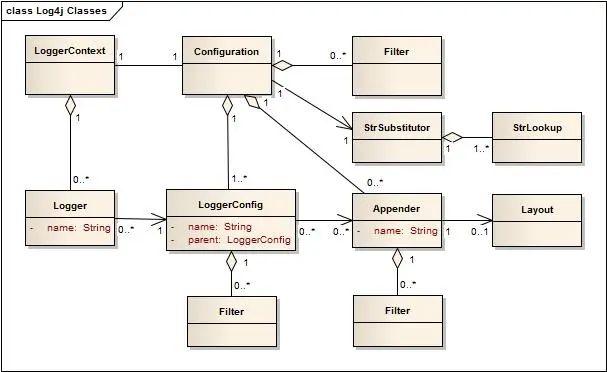
Log4j2的结构主要包括以下几个核心组件:
-
Logger: 这是开发者直接使用的接口,用于记录不同级别的日志信息(如DEBUG, INFO, ERROR等)。每个Logger都有一个名称,并且支持继承性,形成一个名为Logger Hierarchy的树状结构,根Logger的名称为"root"。
-
LoggerContext: 是日志系统的上下文环境,管理着一组Logger实例以及它们的配置。每个应用程序通常只有一个LoggerContext,但它支持多个上下文以实现更细粒度的控制。
-
Configuration: 每个LoggerContext都关联一个有效的Configuration,定义了日志的输出目的地(Appenders)、日志的过滤规则(Filters)、日志的格式化方式(Layouts)等。Configuration可以通过配置文件(如XML、JSON、properties)或编程方式动态加载。
-
Appender: 负责将日志事件发送到指定的目标,如控制台(Console)、文件(File)、数据库、网络Socket等。
-
Layout: 定义了日志信息的格式化方式,如模式字符串(Pattern String)决定了日期、时间、日志级别、线程名、日志信息等内容的排列和格式。
-
Filter: 可以在日志事件从Logger传递到Appender的过程中进行过滤,根据特定条件决定日志是否被输出。
-
Lookup: 提供动态值解析机制,如${ctx:variable}可以在日志中插入上下文变量的值。
那么,Log4j2的日志是怎么将日志输出到文件/数据库/控制台等地方的?
2.3 Log4j2日志输出流程
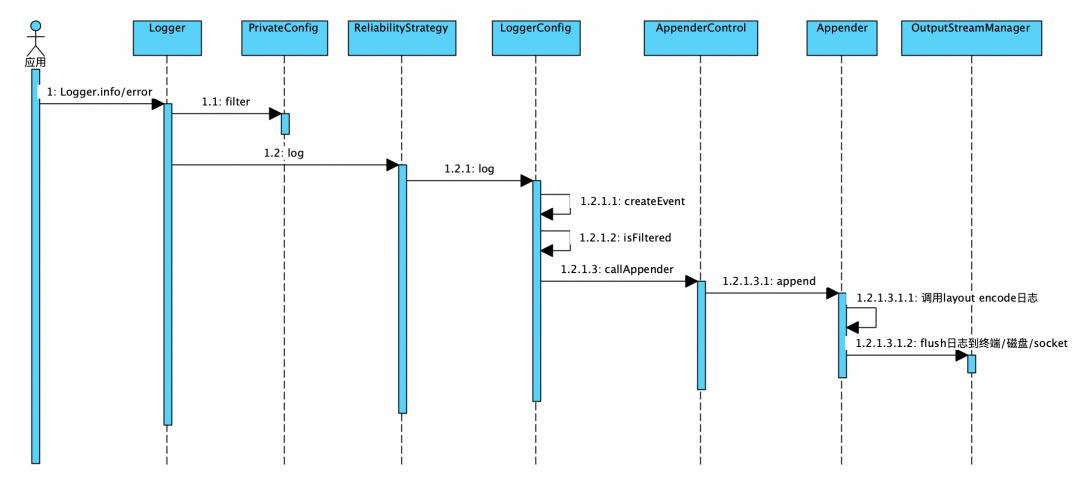
关键步骤源码分析:
1. 1.1主要是针对日志级别Level和指定的全局Filter组件进行过滤
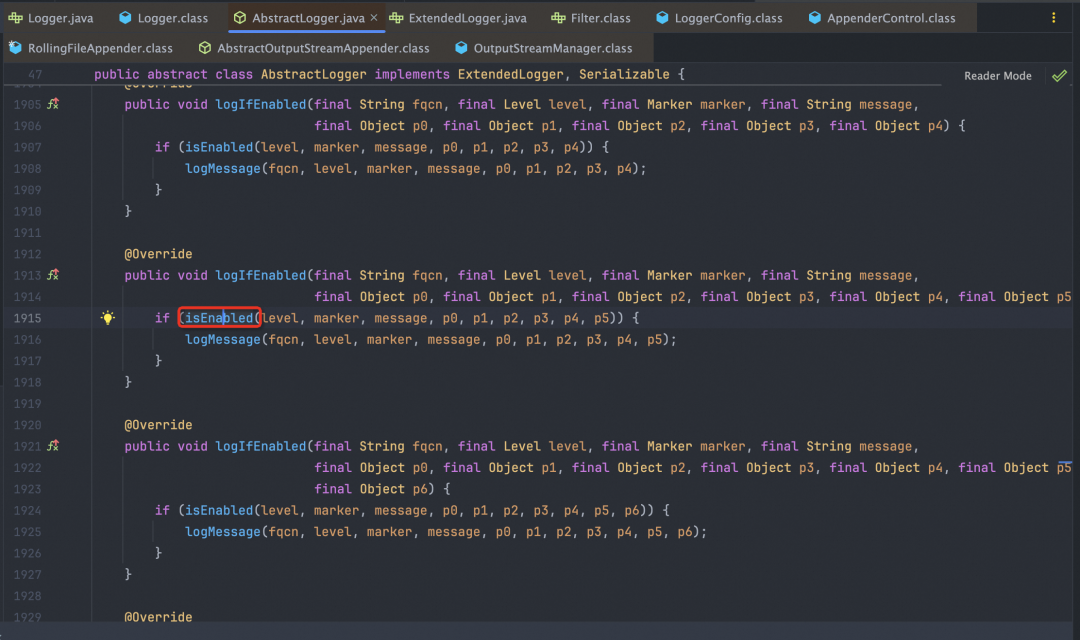
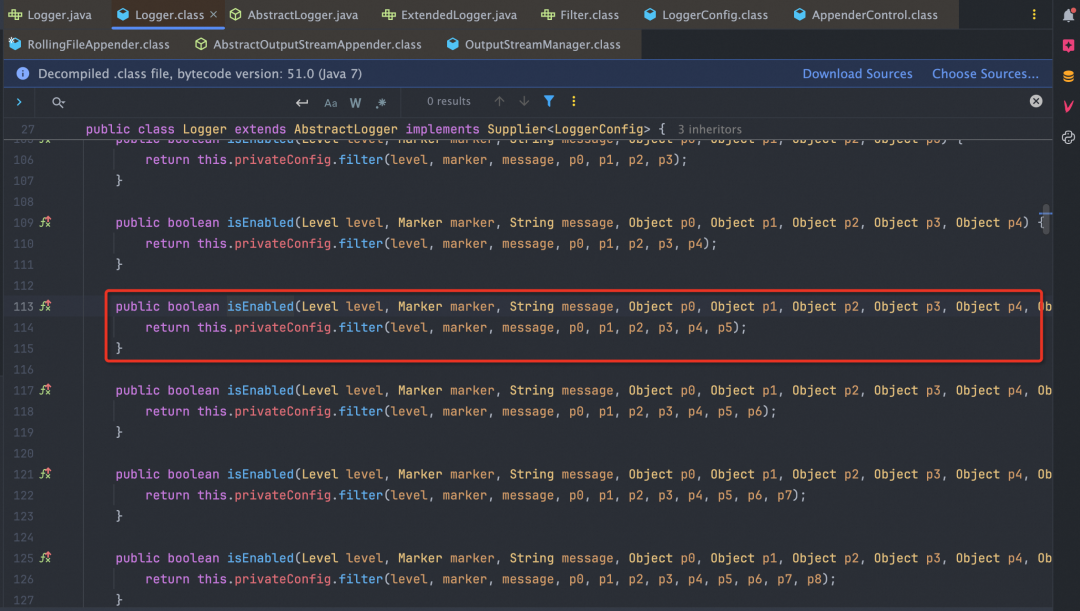
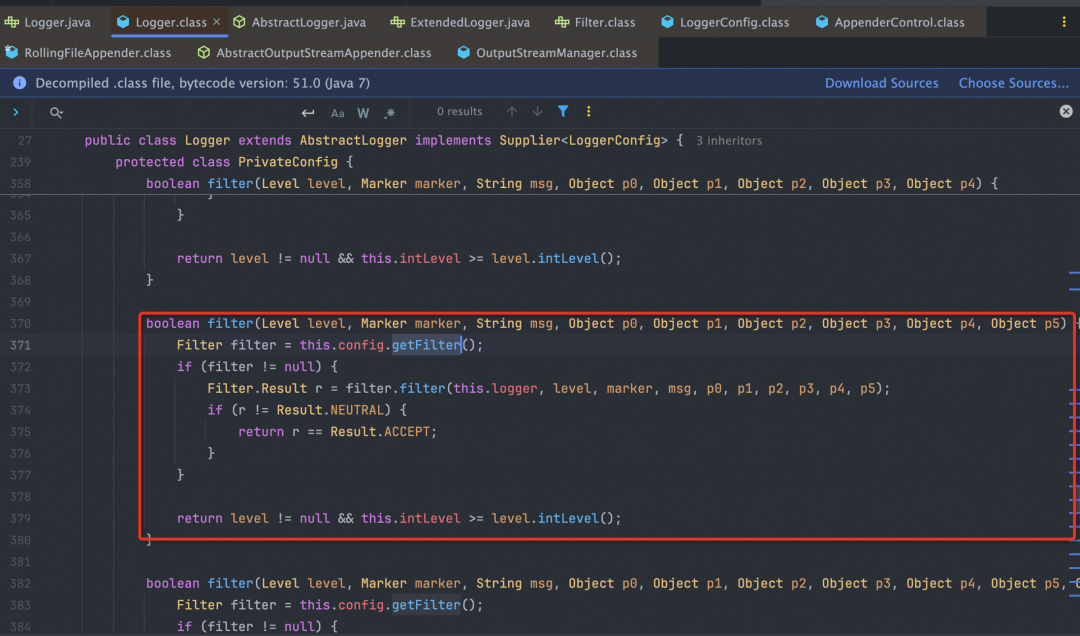
2. ReliabilityStrategy是Log4j2的日志可靠性策略实现,目前主要有以下四种:
-
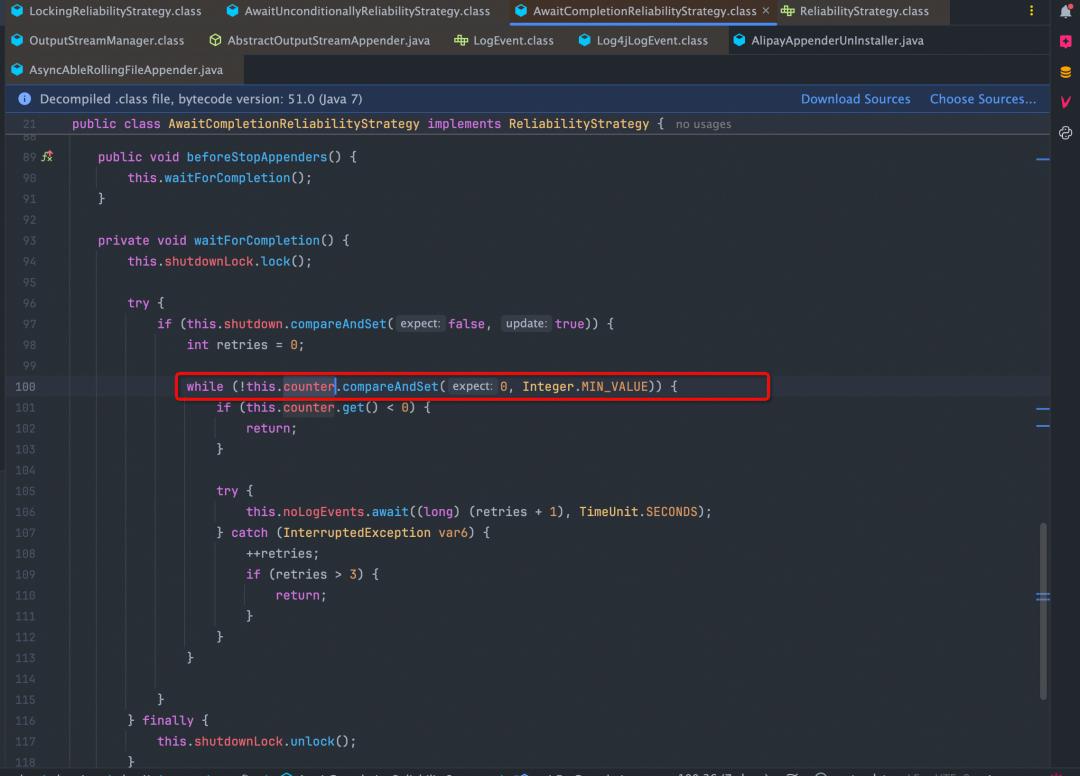
AwaitCompletionReliabilityStrategy: 等待日志接收完成策略。这种策略主要是在应用关闭时,尽可能要等应用日志接收完成后再结束Appender的生命周期(这种策略只是说尽可能所有日志等待调用Appender.append方法完成,但在异步日志场景下,Appender.append其实是落了ringbuffer或者其他队列里,实际上未持久化。因此该策略是尽可能保证接收完成而非处理完成)
-
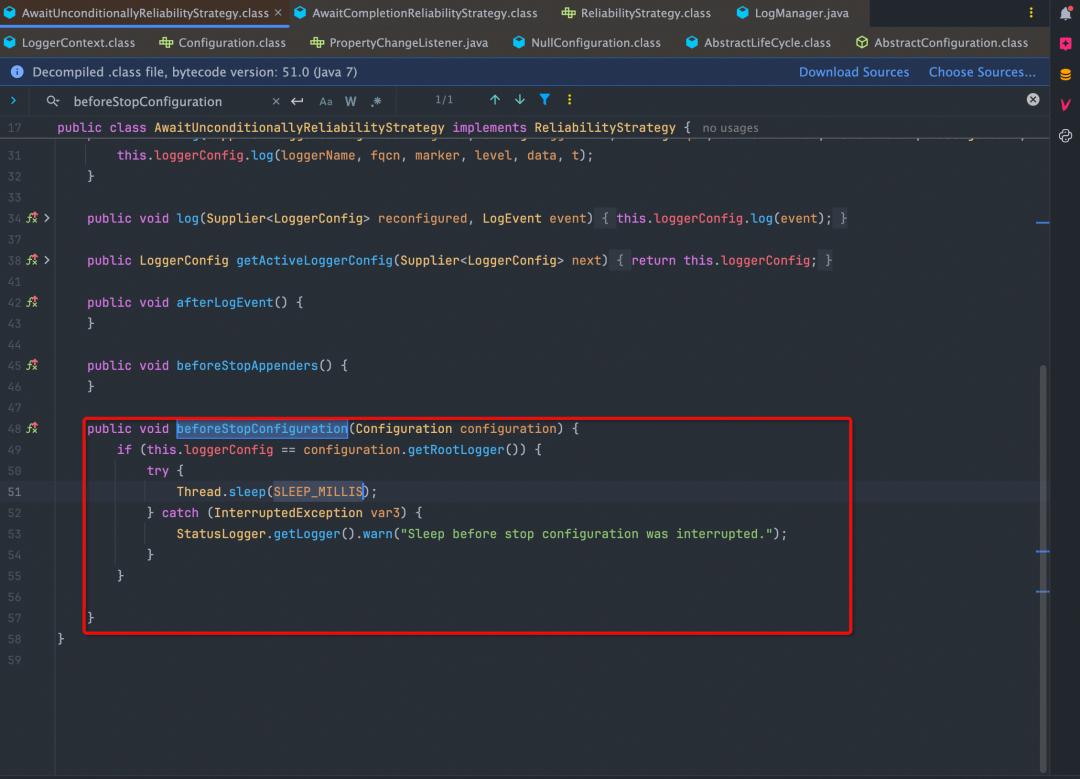
AwaitUnconditionallyReliabilityStrategy: 无条件等待策略。这种策略会在rootLogger关闭时无条件等待一段时间,具体等待时间可以配置log4j2.component.properties文件的log4j.waitMillisBeforeStopOldConfig属性。
-
DefaultReliabilityStrategy: 默认策略。该策略不做任何等待。
-
LockingReliabilityStrategy: 锁等待策略。该策略当正在写入日志时,则会等待;否则即会停止等待。
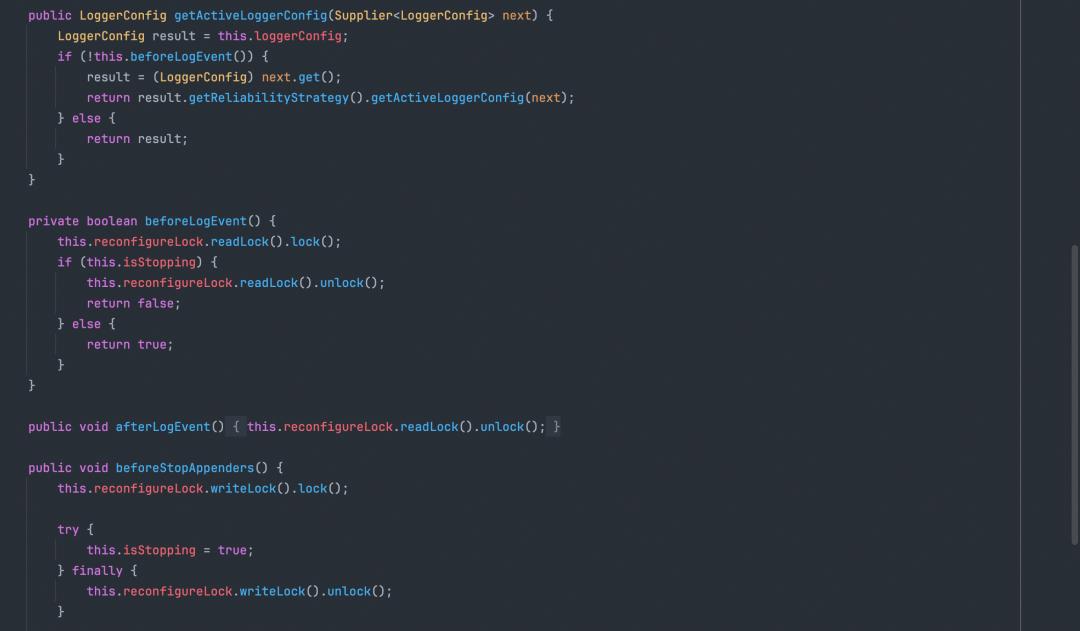
-
1.2.1.3.1append操作是将日志写入到对应的目的地,如kafka、本地文件、邮件等。这里如果是异步日志,则会将日志追加到异步队列里,进而提高日志记录的性能。
-
1.2.1.3.1.1调用Layout encode日志,是根据log4j2.xml中配置的Layout对日志进行格式化输出。
那么如果有一些个性化的日志输出需求,log4j2能否帮我们实现?
2.4 如何实现日志脱敏
上面提到了log4j2的各种组件以及日志输出流程,log4j2的强大很大程度上得益于其清晰且高度解耦的架构设计。例如其具有很强的扩展性,log4j2的很多组件都可以自己定制插件,如:Appender、Filter、Layout等。那么这里我结合我们实际业务中一个很常见的case去分析如何定制一个组件。
首先,作为一家强监管的金融公司,日志脱敏涉及数据保护和隐私安全等问题,非常重要。过去我们很多业务系统在实现业务脱敏时,很容易想到在打日志的入口统一封装一个格式化方法,造成日志输出在无形中把异步日志输出变成了同步输出(日志脱敏的耗时往往比日志集中持久化到磁盘耗时要高)。那么如何优雅的实现日志脱敏的功能,既能实现其功能又可以保证日志的性能,是log4j2插件化的一个很重要的应用场景。前面我们提到日志输出流程中会使用Layout encode日志,而PatternConverter是Layout非常重要的组成部分。其通过定义一系列的占位符(如%d、%m、 %t等)帮助我们自定义格式输出日志对象,同时PatternConverter支持以高度可定制的插件集成到Log4j2框架中,因此我们可以借助其去定制脱敏组件。话不多说,我们直接上日志脱敏PatternConverter插件源码:
//// Source code recreated from a .class file by IntelliJ IDEA// (powered by FernFlower decompiler)//import java.util.Arrays;import org.apache.logging.log4j.core.LogEvent;import org.apache.logging.log4j.core.config.plugins.Plugin;import org.apache.logging.log4j.core.pattern.ConverterKeys;import org.apache.logging.log4j.core.pattern.LogEventPatternConverter;import org.apache.logging.log4j.message.FormattedMessage;import org.apache.logging.log4j.message.Message;import org.apache.logging.log4j.message.MessageFormatMessage;import org.apache.logging.log4j.message.ParameterizedMessage;import org.apache.logging.log4j.message.StringFormattedMessage;import org.apache.logging.log4j.util.PerformanceSensitive;/*** @author baichun* @version ShieldMessagePatternConverter.java, v 0.1 2024年04月09日 21:13 baichun*/@Plugin(name = "ShieldPatternConverter",category = "Converter")@ConverterKeys({"shield", "sd", "shieldMessage", "sm"})@PerformanceSensitive({"allocation"})public final class ShieldMessagePatternConverter extends LogEventPatternConverter {private final String[] options;private ShieldMessagePatternConverter(String[] options) {super("Shield", "shield");this.options = options == null ? null : (String[])Arrays.copyOf(options, options.length);}//必须要有newInstance方法,log4j2会调用该方法进行初始化public static ShieldMessagePatternConverter newInstance(String[] options) {return new ShieldMessagePatternConverter(options);}@Overridepublic void format(LogEvent logEvent, StringBuilder output) {Message message = logEvent.getMessage();String format = message.getFormat();if (isFormatMessage(message)) {//在这里格式化脱敏日志String msgInfo = ShieldUtils.format(format, message.getParameters());output.append(msgInfo);} else {output.append(message.getFormattedMessage());}}private boolean isFormatMessage(Message message) {return message instanceof ParameterizedMessage || message instanceof StringFormattedMessage|| message instanceof FormattedMessage || message instanceof MessageFormatMessage;}}
定义好组件后,log4j2即能够自动扫描识别到,不需要其他定义和配置。接下来看看如何使用。ConverterKeys这个注解指定了在log4j2.xml中应如何使用该插件。
以下是log4j2.xml应用示例:
<RollingFile name="TEST_APPENDER" fileName="test.log"filePattern="test.log.%d{yyyy-MM-dd}"append="true"><!-- %sm即为脱敏组件 --><PatternLayout pattern="%d %sm%n" charset="UTF-8"/><TimeBasedTriggeringPolicy/><DefaultRolloverStrategy/></RollingFile>
2.5 Log4j2的异步日志
2.5.1 异步日志原理概述
前面提到了Log4j2的高可扩展性,同时Log4j2的性能也是极高的,下面是Log4j2官方的benchmark数据,仅供参考:
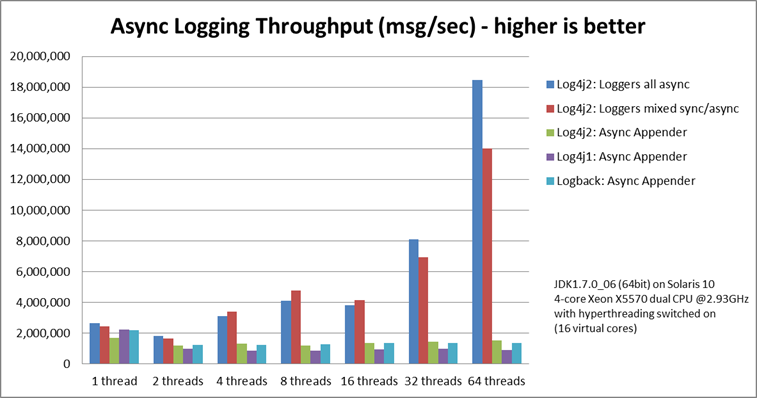
Log4j2之所以性能如此之高,其中一个很重要的原因就是其基于Disrupter的环形缓冲区的无锁化结构Ringbuffer设计。Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,基于Disruptor开发的系统单线程能支撑每秒600万订单。目前,包括Apache Strom、Log4j2在内的很多知名项目都应用了Disruptor来获取高性能。关于Disruptor的原理,这里不再赘述,大家可以自行查阅:https://lmax-exchange.github.io/disruptor/#_what_is_the_disruptor
Disrupter组件构成:
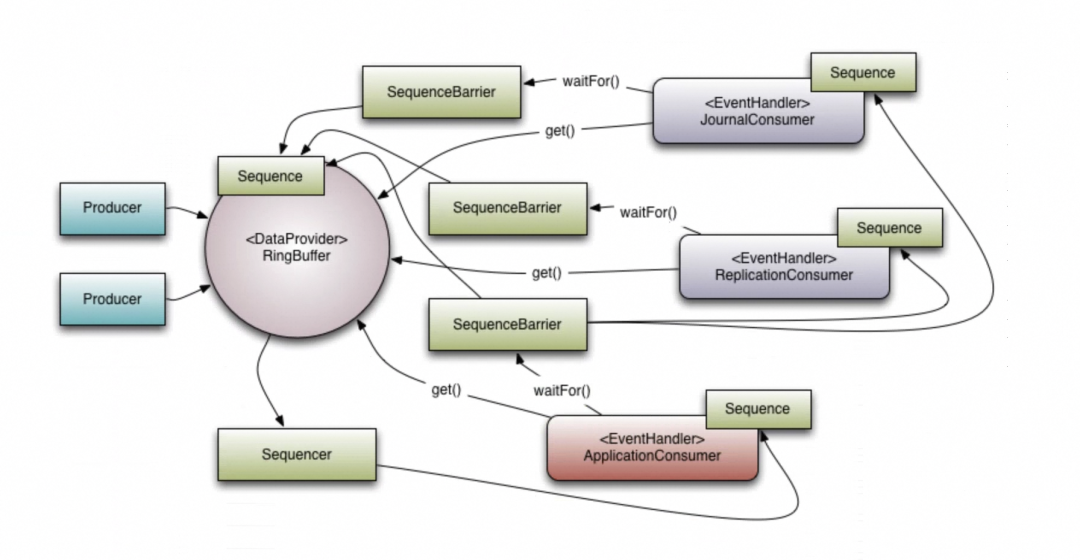
Disrupter性能测试结果
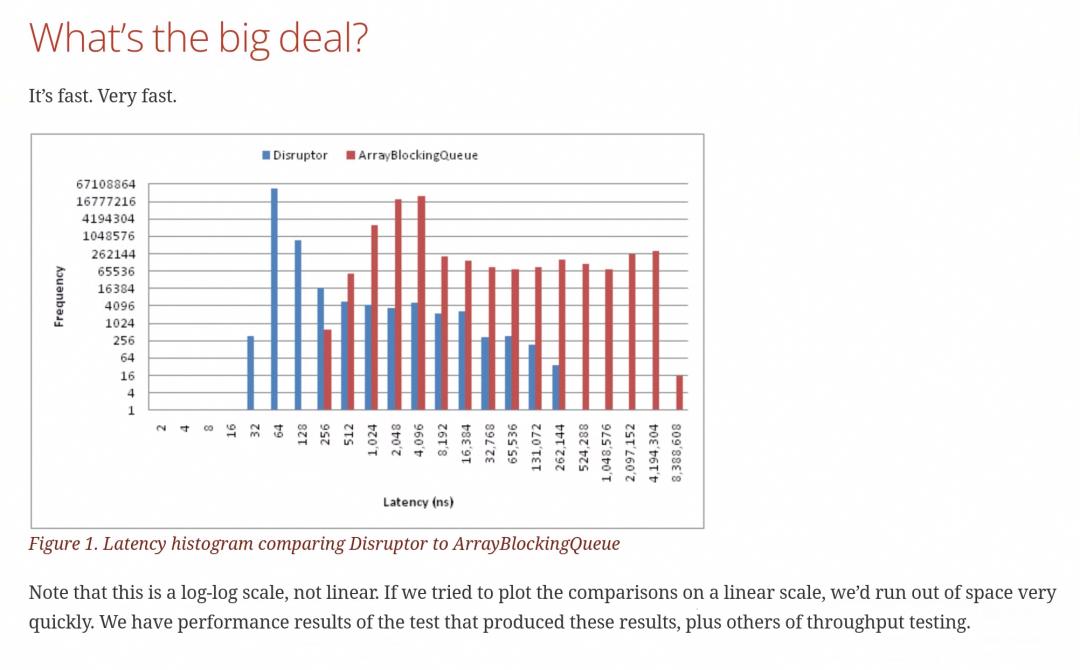
2.5.2 如何使用异步日志
log4j2开启异步日志的方法主要有以下两种方式:
-
全局异步日志
1. 通过JVM启动参数来全局启用异步日志功能。在启动应用程序时,向JVM传递以下系统属性:
-DLog4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector2. 在类路径(classpath)中添加一个名为log4j2.component.properties的文件,并包含以下内容(这个文件会在Log4j2初始化时被读取):
Log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector这两种方式下,所有Logger都会自动使用异步处理。
-
混合异步日志
在log4j2.xml配置文件中,可以手动指定特定的Logger使用异步处理,通过将 <Root>或<Logger>元素替换为<AsyncRoot>或<AsyncLogger>。例如:
<Configuration status="WARN"><Appenders>... <!-- your appenders here --></Appenders><Loggers><AsyncRoot level="info" includeLocation="false"><AppenderRef ref="yourAppenderName"/></AsyncRoot><!-- 或者为特定logger配置 --><AsyncLogger name="com.example.MyClass" level="debug"><AppenderRef ref="yourAppenderName"/></AsyncLogger></Loggers></Configuration>
2.5.3 异步日志的潜在问题及解决方案
-
潜在问题:
-
日志丢失问题:如果机器发生意外重启、发布、掉电导致的jvm进程停止,停留在队列的未来得及输出到目的地的LogEvent可能会丢失
-
日志顺序问题:由于日志事件是在不同的线程中异步处理的,因此日志条目可能不会严格按照它们产生的顺序出现在日志文件中,这对于需要严格按时间顺序追踪日志的应用可能是个问题。
-
其他问题:如增加资源损耗、配置复杂度和调试复杂度等问题
-
解决方案:
-
对于日志丢失问题:
-
原生Log4j2有完整的生命周期管理,并监听了jvm关闭的事件。当jvm关闭时,Log4j2会监听Disrupter队列中的RingbufferLogEvent数量,直到日志打印完(或超时)才释放关闭Log4j2,jvm才得以正常关闭。但是自然灾害或者机房掉电等不可抗力因素,无法避免丢失问题。
-
我们基于Log4j2定制的AsyncAbleRollingFileAppender,其中有独立的Disrupter,且不在Log4j2生命周期管理当中,存在日志丢失风险。可以采用类似方案解决:
try {LoggerContextFactory factory = LogManager.getFactory();if (!(factory instanceof Log4jContextFactory)) {return;}Log4jContextFactory log4jContextFactory = (Log4jContextFactory) factory;ShutdownCallbackRegistry registry = log4jContextFactory.getShutdownCallbackRegistry();if (!(registry instanceof DefaultShutdownCallbackRegistry)) {return;}DefaultShutdownCallbackRegistry defaultShutdownCallbackRegistry = (DefaultShutdownCallbackRegistry) registry;Field hooksField = DefaultShutdownCallbackRegistry.class.getDeclaredField("hooks");hooksField.setAccessible(true);Collection<Cancellable> hooks = (Collection<Cancellable>) hooksField.get(defaultShutdownCallbackRegistry);Collection<Cancellable> newHooks = new CopyOnWriteArrayList<>();//将对Appender的队列消费监听和卸载放在首要位置,避免log4j2关闭后再卸载AppendernewHooks.add(new Log4j2Cancellable(() -> {//负责监听AsyncAbleRollingFileAppender的队列消费情况,并在消费完成后关闭AsyncAbleRollingFileAppendernew AppenderUnInstaller(register).run();}));newHooks.addAll(hooks);hooksField.set(defaultShutdownCallbackRegistry, newHooks);} catch (NoSuchFieldException e) {// This catch statement is intentionally empty} catch (IllegalAccessException e) {// This catch statement is intentionally empty}
-
AsyncAbleRollingFileAppender使用独立的disrupter,且RingBufferLogEvent未及时清理对象,容易导致内存泄漏,异步日志场景请慎用。
-
对于日志顺序性问题:
-
异步线程池大小设置为1,但是会影响日志打印的速度(现在的普遍做法)。
-
延迟打印
三、效果
4月份的这一问题发生后,我们从原理出发,对理财的核心应用做了升级和优化,整体服务耗时上取得了不错的性能优化效果。
应用rpc耗时:
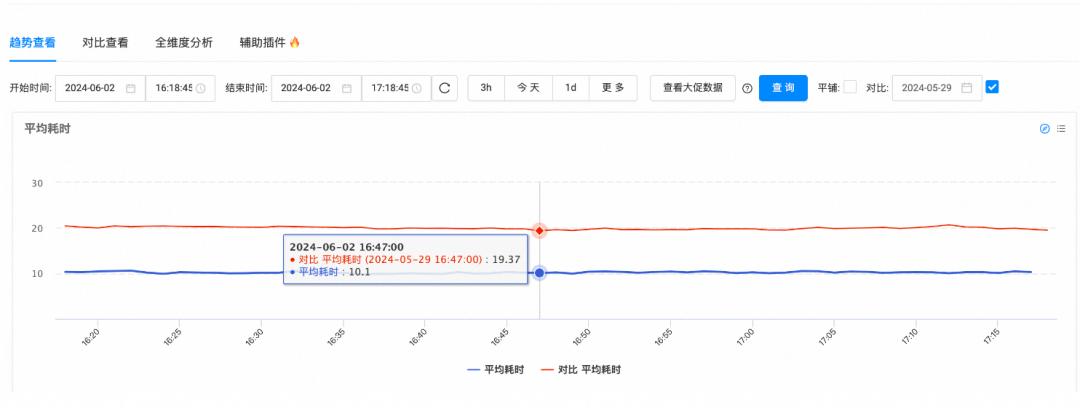
应用网关耗时:
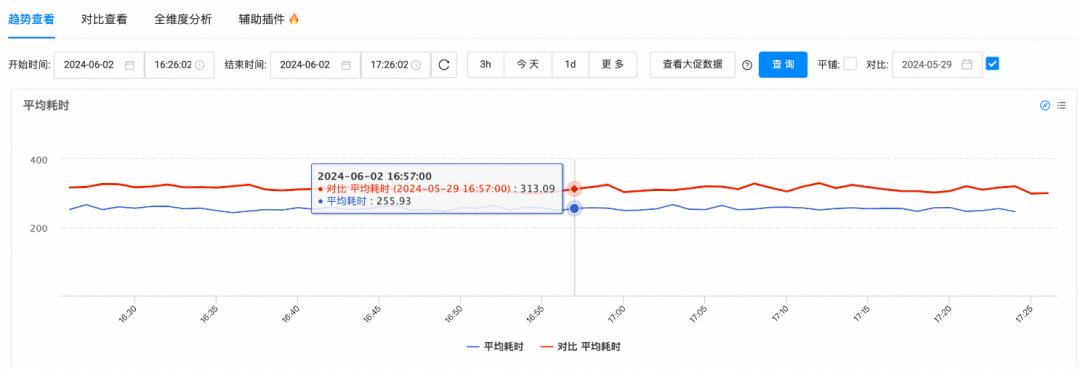
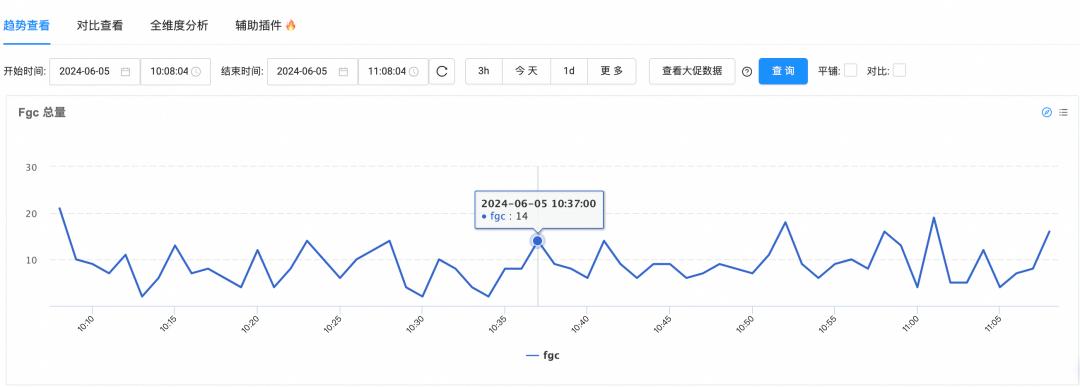
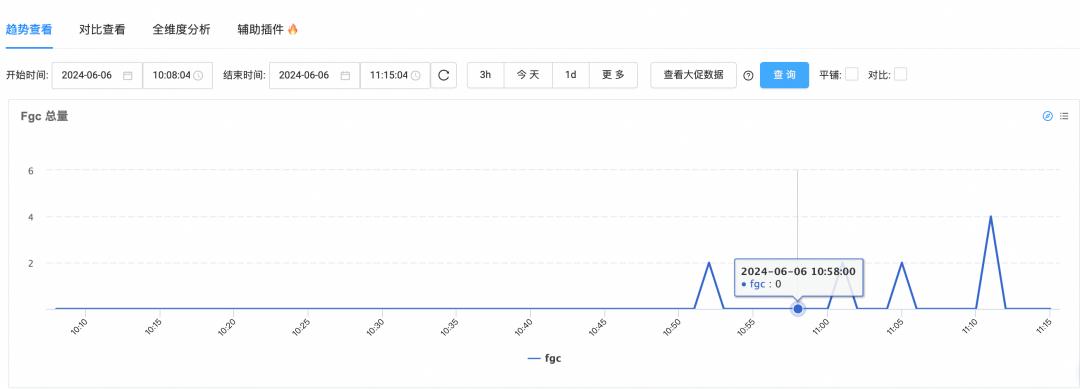
但与此同时,我们也发现升级后,应用的fgc次数更多了,经过heapdump分析后,发现AsyncAbleRollingFileAppender内部实现的RingBufferLogEvent执行后,不会释放引用的LogEvent,导致Disrupter一直持有已打印的LogEvent的引用关系,进而导致了内存泄漏。后来,我们采取主动释放对象引用(RingBufferLogEvent.setLogEvent(null))优化的方案,发布以后前后fgc对比如下:
GC优化前:
GC优化后:
四、建议
日志作为诊断问题、监控系统健康状况与优化服务效能不可或缺的一环,其重要性不言而喻。熟练掌握并有效利用如Log4j2这样的高性能日志框架以及注意一些打印日志的策略(如动静分离、合理分割、合理设置日志级别等),对于开发者而言至关重要:
-
动静分离 :在一些大日志输出场景中,即使是异步日志也会给系统带来性能风险。因此建议合理识别大日志中的动态数据和静态数据。静态数据定时输出,动态数据关联唯一静态标识输出,在降低性能风险的同时又满足监控分析的需要;
-
合理分割 :日志文件需要合理分割,并设置合理的保留策略,及时释放磁盘空间。
-
合理设置日志级别 :避免日志滥用,尤其是debug日志,既有利于日志定位问题的速度,又能提高性能。



















