一、企业灾备体系
1.1 灾备体系
灾备切换的困境:

容灾领域的标准化方法和流程、算法体系是确保业务连续性和数据可靠性的核心,以下从标准框架、流程规范、算法体系三个维度进行系统分析:
1.1.1、标准化方法体系
1. 容灾等级标准
- 国际标准SHARE78:
将容灾能力划分为7级(Tier 0~6),核心指标包括RTO(恢复时间目标)和RPO(恢复点目标)。- Tier 0:无异地备份(RPO≥24小时)
- Tier 3:电子传输+定时备份(RPO≤24小时)
- Tier 6:零数据丢失+自动切换(RPO=0,RTO≤2分钟)
- 中国金融行业标准:
采用6级分类(1级最高),例如:- 1级:RTO≤2小时,RPO≤15分钟(银行核心系统)
- 4级:RTO≤12小时,RPO≤4小时(支付机构)
2. 技术架构标准
- 容灾架构类型:
架构 适用场景 技术要点 同城容灾 低延迟强一致性 同步复制(如EMC VPLEX)、RDMA网络 异地容灾 成本敏感型业务 异步复制(如Canal/Otter)+增量压缩 两地三中心 金融/政府高可用 同城双活+异地异步(如TiDB DR Auto-Sync) 异地多活 互联网高并发业务 分片同步+一致性哈希(如Redis Cluster) - 合规框架:
- ISO 22301:业务连续性管理体系,覆盖容灾规划全流程
- NIST SP 800-34:美国联邦容灾指南,强调风险评估与恢复策略
3. 行业专用标准
- 金融行业:遵循《JR/T 0168-2020》,要求容灾中心独立部署、定期演练
- 云计算:CSA STAR认证,评估云服务商容灾能力(如阿里云多AZ架构)
1.1.2、标准化流程体系
1. 全生命周期管理流程
graph LR
A[风险评估] --> B[业务影响分析] --> C[容灾策略制定] --> D[方案设计与部署] --> E[预案文档化] --> F[演练与迭代]- 风险评估:识别单点故障(如网络分区、存储损坏),量化潜在损失
- 业务影响分析:确定关键业务优先级(如支付系统RTO需≤30分钟)
2. 容灾预案制定与演练流程
- 预案核心要素:
- 数据备份策略(增量/全量)
- 切换触发条件(如心跳检测超时)
- 人员职责分工(应急指挥组、技术恢复组)
- 演练标准化流程:
- 计划制定:模拟灾难场景(如机房断电、网络攻击)
- 技术准备:搭建沙箱环境,注入故障(ChaosMesh)
- 实施与评估:记录切换时间、数据一致性偏差
- 复盘优化:更新预案文档,调整资源分配
3. 资源分配流程
- 静态分配:预先预留资源(如冷备服务器),成本高但切换快
- 动态分配:
- 虚拟机热迁移:vMotion实时迁移(RTO秒级)
- 容器化弹性调度:K8s联邦集群跨云调度Pod
1.1.3、算法体系
1. 数据同步算法
- 同步复制:基于Paxos/Raft共识算法,确保强一致性(金融交易系统)
- 异步复制:
- 增量日志追补:数据库Redo Log解析(如MySQL GTID)
- 向量时钟(Vector Clock):解决分布式写入冲突(Cassandra)
- 压缩优化:LZ4算法压缩增量数据(带宽节省≥50%)
2. 故障检测与切换算法
- BFD(双向转发检测):毫秒级链路探测(间隔≤50ms)
- 智能仲裁:
- ZooKeeper ZAB协议防脑裂
- 基于PSO(粒子群优化)动态选择最优路径
3. 资源调度算法
| 算法 | 原理 | 应用场景 |
|---|---|---|
| 一致性哈希 | 动态增删节点仅迁移1/N数据 | 分布式缓存(Redis) |
| 加权ECMP | 按链路负载动态分配流量 | SDN网络容灾 |
| 动态优先级调度 | 关键业务优先抢占资源 | 虚拟机高可用集群 |
4. 数据一致性算法
- 分布式事务:
- 二阶段提交(2PC):数据库跨中心事务(如Oracle DataGuard)
- Quorum机制:读写多数节点确认(如Cassandra LOCAL_QUORUM)
- 时钟同步:PTP协议(IEEE 1588)实现微秒级对齐(证券交易系统)
1.1.4总结与趋势
- 标准融合:国际标准(ISO 22301)与行业标准(如金融JR/T 0168)逐步整合,推动跨行业兼容
- 算法智能化:
- AI预测故障:LSTM模型分析硬件故障率(准确率≥95%)
- 强化学习动态调优:根据网络状态自适应调整复制策略
- 云原生重构:
- 容器化+Serverless实现分钟级容灾成本降60%
- 跨云多活架构(如AWS Global Accelerator)成新趋势
实施建议:
- 强一致性场景:采用Tier 6架构(同步复制+Paxos算法)
- 成本敏感场景:选择异步复制+增量压缩(LZ4),带宽占用降50%
- 合规要求:金融系统需满足年演练≥1次,并提交审计报告
通过标准化方法约束风险边界、流程保障落地可行性、算法优化性能瓶颈,三者协同构建高可用容灾体系。
专业名词解释
| 名称 | 说明 |
|---|---|
| 机房类型 | 机房类型分为中心机房和容灾机房。机房类型仅用于标识区别两个机房,且不随机房服务状态改变而改变。在HotDB Server产品使用过程中,以添加计算节点集群组管理为入口可以区分中心机房和容灾机房。 |
| 机房状态 | 机房状态分为当前主机房和当前备机房,根据机房内的主计算节点是否提供服务(默认3323服务端口)判断机房类型。当前主计算节点提供服务的机房即为当前主机房;与当前主机房配套提供机房级别高可用服务切换的备用机房为当前备机房。 |
| - | - |
| 容灾模式 | 在两个机房内协调部署了具有容灾关系的完整计算节点集群运行所需组件,称这个集群为开启容灾模式的集群。 |
| 单机房模式 | 未开启容灾模式的计算节点集群即为单机房模式的集群。 |
| 容灾数据复制关系 | 中心机房主存储节点、配置库与容灾机房主存储节点、配置库之间的复制关系,简称:容灾关系。 |
| 容灾数据复制状态 | 中心机房主存储节点、配置库与容灾机房主存储节点、配置库之间的复制状态,简称:容灾状态。 |
| - | - |
| 容灾数据复制时延 | 中心机房主存储节点、配置库与容灾机房主存储节点、配置库之间的复制的延时情况,简称:容灾时延。 |
| 计算节点 | 即分布式事务数据库服务HotDB Server |
| - | - |
| 存储节点 | 即存储数据的MySQL数据库服务,一个MySQL物理库可作为一个存储节点;一个或多个有MySQL复制关系的存储节点组成数据节点。 |
| 配置库 | 存放计算节点配置数据的MySQL数据库。 |
| - | - |
| RPO | Recovery Point Objectives,故障恢复点目标。 |
| RTO | Recovery Time Objectives,故障恢复时间目标。 |
| - | - |
1.2 规划企业安全保障体系考虑的因素
(1)需要防范的灾难类型:
企业信息系统可能遇到的灾难类型及其发生的比例如下:
对于“人为错误”、“软件损坏和程序错误”加上“病毒”等这些都称为逻辑错误,占总故障的 56%,这些错误只能通过备份系统才能防范;
对于“硬件和系统故障”以及“自然灾难”等故障可以通过在容灾系统(或者异地备份)来防范,占总故障率的44%。
(2)允许的RTO和RPO指标
从技术上看,衡量容灾系统有两个主要指标:RPO(Recovery Point Object)和RTO(Recovery Time Object),其中RPO代表了当灾难发生时允许丢失的数据量;而RTO则代表了系统恢复的时间。
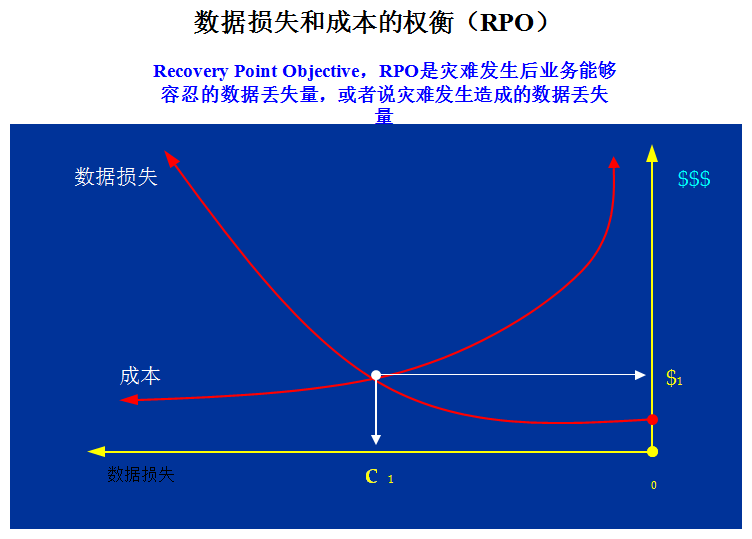
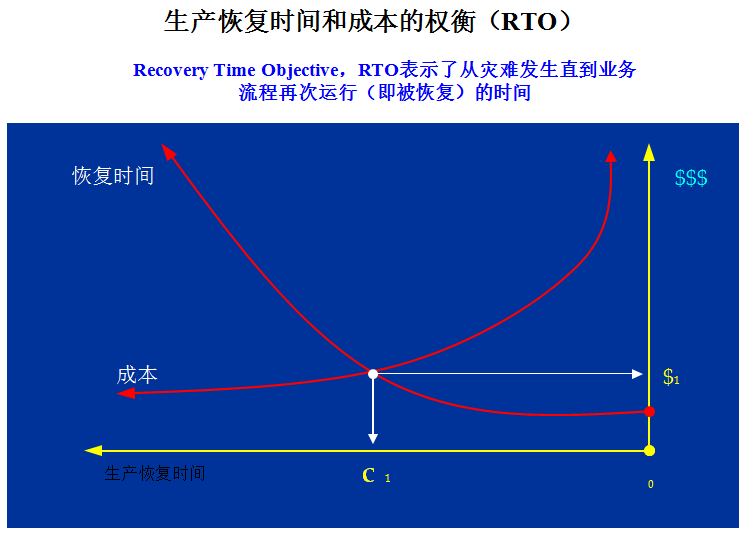
(3)系统投资
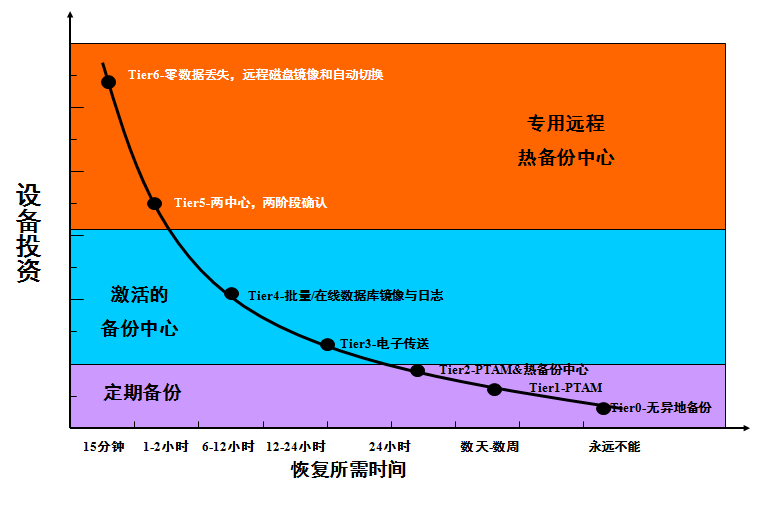
总的说来,建设备份系统的投资远比建设标准意义的容灾系统的投资小得多:
备份系统的投资规模一般在几百万;
而最节省的一套容灾系统投资都将上千万;
灾难恢复与投资关系:
1.3 信息安全容灾标准
信息系统容灾恢复规范是保障业务连续性和数据安全的核心框架,主要依据国家标准《GB/T 20988-2007 信息系统灾恢复规范》。
1.3.1 、核心规范框架与指标
1. 关键术语定义
- 灾难:导致信息系统瘫痪的突发性事件(如自然灾害、人为事故)。
- 灾难恢复:将系统从灾难状态恢复到正常运行的活动流程。
- RTO(恢复时间目标):业务中断到恢复的最长时间(如金融系统通常要求≤30秒)。
- RPO(恢复点目标):灾难发生时允许丢失的数据量(如实时交易系统要求RPO=0)。
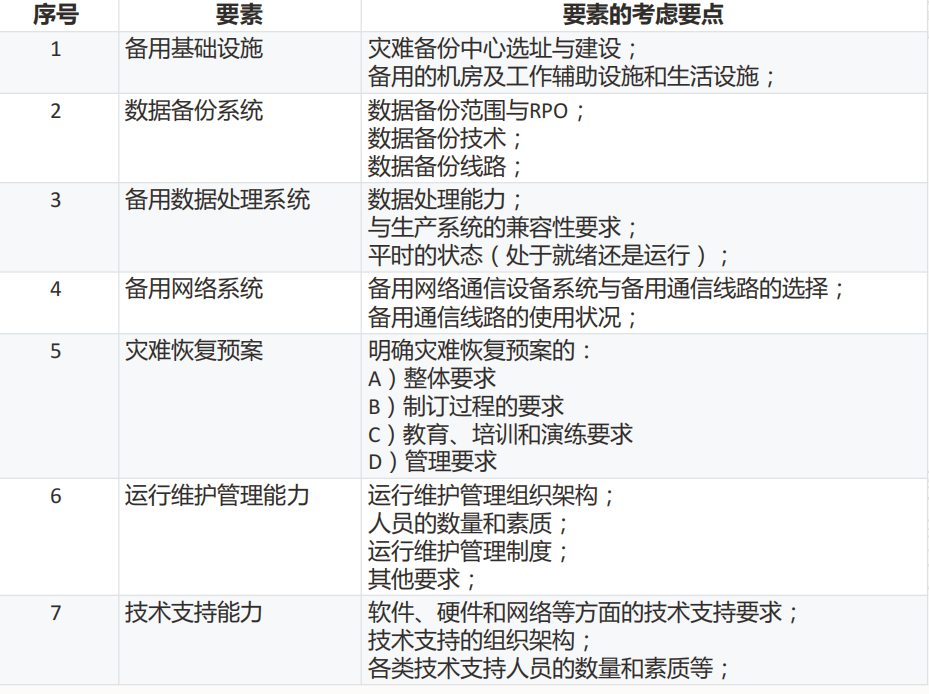
2. 灾难恢复能力等级划分
国家标准将灾难恢复能力分为6个等级,每个等级需满足7项要素要求:
| 等级 | 名称 | 核心要求 | 典型RTO/RPO |
|---|---|---|---|
| 第1级 | 基本支持 | 每周完全备份+介质异地存放,年演练1次 | RTO=天级,RPO≥24小时 |
| 第2级 | 备用场地支持 | 增加备份网络和备用基础设施(如电力、空调) | RTO≤24小时 |
| 第3级 | 电子传输部分设备支持 | 实时数据备份+备用主机就绪,支持部分业务切换 | RTO≤12小时 |
| 第4级 | 电子传输完整设备支持 | 同城双活架构,数据实时同步,业务恢复自动化 | RTO≤4小时,RPO≈0 |
| 第5级 | 实时数据传输完整支持 | 异地双活,零数据丢失(如两阶段提交事务) | RTO≤30分钟,RPO=0 |
| 第6级 | 远程集群支持 | 多中心并行负载均衡,自动故障切换(如分布式数据库Paxos协议) | RTO≤秒级,RPO=0 |
注:第4~6级需满足数据备份、备用处理系统、网络、基础设施、技术支援、运维管理、预案7要素全部要求。
1.3.2、灾备技术方案关键点
1.3.2.1 数据同步技术
容灾系统中的数据同步技术是保障数据一致性、业务连续性的核心,其底层依赖复杂的算法体系及数学物理原理。
数据同步技术分类及实现
1. 基于存储复制的同步
-
原理:由存储硬件(如SAN)实现数据块级复制,通过镜像技术保持主备数据一致。
-
同步模式:
-
同步复制:每个I/O操作需等待灾备端确认(RPO=0),但延迟 敏感(同城RTT<2ms)。同城场景(距离≤100km),RPO=0,延迟敏感(如华为HyperMetro)。
-
异步复制:I/O操作本地确认后异步复制到远端(RPO>0),带宽要求低,容忍网络延迟。
-
半同步复制:折中方案,多数节点确认即返回(MySQL Group Replication)。
-
-
代表技术:
EMC SRDF(同步)、IBM PPRC(异步)、HDS TrueCopy。
2. 基于逻辑卷管理的同步
-
原理:卷管理软件(如Veritas VVR)截获文件系统I/O,实时复制到灾备卷。
-
优势:
与存储硬件解耦,支持异构存储;可配置一对多、多对一复制。 -
数据流:
生产卷 → 日志记录 → 网络传输 → 灾备卷重放。
3. 基于数据库日志的同步
-
原理:捕获数据库事务日志(如Redo Log),传输到灾备端按顺序重放,实现事务级一致性。
-
关键技术:
-
日志解析:实时解析事务操作(增删改);
-
冲突解决:时间戳或版本号排序(如MVCC)。
-
-
代表技术:
Oracle DataGuard(物理级)、MySQL主从复制(逻辑级)。
4. 基于应用的增量同步
-
原理:应用层捕获数据变更(如消息队列),通过发布-订阅模型异步分发。
-
场景:
微服务架构下,Kafka/Pulsar传输变更事件,灾备端消费并更新缓存/数据库。 -
一致性保障:
最终一致性(Eventual Consistency)。
核心算法体系
1. 分布式一致性算法
| 算法 | 原理 | 应用场景 |
|---|---|---|
| Paxos | 多数派投票达成共识,容忍节点故障(如网络分区) | 金融核心系统强一致性 |
| Raft | 选举Leader管理日志复制,简化Paxos流程 | etcd、Consul等分布式存储 |
| Quorum | 读写操作需超过半节点确认(NWR模型) | 分布式数据库(Cassandra) |
2. 数据冲突解决算法
-
向量时钟(Vector Clock):
记录事件因果顺序(例:[A:2, B:1]>[A:1, B:1]),解决分布式系统并发写冲突。 -
操作转换(OT):
实时协同编辑场景,合并并发操作(如Google Docs)。
3. 高效同步优化算法
-
一致性哈希(Consistent Hashing):
动态增减节点时仅迁移少量数据(如Redis Cluster)。 -
数据分片(Sharding):
按Key范围(Range)或哈希值(Hash)分割数据,并行同步提升效率。
数学与物理原理
1. 数学原理
-
信息论(熵编码):
数据压缩(LZ77、Huffman编码)减少传输量,节省带宽。 -
排队论:
优化I/O队列调度(如FIFO、优先级队列),降低同步延迟。 -
概率模型:
-
预测网络丢包率,动态调整TCP窗口(AIMD算法);
-
LSTM预测同步延迟,提前调度资源。
-
2. 物理原理
-
光传输时延约束:
同步复制要求同城距离≤100km(光速30万km/s,RTT≤1ms)。 -
时钟同步机制:
-
锁相环(PLL):调整本地时钟相位匹配参考时钟(光纤通信);
-
NTP/PTP协议:NTP精度毫秒级,PTP(IEEE 1588)精度微秒级(金融交易)。
-
-
量子隧穿效应:
高密度存储芯片(如3D NAND)依赖量子隧穿写入数据,需精准电压控制保障一致性。
技术对比与选型
| 技术类型 | RPO | 适用场景 | 算法依赖 |
|---|---|---|---|
| 存储同步复制 | 0秒 | 同城双活 | 无(硬件实现) |
| 数据库日志复制 | 秒级 | 跨城容灾 | MVCC、WAL |
| 应用层消息队列 | 分钟级 | 微服务架构 | 最终一致性、向量时钟 |
| 逻辑卷管理 | 秒~分钟级 | 异构存储整合 | 环形缓冲区、QoS |
应用趋势
- 云原生融合:
Kubernetes CSI插件实现存储卷跨云同步(如Velero)。 - 智能优化:
- 强化学习动态调整同步策略(如带宽分配);
- 区块链存证保障同步过程不可篡改(金融合规)。
- 存算一体:
iRAID技术实现硬盘KB级分块恢复,TB级数据重构<15分钟(比传统RAID快40倍)。
选型建议:
- 强一致性场景:存储同步复制+Paxos算法(同城RPO=0);
- 跨域容灾:数据库日志复制+Quorum仲裁(容忍网络分区);
- 成本敏感场景:应用层异步队列+最终一致性(带宽节省>40%)。
容灾同步本质是数学(一致性模型)、物理(传输时延)与工程(分布式算法)的深度结合,需根据业务需求在RPO/RTO、成本之间权衡。
1.3.2.2. 网络与高可用架构
- 全局负载均衡(GSLB):基于地理位置分流流量(DNS+Anycast)。
- 单元化部署:按用户/地域拆分业务单元,避免跨单元依赖(阿里UID分片)。
- 分布式事务:金融场景采用TCC模式(Seata框架)保障跨机房原子性。
1.3.3、实施路径与流程
1. 灾备规划四阶段
- 需求分析
- 业务影响分析(BIA):识别关键业务功能(如支付交易)及容忍中断时间。
- 风险评估:分析自然灾害、网络攻击等潜在威胁。
- 策略制定
- 按业务等级选择容灾方案(如核心系统用5级,日志系统用2级)。
- 系统建设
- 数据备份:混合使用完全备份(每日)+增量备份(每小时)。
- 基础设施:同城双活中心(专线保障RTT<2ms)+异地灾备中心。
- 预案管理
- 文档化操作流程,明确故障切换、数据恢复、人员职责。
2. 资源与成本优化
- 虚拟化+云服务:减少物理设备投入(如Kubernetes联邦集群跨机房调度)。
- 分层存储:热数据SSD存储,冷数据转对象存储(成本降50%)。
1.3.4、行业实践与合规要求
1. 金融行业
- 要求:同城RTO≤30秒+异地RPO<5分钟,符合《JR/T 0044-2008》。
- 方案:Oracle RAC同城同步复制 + GoldenGate异地异步备份,数据加密+区块链存证日志。
2. 政务与档案系统
- 数据主权:专网传输+数据脱敏(FPE加密),异地中心距主中心≥45公里。
- 档案备份:电子目录+数字化全文的完全备份(介质异地存放,年有效性验证)。
3. 云服务架构
- 多云容灾:AWS/AliCloud的DRaaS服务,支持按虚拟机粒度计费。
- 可用区设计:同城可用区(抗单机房故障) + 异地可用区(抗区域灾害)。
1.3.5、容灾演练与持续改进
1. 演练类型与周期
| 类型 | 适用场景 | 周期 |
|---|---|---|
| 桌面演练 | 预案流程验证(无实际操作) | 每季度1次 |
| 模拟演练 | 部分系统切换测试 | 每半年1次 |
| 全面中断测试 | 全业务切换至灾备中心(真实环境) | 每年1次 |
2. 演练关键步骤
- 目标设定:明确测试RTO/RPO(如支付系统RTO≤1分钟)。
- 故障注入:模拟机房断电、网络分区(ChaosMesh工具)。
- 问题诊断:记录数据一致性偏差、切换延迟等缺陷。
- 预案迭代:修复问题并更新文档(版本控制管理)。
3. 演练成效评估
- 成功率指标:某银行演练达标率99.8%。
- 成本效益:灾备投入占IT总成本≥5%,但可降低灾难损失90%+。
总结:规范落地核心逻辑
- 分级防御:按业务重要性匹配容灾等级(如1~6级),避免过度投入。
- 技术融合:同步复制+单元化架构保障核心业务零感知切换;异步复制+云服务优化边缘业务成本。
- 合规驱动:金融需满足国标5级+行业审计,政务需数据主权保障。
- 持续运维:年演练覆盖率100% + 预案季度迭代,形成“分析-建设-验证”闭环。
实施建议:参考《GB/T 20988-2007》附录的预案框架。
二、常用的灾备组合方式
2.1 灾备系统建设模式
业界在灾备系统的建设上一般按照以下几种方式:
建设机房内的本地备份系统
建设异地的备份系统
该方式可以备份系统的价格满足备份和异地容灾功能,能够避免主生产中心由于地震、火灾或其他灾害造成的数据丢失。
备份系统+异地容灾系统
这是一个较为理想化的容灾系统一体化解决方案,能够在很大程度上避免各种可能的错误。
2.1.1 容灾恢复等级

以下是关于容灾国际标准Share78的全面解析,涵盖定义、7个等级的方法原理、底层设计思路及系统实现,结合国际标准与行业实践:
Share78标准定义
Share78由国际组织SHARE于1992年制定,是全球公认的容灾方案分级框架。其核心通过8个维度评估容灾能力:
备份/恢复范围
灾备计划状态
主备中心距离
主备中心连接方式
数据传输机制
允许数据丢失量(RPO)
数据更新一致性保障
灾备中心就绪能力
最终将容灾能力划分为 0~6级,从本地备份到零数据丢失的全自动灾备。
7个等级详解:方法、原理与系统实现
1. Tier 0:无异地备份
-
方法:仅本地磁带备份,无异地数据副本。
-
原理:低成本基础备份,依赖物理介质恢复。
-
RPO/RTO:数据丢失量=最后一次备份至灾难发生时的新数据;恢复时间数天至数周。
-
底层设计:
-
系统:磁带机+备份软件(如Veritas NetBackup)。
-
缺陷:本地灾难导致数据全丢失,无业务连续性保障。
-
2. Tier 1:异地备份(PTAM卡车运送)
-
方法:备份磁带运送至异地保存,但无备用系统。
-
原理:通过地理隔离降低数据全损风险,恢复需重建硬件环境。
-
RPO/RTO:数据丢失量=备份周期内数据(通常1-7天);RTO≥24小时。
-
底层设计:
-
系统:自动化磁带库(如IBM TS4500)+物流管理。
-
典型场景:中小企业非关键业务。
-
3. Tier 2:热备份站点
-
方法:异地设热备中心,备份数据定期恢复到备用主机。
-
原理:缩短硬件就绪时间,但数据仍通过运输同步。
-
RPO/RTO:数据丢失量=备份周期(天/周级);RTO≥24小时。
-
底层设计:

:SSTable 磁盘存储)











【题解】合集)





