1、文件读写操作(常用于日志处理、数据导入导出)
1、代码示例
(1)读取文本文件内容
with open("data.txt", "r", encoding="utf-8") as f:content = f.read()print(content)
(2)写入内容到文件
with open("output.txt", "w", encoding="utf-8") as f:f.write("这是要写入的内容\n")f.write("第二行内容")
2、实际用途
- 日志记录
- 数据导入/导出(如CSV、TXT)
- 配置文件读写
2、目录与文件管理(常用于自动化脚本)
1、代码示例
示例:创建目录、列出目录下所有文件。
import os# 创建目录(如果不存在创建目录,存在则跳过)
os.makedirs("backup", exist_ok=True)# 列出当前目录下的所有文件
for file in os.listdir("."):if os.path.isfile(file):print(file)
示例:查看指定目录下的所有文件
import os# 指定目录路径
directory = "/path/to/your/folder"for file in os.listdir(directory):full_path = os.path.join(directory, file) # 获取完整路径
if os.path.isfile(full_path): # 判断是否是文件
# if os.path.isfile(full_path) and file.endswith(".txt"): # 仅列出txt结尾的文件print(file)
2、实际用途
- 自动备份脚本
- 文件批量处理
- 清理无用文件
3、时间处理(常用于日志、任务调度)
1、代码示例
示例:获取当前时间并格式化输出。
from datetime import datetimenow = datetime.now()
print("当前时间1:", now)
formatted_time = now.strftime("%Y-%m-%d %H:%M:%S")
print("当前时间2:", formatted_time)
运行结果:

2、实际用途
- 记录操作时间戳
- 定时任务执行判断
- 生成带时间的文件名(如log_20250620.log)
4、正则表达式(常用于文本解析、数据提取)
1、代码示例
示例:从字符串中提取邮箱地址。
import retext = "联系我: john.doe@example.com或support@company.co.cn"
emails = re.findall(r"[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+", text)
print(emails)
运行结果:

2、实际用途
- 爬虫提取网页信息
- 用户输入校验(如手机号、身份证号)
- 日志分析提取关键字段
5、网络请求(常用于API接口调用)
1、代码示例
示例:发送GET请求获取网页内容。
import requestsresponse = requests.get("https://jsonplaceholder.typicode.com/posts/1")
if response.status_code == 200:data = response.json()print(data["title"])
else:print("请求失败")
运行结果:

说明:
如果提示找不到requests,则需要安装一下requests的依赖,如:

扩展:发送一个POST/JSON请求。
# POST请求示例
url = "https://jsonplaceholder.typicode.com/posts"
# 要发送入参的JSON数据
data = {"title": "我的新文章","body": "这是文章的内容。","userId": 1
}
# 设置请求头(可选),标明发送的是JSON数据
headers = {"Content-Type": "application/json"
}
# 发送POST请求
response = requests.post(url, json=data, headers=headers)
# 检查响应状态码
if response.status_code == 201: # 201 表示资源创建成功print("请求成功!响应数据如下:")print(response.json()) # 输出返回的 JSON 数据
else:print(f"请求失败,状态码:{response.status_code}")
print(response.text)
运行结果:

2、实际用途
- 调用第三方接口获取数据(天气、股票、支付等)
- 微服务之间通信
- Web抓取(爬虫)
6、JSON处理(常用于前后端交互)
1、代码示例
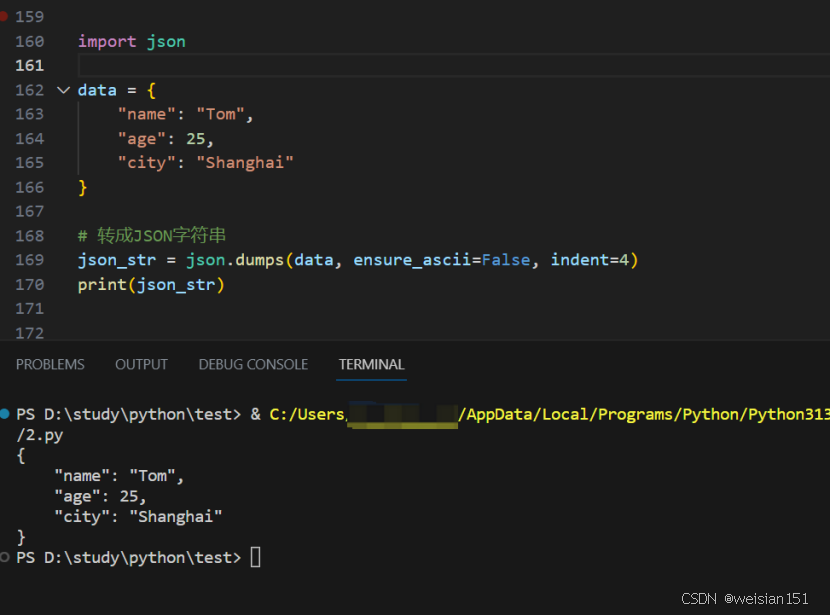
示例:将字典转为 JSON 字符串,并保存到文件。
import jsondata = {"name": "Tom","age": 25,"city": "Shanghai"
}# 转成JSON字符串
json_str = json.dumps(data, ensure_ascii=False, indent=4)
print(json_str)# 写入文件
with open("user.json", "w", encoding="utf-8") as f:f.write(json_str)
运行结果:
2、实际用途
- 前后端数据交换(RESTful API)
- 存储结构化配置
- 缓存中间结果
7、数据处理(常用于数据分析、清洗)
1、代码示例
示例:使用Pandas读取CSV并筛选数据。
import pandas as pd# 读取CSV文件
df = pd.read_csv("sales.csv")# 筛选销售额大于1000的记录
high_sales = df[df['amount'] > 1000]# 输出前5条
print(high_sales.head())
2、实际用途
- 数据清洗、统计分析
- 报表生成
- 机器学习预处理
8、日志记录(常用于调试和运维)
1、代码示例
示例:记录程序运行日志。
import logging# 配置日志格式
logging.basicConfig(filename="app.log",format="%(asctime)s [%(levelname)s] %(message)s",level=logging.INFO
)logging.info("程序启动成功")
logging.warning("这是一个警告")
logging.error("发生了一个错误")
2、实际用途
- 调试程序问题
- 运维监控
- 记录用户行为
9、多线程 / 异步(常用于并发任务)
1、代码示例
示例:使用threading启动多个线程。
import threading
import timedef worker(name):print(f"线程{name}开始")time.sleep(2)print(f"线程{name}结束")threads = []
for i in range(3):t = threading.Thread(target=worker, args=(i,))threads.append(t)t.start()for t in threads:t.join()
运行结果:

2、实际用途
- 提升 I/O 密集型任务效率(如网络请求、文件读写)
- 多任务并行处理
10、装饰器(常用于权限控制、函数增强)
1、代码示例
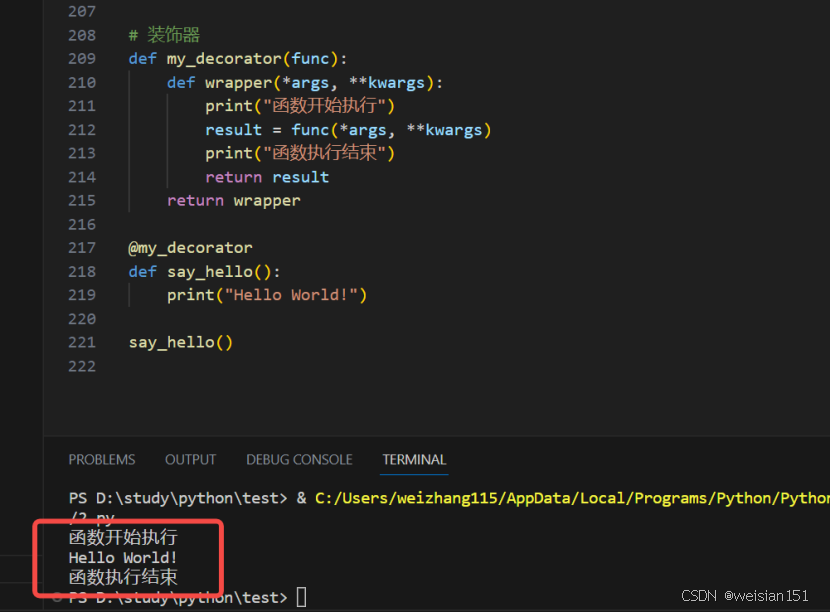
示例:定义一个简单的装饰器。
类似Java中,Spring AOP对目标方法的增强。
def my_decorator(func):def wrapper(*args, **kwargs):print("函数开始执行")result = func(*args, **kwargs)print("函数执行结束")return resultreturn wrapper@my_decorator
def say_hello():print("Hello World!")say_hello()
运行结果:
2、实际用途
- 权限检查
- 性能计时
- 日志记录
- 缓存机制
11、下载网页内容并保存到本地
示例:使用requests获取百度首页内容,并保存为baidu.html
import requests
import os
from urllib.parse import urljoin# 请求百度首页
url = "https://www.baidu.com"
response = requests.get(url)# 自动检测编码,解决中文乱码问题
response.encoding = response.apparent_encoding# 保存HTML到本地
html_file = "baidu.html"
with open(html_file, "w", encoding="utf-8") as f:f.write(response.text)print("✅ 百度首页已保存为 baidu.html")# 可选:下载图片(这里只做简单演示,仅下载第一个 <img> 标签中的图片)
from bs4 import BeautifulSoupsoup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img")if img_tags:# 创建图片保存目录img_dir = "baidu_images"os.makedirs(img_dir, exist_ok=True)first_img_url = img_tags[0]["src"]# 拼接成绝对 URLimg_url = urljoin(url, first_img_url)print(f"📥 正在下载第一张图片: {img_url}")img_response = requests.get(img_url)img_name = os.path.basename(first_img_url)with open(os.path.join(img_dir, img_name), "wb") as img_file:img_file.write(img_response.content)print(f"✅ 图片已保存为 {os.path.join(img_dir, img_name)}")# 可选:修改 HTML 中的 img src 路径为本地路径new_img_path = os.path.join(img_dir, img_name)with open(html_file, "r", encoding="utf-8") as f:html_content = f.read()html_content = html_content.replace(first_img_url, new_img_path)with open(html_file, "w", encoding="utf-8") as f:f.write(html_content)print("🖼️ HTML 中的图片路径已更新为本地路径")
else:
print("⚠️ 页面中未找到图片")
运行结果:

打开网页:

向阳而生,Dare To Be!!!


、地图打印(webprinting)等服务)
全面指南:从基础到实战)

集群搭建 + 原理解释)







【10】之DDD战术模式:工厂模式与表意接口模式)


)


