目录
3D视觉感知任务
单目3D感知
单目3D物体检测 – 直接预测3D信息
单目3D物体检测 – 总结
单目深度估计
双目3D感知
多目3D感知
3D视觉感知任务
输入:单摄像头或多摄像头生成的图像数据
单张图像
图像序列
输出
稀疏:物体在3D坐标系中的位置,大小,朝向,速度等
稠密:像素点的类别标签和深度信息
算法
按输入来分:单目,双目,多目
按输出来分:3D物体检测,场景深度估计

主要难点
图像是真实世界在透视视图下的投影
透视投影导致距离/深度信息丢失
图像上物体的大小随着距离而变化
很难估计物体的实际距离和大小
解决方案
借助其它传感器,比如激光雷达
借助几何假设和约束来辅助求解病态问题
借助深度学习自动地从图像中提取 3D 信息
借助多个摄像头和立体视觉算法

单目3D感知
单目3D物体检测
反变换
关键点和3D模型
2D/3D几何约束
直接预测 3D 信息
单目深度估计
监督学习算法

单目 3D 物体检测 – 反变换
基本思路
2D图像反变换到3D世界坐标,再进行物体检测
病态问题:通过一些额外信息来辅助解决
几何假设:目标位于地面(Oy已知 )
深度估计:目标深度已知(Oz已知)
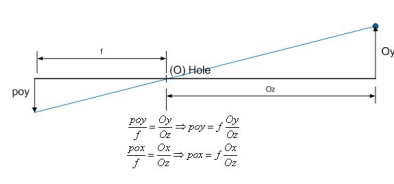
病态问题:已知[ pox,poy ]和 𝑓 ,求解[o x,oy,oz ]
辅助信息1:目标位于地面
BEV-IPM:2D图像变换到BEV视图
假设路面和车辆坐标系都与世界坐标系平行 => 路面高度已知
在像素高度值已知的情况下,将图像转换到BEV视图
采用YOLO网络在BEV视图下检测目标的下边框(与路面接触部分)

助信息2:目标深度已知
Pseudo-LiDAR
依据深度图将输入图像转换为3D点云数据
深度估计不依赖于特定的方法
可以采用单目,双目,甚至低线束激光雷达(Pseudo-LiDAR++)
采用点云和图像融合的算法来检测3D物体
深度估计的精度非常关键

Wang et al., Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving, CVPR 2019
辅助信息2:目标深度已知
问题:可不可以直接采用类似RGB-D的数据表示呢?
远处物体面积非常小,导致检测不准确
相邻像素深度差别可能很大( 比如物体边缘),不适合卷积操作

基本思路
待检测的目标(比如车辆)其大小和形状相对比较固定
将3D模型与2D图像上检测的关键点进行匹配
单目 3D 物体检测 – 关键点和 3D 模型
DeepMANTA(3D车辆检测)
2D图像上的检测输出
2D边框 𝑩𝑩
2D关键点集合 𝑺𝑺 和可见度 𝑽𝑽
与3D模型的相似度 𝑻𝑻
根据 𝑻𝑻 选择相似度最高的3D模型(相当于选择一个车型)
匹配3D模型和2D输出的关键点,得到3D关键点 𝑺𝑺 𝟑𝟑𝟑𝟑 和边框 𝑩𝑩 𝟑𝟑𝟑𝟑
每一对( 𝑺𝑺 𝟑𝟑𝟑𝟑 , 𝑺𝑺 𝟐𝟐𝟐𝟐 )可以得到一个匹配度
基本思路
2D物体框的表示
4维变量:2D的中心点和大小
3D物体框的表示
9维变量:3D的中心点,大小和朝向
无法直接通过2D物体框求解
大小和朝向与视觉特征相关性强
中心点3D位置很难通过视觉特征预测
两步流程
采用2D物体框内的图像特征来估计物体大小和朝向
通过2D/3D的几何约束来求解物体3D中心点的位置
Deep3DBox
约束条件:2D物体框的每条边上都至少能找到一个3D物体框的角点。
超约束问题:约束数量(4个)大于未知参数(3个)数量。
这个超约束问题的求解过程也可以建模成一个网络层,进行端到端训练
单目3D物体检测 – 直接预测3D信息
基本思路
两阶段检测,Anchor-based
根据先验知识生成稠密的3D物体候选
通过2D图像上的特征对所有的候选框进行评分
评分高的候选框作为最终的输出
单阶段检测,Anchor-free
直接从图像回归3D信息
根据先验知识设定物体3D参数的初始值
神经网络只需要回归与实际值的偏差即可
两阶段检测
Mono3D
基于目标先验位置(z坐标位于地面)和大小来生成稠密的3D候选框;
3D候选框投影到图像坐标后,通过2D图像上特征进行评分;
特征来自语义分割、实例分割、上下文、形状以及位置先验信息;
分数较高的候选再通过CNN进行分类和边框回归,以得到最终的3D物体框
两阶段检测,Anchor-based
TLNet
稠密的Anchor带来巨大的计算量;
采用2D图像上的检测结果来降低Anchor数量;
2D检测结果形成的3D视锥可以过滤掉大量背
景上的Anchor。
单阶段检测,Anchor-free
FCOS3D
整体网络结构与2D物体检测非常相似,只是增加了3D回归目标
单阶段检测,Anchor-free
FCOS3D
3D回归目标
• 2.5D中心(ΔX, ΔY,Depth): 3D物体框的中心投影到2D图像;
• 3D大小(L,W,H)和朝向
单阶段检测,Anchor-free
FCOS3D
Centerness的定义
•
以 3D 中心点的 2D 投影为原点的高斯分布

单目3D物体检测 – 总结

单目深度估计
为什么要做深度估计
3D物体检测中经常需要深度估计的辅助
3D场景语义分割需要估计稠密的深度图
基本思路
输入:单张图像
输出:单张图像(一般与输入相同大小),每个像素值
对应输入图像的场景深度
常用的方法
传统方法:利用几何信息,运动信息等线索,通过手工设计
的特征来预测像素深度
深度学习:通过训练数据学习到比手工设计更加优越的特征
全局和局部线索融合
全局分支:将图像进行多层卷积和下采样,得到整个场景的描述特征。
局部分支:在相对较高的分辨率上提取局部特征,并与全局特征融合。
也可以扩展为多个分支,对应不同的分辨率
DORN:回归问题转换为分类问题
多个分支提取不同尺度的特征:全局+局部
将连续的深度值划分为离散的区间,每个区间作为一个类别
非均匀的深度区间划分(80m范围划分大约 40到120个区间)
双目3D感知
优势
单目3D感知依赖于先验知识和几何约束;
深度学习的算法非常依赖于数据集的规模、质量以及多样性;
双目系统解决了透视变换带来的歧义性;
双目感知不依赖于物体检测的结果,对任意障碍物均有效。
劣势
硬件:摄像头需要精确配准,车辆运行过程中也要始终保持配准的正确性;
软件:算法需要同时处理来自两个摄像头的数据,计算复杂度较高
双目深度估计
基本原理
概念和公式
B: 基线长度(两个相机之间的距离)
f: 相机的焦距
d: 视差(左右两张图像上同一个3D点之间的距离)
f和B是固定的,要求解深度z,只需要估计视差d (xl-xr)


基本原理
视差估计:对于左图中的每个像素点,需要找到右图中与其匹配的点。
对于每一个可能的视差(范围有限),计算匹配误差,因此得到的三维的误差数据称为Cost Volume。
计算匹配误差时考虑像素点附近的局部区域,比如对局部区域内所有对应像素值的差进行求和。
通过Cost Volume可以得到每个像素处的视差(对应最小匹配误差的 𝑑𝑑 ),从而得到深度值
PSMNet
左右图像上采用共享的卷积网络进行特征提取
包含下采样,金字塔结构和空洞卷积来提取多分辨率的信息并且扩大感受野
左右特征图构建Cost Volume
3D卷积提取左右特征图以及不同视差级别之间的信息
上采样到原始分辨率,找到匹配误差最小的视差值
多目3D感知
Mobileye和ZF的三目系统
通过不同焦距的摄像头来覆盖不同范围的场景
包含一个150°的广角摄像头,一个52°的中距摄像头和一个28°的远距摄像头
保证中近距的探测视野和精度,用于检测车辆周边的环境
最远探测距离可以达到300米
Foresight的四目感知系统
增加不同波段的传感器,获取更多的环境信息
可见光双目摄像头 + 长波红外(LWIR)双目摄像头
增强了在夜间环境以及在雨雾天气下的适应能力
双目红外摄像头安装在挡风玻璃的左右两侧,以增加基线长度
Tesla的多目全景感知系统 FSD(Full Self Driving)
不同位置,不同探测范围的摄像头,覆盖360度视场
集成了深度学习领域的最新研究成果,在多摄像头融合方面也很有特点
“向量空间”的概念
环境中的各种目标在世界坐标系中的表示空间;
对于物体检测任务,目标在3D空间中的位置、大小、朝向、速度等描述特性组成了一个向量;
对于语义分割任务,车道线或者道路边缘的参数化描述组成了一个向量;
所有描述向量组成的空间就是向量空间。
视觉感知系统的任务:将图像空间转化为向量空间
决策层融合(后融合)
在图像空间中完成所有的感知任务,将结果映射到向量空间,最后融合多摄像头的感知结果。
特征层融合(前融合)
将图像特征转换到世界坐标系,融合来自多个摄像头的特征,最后得到向量空间中的感知结果
)


:2022年12月2023年12月)






)




)
)


