索引结构
概述
MySQL 的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持 B+ 树索引 |
| Hash索引 | 底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES |
MySQL 中所支持的所有的索引结构,接下来,我们再来看看不同的存储引擎对于索引结构的支持情况。
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
注意:我们平常所说的索引,如果没有特别指明,都是指B+树结构组织的索引。
具体实现
B-Tree与B+Tree
B-Tree
B-Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。
以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key,5个指针:

B+Tree
B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4(4阶)的b+tree为例,来看一下其结构示意图:
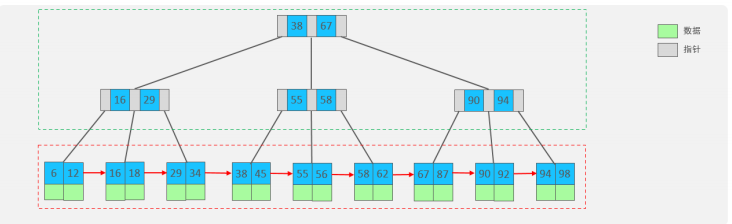
我们可以看到,两部分:
绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
B+Tree 与 B-Tree 的区别
最终我们看到,B+Tree 与 B-Tree 相比,主要有以下三点区别:
所有的数据都会出现在叶子节点。
叶子节点形成一个单向链表。
非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
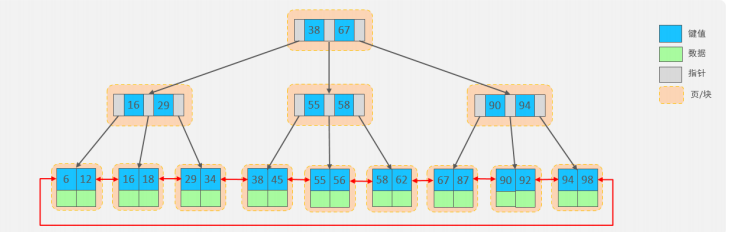
上述我们所看到的结构是标准的 B+Tree 的数据结构,接下来,我们再来看看 MySQL 中优化之后的 B+Tree。
MySQL 索引数据结构对经典的 B+Tree 进行了优化。在原 B+Tree 的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的 B+Tree,提高区间访问的性能,利于排序。
页(Page)的概念与作用
在关系型数据库(如 MySQL InnoDB、Oracle、SQL Server 等)中,最常用的索引结构是 B+ 树(或其变种)。B+ 树索引在磁盘或持久化存储上,都是以“页(page)”为最小 I/O 单元来管理的。
页(Page)是什么?
页(也称数据页、块 block)是数据库读写时的最小单位,典型大小为 4 KB、8 KB 或 16 KB。
每个页在内存中对应一个缓冲区帧(buffer frame),从磁盘读入时,整个页一起加载;修改时,整个页也会被标记为“脏页”并迟缓写回。
为什么要用页?
I/O 单元:磁盘和 OS 的 I/O 都是按页(或块)做的,读写整页比逐条读写要高效得多。
缓存管理:数据库的 Buffer Pool 也是以页为单位进行加载和置换。
空间管理:页作为固定大小的容器,便于分配、回收和查找空闲空间。
B+ 树的逻辑结构与页的映射
┌───────────┐┌──────▶│ Internal │◀──────┐│ │ page(s) │ ││ └───────────┘ │┌──┴──┐ ┌───┴──┐│ ... │ │ ... │└──┬──┘ └───┬──┘│ ┌───────────┐ │└──────▶│ Leaf page │◀──────┘└───────────┘
内部节点(Internal node)对应一个或多个页
存放 键值 + 子节点指针(页号或内存指针)。
用于路由查找:从根开始,根据键值范围逐层向下定位到叶子页。
叶子节点(Leaf node) 对应一系列连续页
真正存放 完整的索引记录 或 聚簇索引的全行数据。
通常包含:
索引键(Key)
若是非聚簇索引,则附带 主键 作为“行定位指针”;
若是聚簇索引(Clustered Index),叶子页直接存放整行数据。
页之间的链表
叶子页还会双向链成一个链表,方便范围扫描;
内部节点页在分裂/合并时,也可能维护兄弟指针或在父节点更新。
页内记录的组织
页头(Header)
存放页类型(内部/叶子)、当前记录数、Free Space 指针、链表指针(前驱/后继页号)等元信息。
记录目录(Slot Array)
有些数据库(如 InnoDB)在页尾维护一个 Slot Array,存放每条记录在页内的偏移。
插入/删除只需调整 Slot Array 及相应记录位置,避免大量移动。
记录存储(Record Storage)
记录以物理或逻辑顺序(根据索引键)存储在页的主体区域。
有的系统支持 前缀压缩:只存储键的增量部分,减少空间。
空闲空间管理(Free Space)
页头维护一个指向空闲区(free space)的指针;新记录优先填满空闲区,再触发分裂。
页分裂与合并
页分裂(Page Split)
触发:当插入一条记录到已无足够空闲空间的叶子页或内部页时。
过程:
分配一个“同级”新页;
将原页中大约一半偏后的记录(或指针)移动到新页;
在父节点中插入一个新的键和指向新页的指针;若父页也满,则递归向上分裂。
影响:
写放大:要写两个页(原页&新页)及更新父页;
碎片化:原本连续的逻辑键可能跨两个页,影响范围扫描的 I/O 连续性;
内存/缓存抖动:新页要加载到内存,可能驱逐其他页面。
页合并(Page Merge)
触发:当删除操作导致某页的记录数低于某个阈值(例如空闲空间过大),并且相邻页也较空时。
过程:把两个兄弟页的记录合并到一页,释放一个页号,并相应在父节点删除指针;若父节点太空,也可递归向上合并。
顺序 vs. 随机主键对页分裂的影响
顺序主键(自增、时间戳)
新记录总插入到叶子页的最右端,
只会在最右页“尾部”分裂;
降低对中间页的频繁分裂,保证大部分页都被顺序填满。
随机/无序主键(UUID、散列)
每次插入可以分散到任何叶子页,
导致各页随机“爆满”并分裂,
频繁触发分裂,带来更高的写放大和碎片率。
索引分类
索引分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
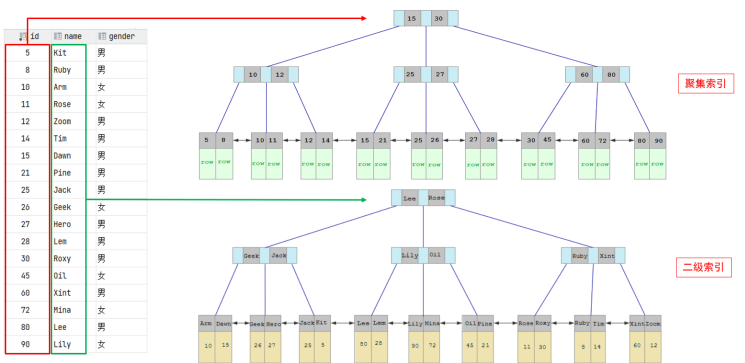
聚集索引 & 二级索引
而在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 (Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引 (Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一 (UNIQUE) 索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引。
查找过程-回表查询
接下来,我们来分析一下,当我们执行如下的SQL语句时,具体的查找过程是什么样子的
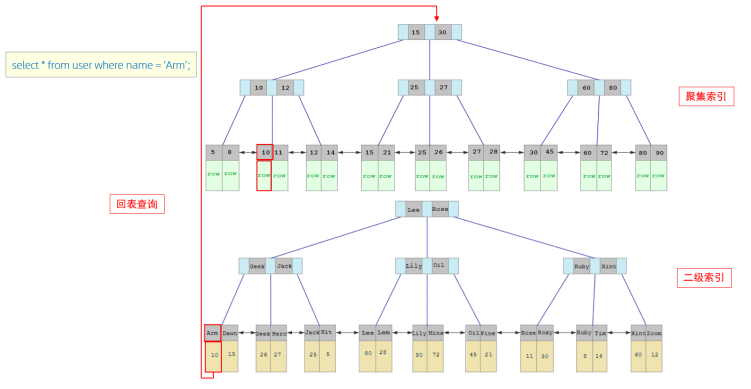
具体过程如下:
①. 由于是根据name字段进行查询,所以先根据name='Arm'到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到Arm对应的主键值10。
②. 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。
③. 最终拿到这一行的数据,直接返回即可。
这个过程也称为回表查询
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取
数据的方式,就称之为回表查询。
HTML零基础教学)
)


 ✨ | DoubleClickHeart(双击爱心))













![[逆向工程]160个CrackMe入门实战之Afkayas.1.Exe解析(二)](http://pic.xiahunao.cn/[逆向工程]160个CrackMe入门实战之Afkayas.1.Exe解析(二))
