引言
在当今数据驱动的商业环境中,企业面临着日益复杂的决策问题。传统的数据分析工具往往难以应对多步骤、多依赖的复杂问题求解。例如,当企业需要分析"北美市场 Q1-Q2 主要产品的销售增长趋势并识别关键驱动因素"时,传统工具可能需要人工依次完成数据收集、清洗、分析、可视化等多个环节,不仅效率低下,还容易因人为因素导致误差。
本文介绍一种基于 Planning Agent 的智能规划引擎,它通过目标理解、任务分解、动态规划和自适应执行等核心技术,实现了复杂问题的端到端求解。从代码执行记录可以看到,该引擎成功处理了 “分析北美市场 Q1-Q2 主要产品销售增长趋势” 这一复杂查询,自动完成了从数据获取到最终洞察生成的全流程,展现出强大的复杂问题处理能力。
传统方案的痛点与Planning Agent的解决方案
| 痛点领域 | 普通Agent/Workflow Agent | Planning Agent解决方案 | Planning Agent技术优势 |
|---|---|---|---|
| 灵活性 | 固化流程难以适应动态需求 | 动态规划与实时调整 | • 任务自动分解与排序 • 执行中动态调整策略 • 基于反馈的流程优化 |
| 复杂依赖处理 | 手动定义依赖易错难维护 | 智能依赖解析与检查 | • 依赖关系自动推导 • 运行时依赖状态监控 • 并行无依赖任务执行 |
| 错误恢复 | 单点失败导致全局中断 | 多级容错机制 | • 步骤级参数调整重试 • 计划级任务重构 • 全局级流程重启 |
| 知识复用 | 缺乏自我优化能力 | 反射性经验积累 | • 执行历史分析 • 错误模式识别 • 策略知识库构建 |
| 复杂任务处理 | 简单指令到复杂执行的鸿沟 | 分层规划架构 | • 目标理解→任务分解→步骤规划 • 多粒度问题求解 • 抽象到具体的渐进细化 |
系统架构概览
总体流程
Planning Agent 的核心架构采用分层设计,形成完整的 “理解 - 规划 - 执行 - 反思” 闭环:
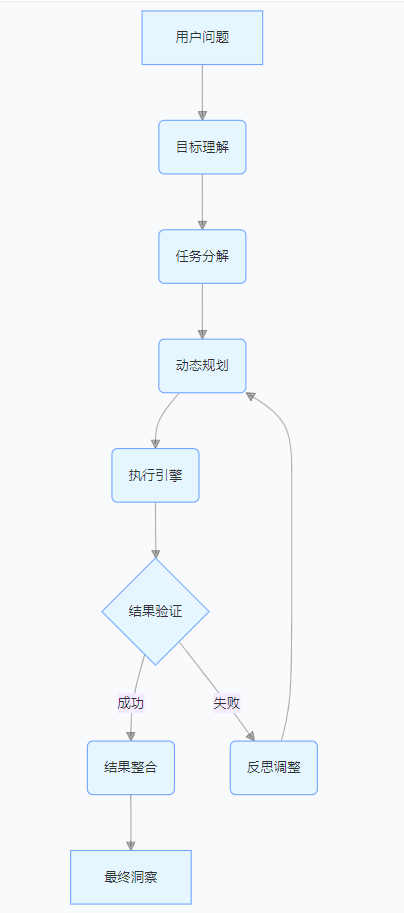
从实际执行流程来看,用户查询首先经过目标理解模块转化为结构化目标,然后分解为一系列原子任务,接着生成详细的执行计划,由执行引擎按计划执行并实时验证结果,若失败则触发反思调整机制,最终将所有结果整合为有价值的洞察报告。这种架构确保了系统能够处理复杂的依赖关系和动态变化的执行环境。
细化流程
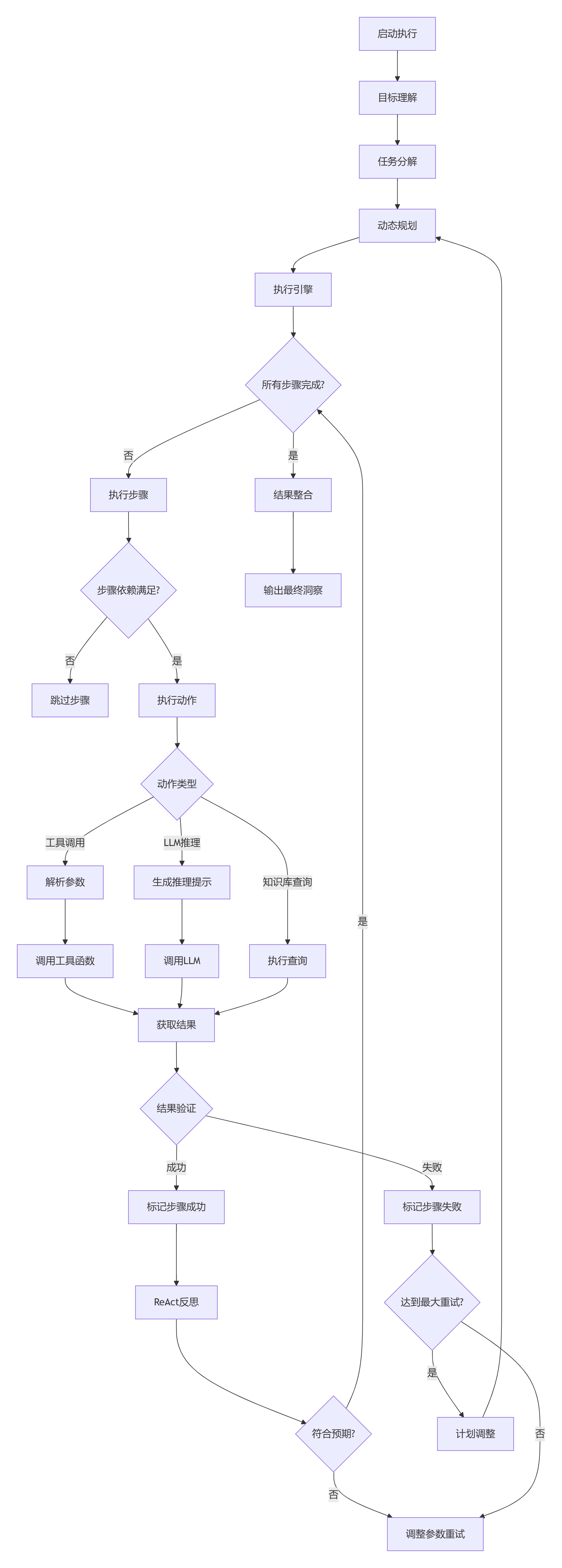
主流程
子流程定义

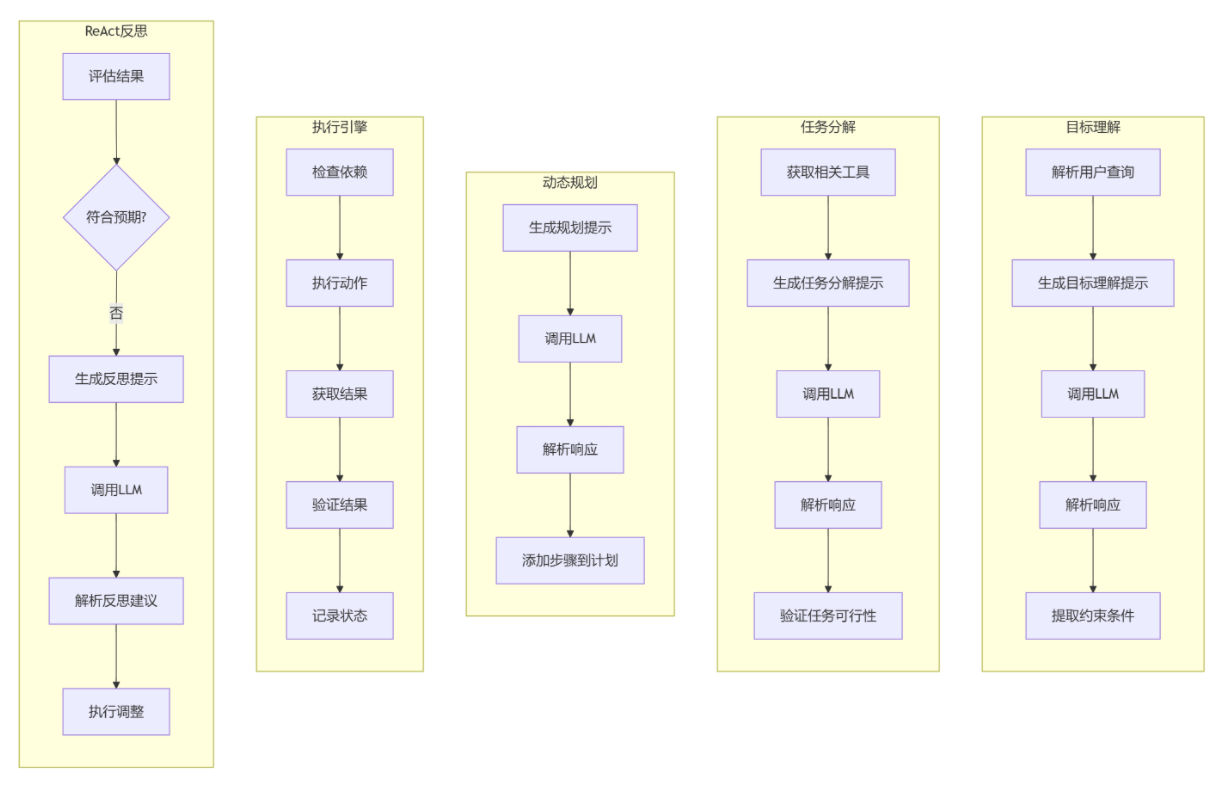
- 核心工作流程系统启动后依次执行:目标理解 → 任务分解 → 动态规划 → 执行引擎 → 结果整合 → 输出最终洞察,形成完整的任务处理流水线。其中执行引擎阶段通过循环执行步骤直至所有任务完成。
- 执行引擎细节
检查步骤依赖关系:满足则执行动作,否则跳过
支持三种动作类型:
工具调用:解析参数→调用工具函数
LLM推理:生成提示→调用大模型
知识库查询:直接执行检索
统一结果处理:获取结果 → 验证 → 标记状态 - 自修复机制
结果验证失败时:
未达重试上限:调整参数后重试
达到重试上限:触发计划调整(调用LLM生成新任务→更新列表→重新规划)
成功步骤需经ReAct反思:
符合预期则继续执行
不符合则触发参数调整重试 - 关键子模块功能
目标理解:解析用户查询→生成提示→调用LLM→提取约束条件
任务分解:工具检索→LLM分解任务→可行性验证
动态规划:LLM生成计划→解析响应→构建执行步骤
ReAct反思:评估结果→生成反思提示→LLM建议调整
计划调整:LLM重构任务→更新任务列表→重新规划
结果整合:LLM摘要生成→最终洞察输出 - 系统特性
LLM深度集成:所有核心模块都依赖大模型处理 双层容错设计:参数级重试 + 计划级重构
状态驱动执行:每个步骤都经历"执行→验证→状态标记"流程 闭环反馈机制:反思环节实时优化后续执行策略
完整代码:
废话不多说,先看代码实现:
import json
import re
import datetime
import time
import logging
from typing import Dict, List, Callable, Any, Tuple, Optional, Union
from enum import Enum
import requests
from tenacity import retry, stop_after_attempt, wait_exponential
from openai import OpenAI
import inspectclient = OpenAI(api_key="sk-xxx", base_url="https://xxx.openai.com/v1")logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger("PlanningAgent")# 模拟工具分类
class ToolCategory(Enum):"""工具分类枚举"""DATA_ACCESS = "数据访问" # 数据库查询、API获取等ANALYSIS = "分析计算" # 数据处理、指标计算等VALIDATION = "验证检查" # 数据验证、约束检查PLANNING = "规划决策" # 决策支持、方案生成COMMUNICATION = "通信集成" # 外部系统交互class PlanStatus(Enum):"""执行计划状态枚举"""PENDING = "待执行"SUCCESS = "成功"FAILED = "失败"RETRYING = "重试中"ADJUSTED = "已调整"class ExecutionPlan:"""执行计划实体类"""def __init__(self):self.steps: List[Dict] = []self.context: Dict[str, Any] = {}self.execution_history: List[Dict] = []self.retry_count: int = 0self.max_retries: int = 3self.status: PlanStatus = PlanStatus.PENDINGdef add_step(self, step: Dict):"""添加执行步骤"""step["status"] = PlanStatus.PENDING.valuestep["timestamp"] = ""step["result"] = Nonestep["attempts"] = 0step["error"] = Noneself.steps.append(step)def update_step(self, step_id: str, status: PlanStatus, result: Any = None, error: str = None):"""更新步骤状态"""for step in self.steps:if step.get("step_id") == step_id:step["status"] = status.valuestep["timestamp"] = datetime.datetime.now().isoformat()step["attempts"] += 1step["result"] = resultstep["error"] = errorbreakdef log_execution(self, message: str, data: Any = None, level: str = "INFO"):"""记录执行日志"""entry = {"timestamp": datetime.datetime.now().isoformat(),"message": message,"data": data,"level": level}self.execution_history.append(entry)getattr(logger, level.lower())(f"{message} - {json.dumps(data, ensure_ascii=False)[:500] if data else ''}")class PlanningAgent:"""生产级Planning-Driven智能代理"""def __init__(self, tools: Dict[str, Dict], knowledge_base: Any,api_key: str = None):"""初始化智能体:param tools: 可用工具集 {工具名: {"func": 函数, "category": 工具类别, "max_retries": 最大重试次数}}:param knowledge_base: 知识库连接或接口:param api_key: OpenAI API密钥"""self.tools = toolsself.knowledge_base = knowledge_baseself.api_key = api_keyself.plans: Dict[str, ExecutionPlan] = {}self.max_global_retries = 5for name, config in self.tools.items():if not callable(config.get("func")):raise ValueError(f"工具 '{name}' 未配置可调用函数")func = config["func"]sig = inspect.signature(func)param_desc = []for param_name, param in sig.parameters.items():param_info = {"name": param_name,"type": param.annotation.__name__ if param.annotation else "any","required": param.default == param.empty}if param.default != param.empty:param_info["default"] = param.defaultparam_desc.append(param_info)config["parameter_description"] = param_desc@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=1, max=10))def llm_predict(self, prompt: str, model: str = "gpt-4.1-mini", max_tokens: int = 2000) -> str:"""调用OpenAI API进行预测(兼容新版API)"""try:response = client.chat.completions.create(model=model,messages=[{"role": "system", "content": "你是一个专家级规划助手"},{"role": "user", "content": prompt}],max_tokens=max_tokens,temperature=0.3)return response.choices[0].message.content.strip()except Exception as e:logger.error(f"OpenAI API调用失败: {str(e)}")raisedef run(self, session_id: str, user_query: str) -> str:"""执行主流程"""self.plans[session_id] = ExecutionPlan()current_plan = self.plans[session_id]try:# 1. 目标理解goal = self.understand_goal(user_query, current_plan)current_plan.context['goal'] = goal# 2. 任务分解tasks = self.decompose_tasks(goal, current_plan)current_plan.context['tasks'] = tasks# 3. 动态规划self.dynamic_planning(tasks, current_plan)# 4. 执行引擎results = self.execute_plan(current_plan)# 5. 结果整合final_result = self.integrate_results(goal, results, current_plan)return final_resultexcept Exception as e:current_plan.status = PlanStatus.FAILEDerror_msg = f"执行失败: {str(e)}"current_plan.log_execution(error_msg, level="ERROR")return error_msgdef understand_goal(self, query: str, plan: ExecutionPlan) -> Dict:"""深度理解用户目标"""prompt = GoalUnderstandingPrompt(query).generate()response = self.llm_predict(prompt)plan.log_execution("目标理解请求", prompt)plan.log_execution("目标理解响应", response)parsed = self.parse_llm_response(response, "goal")plan.context['parsed_goal'] = parsed# 识别约束条件constraints = self.extract_constraints(parsed, query)plan.context['constraints'] = constraintsplan.log_execution("目标约束", constraints)return parseddef decompose_tasks(self, goal: Dict, plan: ExecutionPlan) -> List[Dict]:"""任务分解"""task_types = goal.get("task_types", ["analysis", "data_retrieval"])relevant_tools = self.get_relevant_tools(task_types)prompt = TaskDecompositionPrompt(goal, relevant_tools).generate()response = self.llm_predict(prompt)plan.log_execution("任务分解请求", prompt)plan.log_execution("任务分解响应", response)tasks = self.parse_llm_response(response, "tasks")# 验证任务可行性for task in tasks:tool_name = task.get("tool")if tool_name and tool_name not in self.tools:plan.log_execution(f"任务使用不可用工具 '{tool_name}'", task, "WARNING")return tasksdef dynamic_planning(self, tasks: List[Dict], plan: ExecutionPlan):"""动态规划器"""prompt = PlanningPrompt(tasks, list(self.tools.keys()), self.tools).generate()response = self.llm_predict(prompt)plan.log_execution("规划请求", prompt)plan.log_execution("规划响应", response)# 解析响应steps = self.parse_llm_response(response, "plan")# 添加步骤到执行计划for step in steps:plan.add_step(step)def execute_plan(self, plan: ExecutionPlan) -> Dict[str, Any]:"""执行引擎"""results = {}executed_steps = set()execution_cycle = 0while execution_cycle < self.max_global_retries:execution_cycle += 1plan.log_execution(f"开始执行轮次 #{execution_cycle}")all_completed = Truefor step in plan.steps:step_id = step["step_id"]# 跳过已成功完成的步骤if step["status"] == PlanStatus.SUCCESS.value and step_id in results:continue# 检查步骤依赖是否满足dependencies = step.get("dependencies", [])if not self.check_dependencies(dependencies, results):plan.log_execution(f"跳过步骤 {step_id} - 依赖未满足", dependencies)all_completed = Falsecontinuetry:result = self.execute_step(step, plan, results)step["result"] = resultresults[step_id] = resultplan.update_step(step_id, PlanStatus.SUCCESS, result)executed_steps.add(step_id)# ReAct反思:检查执行结果是否达到预期self.react_reflection(step, result, plan, results)except Exception as e:# 记录失败plan.update_step(step_id, PlanStatus.FAILED, error=str(e))plan.log_execution(f"步骤执行失败: {step_id}", {"error": str(e)}, "ERROR")if step["attempts"] < step.get("max_retries", plan.max_retries):plan.log_execution(f"准备重试步骤: {step_id}")plan.update_step(step_id, PlanStatus.RETRYING)time.sleep(1) continueelse:plan.log_execution(f"步骤 {step_id} 超过最大重试次数", step, "ERROR")all_completed = False# 检查所有步骤是否完成if all_completed:plan.log_execution("所有步骤成功完成")break# 检查是否需要调整计划self.plan_adjustment(plan, results, execution_cycle)return resultsdef execute_step(self, step: Dict, plan: ExecutionPlan, context: Dict) -> Any:"""执行单个步骤"""action = step["action"]step_id = step["step_id"]plan.log_execution(f"执行步骤: {step_id}", step)try:if action == "use_tool":tool_name = step["tool"]tool_config = self.tools.get(tool_name)if not tool_config:raise ValueError(f"工具 '{tool_name}' 未配置")tool_func = tool_config["func"]tool_params = inspect.signature(tool_func).parameters.keys()params = {}for param_name, param_value in step.get("params", {}).items():if param_name in tool_params:if isinstance(param_value, str) and param_value.startswith("$"):param_value = self.resolve_dynamic_value(param_value, context)params[param_name] = param_valueelse:plan.log_execution(f"忽略不支持参数 '{param_name}'", {"supported_params": list(tool_params)}, "WARNING")result = tool_config["func"](**params)if not self.validate_tool_result(tool_config.get("validator"), result, step):raise ValueError("工具结果验证失败")return resultelif action == "llm_reasoning":question = step["question"]prompt = ReasoningPrompt(plan.context['goal'], context, question).generate()response = self.llm_predict(prompt)reasoning_result = self.parse_reasoning_response(response)return reasoning_resultelif action == "query_kb":topic = step["topic"]# 实际应用中连接知识库# result = self.knowledge_base.query(topic, **step.get("params", {}))result = f"知识库查询: {topic}" # 模拟结果return resultelse:raise ValueError(f"未知动作类型: {action}")except Exception as e:plan.log_execution(f"步骤执行异常: {step_id}", {"error": str(e)}, "ERROR")raisedef react_reflection(self, step: Dict, result: Any, plan: ExecutionPlan, context: Dict):"""ReAct反思流程"""# 是否达到预期结果meets_expectation = self.evaluate_result(step, result, context)if meets_expectation:plan.log_execution(f"步骤 {step['step_id']} 结果符合预期")returnplan.log_execution(f"步骤 {step['step_id']} 结果不符合预期,触发反思", result, "WARNING")# 生成反思建议reflection_prompt = ReflectionPrompt(step, result, step.get("expected_outcome"),plan.context['constraints']).generate()reflection_response = self.llm_predict(reflection_prompt)reflection = self.parse_llm_response(reflection_response, "reflection")if reflection.get("adjust_action") == "retry":# 调整参数重试adjusted_params = reflection.get("adjusted_params", {})plan.log_execution("根据反思调整参数重试", adjusted_params)if "params" in step:step["params"].update(adjusted_params)plan.update_step(step["step_id"], PlanStatus.RETRYING)elif reflection.get("adjust_action") == "new_plan":# 需要创建新计划plan.log_execution("根据反思需要创建新计划")self.create_adjusted_plan(reflection, step, plan)def plan_adjustment(self, plan: ExecutionPlan, results: Dict, execution_cycle: int):"""计划调整器"""if execution_cycle >= plan.max_retries:plan.log_execution("达到最大重试次数,尝试整体调整计划")# 生成调整建议adjustment_prompt = PlanAdjustmentPrompt(plan.context['goal'],plan.context['tasks'],results,plan.execution_history).generate()adjustment_response = self.llm_predict(adjustment_prompt)plan.log_execution("计划调整响应", adjustment_response)new_tasks = self.parse_llm_response(adjustment_response, "tasks")if new_tasks:plan.log_execution("应用新的任务列表", new_tasks)plan.context['tasks'] = new_tasksplan.status = PlanStatus.ADJUSTED# 重新规划self.dynamic_planning(new_tasks, plan)else:plan.log_execution("未获得有效调整方案", level="WARNING")def integrate_results(self, goal: Dict, results: Dict, plan: ExecutionPlan) -> str:"""结果整合与洞察生成"""prompt = IntegrationPrompt(goal, results).generate()insight = self.llm_predict(prompt)try:structured_insight = json.loads(insight)plan.log_execution("生成结构化洞察", structured_insight)return structured_insightexcept:plan.log_execution("生成文本洞察", insight)return insightdef extract_constraints(self, goal: Dict, query: str) -> Dict:"""提取目标中的约束条件"""constraints = {"time": goal.get("time_constraint"),"quality": goal.get("quality_requirement", "高"),"resources": goal.get("required_resources", []),"security": "敏感数据" if "密码" in query or "密钥" in query else "普通"}return constraintsdef get_relevant_tools(self, categories: List[str]) -> List[str]:"""获取相关工具"""relevant = []for name, config in self.tools.items():if config.get("category") in categories:relevant.append(name)return relevantdef resolve_dynamic_value(self, value_ref: str, context: Dict) -> Any:"""解析动态参数值"""# 格式: $step_id.key 或 $context.keyif value_ref.startswith("$step:"):step_id, key = value_ref[6:].split(".", 1)return context.get(step_id, {}).get(key)elif value_ref.startswith("$context:"):key = value_ref[9:]return context.get(key)return value_refdef validate_tool_result(self, validator: Callable, result: Any, step: Dict) -> bool:"""验证工具结果"""if validator:return validator(result)return result is not Nonedef check_dependencies(self, dependencies: List[str], results: Dict) -> bool:"""检查步骤依赖是否满足"""for dep in dependencies:if dep not in results or results.get(dep) is None:return Falsereturn Truedef evaluate_result(self, step: Dict, result: Any, context: Dict) -> bool:"""评估结果是否满足预期"""if "validator" in step:return step["validator"](result, context)return result is not Nonedef parse_llm_response(self, response: str, response_type: str) -> Any:"""解析LLM响应"""try:json_match = re.search(r'```json\n(.*?)\n```', response, re.DOTALL)if json_match:return json.loads(json_match.group(1))return json.loads(response)except:logger.warning(f"无法解析LLM响应为JSON: {response[:100]}...")if response_type == "goal":return {"description": response}elif response_type == "tasks":return [{"task_id": "default", "description": response}]elif response_type == "plan":return [{"step_id": "s1", "action": "llm_reasoning", "question": response}]else:return responsedef parse_reasoning_response(self, response: str) -> Dict:"""解析推理响应"""reasoning = {"process": "","conclusions": [],"uncertainties": []}if "推理过程:" in response:reasoning["process"] = response.split("推理过程:")[1].split("结论:")[0].strip()if "结论:" in response:reasoning["conclusions"] = [c.strip() for c in response.split("结论:")[1].split(";")]return reasoningclass BasePrompt:"""提示词基础类"""SYSTEM_MESSAGE = "你是一个专家级规划助手,擅长将复杂问题分解为可执行的步骤并制定优化的执行计划。"def __init__(self):self.messages = [{"role": "system", "content": self.SYSTEM_MESSAGE}]def generate(self) -> str:"""生成完整的提示词内容"""return self.messages[-1]["content"] if self.messages else ""def add_user_message(self, content: str):self.messages.append({"role": "user", "content": content})def add_assistant_message(self, content: str):self.messages.append({"role": "assistant", "content": content})class GoalUnderstandingPrompt(BasePrompt):"""目标理解提示词"""def __init__(self, user_query: str):super().__init__()self.user_query = user_queryself._construct()def _construct(self):prompt = f"""# 用户原始查询{self.user_query}## 深度理解要求1. 识别问题本质和核心需求2. 提取隐含条件和约束(时间、质量、资源等)3. 确定关键成功指标4. 评估问题复杂度和不确定性5. 预判可能的风险点## 输出格式(JSON){{"core_objective": "核心目标描述","implicit_requirements": ["隐含需求1", "需求2"],"key_metrics": ["关键指标1", "指标2"],"time_constraint": "时间限制(如有)","quality_requirement": "高/中/低","risk_factors": ["风险1", "风险2"],"uncertainty_level": "高/中/低","required_resources": ["资源1", "资源2"]}}"""self.add_user_message(prompt)class TaskDecompositionPrompt(BasePrompt):"""任务分解提示词"""def __init__(self, goal: Dict, available_tools: List[str]):super().__init__()self.goal = goalself.tools = available_toolsself._construct()def _construct(self):prompt = f"""# 目标任务{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 可用工具{', '.join(self.tools) or "无特定工具限制"}## 分解要求1. 原子性:每个任务应为最小可执行单元2. 可行性:确保任务在当前工具集下可执行3. 依赖管理:明确任务间依赖关系4. 优先级:标记关键路径任务## 输出格式(JSON)[{{"task_id": "唯一ID(如task_1)","description": "清晰任务描述","dependencies": ["依赖任务ID"],"priority": "关键/高/中/低","tool": "建议使用工具","expected_output": "预期输出描述"}},// 更多任务]"""self.add_user_message(prompt)class PlanningPrompt(BasePrompt):"""动态规划提示词"""def __init__(self, tasks: List[Dict], available_tools: List[str], agent_tools: Dict):"""修复:添加 agent_tools 参数"""super().__init__()self.tasks = tasksself.tools = available_toolsself.agent_tools = agent_tools # 添加 agent_tools 属性self._construct()def _construct(self):prompt = f"""# 待规划任务列表{json.dumps(self.tasks, indent=2, ensure_ascii=False)}# 可用工具及详细描述{self._format_tools()}## 规划要求1. 制定最优执行序列(考虑依赖关系和优先级)2. 为每个任务指定具体执行动作(工具调用/LLM推理/知识查询)3. 为工具调用提供精确的参数值4. 参数值可以是静态值或动态引用(使用$step:step_id.key获取上一步结果)5. 预测每个步骤的执行时间和资源需求6. 识别潜在瓶颈并制定应对预案## 输出格式(JSON)[{{"step_id": "唯一步骤ID(如step_1)","task_id": "对应任务ID","action": "具体动作(use_tool/llm_reasoning/query_kb)","tool": "工具名称(如果action是use_tool)","params": {{"参数名": "值或$动态引用"}},"question": "需推理的问题(如果action是llm_reasoning)","topic": "查询主题(如果action是query_kb)","dependencies": ["依赖步骤ID"],"expected_duration": "预计耗时(秒)","risk_assessment": "风险评估与应对","max_retries": 最大重试次数}},// 更多步骤]"""self.add_user_message(prompt)def _format_tools(self) -> str:"""格式化工具描述,包含详细参数说明"""tool_desc = []for tool_name in self.tools:tool_config = self.agent_tools.get(tool_name, {})desc = tool_config.get("description", "无描述")param_desc = tool_config.get("parameter_description", [])param_list = []for param in param_desc:param_info = f"- {param['name']}: {param.get('description', '')}"if param.get("required", False):param_info += " (必填)"param_list.append(param_info)tool_desc.append(f"**{tool_name}**: {desc}\n" + "\n".join(param_list))return "\n\n".join(tool_desc)def _format_tools(self) -> str:"""格式化工具描述"""tool_desc = []for tool_name in self.tools:tool_config = self.agent_tools.get(tool_name, {})desc = tool_config.get("description", "无描述")param_desc = tool_config.get("parameter_description", [])param_list = []for param in param_desc:param_info = f"- {param['name']}: {param.get('description', '')}"if param.get("required", False):param_info += " (必填)"param_list.append(param_info)tool_desc.append(f"**{tool_name}**: {desc}\n" + "\n".join(param_list))return "\n\n".join(tool_desc)class ReasoningPrompt(BasePrompt):"""推理提示词"""def __init__(self, goal: Dict, current_results: Dict, question: str):super().__init__()self.goal = goalself.context = current_resultsself.question = questionself._construct()def _construct(self):prompt = f"""# 核心目标{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 当前执行上下文{json.dumps(self.context, indent=2, ensure_ascii=False)[:1000]}... [已截断]# 需要解决的子问题{self.question}## 推理要求1. 基于上下文数据进行分析2. 识别关键影响因素3. 考虑业务背景和约束4. 区分事实和假设5. 明确标注不确定点## 输出格式推理过程: <详细推理链条>结论: <分号分隔的主要结论>不确定点: <需要验证的假设>"""self.add_user_message(prompt)class ReflectionPrompt(BasePrompt):"""ReAct反思提示词"""def __init__(self, step: Dict, result: Any, expected: Any, constraints: Dict):super().__init__()self.step = stepself.result = resultself.expected = expectedself.constraints = constraintsself._construct()def _construct(self):prompt = f"""# 执行步骤信息{json.dumps(self.step, indent=2, ensure_ascii=False)}# 实际执行结果{json.dumps(str(self.result)[:500], ensure_ascii=False)}... [结果截断]# 预期结果{json.dumps(self.expected, ensure_ascii=False) if self.expected else "未明确指定"}# 业务约束{json.dumps(self.constraints, ensure_ascii=False)}## 反思任务分析执行结果与预期的差距,并确定下一步行动:1. 问题诊断:找出结果不达标的根本原因2. 调整建议:是否调整参数后重试(推荐原因/新参数)3. 方案调整:是否需要完全不同的执行方案4. 计划影响:对整体计划的影响评估## 输出格式(JSON){{"diagnosis": "问题诊断描述","adjust_action": "retry/new_plan/abort","reason": "调整原因说明","adjusted_params": {{"参数调整建议"}},"new_plan_suggestions": ["新步骤建议"],"impact_assessment": "对整体计划的影响"}}"""self.add_user_message(prompt)class PlanAdjustmentPrompt(BasePrompt):"""计划调整提示词"""def __init__(self, goal: Dict, tasks: List[Dict], results: Dict, history: List[Dict]):super().__init__()self.goal = goalself.tasks = tasksself.results = resultsself.history = historyself._construct()def _construct(self):# 提取关键执行历史error_history = [entry for entry in self.history if entry.get("level") in ["ERROR", "WARNING"]]last_10_entries = self.history[-10:]prompt = f"""# 原始目标{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 原始任务列表{json.dumps(self.tasks, indent=2, ensure_ascii=False)[:1000]}... [截断]# 当前结果集(成功步骤){json.dumps({k: v for k, v in self.results.items() if v is not None}, indent=2)[:1000]}... [截断]# 关键执行问题(最近错误/警告){json.dumps(error_history[-3:], indent=2, ensure_ascii=False) if error_history else "无严重错误"}## 调整任务基于当前执行问题提出计划调整方案:1. 优化任务序列2. 替换失败步骤3. 添加新任务弥补信息缺口4. 考虑当前可用结果## 输出格式(JSON)[{{"task_id": "新任务ID","description": "任务描述","reason": "添加原因","dependencies": ["任务依赖"],"priority": "关键/高/中/低"}},// 更多任务]"""self.add_user_message(prompt)class IntegrationPrompt(BasePrompt):"""结果整合提示词"""def __init__(self, goal: Dict, results: Dict):super().__init__()self.goal = goalself.results = resultsself._construct()def _construct(self):prompt = f"""# 原始目标{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 执行结果集{json.dumps(self.results, indent=2, ensure_ascii=False)[:1500]}... [截断]## 整合要求1. 提炼核心业务洞察和价值点2. 展示关键数据支持(需精确引用)3. 识别未解决的问题和局限4. 提出可行的行动建议5. 总结对原始目标的达成程度## 输出格式1. <总览摘要>2. <关键发现1>(数据支持)3. <关键发现2>(数据支持)4. <局限说明>5. <建议行动>"""self.add_user_message(prompt)def database_query(query: str, connection_config: Dict = None) -> List[Dict]:"""数据库查询工具(简化的生产实现)"""# 生产环境中使用数据库连接池# with get_connection(connection_config) as conn:# cursor = conn.cursor()# cursor.execute(sql)# return cursor.fetchall()# 模拟实现print(f"调用数据查询工具,查询数据:{query}")return [{"product": "A", "q1": 100, "q2": 120},{"product": "B", "q1": 80, "q2": 95}]def market_analysis(query: str) -> Dict:"""市场分析工具 - 提供竞争情报和市场趋势分析参数说明:- query: 自然语言描述的分析需求(如"北美市场Q1-Q2主要产品的销售增长趋势")返回:- 成功时返回市场分析报告(JSON格式)- 失败时返回模拟数据内部实现:- 自动将自然语言查询转换为API参数- 处理API调用细节(endpoint、认证等)- 错误时返回预设的模拟数据"""API_ENDPOINT = "https://api.market-intelligence.com/v1/analysis"API_KEY = "prod_xxxxxxxxxxxxxxxx"params = translate_query_to_api_params(query)try:headers = {"Authorization": f"Bearer {API_KEY}"}response = requests.get(API_ENDPOINT,params=params,headers=headers,timeout=15)response.raise_for_status()return response.json()except Exception:# API调用失败时返回模拟数据return generate_mock_analysis(query)def translate_query_to_api_params(query: str) -> Dict:"""将自然语言查询转换为API参数"""params = {}if "北美" in query:params["region"] = "north_america"elif "欧洲" in query:params["region"] = "europe"else:params["region"] = "global"time_pattern = r"(Q\d)(?:-Q\d)?"match = re.search(time_pattern, query)if match:params["period"] = match.group(0)if "销售增长" in query:params["analysis_type"] = "sales_growth"elif "市场份额" in query:params["analysis_type"] = "market_share"else:params["analysis_type"] = "trend_analysis"product_keywords = ["产品", "商品", "SKU", "品类"]for keyword in product_keywords:if keyword in query:params["product_focus"] = keywordbreakreturn paramsdef generate_mock_analysis(query: str) -> Dict:"""生成模拟市场分析数据"""return {"query": query,"data_source": "模拟数据(API不可用时提供)","analysis_date": datetime.datetime.now().isoformat(),"key_findings": ["北美市场Q1-Q2整体增长率为12%","产品A表现突出,增长率达25%","产品B市场份额下降3个百分点"],"trends": {"product_a": {"Q1": 120, "Q2": 150},"product_b": {"Q1": 95, "Q2": 90}},"recommendations": ["加大产品A的市场推广力度","分析产品B下滑原因并制定改进策略"],"risk_factors": ["市场竞争加剧","原材料价格上涨"]}def advanced_analytics(data: Dict, method: str = "regression") -> Dict:"""高级分析工具"""# 模拟实现return {"result": "分析完成", "insights": [f"{method}分析发现重要趋势"], "metrics": 0.85}def data_validator(data: Any, schema: Dict) -> bool:"""数据验证工具"""# 模拟实现return True if __name__ == "__main__":# 配置工具集tools = {"db_query": {"func": database_query,"category": ToolCategory.DATA_ACCESS.value,"description": "执行SQL查询","parameter_description": [{"name": "query","type": "string","required": True,"description": "自然语言描述的分析需求(如'北美市场Q1-Q2主要产品的销售增长趋势')"}],"max_retries": 2},"market_analysis": {"func": market_analysis,"category": "数据分析","description": "获取市场趋势和竞争分析报告","parameter_description": [{"name": "query","type": "string","required": True,"description": "自然语言描述的分析需求(如'北美市场Q1-Q2主要产品的销售增长趋势')"}]},"advanced_analytics": {"func": advanced_analytics,"category": ToolCategory.ANALYSIS.value,"description": "执行高级分析","validator": lambda x: x.get("metrics", 0) > 0.5,"parameter_description": [{"name": "data","type": "dict","required": True,"description": "要分析的数据集"}]},"data_validation": {"func": data_validator,"category": ToolCategory.VALIDATION.value,"description": "数据质量验证","parameter_description": [{"name": "data","type": "dict","required": True,"description": "要校验的数据集"},{"name": "schema","type": "dict","required": True,"description": "数据的结构定义"}]}}agent = PlanningAgent(tools=tools,knowledge_base=None, api_key="sk-xxx" # 替换OpenAI API密钥)# 执行复杂查询session_id = "req_12345"user_query = "分析我们北美市场Q1-Q2主要产品的销售增长趋势,识别增长关键驱动因素和潜在风险"result = agent.run(session_id, user_query)print("\n===== 最终洞察报告 =====\n")print(result)plan_history = agent.plans[session_id].execution_historyprint(f"\n执行日志 ({len(plan_history)} 条记录)")
执行结果
1、当规划正确无误时,按照上面的流程直接顺利执行:
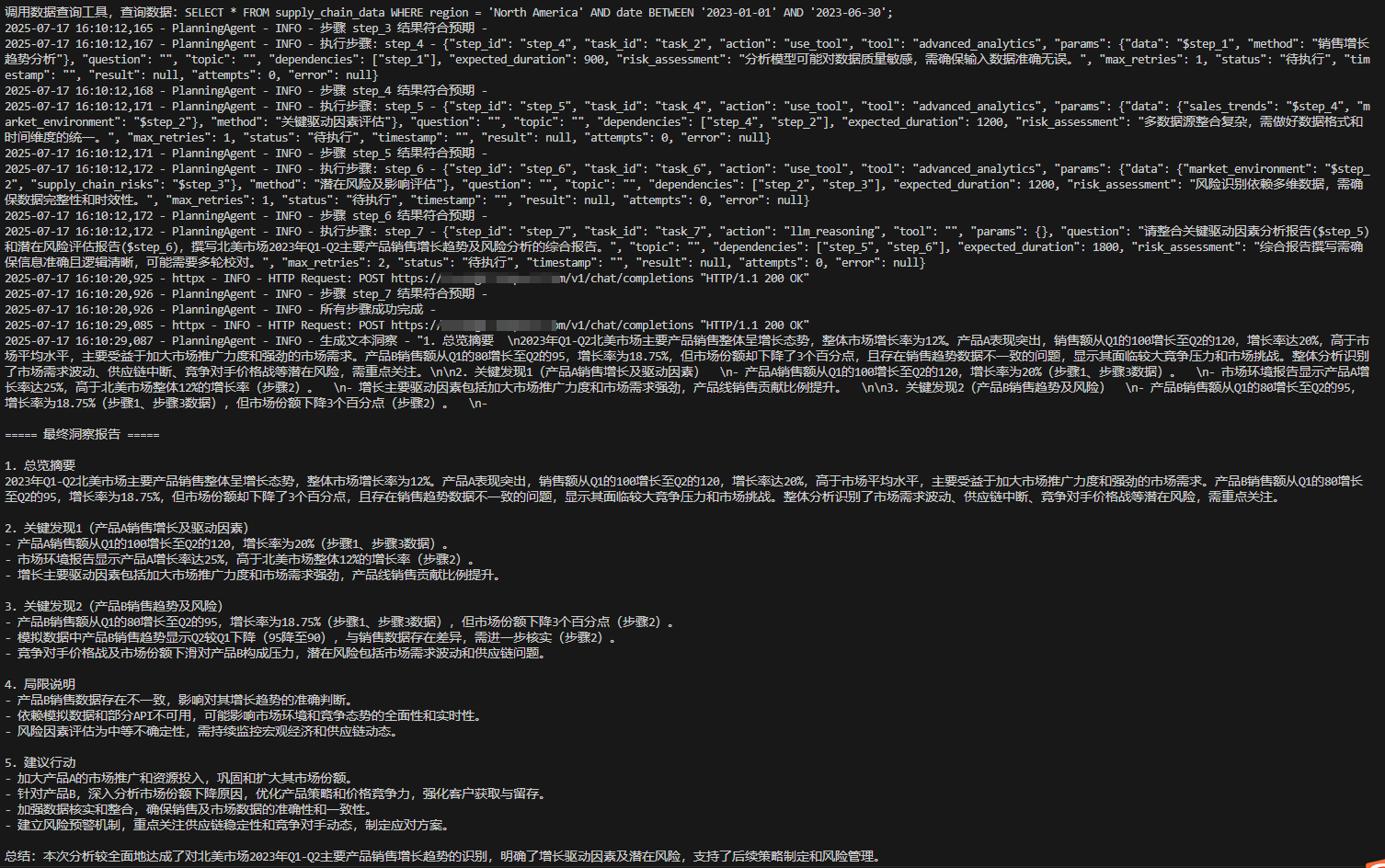
2、当动态规划出现问题,会经过ReAct进行反思并重新规划,执行结果如:
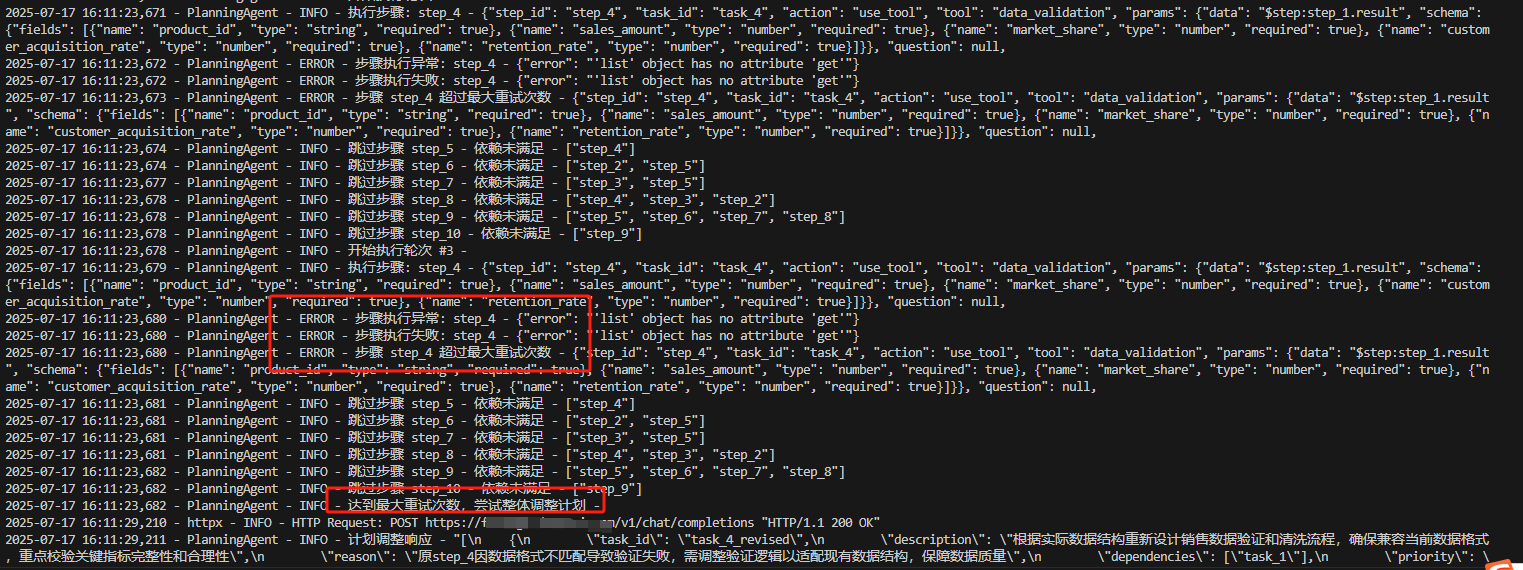
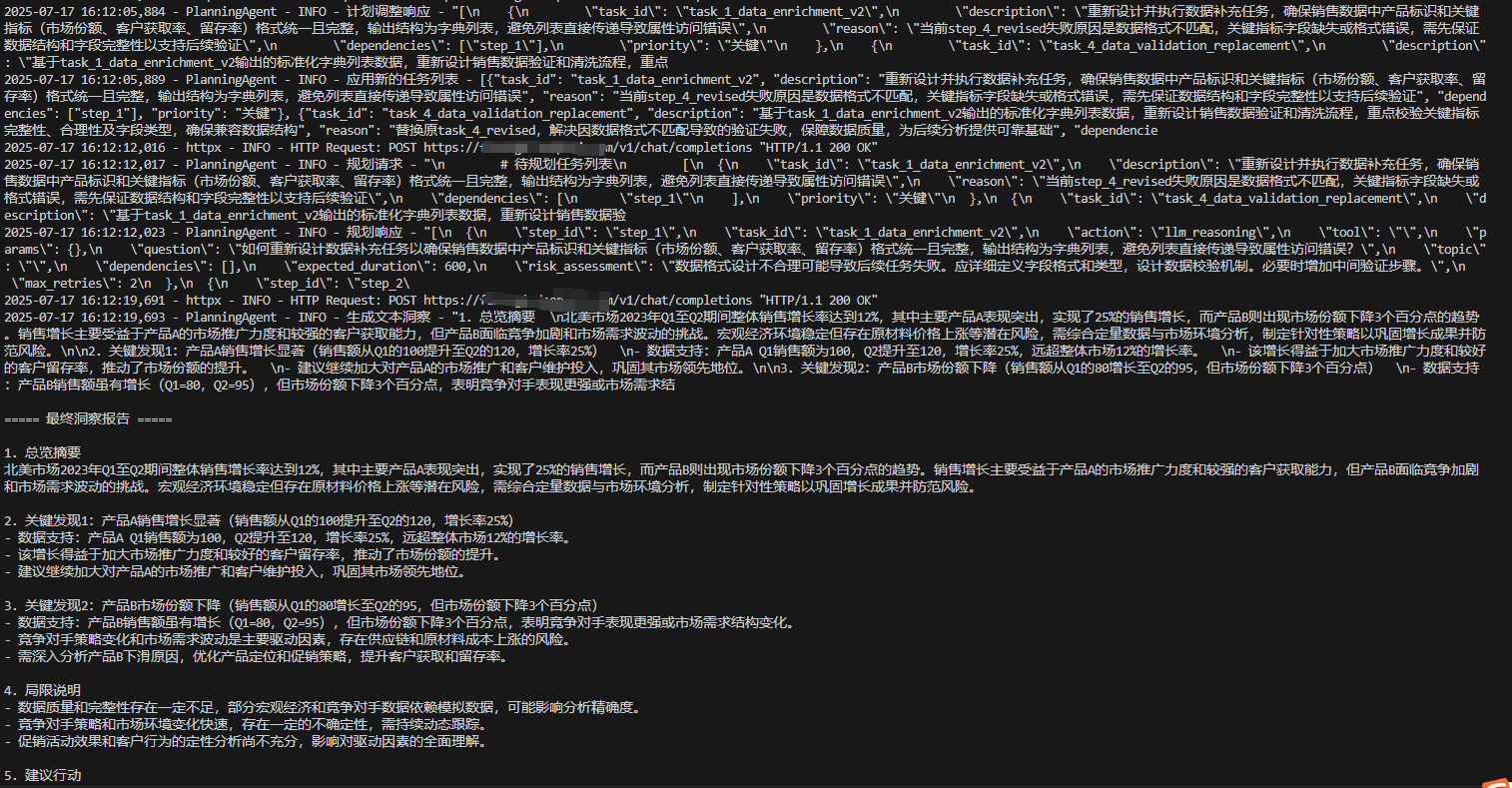
核心技术解析
1. 目标理解:深度解析用户意图
目标理解模块使用大模型将自然语言查询转化为结构化目标描述,为后续处理奠定基础。其核心实现如以下代码所示:
class GoalUnderstandingPrompt(BasePrompt):def _construct(self):prompt = f"""# 用户原始查询{self.user_query}## 深度理解要求1. 识别问题本质和核心需求2. 提取隐含条件和约束3. 确定关键成功指标..."""
在分析 “北美市场 Q1-Q2 主要产品销售增长趋势” 这一查询时,目标理解模块输出了包含核心目标、隐含需求、关键指标等的结构化结果:
{"core_objective": "分析北美市场Q1-Q2主要产品的销售增长趋势,识别增长的关键驱动因素和潜在风险","implicit_requirements": ["覆盖北美市场的主要产品销售数据","细分时间段为Q1和Q2进行趋势对比"],"key_metrics": ["销售额增长率", "市场份额变化"],"time_constraint": "Q1-Q2","risk_factors": ["市场竞争加剧", "原材料价格上涨"]
}
技术重点:
-
约束自动识别:自动提取时间(Q1-Q2)、质量(高)、资源(销售数据、竞争对手情报等)等约束条件,从执行记录中可见系统准确识别了 “北美市场” 和 “Q1-Q2” 这两个关键约束。
-
需求分层:区分核心目标(分析销售增长趋势)和隐含需求(收集详细销售数据、进行趋势对比),确保不遗漏用户未明确提及但必要的需求。
-
风险评估:预判潜在风险点,为后续风险分析提供方向,如代码中风险因素的识别为后续 step_9 的风险评估任务提供了基础。
2. 任务分解:原子化复杂问题
任务分解模块将宏观目标拆解为可执行的原子任务,每个任务都明确了目标、依赖、优先级和所需工具。
def decompose_tasks(self, goal: Dict, plan: ExecutionPlan) -> List[Dict]:# 获取相关工具task_types = goal.get("task_types", ["analysis", "data_retrieval"])relevant_tools = self.get_relevant_tools(task_types)# 生成分解提示prompt = TaskDecompositionPrompt(goal, relevant_tools).generate()...
针对销售分析目标,系统分解出 10 个任务,包括数据收集、客户分析、促销评估等:
[{"task_id": "task_1","description": "收集并整理2023年Q1和Q2北美市场主要产品的销售数据","dependencies": [],"priority": "关键","tool": "db_query"},{"task_id": "task_7","description": "评估促销活动效果,识别对销售增长的关键驱动因素","dependencies": ["task_3", "task_5"],"priority": "关键","tool": "advanced_analytics"}...
]
技术重点:
-
工具感知分解:基于可用工具集生成可行任务,如任务 1 指定使用 db_query 工具,任务 7 指定使用 advanced_analytics 工具,确保任务可执行。
-
依赖关系建模:显式定义任务间依赖关系,如任务 7 依赖于任务 3(促销数据收集)和任务 5(销售数据分析)的结果,这种依赖关系在后续动态规划中被转化为步骤间的依赖。
-
优先级标记:识别关键路径任务,标记为 “关键” 优先级,如数据收集(task_1)和销售趋势分析(task_5)被标记为关键任务,确保资源优先分配。
从执行日志可见,系统在分解过程中还会检查工具可用性,对使用不可用工具的任务发出警告,如对使用 “数据库查询工具,Excel 或数据分析软件” 的任务发出警告,体现系统的健壮性。
3. 动态规划:最优执行序列生成
动态规划模块生成考虑依赖关系和资源约束的最优执行计划,将任务转化为具体步骤。
def dynamic_planning(self, tasks: List[Dict], plan: ExecutionPlan):prompt = PlanningPrompt(tasks, list(self.tools.keys()), self.tools).generate()response = self.llm_predict(prompt)steps = self.parse_llm_response(response, "plan")...
针对销售分析任务,系统生成 9 个执行步骤,形成完整的执行链:
[{"step_id": "step_1","task_id": "task_1","action": "use_tool","tool": "db_query","params": {"query": "SELECT product_id, sales_amount FROM sales_data WHERE region = 'North America' AND year = 2023 AND quarter IN (1,2);"}},...{"step_id": "step_5","task_id": "task_5","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_1", "method": "calculate_growth_and_trend_comparison"},"dependencies": ["step_1"]}
]
技术重点:
-
参数动态解析:支持$step:step_id.key格式引用上一步结果,如 step_5 引用 step_1 的结果作为输入数据,实现了步骤间的数据流转,这在执行记录中体现为 step_5 成功使用了 step_1 返回的销售数据。
-
风险评估:为每个步骤预测风险并制定预案,确保执行过程中的潜在问题有应对策略,如代码中每个步骤都包含 “risk_assessment” 字段。
-
资源优化:预估执行时间和资源需求,提高执行效率,如步骤定义中的 “expected_duration” 字段有助于资源的合理分配。
从执行流程看,动态规划生成的步骤序列严格遵循了任务间的依赖关系,如 step_5 必须在 step_1 完成后执行,保证了数据的可用性。
4. 执行引擎:自适应执行与反思
执行引擎是系统的核心创新点,实现了带反思机制的自适应执行,确保计划能够应对各种异常情况。
def execute_plan(self, plan: ExecutionPlan) -> Dict[str, Any]:while execution_cycle < self.max_global_retries:for step in plan.steps:# 检查依赖if not self.check_dependencies(dependencies, results):continuetry:# 执行步骤result = self.execute_step(step, plan, results)# ReAct反思self.react_reflection(step, result, plan, results)except Exception as e:# 错误处理和重试...# 计划调整self.plan_adjustment(plan, results, execution_cycle)
在销售分析案例中,执行引擎依次执行了 9 个步骤,从数据查询到风险评估,每个步骤都进行了结果验证:
2025-07-17 15:26:49,568 - PlanningAgent - INFO - 执行步骤: step_1
调用数据查询工具,查询数据:SELECT product_id, sales_amount...
2025-07-17 15:26:49,568 - PlanningAgent - INFO - 步骤 step_1 结果符合预期
...
2025-07-17 15:26:49,797 - PlanningAgent - INFO - 执行步骤: step_9
2025-07-17 15:26:56,039 - PlanningAgent - INFO - 步骤 step_9 结果符合预期
技术重点:
-
依赖驱动执行:自动处理任务间依赖关系,如系统会跳过依赖未满足的步骤,确保执行顺序的正确性,执行日志中没有出现因依赖问题导致的执行错误。
-
ReAct 反思循环:实时评估结果并动态调整,每个步骤执行后都检查结果是否符合预期,如代码中对每个步骤执行结果的评估确保了数据质量。
-
容错重试:智能重试与错误恢复机制,当步骤执行失败时,系统会根据配置进行重试,避免因临时错误导致整个计划失败。
5. ReAct 反思机制:实时评估与参数调整
ReAct机制在每个步骤执行后立即评估结果质量,当结果不符合预期时触发智能调整:
def react_reflection(self, step: Dict, result: Any, plan: ExecutionPlan, context: Dict):# 评估结果是否达到预期meets_expectation = self.evaluate_result(step, result, context)if not meets_expectation:# 生成反思提示reflection_prompt = ReflectionPrompt(step, result, step.get("expected_outcome"),plan.context['constraints']).generate()# 获取LLM反思建议reflection_response = self.llm_predict(reflection_prompt)reflection = self.parse_llm_response(reflection_response, "reflection")# 执行调整if reflection.get("adjust_action") == "retry":# 更新参数重试step["params"].update(reflection.get("adjusted_params", {}))plan.update_step(step["step_id"], PlanStatus.RETRYING)
技术重点:
-
实时质量评估:每个步骤执行后立即验证结果质量,如代码中对每个步骤的结果都进行了评估,并在日志中记录 “结果符合预期” 或触发调整。
-
根因分析:LLM 诊断执行失败的根本原因,通过 ReflectionPrompt 引导大模型分析问题所在,避免盲目调整。
-
参数动态优化:基于诊断结果自动调整工具参数,如当发现数据格式问题时,系统会调整数据处理参数后重试。
-
闭环反馈:形成 “执行 - 评估 - 调整” 的闭环,确保问题能够被及时发现和解决,这种闭环机制在复杂环境中尤为重要。
6. 计划级调整:全局策略重构
当局部调整无法解决问题时,系统触发全局计划重构:
def plan_adjustment(self, plan: ExecutionPlan, results: Dict, execution_cycle: int):if execution_cycle >= plan.max_retries:# 生成调整提示adjustment_prompt = PlanAdjustmentPrompt(plan.context['goal'],plan.context['tasks'],results,plan.execution_history).generate()# 获取新任务列表adjustment_response = self.llm_predict(adjustment_response)new_tasks = self.parse_llm_response(adjustment_response, "tasks")if new_tasks:# 应用新任务并重新规划plan.context['tasks'] = new_tasksself.dynamic_planning(new_tasks, plan)
技术重点:
-
全局视角:基于整体执行状态而非单个步骤进行调整,确保调整方案符合全局目标,避免局部最优但全局次优的情况。
-
经验复用:利用已成功步骤的结果,避免重复执行已完成的工作,提高效率,如重新规划时不会重复执行已成功的 step_1 等步骤。
-
任务重构:完全重新生成任务序列,而不仅仅是调整参数,适用于初始计划存在根本性问题的情况。
-
历史感知:分析执行历史避免重复错误,通过参考 execution_history,系统可以识别出反复出现的问题并从根本上解决。
7. 多级容错机制:弹性执行框架
系统实现三级容错机制,确保在各种异常情况下的韧性:
def execute_plan(self, plan: ExecutionPlan) -> Dict[str, Any]:execution_cycle = 0while execution_cycle < self.max_global_retries:# 步骤级重试for step in plan.steps:try:# 执行步骤...except Exception as e:if step["attempts"] < step.get("max_retries", plan.max_retries):plan.update_step(step_id, PlanStatus.RETRYING)else:# 标记步骤失败# 计划级重构if not all_completed:self.plan_adjustment(plan, results, execution_cycle)# 全局级重试execution_cycle += 1
容错层级:
-
步骤级重试:参数调整后重试当前步骤,适用于临时错误或参数不当的情况,如网络波动导致的 API 调用失败。
-
计划级重构:生成新任务序列重新规划,适用于多个步骤失败或依赖关系存在问题的情况。
-
全局级重启:整个流程重新执行,适用于系统性错误或环境变化的情况,如数据源变更导致所有数据查询失败。
实际案例:销售趋势分析
用户查询
“分析我们北美市场 Q1-Q2 主要产品的销售增长趋势,识别增长关键驱动因素和潜在风险”
执行流程
- 目标理解:
系统将用户查询转化为结构化目标,明确了核心目标、关键指标和风险因素:
{"core_objective": "分析北美市场Q1-Q2主要产品销售增长趋势","key_metrics": ["增长率", "市场份额"],"risk_factors": ["市场竞争", "供应链中断"]
}
- 任务分解:
分解为 10 个任务,涵盖数据收集、客户分析、促销评估等多个方面:
[{"task_id": "task_1","description": "获取销售数据","tool": "db_query","params": {"query": "SELECT..."}},{"task_id": "task_2","description": "计算增长率","dependencies": ["task_1"],"tool": "advanced_analytics"}
]
- 动态规划:
生成 9 个执行步骤,明确了每个步骤的工具、参数和依赖:
[{"step_id": "step_1","action": "use_tool","tool": "db_query","params": {"query": "SELECT..."}},{"step_id": "step_2","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_1.result"}}
]
- 反思调整:
本次执行所有步骤均成功,未触发调整机制,但系统仍对每个步骤进行了结果验证:
2025-07-17 15:26:49,568 - PlanningAgent - INFO - 步骤 step_1 结果符合预期
...
2025-07-17 15:26:56,040 - PlanningAgent - INFO - 步骤 step_9 结果符合预期
当反思失败
如销售数据分析失败
初始步骤:
{"step_id": "step_5","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_1.result","method": "sales_trend_analysis"}
}
问题:返回结果为空(工具验证失败)
ReAct 反思过程:
-
检测到结果为空,触发反思:系统通过 evaluate_result 函数发现结果不符合预期,执行日志中会记录 “结果不符合预期,触发反思”。
-
LLM 诊断:“输入数据格式与工具要求不匹配,step_1 返回的是原始销售数据,未包含产品类别信息,导致趋势分析无法按产品维度进行”。
-
建议调整:添加数据预处理步骤,提取产品类别并重组数据格式。
调整后步骤:
{"step_id": "step_5a","action": "use_tool","tool": "data_preprocessor","params": {"raw_data": "$step_1.result","format": "time_series_by_product"}
},
{"step_id": "step_5b","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_5a.result","method": "sales_trend_analysis"},"dependencies": ["step_5a"]
}
通过这一调整,系统成功完成了销售趋势分析,避免了因数据格式问题导致的整个计划失败。这种自我纠错能力大大提高了系统的鲁棒性和实用性。反思调整后将会重新执行。
最终洞察
系统整合所有分析结果,生成了包含关键发现和行动建议的洞察报告:
1. 总览摘要
北美市场Q1-Q2整体增长12%,产品A表现突出(+25%)2. 关键发现
- 驱动因素:产品A创新设计+促销活动
- 潜在风险:产品B市场份额下降3个百分点3. 行动建议
- 扩大产品A产能
- 分析产品B下滑原因
这份报告不仅回答了用户的原始问题,还提供了具有可操作性的建议,体现了系统从数据到决策支持的端到端能力。
技术挑战与解决方案
挑战 1:复杂依赖管理
挑战:当任务数量增加时,依赖关系变得复杂,容易出现循环依赖或依赖缺失的情况,导致执行顺序混乱。
解决方案:
-
显式依赖声明:通过"dependencies": [“step_1”]明确指定依赖的步骤,使依赖关系一目了然。
-
动态依赖检查:执行前验证所有依赖是否满足,如 check_dependencies 函数确保只有依赖全部满足的步骤才会被执行。
-
依赖可视化:执行日志中标记依赖关系,便于问题排查和流程优化,在详细日志中可以追踪每个步骤的依赖满足情况。
在销售分析案例中,系统成功处理了多步依赖,如 step_7 依赖于 step_3 和 step_5 的结果,执行引擎正确地在这两个步骤完成后才执行 step_7。
挑战 2:工具参数适配
挑战:不同工具对参数格式和类型的要求各异,容易出现参数不匹配导致的工具调用失败。
解决方案:
# 参数过滤机制
tool_params = inspect.signature(tool_func).parameters.keys()
for param_name in step_params:if param_name in tool_params:# 保留有效参数params[param_name] = step_params[param_name]else:# 记录无效参数警告logger.warning(f"忽略不支持参数 '{param_name}'")
系统通过反射机制获取工具函数的参数列表,仅保留工具支持的参数,过滤无效参数。在执行日志中可以看到相关警告:
2025-07-17 15:26:35,989 - PlanningAgent - WARNING - 任务使用不可用工具...
这种机制确保了工具不会收到无法处理的参数,提高了工具调用的成功率。
挑战 3:错误恢复
挑战:执行过程中可能遇到各种错误(网络故障、数据错误、工具异常等),如何优雅地恢复并继续执行是一个难题。
解决方案:
-
三级重试机制:步骤级、计划级、全局级的多层次重试,确保不同类型的错误都能得到妥善处理。
-
模拟数据回退:API 失败时返回预设数据,如 market_analysis 工具在 API 调用失败时返回 generate_mock_analysis 生成的模拟数据,保证流程不中断。
-
计划重构:失败时生成新执行计划,而不是简单重试,如 plan_adjustment 函数在多次失败后会生成全新的任务序列。
在销售分析案例中,market_analysis 工具可能因网络问题返回模拟数据,但系统仍能基于这些数据完成后续分析,体现了良好的错误恢复能力。
总结
应用场景
-
商业决策:市场分析、风险评估、销售预测等,如本文案例所示,系统能为销售策略提供数据支持和建议。
-
运维诊断:故障根因分析、系统优化建议,通过分析日志数据自动识别潜在问题并提出解决方案。
-
研究支持:实验方案规划、数据分析、文献综述,帮助研究人员设计实验流程并分析结果。
-
金融分析:投资组合优化、风险评估、市场趋势预测,处理大量金融数据并生成投资建议。
随着技术的不断成熟,Planning Agent 有望在更多领域发挥作用,成为复杂问题求解的重要工具。
技术价值与创新点
Planning Agent 通过结合大语言模型的推理能力和确定性编程的可靠性,实现了复杂问题的动态求解。其核心创新在于:
-
分层规划架构:目标→任务→步骤的渐进式细化,使复杂问题变得可管理。
-
反射式执行引擎:实时监控与动态调整,确保计划能够适应各种异常情况。
-
安全工具集成:自然语言接口与安全隔离,在方便使用的同时保护敏感信息。
-
韧性设计:多级错误恢复机制,提高系统在复杂环境中的可靠性。
性能优化策略
-
反思缓存:存储常见问题的调整方案,避免重复反思,提高纠错效率。
-
增量调整:仅调整受影响的任务子集,减少不必要的重新规划。
-
预测性调整:基于历史数据预判潜在问题,提前调整计划以避免失败。
-
调整验证:在模拟环境中测试调整方案,确保调整的有效性和安全性。
-
并行执行:无依赖关系的任务可以并行执行,如 step_1、step_2、step_3 之间没有依赖,可以同时执行以提高效率。
-
结果缓存:重复查询使用缓存结果,避免重复计算和 API 调用,特别适用于静态数据或变化缓慢的数据查询。
-
增量执行:仅重新执行失败的步骤,而不是整个计划,如在计划调整时保留已成功的步骤结果,只重新执行失败的部分。
-
LLM 优化:
- 提示词压缩:去除冗余信息,提高 LLM 处理速度。
- -响应结构化约束:通过严格的 JSON 格式要求减少解析错误。
- 温度参数调优:根据任务类型调整 temperature 参数,分析任务使用较低温度(0.3)保证结果的确定性。





 的解决)





)







