掌握工具易,领悟其道难——本文带你穿透API表面,直击工业级机器学习实践的核心逻辑。
作为一名长期耕耘在机器学习研究与工业应用一线的从业者,我见过太多因误用 sklearn 而导致的模型失效案例。从数据泄露到评估失真,从特征处理失误到超参调优陷阱。本文将结合真实项目经验,系统阐述如何科学、严谨地使用这一强大工具库。
一、数据预处理:模型效果的基石与常见陷阱
核心原则: 预处理必须在训练集上拟合转换器,在测试集/新数据上仅应用转换。避免任何形式的数据泄露。
1.1 标准化/归一化:不只是调用 StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 错误示范:在整个数据集上拟合转换器
scaler = StandardScaler().fit(X) # 泄露测试集信息!
X_scaled = scaler.transform(X)# 正确方法:严格隔离训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)scaler = StandardScaler().fit(X_train) # 仅在训练集拟合
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test) # 测试集使用训练集的参数转换深入解析: 标准化器(如 StandardScaler)在 fit 时计算训练集的均值(mean_)和标准差(scale_)。在测试集上使用这些参数转换,模拟模型部署时遇到新数据的情景。若在整个数据集上拟合,测试集信息会“污染”转换参数,导致评估过于乐观,模型上线后性能骤降。
1.2 缺失值处理:选择与模型兼容的策略
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor# 数值型特征:中位数填充 (对异常值稳健)
num_imputer = SimpleImputer(strategy='median')# 分类特征:众数填充
cat_imputer = SimpleImputer(strategy='most_frequent')# 高级技巧:模型驱动的填充 (如KNNImputer)
from sklearn.impute import KNNImputer
knn_imputer = KNNImputer(n_neighbors=5)经验之谈: 树模型(如 RandomForest)本身能处理缺失值(sklearn 中需显式设置),但多数模型(如 SVM, 线性模型)不能。KNN填充效果通常优于简单统计量,但计算开销大。关键点: 任何填充策略的拟合(如计算中位数/众数/KNN模型)必须仅基于训练集。
1.3 分类特征编码:OneHotEncoder vs OrdinalEncoder
OneHotEncoder(独热编码): 适用于无内在顺序的类别(如城市:北京、上海、深圳)。产生稀疏矩阵。OrdinalEncoder(序数编码): 适用于有内在顺序的类别(如学历:高中<本科<硕士<博士)。转换为有序整数。
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder# 独热编码 (注意handle_unknown='ignore'防止新类别报错)
ohe = OneHotEncoder(handle_unknown='ignore', sparse_output=False).fit(X_train_cat)
X_train_ohe = ohe.transform(X_train_cat)# 序数编码 (需指定categories顺序)
education_order = [['高中', '本科', '硕士', '博士']]
ord_enc = OrdinalEncoder(categories=education_order).fit(X_train_edu)
X_train_ord = ord_enc.transform(X_train_edu)避坑指南: 独热编码可能导致高维灾难(维度爆炸)。对于高基数类别,考虑:
目标编码 (
TargetEncoder): 用目标变量的统计量(如均值)编码类别。极易导致目标泄露! 必须在交叉验证循环内部谨慎使用或使用平滑技术。嵌入编码 (Embedding): 深度学习常用,将类别映射到低维连续向量(需神经网络模型配合)。
频率编码: 用类别出现频率代替类别本身。
二、模型选择:理解算法本质,匹配问题特性
2.1 没有免费的午餐定理:算法选择取决于数据
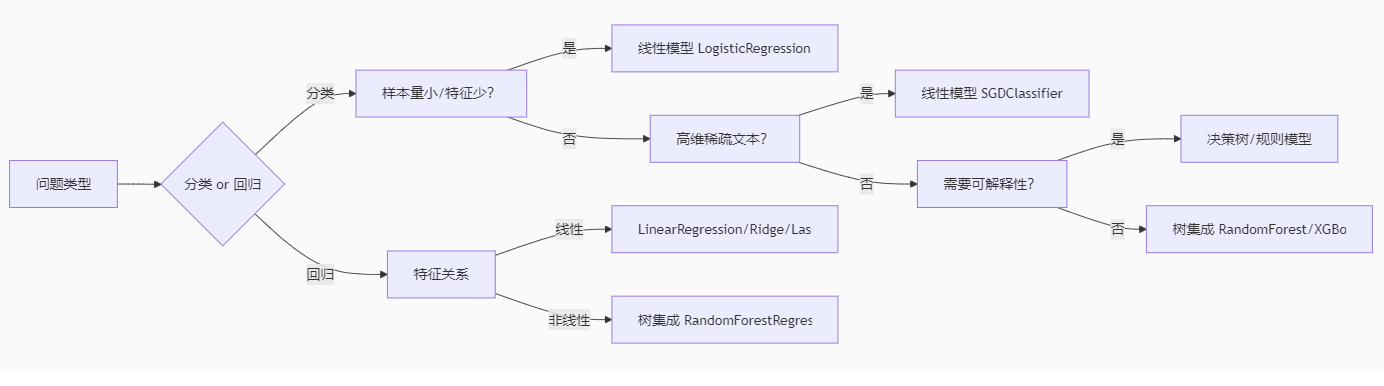
2.2 线性模型:正则化是防止过拟合的关键
Ridge(L2正则化):所有系数收缩但不归零,适用于特征间可能存在共线性的情况。Lasso(L1正则化):倾向于将不重要特征的系数压缩为零,实现特征选择。ElasticNet:结合L1和L2正则化。
from sklearn.linear_model import Ridge, Lasso, ElasticNet# Ridge回归:调整alpha控制正则化强度
ridge = Ridge(alpha=1.0).fit(X_train_scaled, y_train)# Lasso回归:同样调整alpha,特征选择更明显
lasso = Lasso(alpha=0.01, max_iter=10000).fit(X_train_scaled, y_train) # 常需增加max_iter# ElasticNet:平衡L1和L2,调整alpha和l1_ratio
en = ElasticNet(alpha=0.1, l1_ratio=0.5).fit(X_train_scaled, y_train)核心提示: 线性模型通常要求输入特征进行标准化处理。 正则化强度 alpha 需要通过交叉验证仔细调优。
2.3 支持向量机:核函数与参数 C 的选择
线性核 (
kernel='linear'): 高效,适用于特征多、样本多或样本量远大于特征数的情况。可解释性较好。径向基核 (
kernel='rbf'): 最常用,适用于非线性问题。关键参数gamma(控制单个样本影响范围) 和C(控制错误分类惩罚)。gamma小:决策边界平滑,模型简单,可能欠拟合。gamma大:决策边界复杂,模型可能过拟合。C小:允许更多误分类,决策边界平滑,模型简单。C大:严格惩罚误分类,决策边界复杂,模型可能过拟合。
代码如下:
from sklearn.svm import SVC# 线性SVM
svm_linear = SVC(kernel='linear', C=0.1).fit(X_train_scaled, y_train)# RBF核SVM (通常需要特征缩放)
svm_rbf = SVC(kernel='rbf', C=1.0, gamma=0.1).fit(X_train_scaled, y_train)性能注意: SVM 的训练时间复杂度通常在 O(n²) 到 O(n³) 之间,不适合超大规模数据集。
2.4 树与集成:RandomForest 和 Gradient Boosting 实践
RandomForest(随机森林):并行训练多棵决策树,引入行采样和列采样增加多样性。
关键参数:
n_estimators(树的数量,越大越好但计算开销大),max_depth(树的最大深度,控制复杂度),max_features(分裂时考虑的最大特征数,影响多样性和强度)。优点:不易过拟合(相比单棵树),对缺失值、异常值、不同量纲特征相对鲁棒,提供特征重要性。通常作为优秀基线模型。
GradientBoosting(梯度提升树 - GBDT):串行训练树,每棵树学习修正前一棵树的残差。
代表库:
sklearn.ensemble.GradientBoostingClassifier/Regressor,XGBoost,LightGBM,CatBoost。关键参数:
n_estimators(树的数量),learning_rate(学习率,控制每棵树的贡献,小学习率需更多树),max_depth(通常较小,如3-6,构建弱学习器)。优点:精度通常高于随机森林。
缺点:训练更慢,参数调优更关键,对过拟合更敏感(需谨慎控制树深和学习率)。
代码如下:
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier# 随机森林
rf = RandomForestClassifier(n_estimators=100, max_depth=5, max_features='sqrt',random_state=42, n_jobs=-1).fit(X_train, y_train)# 梯度提升树 (sklearn实现)
gb = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1,max_depth=3, subsample=0.8, # 行采样random_state=42).fit(X_train, y_train)工业级建议: 对于表格数据,LightGBM 或 XGBoost 通常是精度和效率的最佳平衡。CatBoost 在处理类别特征上有独特优势。
三、模型评估:超越简单准确率,选择正确的度量
核心原则: 评估指标必须与业务目标一致!盲目使用 accuracy 是常见错误。
3.1 分类任务:理解混淆矩阵及其衍生指标
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score# 预测测试集
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] # 获取正类的概率# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print(cm)# 详细报告 (Precision, Recall, F1, Support)
print(classification_report(y_test, y_pred))# AUC-ROC (评估模型排序能力,对不平衡数据敏感度较低)
auc = roc_auc_score(y_test, y_pred_proba)
print(f"AUC-ROC: {auc:.4f}")准确率 (
accuracy):(TP + TN) / Total。仅在各类别样本均衡时有效。精确率 (
precision):TP / (TP + FP)。关注预测为正的样本中有多少是真正的正例。“宁可放过,不可错杀”。 例如:垃圾邮件检测(不想把正常邮件误判为垃圾)。召回率 (
recall/sensitivity):TP / (TP + FN)。关注实际为正的样本中有多少被正确找出。“宁可错杀,不可放过”。 例如:疾病筛查(不想漏掉真正的病人)。F1分数 (
F1-score):2 * (Precision * Recall) / (Precision + Recall)。精确率和召回率的调和平均,综合两者考量。AUC-ROC: 绘制真正例率
TPR(Recall) 随假正例率FPR(FP / (FP + TN)) 变化的曲线下面积。衡量模型将正样本排在负样本前面的能力。值越接近1越好。对类别不平衡相对鲁棒,常用于比较不同模型。
3.2 回归任务:理解误差的不同视角
均方误差 (
mean_squared_error,MSE):Σ(y_true - y_pred)² / n。平方项放大大误差的影响。均方根误差 (
root_mean_squared_error,RMSE):sqrt(MSE)。与目标变量单位相同,更易解释。平均绝对误差 (
mean_absolute_error,MAE):Σ|y_true - y_pred| / n。对异常值不如MSE敏感。决定系数 (
R² score):1 - (Σ(y_true - y_pred)² / Σ(y_true - mean(y_true))²)。模型解释的方差比例。值越接近1越好,可为负数(表示模型比简单均值预测还差)。
代码如下:
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scoremse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R²: {r2:.4f}")选择依据: 如果大误差的成本非常高(如金融预测),优先考虑 RMSE。如果所有误差同等重要且数据可能有异常值,考虑 MAE。R² 用于衡量模型的整体解释力。
四、泛化能力保障:交叉验证与超参数调优
核心目标: 估计模型在未见数据上的性能,找到最优超参数组合,避免过拟合训练数据。
4.1 交叉验证:KFold 与 StratifiedKFold
KFold: 标准K折交叉验证。将数据随机分割成K个大小相似的互斥子集。依次用其中K-1个子集训练,剩余1个子集验证。重复K次,每次使用不同的验证子集。最终性能取K次验证的平均。StratifiedKFold: 分类问题强烈推荐! 在分层K折中,每个子集内各类别样本的比例尽量保持与原始数据集一致。这尤其在类别不平衡时至关重要,确保每折都能代表整体分布。
代码如下:
from sklearn.model_selection import KFold, StratifiedKFold, cross_val_score# 标准5折交叉验证 (回归或不平衡不严重的分类)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=kf, scoring='accuracy')
print(f"CV Accuracy: {scores.mean():.4f} ± {scores.std():.4f}")# 分层5折交叉验证 (分类,尤其推荐用于不平衡数据)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=skf, scoring='f1_macro') # 使用F1宏平均
print(f"Stratified CV F1 Macro: {scores.mean():.4f} ± {scores.std():.4f}")重要提示: 交叉验证的 fit 过程发生在训练折叠上,整个交叉验证循环结束后,通常会在整个训练集上重新训练一个最终模型。cross_val_score 主要用于评估模型性能,返回的是验证折叠上的分数。
4.2 超参数调优:GridSearchCV 与 RandomizedSearchCV
GridSearchCV(网格搜索): 穷举指定的所有参数组合。计算开销大,适用于参数组合空间较小的情况。RandomizedSearchCV(随机搜索): 从指定的参数分布中随机采样一定数量的组合进行尝试。效率通常远高于网格搜索,尤其在高维参数空间时,是更推荐的方法。
代码如下:
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from scipy.stats import randint, uniform# 定义参数网格/分布
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [3, 5, 7, None],'max_features': ['sqrt', 'log2', 0.8]
}
param_dist = {'n_estimators': randint(50, 300), # 均匀整数分布'max_depth': [3, 5, 7, 9, None],'learning_rate': uniform(0.01, 0.3), # 连续均匀分布 [0.01, 0.31)'subsample': [0.6, 0.7, 0.8, 0.9, 1.0]
}# GridSearchCV
grid_search = GridSearchCV(estimator=GradientBoostingClassifier(random_state=42),param_grid=param_grid,cv=5, # 内部交叉验证折数scoring='neg_mean_squared_error', # 回归常用n_jobs=-1,verbose=1
)
grid_search.fit(X_train, y_train)
print(f"Best Params (Grid): {grid_search.best_params_}")
print(f"Best MSE: {-grid_search.best_score_:.4f}") # 注意负号# RandomizedSearchCV (通常更高效)
random_search = RandomizedSearchCV(estimator=GradientBoostingClassifier(random_state=42),param_distributions=param_dist,n_iter=50, # 随机尝试的组合数cv=5,scoring='accuracy',n_jobs=-1,random_state=42,verbose=1
)
random_search.fit(X_train, y_train)
print(f"Best Params (Random): {random_search.best_params_}")
print(f"Best Accuracy: {random_search.best_score_:.4f}")# 使用找到的最佳参数重新训练最终模型 (或在search对象中best_estimator_已使用全部训练数据训练)
best_model = random_search.best_estimator_关键点:
GridSearchCV/RandomizedSearchCV内部已经包含了交叉验证。传入的
X_train/y_train会被进一步分割用于内部的训练和验证折。搜索结束后,
best_estimator_是用整个传入的X_train/y_train使用找到的最佳参数重新训练好的模型,可以直接用于在测试集X_test上进行最终评估或部署。选择
scoring指标至关重要,它决定了什么是“最佳”参数组合。使用sklearn.metrics.SCORERS.keys()查看所有可用评分指标。
五、构建健壮流程:Pipeline 与 ColumnTransformer
核心价值: 将预处理步骤和模型训练步骤封装成一个单一对象 (Pipeline),结合 ColumnTransformer 按列类型应用不同转换,确保:
所有转换仅基于训练数据进行拟合。
避免测试集/新数据泄露。
代码简洁、可复用、不易出错。
方便在交叉验证/网格搜索中统一应用预处理。
5.1 构建复杂预处理流水线
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer# 定义数值型和分类型特征列名
numeric_features = ['age', 'income', 'credit_score']
categorical_features = ['gender', 'education', 'city']# 为数值型特征创建管道:填充中位数 -> 标准化
numeric_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())
])# 为分类型特征创建管道:填充众数 -> 独热编码
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False)) # sparse_output=False 返回数组
])# 使用ColumnTransformer组合不同的转换器,按特征类型应用
preprocessor = ColumnTransformer(transformers=[('num', numeric_transformer, numeric_features),('cat', categorical_transformer, categorical_features)],remainder='passthrough' # 处理未被指定的列 (例如,保留ID列或手动处理的特征)# 或者 remainder='drop' 丢弃未指定的列
)# 创建包含预处理和最终模型的完整Pipeline
full_pipeline = Pipeline(steps=[('preprocessor', preprocessor),('classifier', RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1))
])# 训练整个流水线 (在preprocessor上自动调用fit_transform,在classifier上调用fit)
full_pipeline.fit(X_train, y_train)# 预测 (在preprocessor上自动调用transform,在classifier上调用predict)
y_pred = full_pipeline.predict(X_test)# 在GridSearchCV/RandomizedSearchCV中使用Pipeline
param_grid = {'classifier__n_estimators': [100, 200],'classifier__max_depth': [5, 10, None],'preprocessor__num__imputer__strategy': ['mean', 'median'], # 访问嵌套参数# ... 其他参数
}
search = GridSearchCV(full_pipeline, param_grid, cv=5, scoring='accuracy')
search.fit(X_train, y_train)Pipeline 魔法:
使用
fit时,流水线依次对每个步骤调用fit或fit_transform,并将输出传递给下一步。使用
predict时,流水线依次对每个步骤(除了最后一步)调用transform,最后一步调用predict。在
GridSearchCV/RandomizedSearchCV中使用Pipeline是最佳实践,能确保交叉验证的每一折内部,预处理都只基于该折的训练部分拟合,完全避免了数据泄露风险。
六、特征工程:提升模型性能的利器
虽然 sklearn 提供了强大的基础转换器,真正的特征工程往往需要结合领域知识和创造力。
6.1 交互特征与多项式特征
from sklearn.preprocessing import PolynomialFeatures# 创建多项式特征 (例如 degree=2: 1, a, b, a², ab, b²)
# 通常只应用于数值特征
poly = PolynomialFeatures(degree=2, interaction_only=False, include_bias=False)
X_train_poly = poly.fit_transform(X_train_num)
X_test_poly = poly.transform(X_test_num) # 注意仅在训练集拟合!# 在Pipeline中集成
numeric_transformer = Pipeline(steps=[('imputer', ...),('scaler', ...),('poly', PolynomialFeatures(degree=2))
])注意: 多项式特征会显著增加维度,可能导致过拟合和计算负担。通常结合正则化使用或进行特征选择。
6.2 分箱 (KBinsDiscretizer) 与特征交叉
from sklearn.preprocessing import KBinsDiscretizer# 将连续年龄分箱成有序类别
age_binner = KBinsDiscretizer(n_bins=5, encode='ordinal', strategy='quantile').fit(X_train[['age']])
X_train['age_bin'] = age_binner.transform(X_train[['age']])
X_test['age_bin'] = age_binner.transform(X_test[['age']])# 特征交叉:结合年龄分箱和城市创建新类别特征
X_train['age_city'] = X_train['age_bin'].astype(str) + '_' + X_train['city']
# 测试集同样操作 (注意处理训练集未出现的新组合)6.3 特征选择
基于模型的特征重要性: 使用
RandomForest,GradientBoosting, 或带L1正则化的线性模型训练后查看feature_importances_或coef_。单变量统计检验:
SelectKBest,SelectPercentile(例如f_classif,mutual_info_classif,f_regression)。递归特征消除 (
RFE/RFECV): 递归地移除最不重要的特征。方差阈值 (
VarianceThreshold): 移除方差极低(几乎恒定)的特征。
代码如下:
from sklearn.feature_selection import SelectFromModel, RFECV# 使用RandomForest选择特征
selector = SelectFromModel(estimator=RandomForestClassifier(n_estimators=100, random_state=42),threshold='median' # 选择重要性大于中位数的特征
).fit(X_train, y_train)
X_train_selected = selector.transform(X_train)
X_test_selected = selector.transform(X_test)# 递归特征消除 (带交叉验证)
rfecv = RFECV(estimator=LogisticRegression(max_iter=1000, solver='liblinear'),step=1, # 每次迭代移除的特征数cv=5,scoring='accuracy'
).fit(X_train_scaled, y_train)
X_train_rfecv = rfecv.transform(X_train_scaled)
print(f"Optimal number of features: {rfecv.n_features_}")重要提示: 特征选择必须作为 Pipeline 中的一个步骤,或者在交叉验证循环内部进行(例如使用 RFECV),以避免使用测试集信息来选择特征而导致评估偏差。
七、高级主题与最佳实践总结
类别特征与树模型: 现代高效的GBDT实现(如
LightGBM,CatBoost)可以直接处理类别特征(内部进行特殊编码)。通常比手动做OneHot更好(避免维度爆炸,保留类别信息)。在sklearn的树模型中,类别特征需要编码(通常OrdinalEncoder或OneHotEncoder)。类别不平衡处理:
数据层面: 过采样 (
SMOTE- 需imbalanced-learn库), 欠采样。算法层面: 使用带类别权重 (
class_weight) 的模型(如LogisticRegression,SVC,RandomForestClassifier- 设置class_weight='balanced')。评估层面: 使用
precision,recall,F1,AUC-ROC,AUC-PR等指标,而非accuracy。
可重复性: 始终设置
random_state! 无论是在数据分割 (train_test_split)、模型 (RandomForest,SVC(probability=True))、交叉验证 (KFold)、还是搜索 (GridSearchCV) 中。这是保证结果可复现的关键。增量学习: 对于无法一次性加载到内存的超大数据集,使用支持
partial_fit的模型(如SGDClassifier,SGDRegressor,PassiveAggressiveClassifier,MiniBatchKMeans)。模型持久化: 使用
joblib(通常比pickle更高效)保存训练好的模型(特别是Pipeline)和必要的转换器(如Scaler,Encoder)。
代码如下:
import joblib# 保存整个训练好的Pipeline
joblib.dump(full_pipeline, 'trained_model_pipeline.joblib')# 加载模型进行预测
loaded_pipeline = joblib.load('trained_model_pipeline.joblib')
new_prediction = loaded_pipeline.predict(new_data)理解计算成本: 不同模型和操作(如网格搜索、某些预处理)的计算开销差异巨大。了解算法的时间/空间复杂度有助于在资源受限时做出选择(例如,对于大数据集,线性模型或
SGD可能比SVM或RandomForest更可行;RandomizedSearchCV比GridSearchCV更高效)。
结语:
Scikit-learn 的强大不仅在于其丰富的算法实现,更在于其一致的 API 设计 (fit, transform, predict) 和构建复杂、健壮机器学习流程的能力 (Pipeline, ColumnTransformer)。遵循本文强调的原则——严防数据泄露、科学评估模型、善用交叉验证与流水线、理解算法本质与适用场景、根据业务目标选择评估指标——将使你能够更专业、更有效地应用 sklearn 解决实际问题。
记住,熟练使用工具只是起点,深刻理解其背后的原理和最佳实践,才是通往构建可靠、高性能机器学习模型的关键。持续实践,结合领域知识进行特征工程,并始终保持对模型泛化能力的关注,你将在机器学习的应用之路上走得更远。
 基础知识点)


)
影响的系统性分析)



![R study notes[1]](http://pic.xiahunao.cn/R study notes[1])










