点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月28日更新到:
Java-83 深入浅出 MySQL 连接、线程、查询缓存与优化器详解
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
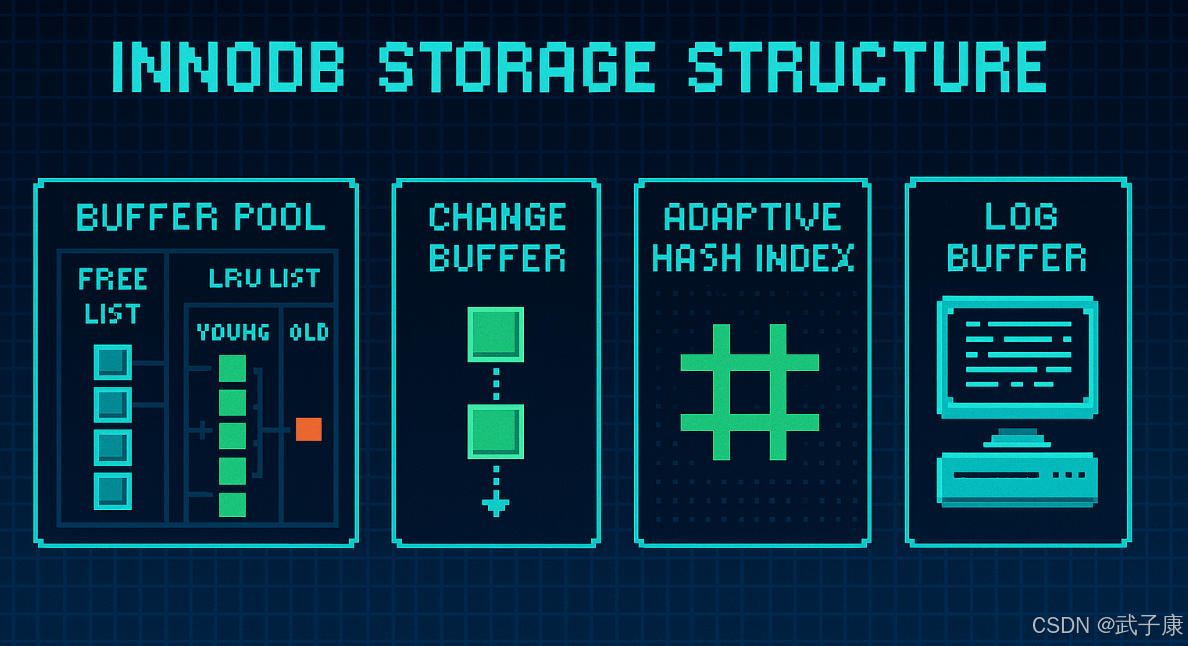
InnoDB存储结构
在 MySQL 5.5 版本开始之后,默认使用 InnoDB 存储引擎,它擅长处理事务,具有自动奔溃恢复的特性,在日常开发中使用非常广泛。
下面是 InnoDB 引擎架构图,主要分为内存结构和磁盘结构两大部分。
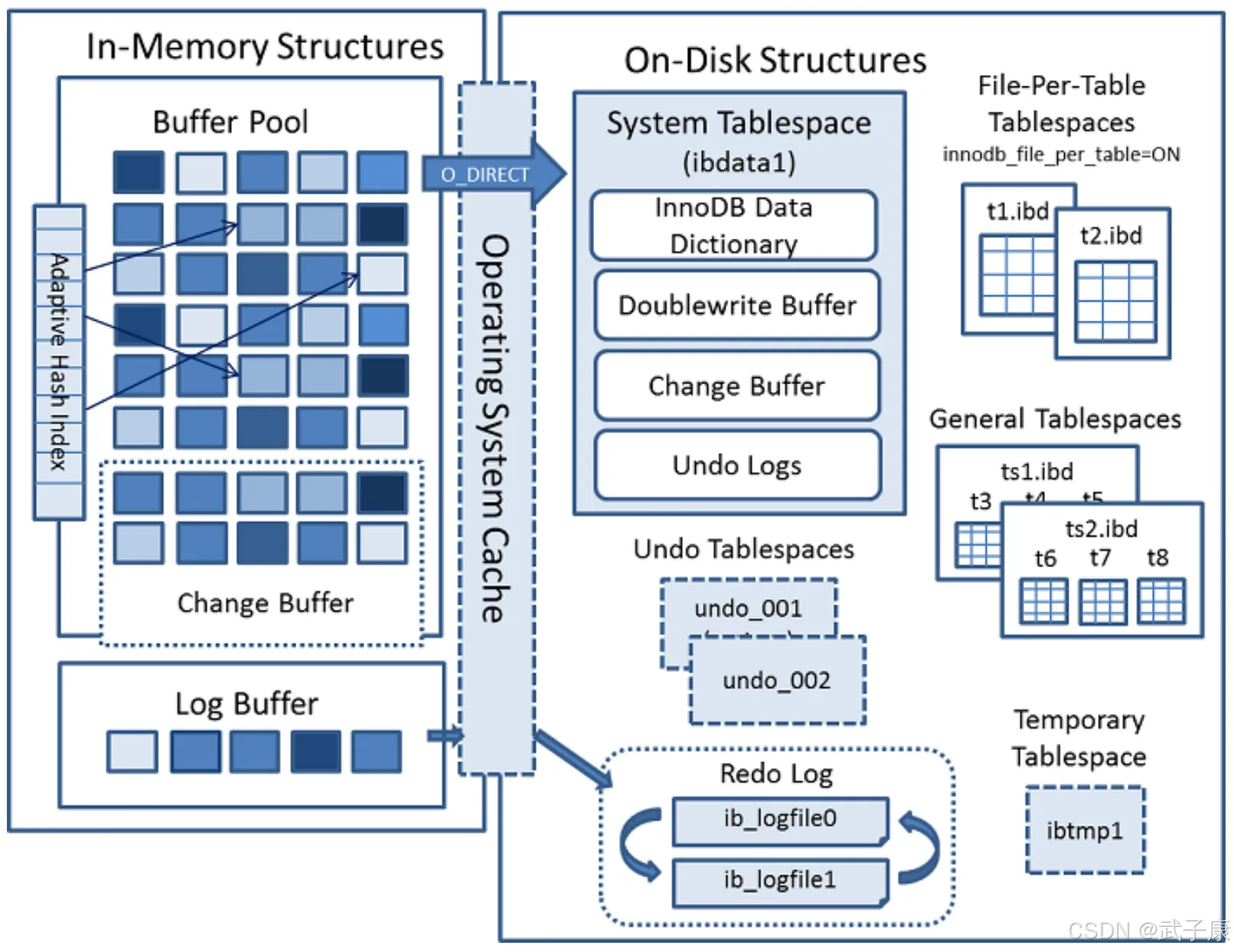
内存结构
内存结构主要包括 Buffer Pool、Change Buffer、Adaptive Hash Index 和 Log Buffer 四大组件。
Buffer Pool(缓冲池)
基本概念
缓冲池(Buffer Pool,简称BP)是InnoDB存储引擎的核心内存区域,主要用于缓存表数据和索引数据,以减少磁盘I/O操作,显著提升数据库性能。
存储单元
- Page(页):BP的基本管理单位
- 默认大小:16KB(可通过
innodb_page_size参数配置) - 包含类型:数据页、索引页、undo页、插入缓冲页等
- 每个Page都有对应的控制信息(约5%额外空间)
- 默认大小:16KB(可通过
数据结构
采用改进的链表结构管理:
- Free List:维护所有空闲页
- LRU List:管理已使用的页,采用改进的LRU算法
- 分为young sublist(5/8)和old sublist(3/8)
- 新页插入到old sublist中部
- 页被访问时可能移至young区
- Flush List:记录被修改过的脏页(按LSN排序)
工作流程示例
-
当查询需要读取某页数据时:
- 先在BP中查找(哈希表快速定位)
- 命中则直接使用内存数据(逻辑读)
- 未命中则从磁盘加载(物理读)
-
写操作流程:
关键配置参数
innodb_buffer_pool_size:总大小(建议设为物理内存的50-70%)innodb_buffer_pool_instances:实例数(减少锁争用)innodb_old_blocks_time:页转入young区前的保护期
性能影响
- 命中率计算公式:
Hit Ratio = 1 - (innodb_buffer_pool_reads / innodb_buffer_pool_read_requests) - 良好实践:监控命中率(建议保持在95%以上),通过预热脚本提升初始性能
应用场景
- 热点数据访问:频繁访问的数据会长期驻留BP
- 事务处理:修改数据先在BP中完成,再异步刷盘
- 全表扫描:通过
innodb_old_blocks_time避免挤出热点数据
Page 管理机制详细说明
● free page(空闲页):
- 完全未被使用的页,处于待分配状态
- 不包含任何有效数据
- 当需要新页面时,首先从这里分配
- 示例:当有新数据插入且缓冲区中没有可用空间时,会从free list获取free page
● clean page(干净页):
- 已被使用的页,但数据与磁盘一致
- 数据未被修改过
- 可以直接替换而不需要写回磁盘
- 示例:执行SELECT操作读取的数据页,在未被修改前都是clean page
● dirty page(脏页):
- 已被使用且被修改过的页
- 内存中的数据与磁盘不一致
- 需要被刷写到磁盘才能释放
- 示例:执行UPDATE操作修改数据后,对应的数据页就变成dirty page
链表管理机制详细说明
● free list(空闲链表):
- 维护所有可分配的空闲页
- 采用简单的链表结构管理
- 当需要新页时,从这里快速获取
- 应用场景:新查询需要加载数据页时
● flush list(刷新链表):
- 维护所有需要刷盘的脏页
- 按照页面的第一次修改时间排序(oldest_modification)
- 采用WAL机制,确保事务持久性
- 与LRU list独立运作
- 刷盘策略:后台线程定期检查,在系统负载低时批量写入
● lru list(最近最少使用链表):
- 采用改进的LRU算法管理
- 结构划分:
- new sublist(新子列表,占5/8):
- 存放热点数据
- 新访问的页先加入这里
- old sublist(老子列表,占3/8):
- 存放较冷数据
- 新页默认先加入这里
- new sublist(新子列表,占5/8):
- 页面移动规则:
- 新访问的页先插入到old sublist头部
- 再次被访问时,移动到new sublist头部
- 长时间未被访问的页会逐渐向尾部移动
- 当需要空间时,优先淘汰old sublist尾部的页
- 冷数据保护机制:
- 设置innodb_old_blocks_time参数
- 防止全表扫描污染缓冲区
改进型LRU算法(LRU with midpoint insertion)
● 普通LRU(Least Recently Used)算法:
- 采用简单的末尾淘汰法,使用双向链表结构管理缓存页
- 新数据总是从链表头部插入,成为最新的数据
- 当需要释放空间时,从链表末尾淘汰最久未被访问的数据
- 示例:一个包含A->B->C的LRU链表,访问B后会变成B->A->C
● 改进型LRU算法(MySQL InnoDB实现):
- 将LRU链表划分为两个区域:
- new子链表(占5/8):存储热点数据
- old子链表(占3/8):存储潜在淘汰数据
- 关键改进点:
- 新元素插入位置:不是直接插入链表头部,而是从中间位置(midpoint,即new和old的交界处)插入
- 动态调整机制:
- 如果数据很快被再次访问(首次访问后的1秒内),该page会向new子链表头部移动
- 未被访问的数据会逐步向old子链表尾部移动
- 淘汰策略:优先从old子链表尾部淘汰页面
具体工作流程:
-
数据读取阶段:
- 当需要将新Page数据加载到Buffer Pool时
- InnoDB引擎首先检查free list是否有可用空闲页
-
内存分配判断:
- 情况1:存在足够空闲页
- 从free list移除对应的free page
- 将该page放入LRU链表的midpoint位置(即old子链表头部)
- 设置首次访问时间戳
- 情况2:无足够空闲页
- 触发LRU淘汰机制:
- 从LRU链表old子表尾部选择待淘汰页
- 如果该页是脏页,先写入磁盘
- 释放该页内存空间
- 将新page插入到midpoint位置
- 触发LRU淘汰机制:
- 情况1:存在足够空闲页
-
访问优化:
- 对于已在LRU链表中的page:
- 若在首次访问后1秒内再次被访问:
- 将其移至new子链表头部
- 否则保持原位或向old子链表尾部移动
- 若在首次访问后1秒内再次被访问:
- 对于已在LRU链表中的page:
应用场景优势:
- 有效防止全表扫描等批量操作污染热点数据
- 更平滑的热点数据迁移过程
- 示例:一个包含1000个page的Buffer Pool,625个page属于new区域,375个page属于old区域,新插入的page会先放在第626的位置
Buffer Pool 配置参数:
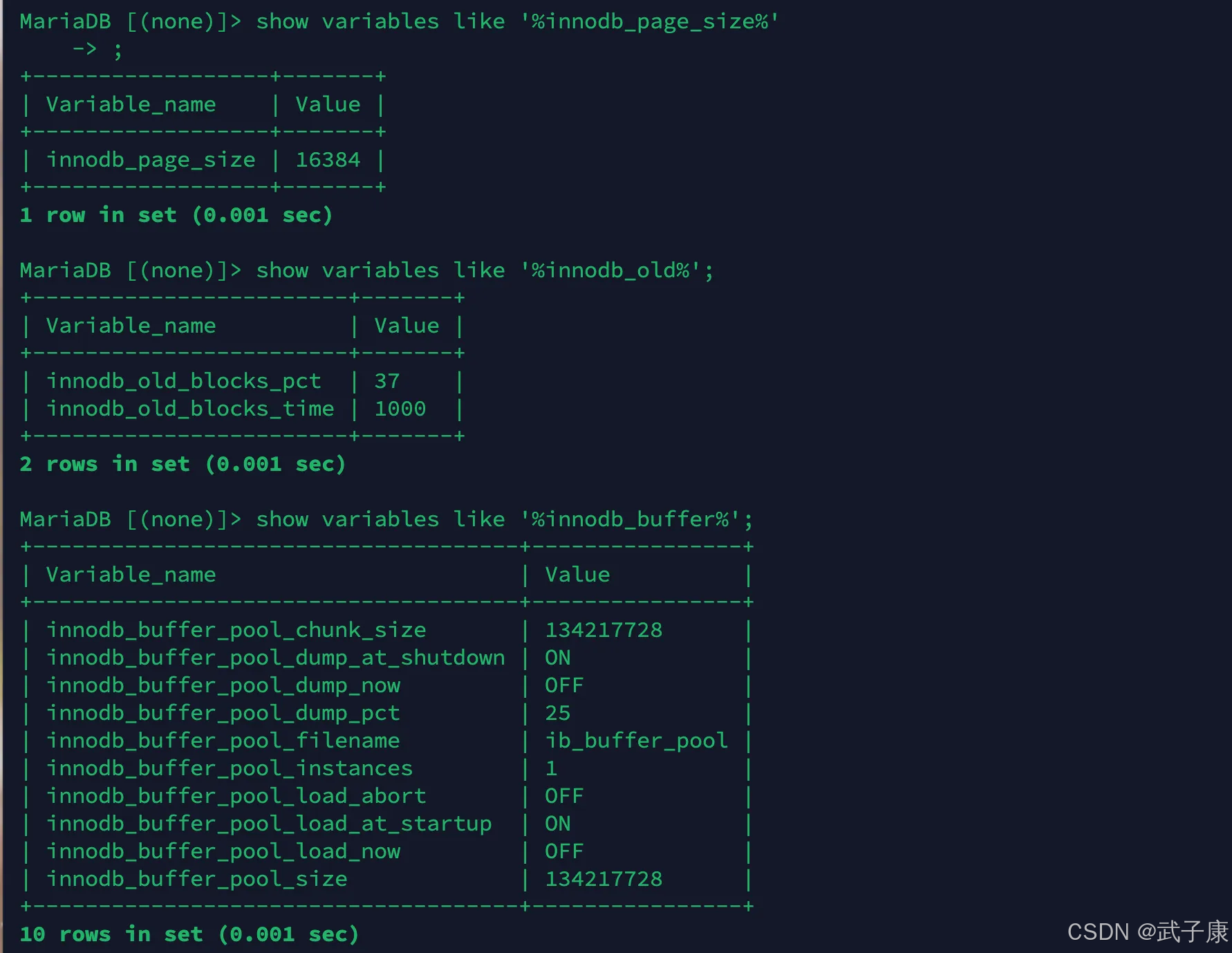
● show variables like ‘%innodb_page_size%’ 查看page页大小
● show variables like ‘%innodb_old%’ 查看 LRU list 中 old列表参数
● show variables like ‘%innodb_buffer%’ 查看 Buffer Pool 参数
Change Buffer
写缓冲区(Change Buffer,简称CB)是InnoDB存储引擎中一种优化非唯一普通索引更新的重要机制。在进行DML(INSERT/UPDATE/DELETE)操作时,如果目标数据页不在缓冲池(Buffer Pool)中,InnoDB不会立即从磁盘加载该页,而是先将这些变更记录在Change Buffer中。待未来该数据页被读取时,再将Change Buffer中的变更合并到缓冲池中。
核心特性:
-
空间占用:
- Change Buffer占用Buffer Pool的空间,默认配置为25%(通过参数
innodb_change_buffer_max_size控制) - 最大可配置为50%,建议根据业务读写比例调整:
- 写密集型业务可适当调高
- 读密集型业务建议降低配置
- Change Buffer占用Buffer Pool的空间,默认配置为25%(通过参数
-
工作流程对比:
-
记录存在Buffer Pool:
- 直接修改缓冲池中的页
- 仅需一次内存操作
-- 示例:当执行UPDATE时,若数据页已在内存 UPDATE users SET name='张三' WHERE id=1; -- 内存直接修改 -
记录不存在Buffer Pool:
- 将变更写入Change Buffer
- 避免立即的磁盘IO
- 后续读取时合并变更
-- 示例:首次更新非活跃数据 UPDATE order_history SET status=2 WHERE order_id=10086; -- 写入ChangeBuffer
-
-
合并触发时机:
- 主动读取:当执行SELECT查询需要加载该数据页时
- 后台线程:由master线程定期合并
- 空间不足:当Change Buffer空间达到阈值时
适用限制:
仅适用于非唯一普通索引页,主要原因如下:
-
唯一性约束验证:
- 唯一索引(包括主键)必须保证数据唯一性
- 每次修改必须检查磁盘现有数据
- 例如:
ALTER TABLE products ADD UNIQUE INDEX idx_sku(sku); -- 以下操作必须立即校验唯一性 INSERT INTO products(sku) VALUES('A1001');
-
强制磁盘加载:
- 校验过程会触发磁盘读取
- 数据页会被加载到Buffer Pool
- 后续修改直接在缓冲池完成
-
典型应用场景:
- 日志表的时间戳索引
- 订单历史表的非关键字段索引
- 批量导入时的辅助索引更新
监控建议:
通过以下命令查看Change Buffer状态:
SHOW ENGINE INNODB STATUS\G
-- 重点关注:
-- INSERT BUFFER AND ADAPTIVE HASH INDEX
-- merged operations: insert/delete mark/purge
注:在SSD存储环境下,因随机IO性能提升,Change Buffer的收益会相对降低,此时可适当减小其配置比例。
Adaptive Hash Index
自适应哈希索引,用于优化对 BP 数据的查询,InnoDB 存储引擎会在监控对表索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应。
InnoDB 存储引擎会自动根据访问的频率和模式来为某些页面建立哈希索引。
Log Buffer(日志缓冲区)
日志缓冲区是数据库系统中一个重要的内存区域,主要用于临时存储即将写入磁盘日志文件(包括Redo日志和Undo日志)的数据。这个缓冲区作为磁盘I/O操作的缓冲层,可以显著提高数据库的写入性能。
主要功能和工作原理
-
数据缓冲:所有DML操作(如INSERT、UPDATE、DELETE)产生的Redo和Undo日志都会先写入Log Buffer,而不是直接写入磁盘。Redo日志记录数据页的物理变化,用于崩溃恢复;Undo日志记录事务前的数据状态,用于事务回滚。
-
自动刷新机制:
- 当缓冲区空间写满时(达到innodb_log_buffer_size设置的大小),系统会自动将缓冲区内容刷新到磁盘的日志文件中。
- 对于大事务(如涉及BLOB或多行更新的操作),增大日志缓冲区可以减少磁盘I/O次数,提高性能。
-
手动刷新控制:通过innodb_flush_log_at_trx_commit参数可以配置不同的日志刷新策略:
- 0:每隔1秒执行一次日志写入和刷盘操作(将LogBuffer内容写入OS Cache,然后从OS Cache刷到磁盘文件)。这种模式性能最好,但可能在系统崩溃时丢失最多1秒的数据。
- 1(默认值):每次事务提交时立即执行日志写入和刷盘操作。这种模式最安全,不会丢失数据,但会产生频繁的I/O操作,影响性能。
- 2:每次事务提交时立即将日志写入OS Cache,但每隔1秒才执行一次刷盘操作。这种模式在系统崩溃时可能会丢失1秒数据,但相比模式1有更好的性能。
实际应用场景
- 高并发事务系统:对于需要处理大量短事务的系统,适当增大innodb_log_buffer_size(如设置为8MB或16MB)可以减少磁盘I/O压力。
- 批量数据处理:在执行大批量数据导入或更新时,可以临时将innodb_flush_log_at_trx_commit设为0或2,完成后恢复为1。
- 关键业务系统:对数据安全性要求高的系统应保持默认设置(innodb_flush_log_at_trx_commit=1),确保每次事务提交后数据立即持久化。
性能优化建议
- 监控日志缓冲区使用情况,如果经常出现等待日志缓冲区空间的情况,应考虑增大缓冲区大小。
- 在SSD存储环境中,可以适当降低日志刷新频率,因为SSD的随机写入性能较好。
- 对于主从复制环境,从库可以配置为较宽松的日志刷新策略以提高复制性能。


——遥操作控制脚本 teleop_hand_and_arm.py 分析与测试部署)





:扩展与生态系统集成)






之Express)



