文章目录
- 一、适配器
- 二、stcak模拟实现
- 三、queue模拟实现
- 四、vector和list的优缺点
- 五、deque
- 六、deque的优缺点
- 七、deque为什么作为stack和queue的默认适配容器
一、适配器
1.适配器的概念:
封装一个已有对象,转换其接口
2.容器适配器:
封装一个已有容器对象,转换其容器对象的接口
3.容器适配器中没有迭代器
(1)行为约束,保证栈后进先出和队列先进先出行为
(2)安全保证,避免破坏内部结构,如:priority_queue的堆序性
4.适配器模式:
封装旧对象 + 接口转换层
适配器模式体现封装和代码的复用
二、stcak模拟实现
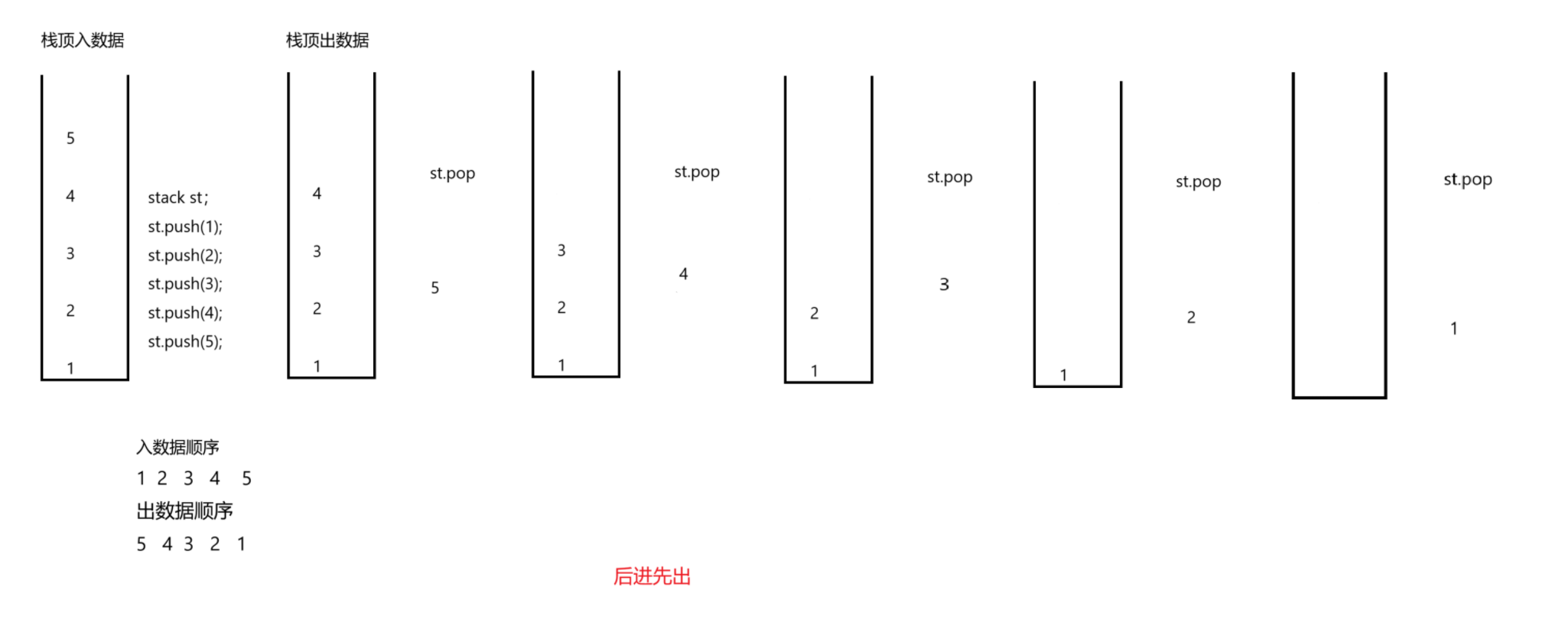
1.stcak栈顶出入数据,后进先出
2.stack的底层可以是数组结构也可以是链式结构
而stack的接口只需要保证拥有push,pop,top...等操作以及保证后进先出
栈顶出入数据
(1)栈的底层可以是数组也可以是链表,跟vector和list的底层一样
(2)栈的接口push,pop,top...等操作的行为,vector和list中也拥有
(3)(1) + (2)表明栈的实现可以封装一个·vector/list容器的对象
在栈的接口中转换vector/list的接口,实现代码的复用
(4)实现栈的逻辑 == 封装一个已有的容器对象 + 转换其容器对象的接口
所以栈为容器适配器
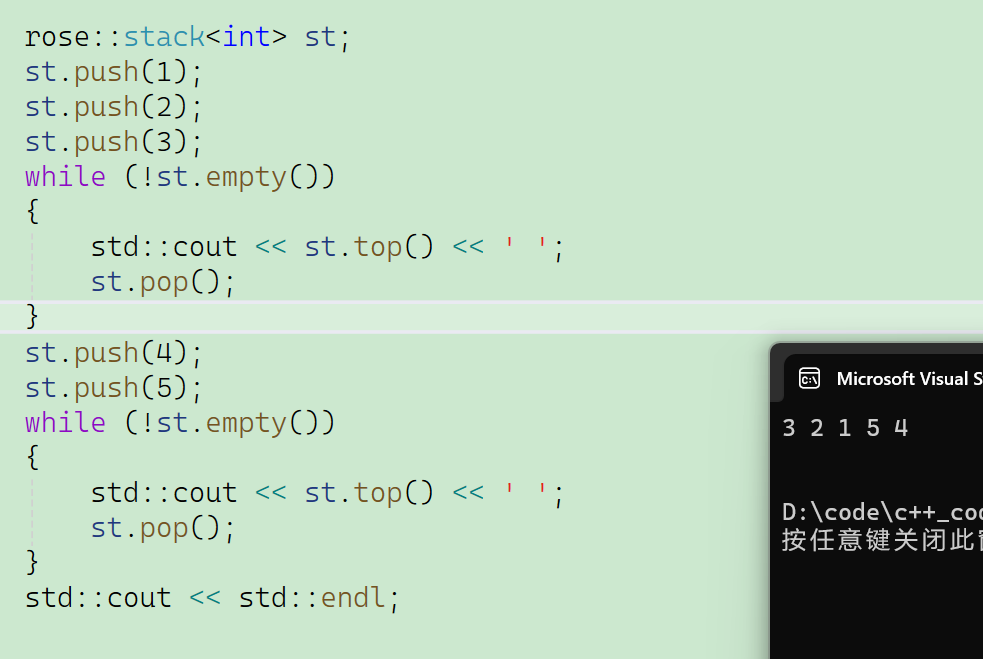
3.stack模拟实现

4.根据出栈的时机不同,出栈的顺序也会不一样

三、queue模拟实现
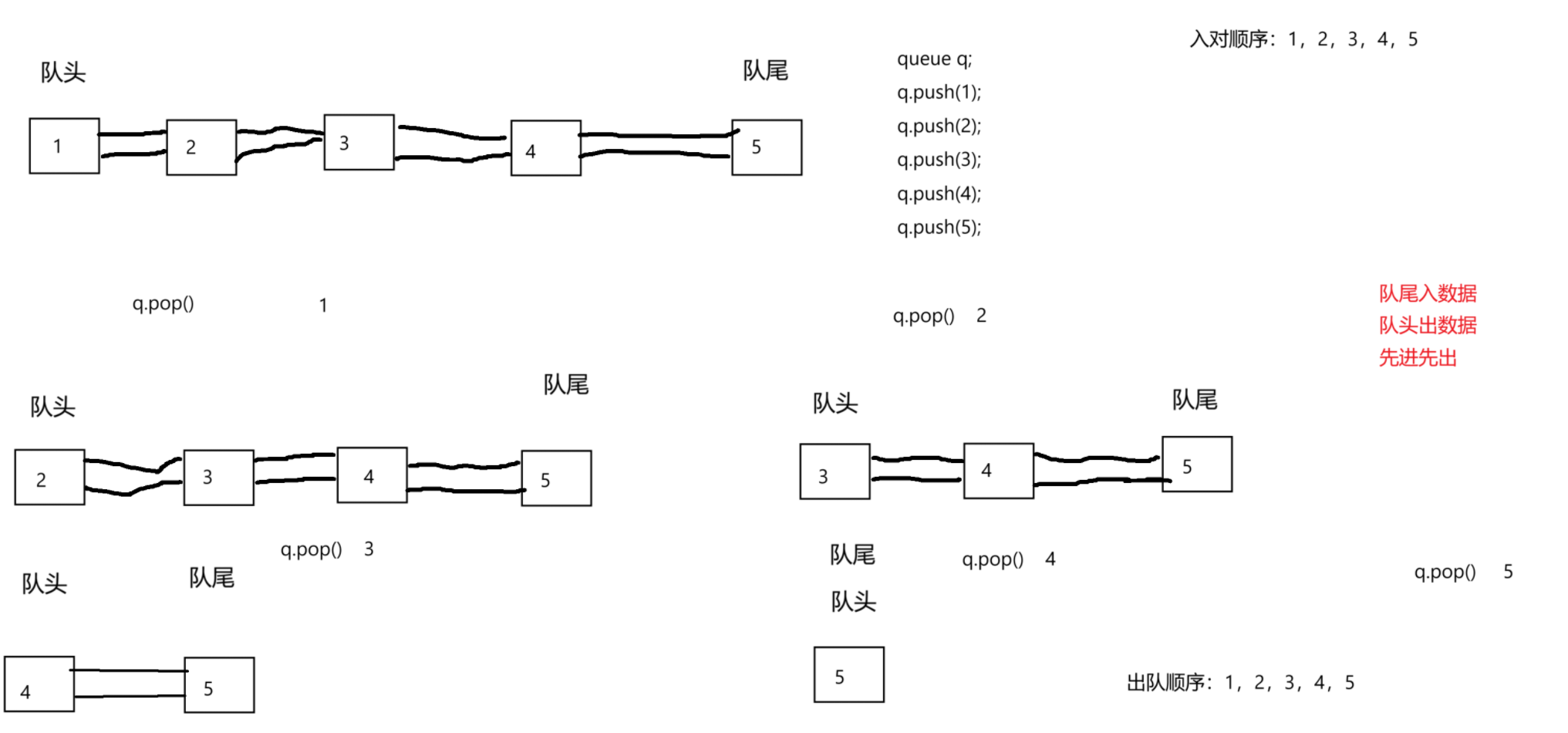
2. queue的底层可以为链式结构
而queue的接口只需要保证拥有push,pop,top...等操作以及保证先进先出
队尾入数据,队头出数据
(1)队列的底层可以是链表,跟list的底层一样
(2)队列的接口push,pop,top...等操作的行为,list中也拥有
(3)(1) + (2)表明队列的实现可以封装一个list容器的对象
在队列的接口中转换list的接口,实现代码的复用
(4)实现队列的逻辑 == 封装一个已有的容器对象 + 转换其容器对象的接口
所以对列为容器适配器
(5)queue之所以不支持数组结构也就是vector原因是数组结构头部删除需要挪动数据
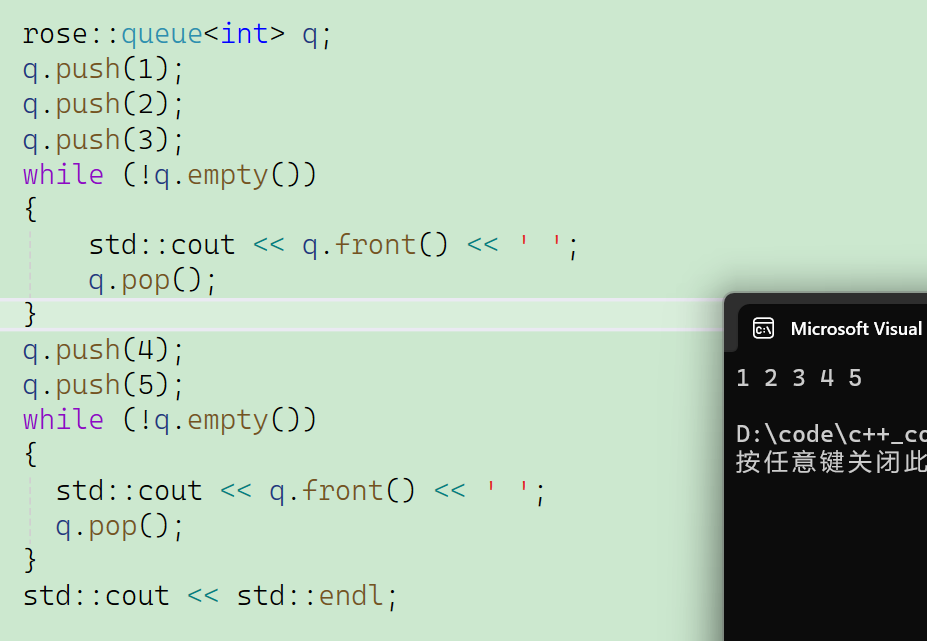
3.queue模拟实现

4. 无论出队列的时机如何,出队列的顺序都是一致的

四、vector和list的优缺点
1.vector
优点:
(1)支持[]下标访问,速度效率快
(2)cpu高速缓存命中率高
(3)内存利用效率高,不存在为存储指针开辟内存
(4)尾插尾删效率高,插入只需要在尾部增添数据,删除只需要--_size
缺点:
(1)头部中间位置插入删除效率低,因为要挪动数据
(2)空间不足需要扩容,而c++的扩容又都是异地扩容
(开辟一块新空间,拷贝旧空间的数据,释放旧空间)
扩容代价高
(3)存在空间的浪费,比如:当前空间为100,有效数据个数为100
此时插入一个新数据,需要扩容至200,之后便不再使用该vector
那么就会浪费99个数据的空间
2.list
优点:
(1)任意位置的插入删除效率高,不需要挪动数据,只需要更改结点中的指针的指向
(2)不存在扩容和浪费空间,存储多少个数据那么旧申请多少个结点
缺点:
(1)不支持[]下标访问,如果需要一下子跳跃很多数据,效率低
(2)cpu高速缓存命中率低
(3)内存利用效率低,因为结点中存储上一个结点和下一个结点的指针
3.vector的优点就是list的缺点,list的优点就是vector的缺点
vector和list属于互补的关系
4.cpu高速缓存命中率
(1)数据是存储在内存当中的,内存的速度跟不上cpu的速度
(2)当cpu需要处理数据时,正因为内存的速度跟不上cpu的速度
所以cpu不会直接去内存中获取数据,而是向缓存中获取数据
(3)如果cpu向缓存中获取数据成功,那么就称作cpu高速缓存命中成功
如果cpu向缓存中获取数据失败,那么就称作cpu高速缓存命中失败
(4)如果cpu向缓存中获取数据失败,那么缓存就会向内存中获取该数据
然后cpu再向缓存中获取数据
(5)缓存向内存获取数据,并不是只将该数据拷贝到缓存
而是将该数据及该数据附近位置的数据全部拷贝到缓存
5.vector cpu高速缓存命中率高正是因为底层是数组结构,数组物理地址空间是连续的
如果首次cpu高速缓存命中失败,缓存向内存中拷贝该数据时,就会将数组附近都拷贝
到缓存当中,那么接下来cpu访问的数组的数据时,大部分都会直接命中
list cpu高速缓存命中率低正是因为底层是链式结构,物理地址空间是不连续的
如果首次cpu高速缓存命中失败,缓存向内存拷贝该数据时,会将该数据物理空间地址
连续的一部分拷贝到缓存,可是链表的物理空间地址是不连续的,所以拷贝到缓存中
是否有下一个结点的数据是不可知的,那么当继续访问链表的数据,就又会产生命中
失败缓存再次区内存中拷贝该数据及其物理空间地址附近的数据
五、deque
1.deque的使用
通过观察deque的接口可以发现,deque支持头部尾部的插入删除
也支持[]下标访问,特别像是vector和list的融合体
2.vector的优点就是list的缺点,list的优点就是vector的缺点
那么有没有一种数据结构,使得头部尾部的插入删除效率高,支持[]下标访问,
cpu高速缓存命中率高
那么就是deque
3.deque正是结合了vector和list的优点而产生的
4.deque的底层结构

(1)deque的成员变量为一个数组指针
(2)该成员变量指向一个中控数组
(3)中控数组又是一个存储指针的数组,存储着每一个buffer数组的指针
(4)当存储数据的空间不足时,只需要新增一个buffer数组,不需要扩容和拷贝数据
只有当中控数组满了时,才需要对中控数组进行扩容,当然中控数组中存储的
是指针,扩容拷贝的代价不会太大,并且中控数组扩容的次数还会比较少
(5)因为每一个buffer数组都比较小,所以不会出现浪费太多空间的场景
假设一个buffer大小为n,插入了x个数据,那么也只会浪费n - x个空间
5.deque的迭代器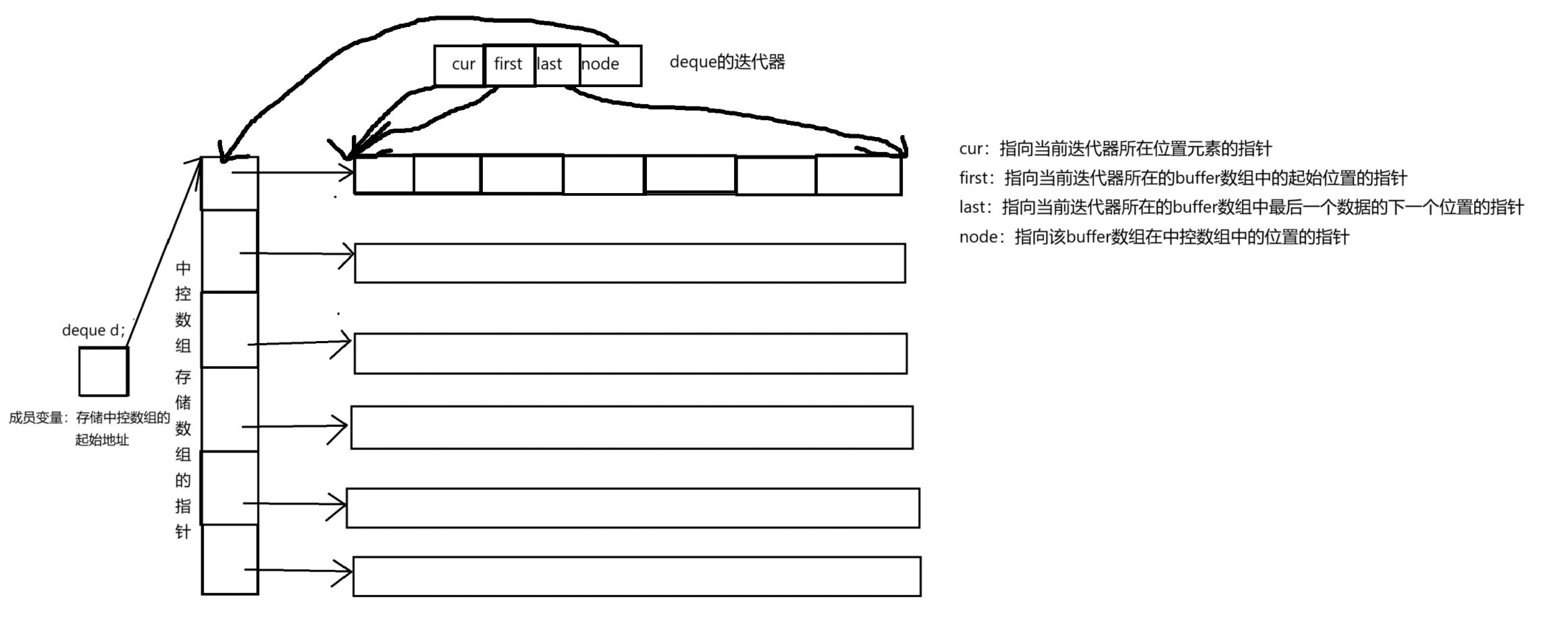 (1)cur是指向当前迭代器所在的buffer数组中的元素的指针 T*
(1)cur是指向当前迭代器所在的buffer数组中的元素的指针 T*
(2)first是指向当前迭代器所在的buffer数组中起始位置的指针 T*
(3)last是指向当前迭代器所在的buffer数组中最后一个数据的下一个位置的指针 T*
(4)node是指向当前迭代器所在的buffer数组在中控数组中位置的指针 T**
中控数组中存储的是buffer数组的起始地址,也就是T*
那么指向中控数组中位置的指针就是T**
首先指向中控数组中的位置,那么就是一个指针需要一个*
而中控数组中的数据类型又是T*,所以主席昂中控数组中位置的指针为T**
6.deque的遍历 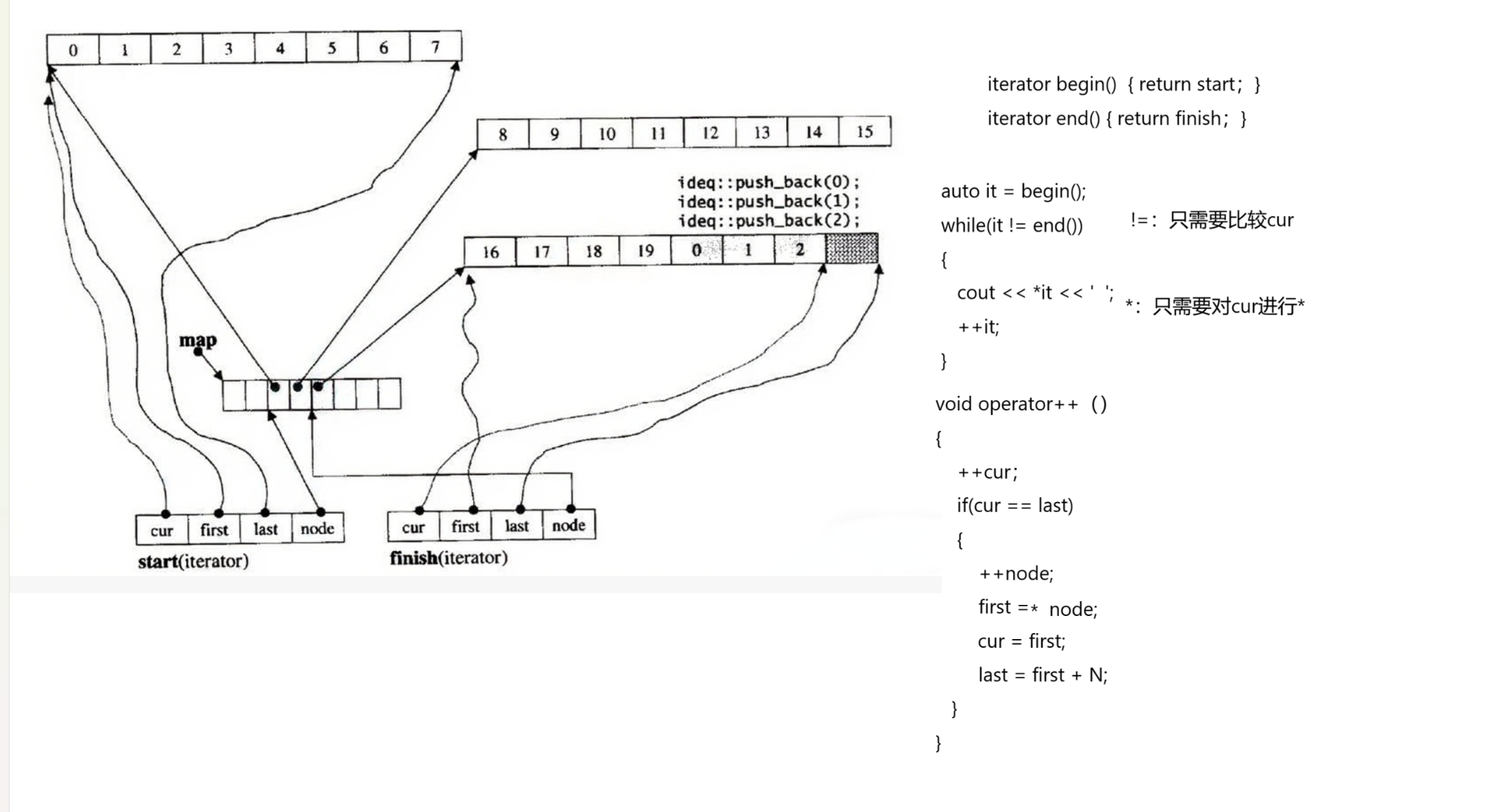 (1)start表示第一个有效数据的迭代器 == begin()
(1)start表示第一个有效数据的迭代器 == begin()
(2)finish表示最后一个有效数据下一个位置的迭代器 == end()
(3)判断两个迭代器是否相等(!=)
只需要比较cur就可以
因为不同buffer中的cur不相等,相同buffer中不同位置的数据的cur不相等
而迭代器相等是指相同buffer中的相同位置
所以!=子需要比较cur
(4)*解引用
*解引用只需要解引用cur就可以了
因为cur是指向当前迭代器所在的buffer数组中的元素的指针 T*
(5)++迭代器
本质上就是++cur,但是当cur == last表明当前buffer数组已经遍历完毕
需要跳转到下一个buffer数组,而要跳转到下一个buffer数组只需要++node
因为node是指向当前迭代器所在的buffer数组在中控数组中位置的指针
指向中控数组中位置的指针,++就是中控数组的下一个位置的指针
此时*node就为新的buffer数组的起始位置的指针
紧接着以此更新first,cur,last就可以得到新的buffer数组中第一个有效元素
的迭代器
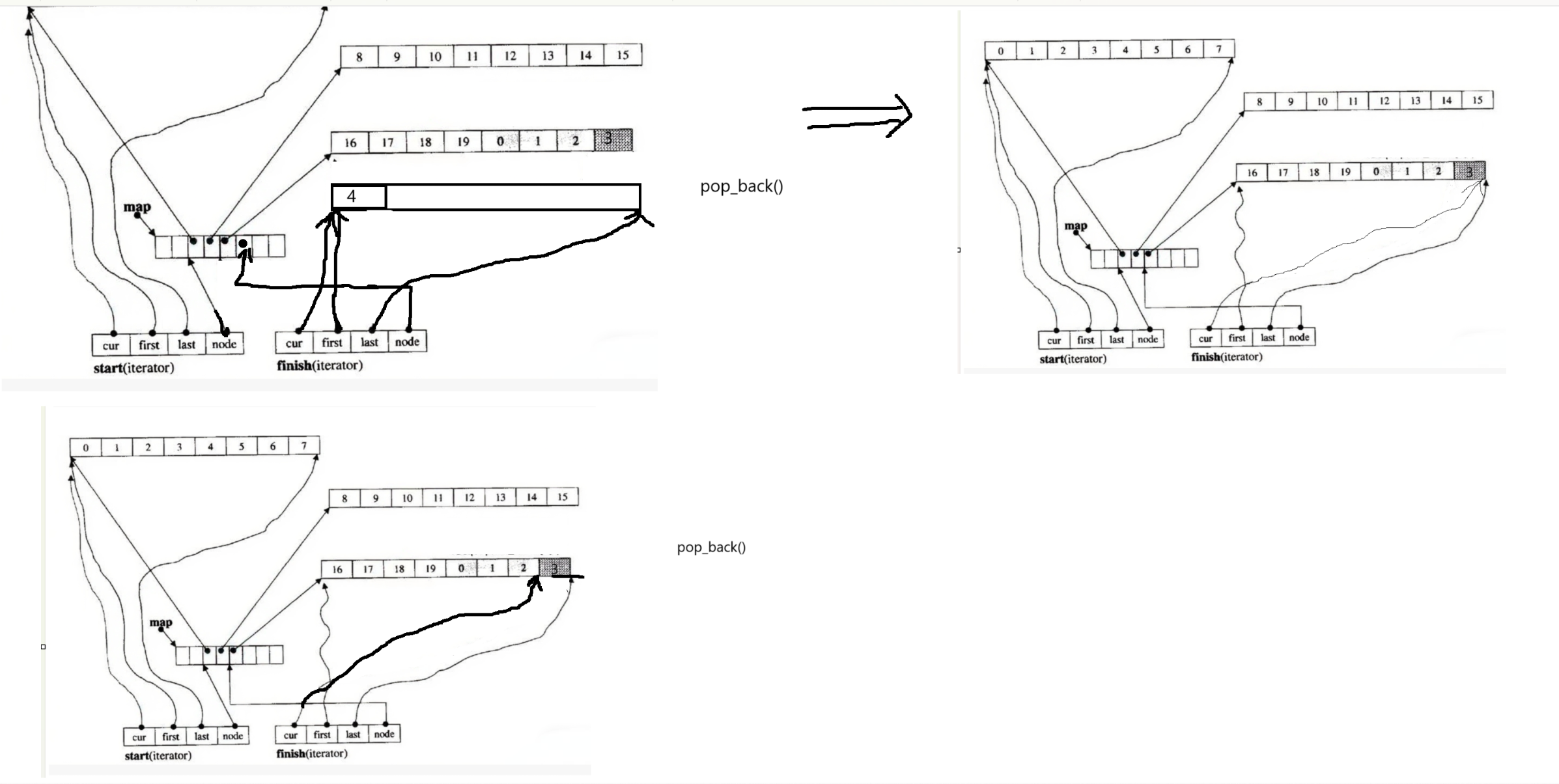
7.deque的尾插尾删
(1)deque的尾插尾删是借组finish迭代器实现的
(最后一个有效数据的下一个位置的迭代器)
(2)如果finish中的cur != last,那么就在finish迭代器中cur位置插入
然后更新finish
如果finish中的cur == last,那么就增加新的buffer,将新的buffer的地址交给
中控数组,如果中控数组满了,那么就有涉及到中控数组扩容的问题,假设
中控数组没有满,那么将新的buffer的地址交给中控数组,在新的buffer数组中
插入数据,更新finish
(3)尾删直接更新finish中的cur,--cur就可以,更新finish
如果--cur == first,那么就表明该buffer数组就空了,释放掉该buffer数组,
更新finish以及中控数组 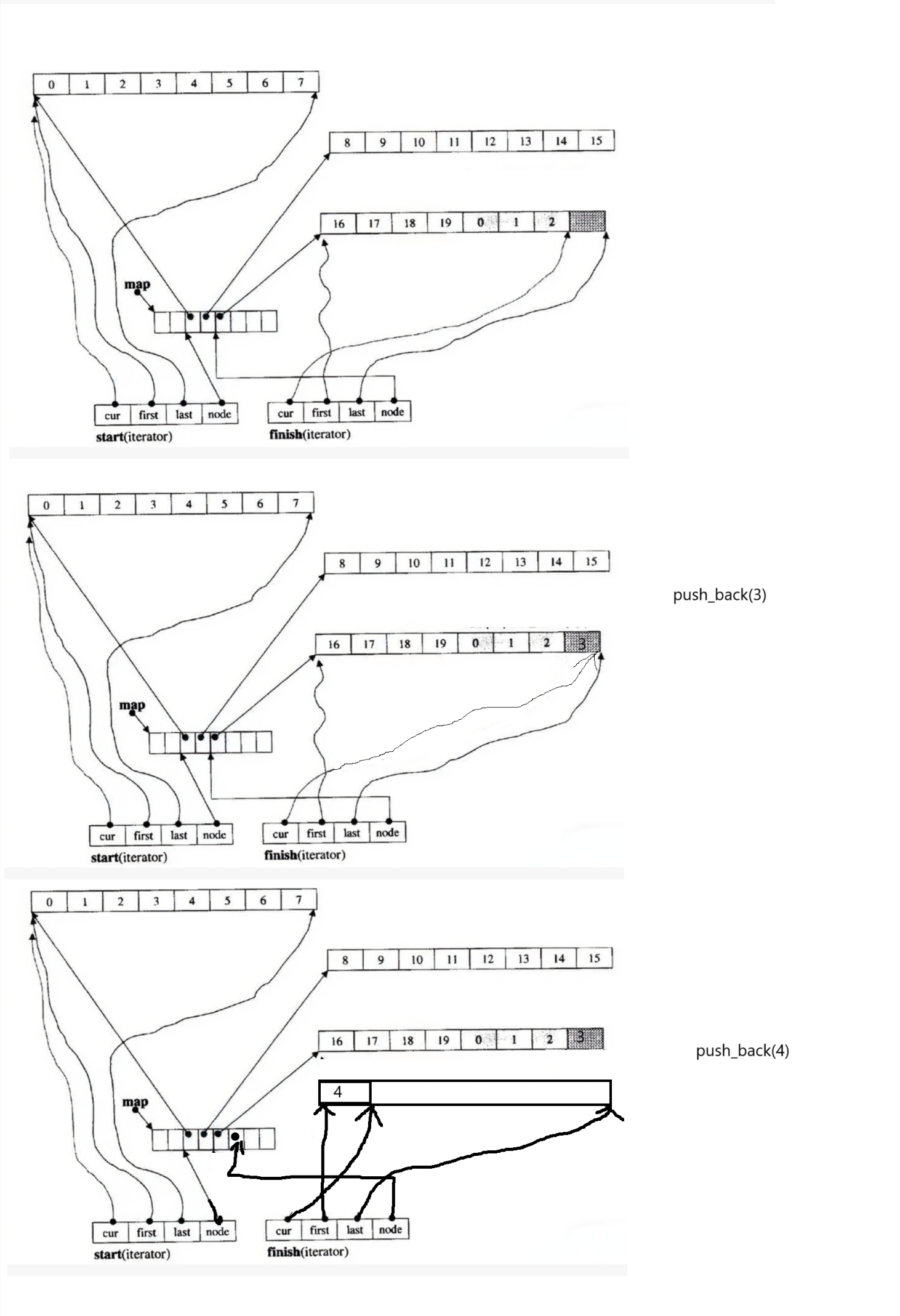
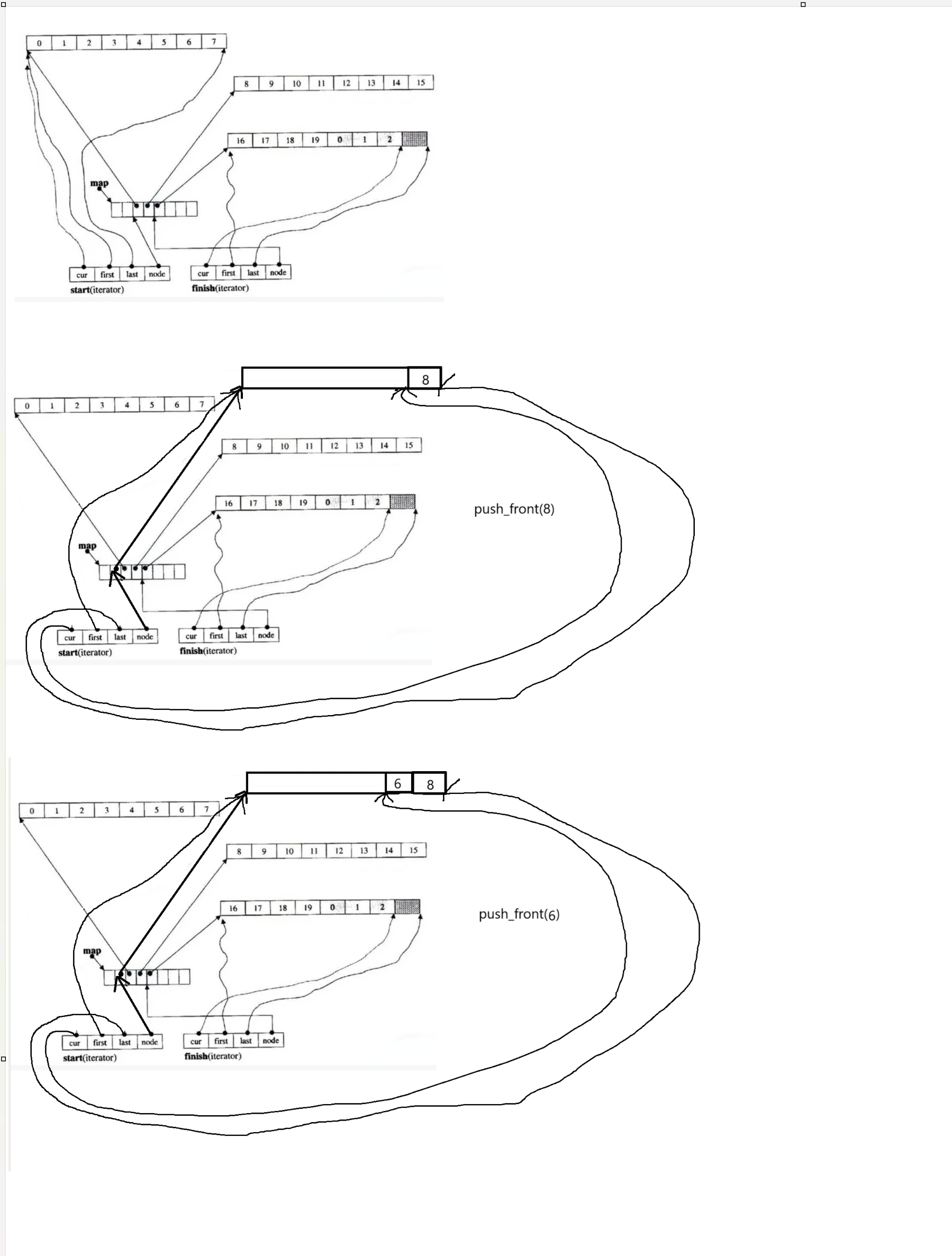
8.deque的头插头删
(1)deque的头插头删是借助start迭代器来实现的
(第一个有效数据位置的迭代器)
(2)如果cur != first,那么直接在--cur的位置插入数据,更新start就可以了
如果cur == first,那么表示该buffer数组头部位置已经满了无法在该buffer数组进行头插
那么就需要新增一个buffer数组,将buffer数组的起始地址交给中控数组,如果中控数组
满了那么就需要对中控数组进行扩容,此时假设中控数组没有满,那么紧接着在新增的
buffer数组的最后一个位置进行插入,更新start迭代器
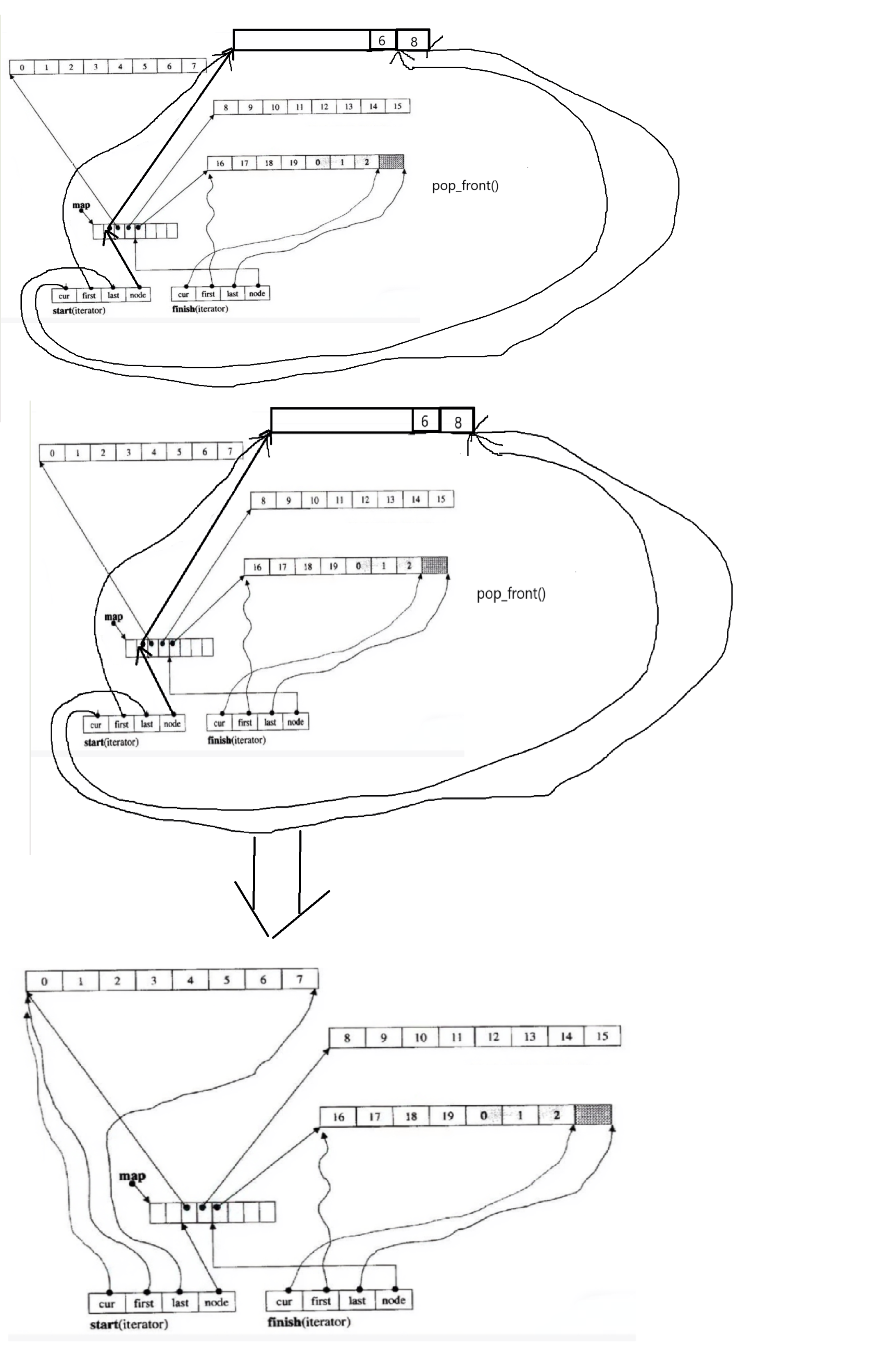
(3)头删直接对start迭代器进行++cur,然后更新start迭代器
如果++cur == first,表示此时该buffer数组为空,那么就需要释放该buffer数组,在中控
数组中删除该buffer数组的地址,然后更新start迭代器
9.+=运算符重载,[]运算符重载
(1)+=运算符重载依靠迭代器实现,[]运算符重载依靠+=实现 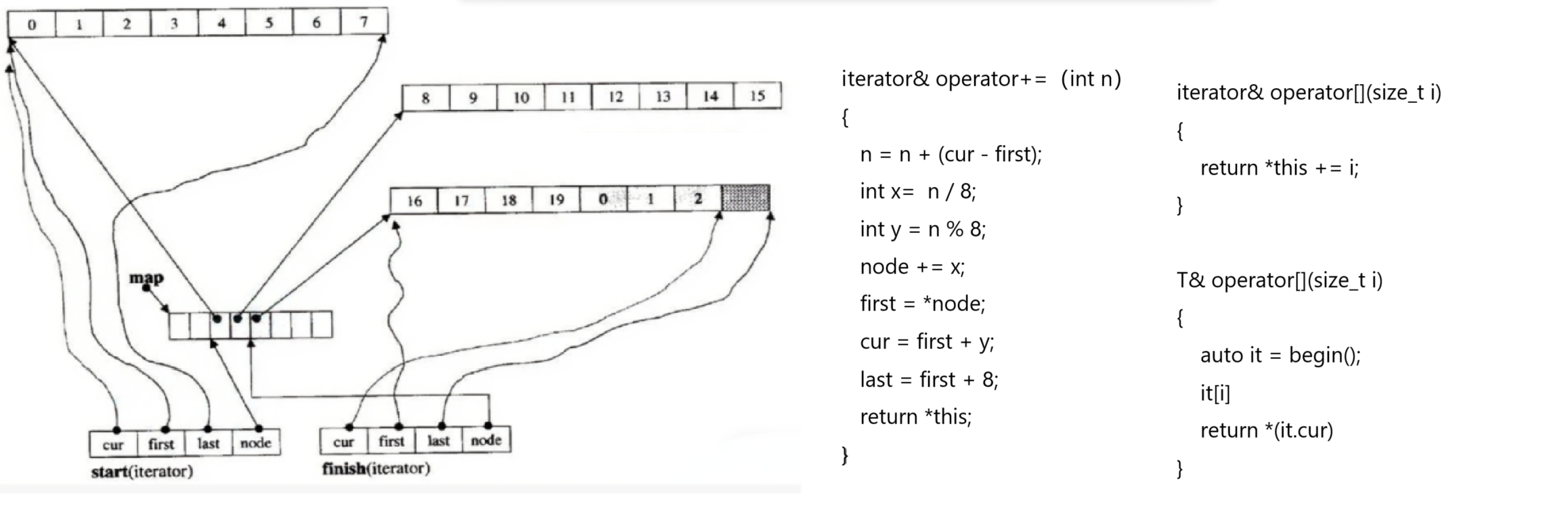
(2)n = n + (cur - first)
是担心第一个buffer头部不是满的,所以cur - first == 起始位置到第一个有效数据之间
相差多少数据,以此来纠正n
(3)int x = n / 8 == 得到+=i之后buffer会跳转到从现在buffer开始的第几个buffer
(4)int y = n % 8 == 得到+=i之后的buffer中下标为y位置的数据
(5)node += x就可以直接得到最终的buffer
(6)接下来就是更新迭代器,cur = first + y 就可以得到最终buffer中下标为y的元素的地址
六、deque的优缺点
1.优点
(1)支持[]下标访问,效率还不错
(2)cpu高速缓存命中率不错
(3)内存使用效率高
(4)扩容也只是针对于中控数组的扩容代价低
(5)浪费空间少,最多浪费buff - 1个空间
(6)头部,尾部是插入删除效率高
2.缺点
(1)中部位置插入删除效率低,因为要挪动数据
(2)迭代器遍历效率低,虽然看着不错,但是相比vector和list迭代器相差甚远
(3)只是为了最大程度的融合vector和list的优点,导致deque像是一个四不像
[]效率不及vector,cpu高速缓存命中率也不如vector
中间位置的插入删除不如list
七、deque为什么作为stack和queue的默认适配容器
1.stack只注重栈顶的插入删除,而deque一端的插入删除效率都很高
并且使用deque没有数据的扩容和空间浪费
2.queue注重队尾入数据和队头出数据,而deque两端的插入删除效率都很高
并且使用deque可以更高效的使用内存,就不会在内存中存储很多指针
3.stack和queue都是容器适配器,容器适配器是没有迭代器的
stack和queue是不可以进行遍历的,所以deque迭代器的缺点也不会展现出来
4.所以deque才作为stack和queue的适配容器
![[echart] Vue3中使用Echart时图表不渲染](http://pic.xiahunao.cn/[echart] Vue3中使用Echart时图表不渲染)











)

栈和队列算法题 OVA)



算法深度剖析:动态环境下的路径规划革新)
——组件通信及其他API)