目录
三剑客支持扩展正则写法
grep命令
sed命令
sed指定行查找:
sed模糊过滤文件内容
sed之删除:
sed之替换:
sed追加插入替换:
sed后向引用:
awk命令
awk按照行查找
awk模糊过滤文件内容
awk取列
awk指定分隔符:
awk模式+动作
awk数字比较:
Linux三剑客是指grep、sed和awk这三个强大的文本处理工具,它们在Linux系统中被广泛用于处理和分析文本数据。
三剑客支持扩展正则写法
grep -E或者egrep
sed -r
awk 默认支持扩展正则
grep命令
作用:模糊过滤文件的内容
语法:
grep [参数] '过滤的内容' 文件
参数:
grep -v :取反,匹配不包含指定内容的行
grep -r :递归搜索,搜索指定的目录以及目录下的文件
grep -i :不区分大小写
grep -w :精准匹配
grep -o :显示匹配过程
grep -E :支持扩展正则,相当于egrep
grep -A n :显示过滤到内容的后 n行
grep -B n :显示过滤到内容的前 n行
grep -C n :显示过滤到内容的前后各n行
grep -n : 显示过滤内容的行号
grep -c :统计某个单词出现的次数
sed命令
功能:用于对文本进行流式编辑,可以进行替换、删除、插入等操作
语法:
sed [参数] '动作' 文件
参数:
sed-i修改源文件
sed-r支持扩展正则
sed-n取消默认输出
创建环境
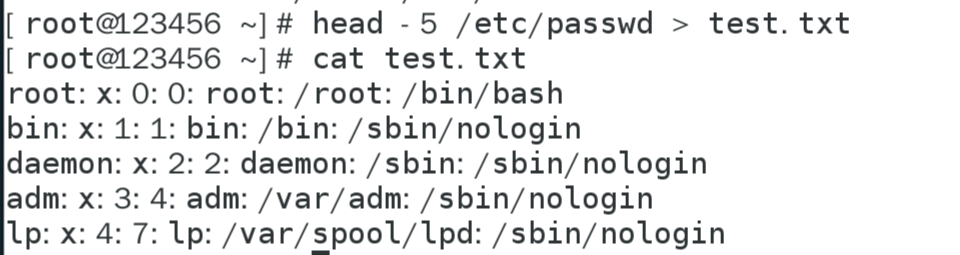
sed指定行查找:
sed -n 只显示被处理的行,通常配合p命令使用

过滤区间范围:
sed -n '2,4p' 文件
过滤2-4行

过滤2到最后一行
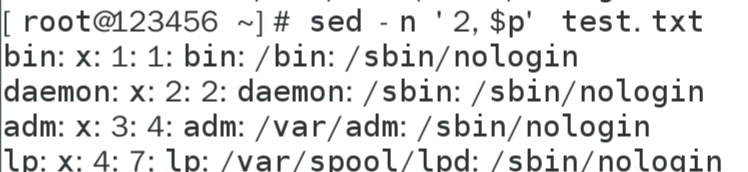
过滤屏幕上的内容

sed模糊过滤文件内容
 模糊过滤语法:
模糊过滤语法:
sed -n '/过滤内容/p' 文件
sed -n '/^r/p' 文件 :过滤r开头的行
sed -n '/^[1-4]/p' 文件 :过滤1-4开头的行
sed -n '/n$/p' 文件 :过滤n结尾的行
过滤区间范围:
sed -n '//,//p' 文件
sed -n '/8.00/,/12.00/p' 文件 :过滤8.00开始到12.00结束的内容
sed之删除:
sed '3d' 1.txt :删除第三行
sed -i '3d' 1.txt :删除第三行(修改源文件)
sed '2,4d' 1.txt :删除二到四行
sed '2,$d' 1.txt :删除二到最后一行
sed '/过滤的内容/d' 1.txt :删除过滤的那一行
sed '/^b/d' :删除b开头的行
-r 支持扩展正则:
sed -r '/^bin | ^lp /d' 1.txt :把bin开头或者lp开头的行删除
sed -r '/^bin/,/^lp /d' 1.txt :把bin开头到lp开头的行删除
扩展正则:
+ ? | () {} \b \s \w
sed之替换:
sed 's# 将谁 # 替换成谁 #g' 1.txt
sed 's@ 将谁 @ 替换成谁 @g' 1.txt
sed 's/ 将谁 / 替换成谁 /g' 1.txt
g:整行替换 ,不加g默认值替换每行第一个单词
sed 's/root //g' 1.txt :把所有root替换成空(删除)
sed 's/[0-9]//g' 1.txt :把所有数字替换成空(删除)
边界符:\b 或 \<
sed 's/\broot\b/lg/g' 1.txt :
如果有sroot,只把root替换,结果是slg
撬棍 \
如果想把 /root/ 替换可以用撬棍或#
sed 's/\/root\//bin/g' 1.txt
sed 's#/root/#bin#g' 1.txt
替换指定行:
sed '3s/root/bin/' 1.txt :替换第三行root为bin
sed '2,3s/root/bin/' 1.txt :替换2-3行root为bin
sed '/adm/s/bin/root/g' 1.txt :先过滤出adm那一行,再把那行bin替换成root
sed '/adm/,/hg/s/bin/root/g' 1.txt :先过滤出adm到hg的行,再把那些行中bin替换成root
sed追加插入替换:
sed '3i aaa' 1.txt 在第三行插入aaa
sed '3a aaa' 1.txt 在第三行下一行(第四行)插入aaa
sed '3c aaa' 1.txt 把第三行整行替换成aaa
sed '3w new' 1.txt 把第三行内容保存到new文件中
sed '3,4w new' 1.txt 把3-4行内容保存到new文件中
sed后向引用:
sed -r s#()()()#\1\2\3#g
\1对应第一个括号
\2对应第二个括号......
可以对指定内容进行修改增添
例:利用sed后向引用批量创建文件
seq 5|sed -r 's#(.*)#touch \1.txt#g'|bash
例:利用后向引用批量创建用户
seq 5|sed -r 's#(.*)#useradd \1#g'|bash
awk命令
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据进行分析并产生报告时,显得尤为强大。简单的说就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分在进行各种分析处理。
作用:
1.取行
2.取列
3.模糊过滤
4.数据统计 数据运算
5.支持for循环 if判断 数组.. 6.格式化输出 sed后向引用
语法:
awk '模式' file :不加任何动作默认输出
awk '模式{print}' file
其他的命令输出|awk '模式'
awk默认支持正则
awk按照行查找
awk 'NR==3' file :输出第三行
NR存放着文件中每行的行号
NR的表达式:
== 等于第几行
> 大于第几行
< 小于第几行
>= 等于等于第几行
<= 小于等于第几行
!= 不等于
&& 并且 || 或者
awk 'NR<3' file :输出小于3的行
awk 'NR>3&&NR<5' file :输出大于3小于5的行
awk 'NR<3|NR>5' file :输出小于3或者大于5的行
awk模糊过滤文件内容
awk '/内容/' file
awk '/123/,/456/' file
awk '/root/' file :匹配所有包含root的行
awk '/^r/' file :匹配所有r开头的行
awk '/h$/' file :匹配所有h结尾的行
awk '/^[1-3]/' file :匹配所有1-3开头的行
awk '/^2/,/^4/' file :匹配所有2开头的行到4开头的行之前的内容
awk取列
默认以空格和tab键为分隔符,如果文件中没有空格和tab键则文件内容被当做第一列
awk '{print $n}' file :取出每一行第n列的内容
awk '{print $1}' file :取出第一列内容
awk '{print $1,$3}' file :取出第一列和第三列
awk '{print $1''----''$3}' file :取出1,3列,并在中间加上----
awk '{print NF}' file :显示最后一列列号
awk '{print $NF}' file :显示最后一列的内容
df -h | awk '{print $5}' 取出磁盘第五列信息
df -h | awk '{print $(NF-1)} :取出磁盘倒数第二列信息'
awk指定分隔符:
默认以tab键或空格分隔
指定分隔符:
awk -F : 或
awk -F " : " : " "中是指定分隔符
awk -F " :/ " :指定多分隔符
awk -F: '{print $NF}' 1.txt
awk -F ":/" '{print $2}' 2.txt
awk模式+动作
awk 'NR==3{print $3}' file :取出第三行的第三列
df -h| awk '/sda3/,/sr0/{print $3}'
df -h|awk 'NR >3 &&NR<5{print $4}'
awk '$2 ~ /^o/' file :筛选输出第二列内容以字母 o 开头的所有行
awk数字比较:
awk -F : '$3>90' file :筛选第三列内容大于90的行
awk -F : '$3>80&&$3<90' file :筛选第三列内容大于80的且小于90的行
这是我的个人学习笔记,主要用于记录自己对知识点的理解和梳理。由于目前仍在学习探索阶段,内容中难免存在理解偏差或表述疏漏,恳请各位大佬不吝赐教,多提宝贵意见~ 若有不同看法,欢迎理性交流探讨,感谢包容与指正!




)









)


![[echarts] 更新数据](http://pic.xiahunao.cn/[echarts] 更新数据)

)