摘要: 长久以来,卷积神经网络(CNN)凭借其精心设计的归纳偏置(inductive biases),无可争议地统治着计算机视觉领域。然而,一篇名为《An Image is Worth 16x16 Words》的论文彻底改变了这一格局,它所提出的 Vision Transformer (ViT) 模型,成功地将源于自然语言处理(NLP)领域的 Transformer 架构直接应用于图像识别,并取得了惊人的成果。本文旨在深度剖析 ViT 的核心原理、架构设计及其深远影响,阐明它是如何挑战传统,并为视觉任务提供一个全新的、具有强大扩展性的解决方案。
今天我先给大家带来原理讲解与入门教学,明天会详细剖析VIT背后深层的原理与代码实现
第一章:背景——CNN的王朝与Transformer的崛起
要理解 ViT 的革命性,我们必须首先回顾它所挑战的CNN王朝。
1.1 CNN的基石:生物的视觉皮层
CNN 的设计哲学源于对生物视觉皮层的模仿。其核心在于两大归纳偏置:
局部性 (Locality):假设图像中邻近的像素点具有强相关性。通过小尺寸的卷积核(Kernel),CNN 能够有效地从局部区域提取边缘、纹理等基础特征。
平移不变性 (Translation Invariance):无论一只猫出现在图像的哪个位置,它仍然是一只猫。通过权重共享(Weight Sharing)的卷积操作和池化(Pooling)操作,CNN 能够识别出在空间上平移的相同特征。
这种分层、由局部到全局的特征提取范式,使得 CNN 在处理图像时极为高效且强大,成为了过去十年计算机视觉领域的黄金标准。
1.2 NLP的革命:自注意力机制的全局视野
与此同时,在自然语言处理领域,Transformer 架构凭借其核心的自注意力机制 (Self-Attention) 颠覆了循环神经网络 (RNN) 的主导地位。自注意力的核心思想是,在处理一个序列(如一个句子)时,序列中的每个元素(单词)都可以直接与其他所有元素计算相关性,从而动态地捕捉长距离依赖关系。这种对全局上下文的直接建模能力,正是处理复杂语言现象的关键。
1.3 跨界的融合
ViT 的诞生源于一个大胆的设想:我们能否抛弃 CNN 为图像“量身定制”的归纳偏置,直接将 Transformer 强大的全局建模能力应用于视觉任务?大白话解释:一张图像,是否可以被当作一个“句子”来阅读?
第二章:ViT架构深度解析
ViT 的架构回答了上述问题。它通过一系列巧妙的设计,将二维的图像数据转换为了 Transformer 所能处理的一维序列数据。
2.1 图像的序列化:从像素网格到“视觉词元”
ViT的第一步,是将输入的二维图像(例如 224×224×3)分割成一系列固定大小的不重叠的图像块(Patches)。例如,如果每个Patch的大小是 16×16,那么一张 224×224 的图像就会被切分成 (224/16)×(224/16)=14×14=196 个Patches。
类比NLP: 这一步就像将一个段落拆分成一个个独立的单词。每个Patch就是图像世界里的一个“视觉单词”。
原始的Patch是二维的(16×16×3),而Transformer的输入需要是一维的向量序列。因此,ViT会将每个Patch展平(Flatten)成一个长向量(16×16×3=768),然后通过一个标准的可训练线性投影层(Linear Projection Layer)将其映射到一个固定的维度 D(例如768)。这个输出的向量就被称为Patch Embedding。
类比NLP: 这完全等同于NLP中的词嵌入(Word Embedding)过程,将每个单词映射到一个高维的语义向量空间中。
2.2 注入空间与全局信息
标准的Transformer模型是置换不变的(Permutation-Invariant),也就是说,打乱输入序列的顺序不会影响最终结果。这在处理语言时是个问题(“我爱你”和“你爱我”含义不同),在处理图像时同样是致命的(打乱图像块会让图像失去空间结构)。
为了解决这个问题,ViT为每一个Patch Embedding都加上一个可学习的位置编码(Position Embedding)。这个编码向量告诉模型每个Patch的原始位置信息(例如,这是第1行第3列的Patch)。
借鉴NLP模型BERT的设计,ViT在所有Patch Embeddings序列的开头,额外添加一个特殊的可学习的分类令牌([CLS] Token)。这个Token不代表任何具体的图像块,它的作用是在经过Transformer Encoder之后,作为一个“全局信息聚合器”,其最终的输出状态将代表整张图像的语义信息,用于最终的分类任务。
至此,我们已经成功地将一张图像转换成了一个Transformer可以理解的向量序列(Sequence of Embeddings)。
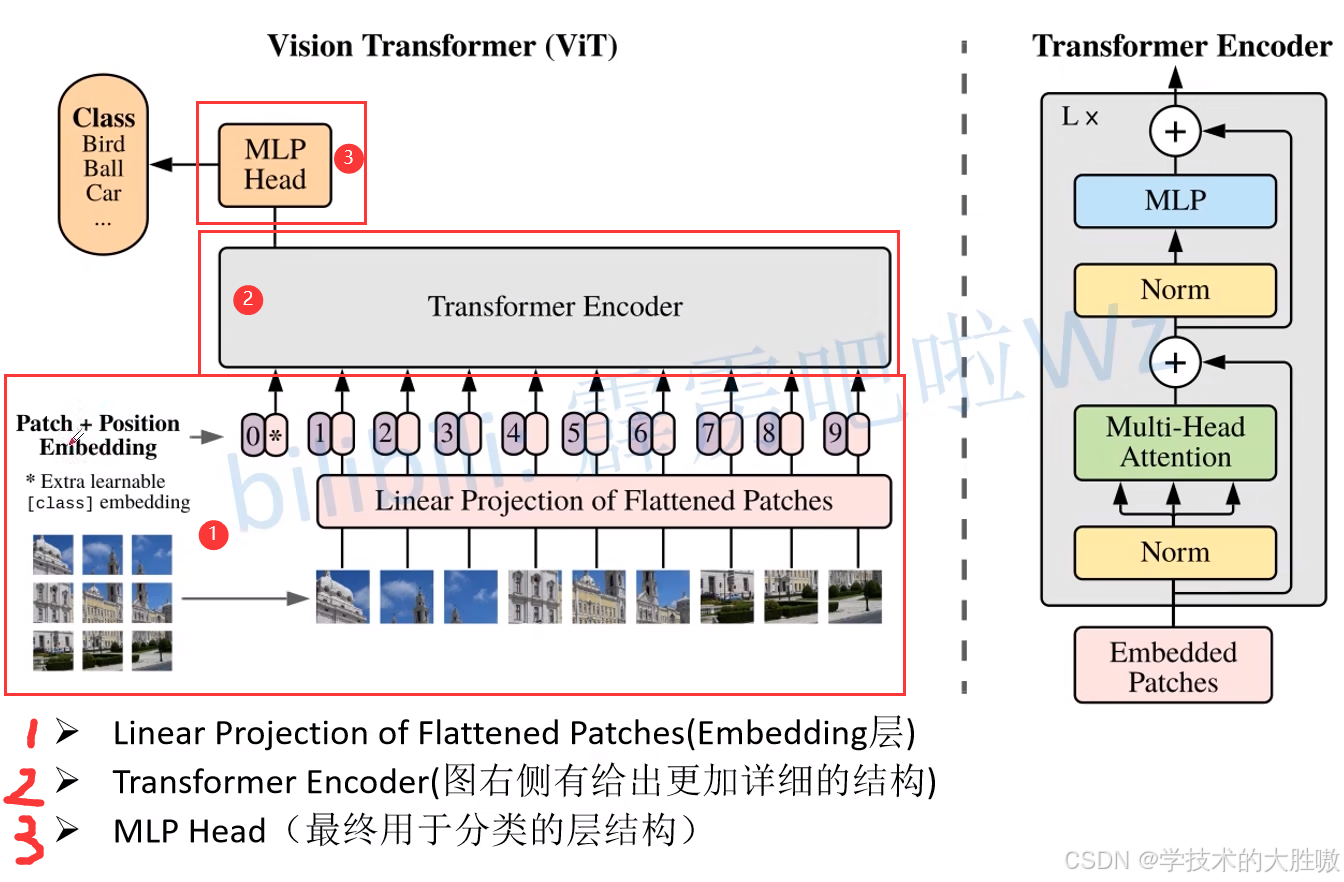
2.3 核心:Transformer 编码器
转换后的向量序列被送入一个标准的Transformer Encoder。这个Encoder由多个相同的层堆叠而成,每一层都包含两个核心子模块:
1. 多头自注意力机制(Multi-Head Self-Attention, MHSA)
这是ViT的核心。对于序列中的每一个Patch(包括[CLS] Token),自注意力机制会计算它与所有其他Patches之间的注意力分数(Attention Score)。
工作原理简述: 每个Patch向量会生成三个不同的向量:查询(Query)、键(Key)和值(Value)。
用某个Patch的Query向量,去和所有Patches的Key向量进行点积计算,得出相似度分数。这些分数经过Softmax归一化后,成为权重。
用这些权重去加权求和所有Patches的Value向量,得到该Patch在当前层的新表示。
意义: 这个过程允许每个Patch“环顾四周”,根据内容相关性,动态地从其他所有Patch中聚合信息。一个草地上的Patch可能会更“关注”天空的Patch(确定背景),而一个眼睛的Patch会高度关注另一个眼睛的Patch(捕捉对称性)。这就是ViT实现全局感受野的方式。
多头(Multi-Head): 将这个过程并行执行多次(例如12个头),每个“头”学习一种不同的关系模式(比如一个头关注纹理,另一个头关注轮廓),最后将所有头的结果拼接起来,增强了模型的表达能力。
2. 前馈网络(Feed-Forward Network, FFN)
在自注意力之后,每个Patch的新表示会独立地通过一个简单的全连接前馈网络(通常由两个线性层和一个激活函数组成)。这一步可以看作是对自注意力聚合来的信息进行进一步的非线性变换和提炼。
在每个子模块(MHSA和FFN)之后,都会使用残差连接(Residual Connection)和层归一化(Layer Normalization)来保证训练的稳定性和效率。
当序列通过所有Encoder层后,我们只取出[CLS] Token对应的最终输出向量,因为它已经聚合了整张图的全局信息。这个向量最后被送入一个简单的多层感知机(MLP Head),并最终通过了这个Softmax层输出各个类别的预测概率。
第三章:ViT的优势与挑战
3.1 优势
可扩展性 (Excellent Scalability):ViT 的性能会随着模型规模和数据量的增加而稳定提升。当在超大规模数据集(如 Google 内部的 JFT-300M)上进行预训练时,ViT 的性能超越了当时最顶尖的 CNN 模型。
更少的归纳偏置:ViT 不依赖于 CNN 的局部性假设。理论上,它能从数据中学习到比硬编码的卷积结构更通用、更强大的视觉模式。例如,它可以学会关注图像中不连续但语义相关的区域。
3.2 挑战
数据需求(Data-Hungry):ViT 的灵活性是一把双刃剑。由于缺乏 CNN 的归纳偏置作为“先验知识”,ViT 需要从零开始学习所有的视觉模式。因此,在中小规模的数据集(如 ImageNet-1k)上从头训练时,其性能通常不如同等规模的 CNN。它对大规模预训练的依赖性极强。
计算成本:自注意力机制的计算复杂度与输入序列长度的平方成正比。这意味着对于高分辨率图像(会产生更多的 Patches),ViT 的计算和内存开销会急剧增加。
第四章:影响与展望
ViT 的出现不仅仅是模型列表中的一个新成员,它更像是一场思想的解放。它证明了注意力机制是构建视觉模型的一种普适且强大的机制。
它的成功催生了计算机视觉领域的研究热潮,后续工作层出不穷:
Swin Transformer 重新引入了局部注意力和层级化结构,使得 Transformer 在通用视觉任务上更高效、更强大,成为了新的基准模型。
Data-efficient ViT (DeiT) 通过知识蒸馏等技术,显著降低了 ViT 对大规模预训练数据的依赖。
Masked Autoencoders (MAE) 提出了一种高效的自监督预训练范式,进一步释放了 ViT 的潜力。
结论
Vision Transformer 标志着计算机视觉领域一个新纪元的开启。它打破了卷积的“神话”,证明了源自语言处理的 Transformer 架构同样能在视觉世界大放异彩。虽然它并非没有缺点,但它所开辟的道路——将图像视为可被全局理解的序列——已经并正在深刻地重塑着我们对视觉智能的认知。未来的视觉模型,很可能会是 Transformer 思想与卷积思想的深度融合,而 ViT,无疑是这场伟大变革的奠基者。





:PHP 性能优化:打造高效应用)



)

)




)

解锁)
