文章目录
- 一、直觉上重要的视觉特征
- 二、视觉神经网络首层试图自主学习 TGD 算子权重
- 2.1 AlexNet
- 2.2 Vision Transformer
- 2.3 MLPMixer
- 三、针对直觉的验证试验
- 3.1 小样本集自然图像分类任务
- 3.2 小样本集医学图像分割任务
- 四、结语
早在 2012 年,卷积神经网络 AlexNet 就已经开始自主学习 TGD 算子和 TGD 特征的雏形了!
TGD 是我们定义的一种新的“变化率表征”,对连续函数而言是一种新的“广义导数”,对离散序列而言是一种新的差分。TGD 是一个名字,一个代号。所谓「 TGD 特征 」,实则为输入序列卷积 TGD 算子得到的结果,输入序列可以为图像,也可以是视频,也可以是连续 CT 扫描图等等等等。在上一篇中,我们介绍了将「 TGD 特征 」引入神经网络,提升了计算机视觉任务的性能。然而,在此之前我们就已经发现,“ 神经网络本就在自主选择学习 TGD 算子得到 TGD 特征 ”。感兴趣的朋友欢迎阅读前面的章节:
理论部分:
TGD 第一篇:初心——我想要为“阶梯函数”求导。
TGD 第二篇:破局——去除导数计算中的无穷小极限。
TGD 第三篇:革新——卷积计算导数的高效之路。
TGD 第四篇:初瞰——抗噪有效的定性计算。
TGD 第五篇:飞升——给多元函数的导数计算加上全景雷达。
TGD 第六篇:落地——离散序列的 TGD 计算。
计算机视觉应用部分:
TGD 第七篇:一维应用——信号去噪和插值。
TGD 第八篇:二维应用——图像边缘检测。
TGD 第九篇:三维应用——视频边缘检测。
TGD 第十篇:当神经网络遇到 TGD 特征。
一、直觉上重要的视觉特征
传统计算机视觉认为, 颜色、纹理、边缘 是最重要的三类视觉特征。前两者都是区域特征,描述物体的表面物理特性;后者是轮廓特征,明确各区域之间的边界。区域和轮廓的结合进一步可以帮助我们分割识别并理解物体。
有些简单任务,单独的某类特征足矣。如颜色是我们分类三色旗的重要特征,包括法国(蓝、白、红),俄罗斯(白、蓝、红),德国(黑、红、金),意大利(绿、白、红),荷兰(红、白、蓝)等;纹理是我们分类纯色丝绸、棉布、麻布等布料等的重要特征;边缘是我们分类圆形、正方形、三角形等的重要特征。
但是对于更为复杂的视觉分类任务,通常需要他们协同配合,从这些视觉特征的组合中去理解和判断更复杂的物体。
值得指出的是,无论是“颜色”、“纹理”、还是“边缘”特征,它们需要 在包含多个像素点的区域中进行统计计算 。在传统计算机视觉算法中已经论证,通过一次简单的卷积计算,就可以提取出颜色、纹理、边缘特征。纹理常用的是 Gabor 函数卷积核、边缘(梯度)特征对应的则是 TGD 卷积核。
理论上,视觉神经网络的第一层卷积层就是执行单次卷积,具备了提取的图像中颜色、纹理、边缘特征的能力。那么神经网络会这么做吗?
二、视觉神经网络首层试图自主学习 TGD 算子权重
说在前面,为力求保真,下面引用的视觉神经网络的首层卷积核结果可视化图均源自该网络原始论文。
2.1 AlexNet
2012 年,深度卷积神经网络 AlexNet 赢得 ImageNet 图像分类任务竞赛冠军,标志着深度学习时代的开启。AlexNet 网络结构图如下所示,首层便是一个 11×11×311 \times 11 \times 311×11×3 尺寸的卷积层。可以说,神经网络从首层开始就在进行特征提取了。作为开山鼻祖, AlexNet 第一层在提取些什么?
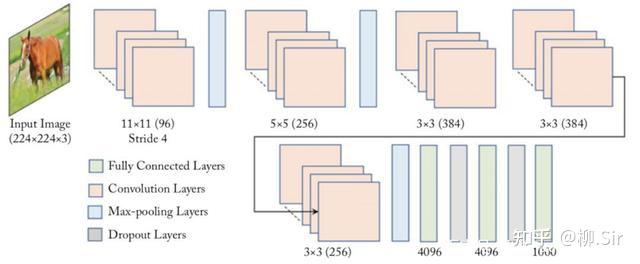
下图展示了经过 ImageNet 训练得到的,AlexNet 首层卷积层中的 969696 个 11×11×311\times11\times311×11×3 的卷积核可视化结果1,图片源自 AlexNet 原始论文。作者诚然: 网络学习到了各种频率和方向选择性的核,以及各种彩色斑点 (The network has learned a variety of frequency- and orientation-selective kernels, as well as various colored blobs. )。在我看来,色彩斑点卷积核即提取的是颜色特征;第二行很多黑白黑白间隔的卷积核实则为 Gabor 函数卷积核,提取的是纹理特征;而红框中则标注出了很多类似 TGD 算子的卷积核,提取的是边缘(图像梯度)特征。即: 神经网络在首层自主选择学习“颜色”、“纹理”、“边缘”,这些重要且易获取的视觉特征 。

在 AlexNet 之后,VGGNet 指出,尽管大卷积核具有更强的拟合和表征能力,但是直接训练大卷积核是存在难度的(数据量和算力带来的历史局限性),建议采用连续的 3×33 \times 33×3 小尺寸卷积核来等效大尺寸卷积核,并取得了更好的性能。使用连续小尺寸卷积核将导致网络层数增多,并带来训练过程中梯度消失的风险。ResNet 提出的残差结构很好地化解了网络层数增多时面临的训练困境,使得网络的层数可以向成百上千迈进。在随后数年的发展中,用于图像分类、医学分割、目标检测等任务的主流卷积神经网络基本采用 1×11 \times 11×1 和 3×33 \times 33×3 小尺寸卷积核,尺寸在 7×77 \times 77×7 及以上的卷积核则很少出现。在这些神经网络中,首层中的 3×33 \times 33×3 等小卷积核的结构属性和可解释性较差,可视化也看不出什么来,难以分辨直接提取什么特征。
2.2 Vision Transformer
迈入 2020 年,算力和数据集规模已经取得了极大的发展,研究者不满足于简单地使卷积神经网络维度上升、层数增加。视觉研究人员注意到 Transformer 在自然语言处理中的应用和成功 ,其使用的自注意力机制将整个输入序列纳入考量。此时视觉研究者意识到在更大的图片块上提取特征的时机已经成熟,并基于此提出了新的视觉范式 Vision Transformer(ViT)2,作为其核心的自注意力机制等效于在 CNN 卷积层中引入一个超大的卷积核,但是卷积核权重与输入相关。ViT 首层采用等效于 14×1414 \times 1414×14 和 16×1616 \times 1616×16 尺寸的卷积核,然而实践表明其需要使用亿级乃至十亿级数据量进行预训练,才能获得优质的模型权重。
下图展示了经过 JFT300M 训练得到的,ViT-L/32 首层 282828 个线性编码层卷积核可视化结果,图片源自 ViT 原始论文。作者同样认为: 网络首层学习到的这些卷积核旨在获取每个 Patch 内精细结构的特征表示。 (Figure 7 (left) shows the top principal components of the the learned embedding filters. The components resemble plausible basis functions for a low-dimensional representation of the fine structure within each patch. )。在我看来,下图中有略微几个训练的比较好的 Gabor 函数算子用于提取纹理特征,还有少数提取颜色的卷积核,提取图像边缘(梯度)特征的算子训练得不够理想, 这可能与自注意力机制 Self-Attention 本身就具备区域关注能力有关 ,使得边缘特征可能在注意力分布图中而非首层中体现了。

2.3 MLPMixer
短短一年之后,即 2021 年,视觉社区进一步思考:“能否放弃自注意机制,让模型从原始数据中自主地学习输入无关的超大卷积核”?研究人员将 Vision Transformer 中的注意力层直接替换为单层全连接层,并提出了视觉新范式:深度 MLP 模型 3。MLPMixer 中的单层全连接层(Token-mixing MLP)依然等效于使用一个 14×1414 \times 1414×14 或 16×1616 \times 1616×16 的超大尺寸卷积核。然而在当下的数据量基础上,采用超大尺寸稠密卷积核的 MLPMixer 性能要弱于基于人为设计自注意力机制的 ViT,延续了“数据不够,先验来凑”的历史周期律,这表明直接训练优质的超大尺寸卷积核或许需要更多的数据作为支撑。
下图展示了经过 JFT300M 训练得到的,MLPMixer-B/32 首层 192192192 个线性编码层卷积核可视化结果,图片源自 MLPMixer 原始论文。作者认为: 网络首层学习到了非常具有结构化的卷积核。 (Mixer-B/32 model that uses patches of higher resolution 32×3232 \times 3232×32 learns very structured low frequency projection units, …, using patches of higher resolution 32×3232 \times 3232×32 leads to Gabor-like low-frequency linear projection units)。从下图中我们同样看到了颜色、纹理、边缘特征的提取算子。作者在图中找到了一些 Gabor 函数卷积核,事实上其中绝大部分是 TGD 算子(红框框出的部分),用于计算图像的边缘(梯度)特征。结果符合我的直觉, MLPMixer 没有自注意力机制,为此需要把 TGD 算子嵌入网络首层权重中 。

从 AlexNet,到 ViT,再到 MLPMixer,三种不同范式的视觉神经网络都告诉我们:从海量数据中自主学习后, 颜色、纹理、边缘是首层需要提取的三类重要视觉特征 。传统计算机视觉的人类实践,与 AI 的抉择,保持高度一致。此外,大约统计可发现,边缘特征约占输入层提取通用特征的 20%20\%20% 至 30%30\%30% 。
为了提取图像的边缘(梯度)特征,模型在首层试图学习 TGD 算子的雏形。可以说,早在 2012 年,我刚小学毕业,TGD 算子的雏形就已经被众多研究者从 AlexNet 的论文中看到过了。但是却没人知道罢了,就像 Dosovitskiy 大佬只认为其是 Gabor-like。
注意到,这是纯靠数据驱动训练出来的算子,和数学理论推导出来的算子有些许差别。如数学理论上为了保证常函数的 TGD 值为 000 ,这要求 TGD 算子的权重和为 000 ,仅此一条,数据驱动的学习方法就很难完美地学习出来,更勿论 TGD 数学理论中的 “单减约束” 了。
三、针对直觉的验证试验
你要这江湖,我便给你这江湖!
在上一篇中,我们是手动计算「 TGD 特征 」,并作为输入引入神经网络,当时我就埋了一个伏笔,TGD 计算其实是用 TGD 算子卷积输入序列。为此,TGD 算子的权重其实可以作为首个卷积层的初始化卷积核参数,构造的卷积层能直接作为神经网络的一部分。因为 TGD 算子是满足各种理论约束的,为此这部分权重无需再训练,只需训练其他的权重就行了。下图展示了传统的通用视觉神经网络架构,以及首层嵌入 TGD 算子后的通用视觉神经网络架构。
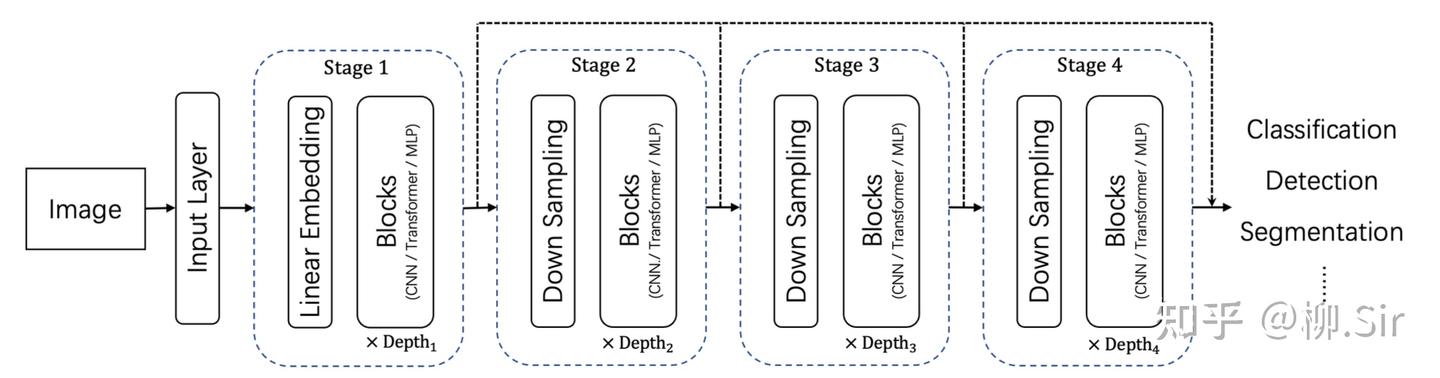
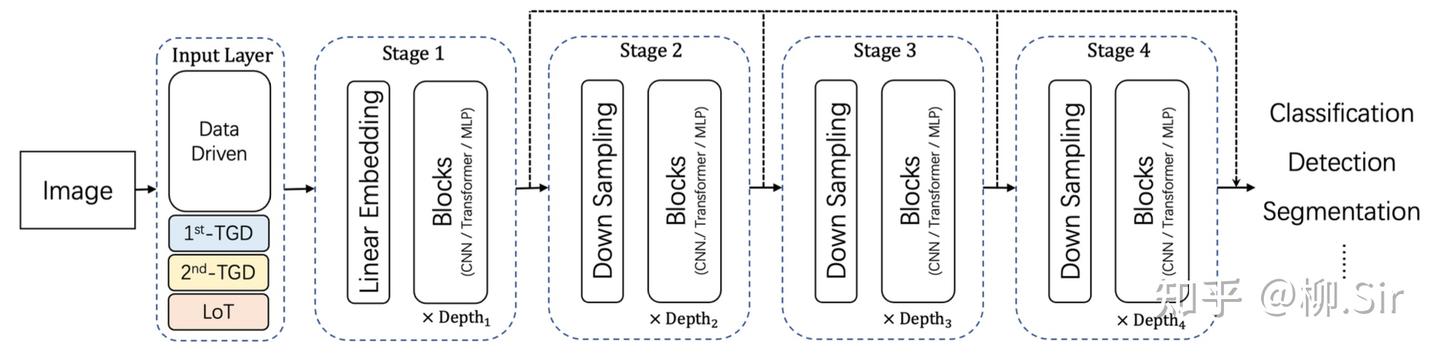
直觉上,嵌入 TGD 算子后会带来 三个结果 :
- 如果 TGD 特征数量够,神经网络无需再学习图像边缘(梯度)特征,进而在数据驱动学习权重的部分专注其他类型特征;
- 初始阶段就有优质的 TGD 特征,模型学习难度降低,训练收敛速度会加快;
- 训练数据量越少,效果提升越明显。
为了验证上述直觉,我进行了两个小样本环境下的小实验(实验不是按照发 paper 那样严谨设置,当初就是想试试而已,看看就行)
3.1 小样本集自然图像分类任务
图像分类实验,选用 Oxford-102 花分类数据集4。作为经典小样本数据集,其中每个类别仅有 101010 张图片用于训练, 101010 张图片用于验证,共计 614961496149 张图片用作测试。下展示了 Oxford-102 数据集部分实例,可见各种花朵之间存在颜色和形状区别。稳定的图像梯度特征将有助于对于花朵的形状进行识别,从而提升分类的精度。

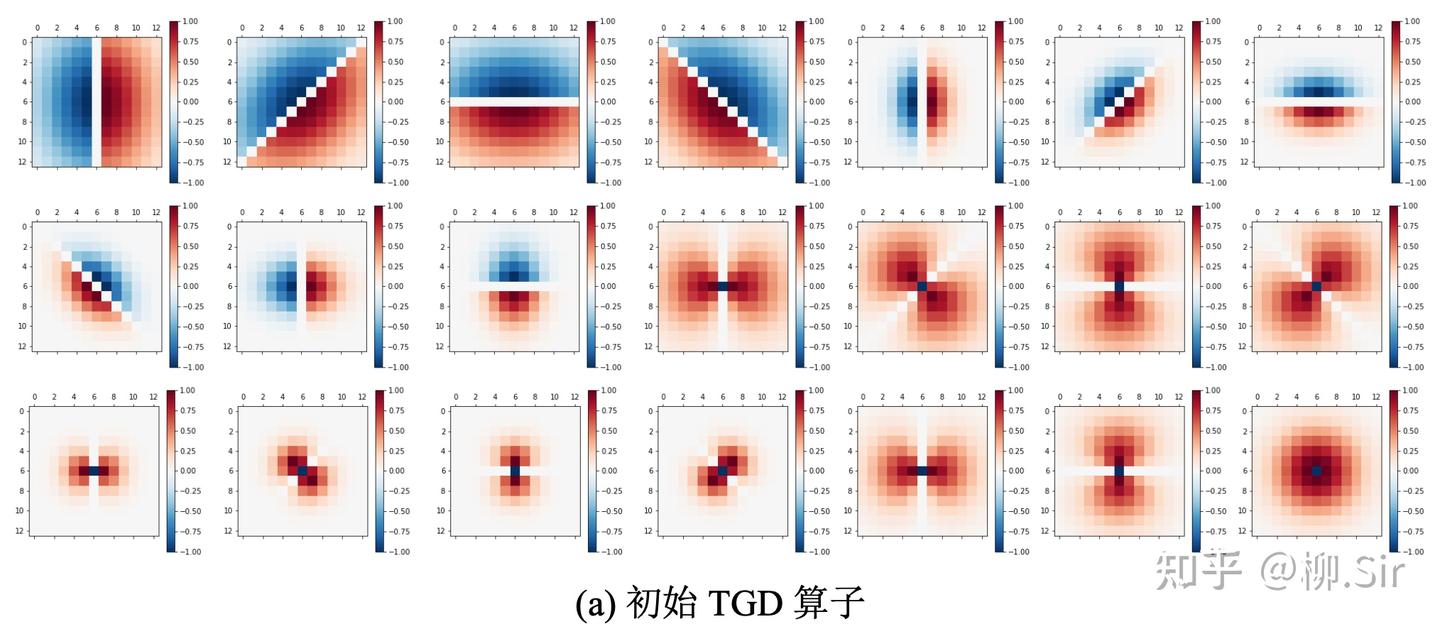
在实验中选用了三个著名的视觉神经网络:ResNet、VAN 以及 Swin。实验源自 2022 年春,当时 Swin 很火,且隔壁实验室的 VAN 刚提出,就用他们了。分别下载了基于 ImageNet 预训练的开源模型权重用于后续实验。在输入层方面,注意到 ResNet 和 VAN 的输入层输出为 646464 个通道, Swin 则为 969696 个通道。为此,统一设定 212121 个尺寸为 13×1313 \times 1313×13 的 TGD 算子,约占输入层提取特征的 20%20\%20% 至 30%30\%30% ,符合梯度特征约占输入特征 30%30\%30% 的统计结果。首层卷积层 TGD 算子权重可视化如下图所示,共包含 101010 个一阶 TGD 算子、 101010 个二阶 TGD 算子, 111 个 LoT 算子,为了更好展示其结构,算子权重经过归一化处理,红色值为正,蓝色值为负,颜色越深,权重绝对值越大:
实验分别在不含预训练权重和含有预训练权重两种配置下进行。针对无预训练情形,训练轮次设定为 300 轮,使用 Adam 优化器以及交叉熵损失。初始学习率为 3×10−33 \times10^{−3}3×10−3 ,使用 MultiStepLR 策略,分别于第 40、 80、 160 和 240 轮将学习率衰减为当前的 20%20\%20% 。针对含 ImageNet 预训练权重的模型,保留了非首层预训练权重,训练轮次设定为 100 轮,依然使用 Adam 优化器以及交叉熵损失,整个模型除 TGD 算子权重外均可训练。初始学习率为 1×10−41 \times 10^{−4}1×10−4 ,使用 MultiStepLR 策略,分别于第 15 和 30 轮将学习率衰减为当前的 20%20\%20% 。batch 大小为 161616 。此外,结合了数据增强技术,包括随机中心裁剪(RandomCrop)、随机水平翻转(RandomHorizontalFlip)和随机垂直翻转(RandomVerticalFlip)。最终选用验证集性能最高的模型用于测试。
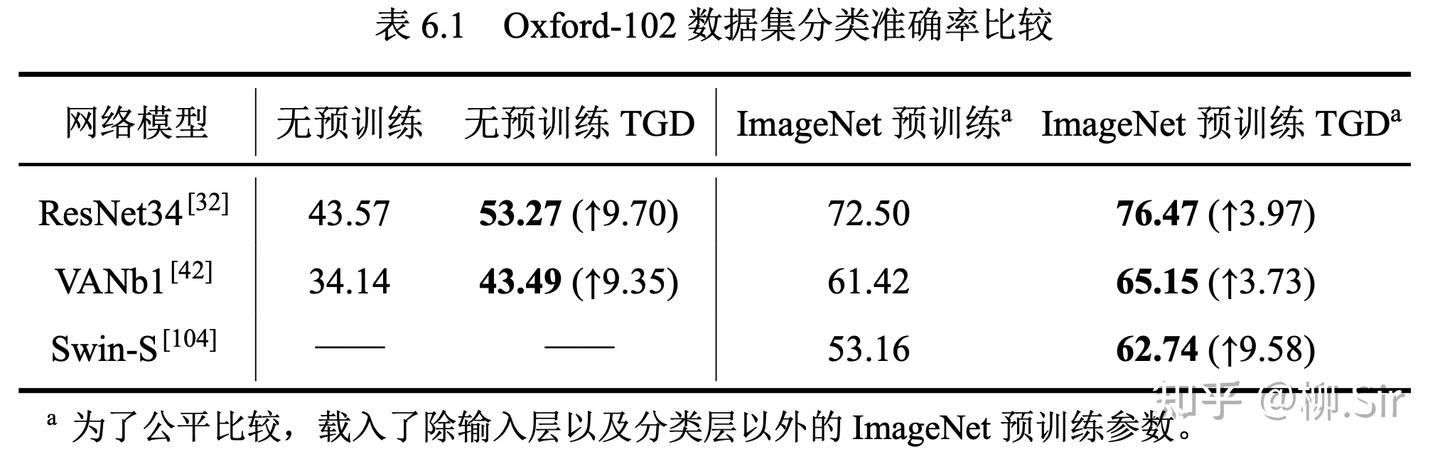
上表的结果表明,在小数据集规模下,无预训练的神经网络性能普遍较低,但 TGD 的引入带来了近 10%10\%10% 的分类准确率提升。Swin 作为 Transformer 变种,其需要大量的数据进行训练,在无预训练权重加持下, Swin 在小数据集上并未收敛,为此不展示相关结果。当载入 ImageNet 预训练参数后,网络的性能大幅提升,然而小数据集依然不足以支撑网络在输入层学习到优质的特征提取模式。TGD 数学模型的引入依然能再次提升网络的性能。
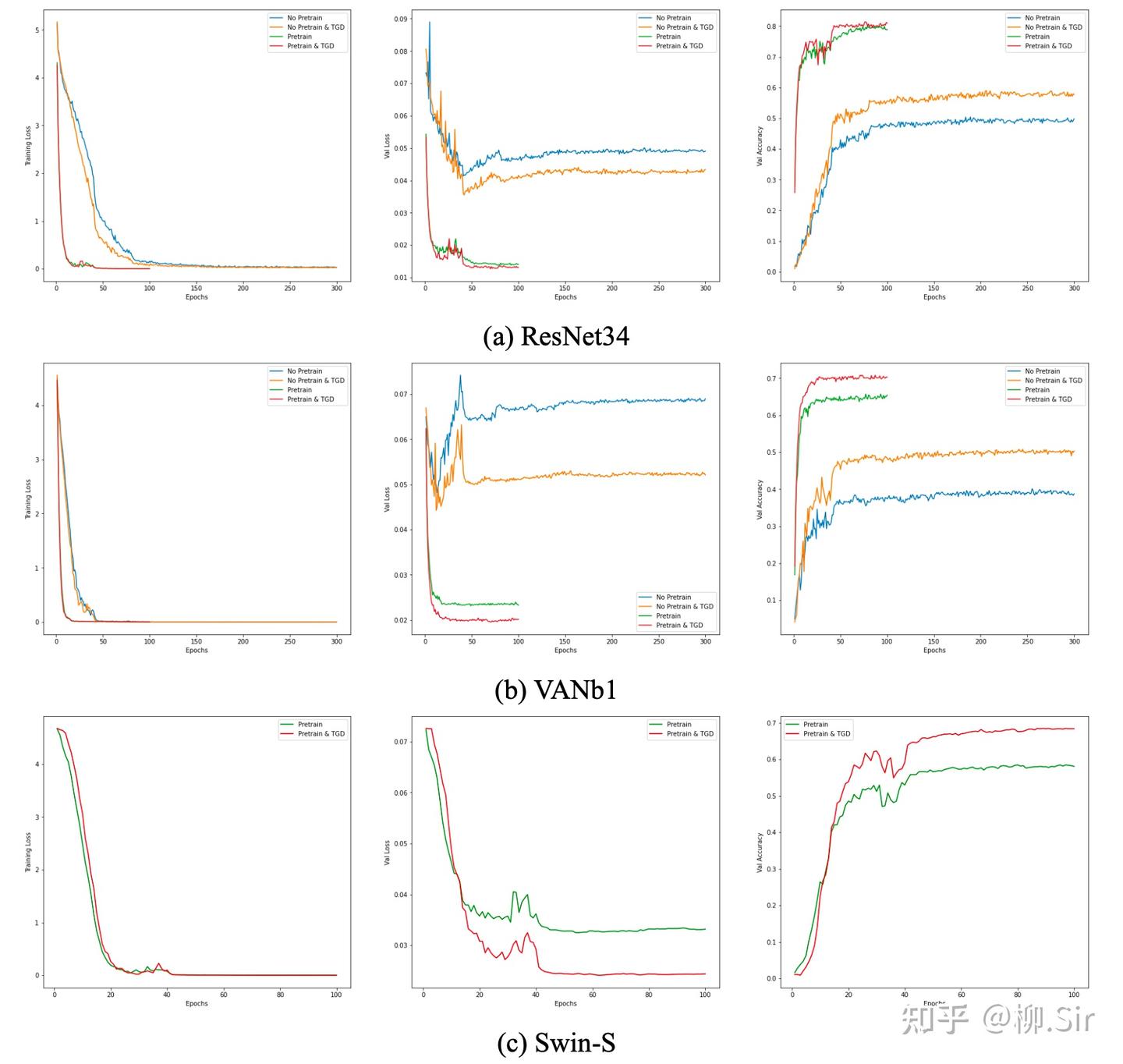
下图展示了三个神经网络在训练过程中损失以及验证集正确率的变化情况。首先可见,大家的训练损失都很低,完全自主学习的神经网络在小数据集上则非常容易出现过拟合,TGD 对模型收敛速度带来的提升暂不明显。当网络的训练损失很低且模型已经收敛时,嵌入 TGD 算子的网络在验证集上具有更小的损失以及更高的准确率。
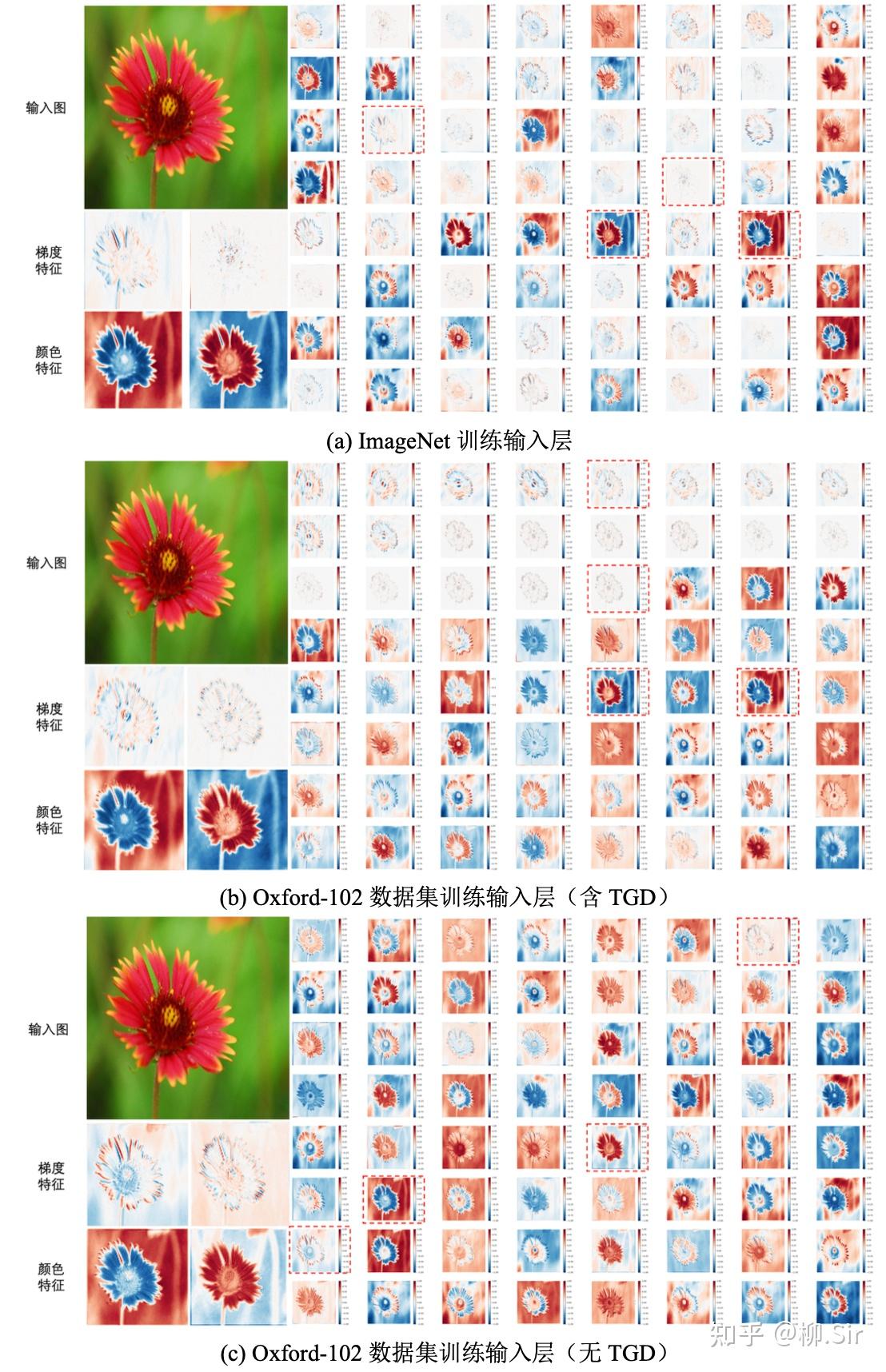
下图进一步对 ResNet 输入层特征图进行比较,为了更好可视化,对特征图进行了归一化处理。在可视化结果中,红色值为正,蓝色值为负,颜色越深,特征绝对值越大。子图(a)显示,经过包含 130 万张图片的 ImageNet 数据集训练得到的 ResNet,在其输入层会自主选择提取图像梯度和颜色特征,尽管采用了百万量级数据进行训练,输入层中用于图像二阶梯度计算的卷积核仍不够理想。子图(b)展示了在 Oxford-102 数据集上训练得到的 ResNet 输入层特征图。结果显示,在其 646464 个输出通道中,前 212121 个通道采用了 TGD 数学模型提取更为精确鲁棒的图像梯度特征,而剩余的 434343 个通道则自发地学习如何提取包括颜色在内的非梯度特征,可见,TGD 的引入可以减轻网络的学习负担,在减少可学习参数的同时, 让网络自主学习部分更专注于非边缘(梯度)特征的挖掘 。并且其针对部分颜色特征的提取能力与 ImageNet 数据集训练得到的输入层结果基本相近。当不设定任何数学模型并使用小数据集进行训练,子图© 的结果表明,在 646464 个输出通道中, ResNet 仅有约 222 个通道在试图学习边缘(梯度)特征的提取方法且不够理想,其余部分均在学习提取颜色等非梯度特征,说明边缘(梯度)特征学习比颜色更难。
3.2 小样本集医学图像分割任务
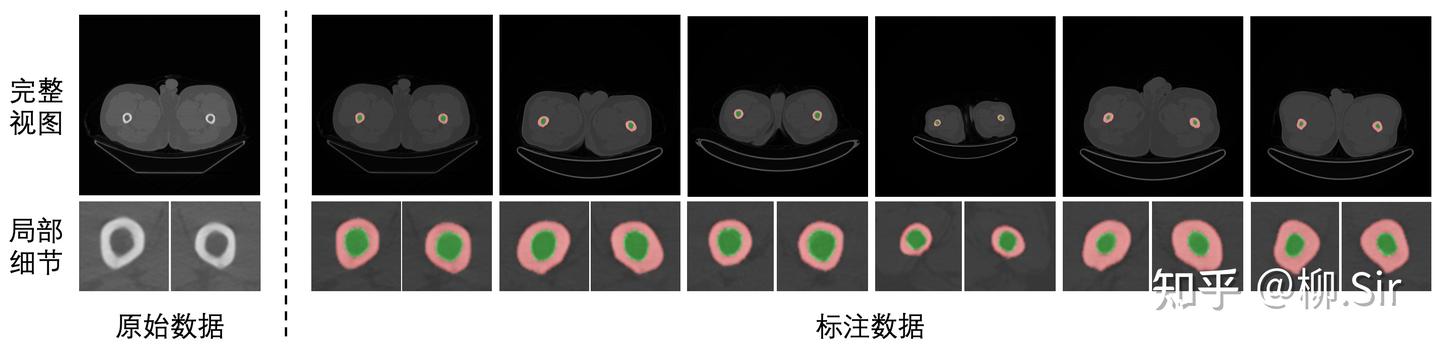
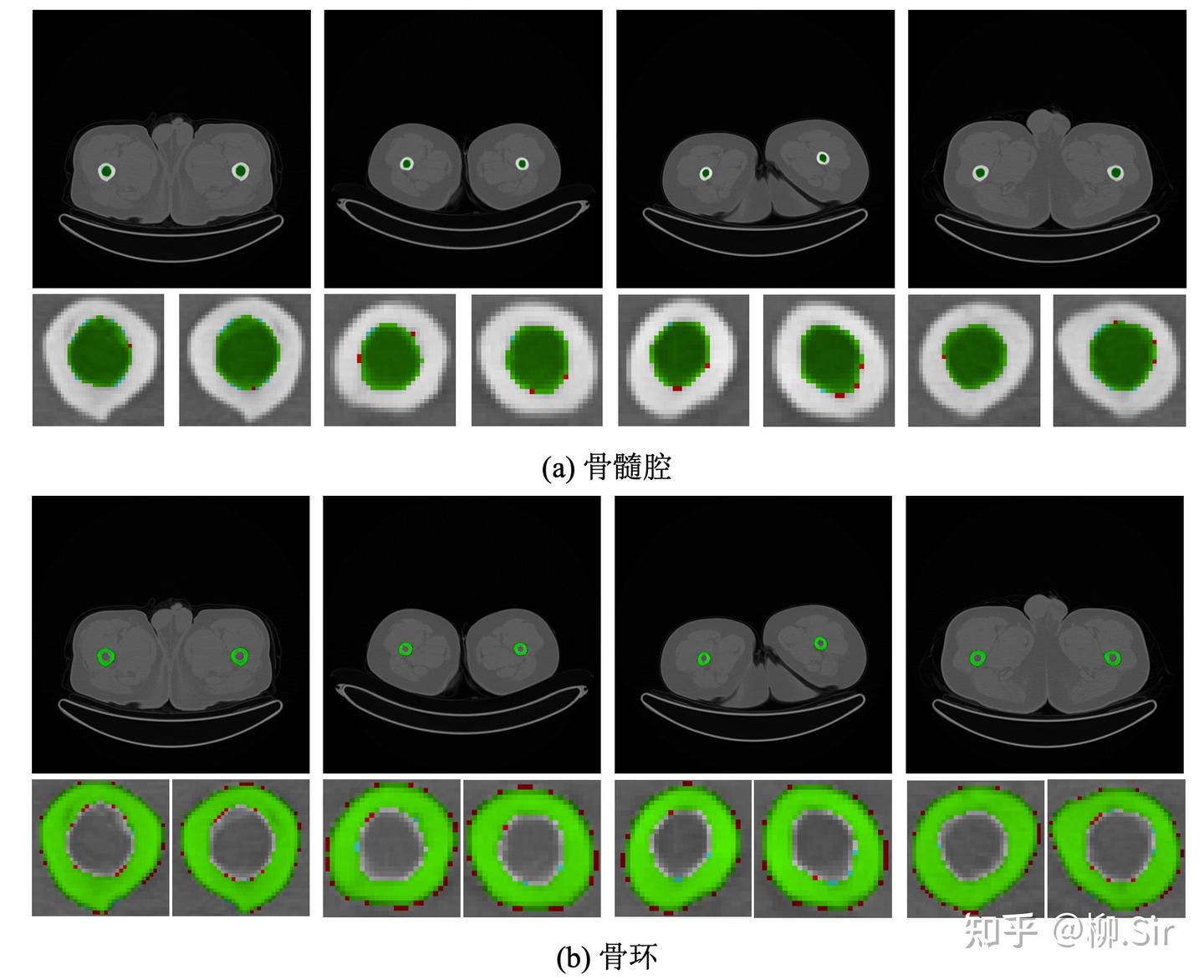
针对医学图像分割实验,我们自行采集标注并构建了医学腿骨分割数据集,实现对于人体大腿骨骨环以及骨髓腔的分割。数据集具体划分结果为:训练集含 110110110 张 CT 图,验证集含 737373 张 CT 图,测试集含 286528652865 张 CT 图。下图展示了医学腿骨分割数据集中的部分实例,第一行为完整视图,第二行为局部细节放大图,红色部分标注了骨环,绿色部分标注了骨髓腔。大腿腿骨的骨环以及骨髓腔具有明确的边缘,为此,将抗噪鲁棒的 TGD 特征引入该任务将会有助于更精确的骨环以及骨髓腔的分割。
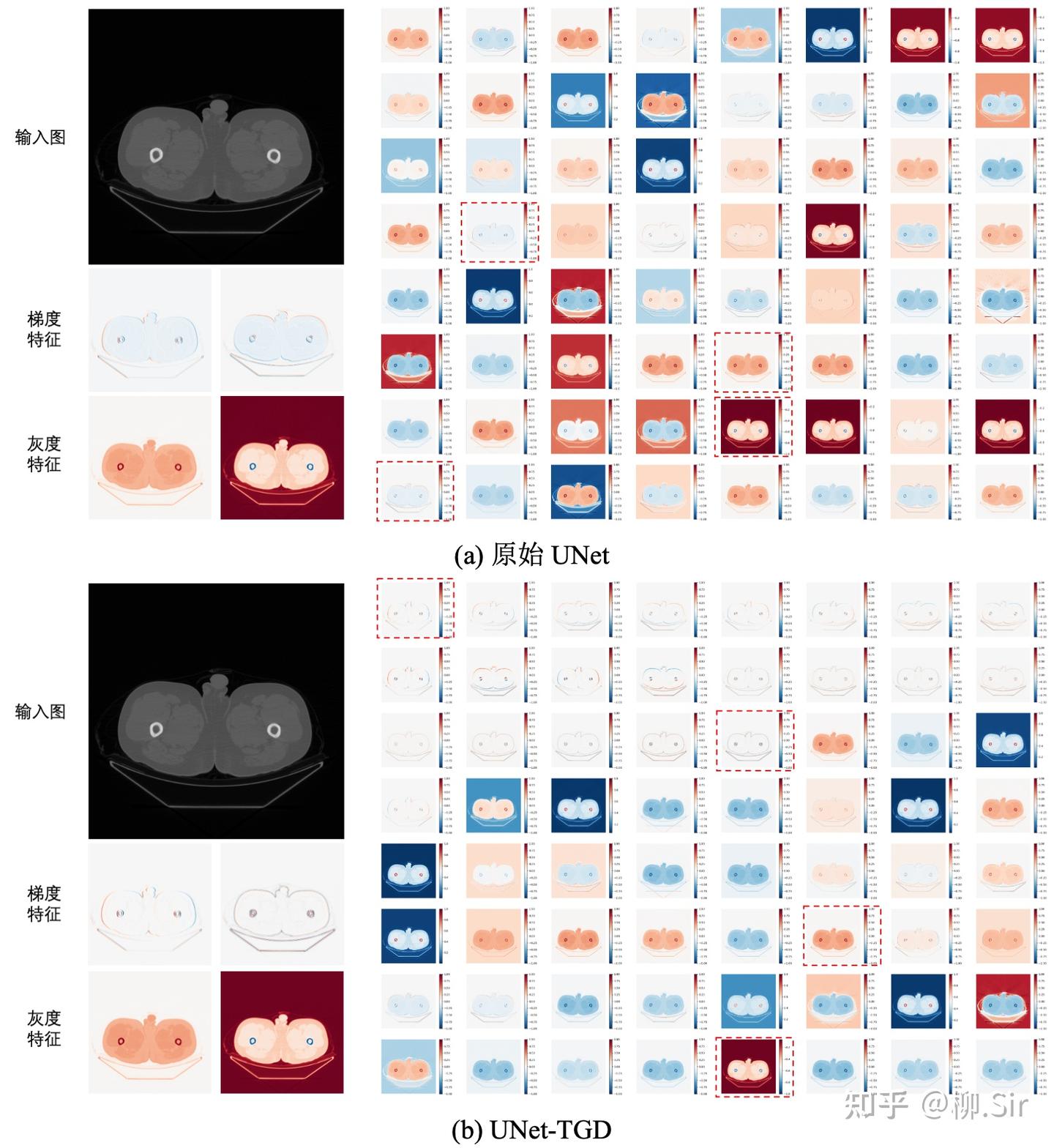
在实验中选用了两个主流的医学图像分割神经网络: UNet 以及 UNeXt。注意到 UNet 的输入层输出为 64 个通道,UNeXt 则为 16 个通道,初始卷积核尺寸均采用 3×33 \times 33×3 。实验中,针对 UNet 设定 212121 个尺寸为 13×1313 \times 1313×13 的 TGD 算子(含 121212 个一阶 TGD 算子、 444 个二阶 TGD 算子以及 555 个 LoT 算子),针对 UNeXt 设定 777 个尺寸为 13×1313 \times 1313×13 的 TGD 算子(含 444 个一阶 TGD 算子、以及 333 个 LoT 算子)。初始化 TGD 算子有效尺寸囊括 3×33 \times 33×3 到 13×1313 \times 1313×13 (图 6.10)。由于梯度特征中的正负值均有具体物理含义,表示灰度值增加或减少,所以在使用 TGD 算子时删除了 UNet 和 UNeXt 中输入层后紧连的 ReLU 激活函数,否则将会直接抹除负梯度特征。
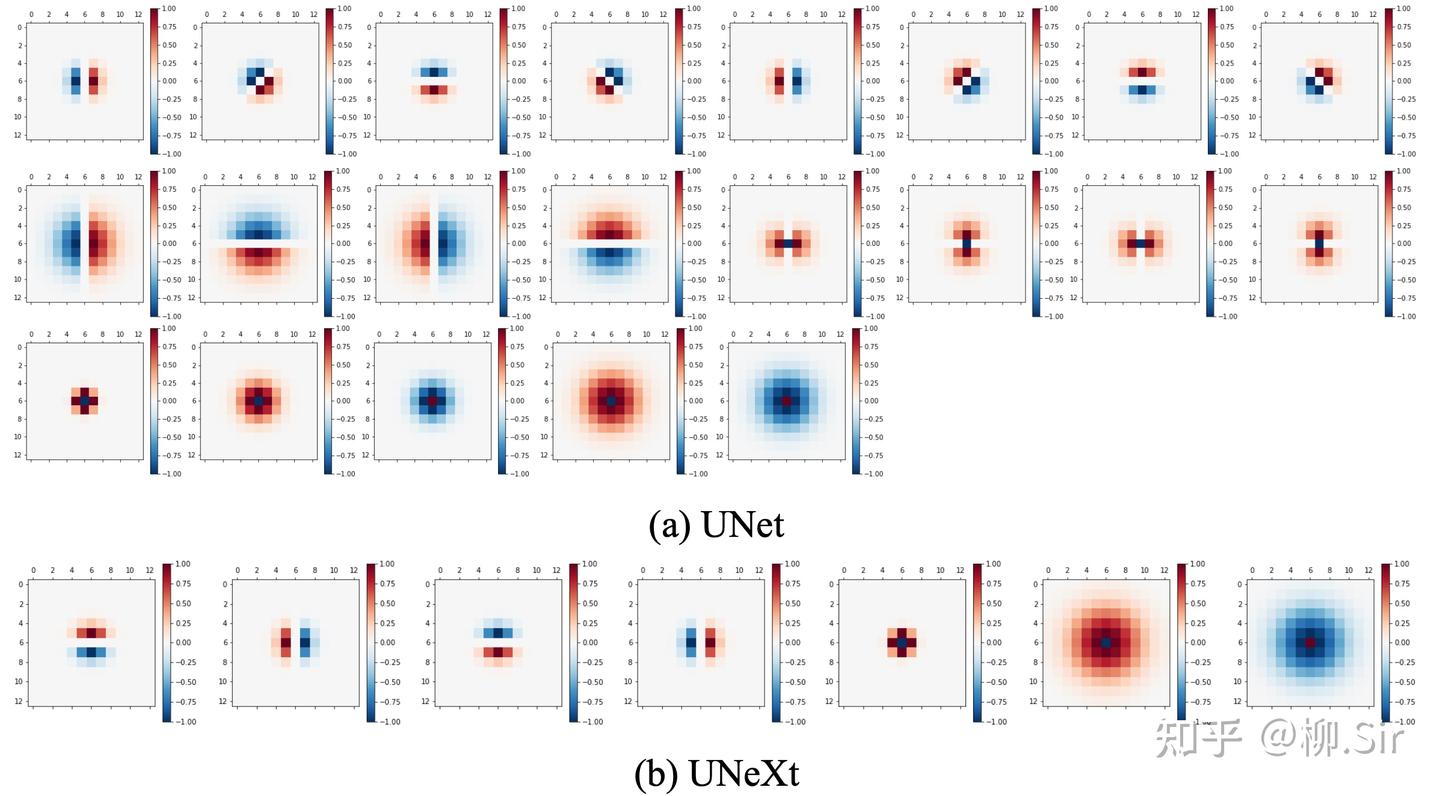
训练基于 UNeXt 官方开源代码仓库 5进行实现。UNet 训练轮次设定为 100100100 轮;因 UNeXt 含全连接层且更难收敛,其训练轮次设定为 400400400 轮。使用 Adam 优化器以及 BCEDiceLoss。初始学习率为 1×10−41 \times 10^{−4}1×10−4 , momentum 为 0.90.90.9 , weight_decay 为 1×10−41 \times 10^{−4}1×10−4 。使用 CosineAnnealingLR 策略,设定最小学习率为 1×10−51 \times 10^{−5}1×10−5 。训练过程中 batch 大小为 444 。此外,结合了数据增强技术,包括随机旋转 90 度(RandomRotate90)以及随机翻转(RandomFlip)。最终选用验证集 IoU 最高的模型用于测试。
实验结果如下表所示,评价指标选用 IoU 和 Dice,以及像素分类的准确率(Precision)和召回率(Recall),指标越高,分割越准确。
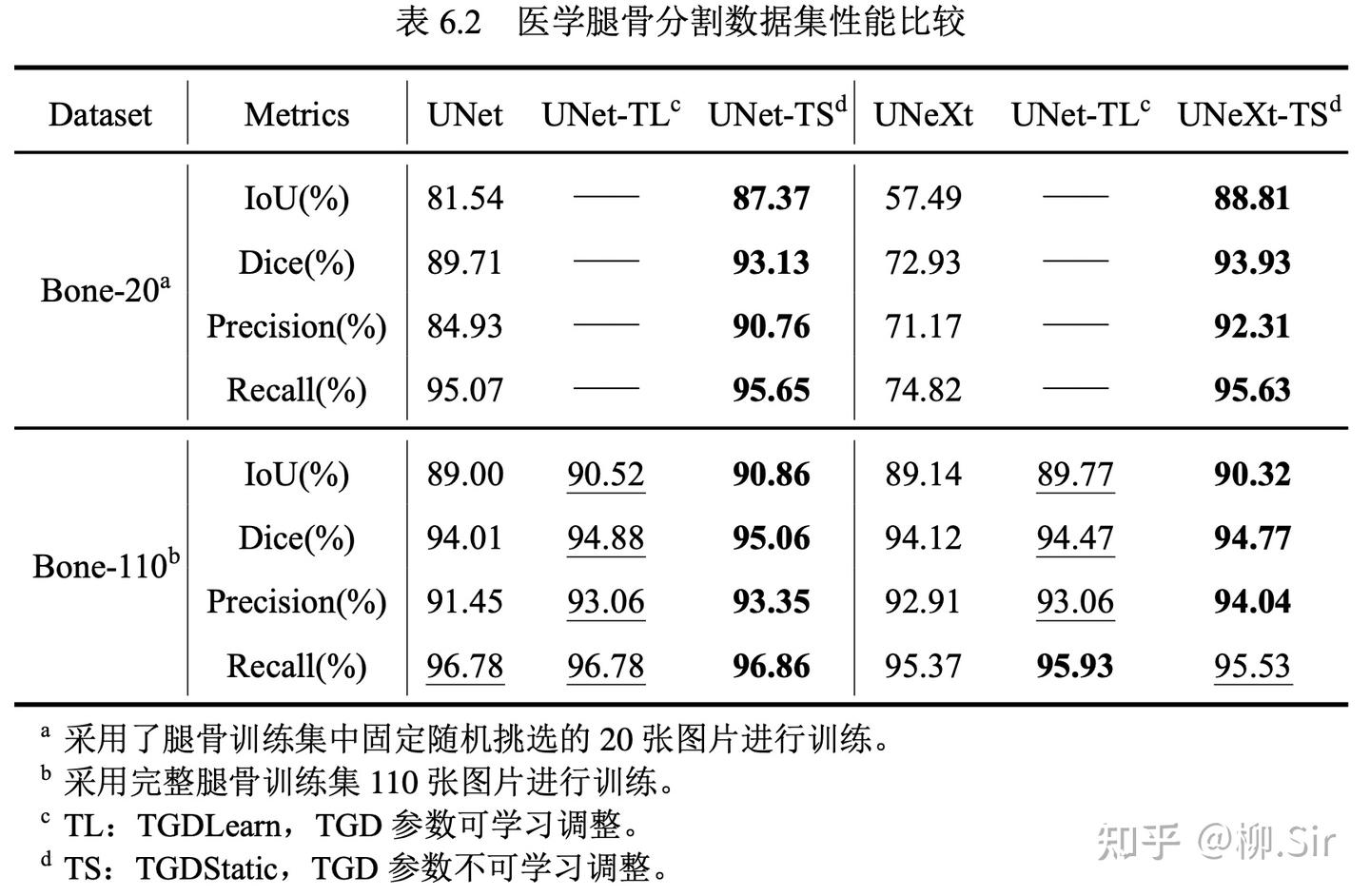
我一共进行了两组对比实验,分别在仅含 20 张训练图像的腿骨数据集子集 Bone-20,以及在含完整 110 张训练图像的腿骨数据集 Bone-110 上进行训练。最优的指标加粗表示,次优的指标以下划线形式展示。由于腿骨分割任务较为简单,当在 Bone-110 数据集上训练时,原始 UNet 和 UNeXt 都取得了不错的结果。在引入 TGD 之后,模型的性能进一步提升。在本次实验中,我新增 TGD 权重可训练作为对比,实验结果中 TGD 参数可训练比仅采用初始参数的性能略低,其可能的成因是数据集规模太小,TGD 的参数未能很好训练,参数的细微扰动会带来特征噪声,从而使模型性能降低。尽管如此,相较于不含 TGD 的朴素模型而言,可学习的 TGD 参数依然带来了性能提升。Bone-20 数据集的结果则进一步展示了 TGD 特征在小数据集上的优势。 当训练数据减少,UNet 的性能大幅降低, UNeXt 甚至出现了欠拟合 。而 TGD 的引入为模型提供了稳定可靠的边缘(梯度)特征,并使得模型取得了接近 5 倍数据量训练的性能。
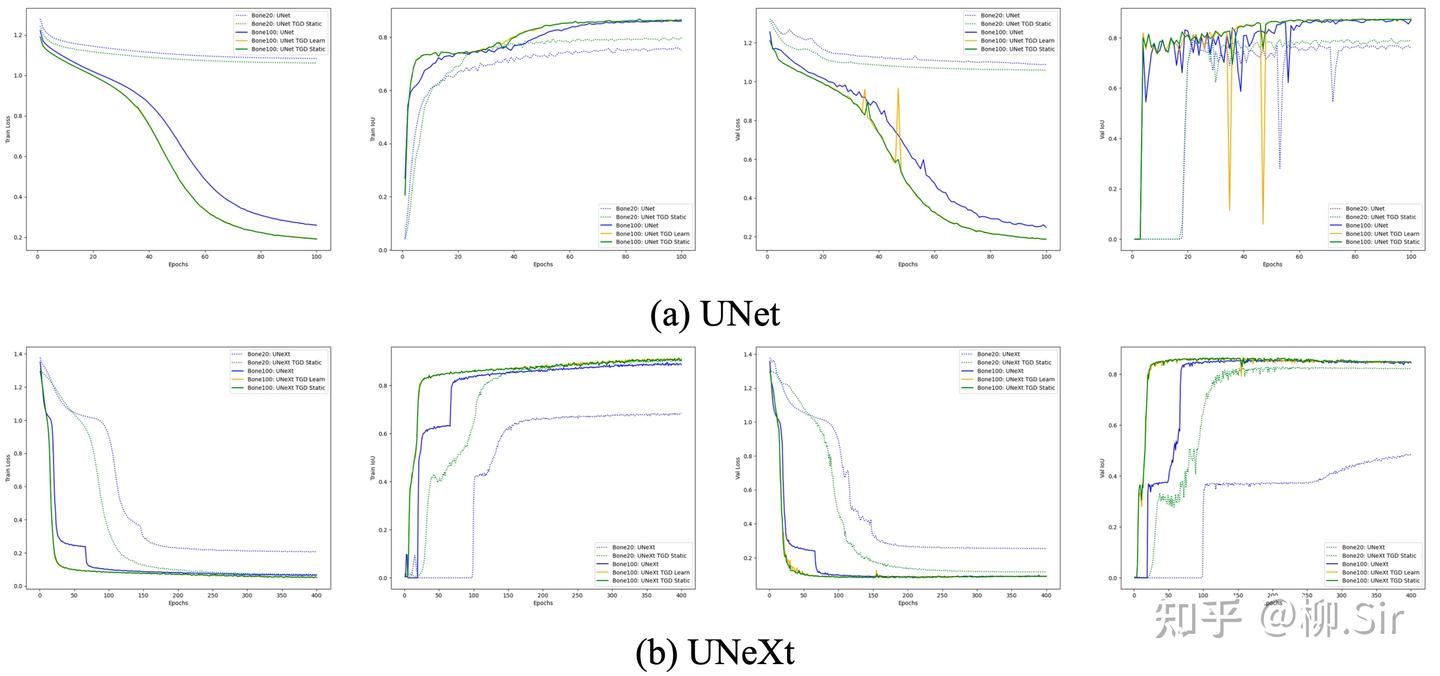
上图展示了 UNet 和 UNeXt 在训练过程中性能指标的变化,从左至右分别为训练损失、训练集 IoU、验证集损失和验证集 IoU。从训练集指标变化可见,向模型中嵌入 TGD 算子后能够帮助模型更快地收敛。验证集指标变化则表明,TGD 算子计算得到的梯度特征具有更具泛化性,能够帮助模型在验证集上取得更好的效果。
下图展示了使用不可训练 TGD 参数在 Bone-110 数据集上训练的 UNet 的分割结果,其中绿色像素表示分割结果与 Ground Truth 一致,红色像素表示模型多分割的部分,蓝色像素则表示模型少分割的部分。除骨环最外圈灰度渐变的数个像素本就模棱两可外,模型实现了精确的像素级分割。
最后,展示在 Bone-110 数据集上训练的 UNet 输入层特征图。当 UNet 对输入层进行完全自主地进行数据驱动学习时,其会学习到数个(不完美的)一阶梯度特征,更多的则是灰度值特征(类似自然图像中的颜色特征),如灰度值越大,响应越大或越小等。当向 UNet 输入层嵌入 TGD 算子之后,UNet 将在输入层提取到各个方向的一阶和二阶梯度特征,并促使剩余通道主要关注灰度等非梯度特征。与数据驱动相比,基于数学模型计算的梯度特征更稳定可靠,它们为模型带来了更好的分割性能以及更强的泛化能力。
在上面的小实验中,有人可能会说,我对比实验消融实验不全,训练设置得不够好,会出现欠拟合啥的,准确率还不够高啥的。
我想说,这不是为了发 paper 做的实验,不是为了刷榜,不是为了炼丹,不是为了实用, 只是当时为了验证我们对于 TGD 和神经网络结合的直觉而已 。并且,前面谈到的三大直觉都已经被实验验证了!
四、结语
本篇实则是抛开 TGD 的理论,依靠视觉特征的直觉和过去深度学习的实践中,去理解 TGD 算子的正确性。TGD 算子的长相,早就在 2012 年的 AlexNet 论文中有所体现,只是数据驱动的学习方法很难完美地学习到数学理论的各种约束,更不论存在数据量和算力两大历史局限性。时至今日,数据量和算力这两大历史局限性或许仍未打破。后面的实验,则是帮助神经网络跳过学习 TGD 算子的步骤,直接赋予它想要的东西,带来的“加速收敛”、“性能提升”和“关注非边缘(梯度)特征”结果完全在意料之中,论证了 视觉神经网络确实需要 TGD 特征 。
2023 年是大模型元年 ,今天不再是 2022 年及以前了。在视觉大语言模型(vLLM)、大视觉模型(LVM)中,那一两个小小的卷积核似乎看起来已经不重要了。几百个参数能对数千亿参数模型带来多大影响喃。换言之, 视觉大模型确实还需要 TGD 特征吗?
我认为,Deepseek 和 ChatGPT 的不同,给了我编写本篇的信心。 有钱,有数据,有算力,有人力,大力出奇迹,可以靠堆积 GPU 数量训练最朴素的 Transformer 得到 ChatGPT;但是, 更注重细节,会绣花针功夫,通过 工程化优化, 以更低成本带来了 Deepseek。
所以,视觉大模型确实还需要 TGD 特征吗?
我的答案是: 需要,但是并非找我要 。就像我才小学毕业的时候,AlexNet 已经尝试提取 TGD 特征了。
不管黑猫白猫,捉住老鼠就是好猫。
知乎原文地址:TGD第十一篇:卷积神经网络中的TGD特征
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. ↩︎
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[A]. 2020. ↩︎
Tolstikhin I O, Houlsby N, Kolesnikov A, et al. Mlp-mixer: An all-mlp architecture for vision [C/OL]//Ranzato M, Beygelzimer A, Dauphin Y N, et al. Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual. 2021: 24261-24272. ↩︎
Oxford-102 数据集下载链接:https://www.robots.ox.ac.uk/~vgg/data/flowers/102/ ↩︎
UNeXt 官方代码仓库 ↩︎







)



——graph进阶)
:模数转换)



)


![[spring-cloud: 负载均衡]-源码分析](http://pic.xiahunao.cn/[spring-cloud: 负载均衡]-源码分析)