

一、最近搭建了个rabbitmq集群 三个磁盘节点,上生产环境之前想做个压测,测试下稳定性,参考Deepseek做了如下测试方案
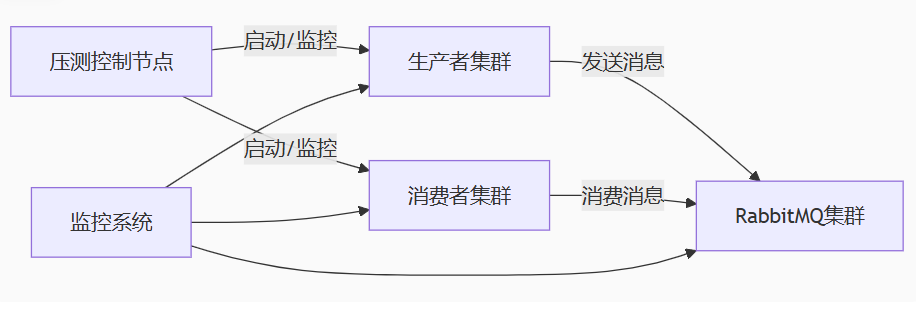
二、核心代码实现:
- 配置文件 (config.py)
import os
RABBITMQ_NODES = ['amqp://admin:123456@192.168.0.175:8101',
]QUEUE_CONFIG = {'queue_name': 'stress_test_queue','durable': True,'arguments': {'x-ha-policy': 'all', # 镜像队列'x-queue-mode': 'lazy' # 惰性队列}
}TEST_PARAMS = {'producer_count': 20, # 生产者进程数'consumer_count': 30, # 消费者进程数'message_size': 1024, # 消息大小(字节) 1KB'total_messages': 1000000, # 总消息量'test_duration': 600 # 测试时长(秒) 10分钟
}
LOG_DIR = "logs"
CONSUMER_LOG_FILE = os.path.join(LOG_DIR, "consumer_stress_test.log")
PRODUCER_LOG_FILE = os.path.join(LOG_DIR, "producer_stress_test.log")
- 生产者实现 (producer.py)
import pika
import time
import random
import os
from config import RABBITMQ_NODES, QUEUE_CONFIG, TEST_PARAMS, PRODUCER_LOG_FILE# 确保日志目录存在
os.makedirs(os.path.dirname(PRODUCER_LOG_FILE), exist_ok=True)def log_producer(message):"""记录生产者日志"""print(message)with open(PRODUCER_LOG_FILE, 'a', encoding='utf-8') as f:f.write(message + '\n')def produce_messages():"""生产者函数"""# 随机选择集群节点node = random.choice(RABBITMQ_NODES)params = pika.URLParameters(node)try:connection = pika.BlockingConnection(params)channel = connection.channel()# 声明队列channel.queue_declare(queue=QUEUE_CONFIG['queue_name'],durable=QUEUE_CONFIG['durable'],arguments=QUEUE_CONFIG['arguments'])start_time = time.time()message_count = 0pid = os.getpid()# 生成测试消息message_body = os.urandom(TEST_PARAMS['message_size'])while (time.time() - start_time) < TEST_PARAMS['test_duration']:try:# 发送消息channel.basic_publish(exchange='',routing_key=QUEUE_CONFIG['queue_name'],body=message_body,properties=pika.BasicProperties(delivery_mode=2, # 持久化消息timestamp=int(time.time() * 1000) # 毫秒时间戳))message_count += 1# 每1000条打印一次if message_count % 1000 == 0:current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())log_producer(f"{current_time}, [Producer {pid}] 发送: {message_count}")except Exception as e:log_producer(f"生产者错误: {str(e)}")# 重连机制try:if connection and connection.is_open:connection.close()connection = pika.BlockingConnection(params)channel = connection.channel()except Exception as e:log_producer(f"重连失败: {str(e)}")time.sleep(1)connection.close()log_producer(f"[Producer {pid}] 发送完成,总计发送: {message_count} 条消息")return message_countexcept Exception as e:log_producer(f"生产者初始化错误: {str(e)}")return 0
if __name__ == "__main__":produce_messages()
- 消费者实现 (consumer.py)
import pika
import time
import random
import os
import threading
from config import RABBITMQ_NODES, QUEUE_CONFIG, TEST_PARAMS, CONSUMER_LOG_FILEos.makedirs(os.path.dirname(CONSUMER_LOG_FILE), exist_ok=True)consumed_count = 0
total_latency = 0
min_latency = float('inf')
max_latency = 0connections = {}
lock = threading.Lock()def log_consumer(message):"""记录消费者日志"""print(message)with open(CONSUMER_LOG_FILE, 'a', encoding='utf-8') as f:f.write(message + '\n')def get_channel():"""获取或创建连接和通道"""with lock:pid = os.getpid()if pid not in connections or not connections[pid].is_open:node = random.choice(RABBITMQ_NODES)params = pika.URLParameters(node)connections[pid] = pika.BlockingConnection(params)return connections[pid].channel()def on_message(channel, method, properties, body):global consumed_count, total_latency, min_latency, max_latencycurrent_ts = time.time() * 1000latency = current_ts - properties.timestampconsumed_count += 1total_latency += latencymin_latency = min(min_latency, latency)max_latency = max(max_latency, latency)if consumed_count % 1000 == 0:pid = os.getpid()avg_latency = total_latency / consumed_countcurrent_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())log_consumer(f"{current_time}, [Consumer {pid}] 消费: {consumed_count}, 平均延迟: {avg_latency:.2f}ms")# 确认消息channel.basic_ack(delivery_tag=method.delivery_tag)def start_consumer():"""启动消费者"""try:channel = get_channel()# QoS设置channel.basic_qos(prefetch_count=100)channel.queue_declare(queue=QUEUE_CONFIG['queue_name'],durable=QUEUE_CONFIG['durable'],arguments=QUEUE_CONFIG['arguments'])channel.basic_consume(queue=QUEUE_CONFIG['queue_name'],on_message_callback=on_message)log_consumer(f"消费者启动 PID: {os.getpid()}")channel.start_consuming()except Exception as e:log_consumer(f"消费者错误: {str(e)}")# 尝试重新连接time.sleep(5)start_consumer()
if __name__ == "__main__":start_consumer()```
- 压测控制器 (controller.py)
import multiprocessing
import time
import os
from producer import produce_messages
from consumer import start_consumer
from config import TEST_PARAMS, CONSUMER_LOG_FILE
from report_generator import ReportGenerator # 确保导入修复后的报告生成器def run_producers():"""启动生产者进程"""producers = []for _ in range(TEST_PARAMS['producer_count']):p = multiprocessing.Process(target=produce_messages)p.start()producers.append(p)return producersdef run_consumers():"""启动消费者进程"""consumers = []for _ in range(TEST_PARAMS['consumer_count']):p = multiprocessing.Process(target=start_consumer)p.start()consumers.append(p)return consumersdef monitor():"""监控压测过程"""start_time = time.time()while time.time() - start_time < TEST_PARAMS['test_duration'] + 10:elapsed = time.time() - start_timeprint(f"[监控] 压测已运行: {int(elapsed)}秒 / {TEST_PARAMS['test_duration']}秒")time.sleep(5)def main():"""主控制函数"""print("=" * 60)print("RabbitMQ集群压测控制器")print("=" * 60)# 确保日志目录存在os.makedirs(os.path.dirname(CONSUMER_LOG_FILE), exist_ok=True)# 清空日志文件open(CONSUMER_LOG_FILE, 'w').close()print("启动消费者...")consumers = run_consumers()time.sleep(5) # 等待消费者就绪print("启动生产者...")producers = run_producers()print("启动监控...")monitor()print("压测完成,终止进程...")for p in producers:if p.is_alive():p.terminate()for c in consumers:if c.is_alive():c.terminate()print("所有进程已终止")# 生成压测报告print("\n" + "=" * 60)print("生成压测报告...")generator = ReportGenerator(CONSUMER_LOG_FILE)report_path = generator.generate_report()if report_path:print(f"报告已生成: {report_path}")else:print("报告生成失败")
if __name__ == "__main__":main()
5、日志解析器 (report_generator.py)
import pandas as pd
import matplotlib# 设置为无头模式,避免GUI问题
matplotlib.use('Agg') # 必须在导入pyplot之前设置
import matplotlib.pyplot as plt
from datetime import datetime
import re
import os
import numpy as np
import sys
import platform# 检查并导入兼容的 docx 模块
try:from docx import Documentfrom docx.shared import Inches, Ptfrom docx.enum.text import WD_ALIGN_PARAGRAPHfrom docx.enum.table import WD_TABLE_ALIGNMENTDOCX_SUPPORT = True
except ImportError as e:print(f"警告: 无法导入 python-docx 库,Word 报告功能将不可用。错误: {str(e)}")print("请运行: pip install python-docx --upgrade")DOCX_SUPPORT = Falseclass ReportGenerator:def __init__(self, log_file='consumer_stress_test.log'):# 获取桌面路径if platform.system() == 'Windows':self.desktop_path = os.path.join(os.environ['USERPROFILE'], 'Desktop')else:self.desktop_path = os.path.join(os.path.expanduser('~'), 'Desktop')self.log_file = log_fileself.report_docx = os.path.join(self.desktop_path, 'RabbitMQ集群压测分析报告.docx')self.report_image = os.path.join(self.desktop_path, 'RabbitMQ压测性能图表.png')# 设置中文字体支持plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS'] # 多个回退选项plt.rcParams['axes.unicode_minus'] = Falsedef parse_logs(self):"""解析日志文件,提取时间戳、消费数量和延迟数据"""print(f"正在解析日志文件: {self.log_file}")data = []line_count = 0parsed_count = 0if not os.path.exists(self.log_file):print(f"错误: 日志文件不存在 - {self.log_file}")return pd.DataFrame()# 尝试多种编码encodings = ['utf-8', 'gbk', 'latin-1', 'cp1252']for encoding in encodings:try:with open(self.log_file, 'r', encoding=encoding) as f:for line in f:line_count += 1# 尝试多种可能的日志格式if 'Consumed' in line or '消费' in line or '已处理' in line or '处理' in line:try:# 尝试解析时间戳 - 支持多种格式timestamp_match = re.search(r'(\d{4}[-/]\d{1,2}[-/]\d{1,2} \d{1,2}:\d{1,2}:\d{1,2})',line)if timestamp_match:timestamp_str = timestamp_match.group(1)try:timestamp = datetime.strptime(timestamp_str, "%Y-%m-%d %H:%M:%S")except:timestamp = datetime.strptime(timestamp_str, "%Y/%m/%d %H:%M:%S")# 解析消息数量count = 0count_match = re.search(r'(Consumed|消费|已处理|处理):?\s*(\d+)', line,re.IGNORECASE)if count_match:count = int(count_match.group(2))else:# 尝试直接查找数字num_match = re.search(r'\b(\d{3,})\b', line)if num_match:count = int(num_match.group(1))# 解析延迟latency = 0latency_match = re.search(r'(avg|平均|延迟|latency)[=::]?\s*([\d.]+)(ms|毫秒)?',line, re.IGNORECASE)if latency_match:latency = float(latency_match.group(2))data.append({'timestamp': timestamp,'count': count,'latency': latency})parsed_count += 1except Exception as e:print(f"解析错误 (行 {line_count}): {line.strip()} - {str(e)}")if parsed_count > 0:print(f"使用 {encoding} 编码成功解析 {parsed_count} 行日志")breakelse:print(f"使用 {encoding} 编码未找到有效数据")except UnicodeDecodeError:print(f"尝试 {encoding} 编码失败,尝试下一种...")continueexcept Exception as e:print(f"解析日志时发生错误: {str(e)}")return pd.DataFrame(data)def generate_charts(self, df):"""生成分析图表并保存到桌面"""if df.empty:print("没有有效数据,无法生成图表")return dfprint("正在生成分析图表...")try:plt.figure(figsize=(16, 12))# 消息消费速率plt.subplot(2, 2, 1)df = df.sort_values('timestamp') # 确保按时间排序# 计算时间差和消息数差df['time_diff'] = df['timestamp'].diff().dt.total_seconds().fillna(0)df['count_diff'] = df['count'].diff().fillna(0)# 计算消息消费速率(避免除以零)df['msg_rate'] = np.where(df['time_diff'] > 0,df['count_diff'] / df['time_diff'],0)# 处理无限值和NaN值df['msg_rate'] = df['msg_rate'].replace([np.inf, -np.inf], np.nan)df['msg_rate'] = df['msg_rate'].ffill().bfill().fillna(0)plt.plot(df['timestamp'], df['msg_rate'], 'b-')plt.title('消息消费速率 (条/秒)', fontsize=14)plt.xlabel('时间', fontsize=12)plt.ylabel('消息数/秒', fontsize=12)plt.grid(True)# 累计消费消息数plt.subplot(2, 2, 2)plt.plot(df['timestamp'], df['count'], 'g-')plt.title('累计消费消息数', fontsize=14)plt.xlabel('时间', fontsize=12)plt.ylabel('总消息数', fontsize=12)plt.grid(True)# 延迟分布plt.subplot(2, 2, 3)plt.hist(df['latency'], bins=50, color='orange', alpha=0.7)plt.title('延迟分布', fontsize=14)plt.xlabel('延迟 (毫秒)', fontsize=12)plt.ylabel('频率', fontsize=12)plt.grid(True)# 延迟随时间变化plt.subplot(2, 2, 4)plt.plot(df['timestamp'], df['latency'], 'r-')plt.title('延迟随时间变化', fontsize=14)plt.xlabel('时间', fontsize=12)plt.ylabel('延迟 (毫秒)', fontsize=12)plt.grid(True)plt.tight_layout()plt.savefig(self.report_image, dpi=300)print(f"分析图表已保存到: {self.report_image}")except Exception as e:print(f"生成图表时出错: {str(e)}")import tracebacktraceback.print_exc()return dfdef create_text_report(self, df):"""创建文本格式的报告"""report_file = os.path.join(self.desktop_path, 'RabbitMQ压测分析报告.txt')with open(report_file, 'w', encoding='utf-8') as f:f.write("=" * 60 + "\n")f.write("RabbitMQ集群压测分析报告\n")f.write("=" * 60 + "\n\n")f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")f.write(f"日志文件: {os.path.abspath(self.log_file)}\n\n")if df.empty:f.write("没有有效数据,无法生成报告\n")return report_file# 计算统计信息start_time = df['timestamp'].min()end_time = df['timestamp'].max()duration = (end_time - start_time).total_seconds()total_messages = df['count'].max() - df['count'].min()throughput = total_messages / duration if duration > 0 else 0# 延迟统计if not df['latency'].empty:latency_min = df['latency'].min()latency_max = df['latency'].max()latency_avg = df['latency'].mean()latency_90 = df['latency'].quantile(0.9)else:latency_min = latency_max = latency_avg = latency_90 = 0# 总体统计f.write("一、压测总体统计\n")f.write("-" * 50 + "\n")f.write(f"测试开始时间: {start_time.strftime('%Y-%m-%d %H:%M:%S')}\n")f.write(f"测试结束时间: {end_time.strftime('%Y-%m-%d %H:%M:%S')}\n")f.write(f"测试持续时间: {duration:.2f} 秒\n")f.write(f"总消费消息数: {total_messages:,} 条\n")f.write(f"平均吞吐量: {throughput:.2f} 条/秒\n")f.write(f"最小延迟: {latency_min:.2f} 毫秒\n")f.write(f"平均延迟: {latency_avg:.2f} 毫秒\n")f.write(f"最大延迟: {latency_max:.2f} 毫秒\n")f.write(f"90%延迟: {latency_90:.2f} 毫秒\n\n")# 分析结论f.write("二、性能分析结论\n")f.write("-" * 50 + "\n")# 吞吐量评估if throughput == 0:f.write("吞吐量评估: 未检测到有效吞吐量数据\n")elif throughput > 5000:f.write("吞吐量评估: 优秀 (>5000条/秒)\n")elif throughput > 2000:f.write("吞吐量评估: 良好 (2000-5000条/秒)\n")else:f.write("吞吐量评估: 需优化 (<2000条/秒)\n")# 延迟评估if latency_avg == 0:f.write("延迟评估: 未检测到延迟数据\n")elif latency_avg < 50:f.write("延迟评估: 优秀 (<50ms)\n")elif latency_avg < 200:f.write("延迟评估: 良好 (50-200ms)\n")else:f.write("延迟评估: 需优化 (>200ms)\n")# 稳定性评估if latency_90 > 0 and latency_avg > 0:stability_ratio = latency_90 / latency_avgf.write(f"稳定性评估: 90%延迟是平均延迟的 {stability_ratio:.1f} 倍\n")if stability_ratio < 2:f.write("稳定性评估: 系统稳定性优秀\n")elif stability_ratio < 5:f.write("稳定性评估: 系统稳定性良好\n")else:f.write("稳定性评估: 系统稳定性较差\n")# 优化建议f.write("\n三、优化建议\n")f.write("-" * 50 + "\n")suggestions = ["1. 增加消费者数量以提高吞吐量","2. 提高预取值(prefetch count)优化消费速度","3. 检查网络延迟,确保RabbitMQ集群节点间通信正常","4. 使用消息批量处理减少网络开销","5. 优化消费者代码,减少处理时间"]for suggestion in suggestions:f.write(suggestion + "\n")# 图表信息if os.path.exists(self.report_image):f.write("\n四、性能图表\n")f.write("-" * 50 + "\n")f.write(f"性能图表已保存到: {self.report_image}\n")print(f"文本报告已保存到: {report_file}")return report_filedef generate_report(self):"""生成完整的压测报告"""print("=" * 60)print("RabbitMQ压测报告生成工具")print("=" * 60)# 解析日志df = self.parse_logs()if df.empty:print("没有有效数据,无法生成报告")report_file = os.path.join(self.desktop_path, 'RabbitMQ压测分析报告.txt')with open(report_file, 'w', encoding='utf-8') as f:f.write("没有从日志文件中提取到有效数据,请检查日志格式\n")f.write(f"日志文件: {os.path.abspath(self.log_file)}\n")print(f"错误报告已保存到: {report_file}")return report_file# 生成图表self.generate_charts(df)# 生成报告return self.create_text_report(df)if __name__ == "__main__":import syslog_file = sys.argv[1] if len(sys.argv) > 1 else 'consumer_stress_test.log'generator = ReportGenerator(log_file)report_path = generator.generate_report()if report_path:print(f"\n报告已生成: {report_path}")else:print("\n报告生成失败")
6、 监控脚本 (monitor.py)
import pika
import time
import json
from config import RABBITMQ_NODES, QUEUE_CONFIGdef monitor_queue():while True:try:connection = pika.BlockingConnection(pika.URLParameters(random.choice(RABBITMQ_NODES)))channel = connection.channel()# 获取队列状态queue = channel.queue_declare(queue=QUEUE_CONFIG['queue_name'],passive=True)messages_ready = queue.method.message_countprint(f"{time.strftime('%Y-%m-%d %H:%M:%S')} 积压消息: {messages_ready}")connection.close()time.sleep(5)except Exception as e:print(f"监控错误: {str(e)}")time.sleep(10)if __name__ == "__main__":monitor_queue()
7、运行压测程序:
python controller.py
8、结果展示
RabbitMQ集群压测分析报告
生成时间: 2025-08-07 13:19:23
日志文件: C:\Users\Administrator\PycharmProjects\pythonProject13\rabbitmq\logs\consumer_stress_test.log
一、压测总体统计
--------------------------------------------------
测试开始时间: 2025-08-07 13:09:27
测试结束时间: 2025-08-07 13:19:21
测试持续时间: 594.00 秒
总消费消息数: 137,000 条
平均吞吐量: 230.64 条/秒
最小延迟: 137895.78 毫秒
平均延迟: 673436.15 毫秒
最大延迟: 4793312.15 毫秒
90%延迟: 1471724.25 毫秒二、性能分析结论
--------------------------------------------------
吞吐量评估: 需优化 (<2000条/秒)
延迟评估: 需优化 (>200ms)
稳定性评估: 90%延迟是平均延迟的 2.2 倍
稳定性评估: 系统稳定性良好三、优化建议
--------------------------------------------------
1. 增加消费者数量以提高吞吐量
2. 提高预取值(prefetch count)优化消费速度
3. 检查网络延迟,确保RabbitMQ集群节点间通信正常
4. 使用消息批量处理减少网络开销
5. 优化消费者代码,减少处理时间四、性能图表
--------------------------------------------------
性能图表已保存到: C:\Users\Administrator\Desktop\RabbitMQ压测性能图表.png
图表展示

这个方案有个缺陷就是测试完成后 还会有很多message堆积在那里,没有被消费掉,所以我做了一个消费脚本,内容如下:
import pika
import threading
import random
import time
from config import RABBITMQ_NODES, QUEUE_CONFIG# 连接池管理
connection_pool = []
lock = threading.Lock()def get_connection():"""获取或创建连接"""with lock:if connection_pool:return connection_pool.pop()else:node = random.choice(RABBITMQ_NODES)return pika.BlockingConnection(pika.URLParameters(node))def release_connection(connection):"""释放连接到连接池"""with lock:if connection.is_open:connection_pool.append(connection)def consume_fast():"""高效消费消息的函数"""try:# 从连接池获取连接connection = get_connection()channel = connection.channel()# 设置高预取值channel.basic_qos(prefetch_count=1000)# 定义消息处理回调def callback(ch, method, properties, body):# 这里可以添加实际的消息处理逻辑# 例如: process_message(body)# 立即确认消息(更安全)ch.basic_ack(delivery_tag=method.delivery_tag)# 开始消费channel.basic_consume(queue=QUEUE_CONFIG['queue_name'],on_message_callback=callback,auto_ack=False # 手动确认)print(f"[{threading.current_thread().name}] 快速消费者启动...")channel.start_consuming()except Exception as e:print(f"消费者错误: {str(e)}")finally:# 释放连接回连接池if 'connection' in locals() and connection.is_open:release_connection(connection)if __name__ == "__main__":# 初始化连接池for _ in range(10): # 创建10个初始连接node = random.choice(RABBITMQ_NODES)connection_pool.append(pika.BlockingConnection(pika.URLParameters(node)))print(f"已创建 {len(connection_pool)} 个初始连接")# 启动多个快速消费者线程threads = []for i in range(20): # 启动20个消费者线程t = threading.Thread(target=consume_fast,name=f"FastConsumer-{i + 1}",daemon=True)t.start()threads.append(t)time.sleep(0.1) # 避免同时启动所有线程print("所有消费者线程已启动,按 Ctrl+C 停止...")# 监控积压消息try:while True:# 检查队列积压try:connection = get_connection()channel = connection.channel()queue = channel.queue_declare(queue=QUEUE_CONFIG['queue_name'],passive=True)backlog = queue.method.message_countprint(f"当前积压消息: {backlog}")release_connection(connection)# 如果积压减少,可以考虑减少消费者if backlog < 1000:print("积压已减少,可以安全停止脚本")breakexcept Exception as e:print(f"监控错误: {str(e)}")time.sleep(5) # 每5秒检查一次except KeyboardInterrupt:print("\n正在停止消费者...")# 清理print("关闭所有连接...")for conn in connection_pool:if conn.is_open:conn.close()


)
















