一、DMETL的介绍
1.1 概述
我们先来简单了解一下DMETL。
DMETL是什么?说的简单一点,DMETL一款数据处理与集成平台;从功能来说,那DMETL就是对数据同步、数据处理以及数据交换共享提供一站式支持的平台;从它的意义来说,DMETL就是大幅度降低了用户使用各种平台进行大数据整合处理的技术门槛的一个平台。
这就是DMETL,即达梦数据交换平台(Dameng Data Exchange Platform)的简称。将传统的ETL工具(Extract、Transform、Loading)与分布式大数据处理平台相结合,更好地应对大规模数据的实时处理和分析需求,也能更高效地完成数据清洗、过滤和格式化等复杂操作。
1.2功能特点
(1)数据抽取(Extract):能够从多种数据源中抽取数据,支持关系型数据库(如 Oracle、MySQL)、NoSQL 数据库(如 MongoDB)、文件格式(如 CSV、Excel)等。
(2)数据转换(Transform):提供数据清洗、转换功能,可以对数据进行格式转换、去重、合并等操作,并支持灵活的转换规则。
(3)数据加载(Load):将处理后的数据加载到目标数据源中,支持多种目标数据源。
(4)可视化设计:采用图形化操作界面,用户可以通过拖拽和配置的方式快速实现数据的导入和转换。
(5)高性能与可靠性:支持多节点部署,具备负载均衡和故障转移功能,能够满足大规模数据处理的需求。
(6)易于使用和扩展:降低了使用 Hadoop 和 Flink 等大数据技术的门槛,同时具备良好的可扩展性(通过对数据源适配器的扩展,可以增加系统所支持的数据源,比如JDBC数据源、文件数据源、FTP数据源、XML数据源。通过对消息适配器的扩展,可以增加系统所支持的第三方消息中间件,如JMS)。
1.3应用场景
数据同步:实现不同数据源之间的数据同步,保持数据一致性。
数据交换:用于不同部门或系统之间的数据交换,支持数据的流动和共享。
数据整合:将来自不同来源的数据进行清洗、转换和整合,存储到数据中心或数据仓库中,为数据分析和共享提供支持。
数据仓库和数据中心建设:是构建数据仓库、数据中心等数据集成类应用的理想平台。
这里找了个图片来介绍一下DMETL的功能

二、系统架构及核心功能组件
DMETL 的系统架构包括以下主要组件:
调度器:负责流程分解和作业调度,协调多个执行器的功能。
执行器:用于执行作业和转换流程,支持多节点部署,包括native、yarn和flink。
管理器:提供可视化的 web 管理、设计、监控界面,用于操作、配置和监控系统。
控制器:是调度器和执行器的守护进程,用于远程修改参数、启停服务、监控系统资源等。
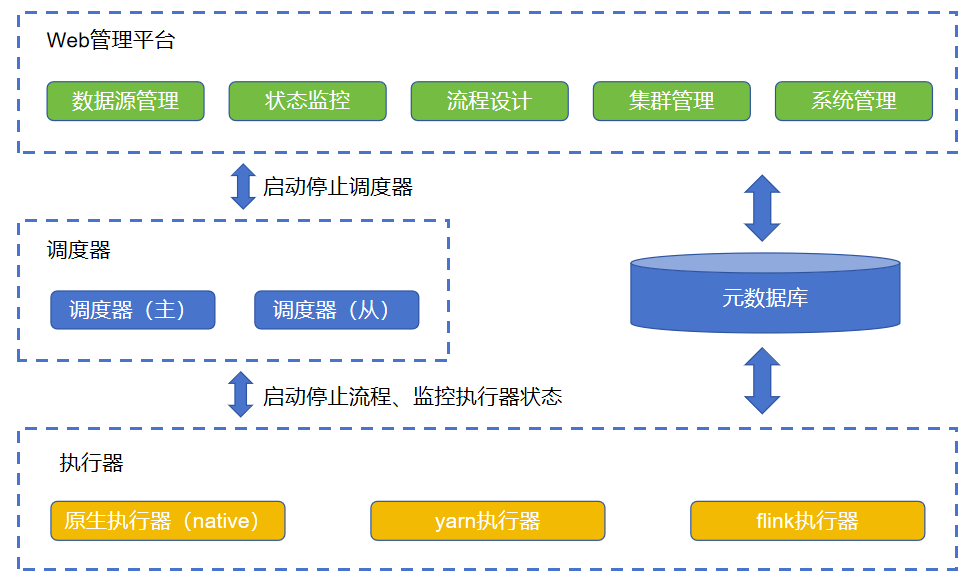
2.1Web管理平台
Web管理平台提供统一的管理界面,主要有以下功能模块:
数据源管理:数据源、数据集的统一管理和维护;
状态监控:系统各个部件(调度器、执行器、控制器)以及作业的状态监控,运行日志查询、统计;
集群管理:执行器、调度器的注册、版本升级;
流程设计:数据流(转换)和控制流(作业)的设计调试,流程调度配置;
系统管理:元数据备份、用户权限、系统参数、系统日志;
2.2共享元数据库
存储DMETL的元数据,包括作业定义、数据源信息、调度配置等。它支持多种数据库作为外置元数据库,如DM7、MySQL6、Oracle12c、SQLServer2012,内置元数据库仅支持Derby。
2.3调度器
负责流程分解和作业调度,协调多个执行器的工作,实现负载均衡。调度器不执行流程,只负责作业步骤的分解和分发,以及流程运行日志元数据的写入,调度器暂不支持主备(HA)模式。
2.4执行器
执行器接收调度器的请求,用于执行作业和转换流程。支持多节点部署,可以根据需求扩展。包括原生执行器、yarn执行器和flink执行器。原生执行器适用于常规作业,yarn执行器和flink执行器分别支持大数据批处理和流处理。关于这三种执行器,我找了一篇对这三者介绍的比较详细的博客内容如下:
(1)native本地执行器:
类似于DMETL4的执行引擎,不依赖于yarn以及其它的分布式计算框架,独立运行。一个系统中本地执行器可以部署多个,多个执行器之间是对等的,除非用户在配置流程时特别指定,否则作业步骤可以运行在任何一个执行器上。一个系统中理论上可以部署任意多个本地执行器,但是实际能够支持的数量取决调度器以及元数据库的支撑能力。
(2)yarn执行器:
yarn执行器仅执行专门的大数据处理流程,不用于执行常规作业步骤(如文件同步,执行sql,设置变量等作业步骤),yarn执行器会把调度器分发过来的转换流程,通过数据源的切分,得到多个切分后的流程,通过Hadoop MapReduce机制提交到Hadoop集群进行流程的分布式并行执行;同时通过Hadoop YARN机制来管理集群节点的负载问题。
(3)flink执行器:
利用flink框架特性,将ETL流程分解、组合成可以在flink服务器上运行的任务,并将其提交到flink服务器上运行。在每个JobManager和TaskManager中都启动并维护一个native执行器实例。TaskSlot通过构建微型ETL流程并提交到native执行器实例的方式处理数据;不同TaskSlot之间则利用flink的数据交互系统来传递数据。根据部分组件的特性,可支持数据的分片并发读取、持续读取并处理、exactly-once的容错机制等。
2.5控制器
控制器是调度器和执行器的守护进程(在上面的架构图中没有画出),与调度器和执行器部署在同一服务器上,其主要功能是提供远程管理调度器、执行器的服务。web管理平台通过控制器可以实现远程启停调度器、执行器,远程对执行器和调度器进行版本升级。
三、安装部署
我这里安装的是DMETL4.0版本(截至博客发布日期,市面上使用的DMETL产品大多数是4.0,虽然已经推出5.0但几乎没人用,对5.0感兴趣的直接去官方文档搜一下,那里的教程是5.0的)
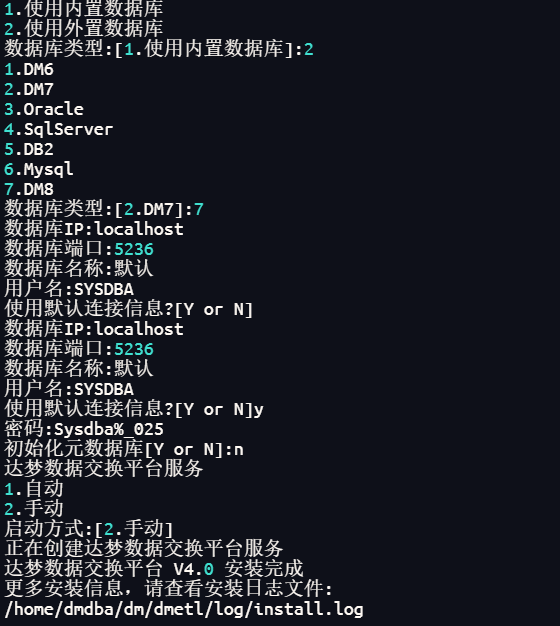
3.1执行以下语句开始安装,并按提示进行操作
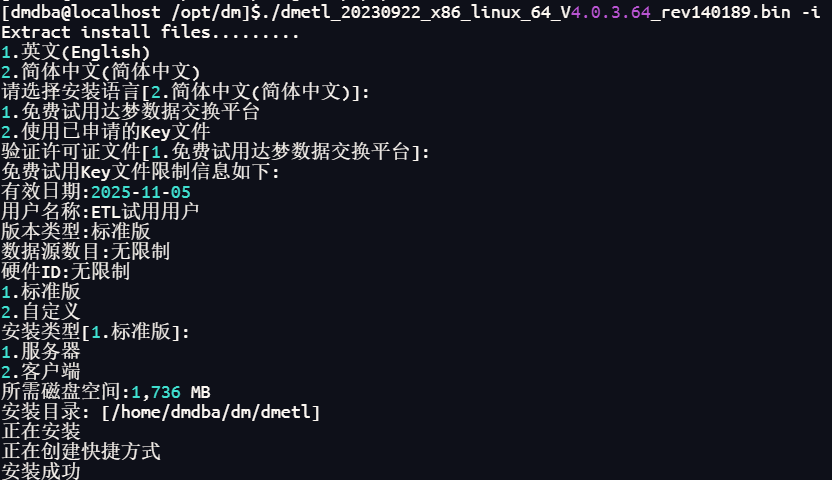
DMETL连接数据库后会自动创建相关资源表
3.2启动服务器
(方法1)执行 server 目录下的 dmetl_start.sh 脚本文件即可,当出现“Metadata engine started”日志信息时说明达梦数据交换平台服务器启动完毕
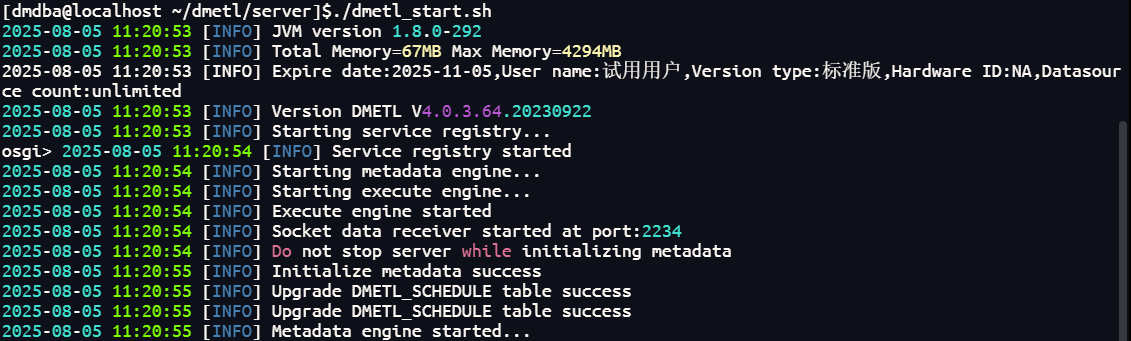
(方法2)在 server 目录下执行对应的脚本文件dmetl_service_start.sh来管理达梦数据交换平台服务

3.3启动客户端
在 client 目录下,执行./studio.sh启动客户端,客户端启动后,弹出登录界面,默认用户名和密码都是 admin,如果是在远程工具上执行困难会报错,建议在虚拟机上直接执行。
四、尝试使用
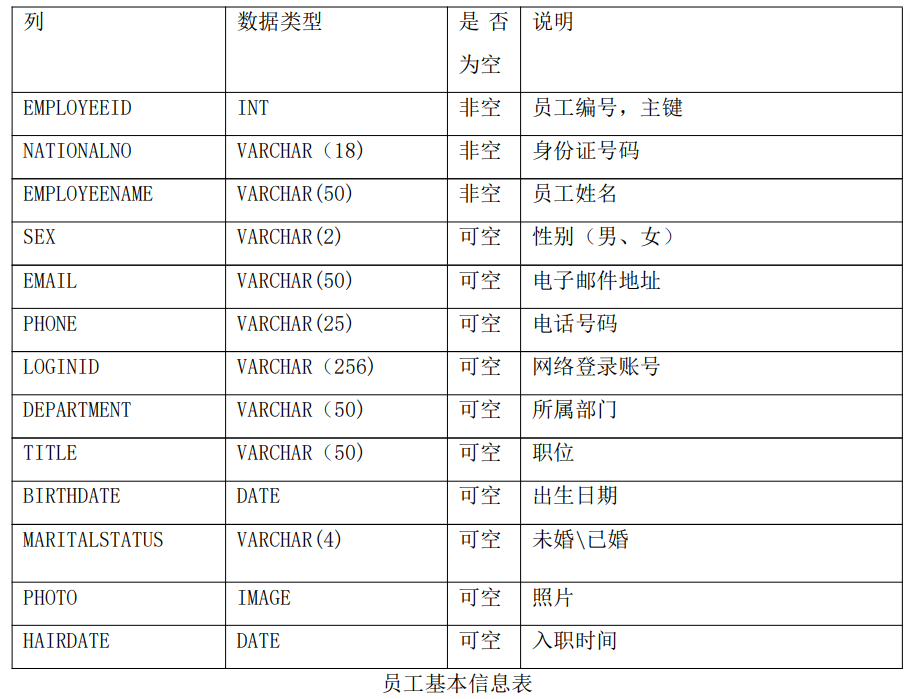
DMETL V4.0 的使用通常可以分为五个主要步骤:创建数据源、创建工程、设计转换、 设计作业和查看运行日志五个步骤。以一个例子说明一下转换过程,该例子功能是将源库中的 EMPLOYEE、EMPLOYEE_DEPARTMENT、DEPARTMENT 以及 PERSON 三张有关员工的表整合成一张完整的员工信息表(EMPLOYEEINFO)。作业的功能是控制转换以及其它任务运行的时间和顺序,这里就不演示了。
4.1创建数据源DM8
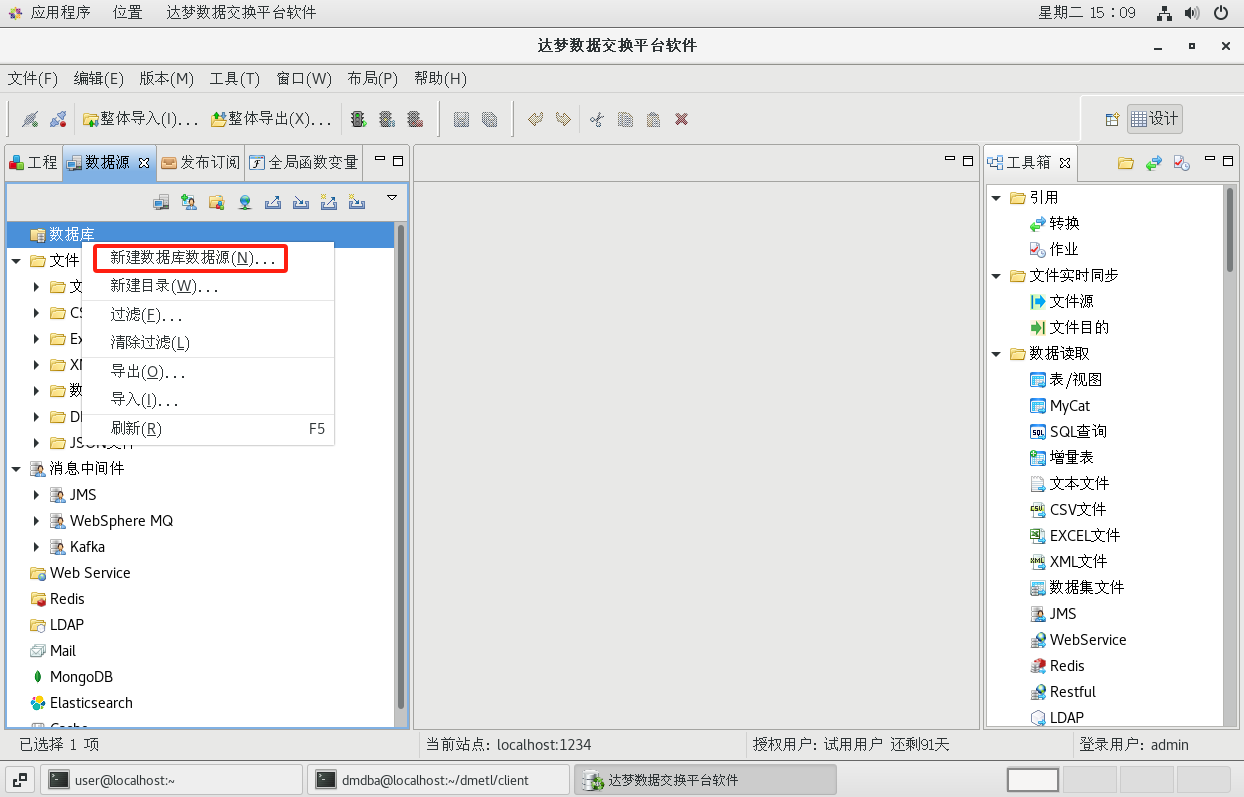
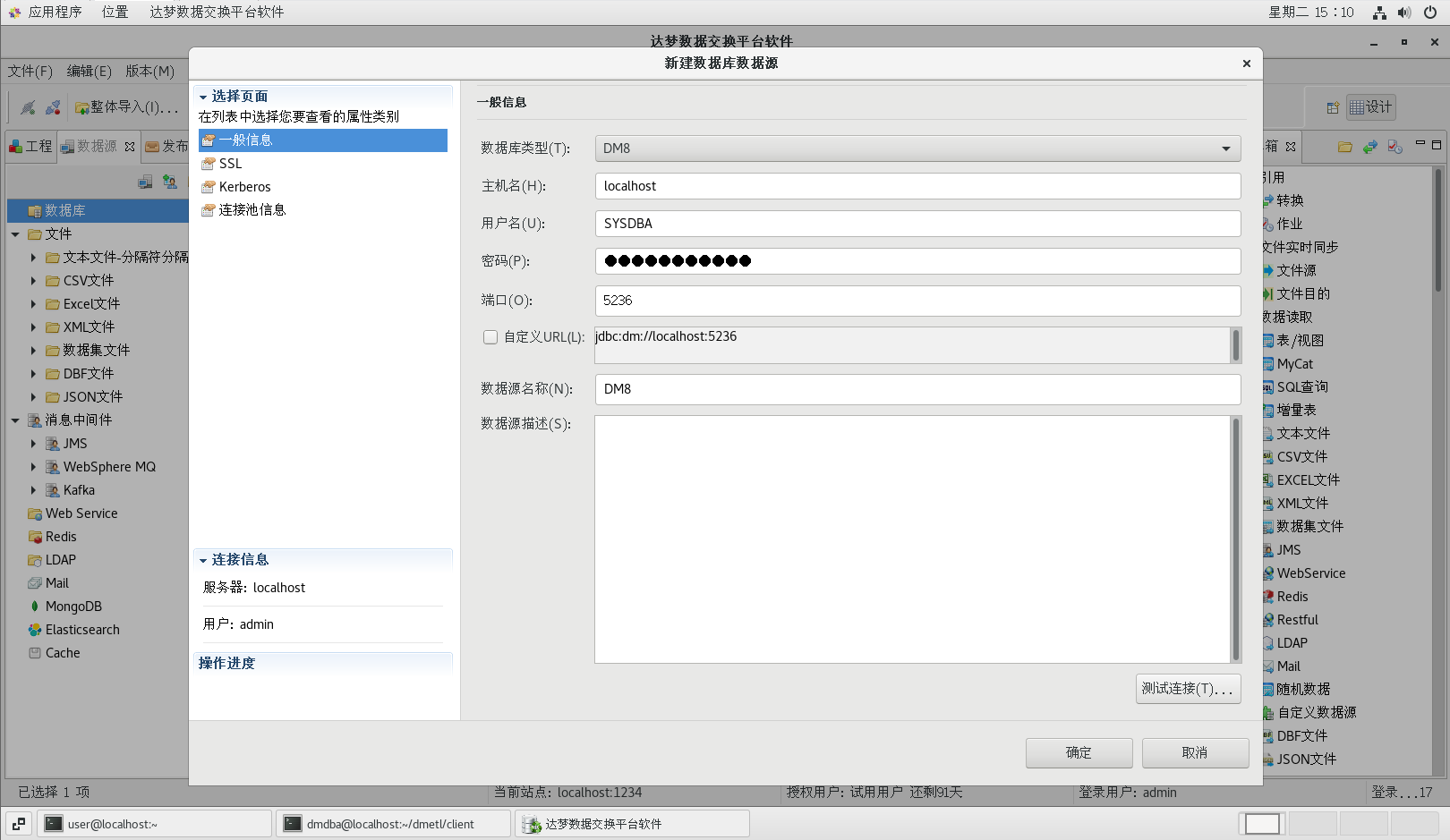
(1)切换到【数据源】选项卡,在【数据库】点击右键,选择【新建数据库数据源】菜单项,打开新建数据库数据源对话框
(2)选择源库类型,并填入相关信息
(3)右击数据源,选择添加表
将 EMPLOYEE、 EMPLOYEE_DEPARTMENT、DEPARTMENT、以及 PERSON 表添加到系统中

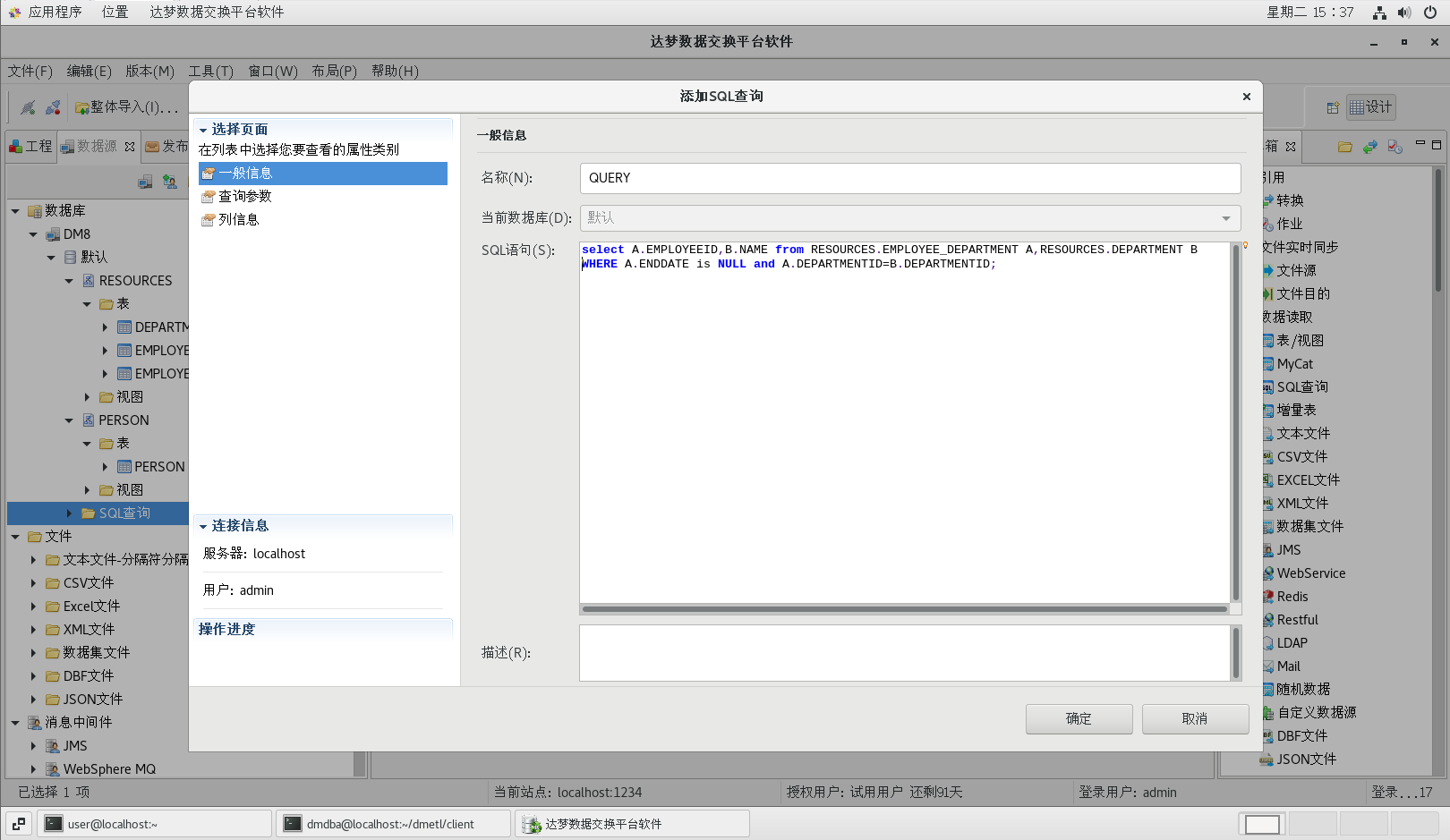
(4)添加 SQL 查询
4.2创建数据源SAMPLE
同上一步一样新建数据源,添加表EMPLOYEEINFO

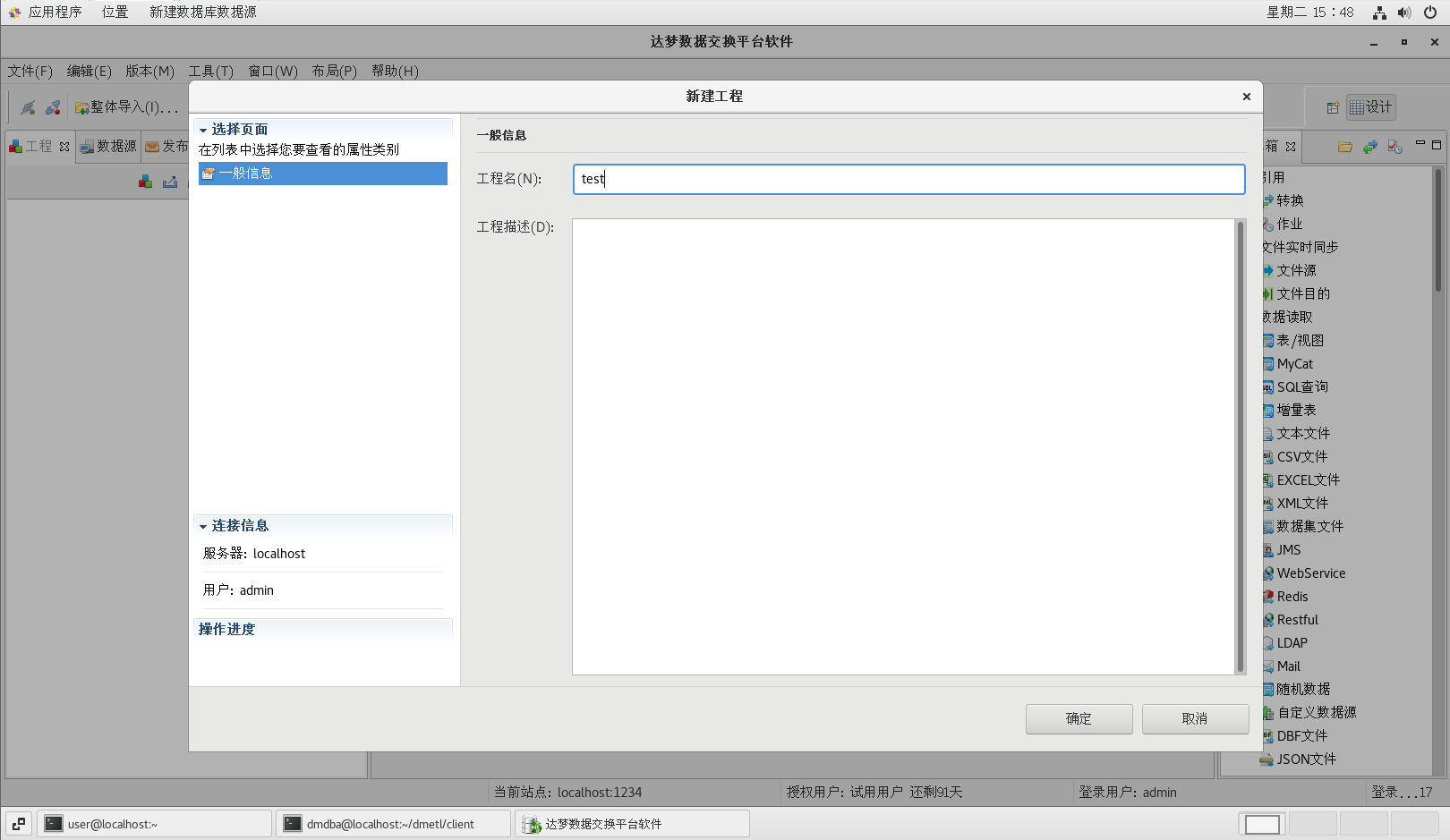
4.3创建工程
4.4设计转换
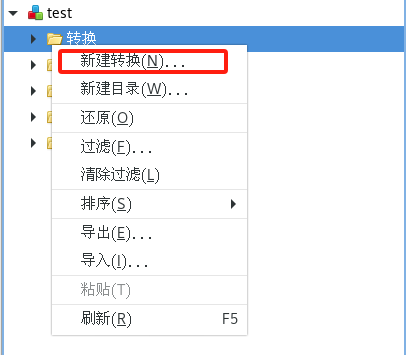
(1)新建转换
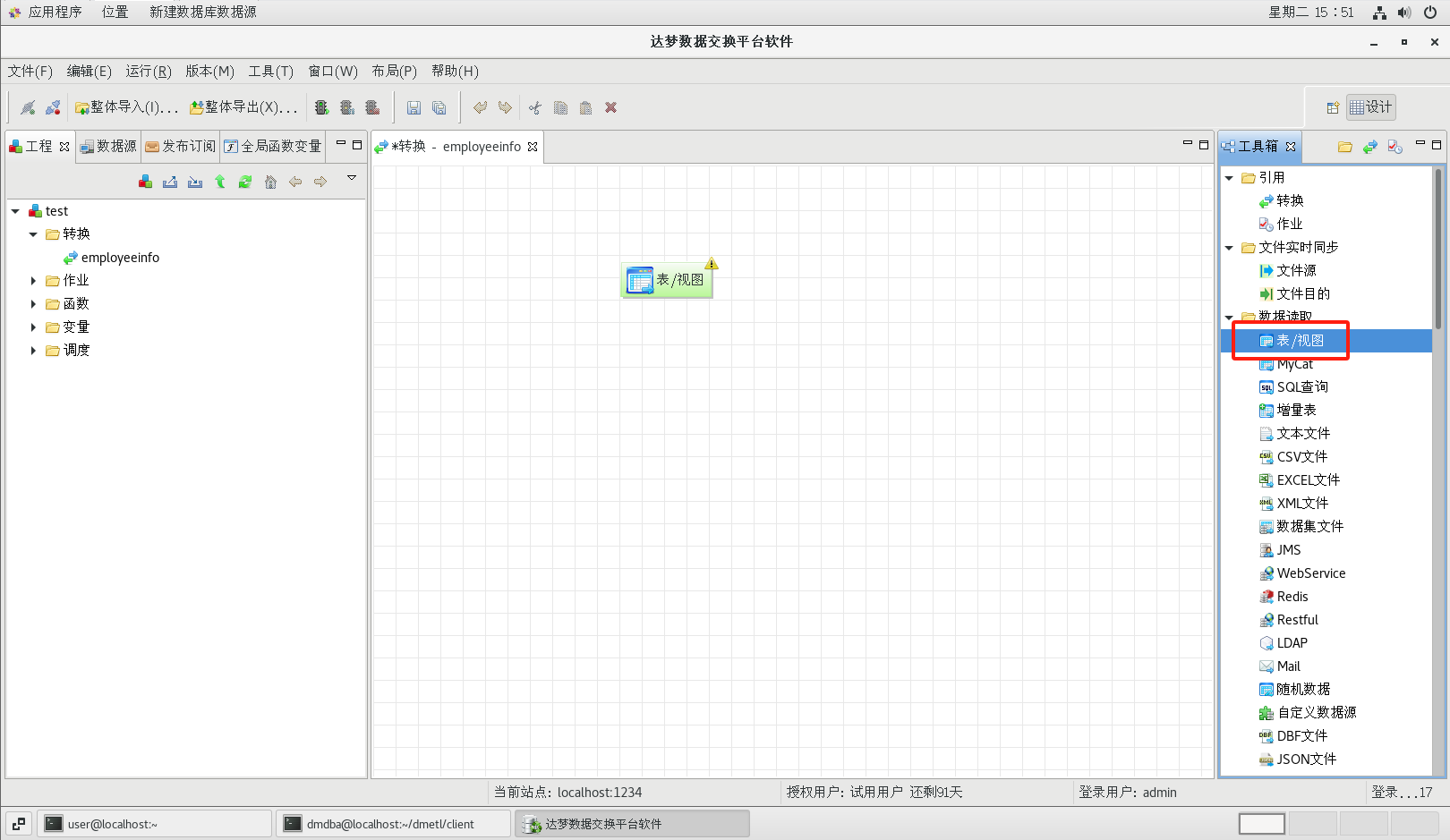
(2)添加源表
转换创建成功后系统会自动打开转换设计器。从工具箱的【数据读取】标题下面把【表/视图】组件拖到流程设计器中,然后双击图标,可以打开表数据源的配置对话框
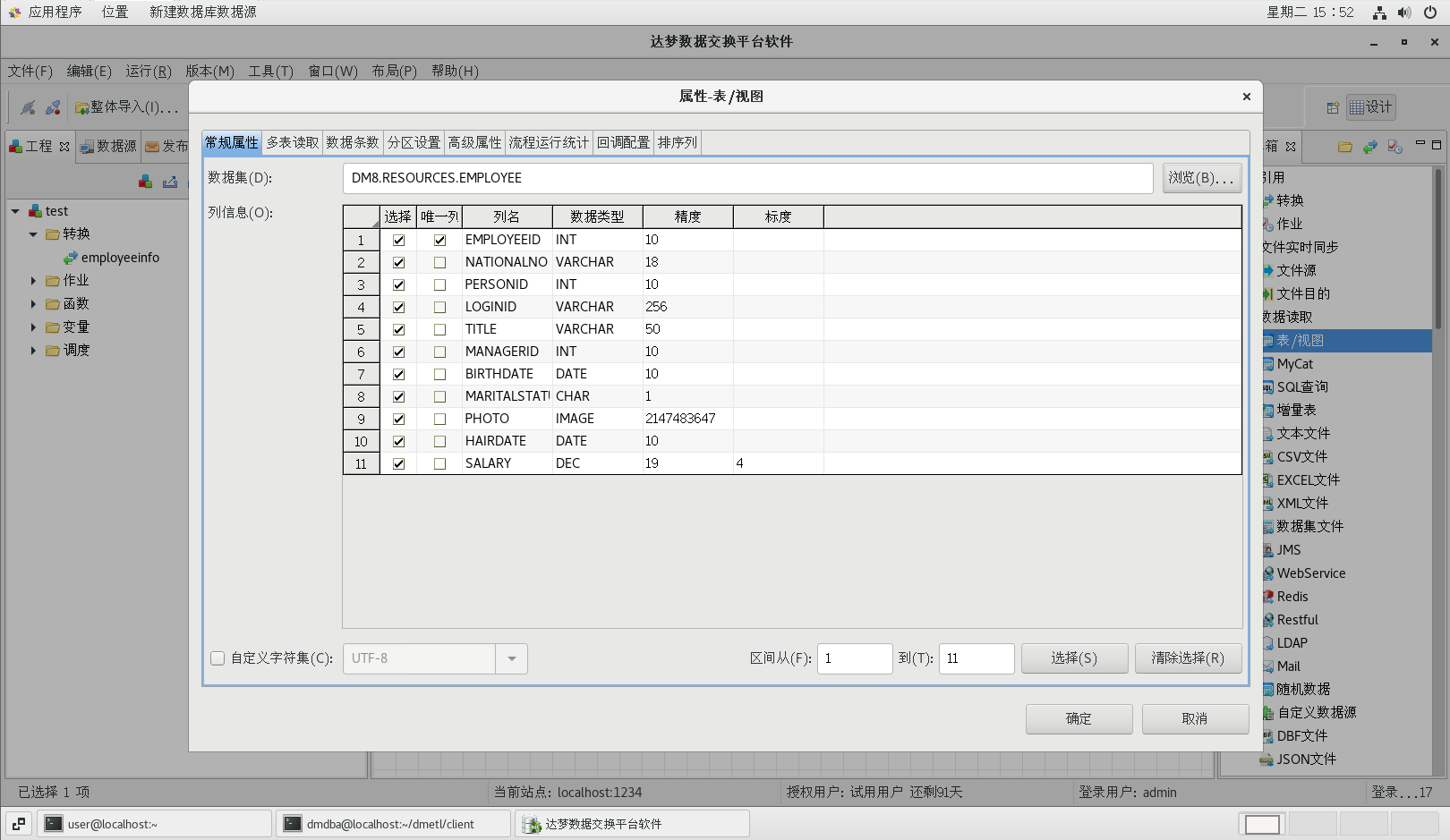
按照下图配置好各个属性
(3)增加所属部门字段
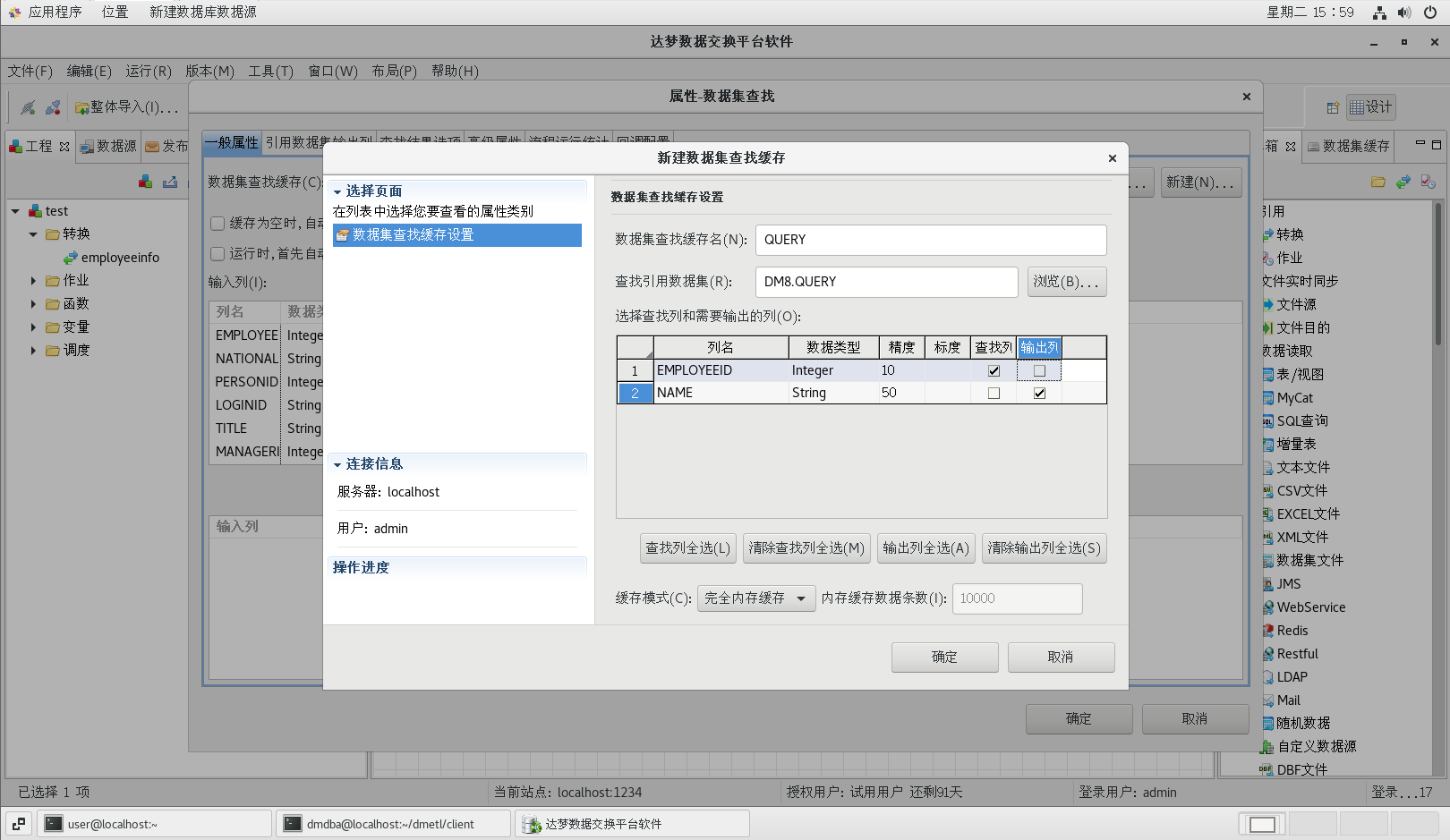
新建数据集缓存,【窗口】菜单中【数据集缓存】,新建数据集缓存;

从工具箱的【数据转换】标题下面把【数据集查找】组件拖到流程设计器中;
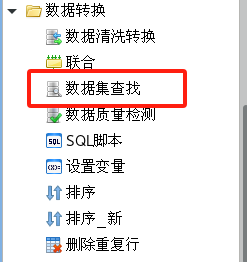
用连接线将流程设计器中的表数据源节点和数据集查找节点连接起来;
(用绿色的线,这里不对)
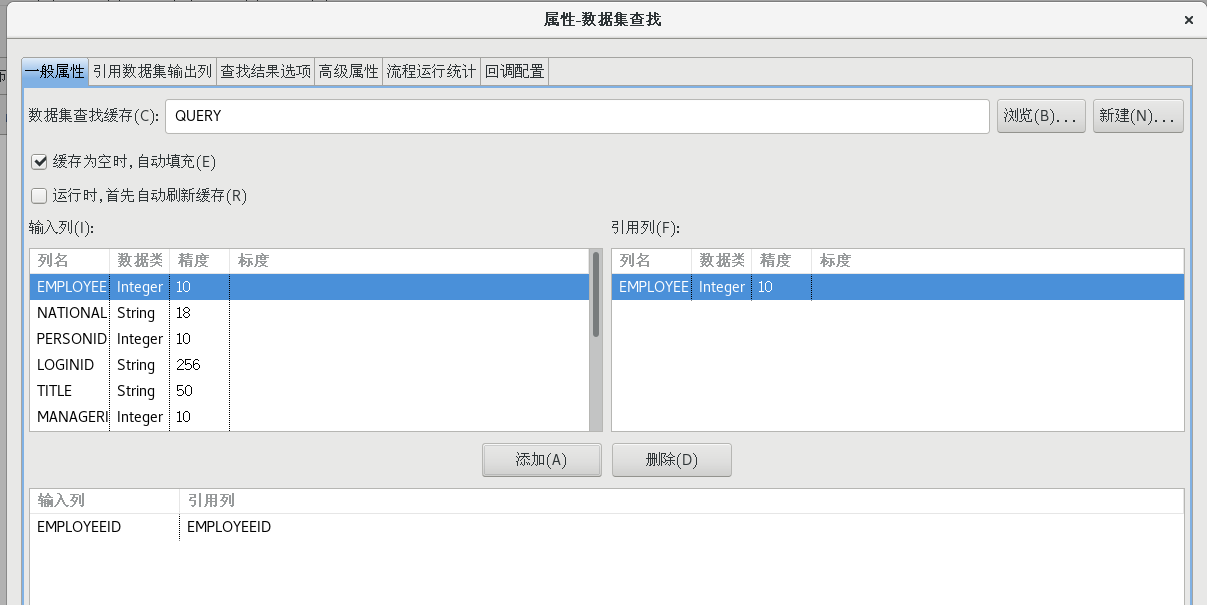
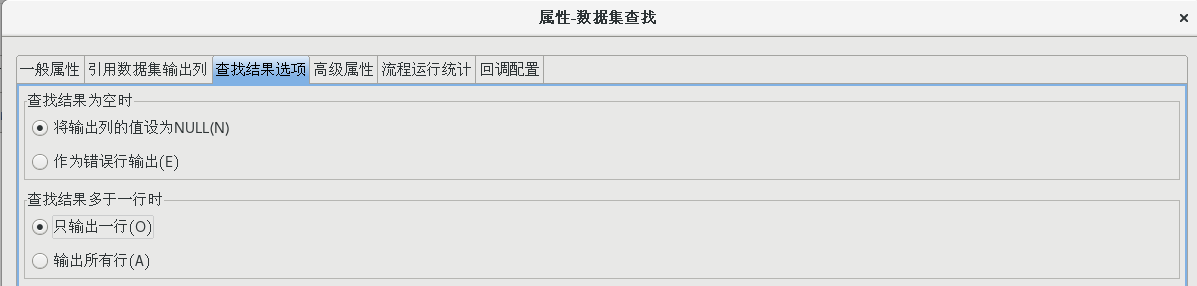
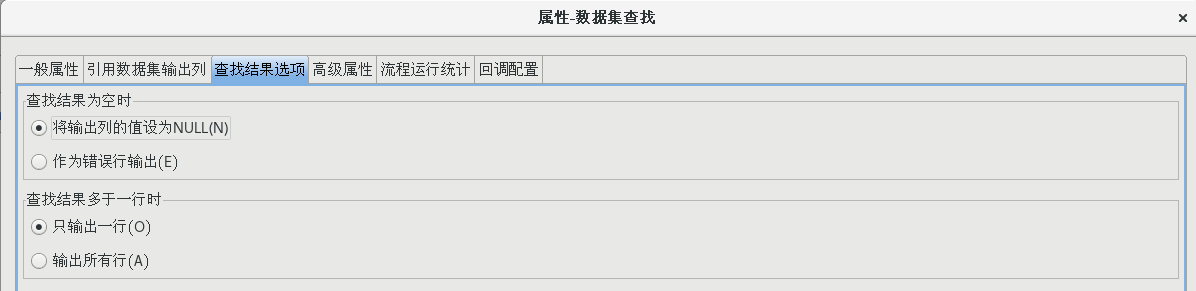
双击【数据集查找】节点,打开数据集查找属性配置对话框,并按照下图所示配置好各个属性值

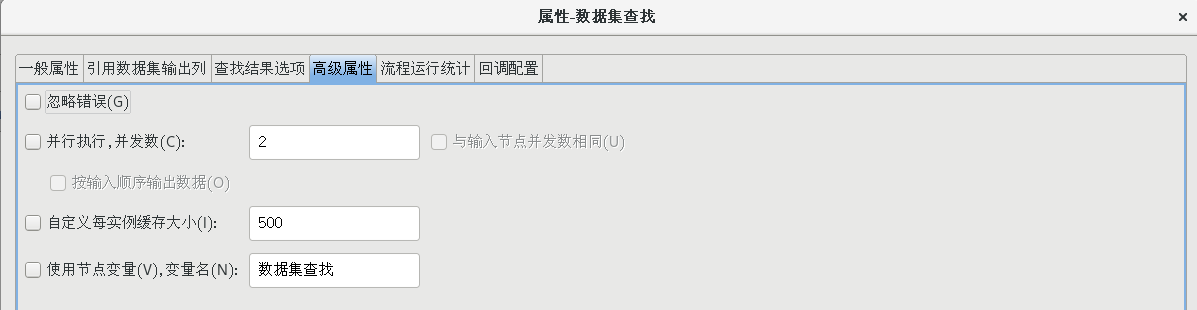
(4)增加姓名、性别、email 地址、电话号码字段
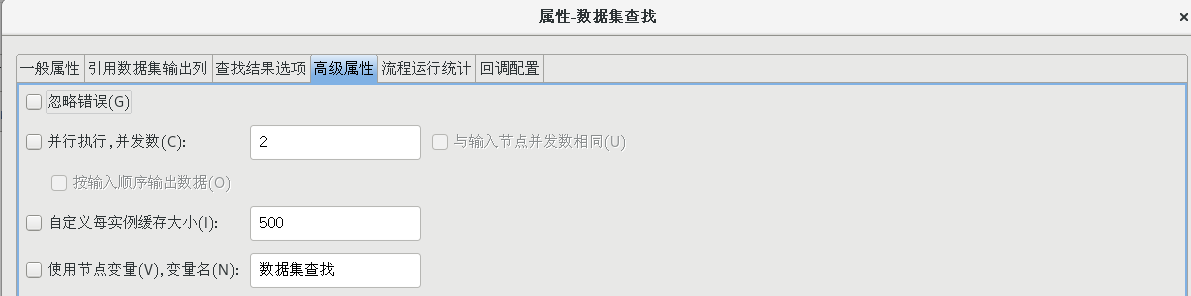
按照上一步的方法再次新建一个数据集缓存,拖一个【数据集查找】组件到流程设计器中,并建立好连接,并按照下图设置好各个属性
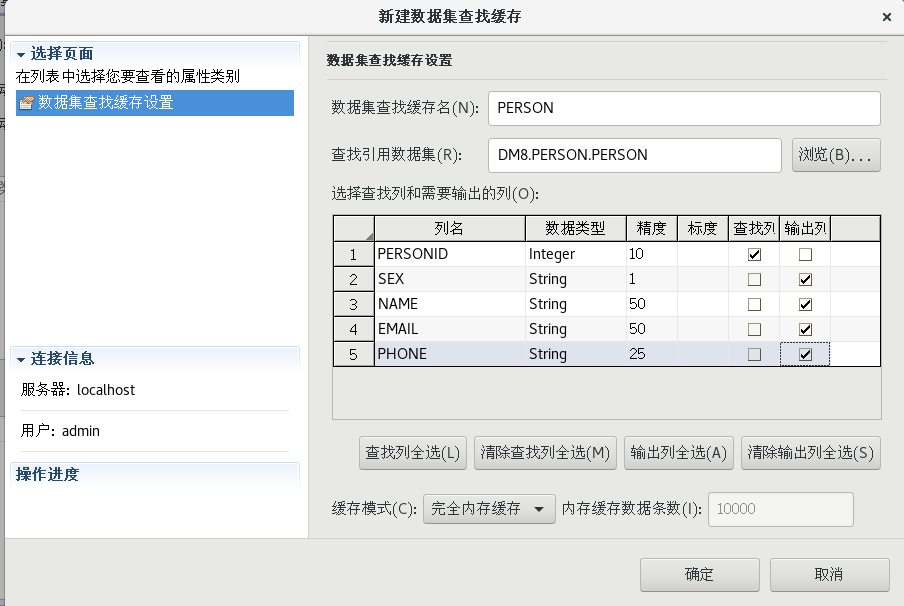
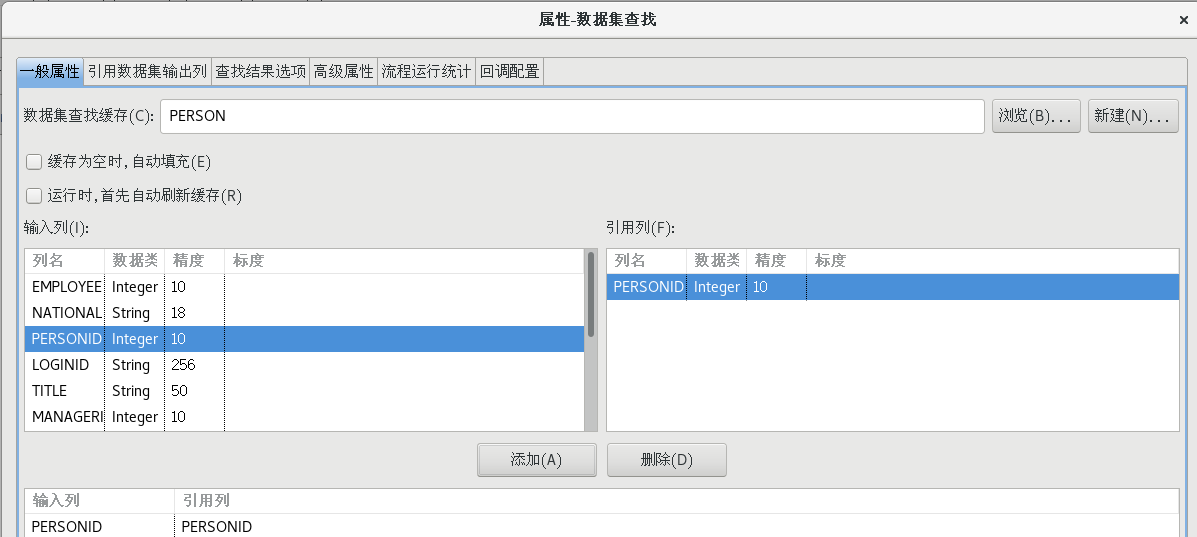
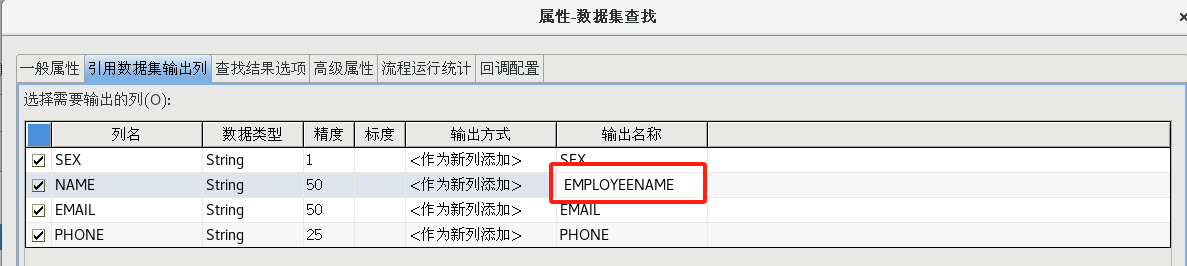
(5)字段值替换
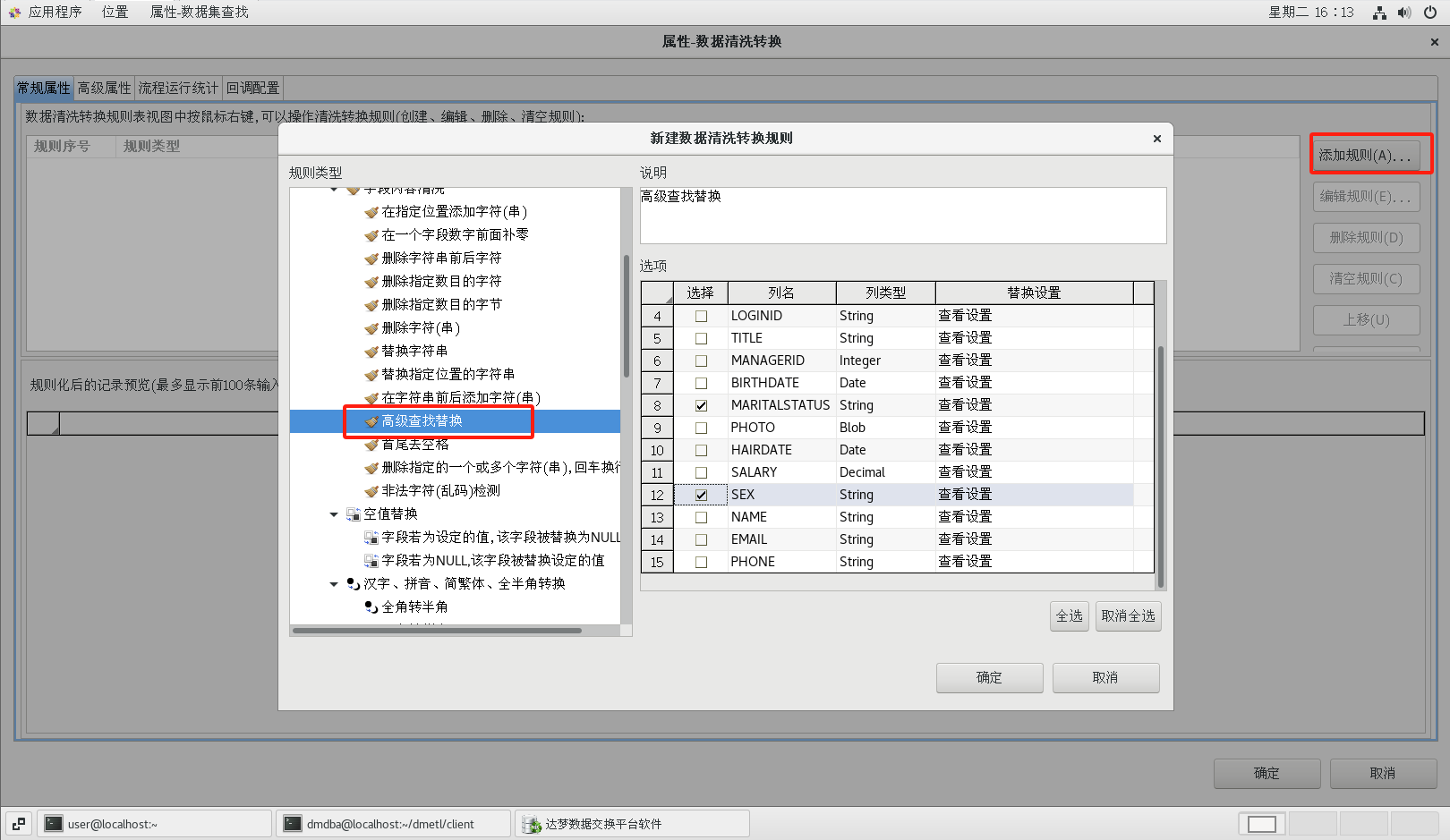
拖动一个【数据清洗转换】组件到流程设计器中,并建立好连接,并按照下图所示配置好属性
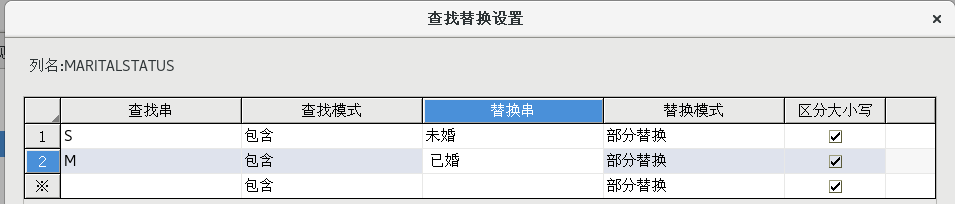

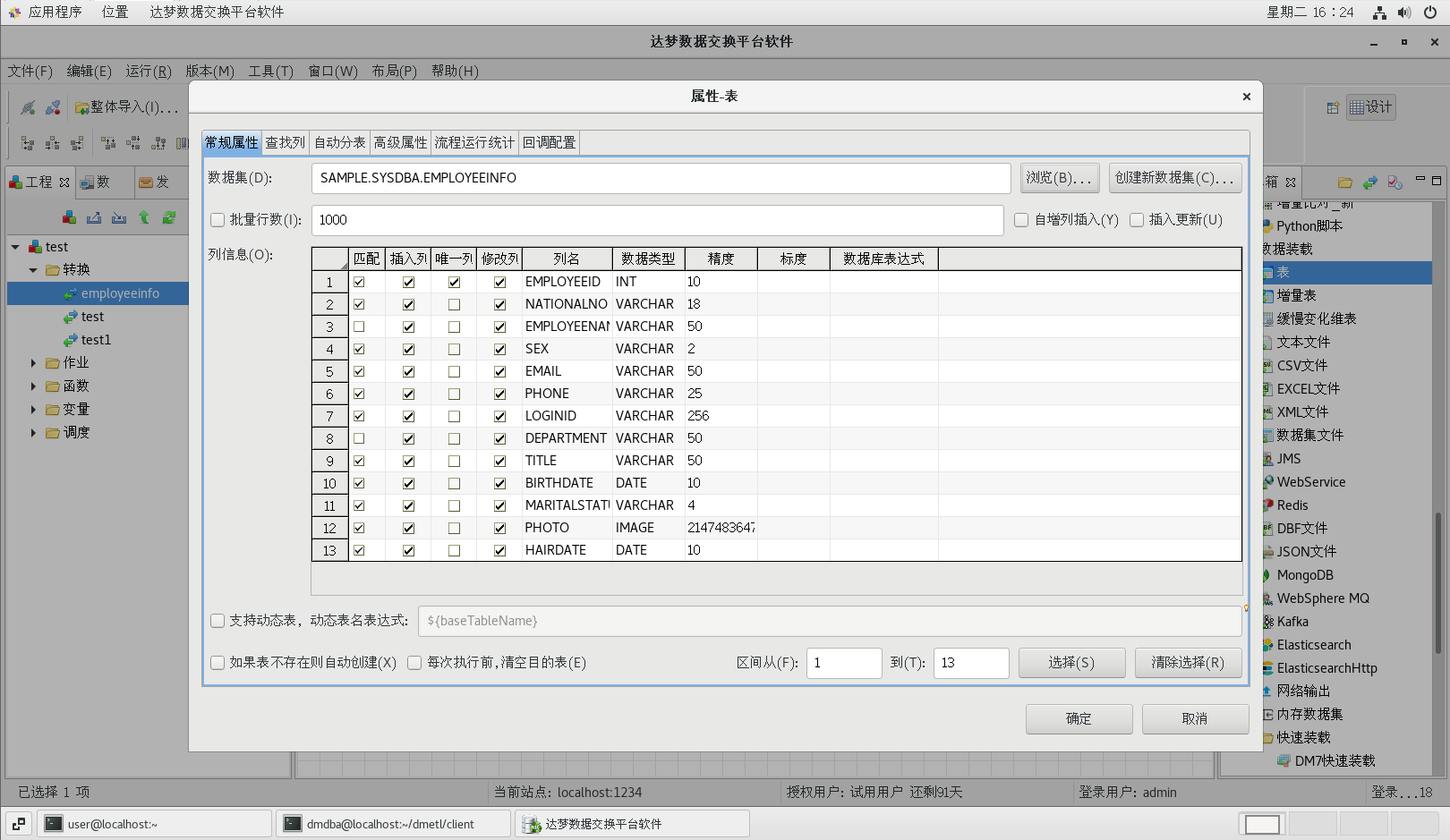
(6)添加目的表
从工具箱中的【数据装载】标题下拖一个【表】组件到流程设计器中,建立好连接并按照下图配置好各个属性值
(7)修改节点名称
在流程设计器中选中节点,然后按 F2 或者使用鼠标单击节点右键,选择重命名菜单可以编辑节点名称
(8)添加注释
将【工具箱】中【辅助工具】中【备注】组件拖到流程设计器中,可以向流程设计器中添加注释节点
(9)执行流程
经过上述步骤后,最终设计好的流程如下图所示
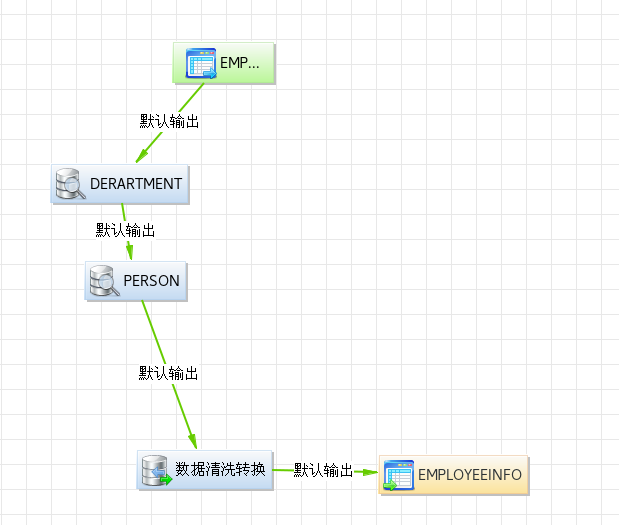
保存后点击绿色执行键执行
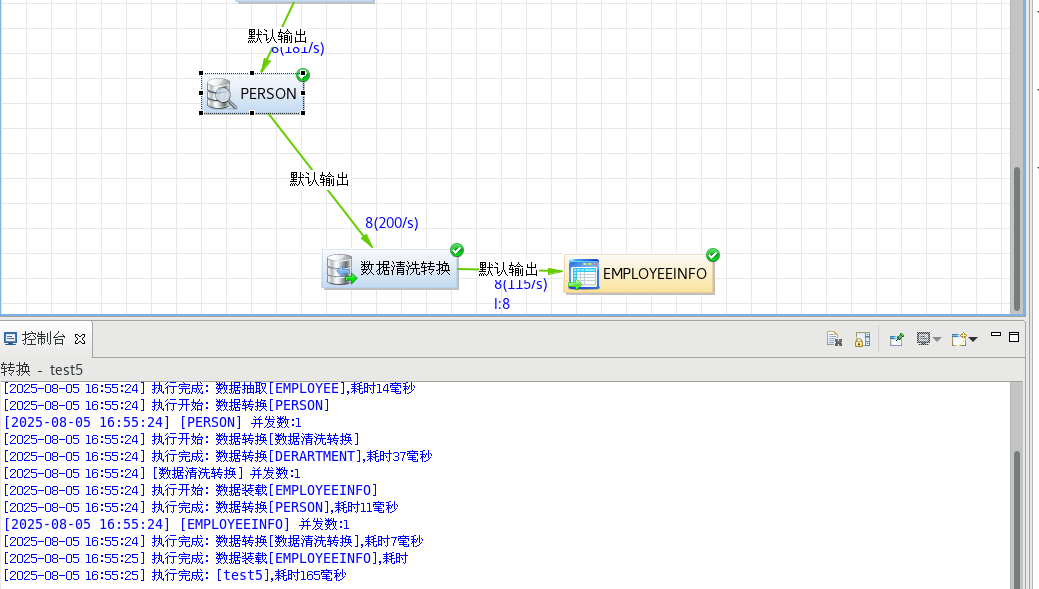
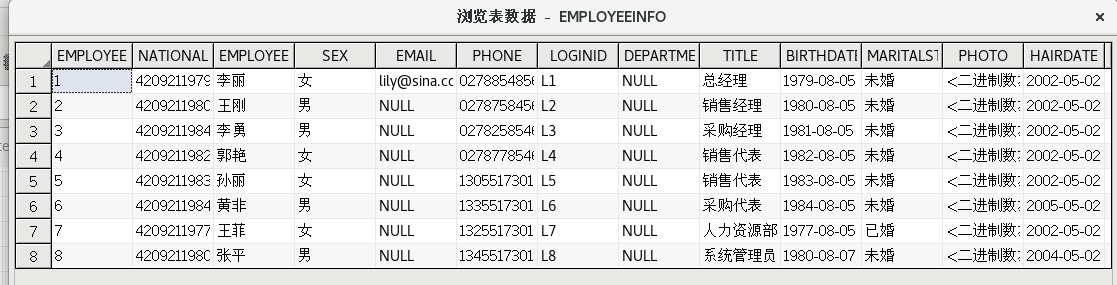
在表目的组件上点击右键选择【浏览数据】菜单项,可以查看目的表中的数据

:全面解析容器化革命 | 2025 终极指南)

)
——学习笔记)


)










与LCS(最长公共子序列))
:5.抽象类和接口)