Digit Recognizer | Kaggle 题面
Digit Recognizer-CNN | Kaggle 下面代码的kaggle版本
使用CNN进行手写数字识别
学习到了网络搭建手法+学习率退火+数据增广 提高训练效果。
使用混淆矩阵 以及对分类出错概率最大的例子单独拎出来分析。

最终以99.546%正确率 排在 86/1035
1. 数据准备
拆成X和Y 输出每个数字 train中的数据量
import pandas as pd
import seaborn as sns
train = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
test = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
Y_train = train["label"]
X_train = train.drop(labels = ["label"],axis = 1)
del train g = sns.countplot(x=Y_train)
Y_train.value_counts()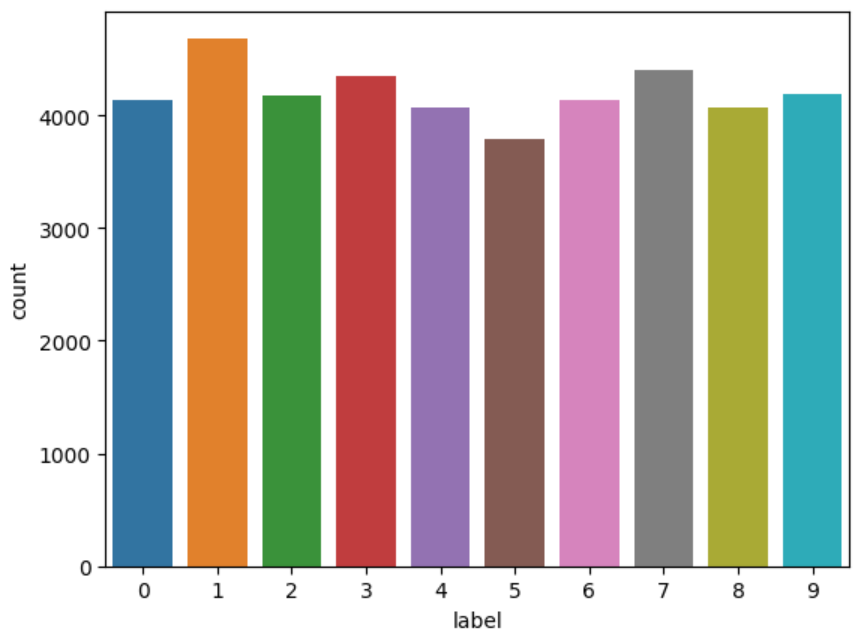
1.确认数据干净 → 没有缺失值。
print(X_train.isnull().any().describe()) # 下面代表所有列 都是False
print(test.isnull().any().describe())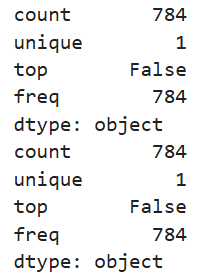
2.灰度归一化(除以255) → 提升训练速度和稳定性。
reshape → 转换成 CNN 所需的 (height, width, channel) 格式。
原来是(样本数, 784) -> (样本数, 高度, 宽度, 通道数) 样本数, 28, 28, 1
X_train, test = X_train / 255.0, test / 255.0
X_train = X_train.values.reshape(-1, 28, 28, 1)
test = test.values.reshape(-1, 28, 28, 1)3.One-Hot 编码 只有一个位置为1的标签 → 后续 softmax 输出10个类别的概率。
from tensorflow.keras.utils import to_categorical
Y_train = to_categorical(Y_train, num_classes=10)4.划分验证集 → 用于调参、防止过拟合。
from sklearn.model_selection import train_test_split
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size=0.1, random_state=2)5.可视化一个样本 → 检查数据是否正确加载。
import matplotlib.pyplot as plt
plt.imshow(X_train[0][:,:,0], cmap='gray')
plt.title("Example Image")
plt.show()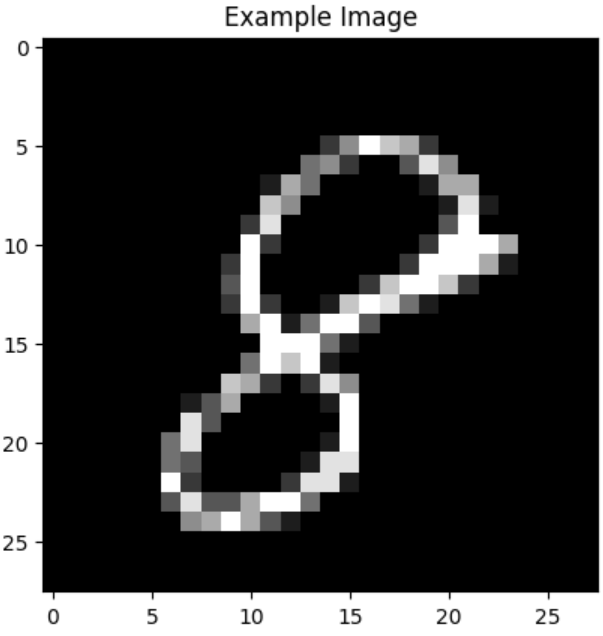
2. CNN模型建构
卷积块:2个Conv(5 * 5)+ BN + 池化 ~ 2个Conv(3 * 3) + BN + 池化。
Dropout舍弃一些神经元防止过拟合。
import numpy as np
import tensorflow as tffrom tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D as MaxPool2D
from tensorflow.keras.layers import Dense, Dropout, Flatten, BatchNormalization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ReduceLROnPlateau
from tensorflow.keras.preprocessing.image import ImageDataGeneratormodel = Sequential()# 卷积块 1
model.add(Conv2D(32, (5,5), padding='same', activation='relu', input_shape=(28,28,1)))
model.add(BatchNormalization()) # 批归一化
model.add(Conv2D(32, (5,5), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))# 卷积块 2
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))
model.add(Dropout(0.25))输出层:Flatten + Dense + Softmax
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))model.compile Adam优化器 + 交叉熵损失 + accuracy评估
optimizer = Adam(learning_rate=0.001)model.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])学习率退火 若 3 个 epoch 内没提升,就把 lr 减半
learning_rate_reduction = ReduceLROnPlateau(monitor='val_accuracy', patience=3, verbose=1,factor=0.5, min_lr=1e-5
)数据增广(ImageDataGenerator) 轻微旋转、缩放、平移等扩充数据
datagen = ImageDataGenerator(rotation_range=10,zoom_range=0.1,width_shift_range=0.1,height_shift_range=0.1
)训练 设置 epoch batch_size steps
datagen.fit(X_train)# ===== 训练 =====
epochs = 30
batch_size = 86
steps = int(np.ceil(len(X_train) / batch_size)) # 一次训练覆盖所有样本history = model.fit(datagen.flow(X_train, Y_train, batch_size=batch_size), # 数据增强epochs=epochs,steps_per_epoch=steps, validation_data=(X_val, Y_val), # 验证数据callbacks=[learning_rate_reduction], # 回调学习率verbose=2 # 每个 epoch 输出一次
)440/440 - 144s - 327ms/step - accuracy: 0.9950 - loss: 0.0170 - val_accuracy: 0.9957 - val_loss: 0.0134 - learning_rate: 6.2500e-05 Epoch 30/30Epoch 30: ReduceLROnPlateau reducing learning rate to 3.125000148429535e-05. 440/440 - 145s - 329ms/step - accuracy: 0.9952 - loss: 0.0153 - val_accuracy: 0.9955 - val_loss: 0.0141 - learning_rate: 6.2500e-05
这是训练日志的最后一部分输出 准确率达到 99.5%
3. 模型评估 evaluation
1. history报告中 训练集和验证集的 Loss 和 Accuracy 可视化。
val为验证,验证不比训练差 说明没有太过拟合。
fig, ax = plt.subplots(2,1)# 绘制训练集和验证集的 Loss
ax[0].plot(history.history['loss'], color='b', label="Training loss")
ax[0].plot(history.history['val_loss'], color='r', label="validation loss")
ax[0].legend(loc='best', shadow=True)# 绘制训练集和验证集的 Accuracy
ax[1].plot(history.history['accuracy'], color='b', label="Training accuracy")
ax[1].plot(history.history['val_accuracy'], color='r', label="Validation accuracy")
ax[1].legend(loc='best', shadow=True)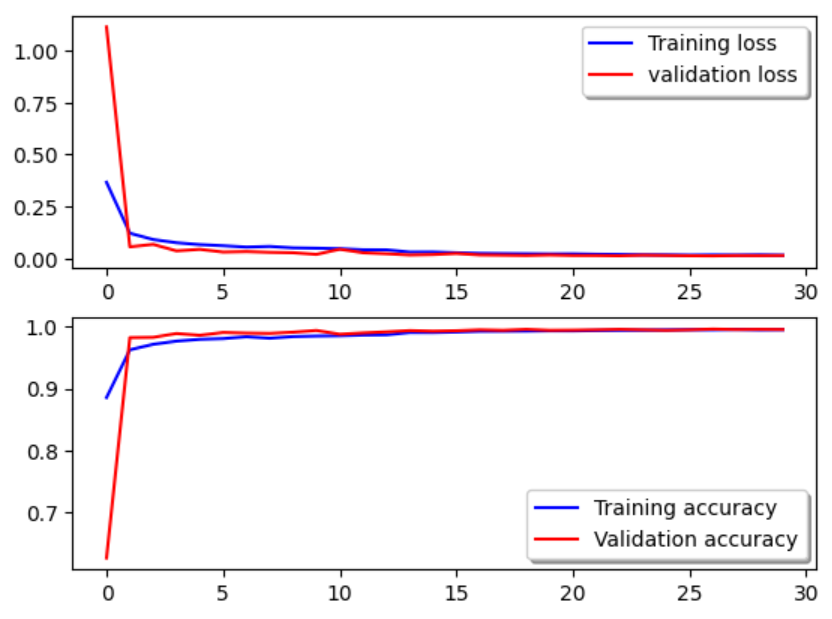
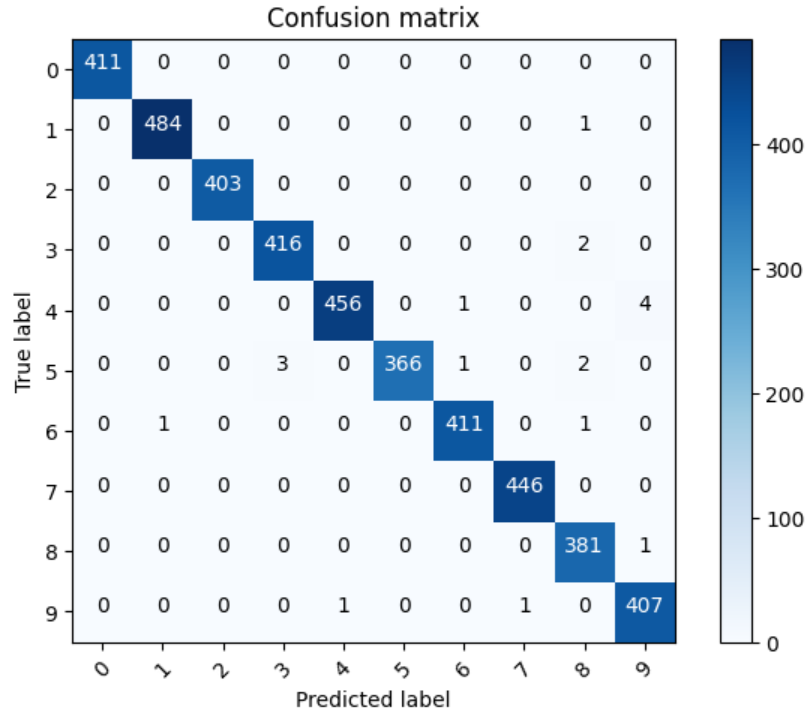
2. 混淆矩阵 confusion_matrix
from sklearn.metrics import confusion_matrix
import itertoolsdef plot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')Y_pred = model.predict(X_val) # 预测值
Y_pred_classes = np.argmax(Y_pred, axis = 1) # 预测对应类别
Y_true = np.argmax(Y_val,axis = 1) # 真实类别confusion_mtx = confusion_matrix(Y_true, Y_pred_classes)
plot_confusion_matrix(confusion_mtx, classes = range(10))
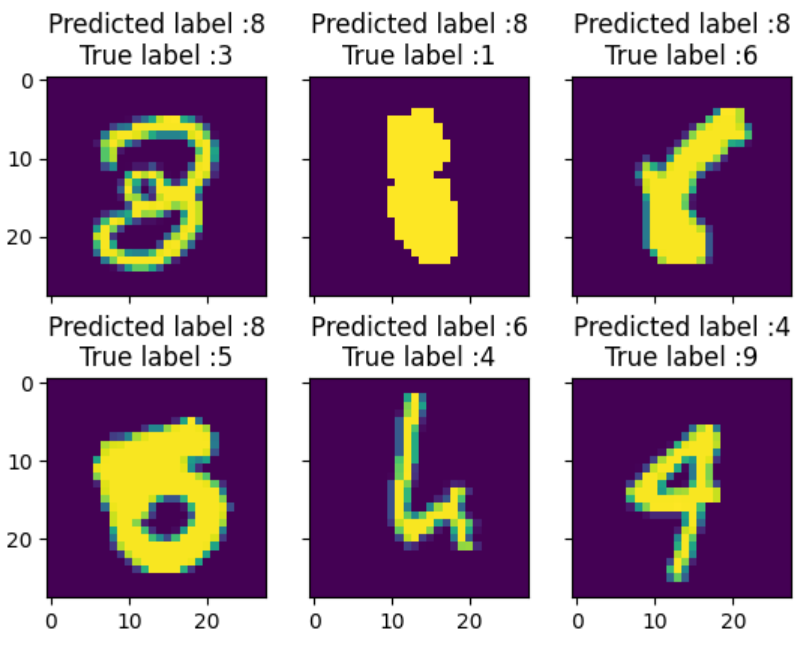
3. 对于分类错误的位置 用预测(错误数字的概率 - 正确标签的概率)
输出预测错误差别最大的图片 是什么样的。
# 找出预测错误的位置 布尔数组
errors = (Y_pred_classes != Y_true )# 提取错误预测的详细数据
Y_pred_classes_errors = Y_pred_classes[errors]
Y_pred_errors = Y_pred[errors]
Y_true_errors = Y_true[errors]
X_val_errors = X_val[errors]# 错误预测的最大概率
Y_pred_errors_prob = np.max(Y_pred_errors,axis = 1)# 正确标签对应的预测概率
true_prob_errors = np.diagonal(np.take(Y_pred_errors, Y_true_errors, axis=1))# 差值:预测的最大概率 - 正确标签概率
delta_pred_true_errors = Y_pred_errors_prob - true_prob_errors# 找出概率差最大的错误
most_important_errors = np.argsort(delta_pred_true_errors)[-6:]def display_errors(errors_index,img_errors,pred_errors, obs_errors):""" This function shows 6 images with their predicted and real labels"""n = 0nrows = 2ncols = 3fig, ax = plt.subplots(nrows,ncols,sharex=True,sharey=True)for row in range(nrows):for col in range(ncols):error = errors_index[n]ax[row,col].imshow((img_errors[error]).reshape((28,28)))ax[row,col].set_title("Predicted label :{}\nTrue label :{}".format(pred_errors[error],obs_errors[error]))n += 1display_errors(most_important_errors, X_val_errors, Y_pred_classes_errors, Y_true_errors)发现预测错误的几张图片 本身就很容易误解
4. 预测&提交结果
results = model.predict(test)
results = np.argmax(results,axis = 1) # 概率转类别
results = pd.Series(results,name="Label")submission = pd.concat([pd.Series(range(1,28001),name = "ImageId"),results],axis = 1)
submission.to_csv("cnn_mnist_datagen.csv",index=False)









:拷贝构造函数与赋值运算符重载深度解析》)

![[ 数据结构 ] 时间和空间复杂度](http://pic.xiahunao.cn/[ 数据结构 ] 时间和空间复杂度)




)

