如果对于框架的介绍不感兴趣的可以直接跳到Getting Started快速开始
在设计一款数据加载编排框架时,除了任何框架都必须具备的可靠性与稳定性之外,对于本次编排框架的设计,我们把核心目标放在高性能与易用性上。这不仅要求框架能够快速、高效地完成数据加载任务,更要让使用者将精力集中在业务逻辑的实现上,而无需为缓存细节或单次调用性能反复操心。受到设计模式的启发,我采用了一种全新的思路,并行Builder,
设计目标
易用性
框架在易用性上的设计理念是:让使用者编写业务步骤时像“施工工人”一样简单。用户只需专注于当前节点的任务及其依赖,其他诸如超时控制、重试策略、降级处理、生命周期钩子、动态任务提交等通用能力,均由框架自动完成,同时使用者也不需要编写额外的流程表达式脚本。
为了实现这种体验,我们采用了隐式约定的方式,给予用户极大的自由度,同时简化了依赖数据的获取与调用链路。框架支持 Builder 模式,将整个结果构建过程抽象为“大楼施工”:每个节点是一个工人,节点间的依赖关系就是施工顺序。这样既直观又易于维护,能覆盖 90% 以上的使用场景。
对于更复杂、灵活的需求,我们还提供了低层级 API,允许用户自定义甚至扩展框架功能。框架还会记录节点运行时的附加信息(如耗时、重试次数等),以便做调用监控或动态决策。
高性能
我们的框架另外一个核心目标就是高性能,把性能做到极致,性能优化贯穿了框架实现的各个细节。
-
依赖就绪即执行:节点在所有依赖完成后立即开始工作,最大化并行度。
-
减少锁与对象创建:尽可能避免锁、匿名类与多余对象,尽可能减少用户态/内核态切换和减轻 JVM 垃圾回收压力。
-
无脚本性能损耗:不引入额外脚本语言,无需额外的编译,直接用高性能原生代码执行。
-
结果共享与懒加载:同一节点只执行一次,其结果可被多个依赖节点复用;无需执行的节点不会创建任务,也不会进入线程池。
-
线程池可定制:用户可根据调用信息优化线程池配置,精细控制并发性能。
编排框架的“不可能三角”
在通用性、易用性(或易维护性)、复用性这三个维度上,几乎不存在一个编排框架能三者兼得。
易用性:易用性意味着低学习成本和直观的 API 设计,无需额外脚本或复杂配置文件即可完成开发。
通用性:通用性要求框架能够在不同场景、不同流程下正常运行。例如,如果一个流程是固定的(像智能洗衣机洗衣服那样),那么针对这个场景的专用框架会很简单。但现实中,业务流程经常变化,甚至同一团队内部也可能有多个差异很大的流程,因此通用性对框架来说往往是必需的。
复用性:复用性强调组件可以跨流程复用。
根据我在编排框架的学习和设计中,发现在自定义流程的编排框架的设计中,易用性与复用性天然存在冲突,如果要实现高度复用,组件必须对流程无感,这会让它无法确定数据来源与结果去向,从而需要引入流程层的变量绑定、条件判断等配置语言。这类脚本复杂度随着流程增长而急剧上升,不仅维护困难,还缺乏 IDE 的智能支持。
因此,我们在设计时选择部分放弃组件复用性,换取简单易用的开发体验:
-
每个组件知道自己处在什么位置、需要什么数据、产出什么结果;
-
组件逻辑更单纯,减少为了兼顾多场景而加入的复杂判断;
-
代码可维护性更高,减少迭代中的逻辑腐化风险。
对于重复逻辑,我们通过公共方法封装来消除冗余。同时,借助 Builder 模式,我们仍保留了一定的复用能力,通过抽象初始化参数与返回结果来实现组件的共享化。
富节点与穷节点
在对于节点设计上,参考DDD理论,我区分了两种模式:
-
穷节点:只关心自身业务逻辑,其他的依赖关系、兜底策略、超时、重试等全部交给框架。这种方式节点解耦好,但数据传递与流程表达复杂度高,尤其在总流程庞大时维护成本极高。比较适合在强调组件复用的框架中使用。
-
富节点:节点同时管理自身的依赖、容错、超时、重试等逻辑。虽然单个节点更重、复用性降低,但整体流程更直观,数据传递简单,易于可视化和性能优化,尤其在流程本身很庞大复杂的时候更能体现其优势。
本框架采用富节点设计思路,因为它不仅优化了可读性与性能,还能轻松实现运行时的动态流程调整。
框架组件
我们的框架设计本身就很简单,很多复杂性已经封装在了框架内部,并且采用了大量默认配置,只有在真正需要的时候才去设置他们,使用上非常方便,核心组件也很简单。这里我们只介绍框架的应用层组件,底层组件一般用于做二次拓展时才会用到这里不做介绍,
ParallelDataBuilder:负责管理和执行整个流程,主要加入流程中的各个节点,需要时候要能设置超时时间,节点钩子函数,自定义执行线程池等等,还提供检查节点是否有循环依赖的方法,提高代码安全性,ParallelDataBuilder是可以复用并且并发安全的,添加了节点和进行了必要配置后就能传入初始参数调用它的构建方法,开启整个流程
ProcessNode:执行每个步骤的节点,主要需要定义名称,执行的工作内容,依赖的节点名称等,如果有需要还可以定义其重试次数,自定义重试判断,是否需要加载判断(用于实现分支的效果)等等,为了进一步简化开发者使用,框架在processNode的工作参数暴露了流程初始化参数,最终返回结果,尽管这些都可以在LoadContext中获取,
LoadContext:context是一个自动化的组件,用户无需自己显式地创建,在ProcessNode直接使用就可以了,LoadContext提供了几乎ProcessNode可能需要的所有功能,包括其他节点的运行结果,流程的启动参数,读写本次流程的共享变量,动态提交其他任务等等
框架结构和流程设计
我们的框架会按照各个节点的依赖关系自动生成最终的任务图,并且每个任务的依赖都完成后都会尽可能快地去执行,大体流程如下
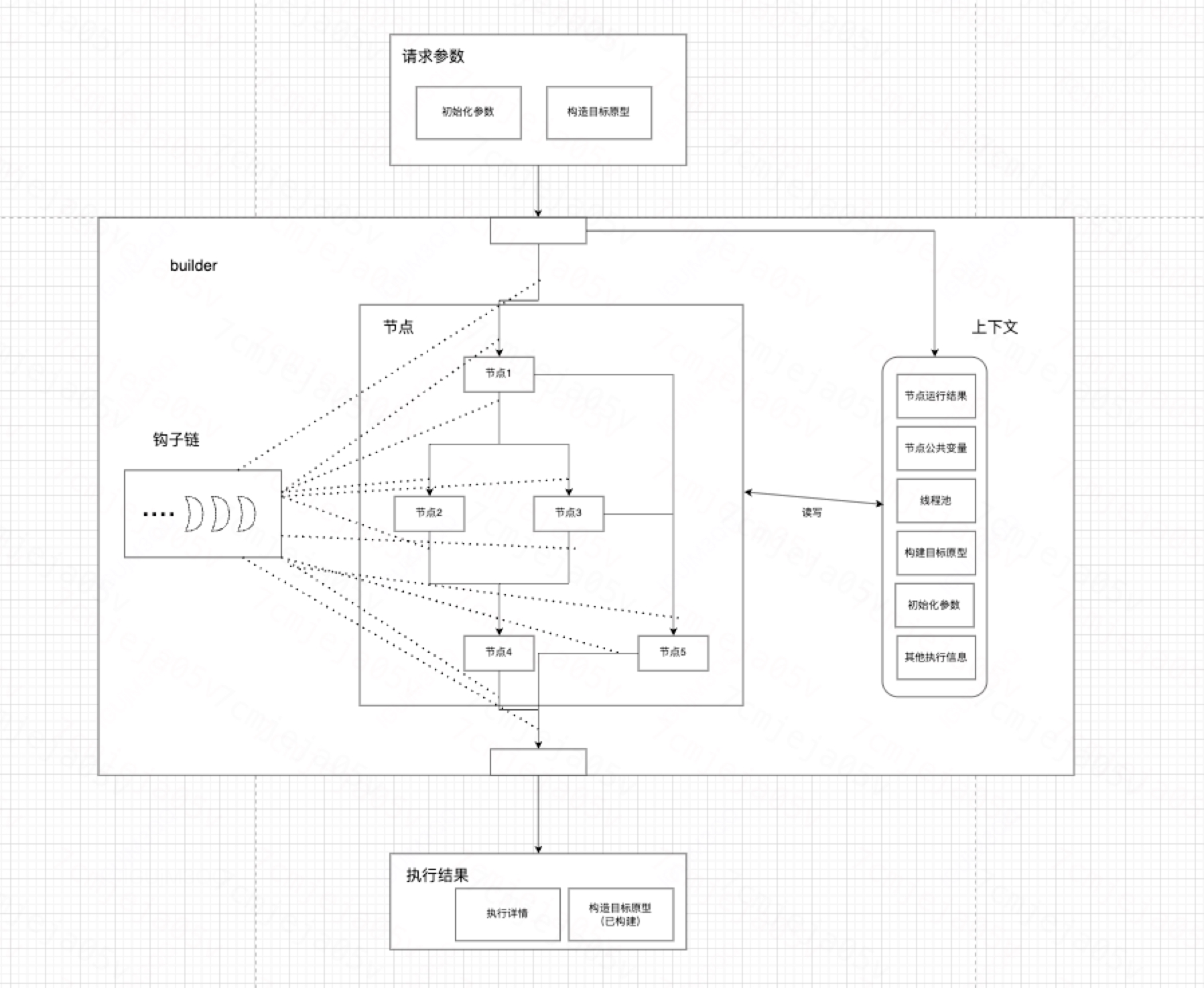
每个节点都会在所有依赖节点执行完成后执行,直到所有节点都完成后整个流程才返回。
其中上下文存储了这个流程的几乎所有信息,包括每个节点的执行结果,执行信息,节点的共享变量等等,每个节点都可以在上下文中获取到自己想要的信息,设置共享变量,以及提交任务等。
Builder模式下,会暴露一个构造目标给到所有节点,这个构造目标是不可修改的,每个节点都参与对这个目标的构建,主要就是修改它的字段内容,最终一起完成这个目标的构建,这个构造目标需要在流程开始时传入。
Builder可以设置钩子链,钩子链由一个个钩子函数组成,他们会在这些节点进入某些特定生命周期时候运行,包括执行前,执行完成,抛出异常,重试等等。主要用于对节点做统一管理,减少重复代码。
额外能力支持
重试:支持自动化重试和自定义重试,节点可以编写最大重试次数(1为不重试),也可以自定义重试判断逻辑。
超时:总体流程支持超时设置,超时后抛出异常。
降级:支持节点编写兜底方法,执行异常并且重试失败后进入降级逻辑。
钩子:支持为Builder加入钩子,在流程或者各个节点进入相应生命周期时候执行。
动态提交任务:框架支持节点在执行时候动态提交异步任务,并且可以选择堵塞式和非堵塞式,堵塞式异步任务虽然不会堵塞当前节点的工作,但是总流程会得到这个任务完成后才返回。
循环依赖检测:框架也为builder提供自查循环依赖的能力,检查是否有循环依赖的节点,避免造成系统性风险。
嵌套:框架提供了对流程之间嵌套的支持。
支持spring:builder提供了对spring的支持,可以通过bean name直接加入节点,
详细信息:框架提供了这流程和每个节点的具体运行详情,比如运行时间,重试次数等
作品信息
github:https://github.com/oraen/oraen-box
maven: Maven Central: com.oraen.box:oraen-box-loader
docs:this
Getting Started
完成了介绍后,让我开始使用吧,这里会通过一个demo展示怎么使用这个框架。
demo目标
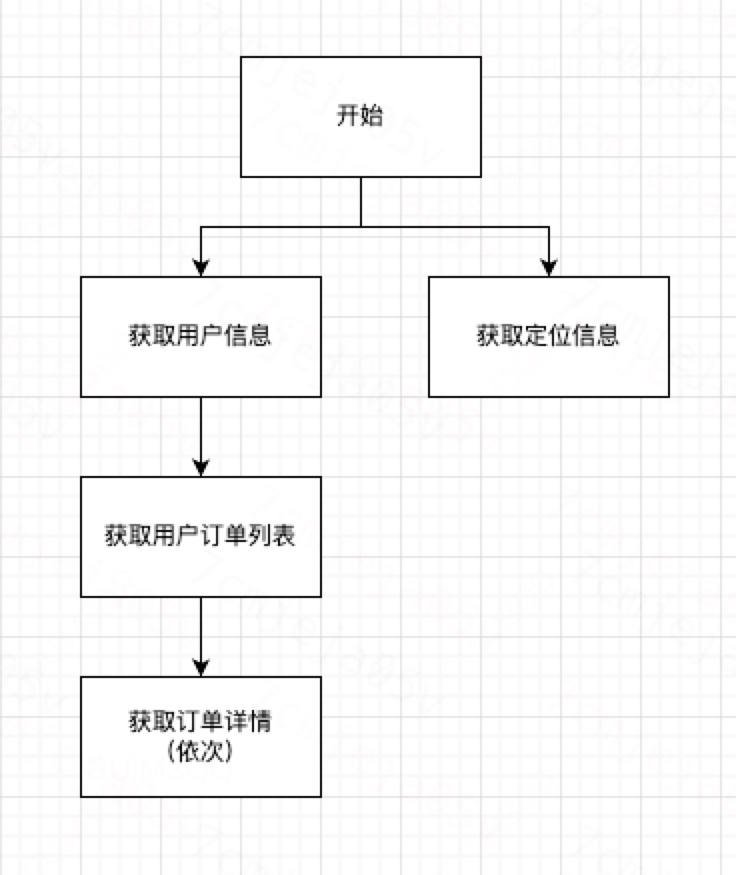
本次简单demo的假设需要从获取用户订单详情列表,需要调用四个接口,分别用于获取用户信息,用户订单,订单详情(不支持批量调用),定位接口。流程如下。
传参对象
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
class Param{String token;String lat;String lng;
}返回对象
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
class Resp{String cityId;String userName;Long userId;String lat;String lng;List<OrderDetail> orderList;@Data@Builder@NoArgsConstructor@AllArgsConstructorpublic static class OrderDetail{Long orderId;Long orderCreateTime;}
}需求分析
根据demo的需求,我们需要根据token获取到用户具体信息,同时通过经纬度获取定位城市,在获取到用户信息后需要通过订单接口获取到用户的所有订单,然后每个订单都需要单独调用订单详情接口获取到订单详情。前面都可以设置单独的节点完成,但是我们不知道订单的数量,最后一步只能通过动态提交任务的方式来完成(相当于动态创建节点),我们这里通过builder的方式来完成这个目标
引入依赖:目前可以通过maven直接引入,各个版本的优化可以在github的commit信息查看
<dependency><groupId>com.oraen.box</groupId><artifactId>oraen-box-loader</artifactId><version>1.2.1-RELEASE</version> </dependency>
编写获取用户信息节点
编写一个节点,负责调用服务解析token,获取用户信息,名字可以取名为getUserInfo,不依赖其他节点,继承ProcessNode<Param, Resp>并且实现主要方法。
class GetUserInfoNode implements ProcessNode<Param, Resp> {@Overridepublic Object process(Param param, Resp resp, LoadContext context) {String token = param.getToken();//mock解析token操作//直接给最终要返回的结果设置值resp.setUserId(20L);resp.setUserName("corki");//builder模式下一般用不到节点的返回结果,可以返回nullreturn null;}@Overridepublic String name() {return "getUserInfo";}@Overridepublic List<String> dependencies() {return Collections.emptyList();}
}编写用户定位节点
同样编写一个节点,获取用户所在地,名字可以取名为getMapInfo,不依赖其他节点
class GetMapInfoNode implements ProcessNode<Param, Resp> {@Overridepublic Object process(Param param, Resp resp, LoadContext context) {String lat = param.getLat();String lng = param.getLng();//mock解析经纬度...resp.setCityId("211");return null;}@Overridepublic String name() {return "getMapInfo";}@Overridepublic List<String> dependencies() {return Collections.emptyList();}
}编写获取用户订单节点
编写一个负责获取用户订单的节点,他需要依赖获取用户信息节点getUserInfo完成才能执行,并且获取到用户订单后还需要获取所有订单的订单详情
class GetUserOrderNode implements ProcessNode<Param, Resp> {@Overridepublic Object process(Param param, Resp resp, LoadContext context) {//mock获取用户的所有订单List<Resp.OrderDetail> orderDetails = new ArrayList<>();for(int i = 0; i < 4; i ++){orderDetails.add(Resp.OrderDetail.builder().orderId(i + 1000L).build());}resp.setOrderList(orderDetails);//异步获取各订单的详情,不堵塞当前节点,但是需全部完成后主流程才能完成for(Resp.OrderDetail orderDetail : orderDetails){//调用context的submitTask的方法用于提交任务,true标识堵塞主流程context.submitTask(() -> {orderDetail.setOrderCreateTime(1000000 + orderDetail.getOrderId());}, true);}return null;}@Overridepublic String name() {return "getUserOrder";}@Overridepublic List<String> dependencies() {return ListUtil.of("getUserInfo");}
}创建Builder
现在我们已经完成了所有节点的编码了,现在就需要创建一个Builder,并且吧这些节点全部加入这个Builder上
ParallelDataBuilder<Param, Resp> builder = new ParallelDataBuilder<Param, Resp>()//添加工作节点,可以根据自己编码习惯一行加入单个或者多个.addNodes(new GetUserInfoNode(), new GetMapInfoNode()).addNodes(new GetUserOrderNode())//设置超时时间.setExecTimeout(1000L)//确保节点之间没出现循环依赖,.ensure();初始化参数和初始化构建目标对象,执行后打印结果
Param initParam = Param.builder().token("asdasdasdasd").lat("18.444369").lng("-97.3794933").build();Resp resp = Resp.builder().lat(initParam.lat).lng(initParam.lng).build();builder.buildResp(initParam, resp);System.out.println(JSONUtil.toJson(resp));打印结果
{
"cityId": "211",
"userName": "corki",
"userId": 20,
"lat": "18.444369",
"lng": "-97.3794933",
"orderList":
[
{
"orderId": 1000,
"orderCreateTime": 1001000
},
{
"orderId": 1001,
"orderCreateTime": 1001001
},
{
"orderId": 1002,
"orderCreateTime": 1001002
},
{
"orderId": 1003,
"orderCreateTime": 1001003
}
]
}
整体demo代码
package test.oraen.box.loader.loader;import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import oraen.box.common.util.JSONUtil;
import oraen.box.common.util.ListUtil;
import oraen.box.loader.LoadContext;
import oraen.box.loader.extend.ParallelDataBuilder;
import oraen.box.loader.extend.ProcessNode;
import org.junit.jupiter.api.Test;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class SimTest {@Testpublic void test() throws Exception {ParallelDataBuilder<Param, Resp> builder = new ParallelDataBuilder<Param, Resp>()//添加工作节点,可以根据自己编码习惯一行加入单个或者多个.addNodes(new GetUserInfoNode(), new GetMapInfoNode()).addNodes(new GetUserOrderNode())//设置超时时间.setExecTimeout(1000L)//确保节点之间没出现循环依赖,.ensure();Param initParam = Param.builder().token("asdasdasdasd").lat("18.444369").lng("-97.3794933").build();Resp resp = Resp.builder().lat(initParam.lat).lng(initParam.lng).build();builder.buildResp(initParam, resp);System.out.println(JSONUtil.toJson(resp));}}@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
class Param{String token;String lat;String lng;
}@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
class Resp{String cityId;String userName;Long userId;String lat;String lng;List<OrderDetail> orderList;@Data@Builder@NoArgsConstructor@AllArgsConstructorpublic static class OrderDetail{Long orderId;Long orderCreateTime;}
}class GetUserInfoNode implements ProcessNode<Param, Resp> {@Overridepublic Object process(Param param, Resp resp, LoadContext context) {String token = param.getToken();//mock解析token操作//直接给最终要返回的结果设置值resp.setUserId(20L);resp.setUserName("corki");//builder模式下一般用不到节点的返回结果,可以返回nullreturn null;}@Overridepublic String name() {return "getUserInfo";}@Overridepublic List<String> dependencies() {return Collections.emptyList();}
}class GetMapInfoNode implements ProcessNode<Param, Resp> {@Overridepublic Object process(Param param, Resp resp, LoadContext context) {String lat = param.getLat();String lng = param.getLng();//mock解析经纬度...resp.setCityId("211");return null;}@Overridepublic String name() {return "getMapInfo";}@Overridepublic List<String> dependencies() {return Collections.emptyList();}
}class GetUserOrderNode implements ProcessNode<Param, Resp> {@Overridepublic Object process(Param param, Resp resp, LoadContext context) {//mock获取用户的所有订单List<Resp.OrderDetail> orderDetails = new ArrayList<>();for(int i = 0; i < 4; i ++){orderDetails.add(Resp.OrderDetail.builder().orderId(i + 1000L).build());}resp.setOrderList(orderDetails);//异步获取各订单的详情,不堵塞当前节点,但是需全部完成后主流程才能完成for(Resp.OrderDetail orderDetail : orderDetails){//调用context的submitTask的方法用于提交任务,true标识堵塞主流程context.submitTask(() -> {orderDetail.setOrderCreateTime(1000000 + orderDetail.getOrderId());}, true);}return null;}@Overridepublic String name() {return "getUserOrder";}@Overridepublic List<String> dependencies() {return ListUtil.of("getUserInfo");}
}最后
至此已经完成了框架的介绍,如果有其他问题可以联系1543493541@qq.com或者oraen1998@gmail.com









全流程)









