当访问XX网站时返回 418 状态码时,说明服务器识别到了爬虫行为并拒绝了请求。这是网站的反爬机制在起作用,我们可以通过模拟浏览器行为来绕过基础反爬。
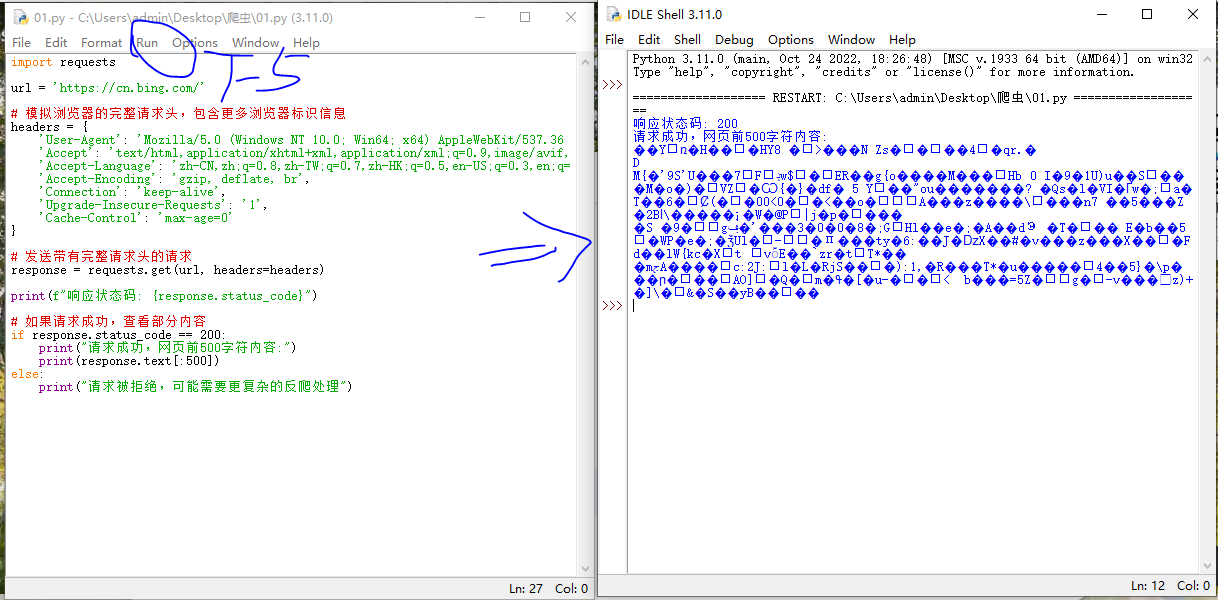
import requestsurl = 'https://cn.bing.com/'# 模拟浏览器的完整请求头,包含更多浏览器标识信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Upgrade-Insecure-Requests': '1','Cache-Control': 'max-age=0'
}# 发送带有完整请求头的请求
response = requests.get(url, headers=headers)print(f"响应状态码: {response.status_code}")# 如果请求成功,查看部分内容
if response.status_code == 200:print("请求成功,网页前500字符内容:")print(response.text[:500])
else:print("请求被拒绝,可能需要更复杂的反爬处理")
安全管理(3)-数据库审计)
—— 数组(超绝详细总结))

通讯--http多文件下载)









)





