1. 引言
图像模糊是数字图像处理中的常见问题,其成因包括相机抖动、物体运动、聚焦不良等。传统方法如维纳滤波、Lucy-Richardson 算法等依赖于模糊核估计和逆滤波,在复杂场景下性能有限。生成对抗网络(Generative Adversarial Networks, GAN)的出现为模糊图像恢复提供了全新的解决方案。GAN 通过生成器与判别器的对抗训练,能够自动学习从模糊图像到清晰图像的非线性映射,在视觉效果和细节恢复上表现优异。本文将深入探讨 GAN 在模糊图像恢复中的具体原理、网络架构、训练策略及应用实践。
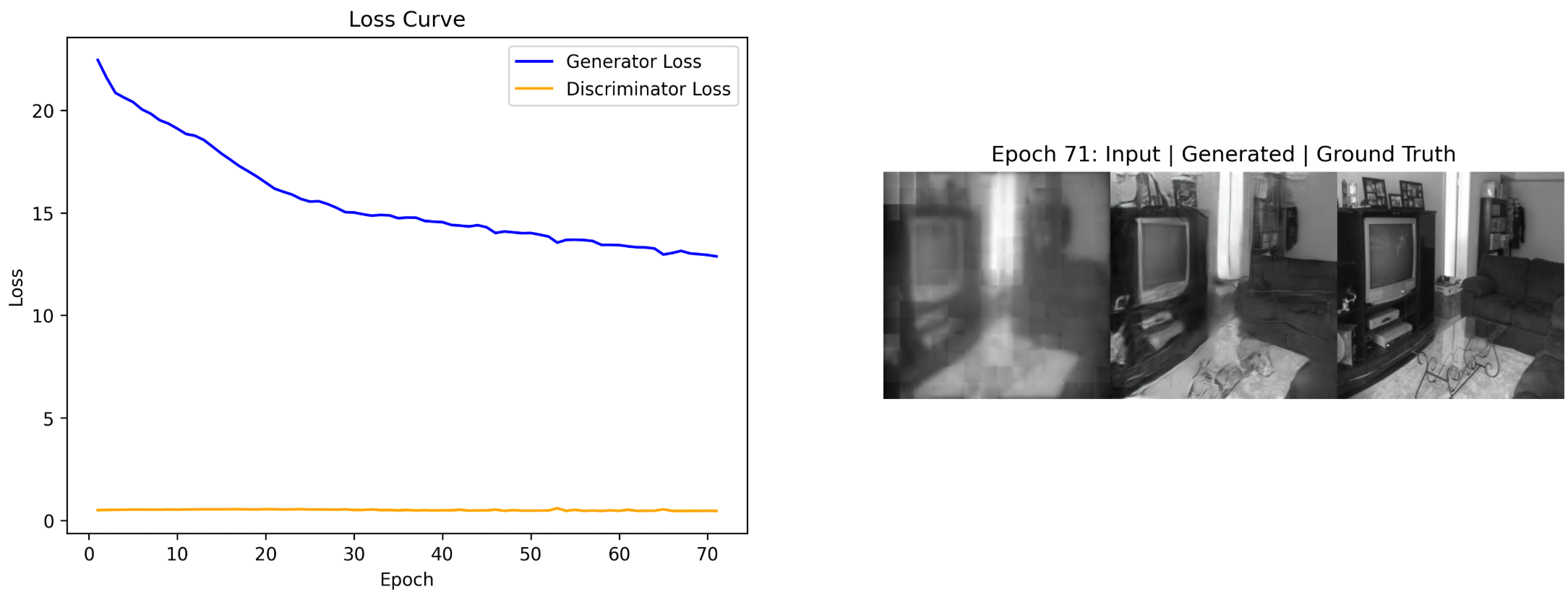
2. GAN 的基本原理与结构
2.1 GAN 的核心思想
GAN 由生成器(Generator)和判别器(Discriminator)组成,二者通过对抗博弈优化。生成器的目标是将随机噪声或模糊图像映射为逼真的清晰图像,而判别器则区分生成图像与真实清晰图像。训练过程中,生成器试图欺骗判别器,而判别器则努力提高识别能力,最终达到纳什均衡状态,生成器能够生成高质量的图像。
2.2 生成器架构设计
生成器通常采用编码器 - 解码器结构,结合卷积和反卷积操作。例如,DeblurGAN 的生成器包含 3 个卷积块、9 个残差块和 2 个转置卷积块,通过全局残差连接加速训练并提升泛化能力。残差块(Residual Block)通过跳跃连接保留输入特征,避免梯度消失,适用于处理深层网络。转置卷积层用于上采样,恢复图像分辨率。
2.3 判别器架构设计
判别器通常采用 PatchGAN 结构,对图像局部区域进行判别,而非全局判断。例如,DeblurGAN 的判别器使用多层卷积提取特征,输出每个图像块的真伪概率,最终取平均值作为全局判断。这种设计有助于捕捉局部细节,提升判别精度。
3. 模糊图像恢复的挑战与解决方案
3.1 模糊类型与数据生成
模糊类型包括运动模糊、高斯模糊等。运动模糊的建模可通过随机轨迹生成模糊核,例如 DeblurGAN 采用马尔可夫过程生成复杂轨迹,模拟真实运动模糊。数据集方面,GOPRO 数据集通过多帧平均生成模糊图像,而 HIDE 数据集则标注了人类区域,用于前景 - 背景区分的去模糊任务。
3.2 损失函数设计
对抗损失:基于 Wasserstein GAN(WGAN)或 WGAN-GP,使用梯度惩罚项稳定训练,避免模式崩溃。公式为:
其中,
为梯度惩罚系数,
为插值样本。
内容损失:采用预训练的 VGG 网络提取特征,计算生成图像与真实图像的 L2 距离(感知损失),公式为:
其中,
表示 VGG 网络第 i 个块的第 j 层特征。
结构损失:结合 L1 或 L2 损失,确保像素级相似性,公式为:
或:
边缘与纹理损失:通过边缘检测算子(如 Sobel)提取边缘信息,或使用局部二进制模式(LBP)评估纹理一致性,增强细节恢复。
4. 训练策略与技巧
4.1 优化器与学习率调整
常用 Adam 优化器,学习率初始化为\(10^{-4}\),采用线性衰减策略,前 150 个 epoch 保持不变,后 150 个 epoch 线性降至 0。Batch Size 通常设为 1 或 4,以适应内存限制。
4.2 正则化与稳定性增强
谱归一化(Spectral Normalization):对判别器权重矩阵进行归一化,限制其 Lipschitz 常数,防止梯度爆炸。通过幂迭代法近似计算矩阵的谱范数,公式为:
其中,
为矩阵 W 的谱范数。
小批量判别(Minibatch Discrimination):引入小批量统计信息,避免模式崩溃。计算每个样本与其他样本的特征差异,生成多样性更高的图像。
4.3 数据增强与预处理
对输入模糊图像进行随机裁剪、旋转、缩放等操作,增加数据多样性。同时,对图像进行归一化(如标准化至 [-1, 1]),加速训练收敛。
5. 典型模型与应用
5.1 DeblurGAN 系列
- DeblurGAN:采用条件 GAN(cGAN)架构,生成器包含残差块和转置卷积层,判别器使用 PatchGAN。结合 WGAN-GP 和感知损失,在 GoPro 数据集上取得优异表现。
- DeblurGAN-v2:引入特征金字塔网络(FPN),结合多尺度特征融合,支持轻量骨干网络(如 MobileNet)实现实时去模糊。判别器采用 relativistic loss,提升训练稳定性。
5.2 CycleGAN 在非配对数据中的应用
CycleGAN 通过循环一致性损失实现非配对数据的转换,适用于无清晰 - 模糊图像对的场景。例如,在透射文本恢复中,CycleGAN 结合注意力机制,非均匀处理不同文本特征,有效去除背面信息。
5.3 医疗影像去模糊
在 CT 重建中,GAN 可将 5mm 层厚扫描数据提升至 0.5mm 精度,结合感知损失和结构损失,减少伪影并保留解剖结构细节。
6. 评估指标与实验分析
6.1 定量指标
峰值信噪比(PSNR):衡量像素级差异,公式为:
其中,
为像素最大值(通常为 255),MSE 为均方误差。
结构相似性指数(SSIM):评估图像结构相似性,范围在 [-1, 1],值越接近 1 表示质量越好。
LPIPS(Learned Perceptual Image Patch Similarity):基于预训练网络的特征距离,更接近人类感知。
6.2 定性分析
通过视觉对比展示恢复结果,观察边缘清晰度、纹理细节和伪影情况。例如,DeblurGAN 在 GoPro 数据集上的恢复结果在 SSIM 和视觉效果上均优于传统方法。
7. 挑战与未来方向
7.1 现有挑战
- 模糊核未知性:盲去模糊需同时估计模糊核和清晰图像,增加模型复杂度。
- 噪声干扰:低信噪比图像中,GAN 易生成伪影。
- 计算资源需求:深层网络和高分辨率图像恢复需要大量 GPU 内存和计算时间。
7.2 未来方向
- 自监督学习:利用单幅模糊图像的先验信息(如边缘、纹理)进行无监督训练。
- 多模态融合:结合光学信息(如深度图、光谱数据)提升恢复精度。
- 轻量化模型:设计高效网络结构(如 MobileNet、Transformer),实现实时处理。
- 伦理与法律:在文物修复、医疗影像等领域,需确保恢复结果的真实性和合规性。
8. 结论
GAN 通过对抗训练和多损失函数的结合,在模糊图像恢复中展现了强大的能力。从基础原理到具体实现,从网络架构到训练策略,GAN 为图像恢复提供了端到端的解决方案。未来,随着技术的不断进步,GAN 有望在更多领域实现高精度、高效率的模糊图像恢复,推动数字图像处理技术的发展。
代码示例(DeblurGAN 生成器部分)
import torch
import torch.nn as nnclass ResidualBlock(nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.in1 = nn.InstanceNorm2d(channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.in2 = nn.InstanceNorm2d(channels)def forward(self, x):residual = xout = self.conv1(x)out = self.in1(out)out = self.relu(out)out = self.conv2(out)out = self.in2(out)out += residualreturn outclass Generator(nn.Module):def __init__(self, input_channels=3, output_channels=3):super(Generator, self).__init__()self.conv1 = nn.Conv2d(input_channels, 64, kernel_size=7, padding=3)self.in1 = nn.InstanceNorm2d(64)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)self.in2 = nn.InstanceNorm2d(128)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)self.in3 = nn.InstanceNorm2d(256)self.res_blocks = nn.Sequential(ResidualBlock(256),ResidualBlock(256),ResidualBlock(256),ResidualBlock(256),ResidualBlock(256),ResidualBlock(256),ResidualBlock(256),ResidualBlock(256),ResidualBlock(256))self.deconv1 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1)self.in4 = nn.InstanceNorm2d(128)self.deconv2 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1)self.in5 = nn.InstanceNorm2d(64)self.conv_out = nn.Conv2d(64, output_channels, kernel_size=7, padding=3)self.tanh = nn.Tanh()def forward(self, x):x = self.conv1(x)x = self.in1(x)x = self.relu(x)x = self.conv2(x)x = self.in2(x)x = self.relu(x)x = self.conv3(x)x = self.in3(x)x = self.relu(x)x = self.res_blocks(x)x = self.deconv1(x)x = self.in4(x)x = self.relu(x)x = self.deconv2(x)x = self.in5(x)x = self.relu(x)x = self.conv_out(x)x = self.tanh(x)return x以下论文是去模糊方面的,可以参考下:
[1] Goodfellow I, et al. Generative adversarial nets. NIPS 2014.
[2] Kupyn O, et al. DeblurGAN: Blind motion deblurring using conditional adversarial networks. CVPR 2018.
[3] Ledig C, et al. Photo-realistic single image super-resolution using a generative adversarial network. CVPR 2017.
[4] Miyato T, et al. Spectral normalization for generative adversarial networks. ICLR 2018.
[5] Zhu J Y, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks. ICCV 2017.
[6] 基于生成对抗网络的图像去模糊技术研究与应用. CSDN 博客,2025.
[7] 深度学习去运动模糊 ----《DeblurGAN》. CSDN 博客,2025.
[8] 谱归一化在 GAN 中的运用. CSDN 博客,2024.
[9] 基于 CycleGAN 的透射文本图像复原。哈尔滨工业大学,2025.
[10] 2024 最全 python 图像修复指南. CSDN 博客,2025.



![【URP】[法线贴图]为什么主要是蓝色的?](http://pic.xiahunao.cn/【URP】[法线贴图]为什么主要是蓝色的?)


)


)









