在近期的顶会顶刊中,迁移学习与多模态融合的热度居高不下,相关成果频出,部分模型在特定任务里性能提升极为显著。
登上顶刊 TPAMI 2025 的某篇研究,借助语言引导的关系迁移,大幅提升了少样本类增量学习中模型的泛化能力,此外,不少 CCF - A 类会议也有众多佳作涌现。但需要留意,当下这一领域单纯的模型结构调整已较难突破,若有医疗、遥感等特色数据,建议从 “跨模态知识迁移与任务定制优化” 方向着手。
本文精心整理了 3 篇前沿论文,旨在助力大家洞悉前沿动态、把握研究思路,如果有论文 er 感兴趣,强烈建议研读这些成果。满满干货,关注收藏不迷路~
Bidirectional Cross-Modal Knowledge Exploration for Video Recognition with Pre-trained Vision-Language Models
方法:这篇文章旨在通过预训练视觉 - 语言模型(VLMs)挖掘双向跨模态知识来提升视频识别性能,解决了现有方法仅单向利用 VLMs 知识、未充分发挥其跨域桥梁价值的局限。
创新点:
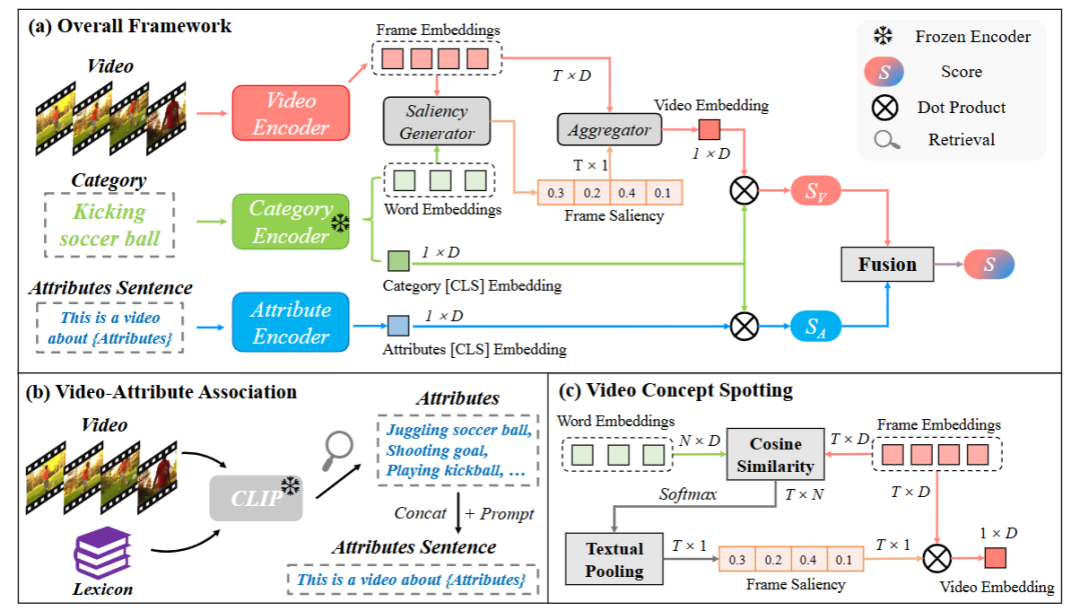
提出 BIKE 框架,首次从预训练视觉 - 语言模型中探索双向跨模态知识以增强视频识别。
在视频到文本方向,设计视频属性关联机制,生成辅助属性用于补充视频识别。
在文本到视频方向,提出视频概念定位机制,生成类别相关的时间显著性以优化视频表征。
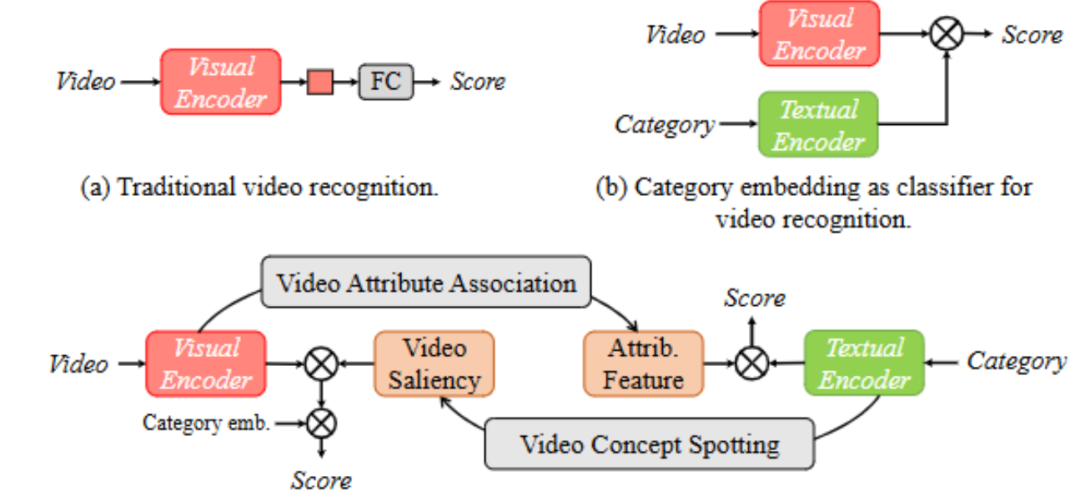
总结:该方法构建了包含属性分支和视频分支的 BIKE 框架,属性分支通过视频属性关联机制从预定义词汇库中检索与视频相关的短语作为属性,形成属性句子并编码,与类别嵌入计算相似度以辅助识别;视频分支利用视频概念定位机制,通过帧与类别词的相似度计算时间显著性,以此聚合帧特征得到增强的视频表征;最终融合两个分支的相似度分数,实现更优的视频识别效果。
HEALNet: Multimodal Fusion for Heterogeneous Biomedical Data
方法:这篇文章提出 HEALNet,一种灵活的多模态融合架构,旨在解决现有方法难以同时保留异质生物医学数据的模态结构、捕获跨模态交互、处理缺失模态及缺乏可解释性的问题。
创新点:
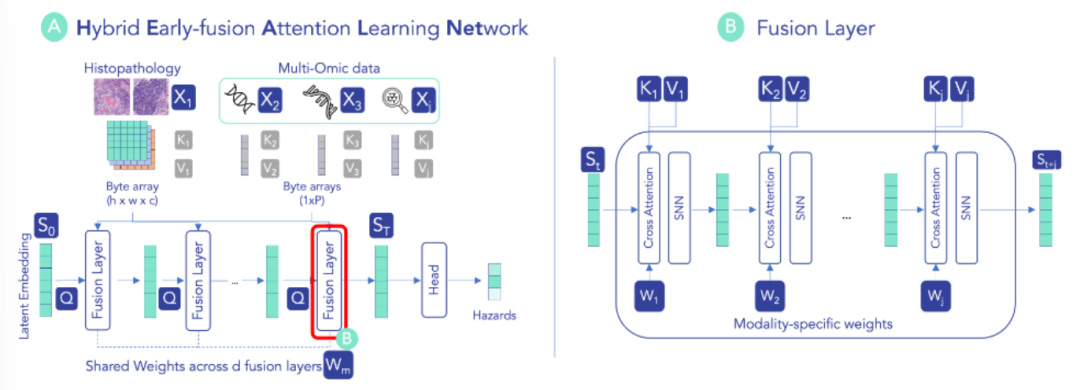
设计混合早期融合架构,通过共享潜在空间和模态特定参数,在迭代注意力过程中同时保留模态结构信息与跨模态交互。
无需额外噪声处理即可有效应对缺失模态,推理时可直接跳过缺失模态的更新步骤,保持性能稳定。
基于原始数据学习,通过模态特定注意力权重实现模型可解释性,无需依赖额外解释方法。
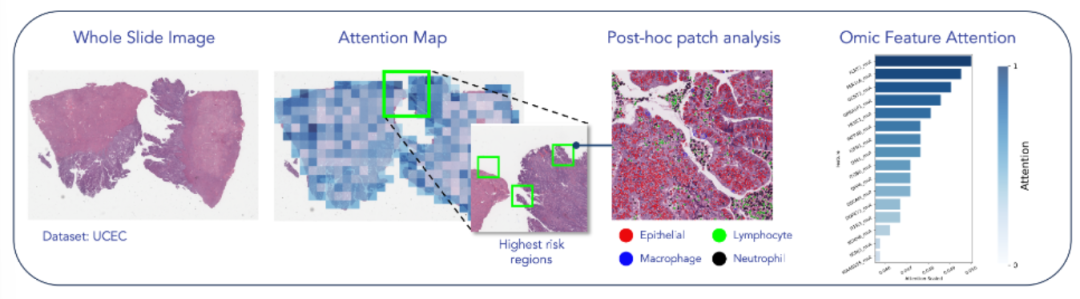
总结:HEALNet 初始化共享潜在嵌入,通过多个融合层迭代更新,每层利用模态特定的查询、键、值权重,将各模态信息整合到共享空间以捕获跨模态交互。对于表格、图像等不同模态,采用对应的交叉注意力机制计算权重,并结合自归一化网络层,将模态结构信息编码到共享嵌入中。最终利用共享潜在嵌入的全连接层生成预测,且在缺失模态时可跳过对应更新步骤,同时通过注意力权重支持模型 inspection。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,获取顶会顶刊前沿资讯~
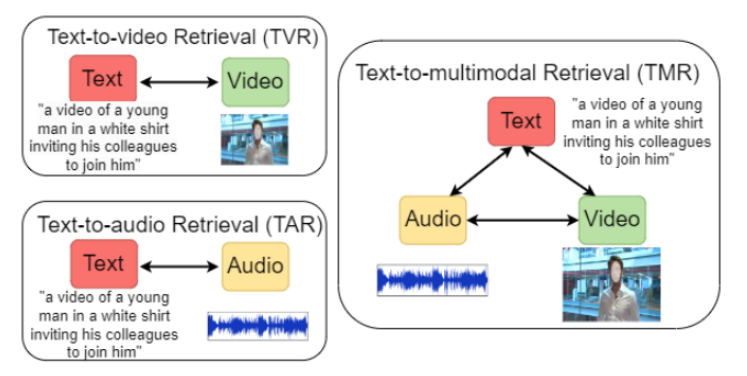
Text-to-Multimodal Retrieval with Bimodal Input Fusion in Shared Cross-Modal Transformer
方法:这篇文章提出一种基于共享跨模态 Transformer 的双向输入融合架构,旨在解决现有文本到多模态检索中模态融合扩展性差、跨模态交互捕捉不足的问题,以提升文本查询对视频(含音频)的检索效果。
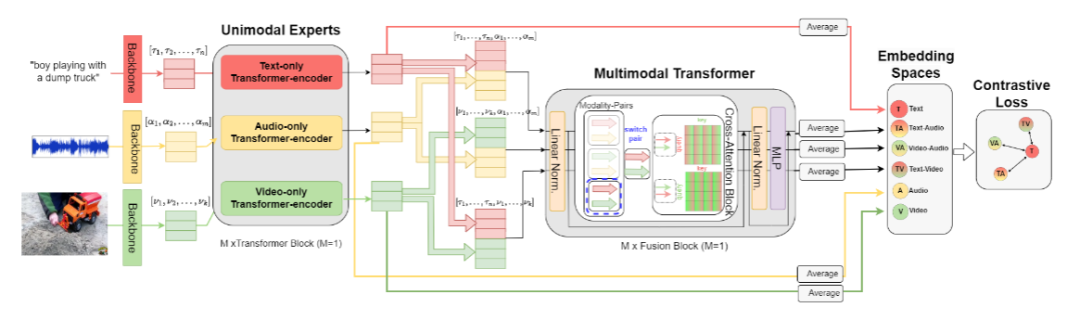
创新点:
设计分层架构,先通过单模态 Transformer 培养模态专属专家,再用共享跨注意力融合 Transformer 构建模态无关的多模态空间,可灵活扩展至更多模态。
针对文本查询的多模态检索任务,提出通过微调损失变体(特定对比损失组合)提升性能,增强文本与跨模态表示的互信息。
证实音频 - 视频融合对文本检索的增强作用,并分析文本查询长度对检索效果的影响,为优化基准提供依据。
总结:该方法首先利用 CLIP 骨干提取文本和视频特征、可训练 CNN 提取音频特征,经线性投影和归一化后,由单模态 Transformer 生成各模态的增强表示。接着,将文本 - 音频、文本 - 视频、视频 - 音频等模态对输入共享跨注意力块,通过双向交叉注意力计算融合表示,并投影至共享空间进行元素级相加。最后,采用由文本与各跨模态表示组成的特定对比损失组合,引导模型学习 discriminative 表示,实现更精准的文本到多模态检索。
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~


 — Swift解法 + 可运行Demo)

![[GraphRAG]完全自动化处理任何文档为向量知识图谱:AbutionGraph如何让知识自动“活”起来?](http://pic.xiahunao.cn/[GraphRAG]完全自动化处理任何文档为向量知识图谱:AbutionGraph如何让知识自动“活”起来?)


:计数排序,排序算法复杂度对比和稳定性分析)

API)









