note
文章目录
- note
- 一、GLM-4.5模型
- 二、Slime RL强化学习训练架构
- Reference
一、GLM-4.5模型
大模型进展,GLM-4.5技术报告,https://arxiv.org/pdf/2508.06471,https://github.com/zai-org/GLM-4.5,包括GLM-4.5(355B总参数,32B激活参数)和精简版GLM-4.5-Air(106B参数),均采用混合专家(MoE)架构。
分开来看,训练上,包括三阶段。预训练阶段,数据规模:23Ttokens,涵盖网页、社交媒体、书籍、代码等,分两阶段训练,第二阶段重点提升代码、数学和科学领域数据占比;
中期训练阶段,增强推理和智能体能力,序列长度从4K扩展至128K。包含仓库级代码训练、合成推理数据训练、长上下文与智能体训练。
后期训练阶段,采用两阶段难度课程学习,先训练中等难度数据,再切换至极难数据(确保有正确答案),解决奖励信号不足问题;同时直接在64K长输出上进行单阶段RL,避免多阶段训练导致的能力退化;
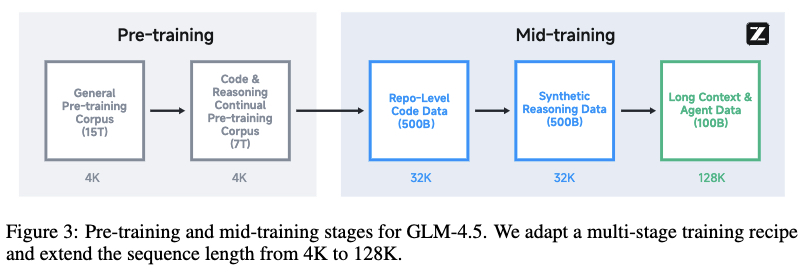
创新点方面,减少模型宽度(隐藏维度)、增加深度(层数)以提升推理能力,采用分组查询注意力(GQA)和QK-Norm稳定训练。
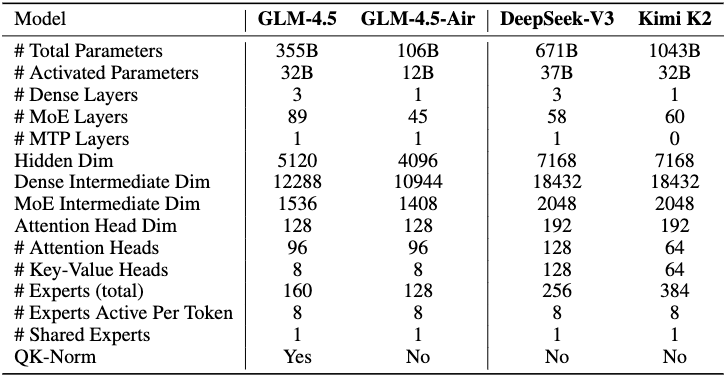
具体的,通过减少隐藏维度(5120)和增加层数(89个MoE层)提升推理能力,而DeepSeek-V3和KimiK2侧重更大的隐藏维度(7168);此外,GLM-4.5引入QK-Norm稳定注意力计算,且包含1个MTP层支持推测解码,而KimiK2无MTP层。
二、Slime RL强化学习训练架构
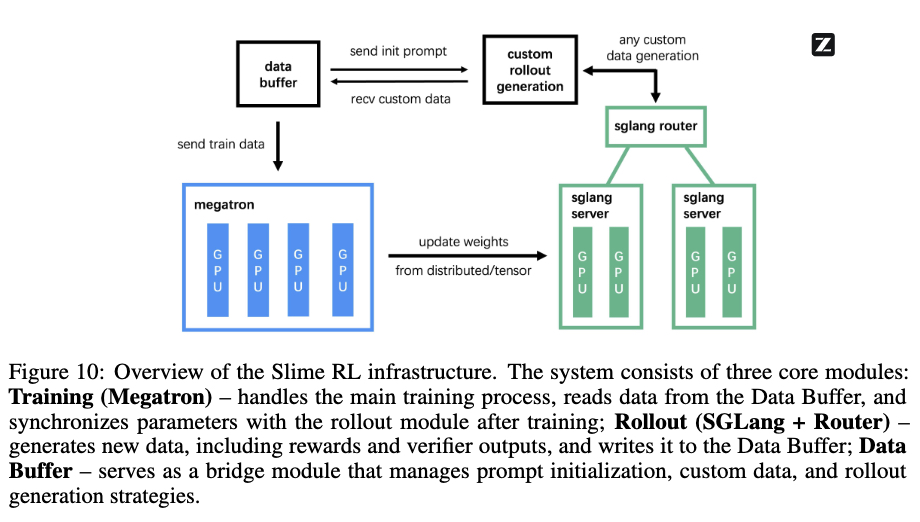
1、核心设计:三模块解耦(分工明确):训练车间(Megatron):专注“学习”,用 GPU 全力计算梯度更新模型参数,就像工厂里埋头干活的工人。
2、数据车间(SGLang + Router):负责“模拟环境”,比如让模型练习网页搜索或写代码,生成训练需要的“经验数据”,类似工厂的原料生产线。
3、中央仓库(Data Buffer):管理数据流转,存放下游的“经验数据”和上游的“训练任务”,相当于智能调度中心,避免生产线堵塞。
Reference
[1] https://github.com/zai-org/GLM-4.5/tree/main
[2] https://www.modelscope.cn/models/ZhipuAI/GLM-4.5/files












 一 归一化)

 egui (0.32.1) 学习笔记(逐行注释)(十八) 使用表格)


)

