1、什么是模型IO
模型 I/O(Model I/O) 是 LangChain 框架中最核心的模块之一,负责处理与语言模型(LLM)交互的输入构建、模型调用和输出解析全流程。它主要分为三个模块:Prompts(输入构建)、Language Models(模型调用)、Output Parsers(输出解析)

2、提示词模板
提示词可以被视为向大语言模型提出的请求,它们表明了使用者希望模型给出何种反应。提示词的质量直接影响模型的回答质量,决定了模型能否成功完成更复杂的任务。
在 LangChain 框架中, 提示词是由 "提示词模板" (PromptTemplate ) 这个包装器对象生成的。每一个 PromptTemplate 类的实例都定义了一种特定类型的提示词格式 和 生成规则。 在 LangChain 中, 要想构造提示词, 就必须学会使用这个包装器对象。
提示词的模板通常包含(不限于):明确的指令、用户输入、少量实例,如下图:
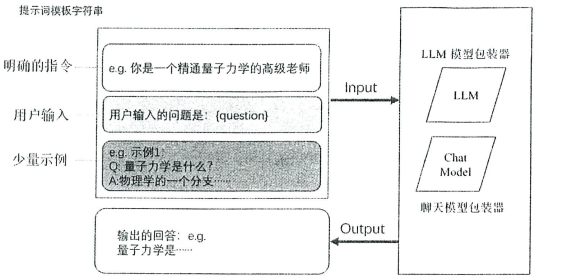
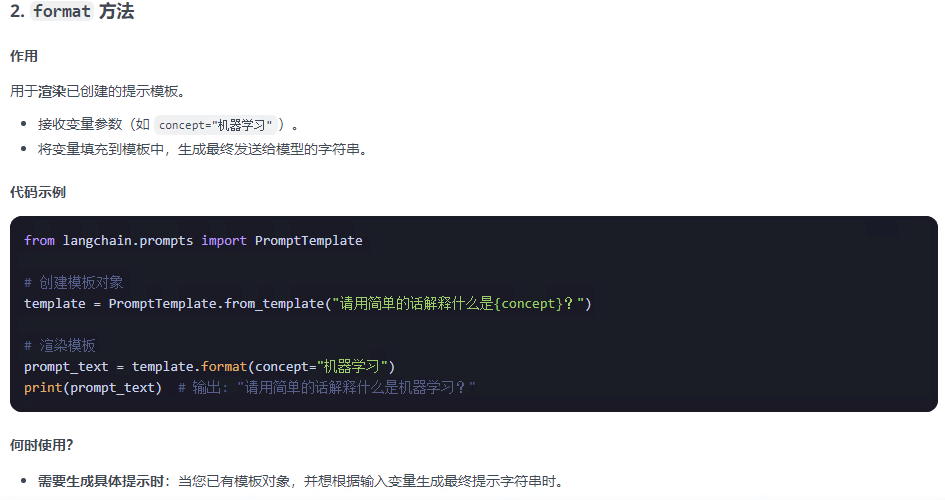
2.1 提示词模板提供了两种方法:from_format和format 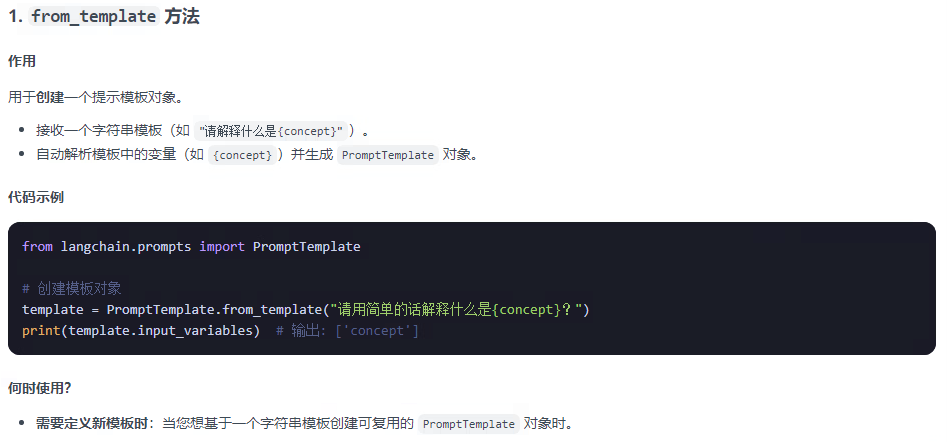

from_format是创建一个模板,模板中可能有需要填充的参数
format的是将模板格式化,填充需要的参数
from langchain.prompts import PromptTemplate# 创建一个提示词模板
template = """
你是一个有用的助手。
用户的名字是 {name}。
用户的问题是: {question}
请用详细的回答这个问题。
"""
print("\n=== formatted_prompt1 ===")
prompt_template = PromptTemplate.from_template(template)
formatted_prompt1 = prompt_template.format(name="张三", question="什么是人工智能?")
print(formatted_prompt1)print("\n=== formatted_prompt2 ===")
formatted_prompt2 = prompt_template.format(name="李四", question="机器学习和深度学习有什么区别?")
print(formatted_prompt2)# 展示另一种使用from_template的方式
print("\n=== 直接使用from_template并传入参数 ===")
prompt_template3 = PromptTemplate.from_template("""
你是一个有用的助手。
用户的名字是 {name}。
用户的问题是: {question}
请用详细的回答这个问题。
""")# 直接在from_template中定义模板并格式化
formatted_prompt3 = prompt_template3.format(name="王五", question="Python中类和对象的概念是什么?")
print(formatted_prompt3)# 展示PromptTemplate的其他常用属性和方法
print("\n=== PromptTemplate属性和方法 ===")
print(f"输入变量: {prompt_template.input_variables}")
print(f"模板字符串: {prompt_template.template}")2.2 langchain定义的内部模板
langchain定义了一些内置的提示词模板,可以通过入参使用。定义在langchain.chains.api.prompt,执行其内容如下:
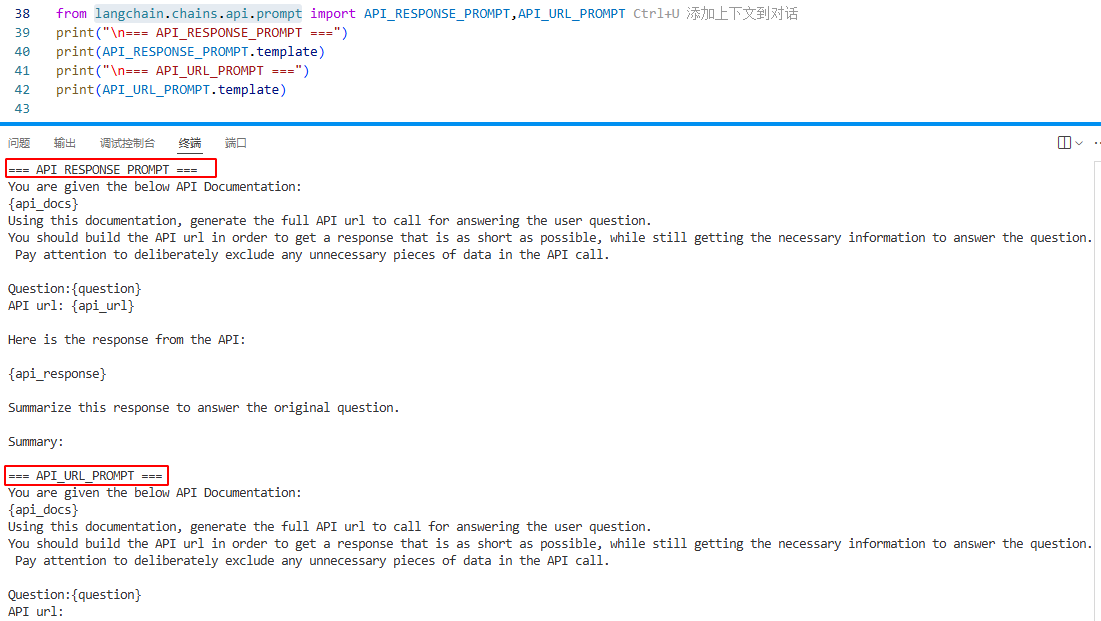
2.3 提示词模板包装器
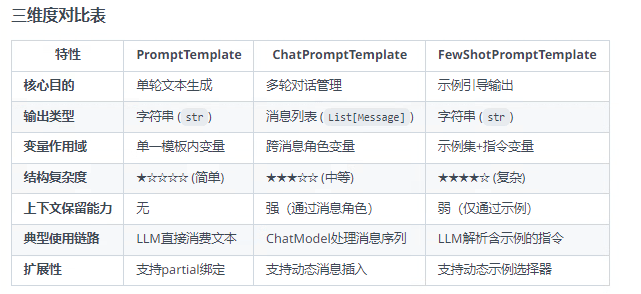
提示词模板包装器分为两类:PromotTemplate包装器 和 ChatPromptTemplate包装器两类,FewShotPromptTemplate是PromotTemplate的扩展,以下总结整理这三种包装器:
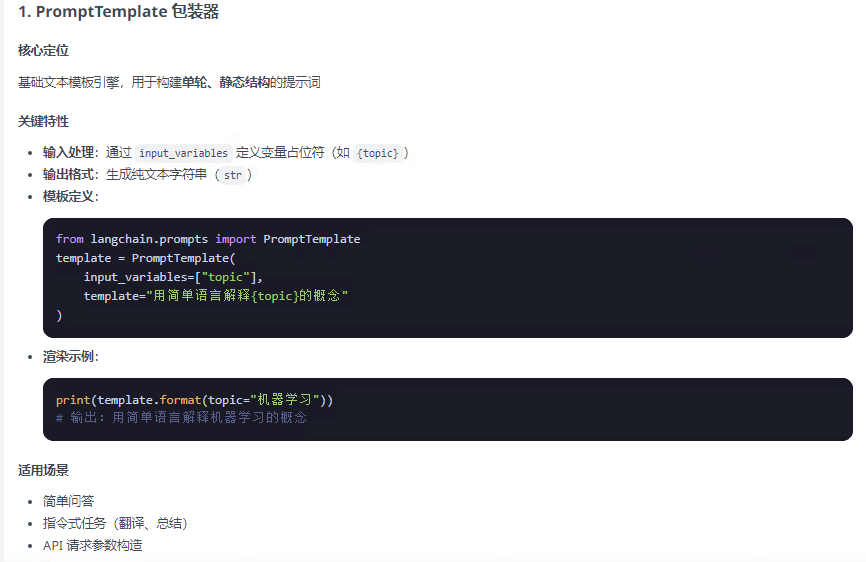
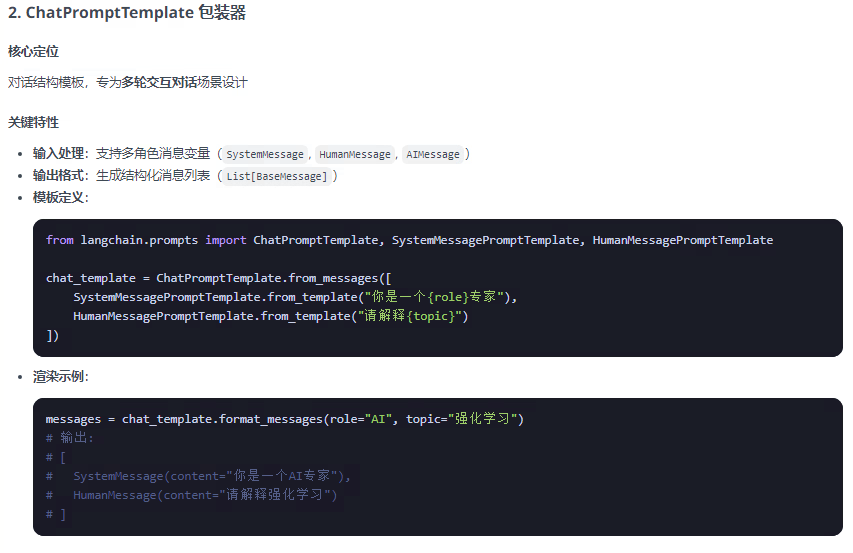

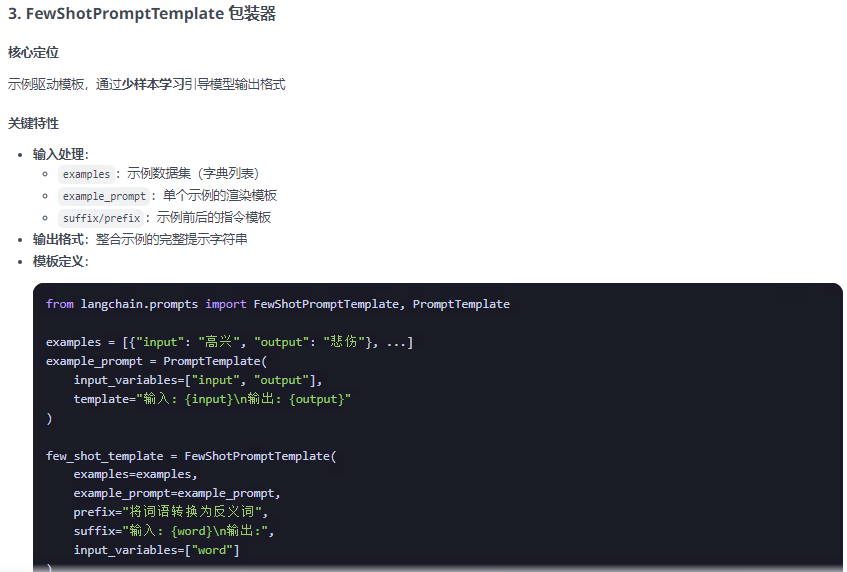
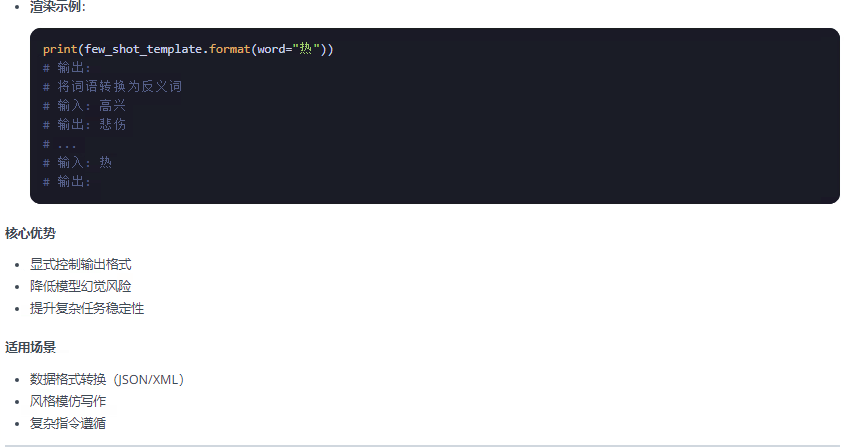
from langchain.prompts import PromptTemplate, ChatPromptTemplate, FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector# 1. PromptTemplate - 基础提示模板
print("=== 1. PromptTemplate - 基础提示模板 ===")
template = """
你是一个{role}。
请回答以下问题: {question}
"""prompt_template = PromptTemplate.from_template(template)
formatted_prompt = prompt_template.format(role="AI助手", question="什么是机器学习?")
print(formatted_prompt)# 2. ChatPromptTemplate - 聊天提示模板
print("\n=== 2. ChatPromptTemplate - 聊天提示模板 ===")
chat_template = ChatPromptTemplate.from_messages([("system", "你是一个{role},你的名字是{name}"),("human", "你好,{greeting}"),("ai", "你好!很高兴见到你。"),("human", "{question}")
])chat_prompt = chat_template.format_messages(role="专业的技术顾问",name="TechExpert",greeting="我想了解一些技术知识",question="请解释一下深度学习的基本概念"
)for message in chat_prompt:print(f"{message.type}: {message.content}")# 3. FewShotPromptTemplate - 少样本提示模板
print("\n=== 3. FewShotPromptTemplate - 少样本提示模板 ===")# 定义示例
examples = [{"input": "什么是人工智能?","output": "人工智能是计算机科学的一个分支,旨在创建能够执行通常需要人类智能的任务的机器。"},{"input": "机器学习是什么?","output": "机器学习是人工智能的一个子集,它使计算机能够从数据中学习并做出决策或预测,而无需明确编程。"}
]# 创建基础模板
example_prompt = PromptTemplate.from_template("问题: {input}\n答案: {output}"
)# 创建FewShotPromptTemplate
few_shot_prompt = FewShotPromptTemplate(examples=examples,example_prompt=example_prompt,suffix="问题: {input}\n答案: ",input_variables=["input"]
)formatted_few_shot = few_shot_prompt.format(input="深度学习和机器学习有什么区别?"
)
print(formatted_few_shot)# 4. 带有示例选择器的FewShotPromptTemplate
print("\n=== 4. 带有示例选择器的FewShotPromptTemplate ===")# 添加更多示例
more_examples = examples + [{"input": "什么是神经网络?","output": "神经网络是一种模拟人脑神经元结构的计算模型,由相互连接的节点(神经元)组成。"},{"input": "什么是自然语言处理?","output": "自然语言处理是人工智能的一个领域,专注于计算机与人类语言之间的交互,包括理解和生成文本。"}
]# 使用LengthBasedExampleSelector根据输入长度选择示例
example_selector = LengthBasedExampleSelector(examples=more_examples,example_prompt=example_prompt,max_length=50 # 根据输入长度限制示例数量
)few_shot_prompt_with_selector = FewShotPromptTemplate(example_selector=example_selector,example_prompt=example_prompt,suffix="问题: {input}\n答案: ",input_variables=["input"]
)formatted_selector_prompt = few_shot_prompt_with_selector.format(input="请简要解释Transformer模型在NLP中的作用"
)
print(formatted_selector_prompt)
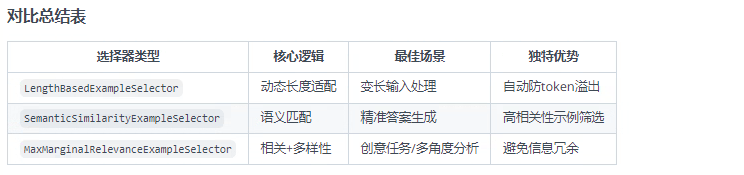
2.4 示例选择器
作用:在少样本学习模板(FewShotPromptTemplate)中智能筛选示例,解决两大关键问题:
上下文窗口限制:避免示例过多导致 token 超限
相关性优化:选择与当前查询最相关的示例
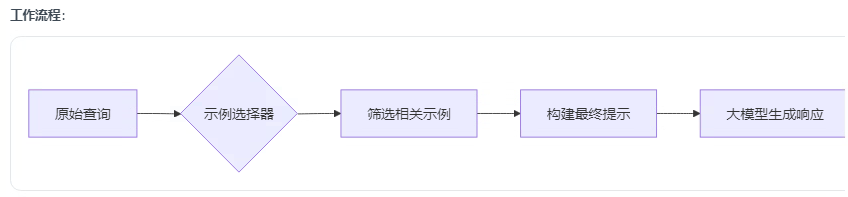
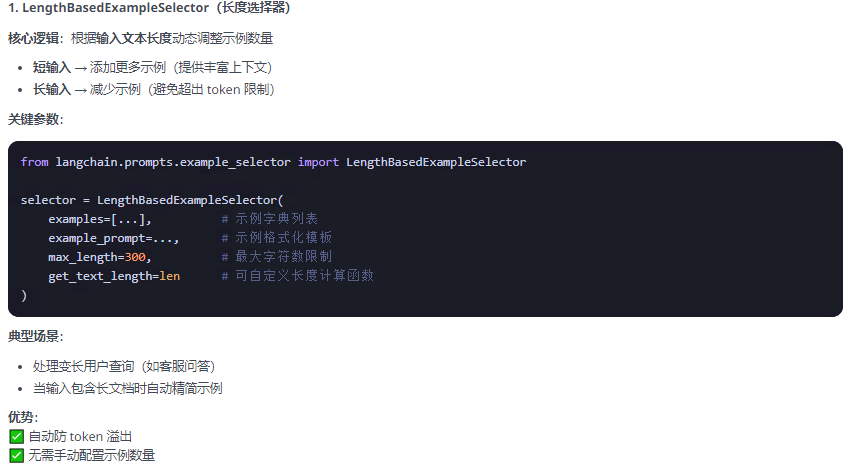
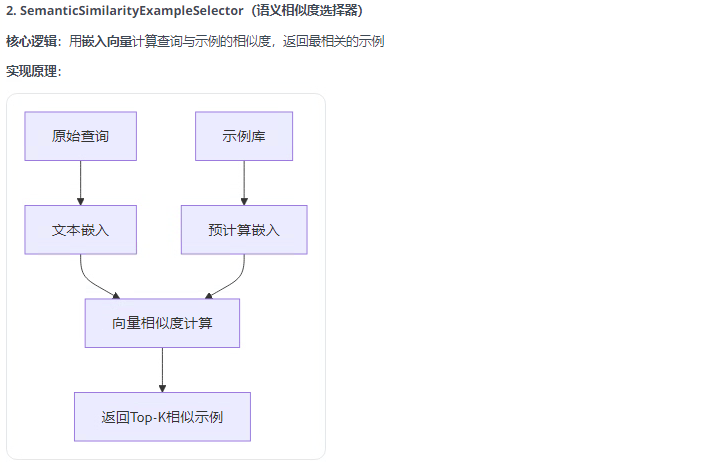
以下列举常用的三个示例选择器,以及demo:
max_length 参数限制的是 最终生成提示词(prompt)的总长度
包含所有元素的完整提示长度:
用户当前输入文本(input)
所有被选中的示例(examples)
提示前缀(prefix,如系统指令)
提示后缀(suffix,如回答格式要求)
计算方式
总长度 = len(prefix) + len(所有示例文本) + len(input) + len(suffix)
import os
from langchain.prompts import PromptTemplate, FewShotPromptTemplate
from langchain.prompts.example_selector import (LengthBasedExampleSelector,SemanticSimilarityExampleSelector,MaxMarginalRelevanceExampleSelector
)
from langchain.vectorstores import FAISS
from langchain_community.embeddings import DashScopeEmbeddings# 设置API密钥
api_key = os.getenv("DASHSCOPE_API_KEY")# 定义示例数据
examples = [{"question": "什么是人工智能?","answer": "人工智能是计算机科学的一个分支,旨在创建能够执行通常需要人类智能的任务的机器。"},{"question": "机器学习是什么?","answer": "机器学习是人工智能的一个子集,它使计算机能够从数据中学习并做出决策或预测,而无需明确编程。"},{"question": "什么是深度学习?","answer": "深度学习是机器学习的一个子集,使用多层神经网络来模拟人脑处理信息的方式。"},{"question": "什么是神经网络?","answer": "神经网络是一种模拟人脑神经元结构的计算模型,由相互连接的节点(神经元)组成。"},{"question": "什么是自然语言处理?","answer": "自然语言处理是人工智能的一个领域,专注于计算机与人类语言之间的交互,包括理解和生成文本。"}
]# 创建基础模板
example_prompt = PromptTemplate.from_template("问题: {question}\n答案: {answer}"
)print("=== 1. LengthBasedExampleSelector - 基于长度的示例选择器 ===")
# LengthBasedExampleSelector根据输入长度选择示例数量
length_selector = LengthBasedExampleSelector(examples=examples,example_prompt=example_prompt,max_length=10 # 根据输入长度限制示例数量
)few_shot_prompt_length = FewShotPromptTemplate(example_selector=length_selector,example_prompt=example_prompt,suffix="问题: {input}\n答案: ",input_variables=["input"]
)# 短输入 - 会选择更多示例
short_input = "AI"
print(f"输入: {short_input}")
print(f"选择的示例:\n{few_shot_prompt_length.format(input=short_input)}")# 长输入 - 会选择较少示例
long_input = "请详细解释人工智能、机器学习和深度学习之间的关系和区别"
print(f"\n输入: {long_input}")
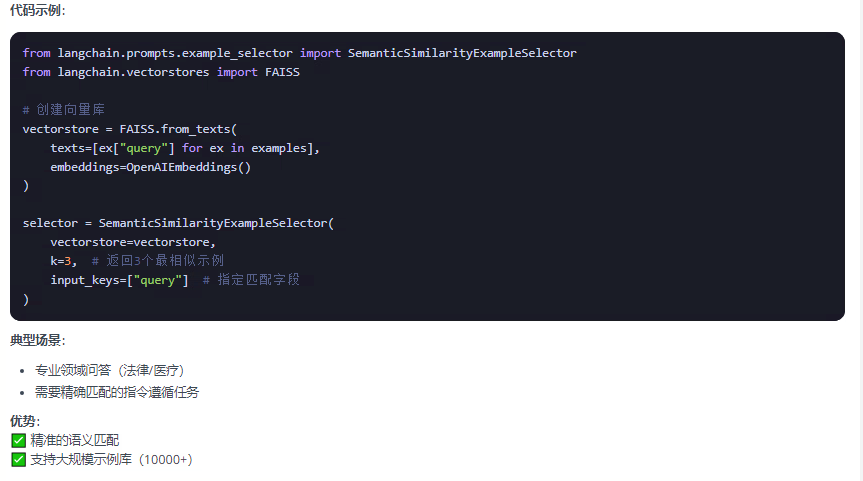
print(f"选择的示例:\n{few_shot_prompt_length.format(input=long_input)}")print("\n=== 2. SemanticSimilarityExampleSelector - 基于语义相似度的示例选择器 ===")
# SemanticSimilarityExampleSelector基于语义相似度选择示例
# 注意:这需要API密钥来创建嵌入模型
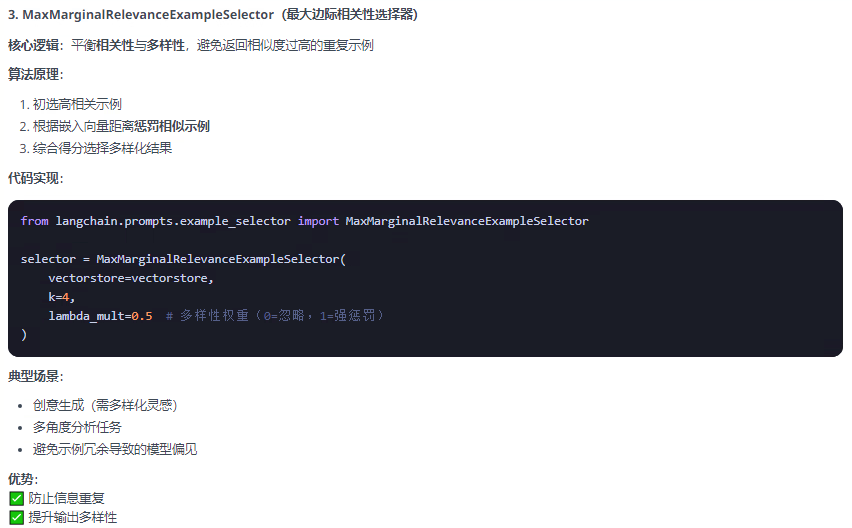
try:embeddings = DashScopeEmbeddings(model="text-embedding-v1",dashscope_api_key=api_key)similarity_selector = SemanticSimilarityExampleSelector.from_examples(examples,embeddings,FAISS,k=2 # 选择2个最相似的示例)few_shot_prompt_similarity = FewShotPromptTemplate(example_selector=similarity_selector,example_prompt=example_prompt,suffix="问题: {input}\n答案: ",input_variables=["input"])# 输入与示例相似的问题similar_input = "什么是机器学习算法?"print(f"输入: {similar_input}")print(f"选择的示例:\n{few_shot_prompt_similarity.format(input=similar_input)}")except Exception as e:print(f"注意:SemanticSimilarityExampleSelector需要有效的API密钥。错误信息: {e}")print("\n=== 3. MaxMarginalRelevanceExampleSelector - 最大边缘相关性示例选择器 ===")
# MaxMarginalRelevanceExampleSelector选择既相似又多样化的示例
try:mmr_selector = MaxMarginalRelevanceExampleSelector.from_examples(examples,embeddings,FAISS,k=3, # 选择3个示例fetch_k=5 # 从5个候选示例中选择3个)few_shot_prompt_mmr = FewShotPromptTemplate(example_selector=mmr_selector,example_prompt=example_prompt,suffix="问题: {input}\n答案: ",input_variables=["input"])# 输入一个综合性问题mmr_input = "请解释AI技术在现代科技中的应用"print(f"输入: {mmr_input}")print(f"选择的示例:\n{few_shot_prompt_mmr.format(input=mmr_input)}")except Exception as e:print(f"注意:MaxMarginalRelevanceExampleSelector需要有效的API密钥。错误信息: {e}")#print("\n=== 4. 三种选择器的对比总结 ===")
comparison = """
1. LengthBasedExampleSelector:- 根据输入长度选择示例数量- 输入越短,选择的示例越多- 输入越长,选择的示例越少- 不需要API密钥或嵌入模型- 适用于需要根据上下文长度调整示例数量的场景2. SemanticSimilarityExampleSelector:- 基于语义相似度选择最相关的示例- 需要嵌入模型和API密钥- 选择与输入最相似的示例- 适用于需要相关示例来指导输出的场景3. MaxMarginalRelevanceExampleSelector:- 选择既相关又多样化的示例- 需要嵌入模型和API密钥- 首先选择最相似的示例,然后增加多样性- 适用于需要平衡相关性和多样性的场景
"""
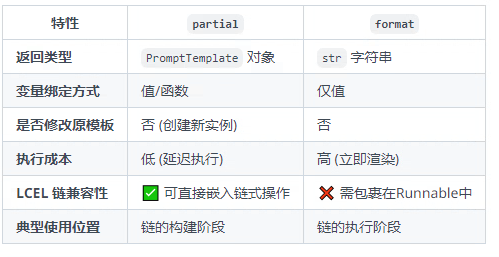
#print(comparison)2.5 partial的使用
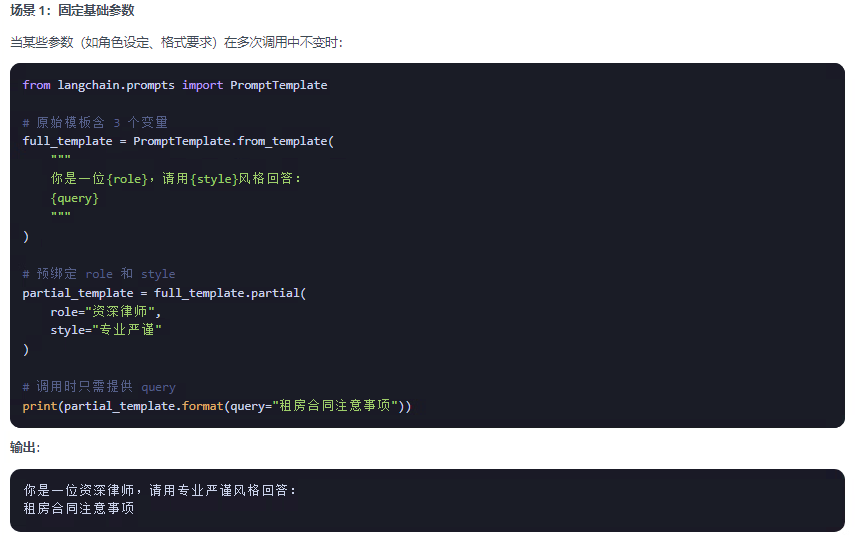
partial 主要用于 提前绑定提示模板变量,实现模板的预配置和复用,是构建高效链(Chain)的关键技术。
解决三大问题:
1、变量预绑定:将部分模板变量提前固定,简化运行时输入
2、模板复用:创建可配置的模板实例,避免重复定义
3、动态适配:结合函数实现运行时动态变量生成
以下列举几个使用场景:
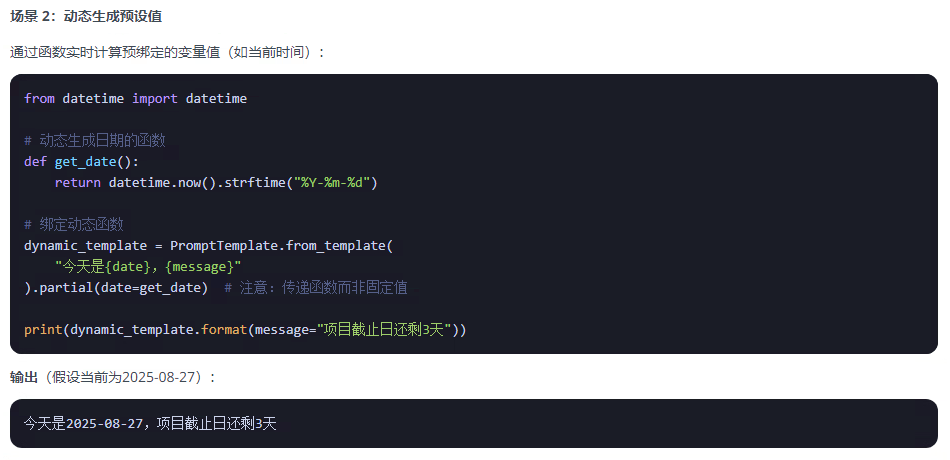
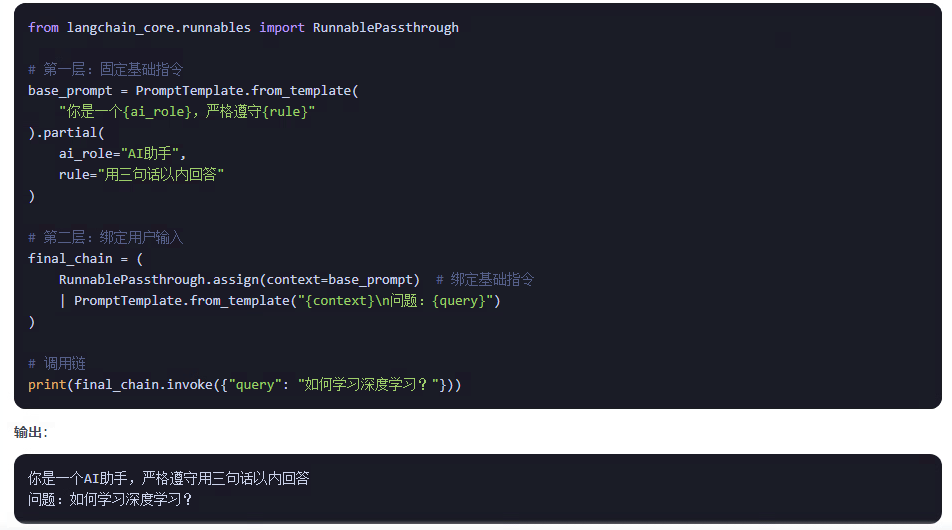
在使用上能感觉出partial和format有一些相似,他们有什么区别呢?
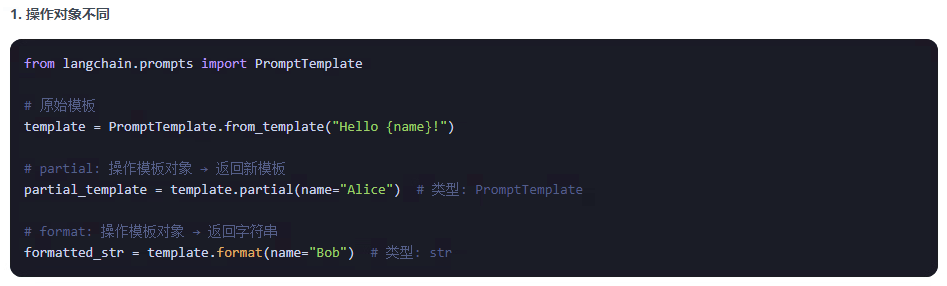
他们的返回值不同
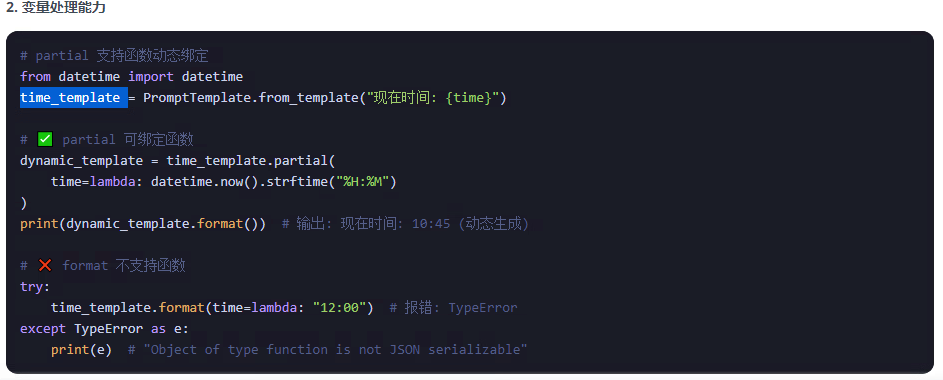
partial的入参可以添加函数
差异总结表如下:
3、输出解析器
3.1 输出解析器的功能和使用
输出解析器具有两大功能:添加 提示词模板的输出指令 和 解析输出格式。看到这里你也许会感到很奇怪,解析输出格式很好理解,但是输出解析器跟提示词模板有什么关系呢?
确实, 从名字上看, 输出解析器 (OutputParser) 似乎与提示词模板没有关系, 因为它听起来更像用于处理和解析输出的工具。然而实际上,输出解析器是通过改变提示词模板,即增加输出指令,来指导模型按照特定格式输出内容的。换句话说,原本的提示词模板中不包含输出指令,如果你想得到某种特定格式的输出结果,就得使用输出解析器。这样做的目的是分离提示词模板的输入和输出,输出解析器会把增加"输出指令"这件事做好。如果不要求模型按照特定的格式输出结果,则保持原提示词模板即可。
输出解析器的便利性体现在, 你想要某种输出格式时不需要手动写入输出指令,而是导入预设的输出解析器即可。除了预设大量的输出指令, 输出解析器的 parse 方法还支持将模型的输出解析为对应的数据格式。总的来说,输出解析器已经写好了输出指令(注入提示词模板的字符串),也写好了输出数据的格式处理函数,开发者不需要"重复造轮子"。
langchain提供了一些预设的输出解析器,如下图:

下面使用CommaSeparatedListOutputParser举个例子,CommaSeparatedListOutputParser是一个定义的类用于解析以逗号分隔的列表类型的输出。
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate# 创建CommaSeparatedListOutputParser实例
output_parser = CommaSeparatedListOutputParser()# 查看格式化指令
format_instructions = output_parser.get_format_instructions()
print("格式化指令:")
print(format_instructions)
print()# 创建提示模板
prompt_template = PromptTemplate(template="列出5个{topic}。{format_instructions}",input_variables=["topic"],partial_variables={"format_instructions": format_instructions}
)# 生成提示
prompt = prompt_template.format(topic="编程语言")
print("生成的提示:")
print(prompt)
print()# 模拟LLM的输出(实际使用时这里会是真实的LLM调用结果)
llm_output = "Python, Java, JavaScript, C++, Go"# 使用CommaSeparatedListOutputParser解析输出
parsed_output = output_parser.parse(llm_output)
print("解析后的结果:")
print(type(parsed_output))
print(parsed_output)
print()# 遍历解析后的列表
print("逐项输出:")
for i, item in enumerate(parsed_output, 1):print(f"{i}. {item.strip()}")print()
print("="*50)# 另一个示例:解析水果列表
prompt_template2 = PromptTemplate(template="列举一些{category}。{format_instructions}",input_variables=["category"],partial_variables={"format_instructions": format_instructions}
)prompt2 = prompt_template2.format(category="热带水果")
print("第二个提示:")
print(prompt2)
print()# 模拟LLM输出
llm_output2 = "芒果, 菠萝, 香蕉, 椰子, 火龙果, 山竹, 榴莲"# 解析输出
parsed_output2 = output_parser.parse(llm_output2)
print("解析后的热带水果列表:")
print(parsed_output2)
print()print("热带水果:")
for i, fruit in enumerate(parsed_output2, 1):print(f"{i}. {fruit.strip()}")print()
print("="*50)# 展示错误处理
print("错误处理示例:")
try:# 尝试解析无效格式invalid_output = "这是一个无效的列表格式没有逗号分隔:Your response"parsed_invalid = output_parser.parse(invalid_output)print("解析结果:", parsed_invalid)
except Exception as e:print(f"解析错误: {e}")# 正确处理无逗号的情况
print()
print("处理单个项目:")
single_item_output = "Python"
single_parsed = output_parser.parse(single_item_output)
print("单个项目解析结果:", single_parsed)3.2 Pydantic JSON输出解析器
pydantic是连接 LLM 非结构化输出与结构化数据的核心组件,在真实项目中应用率高达 85%(LangChain 官方调研数据)。
什么是 Pydantic JSON 输出解析器? 本质:将 LLM 原始文本输出自动转换为 类型安全的 Python 对象 核心组件:
Pydantic:数据验证库(定义数据结构)
JSON:结构化数据格式
OutputParser:LangChain 解析接口
import os
from typing import List, Optional
from langchain_community.llms import Tongyi
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
# 更新Pydantic导入方式
from pydantic import BaseModel, Field# 定义一个Pydantic模型来表示我们期望的输出结构
class PersonInfo(BaseModel):name: str = Field(description="人的姓名")age: int = Field(description="人的年龄")occupation: str = Field(description="人的职业")hobbies: List[str] = Field(description="人的爱好列表")def age_must_be_positive(cls, v):if v <= 0:raise ValueError('年龄必须是正数')return v# 定义另一个Pydantic模型表示更复杂的结构
class PersonDetail(BaseModel):person: PersonInfo = Field(description="个人信息")summary: str = Field(description="对这个人的简要总结")def main():# 修复API密钥变量名llm = Tongyi(dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"),model_name="qwen-turbo-latest")# 创建Pydantic输出解析器parser = PydanticOutputParser(pydantic_object=PersonDetail)# 创建提示模板prompt_template = PromptTemplate(template="请提供以下人物的详细信息:\n人物: {person_name}\n{format_instructions}\n",input_variables=["person_name"],partial_variables={"format_instructions": parser.get_format_instructions()})# 示例查询person_name = "爱因斯坦"# 格式化提示词prompt = prompt_template.format(person_name=person_name)print("提示词:")print(prompt)print("-" * 50)# 调用大模型response = llm.invoke(prompt)print("大模型原始输出:")print(response)print("-" * 50)# 使用Pydantic解析器解析输出try:parsed_output = parser.parse(response)print("解析后的结构化数据:")print(f"姓名: {parsed_output.person.name}")print(f"年龄: {parsed_output.person.age}")print(f"职业: {parsed_output.person.occupation}")print(f"爱好: {', '.join(parsed_output.person.hobbies)}")print(f"总结: {parsed_output.summary}")except Exception as e:print(f"解析失败: {e}")if __name__ == "__main__":main()3.3 StructuredOutputParser 结构化输出解析器
解释 StructuredOutputParser 和 ResponseSchema 的含义和使用方法。这两个组件是 LangChain 中用于结构化输出解析的核心工具,使语言模型 (LLM) 的输出能够被解析为预定义的、类型安全的 Python 对象。
(1)ResponseSchema(响应模式)
含义:定义你期望从语言模型 (LLM) 输出中提取的结构化字段。每个 ResponseSchema 描述一个字段的:
名称 (name):字段的键名(如 "name", "age")
描述 (description):提示 LLM 应在此字段中返回什么内容
类型 (type):字段的数据类型(如 string, integer, list)
作用:相当于告诉 LLM:“你的输出需要包含以下字段,并按照这些要求填充数据”。
(2)StructuredOutputParser(结构化输出解析器)
含义:将 LLM 的自由文本输出根据 ResponseSchema 定义的规则自动解析为结构化数据(如字典、Pydantic 模型)。
核心能力:
生成给 LLM 的格式化指令(如 JSON 格式要求)
将 LLM 的文本输出解析为 Python 对象
自动处理类型转换和验证
import os
from typing import List, Optional
from langchain_community.llms import Tongyi
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessagedef main():# 初始化通义千问大模型llm = Tongyi(dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"),model_name="qwen-turbo-latest")# 定义响应结构response_schemas = [ResponseSchema(name="name", description="人物的姓名,只有名字使用英文输出,其他部分使用中文输出"),ResponseSchema(name="age", description="人物的年龄,不是出生死亡的年月日,是一个数字"),ResponseSchema(name="occupation", description="人物的职业"),ResponseSchema(name="hobbies", description="人物的爱好列表,以逗号分隔"),ResponseSchema(name="summary", description="对这个人的简要总结")]# 创建结构化输出解析器output_parser = StructuredOutputParser.from_response_schemas(response_schemas)# 获取格式化指令format_instructions = output_parser.get_format_instructions()# 创建提示模板prompt_template = """请提供以下人物的详细信息:人物: {person_name}{format_instructions}"""# 创建ChatPromptTemplatechat_prompt = ChatPromptTemplate.from_messages([("system", "你是一个 helpful AI 助手"),("user", prompt_template)])# 示例查询person_name = "爱因斯坦"# 格式化提示词prompt = chat_prompt.format_messages(person_name=person_name,format_instructions=format_instructions)print("提示词:")print(prompt[1].content)print("-" * 50)# 调用大模型response = llm.invoke(prompt)print("大模型原始输出:")print(response)print("-" * 50)# 使用StructuredOutput解析器解析输出try:parsed_output = output_parser.parse(response)print("解析后的结构化数据:")print(f"姓名: {parsed_output['name']}")print(f"年龄: {parsed_output['age']}")print(f"职业: {parsed_output['occupation']}")print(f"爱好: {parsed_output['hobbies']}")print(f"总结: {parsed_output['summary']}")except Exception as e:print(f"解析失败: {e}")if __name__ == "__main__":main()4、模型包装器
LangChain 的模型包装器组件是基于各个模型平台的 API 协议进行开发的, 主要提供了两种类型的包装器。一种是通用的 LLM模型包装器, 另一种是专门针对 Chat 类型 API 的 Chat Model (聊天模型包装器)。
4.1 模型包装器的区别
在 LangChain 的官网文档中,凡是涉及模型输入、输出的链(Chain )和代理(Agent)的示例代码,都会提供两份。一份是使用LLM模型包装器的,一份是使用聊天模型包装器的,这是因为两者之间存在着细微但是很重要的区别。
(1)输入的区别
对于 LLM 模型包装器, 其输入通常是单一的字符串提示词 (prompt) 。例如,你可以输入"Translate the following English text to French: '{text}", 然后模型会生成对应的法文翻译。另外,LLM模型包装器主要用于文本任务,例如给定一个提示"今天的天气如何?"模型会生成一个相应的答案"今天的天气很好。"
聊天模型包装器,其输入则是一系列的聊天消息。通常这些消息都带有发言人的标签 (比如系统、 AI 和人类)。每条消息都有一个 role (角色) 和 content (内容) 。例如, 你可以输入[{"role": "user", "content": 'Translate the following English text toFrench: "{text}"}], 模型会返回对应的法文翻译, 但是返回内容包含在 AIMessage(...)内。
(2)输出的区别
对于LLM模型包装器,其输出是一个字符串,这个字符串是模型对提示词的补全。而聊天模型包装器的输出是一则聊天消息,是模型对输入消息的响应。
虽然LLM模型包装器和聊天模型包装器在处理输入和输出的方式上有所不同,但是为了使它们可以混合使用,它们都实现了基础模型接口。这个接口公开了两个常见的方法:predict(接收一个字符串并返回一个字符串)和predict messages(接收一则消息并返回一则消息)。这样,无论你是使用特定的模型,还是创建一个应该匹配其他类型模型的应用,都可以通过这个共享接口来进行操作。
4.2 模型包装器的案例解释
以下给出LLM模型包装器和Chat模型包装器的示例:
LLM模型包装器:
import os
from langchain_community.llms import Tongyi# 初始化通义千问大模型
llm = Tongyi(dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"),model_name="qwen-turbo"
)# 简单调用
response = llm.invoke("你好,介绍一下人工智能")
print("大模型回答:")
print(response)Chat模型包装器:
import os
from langchain_community.chat_models import ChatTongyi
#from langchain import LLMChain
from langchain.chains import LLMChain
from langchain.prompts.chat import (ChatPromptTemplate,HumanMessagePromptTemplate,SystemMessagePromptTemplate,
)
from langchain_core.output_parsers import StrOutputParser# 从环境变量获取 DASHSCOPE_API_KEY
api_key = os.getenv('DASHSCOPE_API_KEY')# 检查是否获取到 API Key
if not api_key:raise ValueError("请设置 DASHSCOPE_API_KEY 环境变量")# 使用通义千问模型
llm = ChatTongyi(temperature=1,dashscope_api_key=api_key,model_name="qwen-plus")template = ("以下是一段人类与人工智能之间的友好对话。""该人工智能健谈,并从其上下文中提供大量具体细节。如果人工智能不知道某个问题的答案,它会如实说明自己不知道。"
)system_message_prompt = SystemMessagePromptTemplate.from_template(template)human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])chain = LLMChain(llm=llm, prompt=chat_prompt)
ret = chain.run(text="你叫张三")
print(ret)
)
:几种草体的实现方式(透明度剔除,GPU Instaning, 曲面细分+几何着色器实现))



JavaScript 表单验证)
)


 - 飞控中的传感器)





)


)