一、CNN
视觉处理三大任务:图像分类、目标检测、图像分割
上游:提取特征,CNN
下游:分类、目标、分割等,具体的业务
1. 概述
卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域, 往往我们输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。
卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理具有网格状结构数据的深度学习模型。最初,CNN主要应用于计算机视觉任务,但它的成功启发了在其他领域应用,如自然语言处理等。
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络. 卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低运算量并特征增强;全连接层类似神经网络的部分,用来输出想要的结果。
1.1 使用场景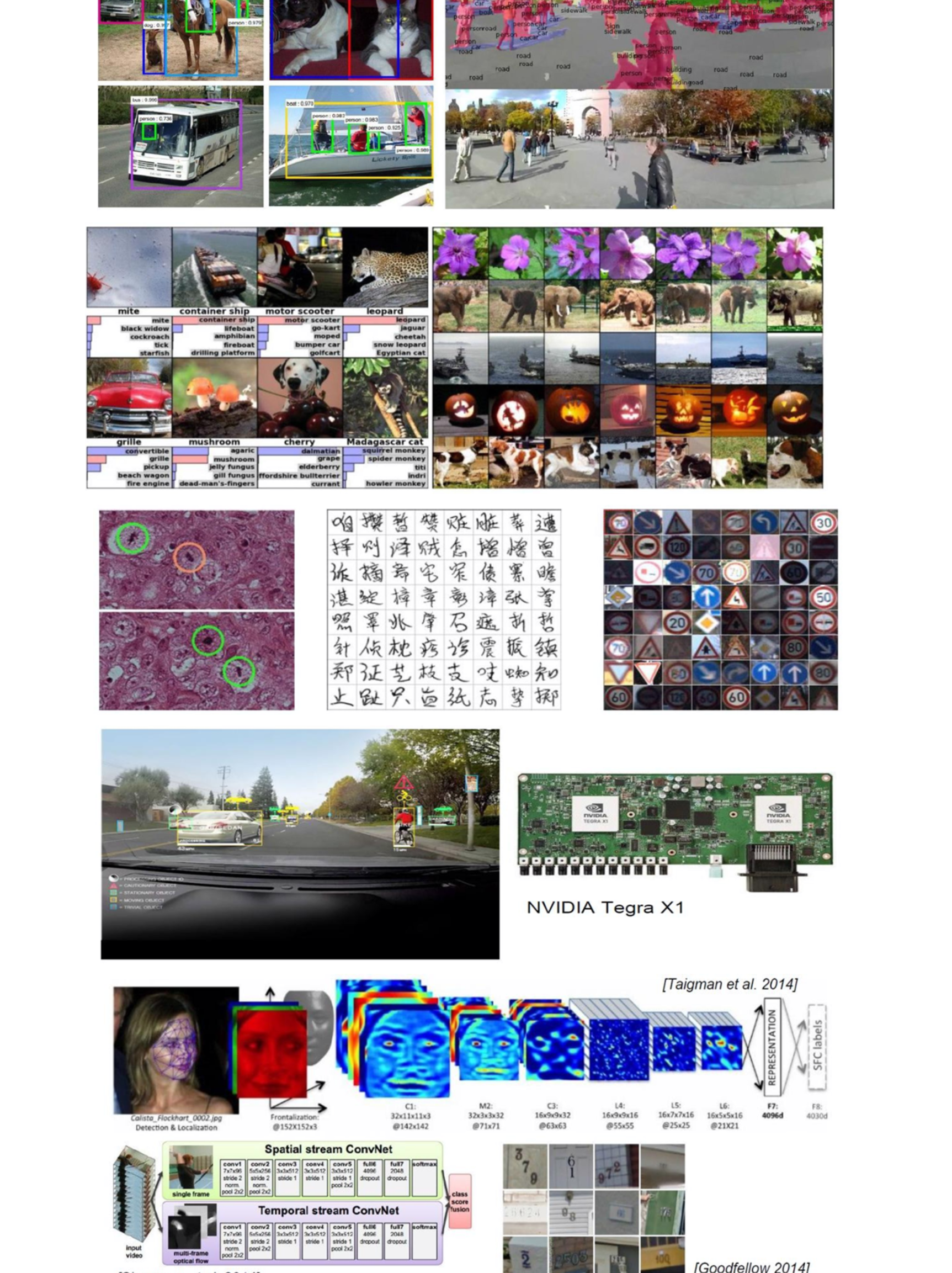
1.2 与传统网络的区别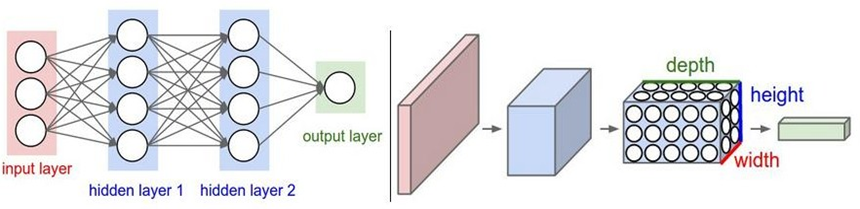
1.3 全连接的局限性
全连接神经网络并不太适合处理图像数据....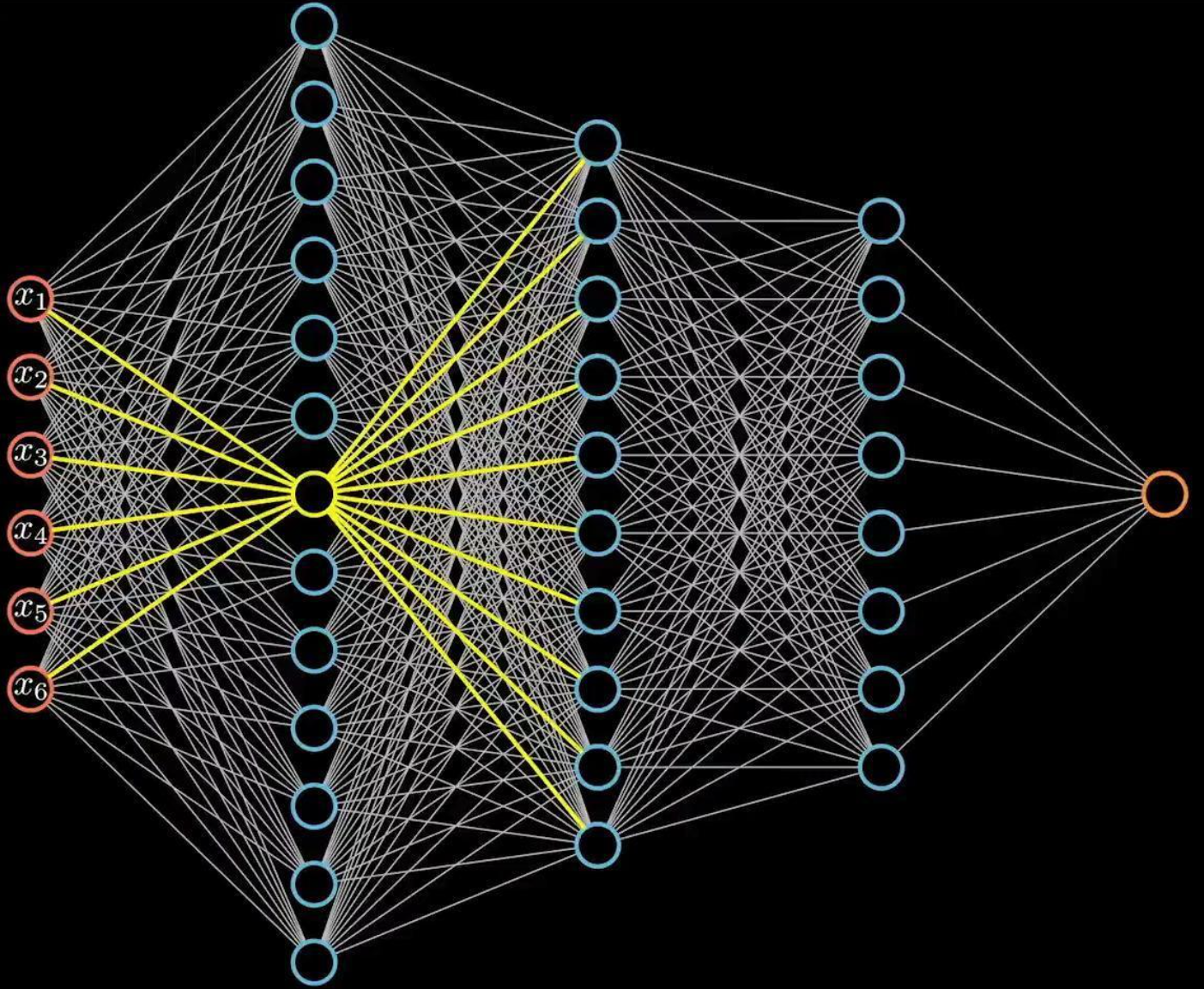
1.3.1 参数量巨大
$$
y = x \times W^T + b
$$
全连接结构计算量非常大,假设我们有1000×1000的输入,如果隐藏层也是1000×1000大小的神经元,由于神经元和图像每一个像素连接,则参数量会达到惊人的1000×1000×1000×1000,仅仅一层网络就已经有10^{12}个参数。
1.3.2 表达能力太有限
全连接神经网络的角色只是一个分类器,如果将整个图片直接输入网络,不仅参数量大,也没有利用好图片中像素的空间特性,增加了学习难度,降低了学习效果。
1.4 卷积思想
卷:从左往右,从上往下
积:乘积,求和
1.4.1 概念
Convolution,输入信息与卷积核(滤波器,Filter)的乘积。
1.4.2 局部连接
局部连接可以更好地利用图像中的结构信息,空间距离越相近的像素其相互影响越大。
根据局部特征完成目标的可辨识性。
1.4.3 权重共享
图像从一个局部区域学习到的信息应用到其他区域。
减少参数,降低学习难度。
2. 卷积层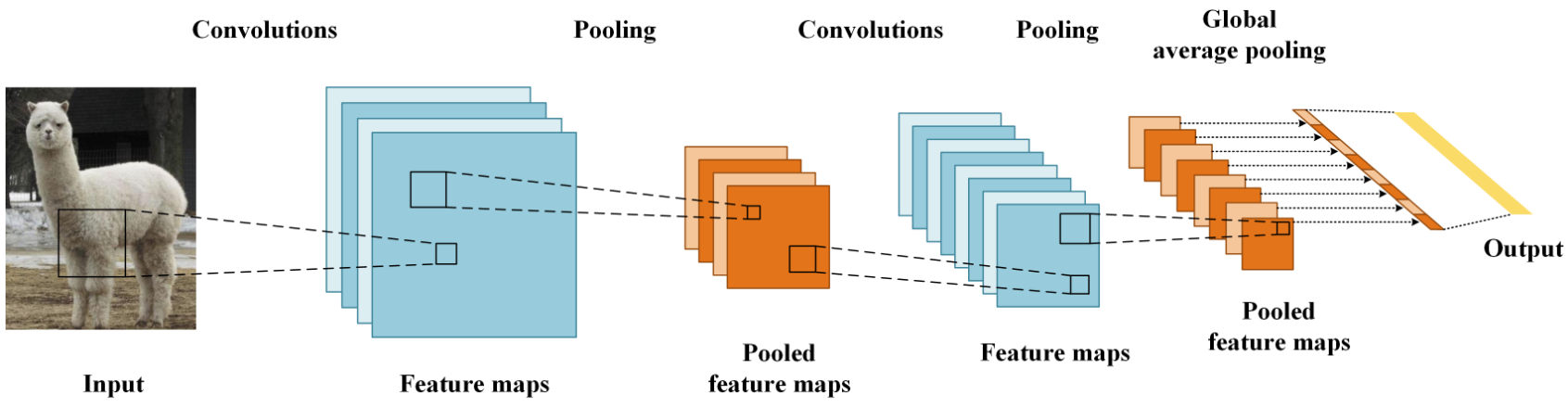
接下来,我们开始学习卷积核的计算过程, 即: 卷积核是如何提取特征的。
2.1 卷积核
卷积核是卷积运算过程中必不可少的一个“工具”,在卷积神经网络中,卷积核是非常重要的,它们被用来提取图像中的特征。
卷积核其实是一个小矩阵,在定义时需要考虑以下几方面的内容:
卷积核的个数:卷积核(过滤器)的个数决定了其输出特征矩阵的通道数。
卷积核的值:卷积核的值是初始化好的,后续进行更新。
卷积核的大小:常见的卷积核有1×1、3×3、5×5等,一般都是奇数 × 奇数。
下图就是一个3×3的卷积核:
2.2 卷积计算
2.2.1 卷积计算过程
卷积的过程是将卷积核在图像上进行滑动计算,每次滑动到一个新的位置时,卷积核和图像进行点对点的计算,并将其求和得到一个新的值,然后将这个新的值加入到特征图中,最终得到一个新的特征图。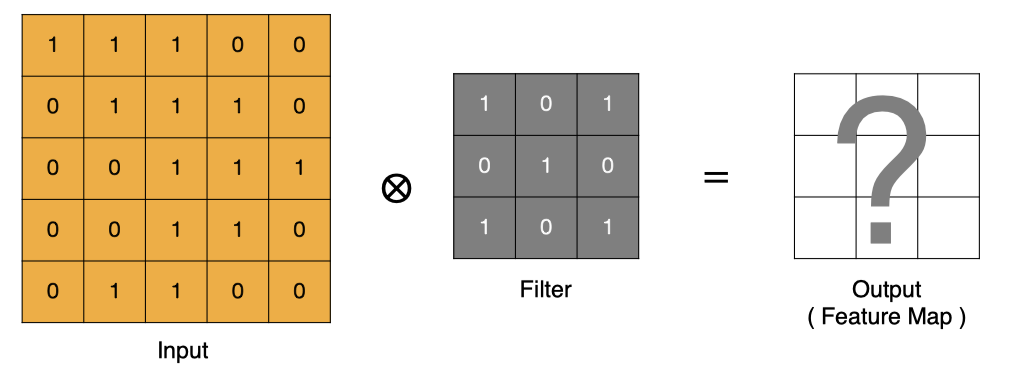
input 表示输入的图像
filter 表示卷积核, 也叫做滤波器
input 经过 filter 的得到输出为最右侧的图像,该图叫做特征图
那么, 它是如何进行计算的呢?卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。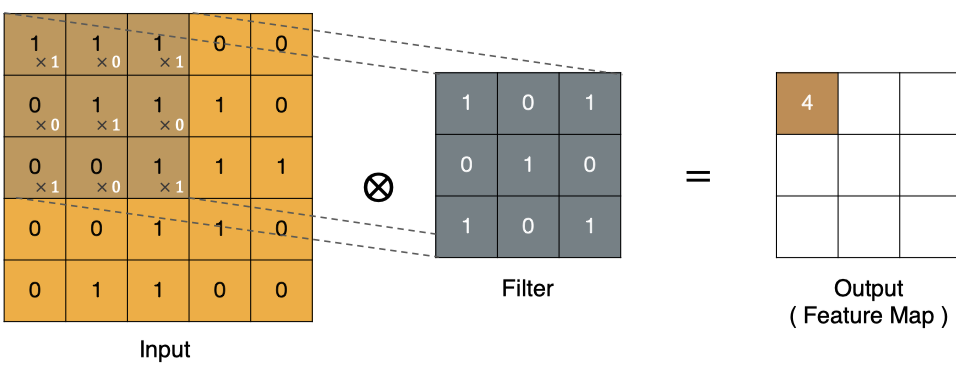
左上角的点计算方法: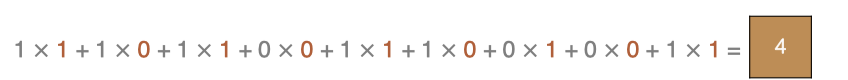
按照上面的计算方法可以得到最终的特征图为: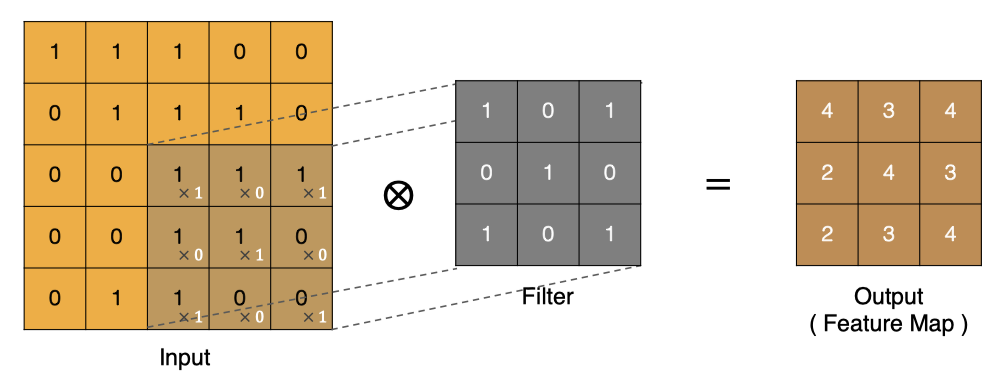
卷积的重要性在于它可以将图像中的特征与卷积核进行卷积操作,从而提取出图像中的特征。
可以通过不断调整卷积核的大小、卷积核的值和卷积操作的步长,可以提取出不同尺度和位置的特征。
# 面向对象的模块化编程 from matplotlib import pyplot as plt import os import torch import torch.nn as nn def test001():current_path = os.path.dirname(__file__)img_path = os.path.join(current_path, "data", "彩色.png")# 转换为相对路径img_path = os.path.relpath(img_path) # 使用plt读取图片img = plt.imread(img_path)print(img.shape)# 转换为张量:HWC ---> CHW ---> NCHW 链式调用img = torch.tensor(img).permute(2, 0, 1).unsqueeze(0)# 创建卷积核 (501, 500, 4)conv = nn.Conv2d(in_channels=4, # 输入通道out_channels=32, # 输出通道kernel_size=(5, 3), # 卷积核大小stride=1, # 步长padding=0, # 填充bias=True)# 使用卷积核对图像进行卷积操作 [9999] [[[[]]]]out = conv(img)# 输出128个特征图conv2 = nn.Conv2d(in_channels=32, # 输入通道out_channels=128, # 输出通道kernel_size=(5, 5), # 卷积核大小stride=1, # 步长padding=0, # 填充bias=True)out = conv2(out)print(out)# 把图像显示出来print(out.shape)plt.imshow(out[0][10].detach().numpy(), cmap='gray')plt.show() # 作为主模块执行 if __name__ == "__main__":test001()
2.2.2 卷积计算底层实现
并不是水平和垂直方向的循环。
下图是卷积的基本运算方式: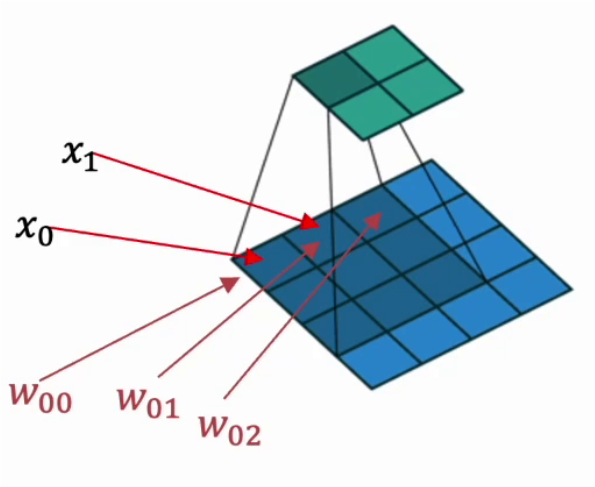
卷积真正的计算过程如下图: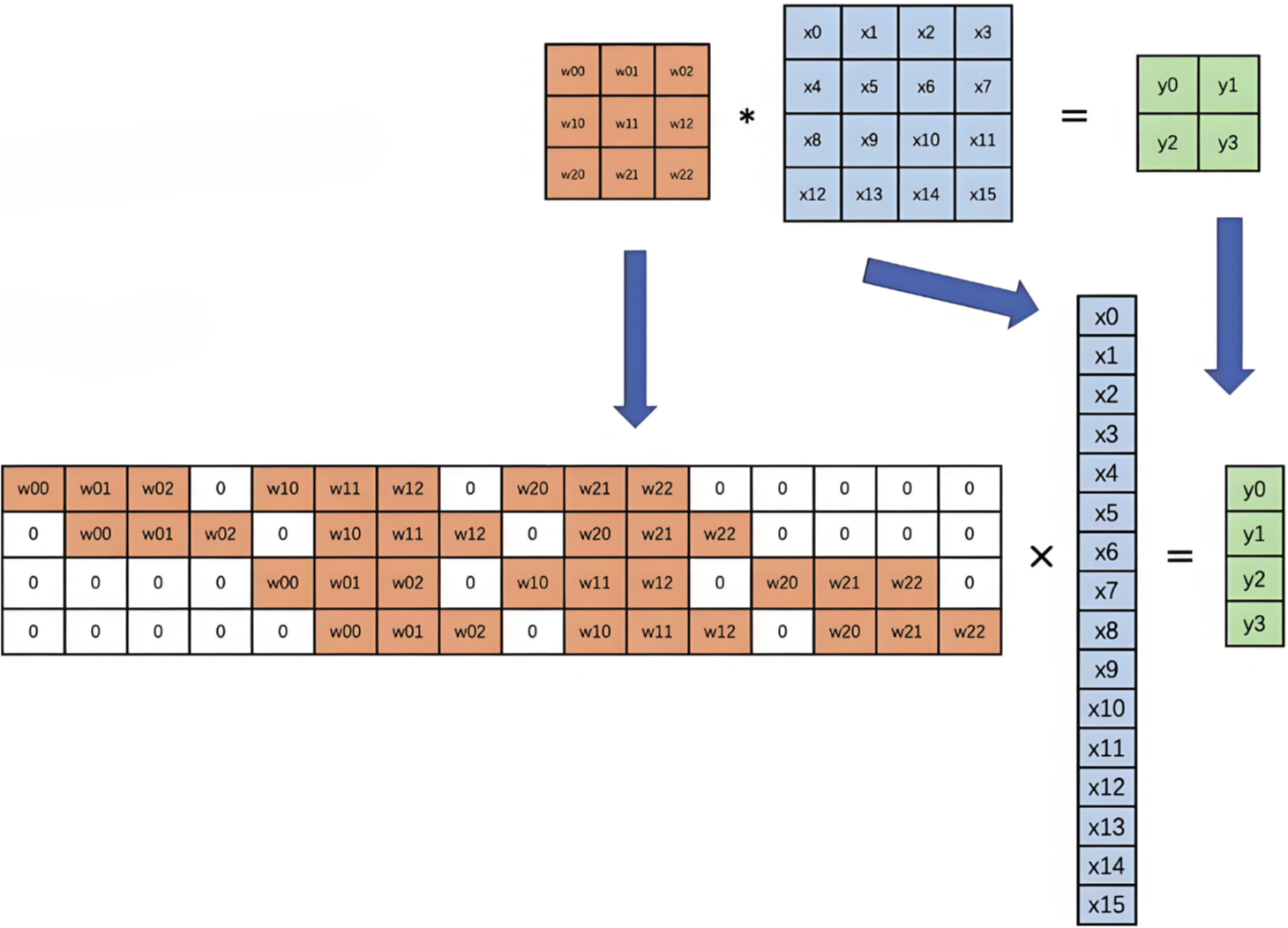
2.3 边缘填充
Padding
通过上面的卷积计算,我们发现最终的特征图比原始图像要小,如果想要保持图像大小不变, 可在原图周围添加padding来实现。
更重要的,边缘填充还更好的保护了图像边缘数据的特征。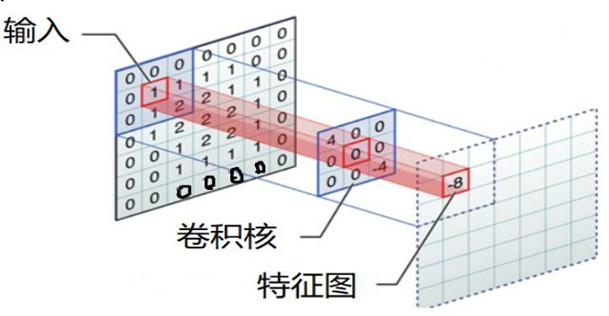
2.4 步长Stride
按照步长为1来移动卷积核,计算特征图如下所示:
如果我们把 Stride 增大为2,也是可以提取特征图的,如下图所示: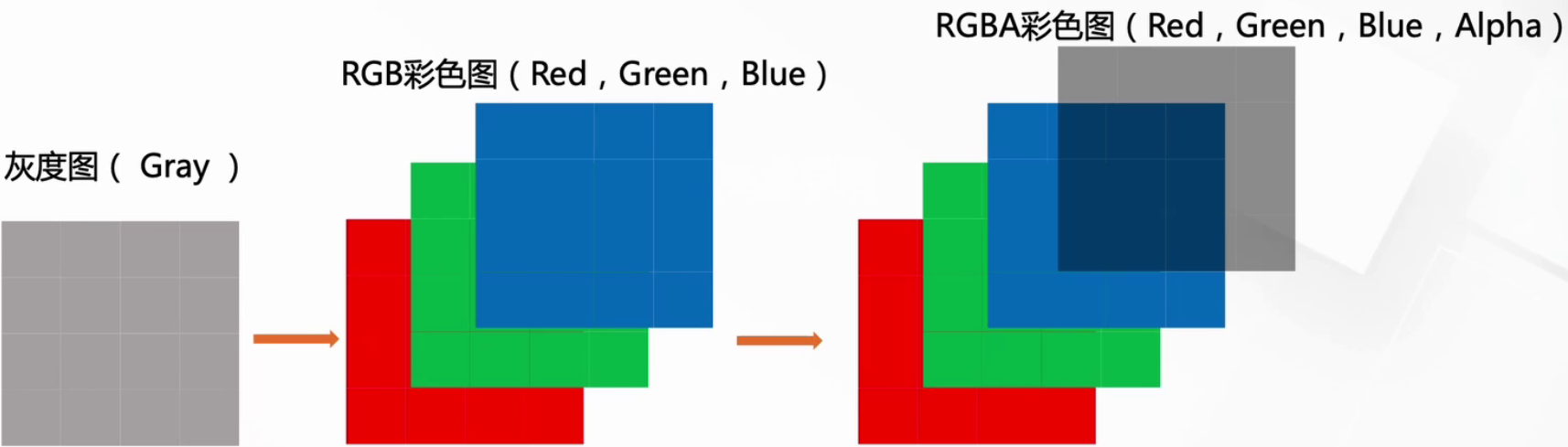
stride太小:重复计算较多,计算量大,训练效率降低; stride太大:会造成信息遗漏,无法有效提炼数据背后的特征;
2.5 多通道卷积计算
首先我们需要认识下通道,做到颗粒度对齐~
2.5.1 数字图像的标识
我们知道图像在计算机眼中是一个矩阵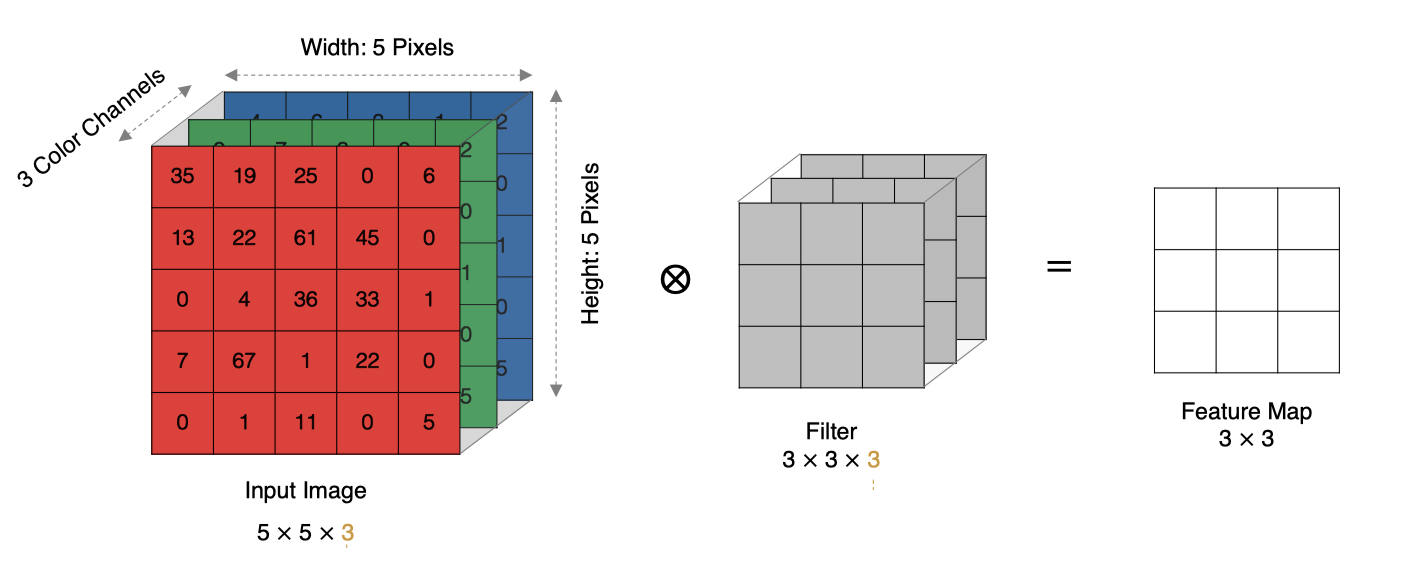
通道越多,可以表达的特征就越丰富~
2.5.2 具体计算实现
实际中的图像都是多个通道组成的,我们怎么计算卷积呢?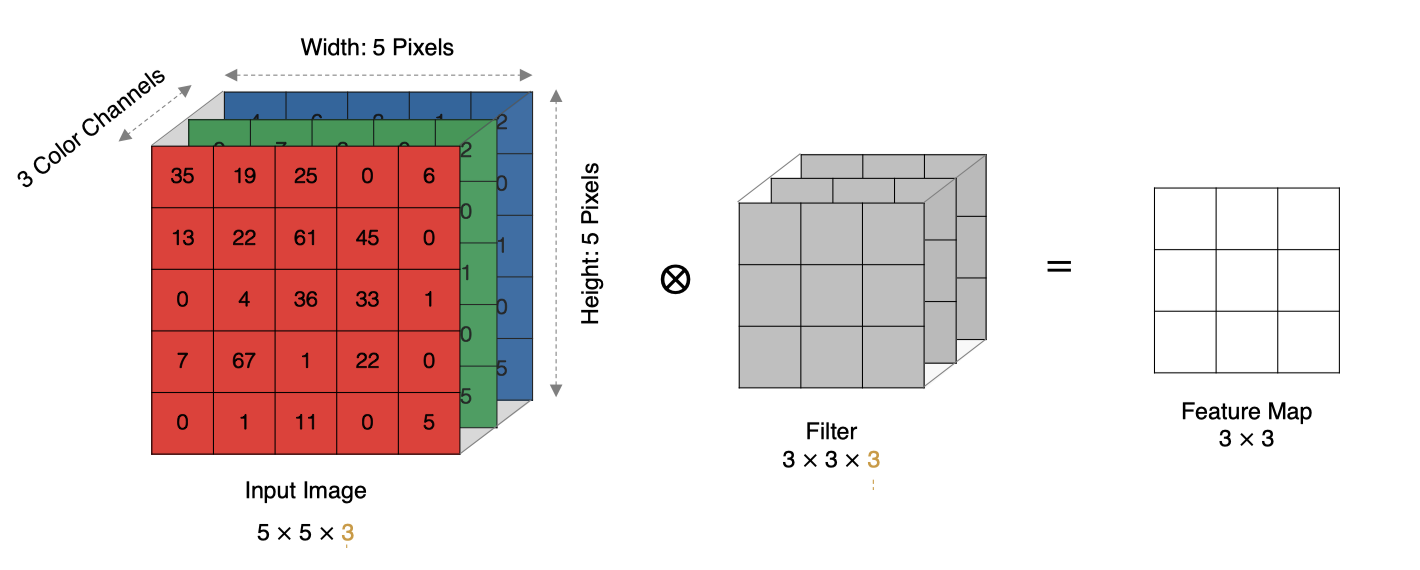
计算方法如下:
当输入有多个通道(Channel), 例如RGB三通道, 此时要求卷积核需要有相同的通道数。
卷积核通道与对应的输入图像通道进行卷积。
将每个通道的卷积结果按位相加得到最终的特征图。
如下图所示: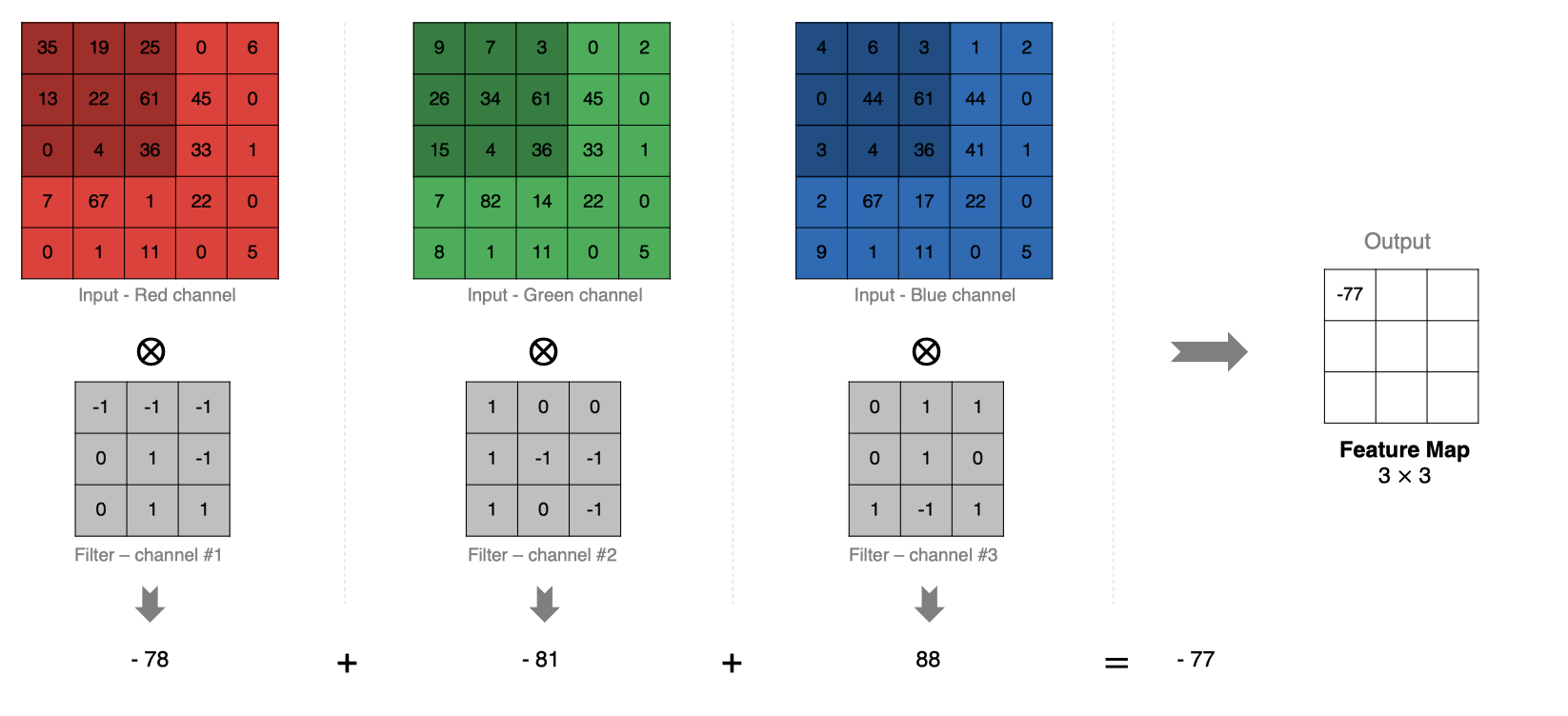
2.6 多卷积核卷积计算
实际对图像进行特征提取时, 我们需要使用多个卷积核进行特征提取。这个多个卷积核可以理解为从不同到的视角、不同的角度对图像特征进行提取。
那么, 当使用多个卷积核时, 应该怎么进行特征提取呢?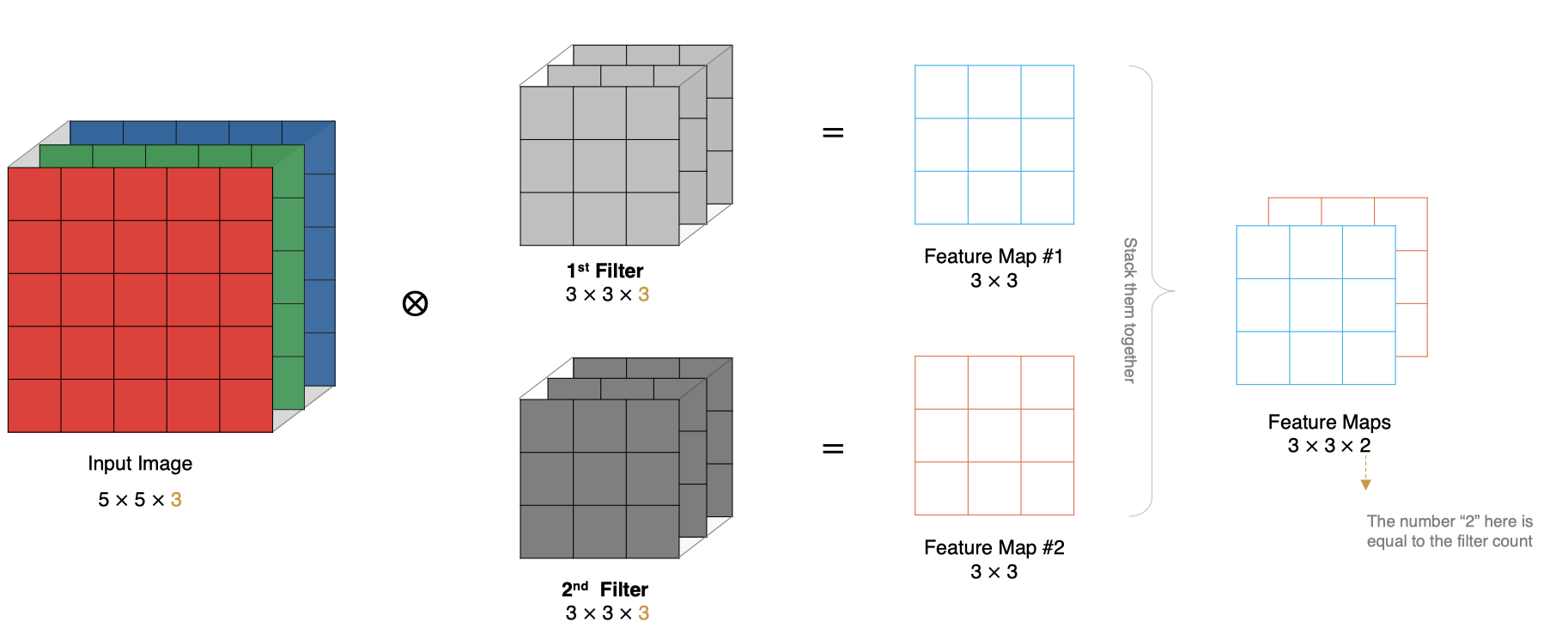
2.7 特征图大小
输出特征图的大小与以下参数息息相关:
size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1×1, 3×3, 5×5
Padding: 零填充的方式
Stride: 步长
那计算方法如下图所示:
输入图像大小: W x W
卷积核大小: F x F
Stride: S
Padding: P
输出图像大小: N x N
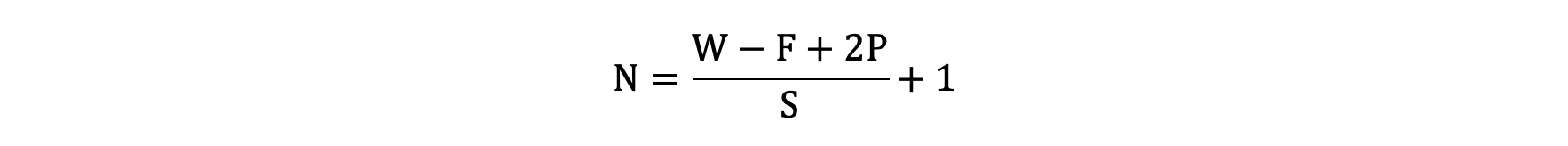
以下图为例:
图像大小: 5 x 5
卷积核大小: 3 x 3
Stride: 1
Padding: 1
(5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为: 5 x 5
2.8 只卷一次?

2.9 卷积参数共享
数据是 32×32×3 的图像,用 10 个 5×5 的filter来进行卷积操作,所需的权重参数有多少个呢?
5×5×3 = 75,表示每个卷积核只需要75个参数。
10个不同的卷积核,就需要10*75 = 750个卷积核参数。
如果还考虑偏置参数b,最终需要 750+10=760 个参数。
$$
全连接参数量: 10 * 28 * 28 *(32 * 32 * 3 + 1)
$$
2.10 局部特征提取
通过卷积操作,CNN具有局部感知性,能够捕捉输入数据的局部特征,这在处理图像等具有空间结构的数据时非常有用。
2.11 PyTorch卷积层 API
test01 函数使用一个多通道卷积核进行特征提取, test02 函数使用 3 个多通道卷积核进行特征提取:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import os
def showimg(img):plt.imshow(img)# 隐藏刻度plt.axis("off")plt.show()
def test001():dir = os.path.dirname(__file__)img = plt.imread(os.path.join(dir, "彩色.png"))# 创建卷积核# in_channels:输入数据的通道数# out_channels:输出特征图数,和filter数一直conv = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=3, stride=1, padding=1)# 注意:卷积层对输入的数据有形状要求 [batch, channel, height, width]# 需要进行形状转换 H, W, C -> C, H, Wimg = torch.tensor(img, dtype=torch.float).permute(2, 0, 1)print(img.shape)# 接着变形:CHW -> BCHWnewimg = img.unsqueeze(0)print(newimg.shape)# 送入卷积核运算一下newimg = conv(newimg)print(newimg.shape)
# 蒋NCHW->HWCnewimg = newimg.squeeze(0).permute(1, 2, 0)showimg(newimg.detach().numpy())
# 多卷积核
def test002():dir = os.path.dirname(__file__)img = plt.imread(os.path.join(dir, "彩色.png"))# 定义一个多特征图输出的卷积核conv = nn.Conv2d(in_channels=4, out_channels=3, kernel_size=3, stride=1, padding=1)
# 图形要进行变形处理img = torch.tensor(img).permute(2, 0, 1).unsqueeze(0)# 使用卷积核对图片进行卷积计算outimg = conv(img)print(outimg.shape)# 把图形形状转换回来以方便显示outimg = outimg.squeeze(0).permute(1, 2, 0)print(outimg.shape)# showimg(outimg)# 显示这些特征图for idx in range(outimg.shape[2]):showimg(outimg[:, :, idx].squeeze(-1).detach())
if __name__ == "__main__":test002()
效果:
2.12 卷积层实验
2.12.1 基本原理
在前面的章节中我们了解了卷积的过程,明白了卷积过程就是使用一个小的卷积核与输入特征矩阵进行滑动卷积的过程。
前面的章节中为了能更好的说清楚卷积的过程,其输入特征矩阵都是单通道的,根据“计算机眼中的图像”章节,知道单通道是灰度图或者二值化图,但是实际上识别图像大部分都是彩色图,也就意味着不是一个通道的特征输入。
所以,卷积的过程中大部分都是多通道的卷积,并且在卷积完之后还会加上偏置项。
2.12.1.1 特征输入
在“特征输入”组件中,提供了一个3x3的三通道输入特征矩阵,并将其三个通道的内容都展示了出来。
也就意味着这个输入矩阵是一个3x3大小的,并且有三个通道。可以看成是三张3x3的A4纸“啪”一下,粘在一块了。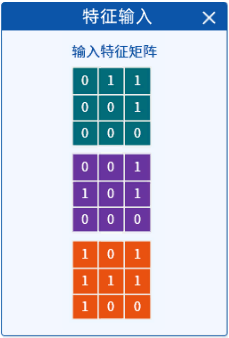
2.12.1.2 卷积核
有了输入特征矩阵后,就需要定义卷积核了。
在“卷积核”组件中,为了简化计算,定义了卷积核的大小为2x2(实际上几乎不会有2x2的卷积核), 通过拖动滑动条可以修改卷积核的个数。
并且为了能够对一个三通道的输入特征矩阵进行卷积,这里的每一个卷积核也是三通道的卷积核。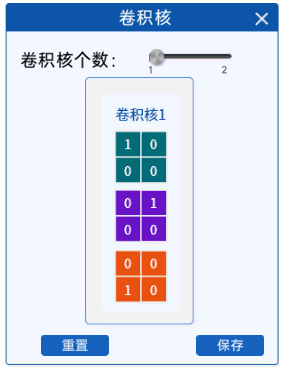
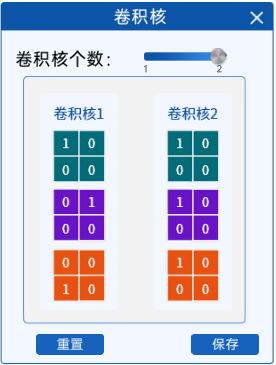
| 卷积核个数为1 | 卷积核个数为2 |
2.12.1.3 卷积过程显示
在“卷积过程显示”组件中,固定了Padding方式为VALID和步长为1。
在多通道卷积过程中,输出特征矩阵是由每个通道的卷积核与对应通道的输入特征矩阵在对应位置进行卷积,然后将多个通道的卷积结果相加的结果。
以输出特征矩阵的左上角“1”为例,其值是由第一个通道的卷积核与第一个通道的输入特征矩阵的左上角进行卷积加上第二个通道的卷积核与第二个通道的输入特征矩阵的左上角进行卷积加上第三个通道的卷积核与第三个通道的输入特征矩阵的左上角进行卷积,最后得到的卷积结果相加得到输出特征矩阵的左上角值为“1”,其他的以此类推。
在得到输出特征矩阵后,偏置矩阵就会与输出特征矩阵相加,得到本次多通道卷积的最终结果。
由此我们得到两个结论:
输入特征的通道数决定了卷积核的通道数(卷积核通道个数=输入特征通道个数)。
卷积核的个数决定了输出特征矩阵的通道数与偏置矩阵的通道数(卷积核个数=输出特征通道数=偏置矩阵通道数)。
2.12.1.2 步骤
需要默认打开“华清远见人工智能虚拟仿真”和“华清远见人工智能虚拟仿真本地服务管理平台”。
(可选)使用“华清远见人工智能虚拟仿真本地服务管理平台”启动服务。
服务启动一次之后就不需要再次启动了。
单击多通道卷积与偏置实验进入
如果之前进入了某个实验,可以在实验面板的右上角点击“返回”回到主页即可。
拖出组件并连线
根据实验原理,将我们的逻辑抽象成组件之后,连线如下图所示。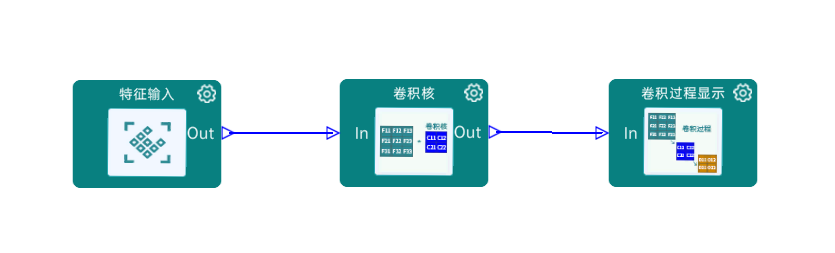
验证
点击验证,如显示校验成功,即代表逻辑无误,验证按钮与校验成功界面如下图所示。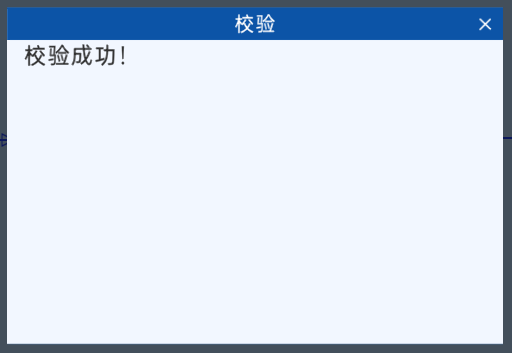
运行
点击运行,可以实现功能运行,并显示结果输出,如下图所示。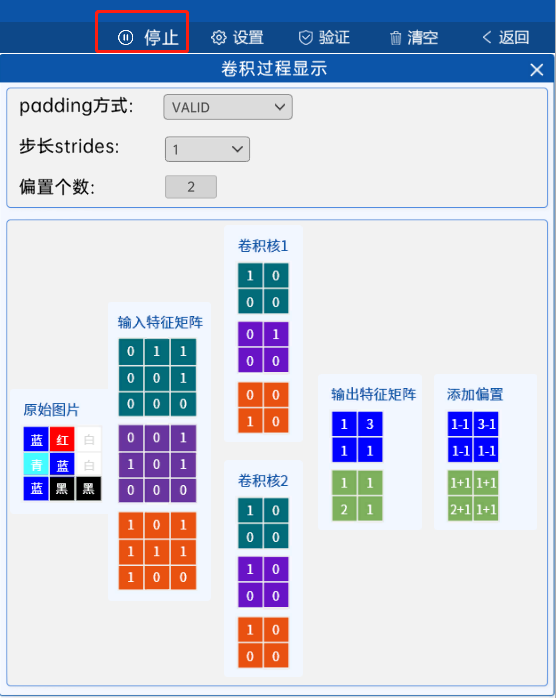
代码生成
点击界面左下角的生成代码按钮,可生成本实验的Python代码,生成代码按钮如下图所示。
点击后可以查看该实验代码,代码会根据界面所选参数进行适配,点击复制可以将其复制,并粘贴在其它地方。
这里我们可以粘贴到软件的Jupyter中运行,“华清远见人工智能虚拟仿真本地服务管理平台”打开Jupyter,第一次打开Jupyter需要点击“打开CMD命令”,打开Jupyter后无需再次打开CMD,如下图所示。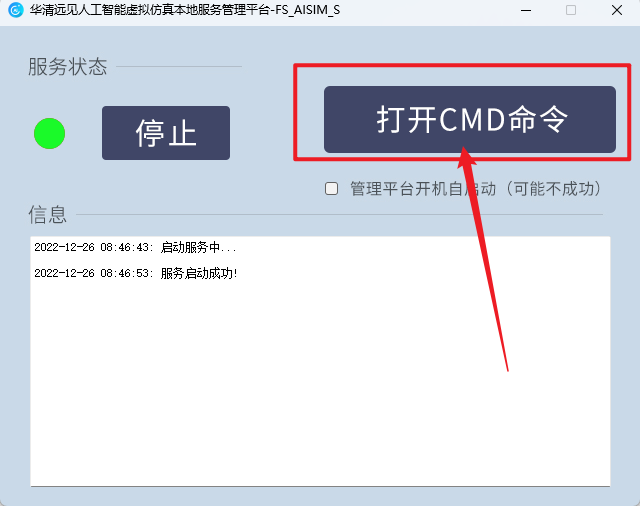
在弹出的CMD命令行中,输入python -m jupyterlab --notebook-dir .\\learn,点击回车,浏览器会自动跳转打开Jupyter,如下图所示。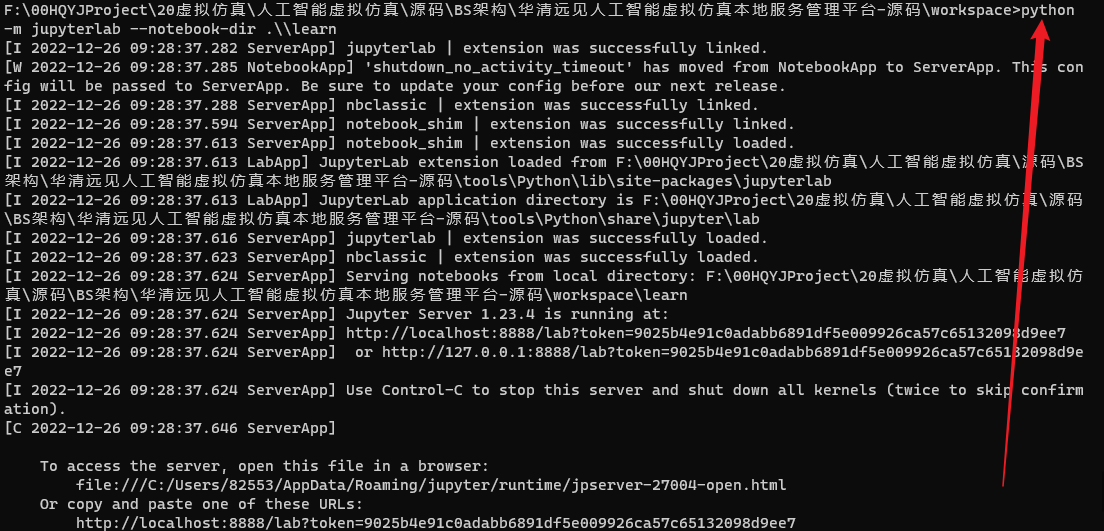
如果没有自动跳转和打开浏览器,请输入下图中圈出的内容,每个人的该内容不一致,请复制自己的 弹出的。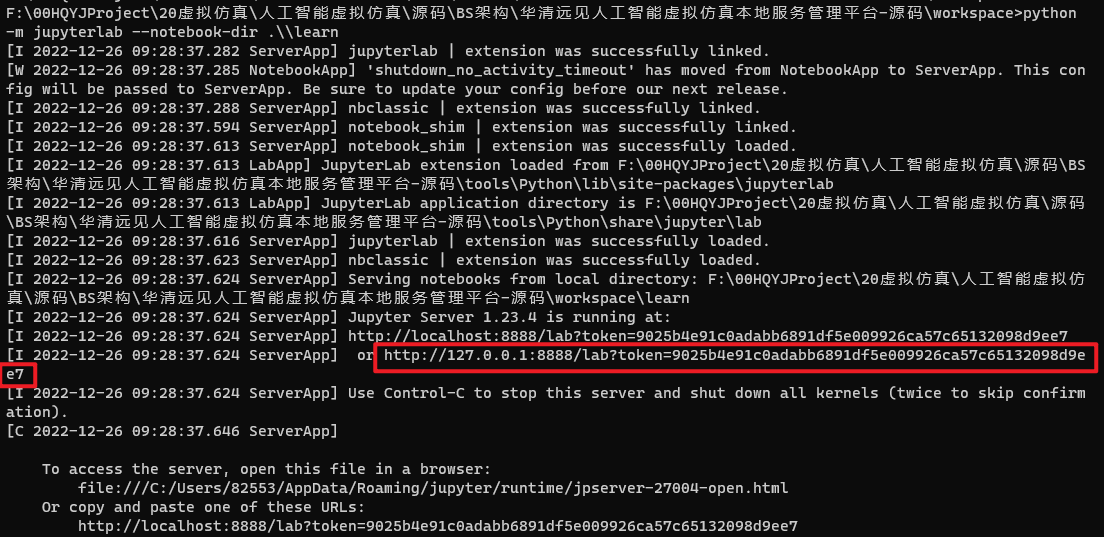
将代码输入到Jupyter中,点击运行可以查看结果。
2.12.1.3 实验现象
实验结果为:![]()
2.13 卷积作业
基本概念理解题:
什么是多通道卷积?在处理RGB图像时,如何体现多通道卷积的特性?
计算过程描述题:
假设你有一个3通道(如RGB)的输入图像,其尺寸为64x64,应用一个大小为3x3、深度也为3的卷积核进行卷积操作,请描述这个过程。
参数数量计算题:
请计算一个大小为5x5、深度为3的卷积核应用于具有10个通道的输入时,需要多少个可学习参数。如果有偏置项,总参数量是多少?
偏置项含义题:
解释卷积层中的偏置项是什么,并讨论在神经网络中引入偏置项的好处。
设计选择题:
在实际应用中,为什么有些卷积层会选择不包含偏置项?列举并解释可能的情况。
2.14 知识点扩展
深度理解题:
在多通道卷积过程中,权重共享如何在不同通道间实现特征学习的协同作用?请结合实际应用案例进行说明。
优化策略设计题:
当处理高维输入数据时(例如视频帧序列或高光谱图像),针对多个通道上的卷积操作,你可能会采取哪些优化策略以减少计算复杂度并提高模型性能?
数学表达与梯度传播分析题:
请推导一个多通道卷积层(包括多个滤波器和每个滤波器对应的偏置项)前向传播过程中的矩阵运算表达式,并解释反向传播时这些参数(权重和偏置)的梯度是如何计算的。
架构创新思考题:
现代深度学习框架中存在将通道注意力机制融入到卷积层的设计,例如SENet中的Squeeze-and-Excitation模块。请描述这一机制如何影响卷积层对多通道信息的处理,并讨论其优势。
跨通道交互研究题:
举例说明一种或多通道特征融合的方法,比如深度可分离卷积中的点wise卷积或者跨通道卷积,并阐述它们如何促进不同通道间的特征交互。
实践问题解决题:
假设你在训练一个用于图像分类的深度卷积神经网络时,发现由于输入图像的多通道特性导致模型过拟合,请提出至少两种通过调整卷积层结构或配置来缓解过拟合的技术方案,并讨论其原理。
偏置项作用与权衡题:
讨论卷积层中偏置项的作用以及它可能引入的问题(如模型的平移不变性)。在某些场景下为何会选择去除偏置项?如果有,会采用什么替代策略来补偿去除偏置带来的潜在损失?
技术对比与选择题:
比较全局平均池化、全局最大池化以及具有偏置项的1x1卷积在获取通道级统计特征方面的异同,并根据特定任务需求阐述何时选择哪种方法更为合适。
3.池化层
3.1 概述
池化层 (Pooling) 降低空间维度, 缩减模型大小,提高计算速度. 即: 主要对卷积层学习到的特征图进行下采样(SubSampling)处理。
池化层主要有两种:
最大池化 max pooling
最大池化是从每个局部区域中选择最大值作为池化后的值,这样可以保留局部区域中最显著的特征。最大池化在提取图像中的纹理、形状等方面具有很好的效果。
平均池化 avgPooling
平均池化是将局部区域中的值取平均作为池化后的值,这样可以得到整体特征的平均值。平均池化在提取图像中的整体特征、减少噪声等方面具有较好的效果。
3.2 池化层计算
整体结构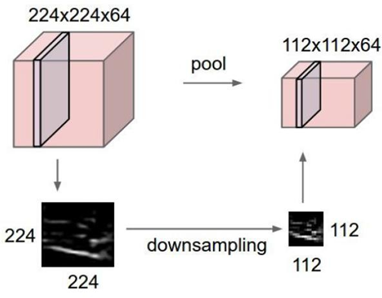
计算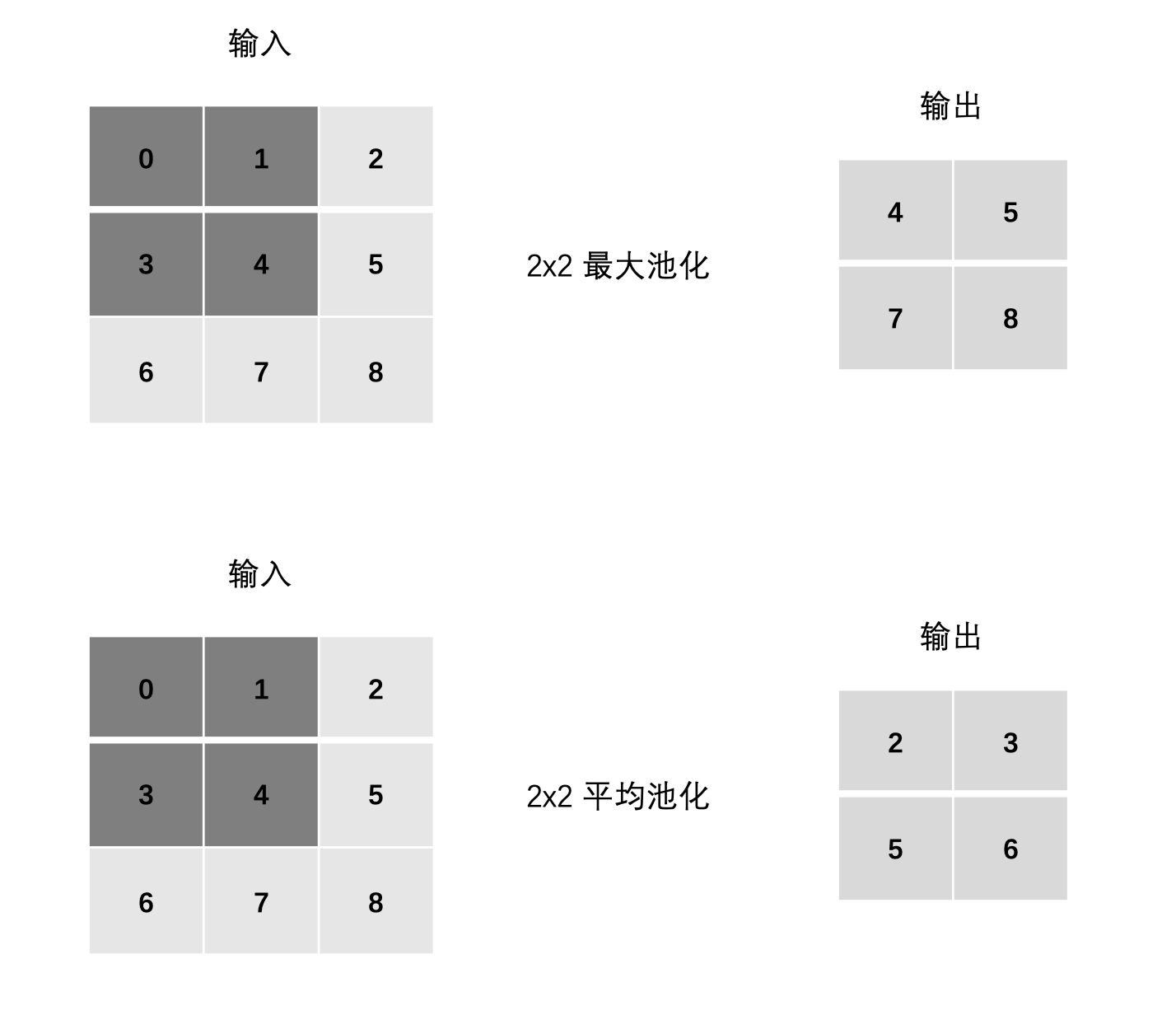
最大池化:
max(0, 1, 3, 4)
max(1, 2, 4, 5)
max(3, 4, 6, 7)
max(4, 5, 7, 8)
平均池化:
mean(0, 1, 3, 4)
mean(1, 2, 4, 5)
mean(3, 4, 6, 7)
mean(4, 5, 7, 8)
3.3 步长Stride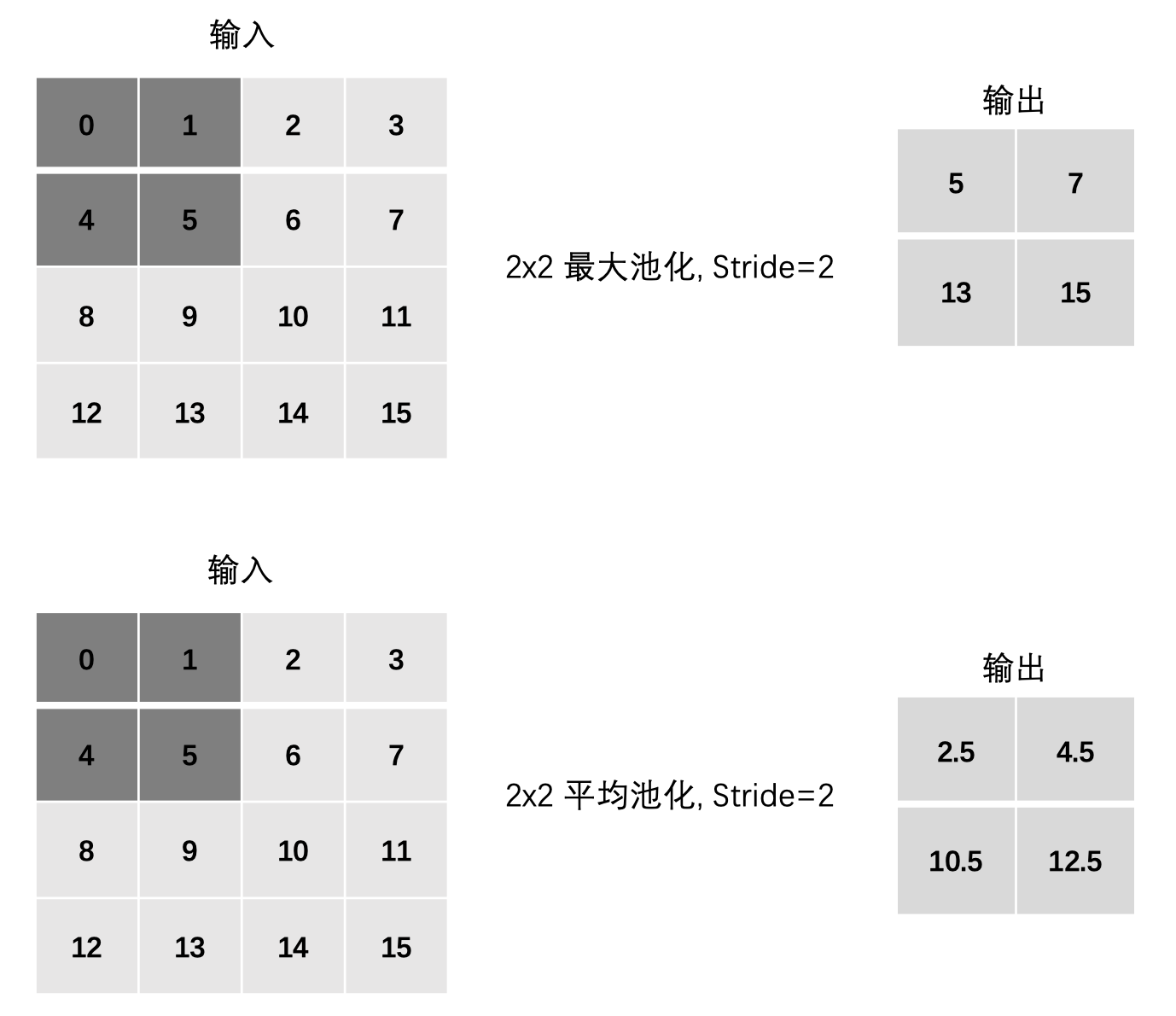
最大池化:
max(0, 1, 4, 5)
max(2, 3, 6, 7)
max(8, 9, 12, 13)
max(10, 11, 14, 15)
平均池化:
mean(0, 1, 4, 5)
mean(2, 3, 6, 7)
mean(8, 9, 12, 13)
mean(10, 11, 14, 15)
3.4 边缘填充Padding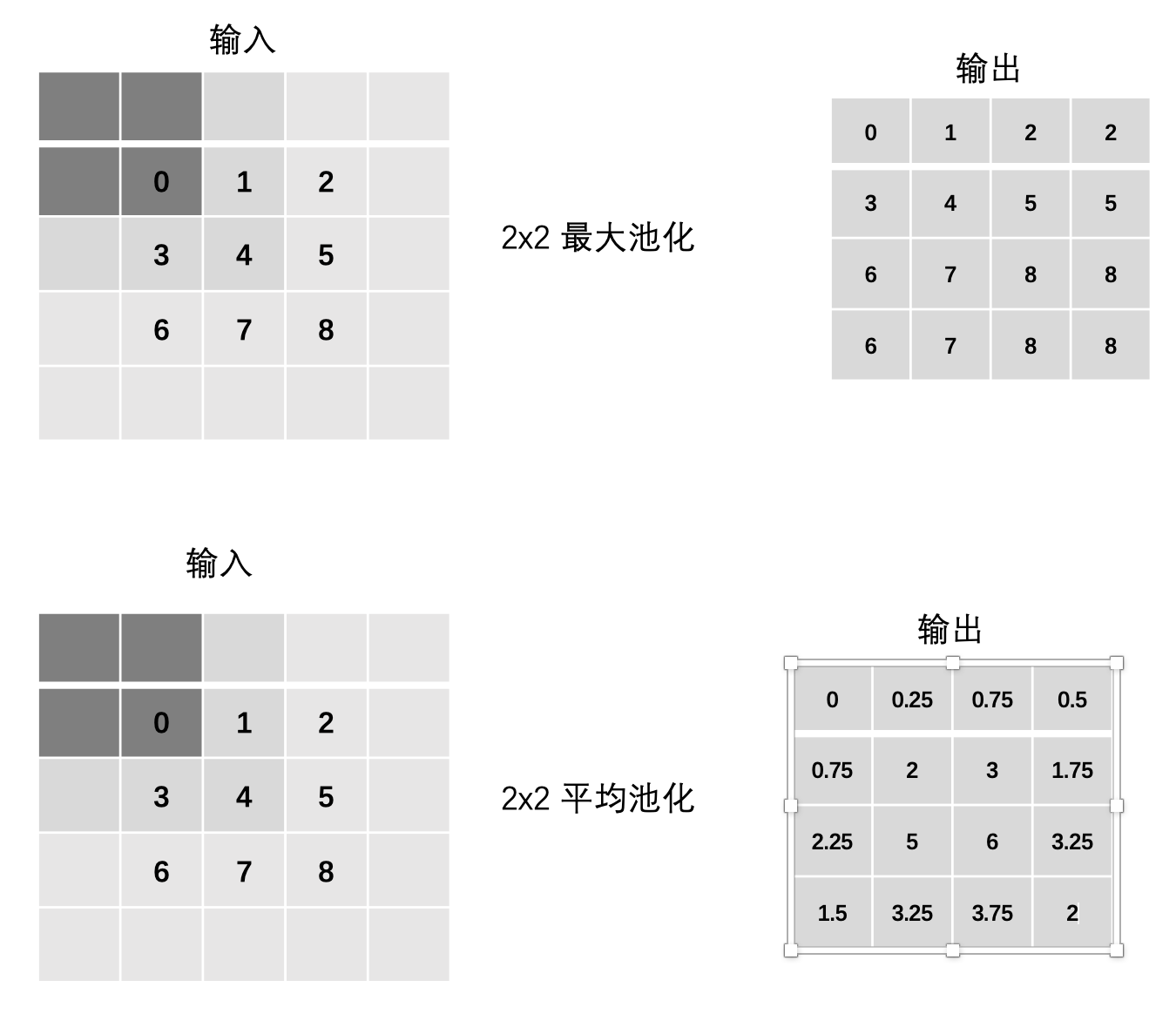
最大池化:
max(0, 0, 0, 0)
max(0, 0, 0, 1)
max(0, 0, 1, 2)
max(0, 0, 2, 0)
... 以此类推
平均池化:
mean(0, 0, 0, 0)
mean(0, 0, 0, 1)
mean(0, 0, 1, 2)
mean(0, 0, 2, 0)
... 以此类推
3.5 多通道池化计算
在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各个通道的输入相加。这意味着池化层的输出和输入的通道数是相等。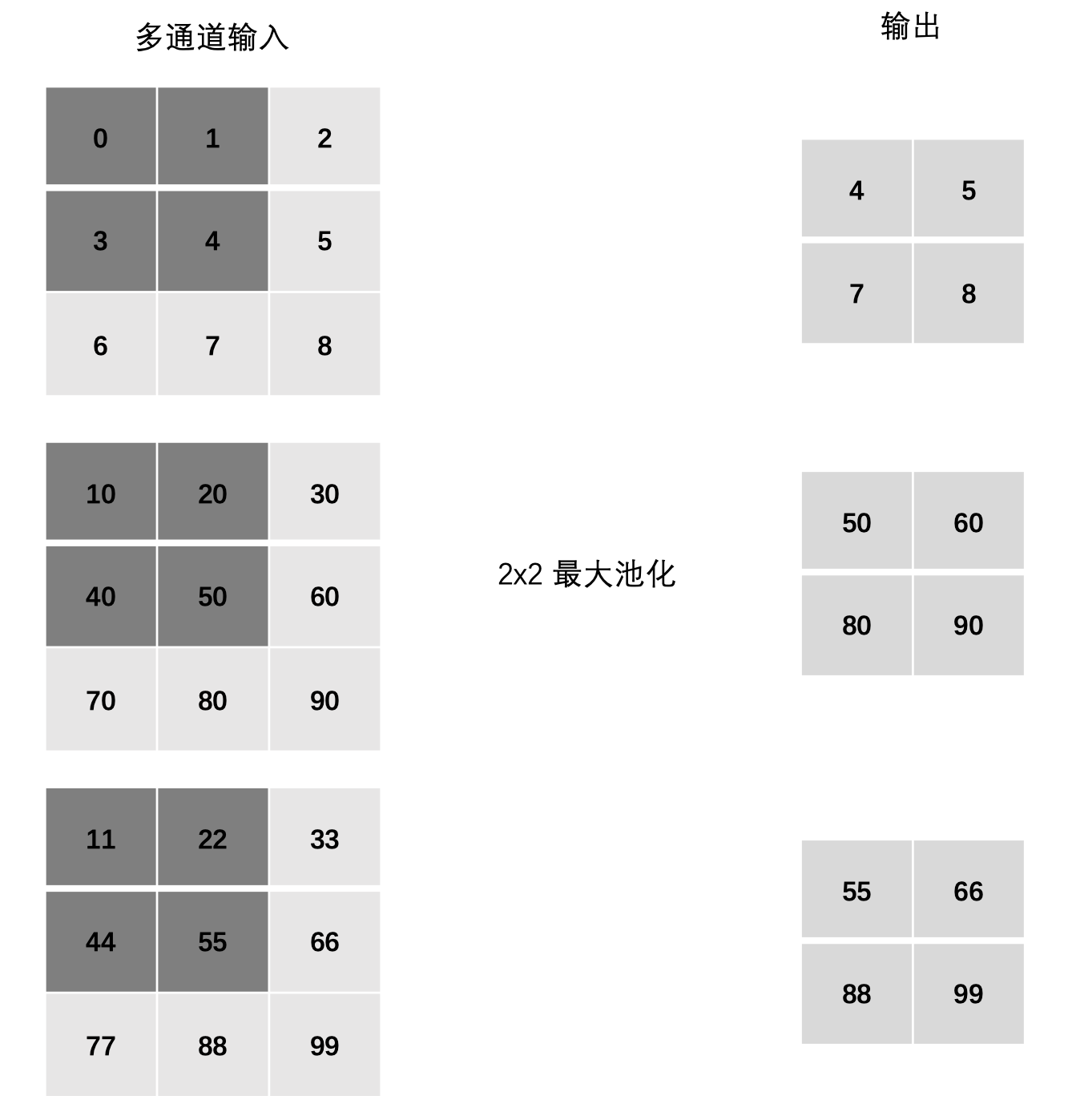
3.6 池化层的作用
池化操作的优势有:
通过降低特征图的尺寸,池化层能够减少计算量,从而提升模型的运行效率。
池化操作可以带来特征的平移、旋转等不变性,这有助于提高模型对输入数据的鲁棒性。
池化层通常是非线性操作,例如最大值池化,这样可以增强网络的表达能力,进一步提升模型的性能。
但是池化也有缺点:
池化操作会丢失一些信息,这是它最大的缺点;
3.7 池化API使用
import torch import torch.nn as nn # 1. API 基本使用 def test01(): inputs = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]).float()inputs = inputs.unsqueeze(0).unsqueeze(0) # 1. 最大池化# 输入形状: (N, C, H, W)polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)output = polling(inputs)print(output) # 2. 平均池化polling = nn.AvgPool2d(kernel_size=2, stride=1, padding=0)output = polling(inputs)print(output) # 2. stride 步长 def test02(): inputs = torch.tensor([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]]).float()inputs = inputs.unsqueeze(0).unsqueeze(0) # 1. 最大池化polling = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)output = polling(inputs)print(output) # 2. 平均池化polling = nn.AvgPool2d(kernel_size=2, stride=2, padding=0)output = polling(inputs)print(output) # 3. padding 填充 def test03(): inputs = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]).float()inputs = inputs.unsqueeze(0).unsqueeze(0) # 1. 最大池化polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=1)output = polling(inputs)print(output) # 2. 平均池化polling = nn.AvgPool2d(kernel_size=2, stride=1, padding=1)output = polling(inputs)print(output) # 4. 多通道池化 def test04(): inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],[[10, 20, 30], [40, 50, 60], [70, 80, 90]],[[11, 22, 33], [44, 55, 66], [77, 88, 99]]]).float() inputs = inputs.unsqueeze(0) # 最大池化polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)output = polling(inputs)print(output) if __name__ == '__main__':test04()
4. 整体结构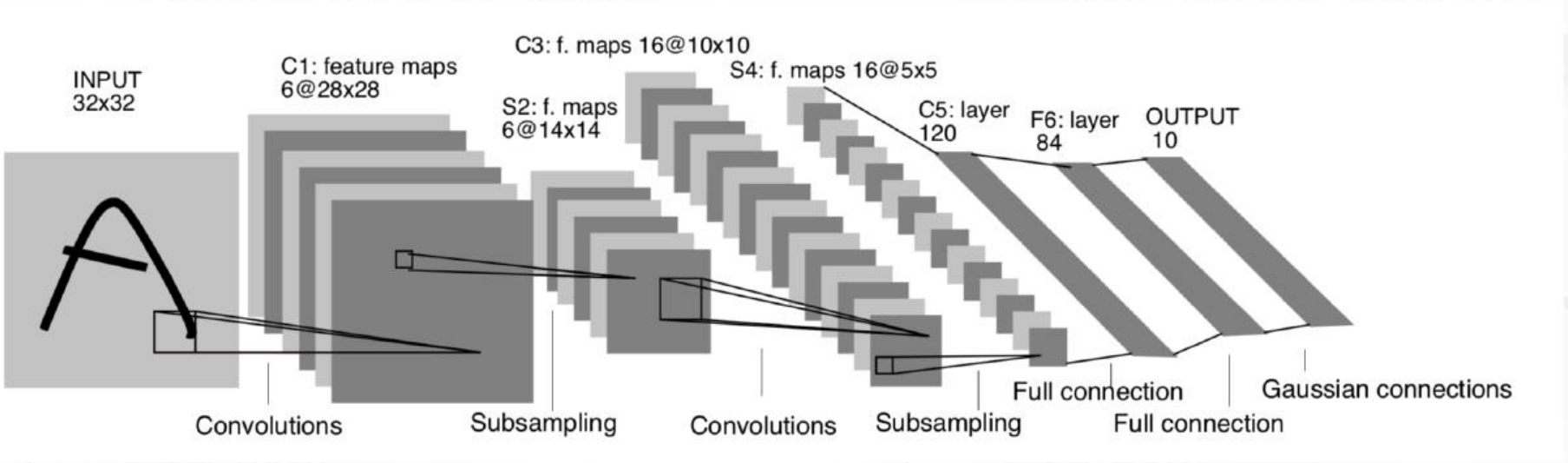
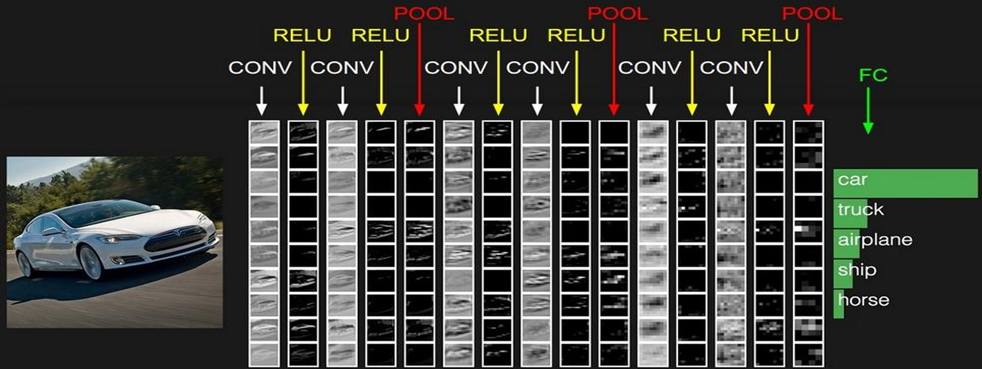
4.1 特征图变化
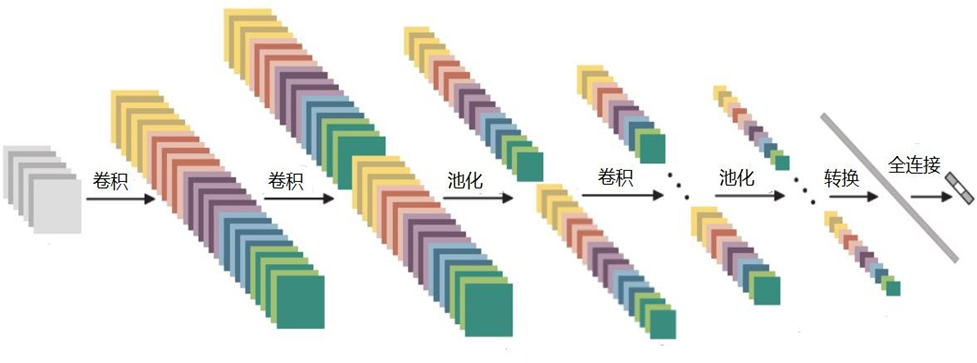
5. 卷积知识扩展
5.1 卷积结果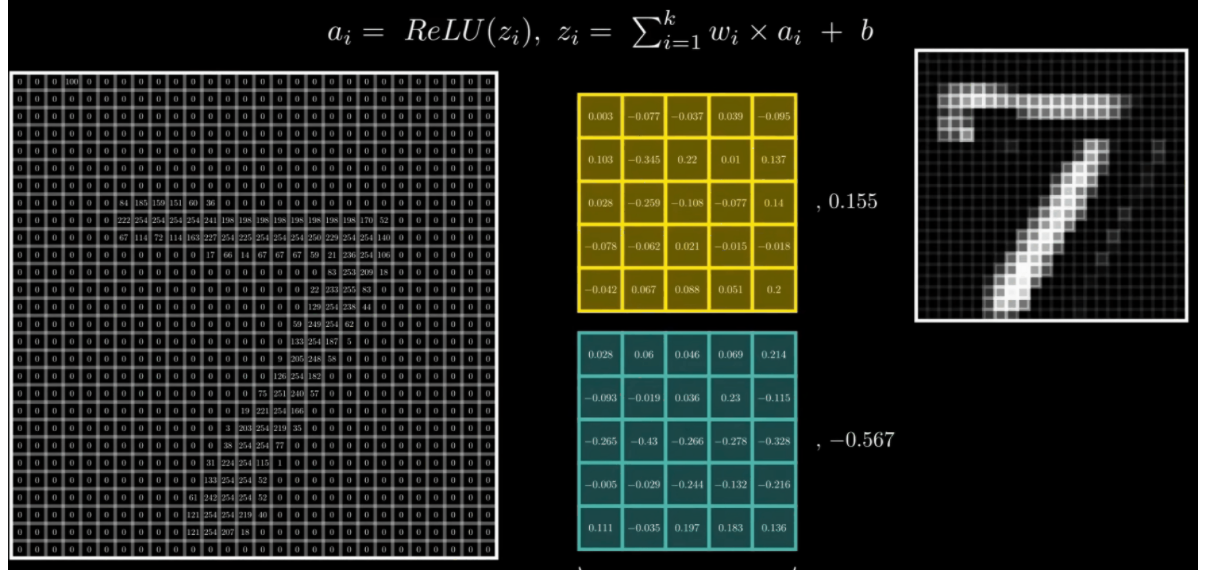
通过上述,可以发现卷积实际上将原本图像中的某一特征进行提取。
5.2 二维卷积
分单通道版本和多通道版本。
5.2.1 单通道版本
之前所讲卷积相关内容其实真正意义上叫做二维卷积(单通道卷积版本),即只有一个通道的卷积。
如下图,我们对于卷积核(kernel)的描述一般是大小3x3、步长(stride)为1、填充(Padding)为0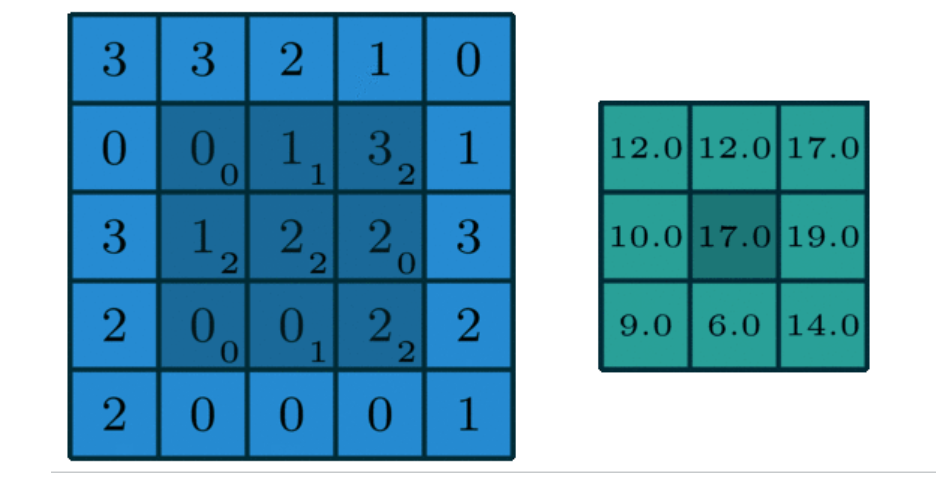
5.2.2 多通道版本
彩色图像拥有R、G、B这三层通道,因此我们在卷积时需要分别针对这三层进行卷积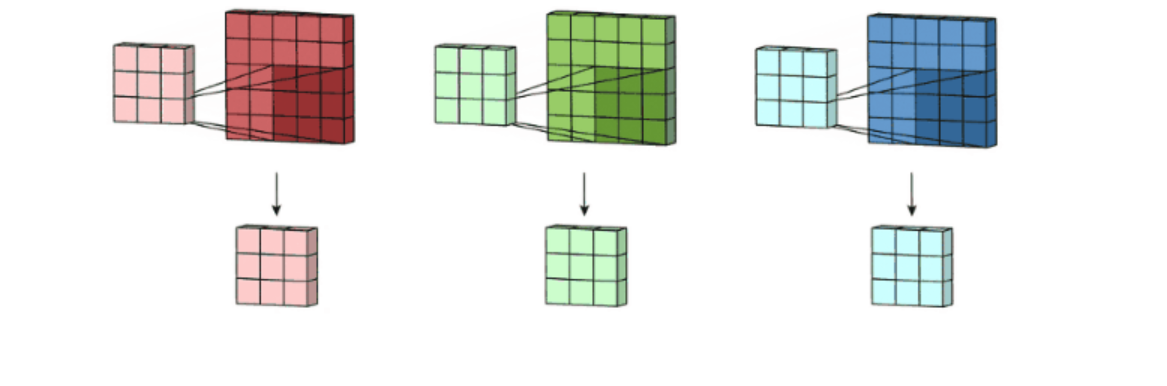
最后将三个通道的卷积结果进行合并(元素相加,就是在通道上进行特征的一个融合操作),得到卷积结果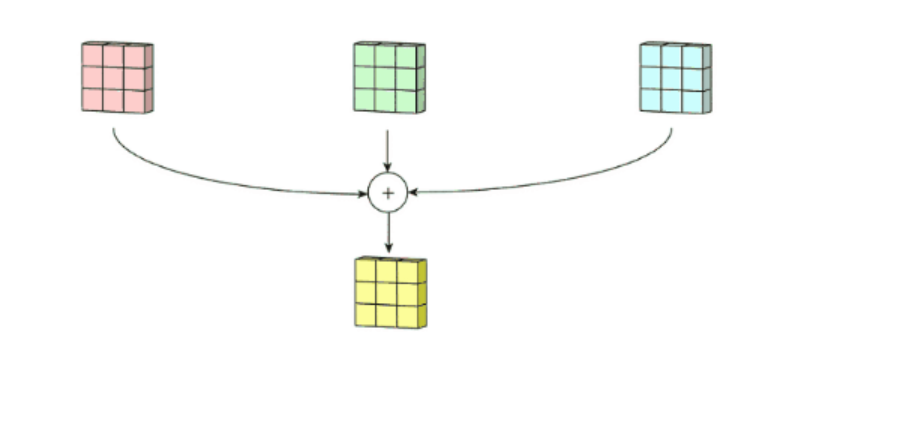
5.3 三维卷积
二维卷积是在单通道的一帧图像上进行滑窗操作,输入是高度H宽度W的二维矩阵。
而如果涉及到视频上的连续帧或者立体图像中的不同切片,就需要引入深度通道,此时输入就变为高度H宽度W*深度C的三维矩阵。
不同于二维卷积核只在两个方向上运动,三维卷积的卷积核会在三个方向上运动,因此需要有三个自由度。
这种特性使得三维卷积能够有效地描述3D空间中的对象关系,它在一些应用中具有显著的优势,例如3D对象的分割以及医学图像的重构等。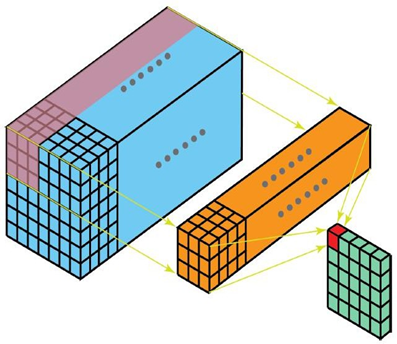
5.4 反卷积
卷积是对输入图像及进行特征提取,这样会导致尺寸会越变越小,而反卷积是进行相反操作。并不会完全还原到跟输入图一样,只是保证了与输入图像尺寸一致,主要用于向上采样。从数学上看,反卷积相当于是将卷积核转换为稀疏矩阵后进行转置计算。也被称为转置卷积。
5.4.1 反卷积计算过程
如图,在2x2的输入图像上使用【步长1、边界全0填充】的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4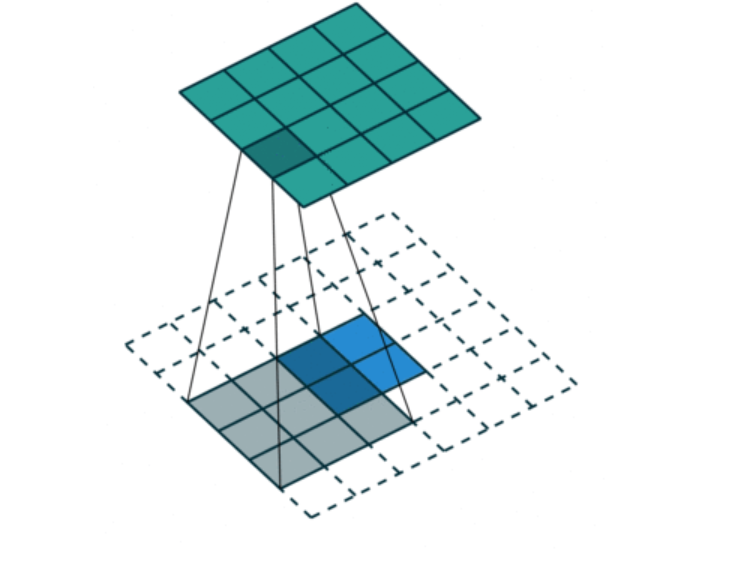
如我们的语义分割里面就需要反卷积还原到原始图像大小。
5.4.2 反卷积底层计算
反卷积的计算过程如下图: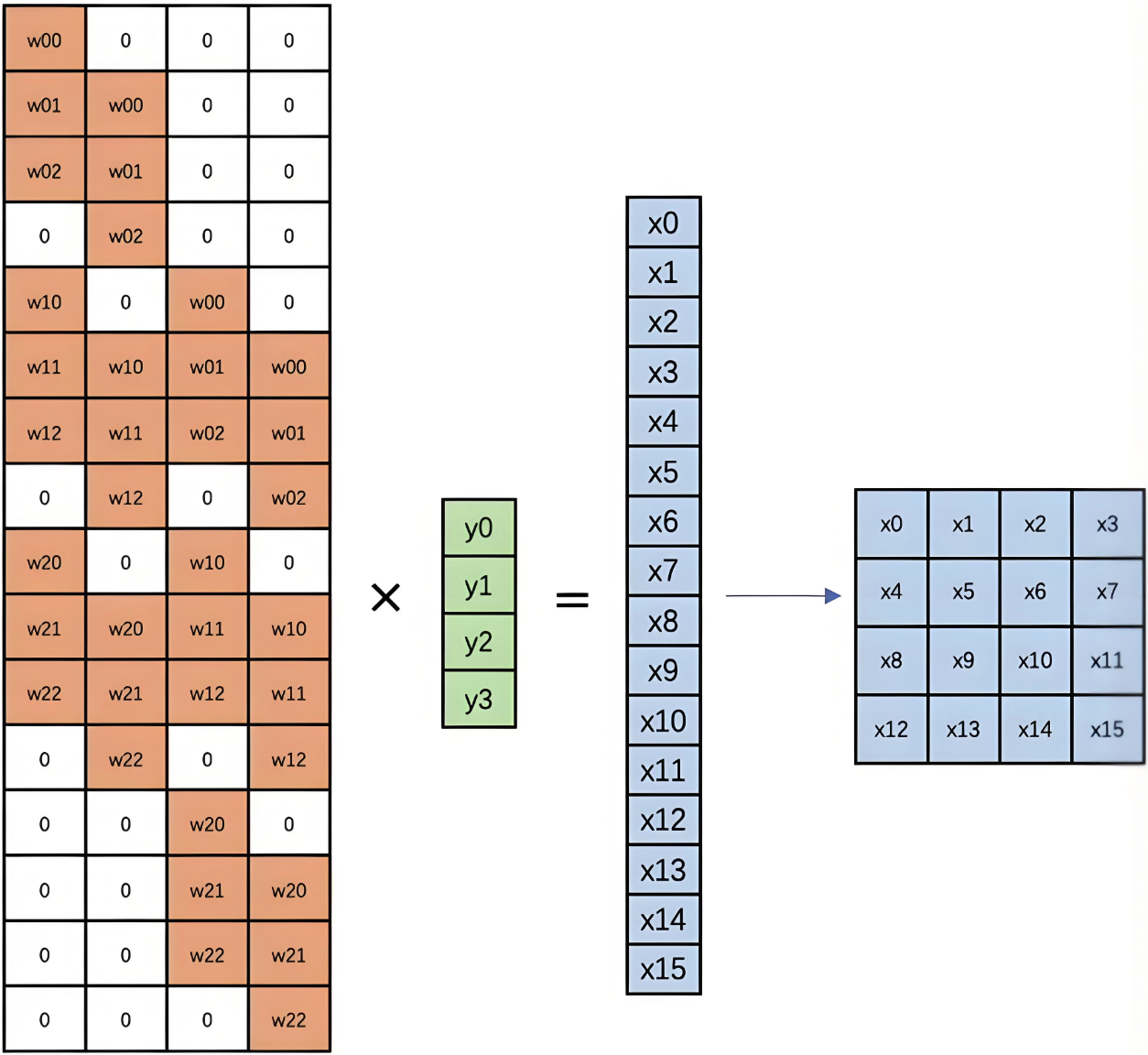
5.5 膨胀卷积
也叫膨胀卷积。为扩大感受野,在卷积核的元素之间插入空格“膨胀”内核,形成空洞卷积,并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,内核元素之间没有插入空格,变为标准卷积。图中是L=2的空洞卷积。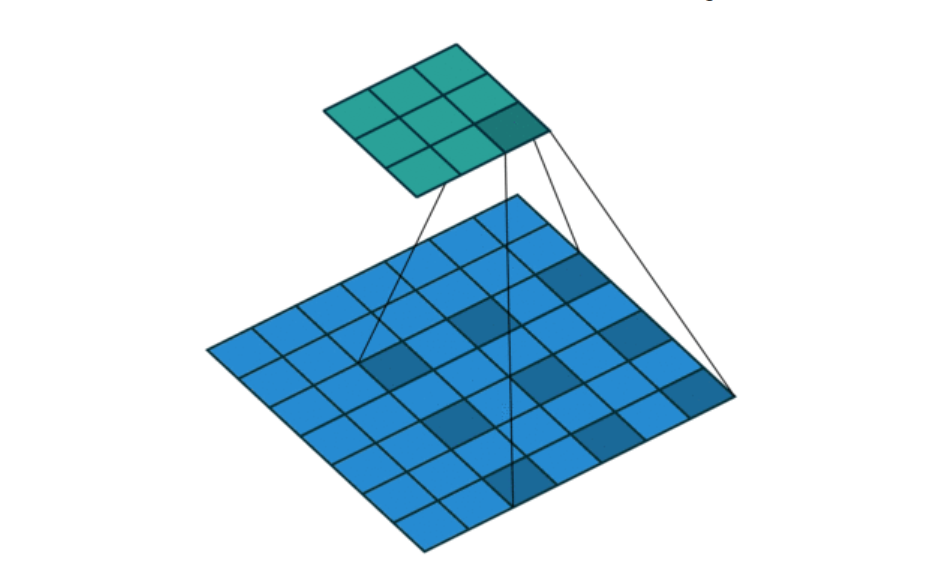
5.6 可分离卷积
5.6.1 空间可分离卷积
空间可分离卷积是将卷积核分解为两项独立的核分别进行操作。在数学中我们可以将矩阵分解:
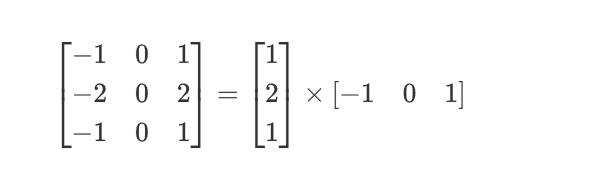
所以对3x3的卷积核,我们同样可以拆分成 3x1 和 1x3 的两个卷积核,对其进行卷积,且采用可分离卷积的计算量比标准卷积要少。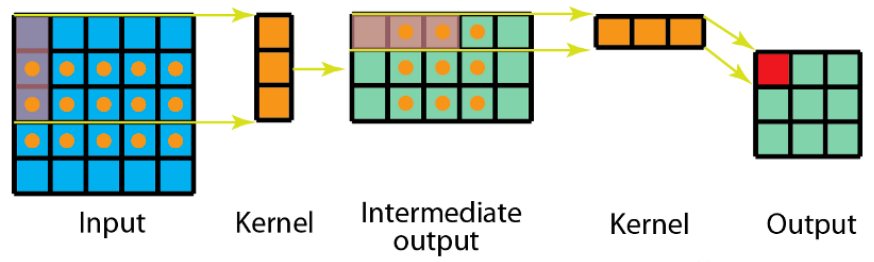
5.6.2 深度可分离卷积
深度可分离卷积由两部组成:深度卷积核1\times1卷积,我们可以使用Animated AI官网的图来演示这一过程
图1:输入图的每一个通道,我们都使用了对应的卷积核进行卷积。 通道数量 = 卷积核个数,每个卷积核只有一个通道
图2:完成卷积后,对输出内容进行1x1的卷积
5.7 扁平卷积
扁平卷积是将标准卷积拆分成为3个1x1的卷积核,然后再分别对输入层进行卷积计算。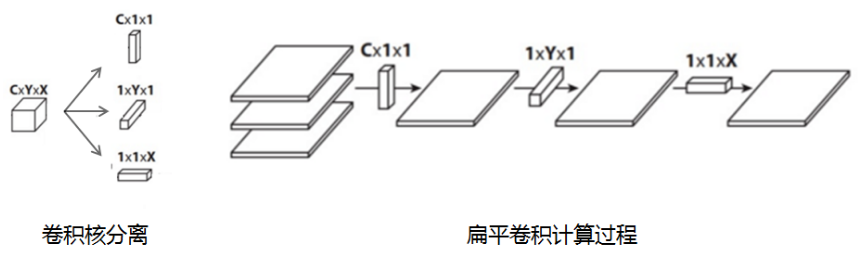
标准卷积参数量XYC,计算量为MNCXY
拆分卷积参数量(X+Y+C),计算量为MN(C+X+Y)
5.8 分组卷积
2012年,AlexNet论文中最先提出来的概念,当时主要为了解决GPU显存不足问题,将卷积分组放到两个GPU中并行执行。
在分组卷积中,卷积核被分成不同的组,每组负责对相应的输入层进行卷积计算,最后再进行合并。
下图中卷积核被分成两个组,前半部负责处理前半部的输入层,后半部负责后半部的输入层,最后将结果组合。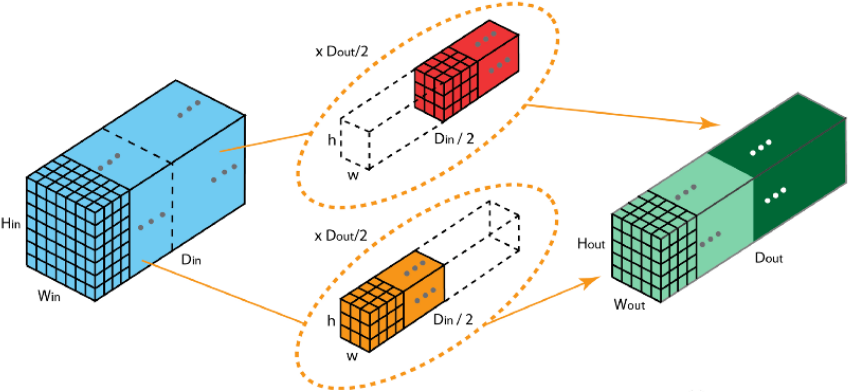
分组卷积中:
输入通道被划分为若干组。
每组通道只与对应的卷积核计算。
不同组之间互相独立,卷积核不共享。
5.9 混洗分组卷积
分组卷积中最终结果会按照原先的顺序进行合并组合,阻碍了模型在训练时特征信息在通道间流动,削弱了特征表示。混洗分组卷积,主要是将分组卷积后的计算结果混合交叉在一起输出。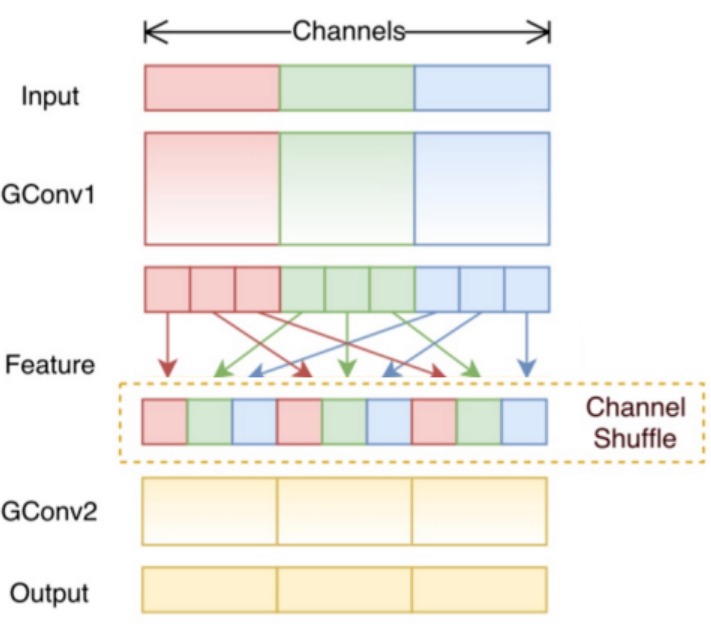
6.感受野
6.1 理解感受野
字面意思是感受的视野范围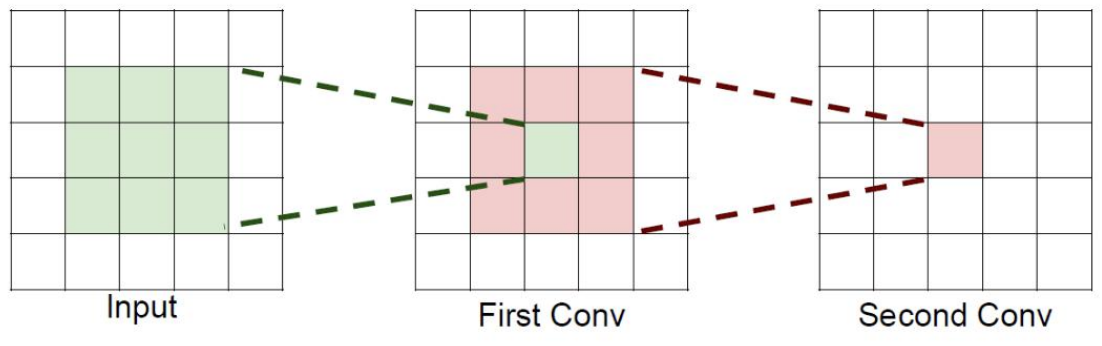
如果堆叠3个3 x 3的卷积层,并且保持滑动窗口步长为1,其感受野就是7×7的了, 这跟一个使用7x7卷积核的结果是一样的,那为什么非要堆叠3个小卷积呢?
6.2 感受野的作用
假设输入大小都是h × w × C,并且都使用C个卷积核(得到C个特征图),可以来计算 一下其各自所需参数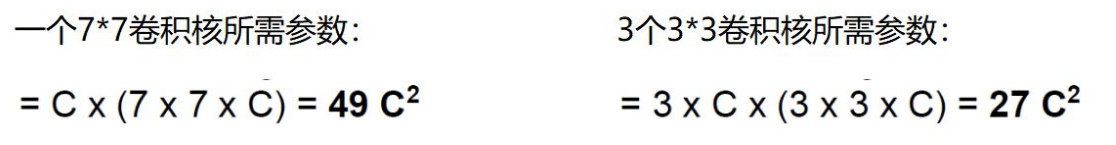
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换也随着增多,还不会增大权重参数个数,用小的卷积核来完成体特征提取操作。
7.卷积神经网络案例
7.1 模型结构
网络结构如下: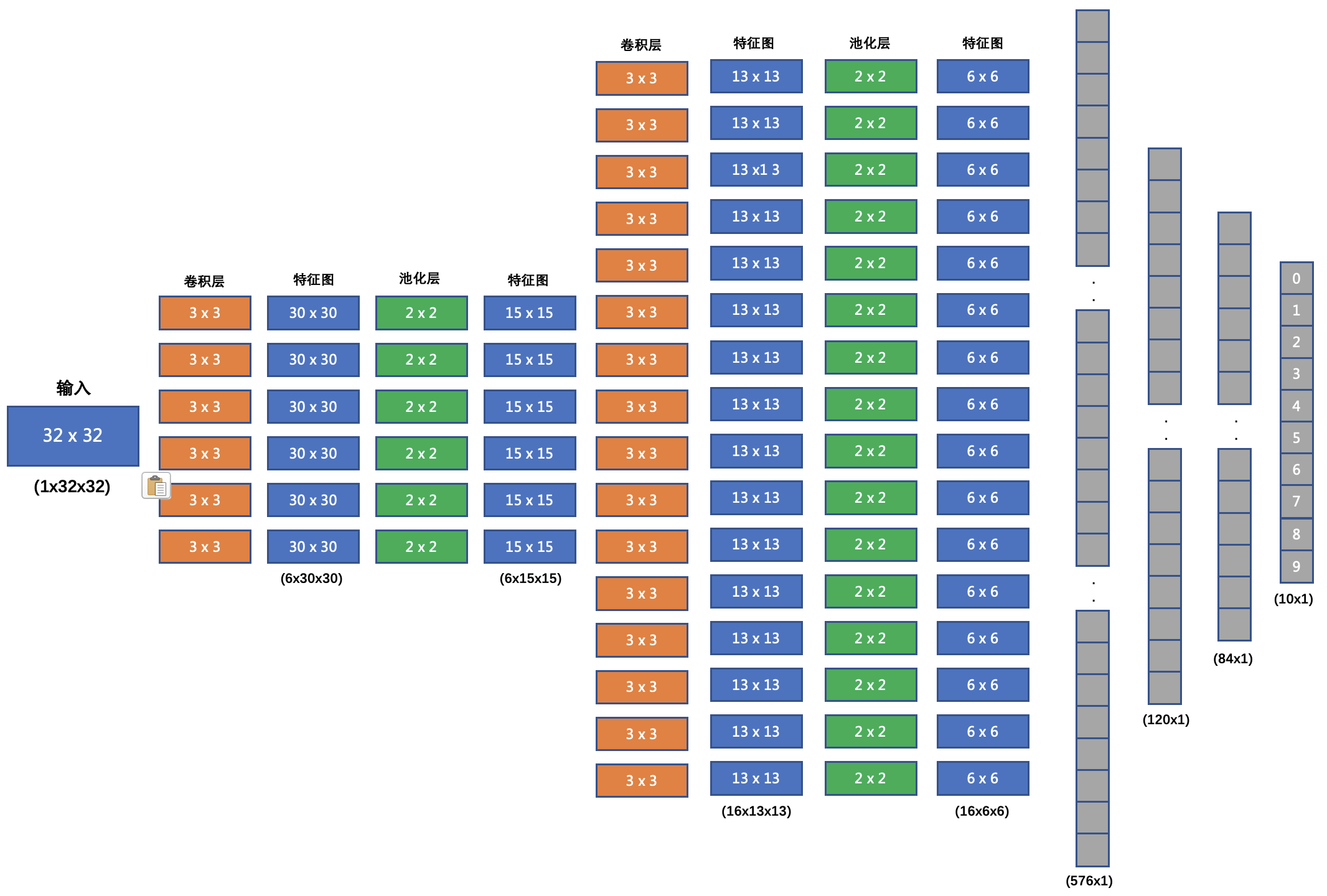
输入形状: 32x32
第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
第一个全连接层输入 576 维, 输出 120 维
第二个全连接层输入 120 维, 输出 84 维
最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
7.2 网络模型定义
import torch import torch.nn as nn class ImageClassification(nn.Module):def __init__(self):super(ImageClassification, self).__init__()# 这是一层卷积层self.layer1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Dropout(0.25),) self.layer2 = nn.Sequential(nn.Conv2d(in_channels=32, out_channels=128, kernel_size=3, stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Dropout(0.25),) self.linear1 = nn.Sequential(nn.Linear(128 * 6 * 6, 2048), nn.ReLU(), nn.Dropout(0.5)) self.linear2 = nn.Sequential(nn.Linear(2048, 1024), nn.ReLU(), nn.Dropout(0.5)) self.out = nn.Linear(1024, 10) def forward(self, x):x = self.layer1(x)x = self.layer2(x)x = x.reshape(x.size(0), -1)x = self.linear1(x)x = self.linear2(x)return self.out(x)
7.3 用到的模块
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torchvision.datasets import CIFAR10 from torchvision.transforms import Compose, ToTensor from torch.utils.data import DataLoader import os import time # 从modele目录导入模型 from model.image_classification import ImageClassification
7.4 CIFAR10数据源
def test001():dir = os.path.dirname(__file__)# 加载数据集train = CIFAR10(root=os.path.join(dir, "data"),train=True,download=True,transform=Compose([ToTensor()]),)
vaild = CIFAR10(root=os.path.join(dir, "data"),train=False,download=True,transform=Compose([ToTensor()]),)
# 观察一下数据集信息print("训练数据集数量:", train.__len__())# 观察一下数据集分类情况print("训练数据集分类情况:", train.class_to_idx)
train_loader = DataLoader(train, batch_size=128, shuffle=True)vaild_loader = DataLoader(vaild, batch_size=128, shuffle=True)for i, (x, y) in enumerate(train_loader):print(i, x.shape, y.shape)7.5 模型训练及保存
def train():dir = os.path.dirname(__file__)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载数据集train = CIFAR10(root=os.path.join(dir, "data"),train=True,download=True,transform=transform,)# 导入模型model = ImageClassification()model.to(device)# 定义i模型训练的超参数epochs = 80lr = 1e-3batch_size = 256loss_history = []# 构建训练用的损失函数及优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=lr)for i, epoch in enumerate(range(epochs)):# 构建训练数据批次train_loader = DataLoader(train, batch_size=batch_size, shuffle=True)# 记录样本数量train_num = 0# 记录总的损失值:用于计算平均损失total_loss = 0.0# 记录正确记录数correct = 0# 记录训练开始时间start = time.time()# 开始使用批次数据进行训练for x, y in train_loader:# 更改模型训练设备x = x.to(device)y = y.to(device)# 送入模型output = model(x)# 计算损失loss = criterion(output, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新参数optimizer.step()# 更新训练过程的数据train_num += len(y)total_loss += loss.item() * len(y)correct += output.argmax(1).eq(y).sum().item()
print("epoc:%d loss:%.3f accuracy:%.3f time:%.3f"% (i + 1, total_loss / train_num, correct / train_num, time.time() - start))loss_history.append(total_loss / train_num)# 更新图形update_plot(loss_history)# 训练完成之后,保存模型torch.save(model.state_dict(), os.path.join(dir, "model.pth"))print("模型保存成功:", i)
7.6 模型加载及验证
# 测试集评估
def vaild():dir = os.path.dirname(__file__)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 定义超参数batch_size = 100# 定义测试记录数据vaild_num = 0total_correct = 0
vaild_data = CIFAR10(root=os.path.join(dir, "data"),train=False,download=False,transform=transform,)# 构建测评数据集批次vaild_loader = DataLoader(vaild_data, batch_size=batch_size, shuffle=False)model = ImageClassification()# 加载模型参数model.load_state_dict(torch.load(os.path.join(dir, "model.pth")))# 切换为验证模式model.to(device)model.eval()for x, y in vaild_loader:x = x.to(device)y = y.to(device)output = model(x)total_correct += output.argmax(1).eq(y).sum().item()vaild_num += len(y)
print("测试集正确率:%.3f" % (total_correct / vaild_num))
我们可以从以下几个方面来调整网络:
增加卷积核输出通道数
增加全连接层的参数量
调整学习率
调整优化方法
修改激活函数
进行数据增强,等等
7.7 数据增强
data_transforms = {'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选transforms.CenterCrop(224),#从中心开始裁剪transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差]),'valid': transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}
from torchvision import transforms
from PIL import Image
# 定义图像预处理步骤
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 打开图像
img = Image.open("path_to_image.jpg")
# 应用预处理步骤
img_tensor = preprocess(img)
7.8 实时渲染训练效果
# 更新图形的函数
def update_plot(loss_history):plt.cla() # 清除之前的图形plt.plot(loss_history, marker="o", color="green", linestyle="-") # 绘制损失率曲线plt.xlabel("Epoch")plt.ylabel("Loss")plt.title("Training Loss")plt.grid(True)plt.pause(0.001) # 暂停一段时间以便更新图形
# 开始训练模型并动态显示损失率变化plt.ion() # 打开交互模式train()plt.ioff() # 关闭交互模式plt.show()#在训练的时候实时更新数据
loss_history = []
loss_history.append(total_loss / train_num)
# 更新图形
update_plot(loss_history)

)



![[吾爱原创] 千千每日计划](http://pic.xiahunao.cn/[吾爱原创] 千千每日计划)
)
)





)
![[光学原理与应用-337]:ZEMAX - 自带的用于学习的样例设计](http://pic.xiahunao.cn/[光学原理与应用-337]:ZEMAX - 自带的用于学习的样例设计)




)