目的
最近做一个加密方面的研究,加密之后的二进制,通过转码之后,再也找不回之前的二进制了。
怎么试都不行,真是非常得奇怪!!!!

先说说字符编码基础知识
在信息技术的海洋中,字符编码是数据表示的基本桥梁,它使计算机能够存储和传输文本信息。字符编码的本质,是对字符集进行数字化的一种方式,通过特定的编码规则将文字转换为计算机可以处理的二进制代码。理解字符编码的工作原理对于从事软件开发、数据处理等IT行业的专业人员来说至关重要。
字符集与编码
字符集是一组符号和编码的集合,而编码则是这些字符集的数字化表示(这句话有理,编码就是二进制,转化编码就是更改二进制)。不同的编码方式有不同的特性,它们决定了数据存储、网络传输及文件处理的效率和范围。
常见字符编码
字符编码的种类繁多,常见的包括ASCII、GBK、UTF-8等。每种编码都有其特定的使用背景和适用场景。掌握这些基础知识,有助于我们更好地处理国际化文本、网络数据交换等问题。
情况分析
实例分析

点击加密之后显示:

点击解密之后:

解密里没显示什么,后台提示了报错:
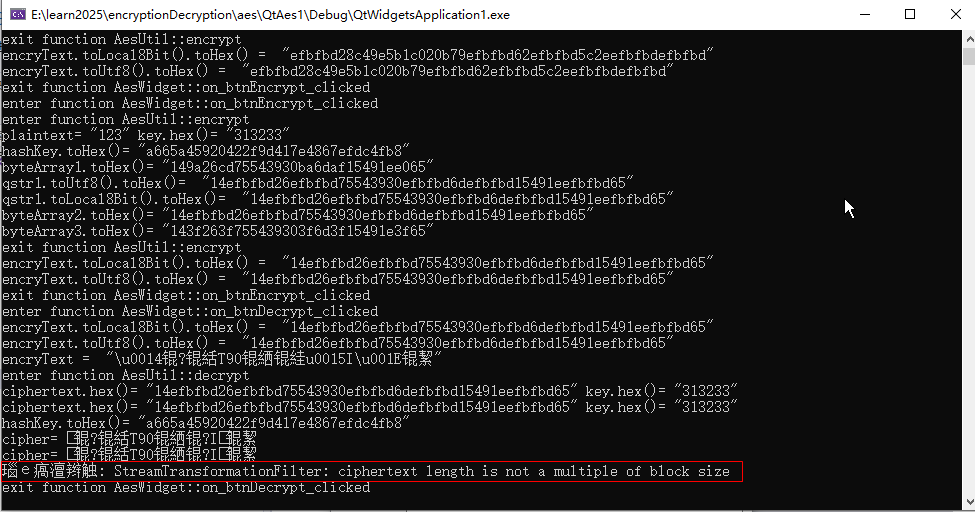
怎么回事,那就跟踪代码看看情况:
先看加密的代码:
源码如下:
QByteArray AesUtil::encrypt(const QString& plaintext, const QString& key) {qDebug("enter function AesUtil::encrypt");qDebug()<< "plaintext="<< plaintext << "key.hex()=" << key.toLocal8Bit().toHex();try {QByteArray hashKey = QCryptographicHash::hash(key.toUtf8(),QCryptographicHash::Sha256);hashKey = hashKey.left(16);qDebug() << "hashKey.toHex()=" << hashKey.toHex();//std::string plain = qtToStdString(plaintext);std::string plain = plaintext.toUtf8();//std::string plain2 = plaintext.toUtf8().constData();//std::string keyStr = qtToStdString(key);byte iv[CryptoPP::AES::BLOCKSIZE] = { 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16};CryptoPP::CBC_Mode<CryptoPP::AES>::Encryption encryptor((byte*)hashKey.data(), hashKey.size(), iv);std::string cipher;CryptoPP::StringSource(plain, true,new CryptoPP::StreamTransformationFilter(encryptor,new CryptoPP::StringSink(cipher)));// 将二进制密文转换为十六进制字符串便于显示和传输/*string encoded;StringSource(cipher, true,new HexEncoder(new StringSink(encoded)));*/QByteArray ar1 = QByteArray::fromStdString(cipher);std::string cipher2 = ar1.toStdString();QString str1 = QString::fromLocal8Bit(cipher.c_str());QString str3 = QString::fromUtf8(cipher.c_str());QString str2 = ar1;QByteArray byteArray1 = QByteArray::fromStdString(cipher);qDebug() << "byteArray1.toHex()=" << byteArray1.toHex();QString qstr1 = QString::fromUtf8(byteArray1);qDebug() << "qstr1.toUtf8().toHex()= " << qstr1.toUtf8().toHex();qDebug() << "qstr1.toLocal8Bit().toHex()= " << qstr1.toLocal8Bit().toHex();QByteArray byteArray2 = qstr1.toUtf8();qDebug() << "byteArray2.toHex()=" << byteArray2.toHex();QByteArray byteArray3 = qstr1.toLatin1();qDebug() << "byteArray3.toHex()=" << byteArray3.toHex();qDebug("exit function AesUtil::encrypt");return QByteArray::fromStdString(cipher);}catch (const CryptoPP::Exception& e) {cerr << "加密失败: " << e.what() << endl;return "";}qDebug("exit function AesUtil::encrypt");
}
跟踪代码的情况:
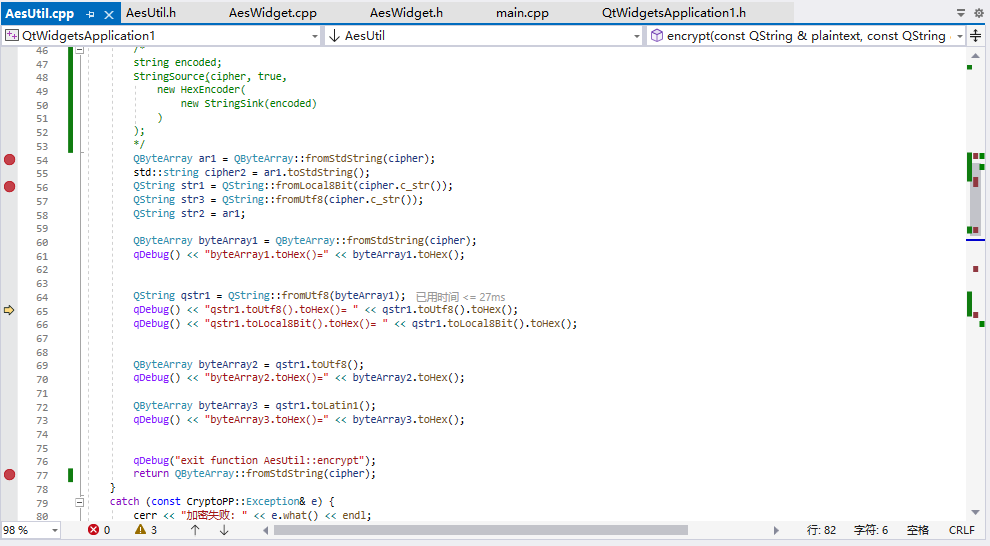
调试情况:
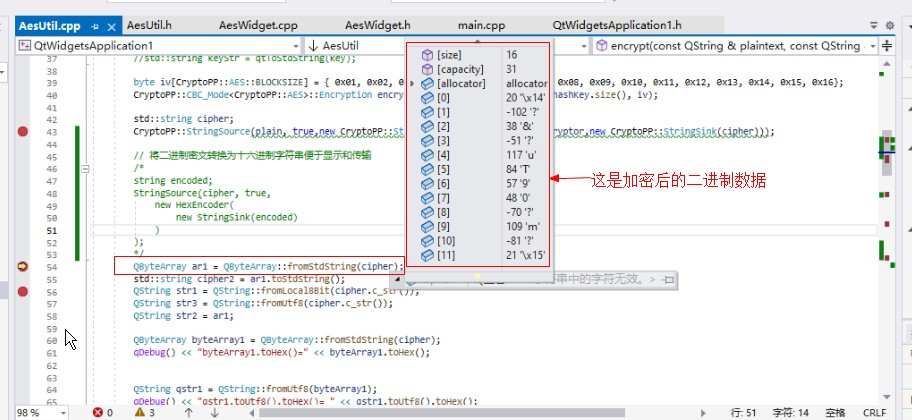
下面把密文转化为QByteArray类型:
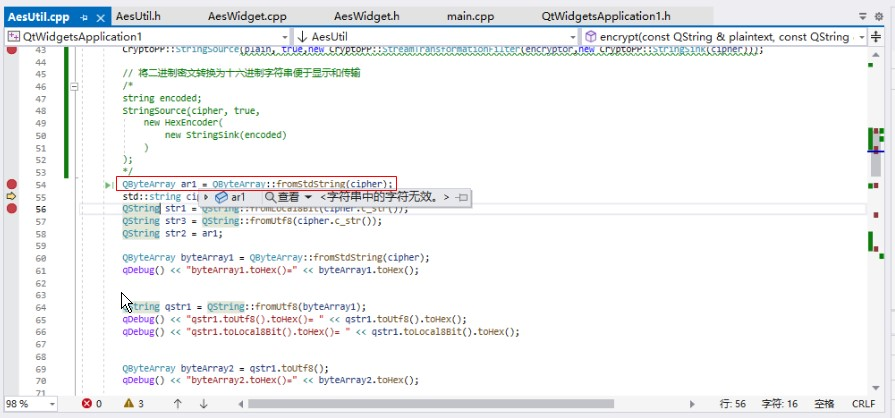
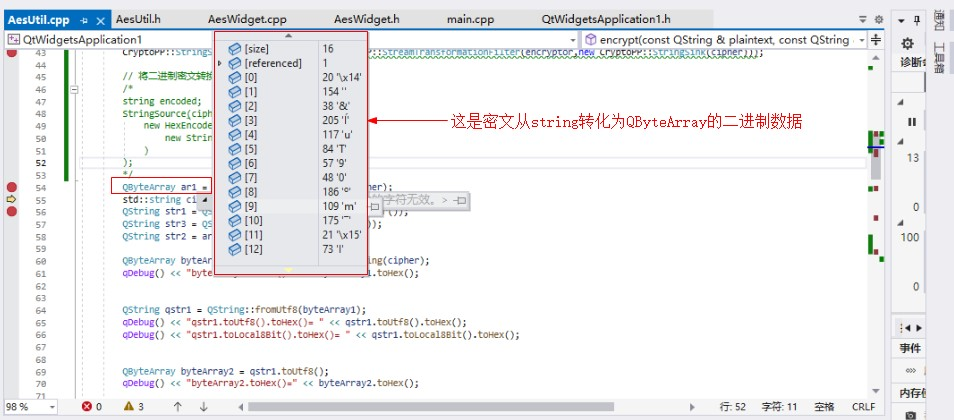
QByteArray的数据与原始二进制数据是一致的,因为负号的处理方式不同,所以有些显示不一样,但二进制数据是一样的。
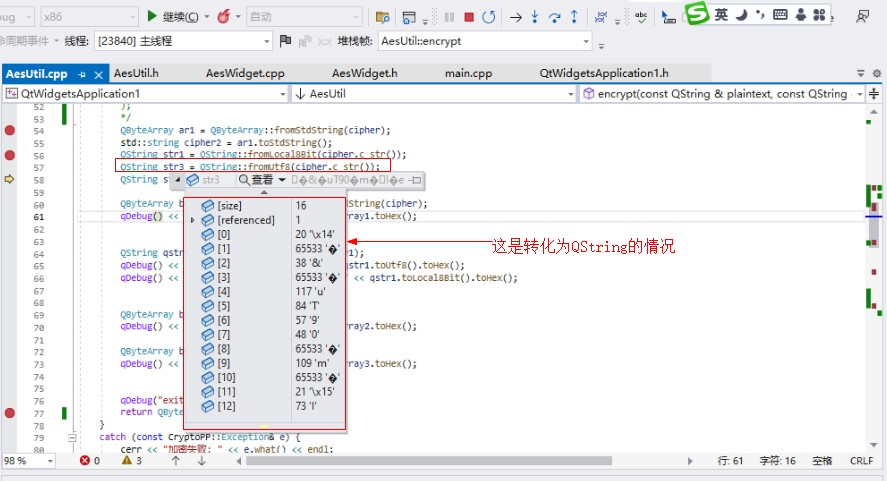
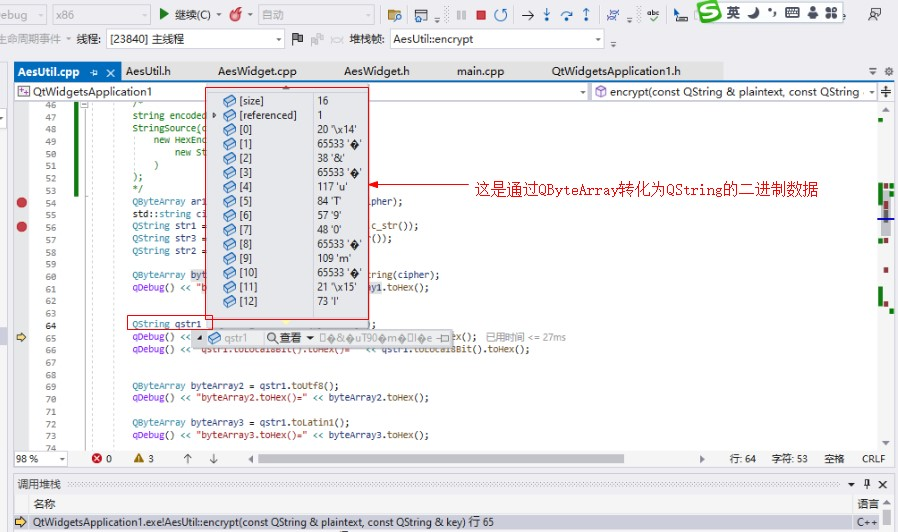
到了QString数据明显不一样了,但表示的编码是一致的。
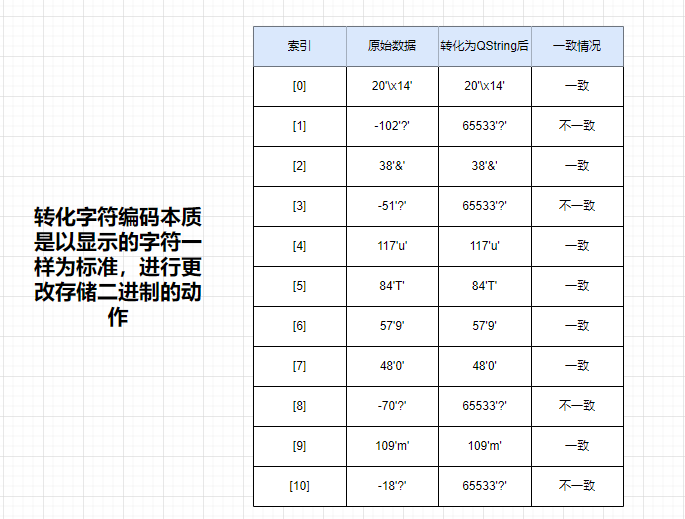
可以对比一下看看:(第一张图是原始加密二进制数据,第二张图是转化为QString的加密二进制数据)
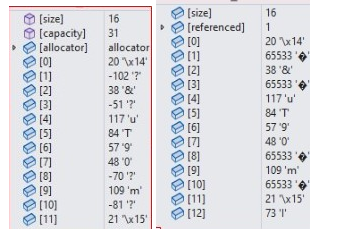
上面最显著的区别是:原始数据[1][3][8][10]数值是不一样的,但到了QString 却成了一样的了是65533,并且都显示为?号。
这证明了QString进行了utf8的转化,这种编码转化是以字符为标准的进行更改相应的二进制数,也可以说是以显示的东西为标准,更改后面的二进制数,当然,也有相同的,相同是因为巧合而已,所以这说明了,要想保持二进制一样,就不能进行编码相关的转化。
因为编码的本质是以显示的东西一样为要求,对存储的二进制数进行更改。
解密时变化会更为明显:
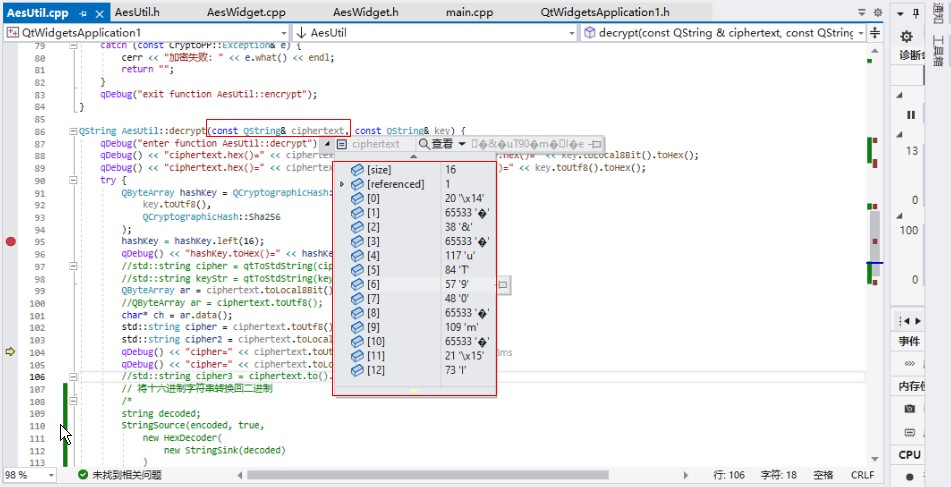
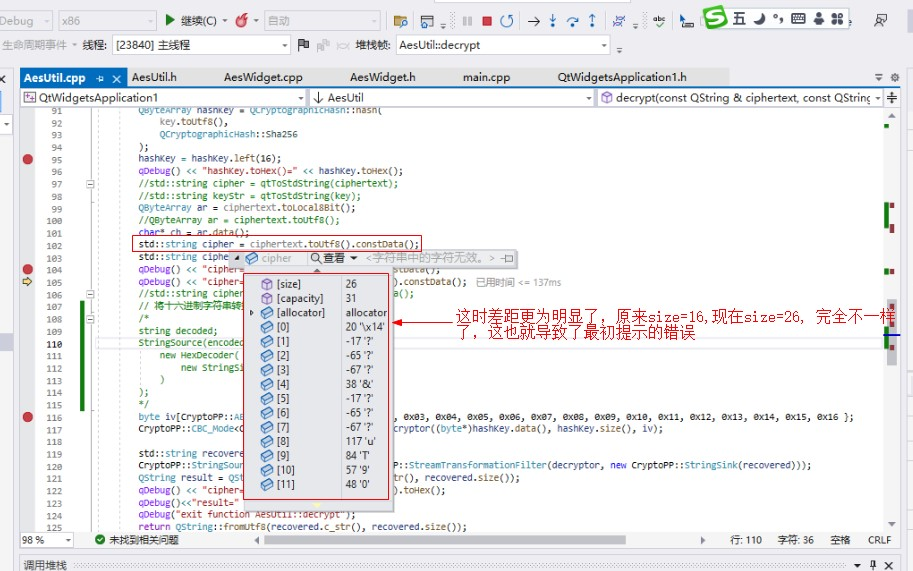
解码的相关代码:
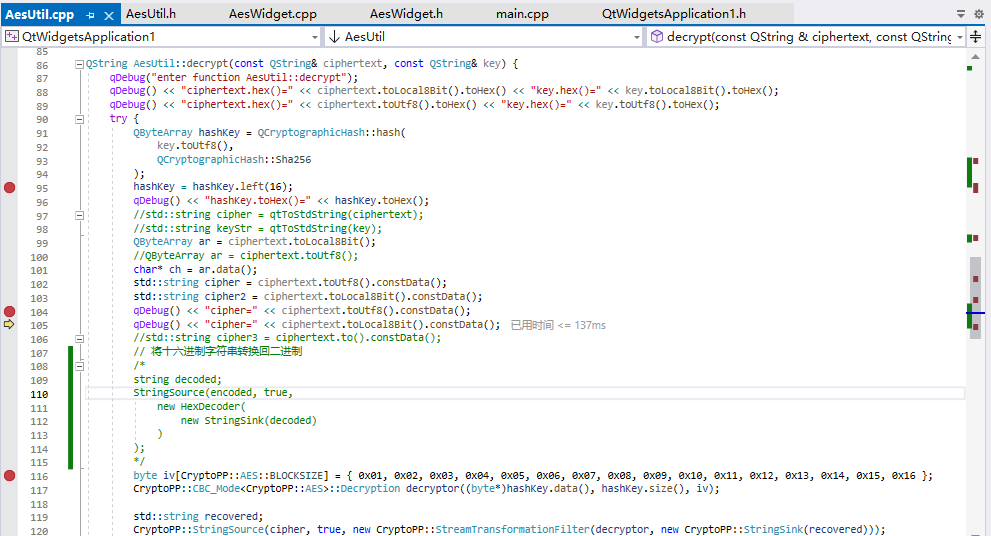
关于常用的编码
UTF-8 和 GBK 编码的本质区别在于字符集覆盖范围和编码方式:
字符集覆盖范围
GBK:基于 GB2312 扩展,支持21003个汉字及682个符号,主要用于中文信息处理。
UTF-8:基于 Unicode 标准,理论上支持任何字符(包括中文、英文、数字等),兼容 ASCII 字符,广泛应用于多语言场景。
编码方式
GBK:采用双字节编码,首字节为0x81-0xFE,尾字节为0x40-0xFE,通过高位字节扩展汉字数量。
UTF-8:可变长度编码(1-4字节),第一个字节与ASCII兼容,后续字节用于扩展字符范围。
应用场景
GBK:适合中文系统内部处理(如Windows系统默认中文编码)。
UTF-8:优先用于国际化和跨平台数据交换(如网页、邮件)。
总结
之所以出现了上面的错误,还是没理解字符编码的本质,编码就是用数字对应字符,就是这么简单。
比如ASCII编码:
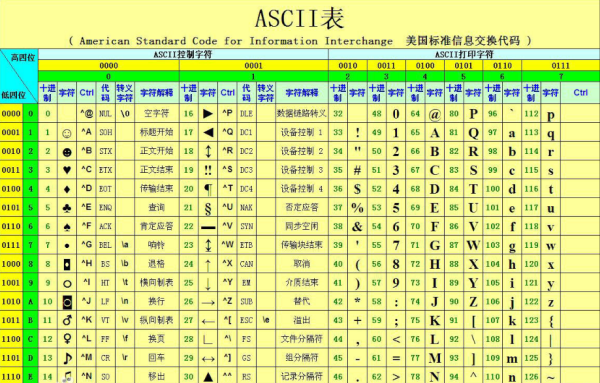
最后总结:



)
)




)







)

