自主构建智慧科研写作系统——融合LLM语义理解、多智能体任务协同与n8n自动化工作流
n8n 是一款开源的 工作流自动化工具,类似于 Zapier 或 Make(原 Integromat),但更注重灵活性和开发者友好性。在课程文件中提到的 n8n 自动化流水线 主要用于科研写作的自动化流程集成,以下是详细解释:
n8n 的核心功能
可视化工作流设计:通过拖拽节点(Nodes)连接不同工具和服务,无需编写复杂代码即可搭建自动化流程。
多平台集成:支持连接文献数据库(如 PubMed、arXiv)、AI 模型(如 OpenAI、DeepSeek)、邮件、云存储等数百种 API。
触发式执行:可根据条件(如新文献发布、定时任务)自动触发后续操作(如摘要生成、论文草稿撰写)。
n8n 搭建科研写作的 “全链路自动化流水线”,具体包括:
文献检索:自动从 PubMed/arXiv 抓取最新论文。
内容生成:调用 LLM(如 ChatGPT)生成摘要或论文大纲。
多 Agent 协同:与 AutoGen/LangChain 的 Agent 交互,传递任务(如写作→校对)。
质量检测与润色:自动触发语言优化或学术规范性检查。
技术优势
低代码/高灵活性:适合科研人员快速实现定制化流程,无需深入编程。
本地化部署:n8n 可自托管,保障数据隐私(适合处理敏感科研数据)。
与 AI 工具无缝衔接:直接调用 OpenAI API 或本地部署的 LLM(如 OLLAMA)
随着多智能体协同架构、大语言模型(LLM)与自动化工具链的快速发展,科研写作正从“人工主导”向“智能赋能”加速转型。本课程深度融合LLM(ChatGPT/DeepSeek等)、多智能体系统(AutoGen/LangChain)及n8n自动化流水线,直击科研学者三大核心痛点——文献检索耗时、写作流程割裂、成果打磨低效,打造“全链路智能写作解决方案”。
技术特色上,构建“多Agent协同+自动化”双引擎,通过AutoGen设计规划、写作、校对Agent集群,实现论文结构自动生成与内容协同创作;依托n8n搭建“文献更新→自动写作→质量检测→润色定稿”的触发式流水线,彻底解放重复劳动。科研学者学习后,可一键获取文献摘要、自动生成论文框架、自动优化语言表达,效率提升300%,同时借助LoRA微调与RAG增强技术,保障学术内容的准确性与专业性。
以“实战落地”为核心,七章内容从LLM原理与科研痛点解析起步,逐步深入文献检索Agent(集成PubMed/arXiv API)、写作协同Agent(多Agent任务规划)、n8n自动化流水线搭建、模型微调与Prompt工程等核心技术模块,每章均含代码实操(如OpenAI API摘要生成、n8n工作流演示)与真实案例演练,从理论到系统开发全面掌握。无论是高校教师快速产出高质量论文,还是科研人员高效管理多项目写作,亦或AI开发者掌握前沿系统架构,本问均为稀缺赋能平台。
目 标:
1、掌握大型语言模型与多智能体系统的科研写作应用
2、掌握LangChain、AutoGen等多Agent协作框架
3、结合Agent实现科研自动化创新
4、用n8n等工具搭建写作自动化流水线
5、实现文献检索、自动摘要、论文结构规划、多Agent协同写作与内容润色
第一章、AI Agent科研写作系统框架介绍
1.AI Agent科研系统简介(通过不同Agent协同合作提供创新点和论文初稿)
2.为什么需要AI Agent?(AI Agent能有效的帮我们节省时间,提高效率,并且提供一定的科研创新能力。)
3.目前主流的LangChain结合RAG(检索增强生成),Fine-Tuning(微调),LoRA技术实现AI Agent。(有效提高准确性和效率)
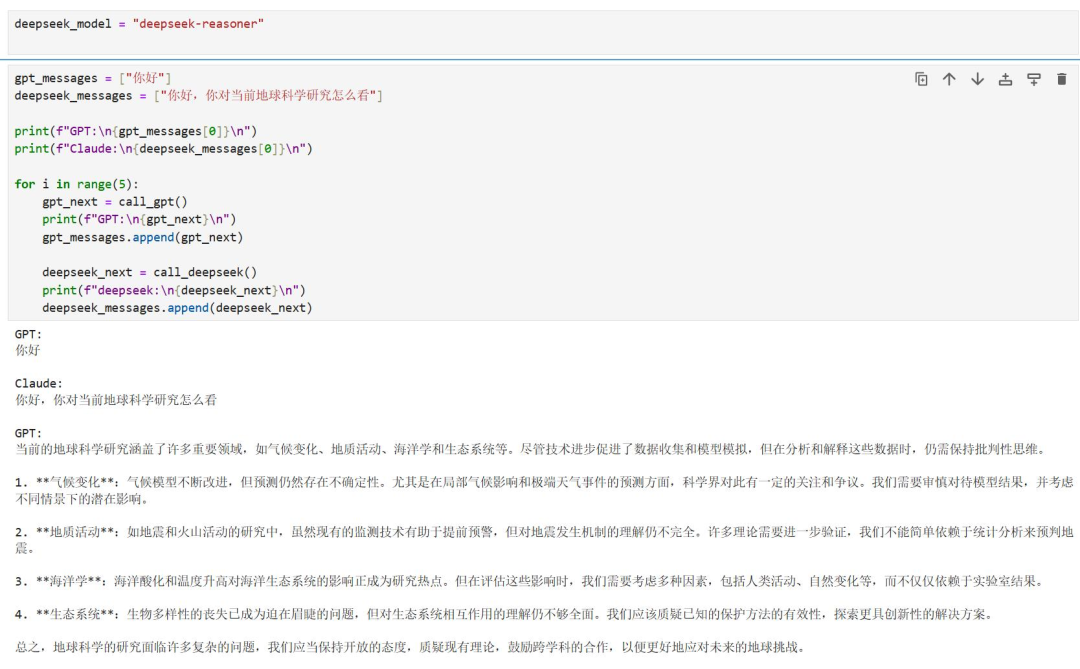
案例:通过不同大模型的API接口,通过多个大模型多轮次对话的方式,创新性给出相关学科领域的内容。(本案例可以通过调用API接口,使ChatGPT和deepseek同时工作,发挥两者优势)
第二章、环境平台的安装与配置
1.Anaconda的下载和安装(通过jupyter Notebook调用不同大模型API接口)
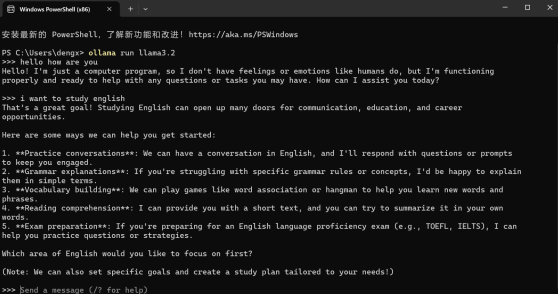
2.Ollama的下载和安装(本地部署开源大模型如deepseek和llama,有效保护数据隐私性)
3.HuggingFace等开源大模型平台和数据集的使用(准确评估不同前沿大模型作用)
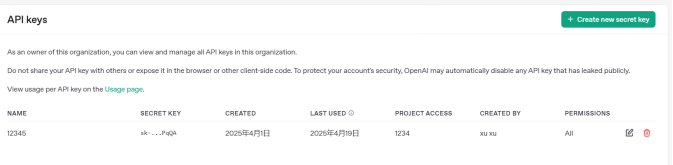
4.不同大模型的API KEY配置方法(通过API KEY可以使用其大模型算力)
案例:大模型API KEY配置
第三章、AI Agent创建与实例操作
1.什么是AI Agent(AI Agent是通过agent和大模型结合具有人类一定能力的智能体)。
2.为什么需要AI Agent(AI Agent可以多个AI Agent结合解决复杂问题,并具有自主决策能力,大大的提高人类的效率)
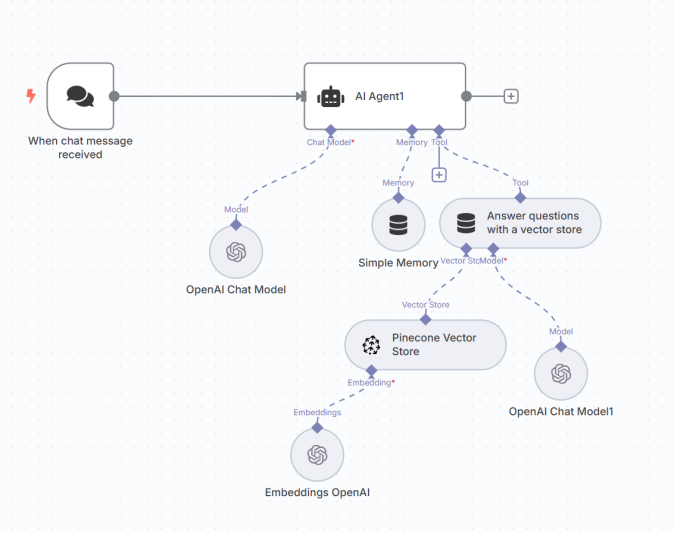
3.怎么创建AI Agent(通过API KEY在python语言平台或n8n平台使用其算力)
第四章、RAG(检索增加生成)技术与实例操作
1.检索增加生成技术介绍(向量化专业知识存储数据库,大模型检索其数据库)
2.检索增加生成技术提高专业性和准确性(通过AI Agent自动检索其专业知识,给大模型提供更精准的专业信息)
3.LangChain技术和N8N流的方式执行RAG技术.(其结果比第一章不适用RAG技术的AI Agent更准确)
案例:RAG技术生成更智能AI Agent
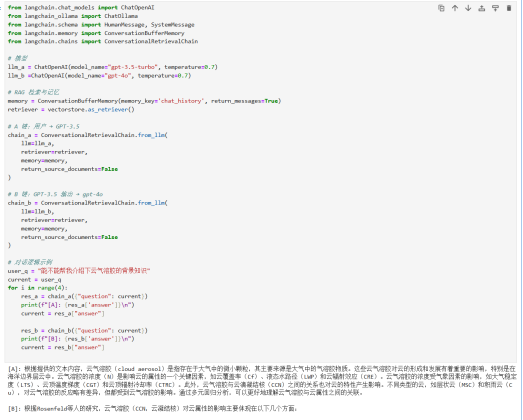
第五章、Fine-Tuning(微调)技术与实例操作
1.微调的定义(提供目标数据集,使大模型结果更趋向于该数据集)
2.微调的意义(微调只需调整大模型,并不需要重新训练大模型,有效节省算力)
3.微调需要注意的问题。(使用ChatGPT-4o时费用相对较高)
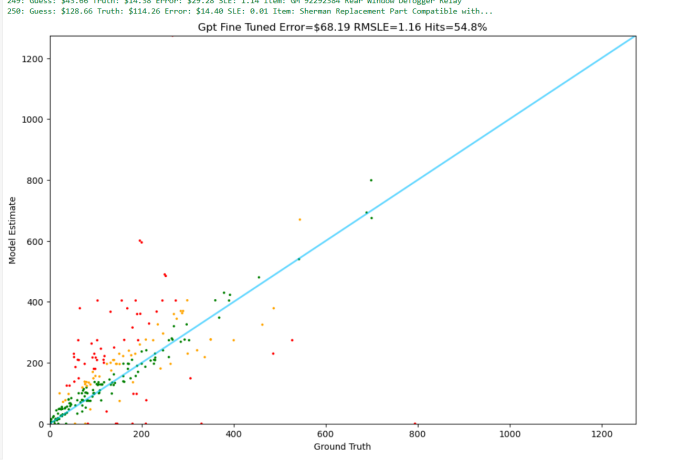
4.微调的结果(相对于传统大模型,微调结果更好)
案例:微调chat-gpt-4o模型
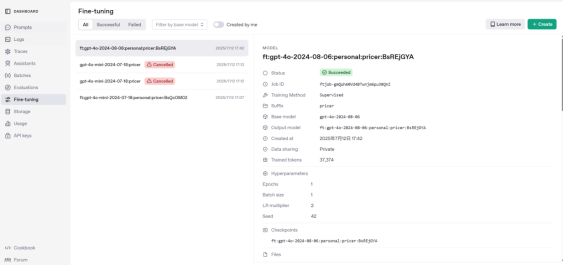
第六章、Lora技术与实例操作
1.LoRA的定义(大语言模型的低阶适应)
2.LoRA的意义(微软的研究人员为了解决大语言模型微调而开发的一项技术)
3.LoRA的目的(LoRA在保证有准确性,只需要训练大模型里面的transfer结构,训练费用有效减少。)
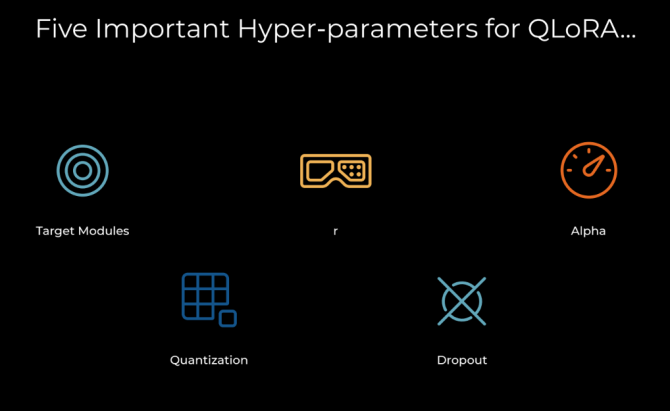
4.LoRA的需要关注的超参数
5.LoRA的训练过程
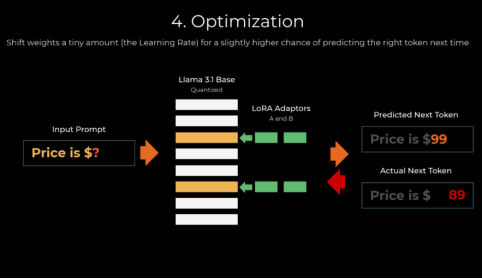
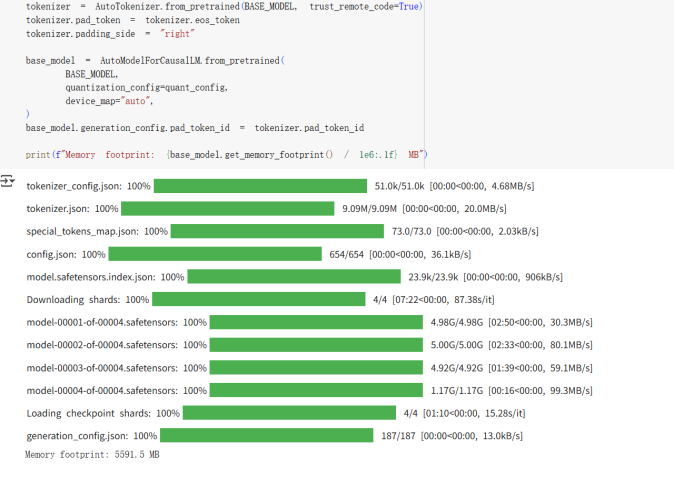
案例:1.LoRA内存和微调显示结果。
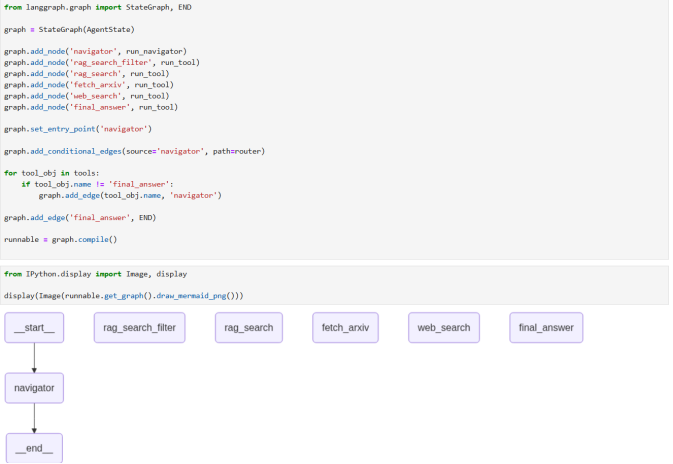
第七章、N8N技术与实例操作
1.N8N的定义
2.N8N的意义
3.N8N的目的(创建自动化工作流)
4.N8N的环境配置(DOCKER平台安装N8N)
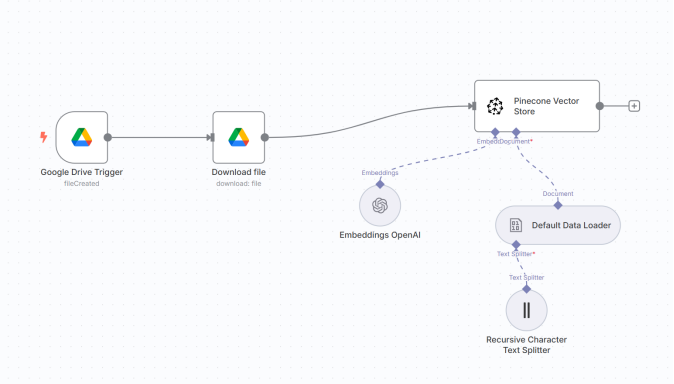
案例:创建RAG自动化工作流(与python Langchain的RAG系统进行比较)
第八章、多AI Agent交互与总结
1.结合以上技术形成一个效果更好更智能化的AI Agent科研研究系统(包括AI Agent提供快速arxiv论文快速检索生成相关论文知识,通过AI Agent自主使用RAG等技术提高写作内容深度,多AI Agent互相沟通帮助论文从生成到修改到完善论文多步走。)












出口商品类章金额数据库)

)


)

