🎯 需求和概述
当前基于Dify实现企业级的智能问答系统需求日益增长,Dify的低代码开发框架和功能完整、灵活适应各种需求的特色得到广大大模型和RAG开发着的欢迎。但是Dify在落地企业级应用时候,也面临不少的问题,最突出的就是Dify虽然提供了可视化的前端问答界面和后端的知识库管理,但毕竟是给开发人员提供的,而且开发和管理功能都混在一起,这个提供给最终用户,导致的问题是:
- 用户很难使用,对他(她)来说这个界面很不清晰,设置复杂,很难应用
- 用户的非专业操作很可能导致系统破坏
- 实施者也不愿意给用户暴露内部实施的各种开发细节
好消息是Dify提供了前端chatflow和workflow以及知识库的完整API,因此可以基于API来实现前端问答界面和后端的知识库管理系统。关于前端问答界面的实现,“深度集成Dify API:基于Vue 3的智能对话前端解决方案”已经做了详细阐述,本文解决的就是基于Dify API实现后端的知识库管理系统的完整实现。这样就能实现用户和Dify开发平台的隔离,可以独立使用专属的界面和系统,也解决了Dify开发者实施和落地的困境。
Dify RAG Knowledge Management System 是一个基于 Streamlit 构建的企业级知识库管理平台,提供对 Dify RAG 知识库的全生命周期管理。系统采用分层架构设计,通过 RESTful API 与 Dify 服务进行通信,实现了知识库、文档和文本块的完整管理功能。
✨ 功能特性
1. 知识库管理
- 📚 知识库列表展示(卡片式布局)
- ➕ 创建新知识库
- ✏️ 更新知识库信息
- 🗑️ 删除知识库(级联删除所有文档和文本块)
- 📊 查看知识库详情和统计数据
- 🏷️ 设置知识库元数据
2. 文档管理
- 📄 文档列表展示(表格形式,支持分页)
- 📤 上传多种格式文档(PDF, DOCX, XLSX, PPTX, TXT, MD, CSV, HTML)
- 📊 查看文档详情和处理状态
- ✏️ 更新文档信息
- 🗑️ 删除文档
- ⬇️ 下载文档
- 🏷️ 设置文档元数据
- 🔍 搜索和筛选功能(按名称、时间、类型、元数据)
3. 文本块管理
- 📋 文本块列表展示(表格形式,支持分页)
- ➕ 添加新文本块
- ✏️ 更新文本块内容
- 🗑️ 删除文本块
- 📊 查看文本块详情
- 🔍 搜索和筛选功能(按内容、关键字)
4. 用户体验
- 🎯 直观的层次化导航
- 📱 响应式设计
- 🎨 美观的企业级界面
- ⚡ 实时状态更新
- 📊 丰富的统计信息
下面是一些界面展示:
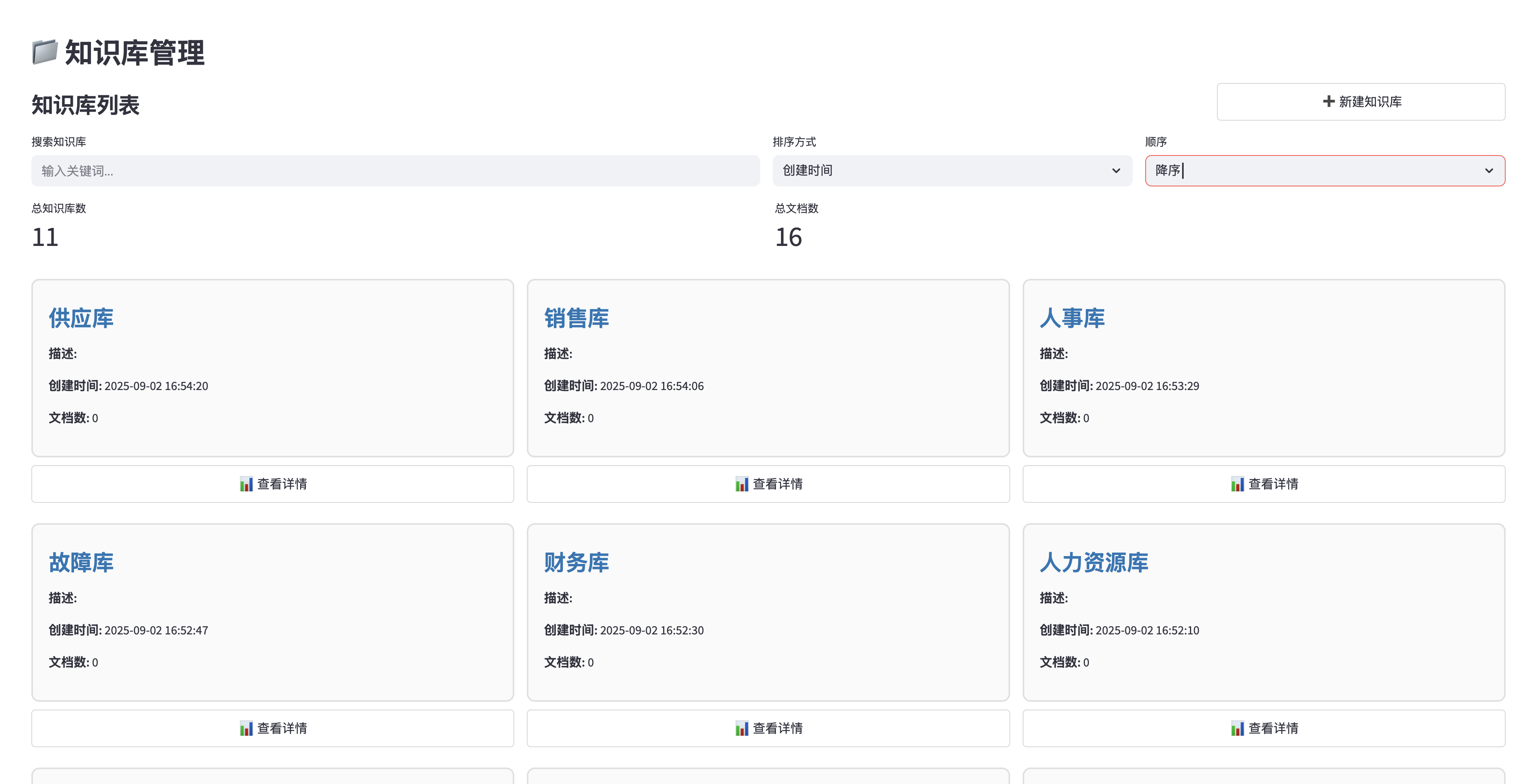
知识库管理首页

文件上传拖拽
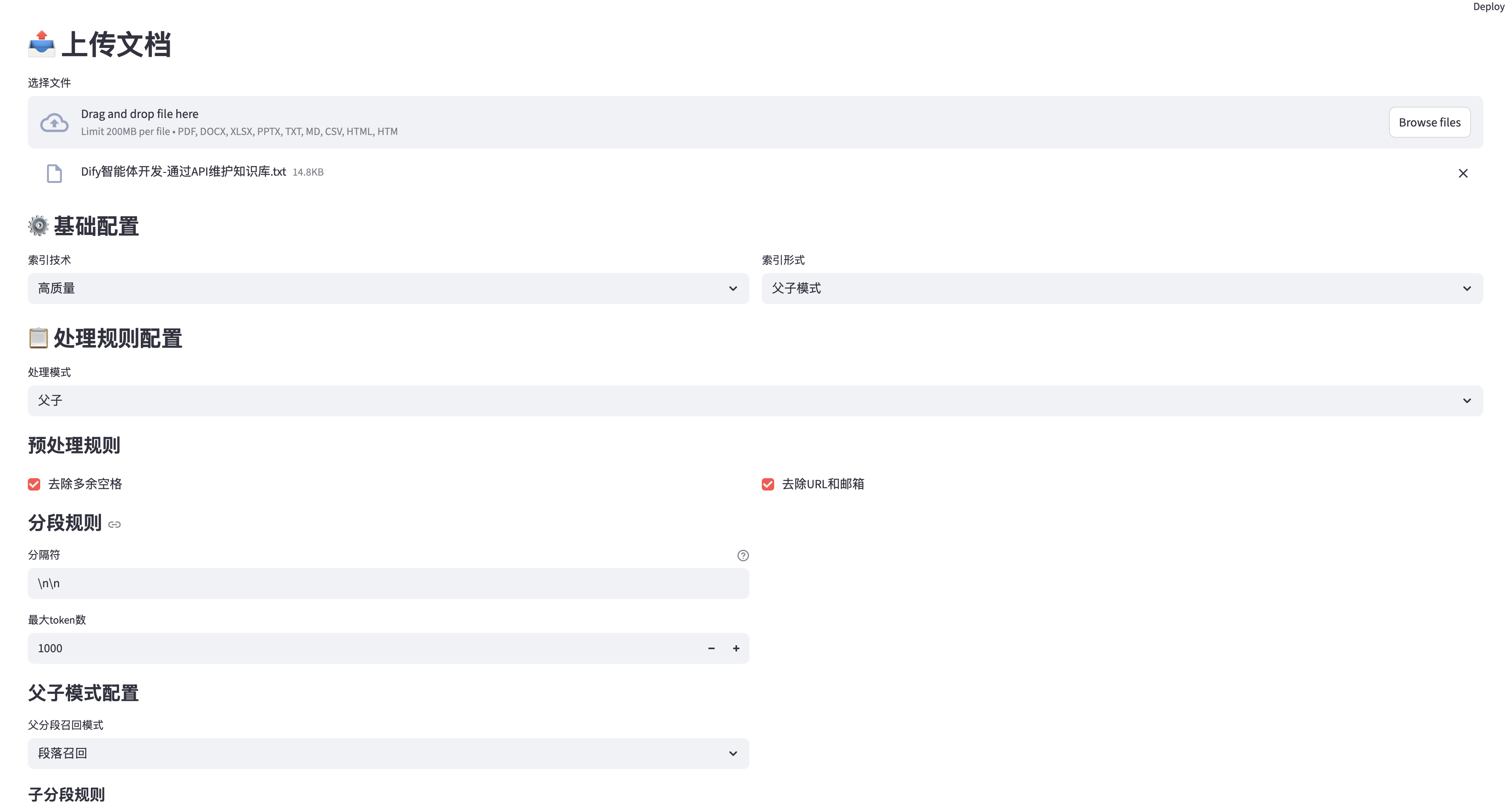
上传文档配置(可以选择默认)
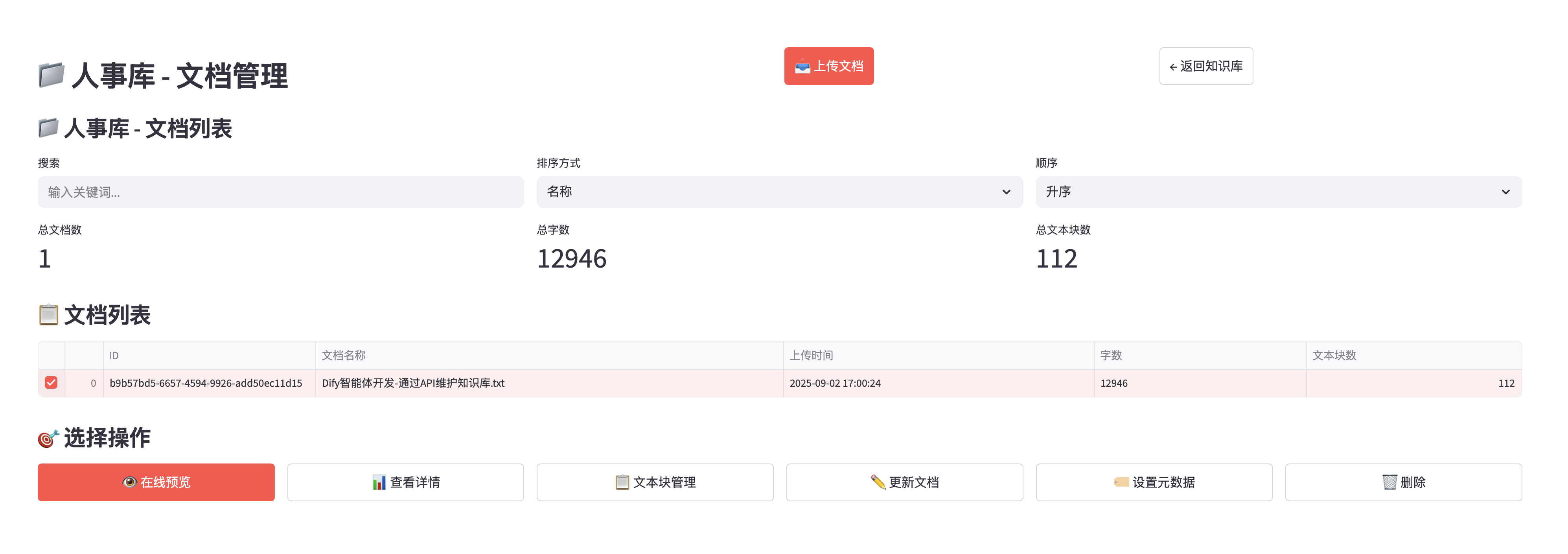
查看知识库的文档等
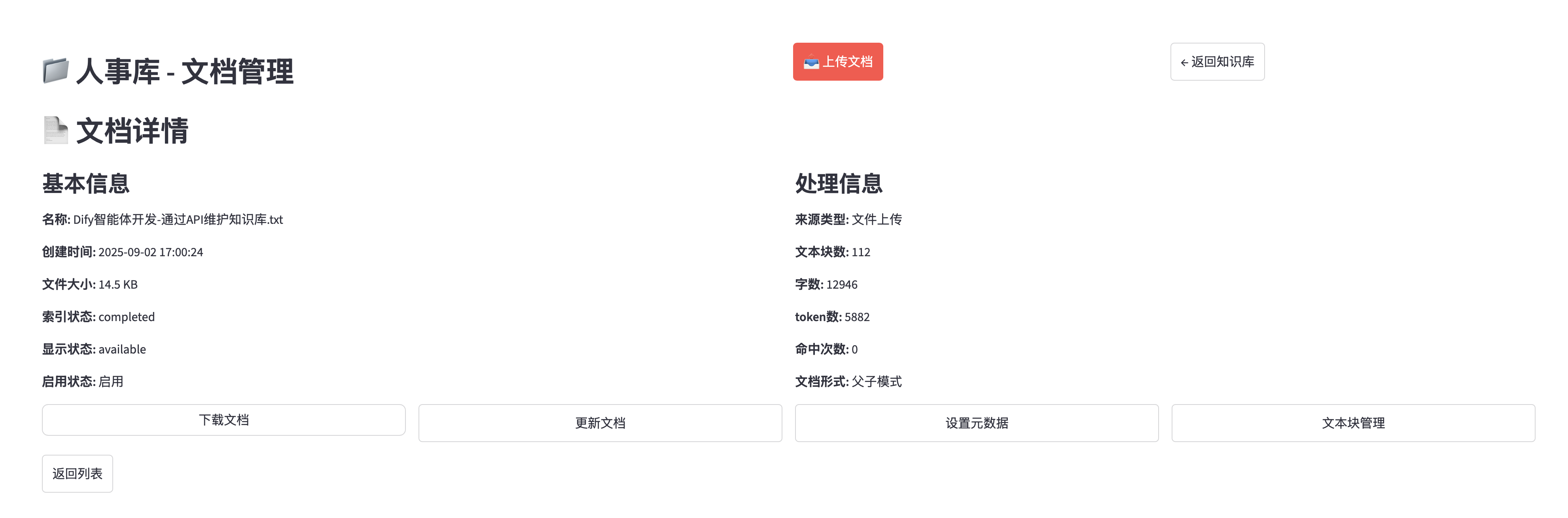
文档信息和下载等
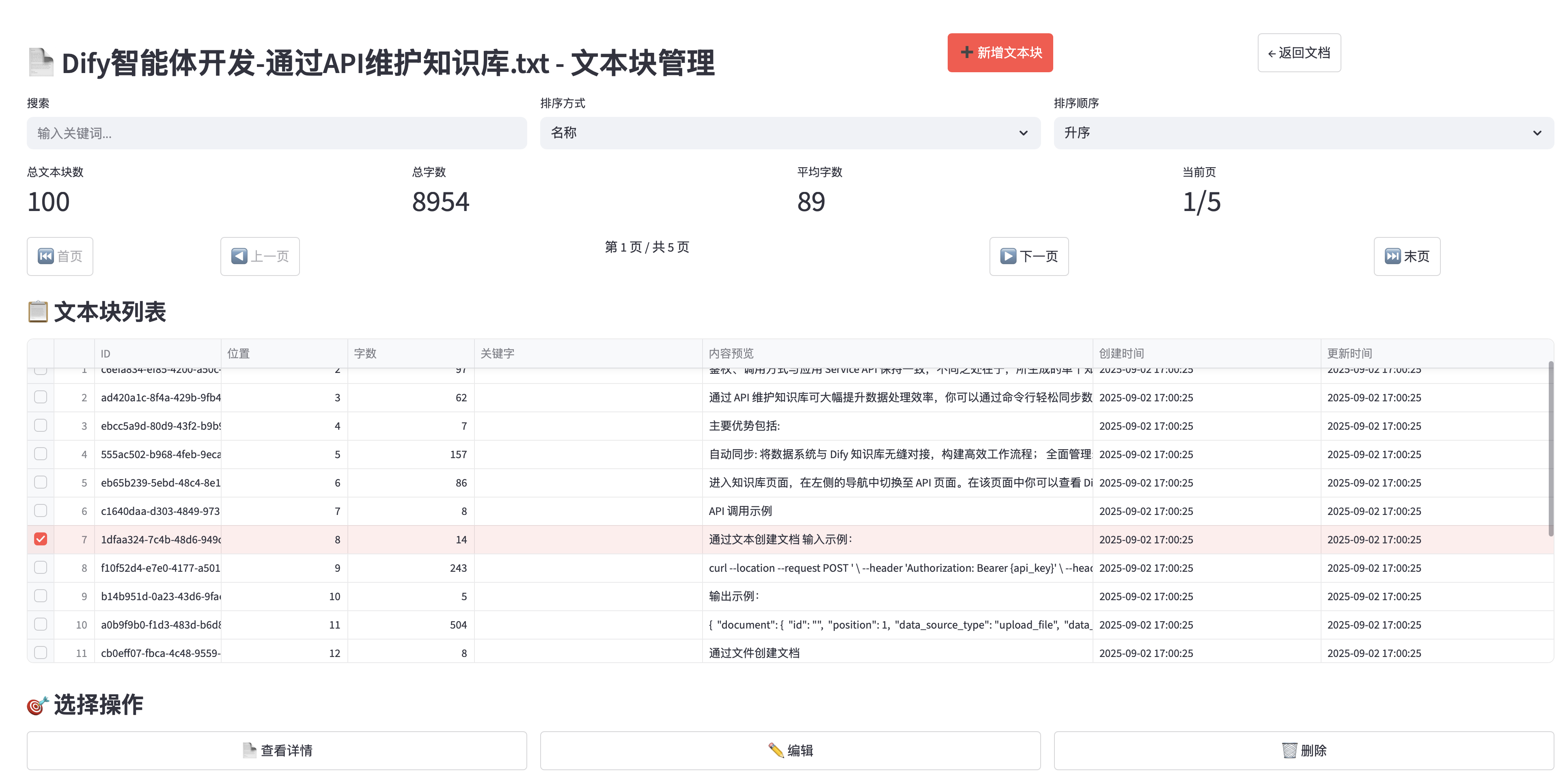
查看文档块

文档预览
🏗️ 系统架构
1. 整体架构图
2. 技术栈架构
| 层级 | 技术 | 用途 | 特点 |
|---|---|---|---|
| 前端 | Streamlit | Web界面 | 快速原型、响应式设计 |
| 后端 | Python 3.8+ | 业务逻辑 | 简洁高效、生态丰富 |
| 通信 | HTTP/RESTful | API调用 | 标准化、跨平台 |
| 配置 | python-dotenv | 环境管理 | 灵活配置、安全隔离 |
| 存储 | 临时文件系统 | 文件缓存 | 轻量级、易部署 |
📊 核心模块设计
1. 模块结构图
dify-knowledge/
├── main.py # 应用入口点
├── requirements.txt # 依赖管理
├── .env # 环境配置
├── src/
│ ├── config.py # 配置管理模块
│ ├── api/
│ │ └── dify_client.py # Dify API客户端
│ ├── pages/ # 页面模块
│ │ ├── knowledge_base.py # 知识库管理
│ │ ├── document_management.py # 文档管理
│ │ └── segment_management.py # 文本块管理
│ └── utils/
│ └── helpers.py # 工具函数
└── temp_uploads/ # 临时文件存储
2. 数据流架构
🔧 核心组件详解
1. 配置管理模块 (src/config.py)
设计目标:
- 集中管理所有配置项
- 支持环境变量配置
- 提供配置验证和默认值
核心代码:
import os
from dotenv import load_dotenvdef load_config():"""加载配置 - 支持环境变量和热重载"""load_dotenv()config = {'dify_url': os.getenv('DIFY_URL', 'http://localhost'),'dify_api_key': os.getenv('DIFY_API_KEY', ''),'theme_base': os.getenv('STREAMLIT_THEME_BASE', 'light')}# 配置验证if not config['dify_api_key']:raise ValueError("DIFY_API_KEY 未在 .env 文件中配置")return config# 全局配置实例
config = load_config()
2. API客户端模块 (src/api/dify_client.py)
设计特点:
- 统一的错误处理机制
- 支持所有Dify API端点
- 类型安全的参数传递
- 自动重试和日志记录
架构模式:
- 单例模式:全局共享API客户端实例
- 模板方法:统一的请求处理流程
- 策略模式:灵活的处理规则配置
核心架构:
API客户端实现详解
# src/api/dify_client.py
import requests
import json
from typing import Dict, Any, Optional
from functools import wrapsclass APIError(Exception):"""自定义API错误类"""def __init__(self, message, status_code=None, response=None):super().__init__(message)self.status_code = status_codeself.response = responseclass DifyClient:"""Dify API客户端 - 单例模式实现"""_instance = Nonedef __new__(cls):if cls._instance is None:cls._instance = super().__new__(cls)return cls._instancedef __init__(self):if not hasattr(self, 'initialized'):self.base_url = config['dify_url']self.api_key = config['dify_api_key']self.headers = {'Authorization': f'Bearer {self.api_key}','Content-Type': 'application/json'}self.initialized = Truedef _make_request(self, method: str, endpoint: str, **kwargs) -> Dict[str, Any]:"""统一的HTTP请求处理设计特点:- 自动重试机制- 详细日志记录- 错误分类处理"""url = f"{self.base_url}/v1{endpoint}"# 合并headersheaders = kwargs.pop('headers', {})headers.update(self.headers)try:response = requests.request(method, url, headers=headers, timeout=30, **kwargs)# 详细日志记录self._log_request(method, url, kwargs, response)# 错误处理if response.status_code == 401:raise APIError("API密钥无效或已过期", 401, response)elif response.status_code == 403:raise APIError("权限不足", 403, response)elif response.status_code == 429:raise APIError("请求频率限制", 429, response)elif response.status_code >= 500:raise APIError("服务器内部错误", response.status_code, response)response.raise_for_status()return response.json()except requests.exceptions.Timeout:raise APIError("请求超时,请稍后重试")except requests.exceptions.ConnectionError:raise APIError("网络连接失败,请检查网络设置")except requests.exceptions.RequestException as e:raise APIError(f"请求失败: {str(e)}")def _log_request(self, method, url, kwargs, response):"""请求日志记录"""log_data = {'method': method,'url': url,'status_code': response.status_code,'response_time': response.elapsed.total_seconds()}if response.status_code >= 400:log_data['error'] = response.textlogger.error("API请求失败", extra=log_data)else:logger.info("API请求成功", extra=log_data)# 使用示例
@handle_api_error
def create_dataset_with_retry(name: str, description: str, max_retries: int = 3):"""创建知识库 - 带重试机制"""client = DifyClient()for attempt in range(max_retries):try:return client.create_dataset(name, description)except APIError as e:if e.status_code == 429 and attempt < max_retries - 1:time.sleep(2 ** attempt) # 指数退避continueraise
3. 页面管理模块
3.1 知识库管理页面 (knowledge_base.py)
功能架构:
- 列表视图:卡片式布局展示知识库
- 详情视图:知识库详细信息展示
- CRUD操作:创建、读取、更新、删除
- 搜索过滤:多维度筛选和排序
状态管理:
# 页面状态管理
st.session_state.page = "knowledge_management" # 当前页面
st.session_state.selected_dataset = {...} # 选中的知识库
st.session_state.show_create_form = True # 显示创建表单
st.session_state.show_detail = True # 显示详情
3.2 文档管理页面 (document_management.py)
处理流程图:
支持的文件格式:
- 文档类:PDF, DOCX, TXT, MD, HTML
- 表格类:XLSX, CSV
- 演示类:PPTX
文件上传的高级实现
def upload_document_with_progress(self, dataset_id: str, file_path: str, **kwargs):"""带进度条的文件上传特点:- 分块上传大文件- 实时进度反馈- 断点续传支持"""import osfrom tqdm import tqdmfile_size = os.path.getsize(file_path)chunk_size = 1024 * 1024 # 1MB chunkswith open(file_path, 'rb') as f:with tqdm(total=file_size, unit='B', unit_scale=True, desc="上传文件") as pbar:files = {'file': f}headers = {'Authorization': f'Bearer {self.api_key}'}# 构建上传数据api_data = {'indexing_technique': kwargs.get('indexing_technique', 'high_quality'),'process_rule': kwargs.get('process_rule', {'mode': 'automatic','rules': {'pre_processing_rules': [],'segmentation': {'separator': '\n\n','max_tokens': 1000,'chunk_overlap': 50}}})}data = {'data': json.dumps(api_data)}# 使用requests-toolbelt进行流式上传from requests_toolbelt.multipart.encoder import MultipartEncoderm = MultipartEncoder(fields={'file': (os.path.basename(file_path), f, 'application/octet-stream'),'data': json.dumps(api_data)})headers['Content-Type'] = m.content_typeresponse = requests.post(f"{self.base_url}/v1/datasets/{dataset_id}/document/create-by-file",headers=headers,data=m,stream=True)response.raise_for_status()return response.json()
3.3 文本块管理页面 (segment_management.py)
数据结构:
- 文本块实体:
{"id": "segment_123","content": "文本内容","answer": "可选答案","keywords": ["关键词1", "关键词2"],"position": 1,"word_count": 150 }
4. 工具函数模块 (utils/helpers.py)
功能分类:
- 格式化工具:时间、文件大小、状态格式化
- UI组件:消息提示、卡片组件、加载动画
- 数据处理:文本截断、分页处理
- 错误处理:统一的异常处理和用户提示
🎨 用户界面设计
1. 设计原则
- 直观性:层次化导航,清晰的信息架构
- 响应式:适配不同屏幕尺寸
- 一致性:统一的设计语言和交互模式
- 反馈性:即时的操作反馈和状态更新
2. 页面布局
3. 交互设计
核心交互模式:
- 点击选择:知识库 -> 文档 -> 文本块的逐层深入
- 右键菜单:快捷操作入口
- 批量操作:支持多选和批量处理
- 实时搜索:即时过滤和查找
🔍 数据模型设计
1. Dify 内部实体关系图
2. API数据映射
知识库数据结构:
{"id": "kb_123456","name": "技术文档知识库","description": "包含所有技术文档的知识库","created_at": 1695123456.789,"document_count": 150,"embedding_model": "text-embedding-3-small","retrieval_config": {"search_method": "semantic_search","top_k": 5,"score_threshold": 0.8}
}
⚡ 性能优化策略
1. 前端优化
分页加载:
def load_data_with_pagination(page, limit=20):"""分页加载数据,避免一次性加载大量数据"""offset = (page - 1) * limitreturn api_client.get_data(limit=limit, offset=offset)
缓存策略:
- 会话缓存:使用
st.session_state缓存当前会话数据 - 静态数据缓存:使用
@st.cache_data缓存不经常变化的数据 - API响应缓存:减少重复API调用
2. 后端优化
异步处理:
# 文档上传后的异步处理
async def process_document_async(document_id):"""异步处理文档,避免阻塞用户界面"""task = asyncio.create_task(api_client.process_document(document_id))return task
状态轮询优化:
def poll_processing_status(document_id, interval=2):"""智能轮询处理状态,指数退避"""max_attempts = 30for attempt in range(max_attempts):status = api_client.get_status(document_id)if status in ['completed', 'error']:return statustime.sleep(min(interval * (2 ** attempt), 10))
🔒 安全设计
1. 认证授权
API密钥管理:
- 环境变量存储,不暴露在代码中
- 最小权限原则,只授予必要权限
- 定期轮换机制
2. 数据安全
文件上传安全:
def validate_uploaded_file(file):"""文件安全检查"""allowed_extensions = {'.pdf', '.docx', '.txt', '.md', '.xlsx', '.csv'}# 检查文件扩展名file_ext = os.path.splitext(file.name)[1].lower()if file_ext not in allowed_extensions:raise ValueError(f"不支持的文件格式: {file_ext}")# 检查文件大小if file.size > 100 * 1024 * 1024: # 100MBraise ValueError("文件大小超过限制")return True
3. 输入验证
数据验证框架:
from typing import Dict, Anydef validate_knowledge_base_data(data: Dict[str, Any]) -> bool:"""知识库数据验证"""required_fields = ['name']for field in required_fields:if not data.get(field):raise ValueError(f"必填字段缺失: {field}")if len(data.get('name', '')) > 100:raise ValueError("知识库名称长度不能超过100字符")return True
📋 部署架构
1. 部署模式
单机部署:
容器化部署:
FROM python:3.9-slimWORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txtCOPY . .
EXPOSE 8501CMD ["streamlit", "run", "main.py", "--server.port=8501", "--server.address=0.0.0.0"]
2. 环境配置
生产环境配置:
# .env.production
DIFY_URL=https://api.dify.production.com
DIFY_API_KEY=prod_key_xxx
STREAMLIT_THEME_BASE=dark
STREAMLIT_SERVER_MAX_UPLOAD_SIZE=200
🧪 测试策略
1. 测试金字塔
2. 测试用例示例
API客户端测试:
import pytest
from src.api.dify_client import DifyClientclass TestDifyClient:def test_create_dataset(self):client = DifyClient()result = client.create_dataset("测试知识库", "测试描述")assert result['name'] == "测试知识库"assert 'id' in resultdef test_upload_document(self):client = DifyClient()# 测试文件上传...
📊 监控与日志
1. 监控指标
业务指标:
- 知识库数量、文档数量、文本块数量
系统指标:
- 内存使用率、CPU使用率
- 磁盘空间、网络带宽
- 并发用户数
2. 日志设计
日志级别:
import logging# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler('app.log'),logging.StreamHandler()]
)logger = logging.getLogger(__name__)
📚 开发指南
1. 开发环境设置
# 1. 克隆项目
git clone <repository-url>
cd dify-knowledge# 2. 创建虚拟环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate# 3. 安装依赖
pip install -r requirements.txt# 4. 配置环境变量
cp .env.example .env
# 编辑 .env 文件# 5. 启动应用
streamlit run main.py
2. 故障排除
常见问题解决方案:
| 问题描述 | 可能原因 | 解决方案 |
|---|---|---|
| API连接失败 | 网络问题 | 检查DIFY_URL配置 |
| 上传文件失败 | 格式不支持 | 检查文件格式和大小 |
| 处理状态异常 | 服务资源不足 | 检查Dify服务状态 |
有需要系统源代码的请私信联系。


)





Python控制结构(条件结构))





——并查集:探索如何高效地管理集合)


)

