从@Schedule到XXL-JOB:分布式定时任务的演进与实践
在分布式系统中,定时任务是常见需求(如数据备份、报表生成、缓存刷新等)。Spring框架的@Schedule注解虽简单易用,但在集群环境下存在明显局限;而XXL-JOB作为成熟的分布式任务调度框架,通过精细化设计解决了这些问题。本文将深入对比两者差异,并详解XXL-JOB的核心设计与实现。
一、@Schedule的局限:集群环境下的"重复执行"痛点
@Scheduled 是 Spring 框架提供的用于实现定时任务的注解,其底层基于任务调度器(Task Scheduler) 实现,通过注解配置简化了定时任务的开发流程。下面从核心原理、执行机制、关键组件等方面详细解析其工作原理:
1、核心原理:基于任务调度器的定时触发
@Scheduled 的本质是通过 Spring 容器中的 TaskScheduler 接口(任务调度器),按照注解中配置的时间规则(如固定延迟、固定速率、Cron 表达式等),周期性地触发目标方法的执行。
核心逻辑:当 Spring 容器启动时,会扫描所有标注了 @Scheduled 的方法,并根据注解中的参数(如 cron、fixedDelay 等)生成对应的任务触发器(Trigger),最终由任务调度器按照触发器的规则执行任务。
2、关键组件与执行流程
(1) 核心接口与类
-
TaskScheduler:Spring 任务调度的核心接口,定义了调度任务的方法(如 schedule(Runnable task, Trigger trigger)),负责根据触发器规则执行任务。
- 常见实现类:ThreadPoolTaskScheduler(基于线程池的调度器,默认使用),通过线程池管理任务执行,避免单线程阻塞。
-
Trigger:触发器接口,定义了任务下次执行的时间(nextExecutionTime(TriggerContext context)),决定任务的执行时机。
常见实现类:- CronTrigger:基于 Cron 表达式的触发器(对应 @Scheduled 的 cron 参数)。
- FixedDelayTrigger:固定延迟触发器(对应 fixedDelay 参数,任务执行完成后间隔固定时间再次执行)。
- FixedRateTrigger:固定速率触发器(对应 fixedRate 参数,任务开始执行后间隔固定时间再次执行)。
-
@Scheduled 注解:标记需要定时执行的方法,通过参数(cron、fixedDelay、fixedRate 等)指定触发规则,Spring 会自动解析这些参数并绑定到对应的 Trigger。
(2) 执行流程
- 容器初始化:Spring 容器启动时,通过 @EnableScheduling 注解开启定时任务支持,激活相关的处理器(ScheduledAnnotationBeanPostProcessor)。
- 扫描与解析:ScheduledAnnotationBeanPostProcessor 扫描所有 Bean 中被 @Scheduled 标注的方法,解析注解中的参数(如 cron 表达式、延迟时间等),生成对应的 Trigger 实例。
- 任务注册:将解析后的任务(Runnable)与 Trigger 绑定,通过 TaskScheduler 注册到调度器中。
- 定时触发:TaskScheduler 按照 Trigger 计算的下次执行时间,在指定时刻触发任务执行(通过线程池中的线程执行目标方法)。
- 周期执行:任务执行完成后,Trigger 重新计算下次执行时间,重复触发,形成周期性调度。
3、@Scheduled 的参数与触发规则
@Scheduled 支持多种触发规则,通过不同参数指定,对应不同的 Trigger 实现:
|参数| 作用 对应 Trigger 示例
| 参数 | 作用 | 对应 Trigger | 示例 |
|---|---|---|---|
| cron | 基于 Cron 表达式的定时规则(最灵活,支持复杂时间配置) | CronTrigger | @Scheduled(cron = "0 0 12 * * ?")(每天 12 点执行) |
| fixedDelay | 任务执行完成后,间隔固定毫秒数再次执行(以任务结束时间为基准) | FixedDelayTrigger | @Scheduled(fixedDelay = 5000)(间隔 5 秒) |
| fixedRate | 任务开始执行后,间隔固定毫秒数再次执行(以任务开始时间为基准) | FixedRateTrigger | @Scheduled(fixedRate = 5000)(间隔 5 秒) |
| initialDelay | 首次执行前的延迟毫秒数(配合 fixedDelay 或 fixedRate 使用) | - | @Scheduled(initialDelay = 1000, fixedDelay = 5000)(延迟 1 秒后开始,之后间隔 5 秒) |
注意:如果任务执行时间超过了 fixedRate 设定的间隔,下一次任务会立即执行(不会并行,默认单线程调度时会等待前一次完成);而 fixedDelay 则始终等待前一次任务完成后再间隔指定时间执行。
4、 默认调度器的线程模型
Spring 默认的 TaskScheduler 实现是 ThreadPoolTaskScheduler,其线程池配置如下:
- 默认核心线程数:1(单线程)。
- 线程池行为:所有定时任务默认共享这一个线程,若一个任务执行时间过长,会阻塞其他任务的触发(例如:任务 A 执行 10 秒,任务 B 每隔 5 秒执行一次,则任务 B 会被阻塞至任务 A 完成后才会执行)。
如何避免阻塞?
可以通过自定义 ThreadPoolTaskScheduler 配置线程池参数(如增加核心线程数),让不同任务在不同线程中执行,避免相互影响:
@Configuration
public class SchedulerConfig {@Beanpublic TaskScheduler taskScheduler() {ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();scheduler.setPoolSize(5); // 核心线程数5scheduler.setThreadNamePrefix("scheduled-task-");return scheduler;}
}
5、局限性:分布式场景下的问题
- @Scheduled 适用于单机场景,但在分布式集群环境中存在明显缺陷:
任务重复执行:集群中的多个节点都会扫描并执行相同的定时任务(因为每个节点的 Spring 容器都会独立调度)。 - 缺乏统一管理:无法集中监控、暂停、恢复任务,也没有失败重试、任务依赖等高级特性。
解决方案:使用分布式定时任务框架(如 XXL-JOB、Elastic-Job 等),通过中心化调度避免重复执行,并提供更完善的任务管理能力。
二、XXL-JOB:分布式定时任务的完整解决方案
XXL-JOB是一款开源分布式任务调度框架,由调度中心和执行器两大核心模块组成,通过统一的调度中心协调集群中的任务执行,从根本上解决重复执行问题,同时提供可视化管理、监控告警等能力。
2.1 核心模块架构
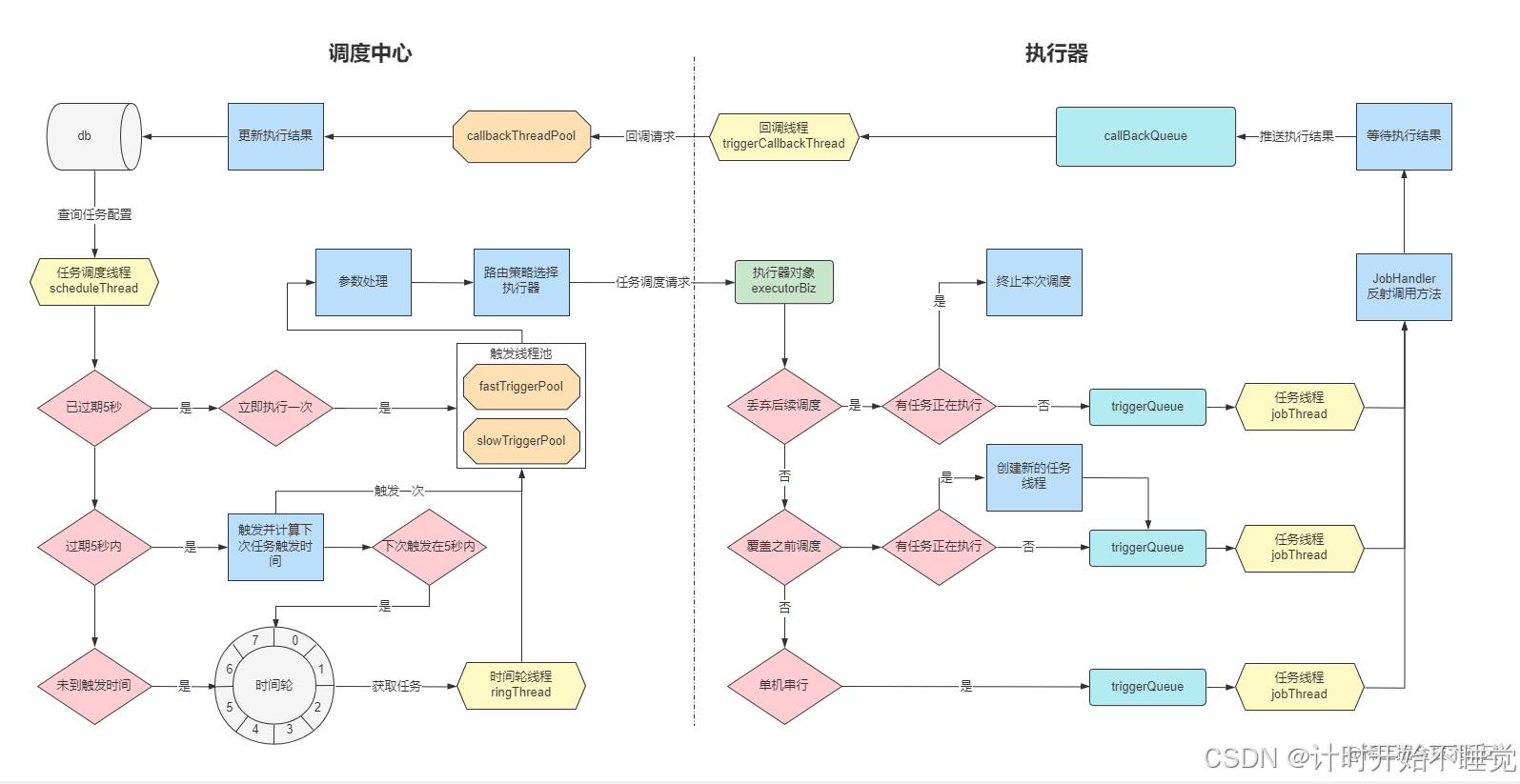
XXL-JOB架构:调度中心负责任务管理与触发,执行器负责任务实际执行
2.1.1 调度中心模块
调度中心是XXL-JOB的"大脑",负责任务配置、触发调度、执行监控等核心功能,其核心依赖以下数据库表实现数据持久化:
| 表名 | 核心作用 | 关键字段示例 |
|---|---|---|
xxl_job_registry | 记录执行器心跳信息,维护活跃执行器列表 | registry_group、registry_key(执行器地址)、update_time(最后心跳时间) |
xxl_job_group | 管理执行器分组配置(如"订单服务执行器"、“用户服务执行器”) | app_name(执行器唯一标识)、title、address_type(自动/手动注册) |
xxl_job_info | 存储定时任务详细配置,是调度的核心数据 | job_cron(触发表达式)、job_group(所属执行器组)、executor_handler(执行器方法名)、trigger_next_time(下次触发时间) |
xxl_job_lock | 分布式锁表,确保调度中心集群环境下任务触发的唯一性(防止调度中心重复触发) | lock_name(锁标识,如"schedule_lock") |
2.1.2 执行器模块
执行器是任务的"执行者",部署在业务应用中,通过注册中心与调度中心通信,接收并执行任务。其核心配置包括:
-
运行模式:
Bean模式:任务以Spring Bean方式存在(如@XxlJob("demoJobHandler")注解的方法),适合固定逻辑的任务。GLUE模式:任务逻辑以代码片段(Java、Groovy等)存储在调度中心,运行时动态加载执行,支持在线编辑无需重启执行器,适合需频繁调整逻辑的任务。
-
高级特性:
- 集群负载均衡:调度中心向执行器集群分发任务时,支持轮询、随机、一致性哈希等策略(如
ROUND轮询可均衡负载)。 - 任务回调:执行器完成任务后,通过HTTP接口将结果(成功/失败、日志ID等)回调给调度中心,确保状态同步。
- 集群负载均衡:调度中心向执行器集群分发任务时,支持轮询、随机、一致性哈希等策略(如
2.2 调度中心核心线程:任务触发的"双引擎"
调度中心初始化时启动两个核心线程,协同完成任务触发:
1. scheduleThread:任务扫描线程
- 作用:周期性扫描
xxl_job_info表,计算任务下次触发时间并维护到时间轮。 - 工作流程:
- 每3秒扫描一次数据库,筛选出"状态为启用"且"下次触发时间≤当前时间+5秒"的任务。
- 对符合条件的任务,计算其
triggerNextTime(下次触发时间),并根据时间轮算法放入对应槽位。 - 若任务触发时间已过期(如服务器宕机后重启),根据"调度过期策略"处理(见2.4节)。
2. ringThread:时间轮线程
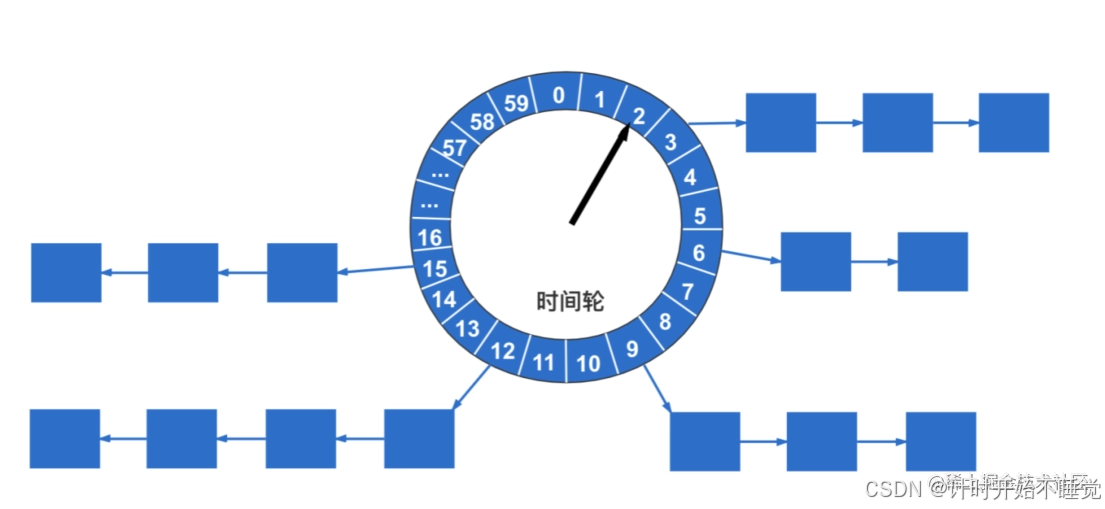
-
作用:驱动时间轮转动,触发到达执行时间的任务。
-
时间轮设计:XXL-JOB的时间轮是一个简化版实现,本质是
ConcurrentHashMap<Integer, List<Integer>>,其中:- Key:
ringSecond(0-59的秒数),对应时间轮的60个"槽位"(与分钟的秒数对应)。 - Value:该秒数需要触发的任务ID列表。
- 计算逻辑:
ringSecond = (triggerNextTime / 1000) % 60,即任务下次触发时间的秒数对应到时间轮的槽位。
- Key:
-
任务触发逻辑:
- 每1秒获取当前时间的秒数(
currentSecond)。 - 从时间轮中取出
currentSecond(当前秒)和currentSecond-1(前一秒)的任务列表。 - 遍历任务列表,通过线程池触发任务执行。
- 每1秒获取当前时间的秒数(
-
为何要获取前一秒任务?
这是XXL-JOB的容错设计:前一秒的任务可能因线程池繁忙、系统延迟等原因未执行,通过再次检查确保任务不遗漏,实现"补漏+当前处理"的双重保障。
2.3 线程池隔离:快慢任务的"分道扬镳"
为避免慢任务阻塞整个调度系统,XXL-JOB设计了两个线程池实现隔离:
fastTriggerPool:处理正常任务(执行时间≤500ms)。slowTriggerPool:处理慢任务(执行时间>500ms)。
隔离逻辑:
- 用
ConcurrentHashMap维护任务超时计数器(jobId -> 超时次数)。 - 若任务单次执行时间>500ms,超时次数+1。
- 当1分钟内超时次数≥10次,该任务被标记为"慢任务",后续由
slowTriggerPool调度。
这种设计确保慢任务不会占用快速任务的资源,提升系统整体稳定性。
2.4 调度过期策略:任务延迟时的"智能抉择"
当任务因调度中心宕机、网络故障等原因错过触发时间(即triggerNextTime < 当前时间),XXL-JOB提供4种过期策略:
- 立即执行一次:无论延迟多久,触发一次任务(适合数据补全类任务)。
- 触发一次后跳过:仅执行一次,跳过后续因过期累积的触发(适合非周期性任务)。
- 忽略过期,按原周期执行:跳过过期的触发,等待下一个周期(适合严格按周期执行的任务,如每小时统计)。
- 按照过期次数补执行:若错过N次触发,补执行N次(适合必须执行所有周期的任务,如分钟级监控)。
用户可根据任务特性选择策略,平衡时效性与资源消耗。
三、XXL-JOB整体执行流程
- 任务配置:在调度中心配置任务(Cron表达式、执行器、处理方法等),信息存入
xxl_job_info。 - 执行器注册:执行器启动时,通过
xxl_job_registry表向调度中心注册地址(心跳机制维持活跃状态)。 - 任务扫描与入轮:
scheduleThread扫描任务,计算triggerNextTime并放入时间轮对应槽位。 - 任务触发:
ringThread每秒从时间轮取当前秒和前一秒任务,通过线程池向执行器发送触发请求。 - 任务执行:执行器接收请求,调用对应
JobHandler执行任务逻辑。 - 结果回调:执行器将结果(成功/失败、日志)通过HTTP回调给调度中心,更新任务状态。
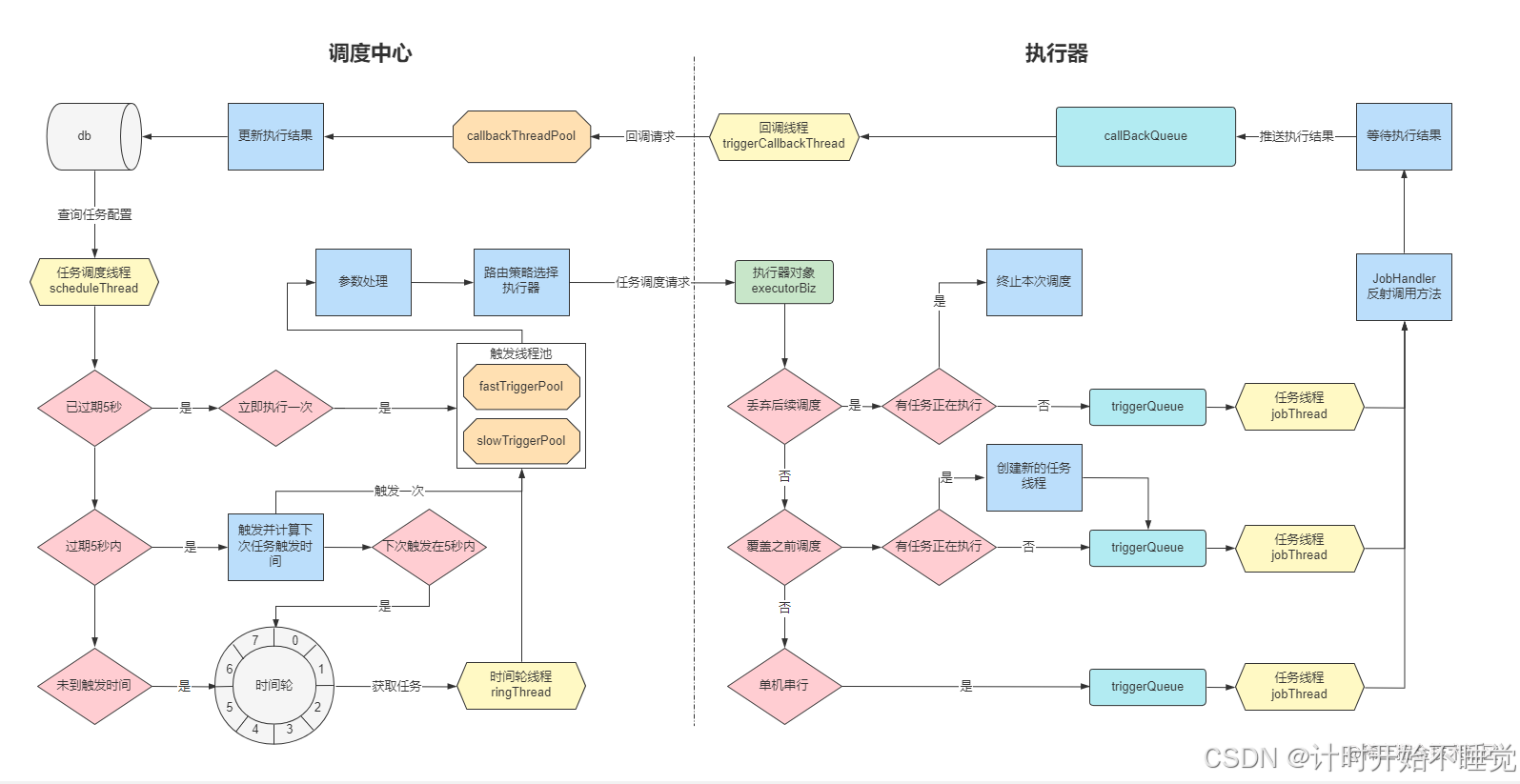
XXL-JOB端到端执行流程
四、XXL-JOB核心优势总结
相比@Schedule,XXL-JOB在分布式场景下的优势显著:
- 分布式协调:通过调度中心统一管控,解决集群重复执行问题。
- 动态管理:支持在线配置、启停、编辑任务,无需代码部署。
- 高可用设计:调度中心与执行器均支持集群部署,结合时间轮补漏机制,确保任务不丢失。
- 运维友好:提供任务日志、监控告警、失败重试等功能,降低运维成本。
- 灵活扩展:支持多种负载均衡策略、执行模式及过期处理机制,适配复杂业务场景。
五、总结
从@Schedule的简单易用到XXL-JOB的分布式能力,定时任务框架的演进体现了系统从单体到分布式的必然需求。XXL-JOB通过时间轮、线程池隔离、分布式协调等设计,完美解决了集群环境下的任务调度难题,是中大型分布式系统的理想选择。在实际开发中,应根据系统规模(单体/集群)、任务复杂度(静态/动态)选择合适的框架,平衡开发效率与系统可靠性。





:指令与过滤器)


)


日志系统原理以及k8s集群日志采集过程)
 复杂度分析笔记)
![【光照】Unity中的[经验模型]](http://pic.xiahunao.cn/【光照】Unity中的[经验模型])

)



