篇幅所限,本文只提供部分资料内容,完整资料请看下面链接
https://download.csdn.net/download/2501_92796370/91778320
资料解读:《基于DeepSeek的数据治理技术》
详细资料请看本解读文章的最后内容。
作为数据治理领域的资深研究者,我很荣幸为大家解读这份由数桨AI实验室发布的《基于DeepSeek的数据治理技术》文件。这份资料系统性地介绍了如何利用DeepSeek这一先进的大模型技术来优化和提升数据治理工作的效率与质量,内容涵盖从理论基础到实践应用的完整知识体系。
大模型技术基础
文件开篇首先阐述了人工智能与大模型的技术基础。人工智能(AI)被定义为模拟人类智能的技术,使机器能够学习、思考和决策。资料中详细介绍了人工智能技术全景图,包括机器学习、深度学习、大语言模型等核心技术分支。
特别值得注意的是,文件对机器学习的不同范式进行了专业区分:监督学习通过标记数据训练模型;无监督学习自主发现数据模式;强化学习则通过环境反馈优化策略。深度学习作为机器学习的重要分支,采用多层神经网络模拟人脑处理信息的方式,其"深度"体现在层次化结构上。
DeepSeek技术架构
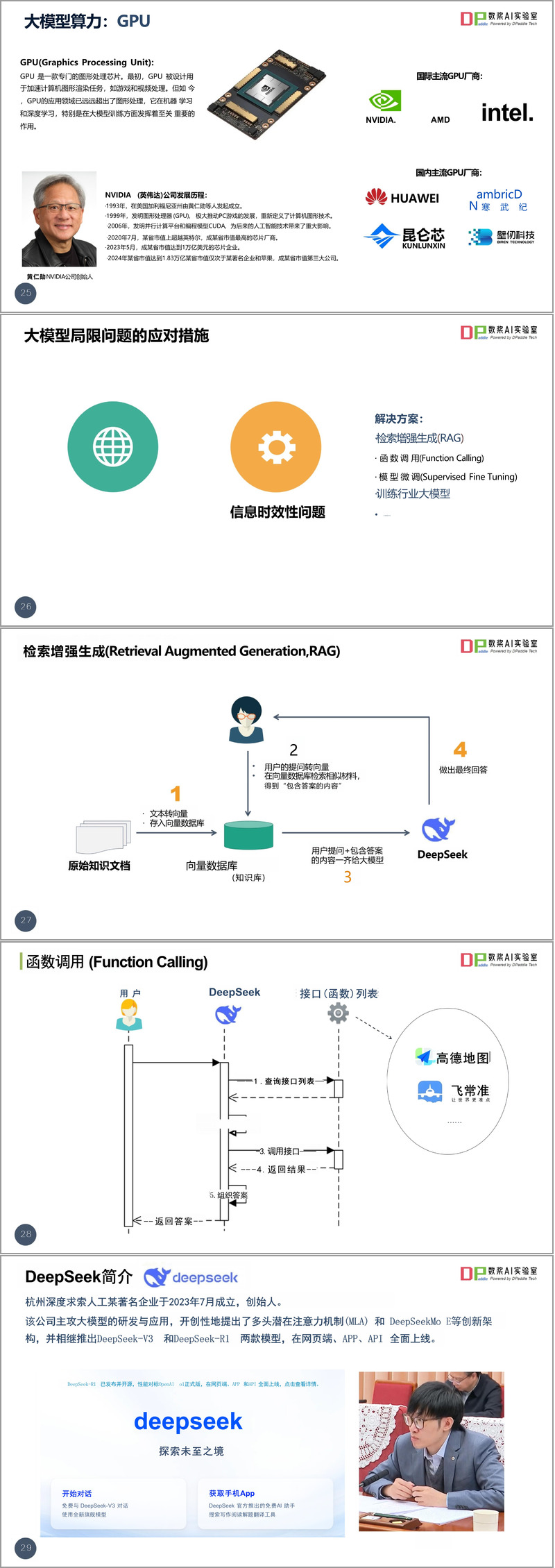
资料重点介绍了DeepSeek的技术特点。作为由深度求索公司开发的大语言模型,DeepSeek采用了创新的多头潜在注意力机制(MLA)和MoE架构。目前推出的DeepSeek-V3是一款671B参数的通用型大模型,在多项评测中表现优异;而DeepSeek-R1则专注于复杂推理任务,采用强化学习技术显著提升了推理能力。
文件详细分析了影响大模型性能的关键因素:训练数据量、参数量和计算资源。随着参数增加,模型创造力和表现力显著提升。DeepSeek采用了"以数据为中心"的AI开发理念,系统性地迭代优化数据质量,与传统"以模型为中心"的方法形成鲜明对比。
数据治理应用场景
资料的核心部分深入探讨了DeepSeek在数据治理各阶段的应用价值:
在数据规划阶段,可辅助数据标准管理和质量评估;数据采集环节能实现清洗和标准化处理;存储阶段支持数据库设计优化和元数据管理;应用层面则赋能自然语言查询、文档生成等场景。
文件特别强调了DeepSeek在数据资产入表流程中的重要作用,包括数据资产识别、权属确认、财务报表编制与披露等关键环节。同时也客观分析了数据治理面临的挑战:技术整合更新、安全隐私保护、数据质量保证等问题。
核心技术能力解析
资料系统梳理了DeepSeek在自然语言处理方面的核心能力:
词法和句法分析方面,模型可精准实现分词、命名实体识别、词性标注等任务。测试显示,即使面对"丘处机"这类复杂人名,也能准确拆分姓和名。实体匿名化功能则可通过替换敏感信息保障隐私安全。
信息抽取能力包括关键词提取、实体关系三元组抽取等。在一个足球新闻案例中,模型准确提取出"国足出线形势"等关键短语并赋予合理权重;在ChatGPT描述文本中,成功抽取出"(ChatGPT,开发,OpenAI)"等结构化关系。
分类与聚类技术应用于文本分类、情感分析等场景。模型不仅能完成常规新闻分类,还能处理"simon语"这类小众语言的小样本分类任务。情感分析案例中,对社交网络抱怨文本的消极情绪判断准确。
高级文本处理能力
DeepSeek的受控文本生成能力令人印象深刻。资料展示了模型如何按照指定风格(如"极尽嘲笑")重写《孔乙己》摘要,以及将结构化天气数据转化为自然语言描述的能力。
在问答系统方面,模型展现出强大的常识问答、跨语言问答和意图识别能力。无论是用中英文描述《西游记》内容,还是准确识别"北京沙尘暴"查询的天气意图,都表现出类人的理解水平。
技术实现层面,DeepSeek支持多种编程语言的代码生成,并能根据自然语言描述生成符合规范的MySQL建表脚本,极大提升了开发效率。
实践案例与建议
文件最后分享了数据清洗标准化的实际案例,展示如何利用DeepSeek处理多源异构的客户数据。在结语部分,作者提出了对大模型时代数据治理工作的专业建议:
- 深入理解业务需求和数据现状,制定合理治理目标
- 建立完善的数据治理体系框架
- 加强专业人才培养和团队建设
- 建立定期复盘和持续优化机制
这份资料全面展现了DeepSeek在数据治理领域的技术优势和应用前景,既有理论高度,又包含丰富实践案例,为业界提供了宝贵的参考框架和方法论指导。
接下来请您阅读下面的详细资料吧。

)

)







)

及常见问题解答)





内容大纲)