本文为您介绍,如何逐步设计一个基于Redis的高可用缓存。
目录
业务背景
步骤一:写一个最简单的缓存设计
存在的问题:大量冷数据占据Redis内存
解决思路:让缓存自主释放
步骤二:为缓存设置超时时间
存在的问题:热点缓存也会失效
解决思路:为热点缓存续命
步骤三:数据查询缓存后,重新设置缓存过期时间,为其续命
存在的问题:缓存击穿/缓存失效
解决思路:如何保证缓存不同一时间失效
步骤四:为缓存设置不一样的失效时间编辑
存在的问题:缓存穿透
解决思路:拦截查询不存在数据请求,禁止直击数据库
步骤五:为不存在的数据创建空缓存并为其指定过期时间,并对重复请求的空缓存续命编辑
存在的问题:冷数据突变热数据,导致众多获取冷数据的请求直接打在了数据库
解决思路:只让一个查询冷数据的请求查询数据库并为其创建缓存,其他请求查缓存
总结:上述锁已经能解决99%的问题,但是还存在一定缺陷
业务背景
本文将以如何查询,更改个商品的为例,讲述高并发下,如何设计一个高并发缓存。
步骤一:写一个最简单的缓存设计
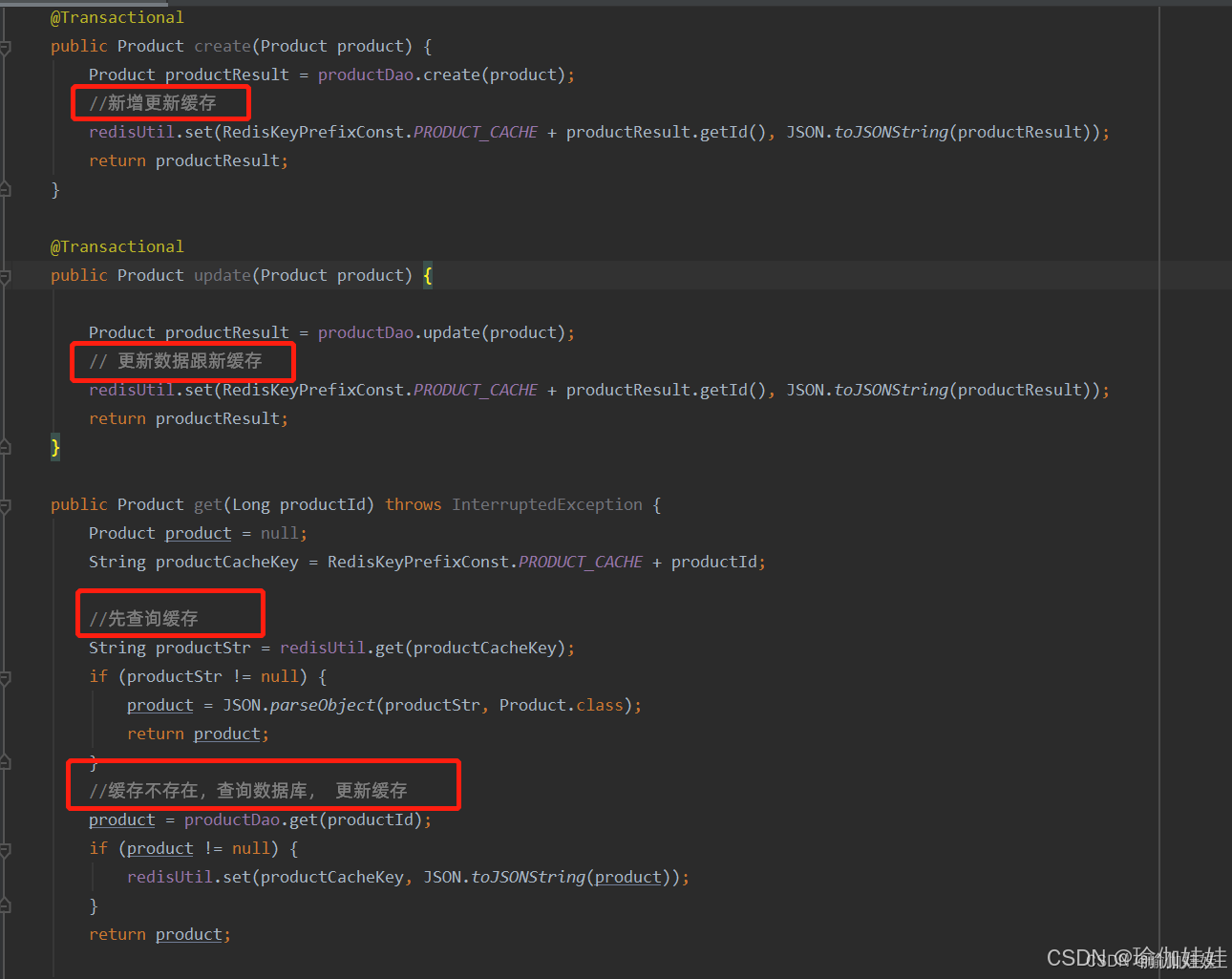
以下代码是常见的最简单的redis缓存的设计:
- 新增、更改数据时,更新缓存。
- 查询时,先查询缓存。
- 缓存存在,直接返回。
- 缓存不存在,查询数据库,且更新缓存数据。
存在的问题:大量冷数据占据Redis内存
在数据少,压力小,并发小的情况下,这个设计似乎没有什么大问题,但是在数据量大,高并发的情况下,却会有不少问题。
例如系统有上亿数据,但是用户经常访问的数据,只有几百万数据,那么大量冷数据常驻Redis内存,造成redis内存浪费。
解决思路:让缓存自主释放
既然这个数据在一段时间内无人问津,那么是不是可以根据一定规则,让缓存自主失效就可以了?那么为缓存设计一个失效时间就可以了?
步骤二:为缓存设置超时时间
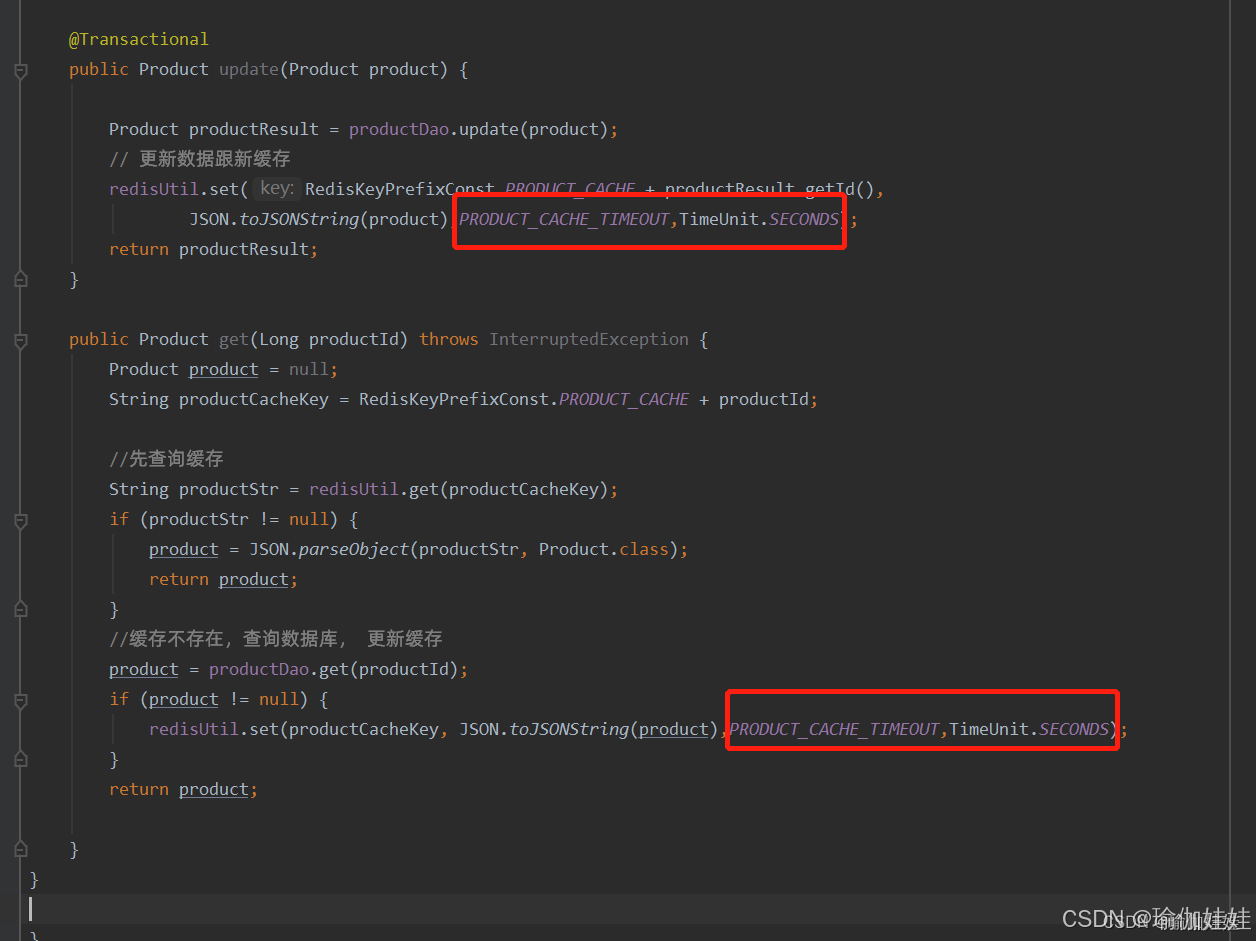
存在的问题:热点缓存也会失效
在为缓存设置超时时间后,那么热点数据的缓存,在该设置的时间内,也会失效,那么缓存失效后,大量请求查询无缓存后,都会请求到数据库,这样会造成数据库的压力增大。
解决思路:为热点缓存续命
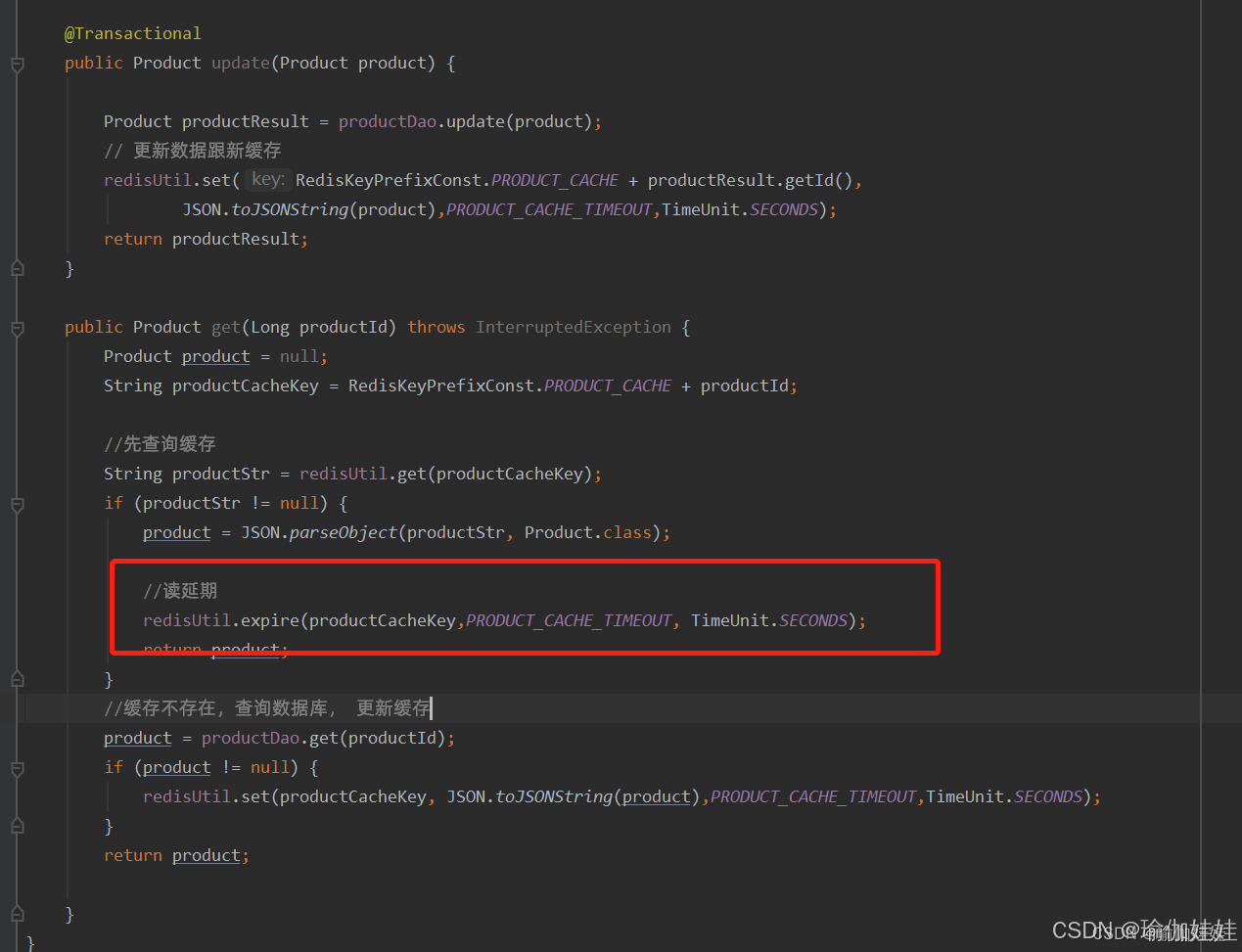
如何在缓存设置了失效时间后,只是让冷数据失效,热数据不失效呢?此时您有没有想到为热点数据的缓存续命的方法吗?那就每次请求查询缓存后,为该缓存重新设置缓存失效时间,延长其失效时间,这样是不是就为其续命了呢?
步骤三:数据查询缓存后,重新设置缓存过期时间,为其续命
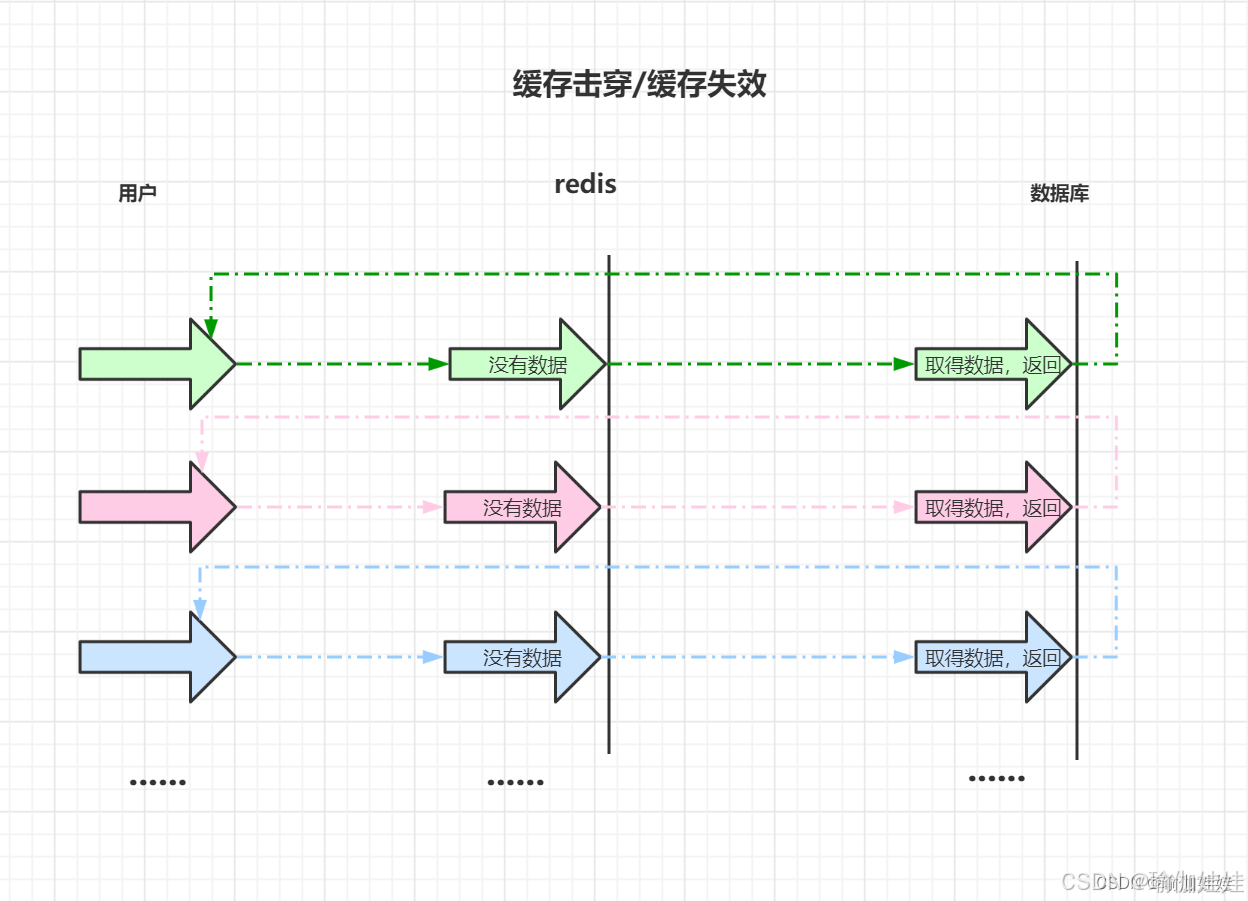
存在的问题:缓存击穿/缓存失效
上述方案中,如果您批量导入数据或者批量新增数据,那么这些数据建立缓存时缓存失效的时间会差不多一样,那么就会出现大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大甚至挂掉。
解决思路:如何保证缓存不同一时间失效
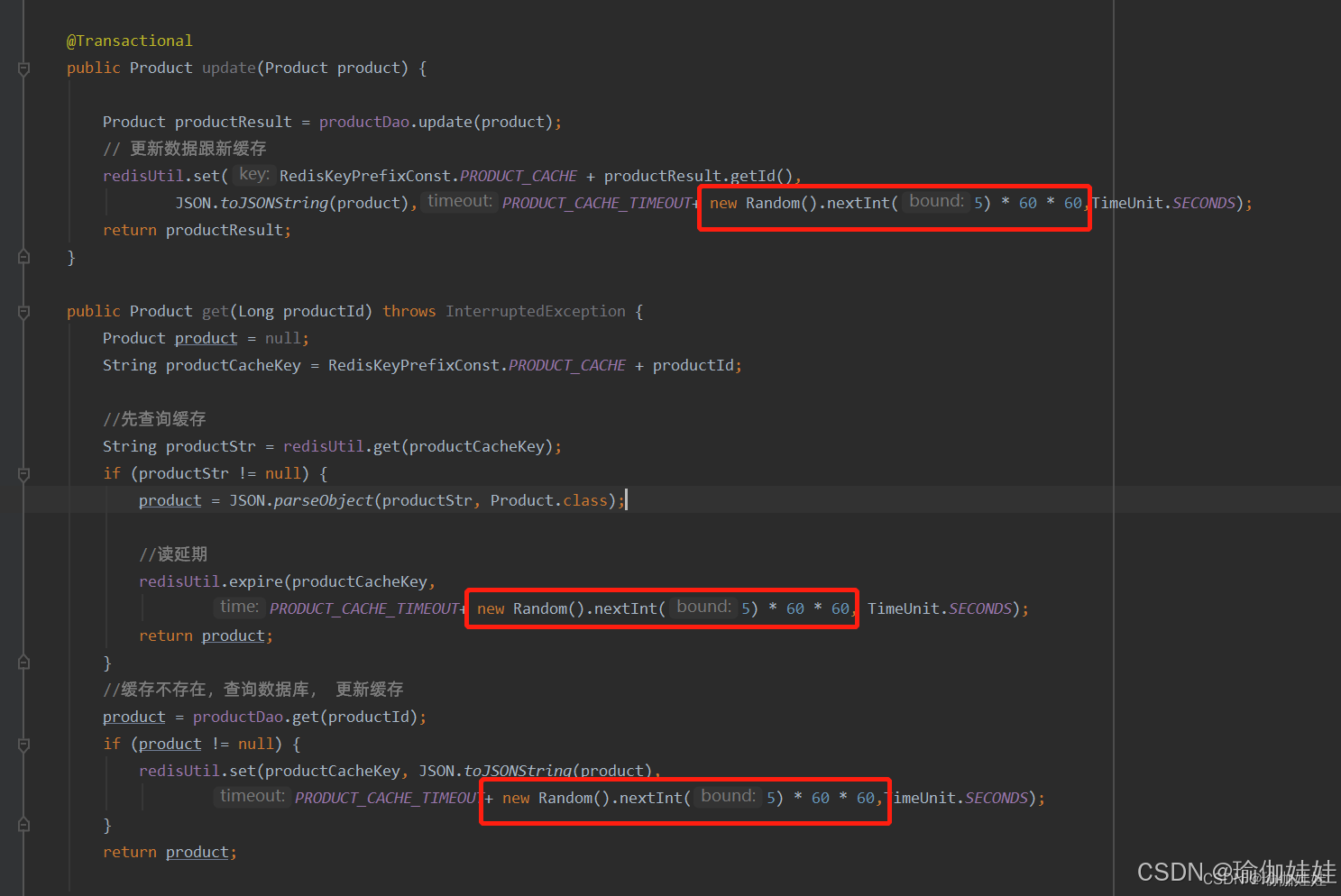
上述方案中,大量请求直击数据库的主要原因是因为缓存失效的时间也是同一时间,那么如何让缓存失效时间不一样呢?在设置缓存失效时,给设置不一样的时间是不是就可以了?例如在设计缓存时在设定时间上再加上一个随机时间。
步骤四:为缓存设置不一样的失效时间
存在的问题:缓存穿透
写到这里,您是不是觉得,这下没有问题了吧?还有一下小概率时间还未考虑到呢,比如缓存穿透的问题。
缓存穿透:
- 是指查询一个根本不存在的数据,缓存层和存储层都不会命中。
- 缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。
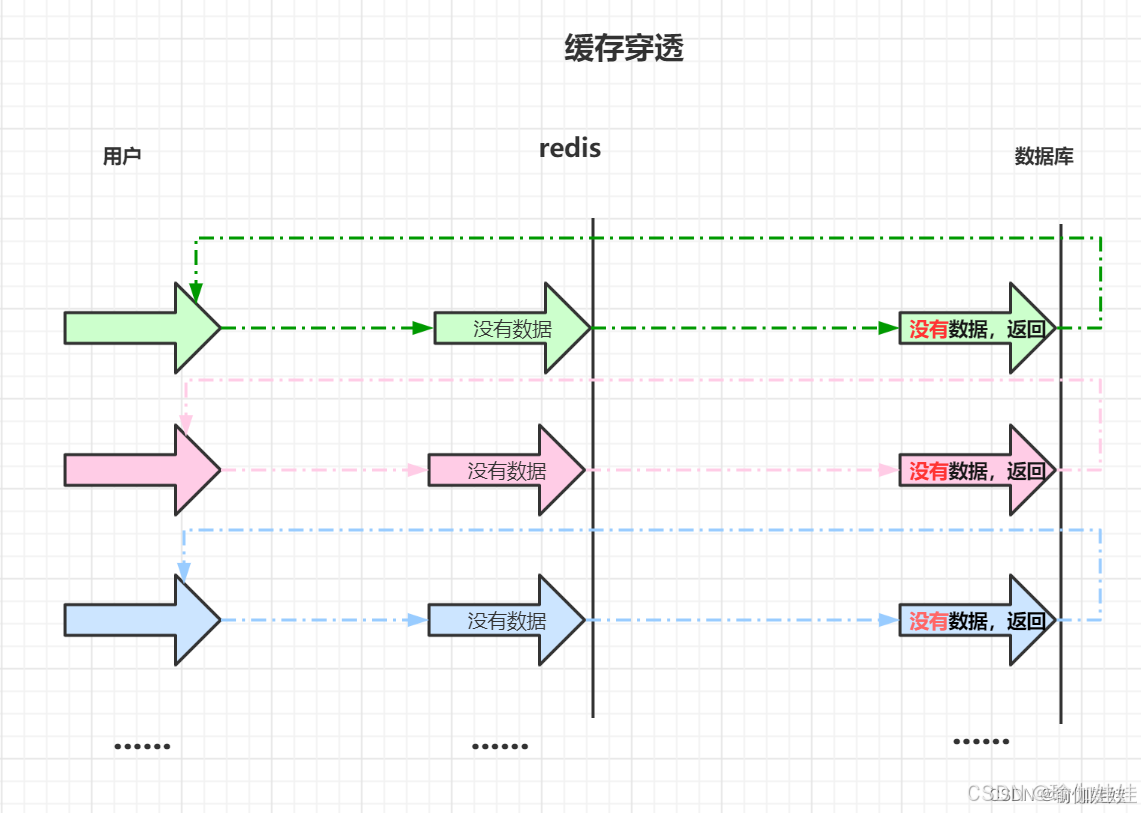
造成缓存穿透的基本原因:
- 自身业务代码或者数据出现问题。
- 一些恶意攻击、 爬虫等造成大量空命中。
解决思路:拦截查询不存在数据请求,禁止直击数据库
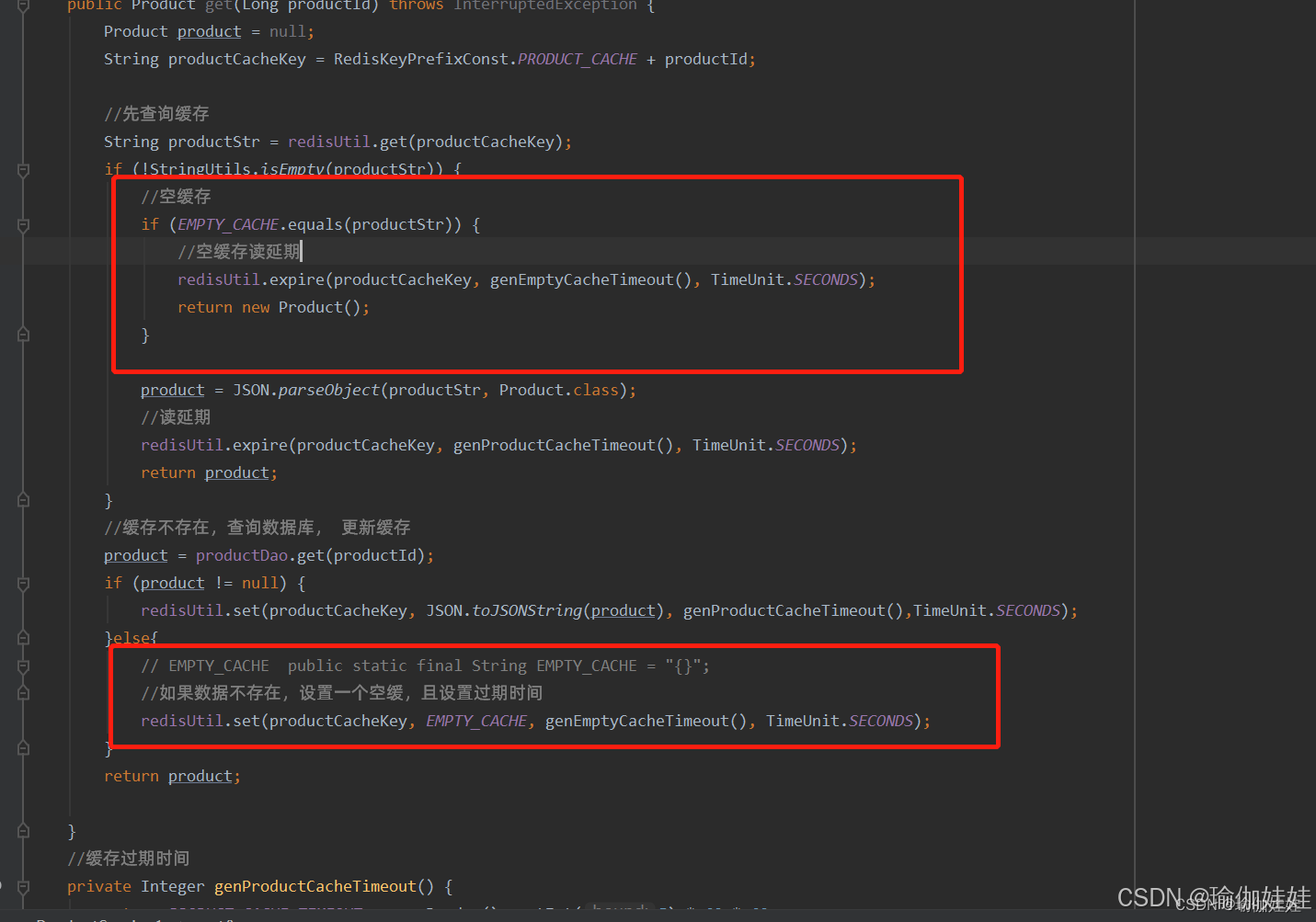
怎么拦截这些查询不存在数据的请求呢?究其根本原因是,请求第一次查询缓存时,缓存没有,又继续查询数据库,数据库没有的就直接返回了。同样的请求会重复这样的动作。
想一下如何能拦截除第一次以外这样的请求呢?那可不可以在第一次这样的请求后,在其查询数据库也没有的后,仍然为其创建一个空缓存,这样其他请求是不是就会被拦截到缓存层,就不会直击数据库了呢?
只是为其创建一个空缓存就够了吗?那么恶意攻击后,这样Redis中是不是还会存在这种大量的空缓存,浪费Redis 内存呢? 同样的,还需为其加一个过期时间。
那么如果对同一个不存在的数据恶意请求呢?那是不是还需要为其对应的空缓存续命呢?
步骤五:为不存在的数据创建空缓存并为其指定过期时间,并对重复请求的空缓存续命
存在的问题:冷数据突变热数据,导致众多获取冷数据的请求直接打在了数据库
比如大V直播间对冷产品的推广,导致大量用户同一时间抢购同一冷商品(缓存已经过期),导致大量请求直达数据库,造成数据库压力突然暴增。
解决思路:只让一个查询冷数据的请求查询数据库并为其创建缓存,其他请求查缓存
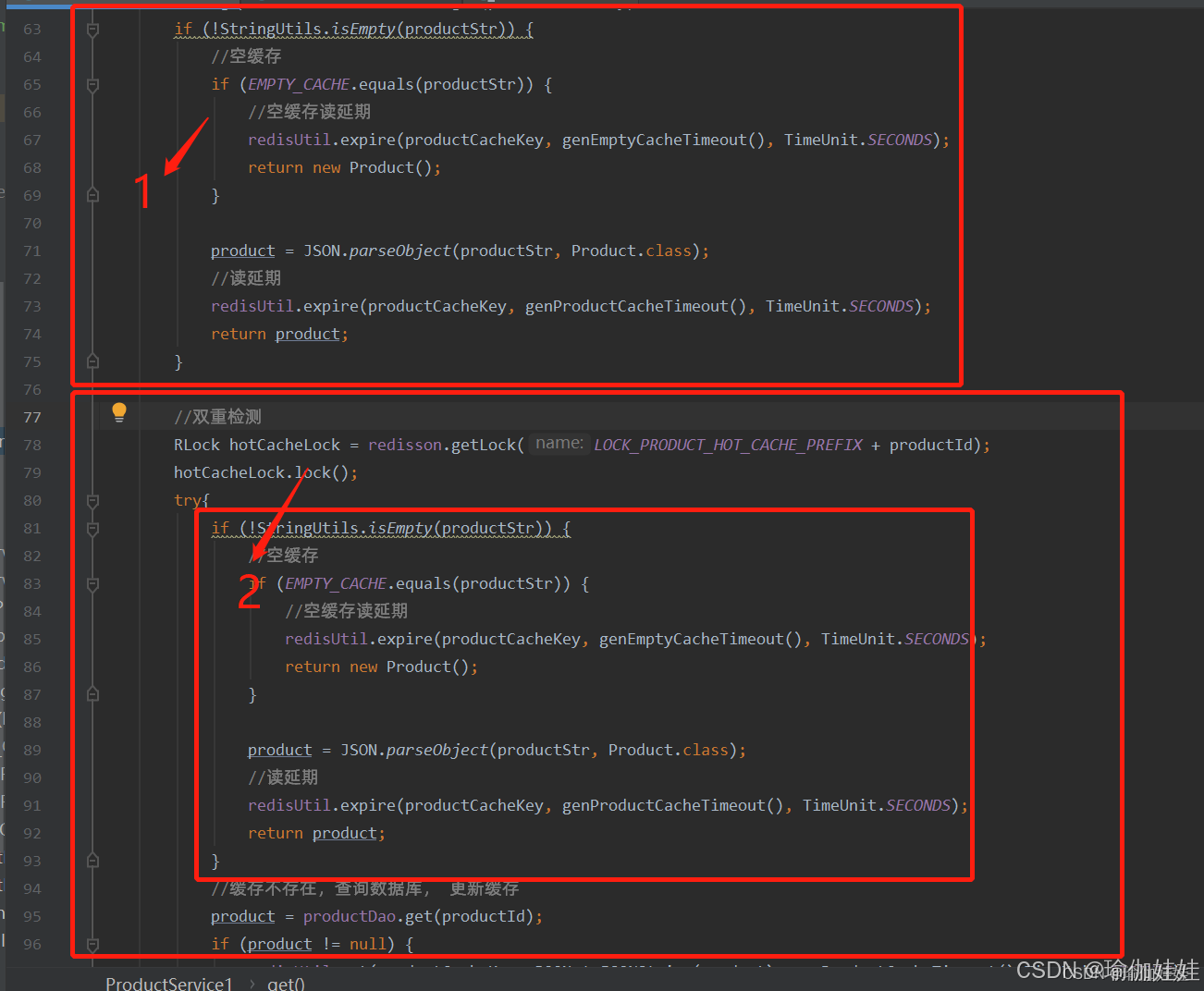
如何让众多请求中的一个查询查询数据库,并创建缓存,而其他请求查询该请求创建后的缓存呢?这听起来是不是有一个顺序的含义?谈到顺序,您是否想到锁机制呢?是的,这种场景,可以使用一把锁,解决该问题,思路如下:
当多个请求过来时,查询缓存没有数据时,要去查数据库前,获取一把锁,这样就能保证有一个请求该数据后,这个数据就存在了缓存中。
在获取锁后,再查询一次缓存,保证其他请求,获取锁后,直接查缓存,然后直接返回。
总结:上述锁已经能解决99%的问题,但是还存在一定缺陷
虽然上述锁已经解决了大多数问题,但还是有一些小概率问题会出现,例如以下问题:
- 缓存与数据库双写不一致问题。
例如线程A查询缓存为空,然后去读数据库,在读完数据库后,准备写缓存时,系统卡顿了,就在这期间,有一个线程B将数据做了更改,但待系统恢复后,线程A继续执行写入缓存的操作,但此时数据库中的内容已经是线程B更改过的数据了。 - 热点数据突然暴增导致系统奔溃问题。
热点数据突然访问过大,同一时刻又几十万、上百万的请求过来,Redis单节点也就能扛10万的并发,这种超大压力,都可能打垮Redis,导致系统崩溃。 - 缓存雪崩问题。
缓存雪崩指的是缓存层由于某些原因不能提供服务,导致大量请求都会打到存储层, 存储层的调用量会暴增, 最终造成存储层也会级联宕机的情况。
根据前面分析解决每个缓存设计出现问题的思路,针对这三个问题,您是否有解决思路呢?如果没有,您可参见https://blog.csdn.net/weixin_43134177/article/details/134151930,为您提供一定解决方案。





)




模式可以在不修改对象外观和功能的情况下添加或者删除对象功能)








