1 开发背景
VGGNet是牛津大学视觉几何组(Visual Geometry Group)提出的模型,该模型在2014ImageNet图像分类与定位挑战赛 ILSVRC-2014中取得在分类任务第二,定位任务第一的优异成绩。其核心贡献在于系统性地探索了网络深度对性能的影响,并证明了通过堆叠非常小的卷积核(3x3)可以显著提升网络性能。
论文地址:1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition![]() https://arxiv.org/abs/1409.1556
https://arxiv.org/abs/1409.1556
论文详解:(51 封私信 / 60 条消息) 经典神经网络超详细解读(五)VGG网络(论文精读+网络详解+代码实战) - 知乎![]() https://zhuanlan.zhihu.com/p/27715976701
https://zhuanlan.zhihu.com/p/27715976701
2 网络结构
2.1 VGG的核心思想
-
采用更深的网络结构:相比 AlexNet(8 层),VGG 增加到了 16 或 19 层,提升了网络的表达能力。
-
使用小卷积核(3×3)和多个连续的卷积层:所有卷积层都使用 3×3 卷积核,而不是较大的 5×5 或 7×7,这样可以:
-
每个卷积层后面通常跟着一个ReLU激活函数,多个卷积层可以增加非线性能力(两个 3×3 卷积相当于一个 5×5 卷积);
-
与使用大尺寸卷积核的单一层相比,多个小卷积层的堆叠可以提供更好的特征提取能力;
-
减少参数数量(比单个 5×5 卷积的参数更少)。
这里说明一下为什么两个 3×3 卷积相当于一个 5×5 卷积,以及为什么参数数量变少了:
如上图所示,如果我们使用一个 5×5 的卷积核对一个 5×5 的图像进行卷积,最后可以得到一个 1×1 的输出,而使用 3×3 的卷积核进行两次连续的卷积,同样可以得到 1×1 的输出。同理,三个 3×3 的卷积相当于一个 7×7 的卷积。一个3×3卷积核在处理具有64个输入通道的特征图时,只有577(3×3×64+1=577,加的1是偏置项)个参数,而一个11x11的卷积核则有7745(11×11×64+1)个参数,7745>577×2。这种参数数量的显著差异意味着使用小卷积核可以大幅减少网络的参数量。
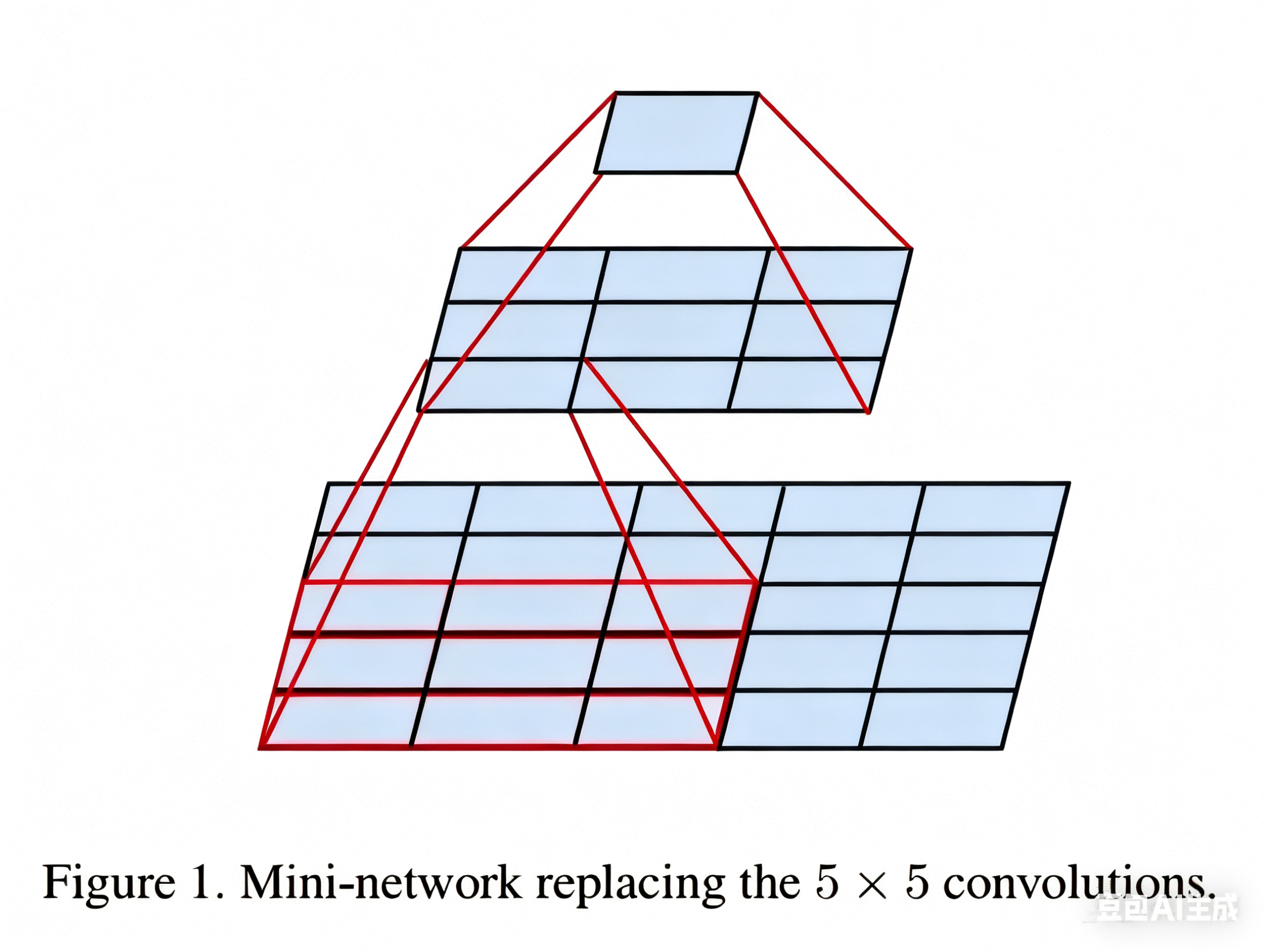
2.2 VGG架构实验
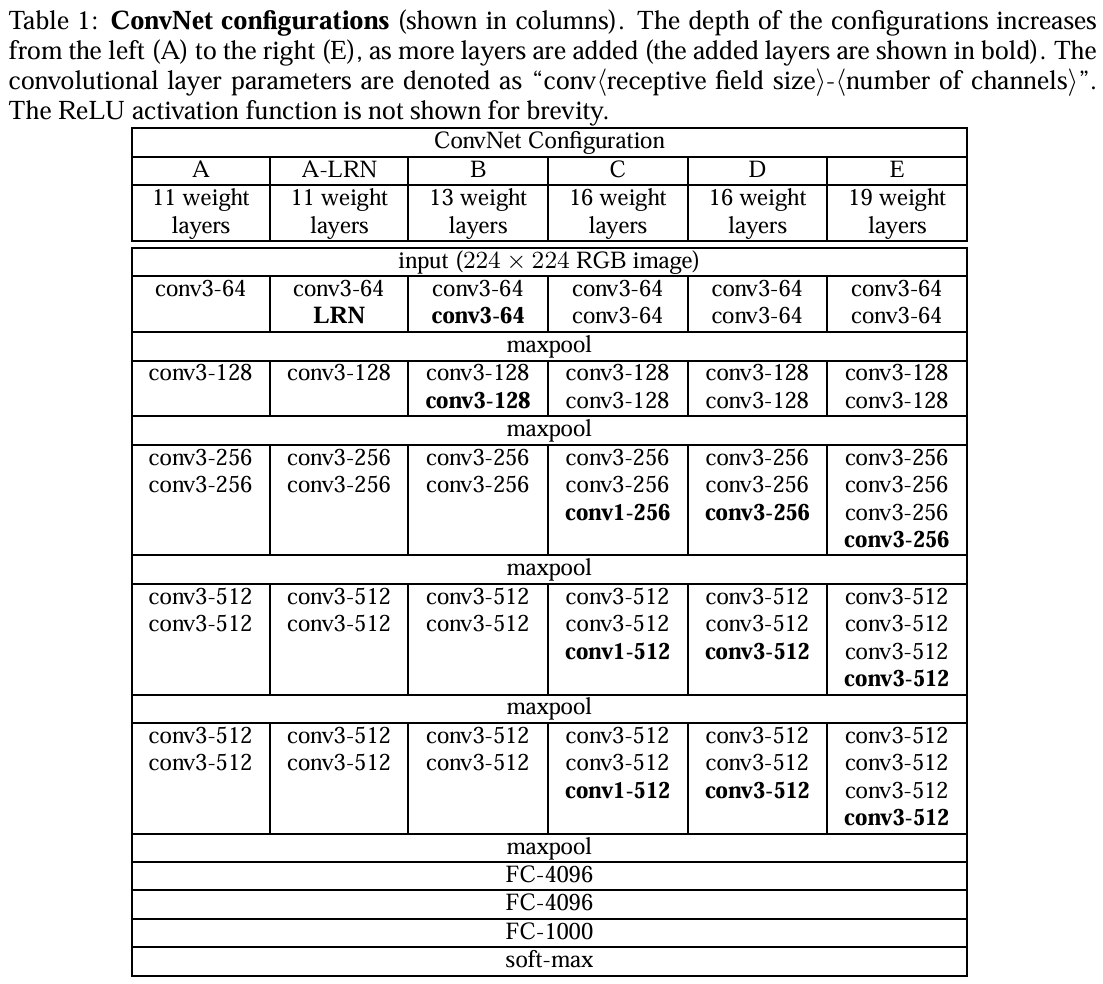
上图是论文中六次实验的结果图。VGG网络的卷积层全部为3*3的卷积核,用conv3-xxx来表示,xxx表示通道数。
-
第一组(A)就是个简单的卷积神经网络,没有啥花里胡哨的地方。
-
第二组(A-LRN)在第一组的卷积神经网络的基础上加了LRN(LRN:局部响应归一化,一种正则化手段,现在已不是主流了,LRN是Alexnet中提出的方法,在Alexnet中有不错的表现 )
-
第三组(B)在A的基础上加了两个conv3,即多加了两个3*3卷积核
-
第四组(C)在B的基础上加了三个conv1,即多加了三个1*1卷积核
-
第五组(D)在C的基础上把三个conv1换成了三个3*3卷积核
-
第六组(E)在D的基础上又加了三个conv3,即多加了三个3*3卷积核
结论:
1.第一组和第二组进行对比,LRN在这里并没有很好的表现;
2.第四组和第五组进行对比,conv3比conv1好使;
3.统筹看这六组实验,会发现随着网络层数的加深,模型的表现会越来越好。
据此可简单总结:作者一共实验了6种网络结构,其中VGG16(D)和VGG19(E)分类效果最好(16、19层隐藏层),证明了增加网络深度能在一定程度上影响最终的性能。 两者没有本质的区别,只是网络的深度不一样。
2.3 VGG16架构
下面以VGG16为例做具体讲解。
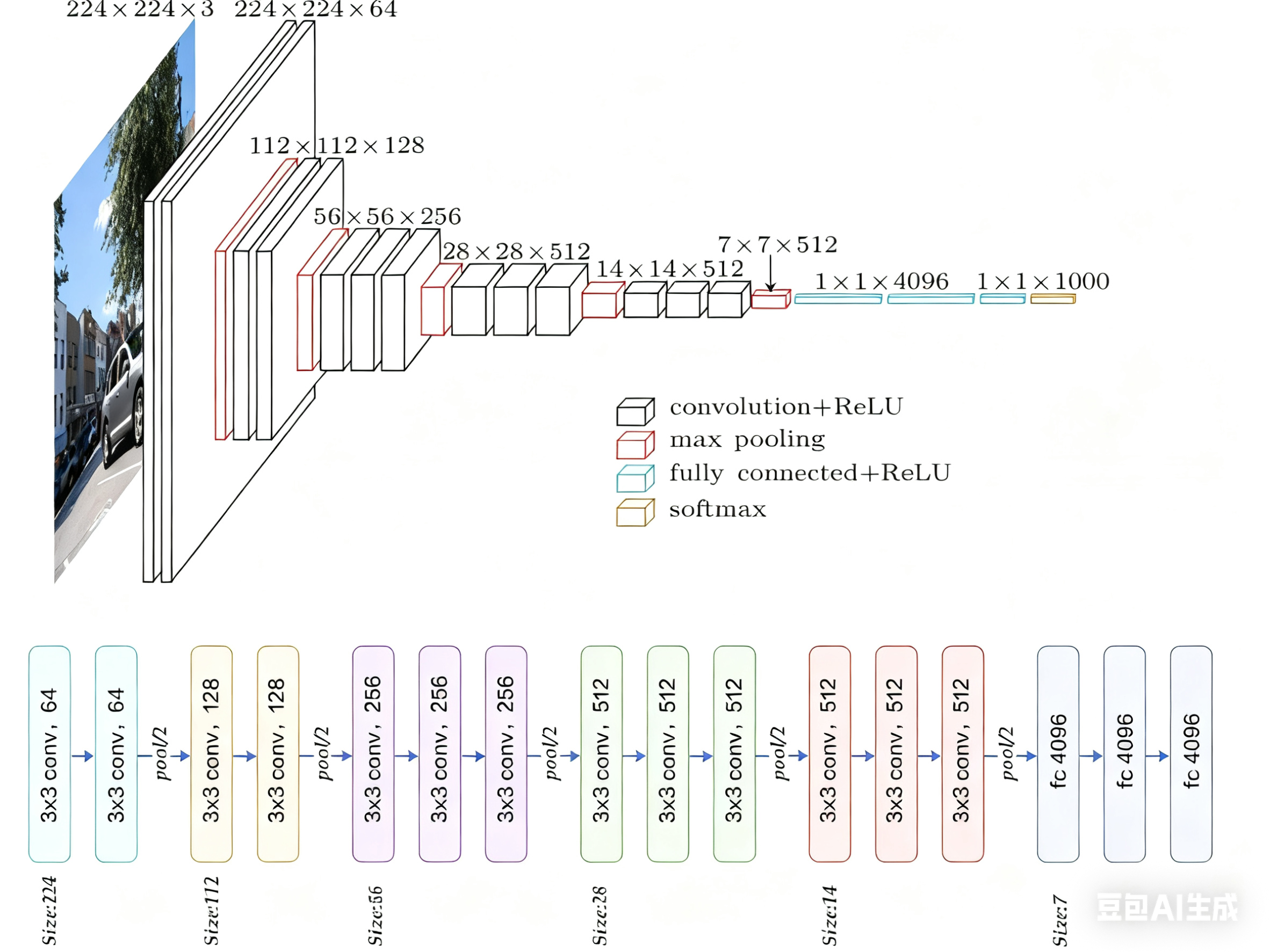
VGG16是最常用和最经典的VGG变体之一。数字“16”指的是网络中包含权重参数的层数,即13个卷积层 + 3个全连接层 = 16层。池化层和激活层不计入此数。
具体参数如下:
| 阶段 | 层类型 | 输出尺寸 (C x H x W) | 参数配置 (核大小/步长/填充) | 输出通道数 | 备注 |
|---|---|---|---|---|---|
| 输入 | Input Image | 3 x 224 x 224 | - | - | 假设输入图像尺寸为224x224 |
| Block 1 | Conv3-64 | 64 x 224 x 224 | 3x3 / 1 / 1 | 64 | |
| Conv3-64 | 64 x 224 x 224 | 3x3 / 1 / 1 | 64 | ||
| MaxPool | 64 x 112 x 112 | 2x2 / 2 | - | 尺寸减半 | |
| Block 2 | Conv3-128 | 128 x 112 x 112 | 3x3 / 1 / 1 | 128 | |
| Conv3-128 | 128 x 112 x 112 | 3x3 / 1 / 1 | 128 | ||
| MaxPool | 128 x 56 x 56 | 2x2 / 2 | - | 尺寸减半 | |
| Block 3 | Conv3-256 | 256 x 56 x 56 | 3x3 / 1 / 1 | 256 | |
| Conv3-256 | 256 x 56 x 56 | 3x3 / 1 / 1 | 256 | ||
| Conv3-256 | 256 x 56 x 56 | 3x3 / 1 / 1 | 256 | ||
| MaxPool | 256 x 28 x 28 | 2x2 / 2 | - | 尺寸减半 | |
| Block 4 | Conv3-512 | 512 x 28 x 28 | 3x3 / 1 / 1 | 512 | |
| Conv3-512 | 512 x 28 x 28 | 3x3 / 1 / 1 | 512 | ||
| Conv3-512 | 512 x 28 x 28 | 3x3 / 1 / 1 | 512 | ||
| MaxPool | 512 x 14 x 14 | 2x2 / 2 | - | 尺寸减半 | |
| Block 5 | Conv3-512 | 512 x 14 x 14 | 3x3 / 1 / 1 | 512 | |
| Conv3-512 | 512 x 14 x 14 | 3x3 / 1 / 1 | 512 | ||
| Conv3-512 | 512 x 14 x 14 | 3x3 / 1 / 1 | 512 | ||
| MaxPool | 512 x 7 x 7 | 2x2 / 2 | - | 尺寸减半 | |
| FC | Flatten | 1 x 25088 | - | - | 将特征图展平为一维向量 |
| FC-4096 | 4096 | - | 4096 | 全连接层1 | |
| FC-4096 | 4096 | - | 4096 | 全连接层2 | |
| FC-1000 | 1000 | - | 1000 | 输出层 (Softmax) |
关键点说明
-
卷积块(Conv Block): 每个Block由连续的2-3个3x3卷积层组成,通道数在Block内保持不变(如Block1都是64通道),在Block之间通过池化层后翻倍(64->128->256->512->512)。Block5的通道数没有继续翻倍,保持512。
-
池化层(MaxPool): 位于每个卷积块之后,负责降低空间维度(H, W减半),增加感受野,并一定程度上提供平移不变性。
-
全连接层(FC):
-
在最后一个池化层(输出尺寸为
512 x 7 x 7)之后,将特征图展平(Flat) 成一个长度为512 * 7 * 7 = 25088的一维向量。 -
然后依次通过两个4096维的全连接层(通常使用ReLU激活和Dropout防止过拟合)。
-
最后是一个1000维的全连接层(对应ImageNet的1000类),使用Softmax函数输出每个类别的预测概率。
-
-
激活函数: 所有卷积层和全连接层(除最后一层)之后都使用ReLU激活函数,引入非线性。
-
参数量: VGG16的总参数量约为138 million (1.38亿)。其中,绝大部分参数(约90%)集中在最后的三个全连接层(FC-4096: ~102M, FC-4096: ~102M, FC-1000: ~4M)。卷积层的参数量相对较少(约27M)。
3 VGG的优缺点
3.1 核心优点
-
设计简洁统一,易于理解与实现
-
规则化结构:所有卷积层均使用 3×3核(除少量1×1卷积),所有池化层均使用 2×2最大池化,模块化设计清晰。
-
配置单一:卷积层参数固定(
stride=1, padding=1),池化层参数固定(stride=2),无需复杂调参。 -
代码复用性高:相同结构的卷积块可循环实现,降低工程复杂度。
-
-
深度网络性能的强力证明
-
深度提升效果显著:通过对比VGG11(11层)到VGG19(19层),证明增加深度能持续提升精度(ImageNet Top-5错误率从10.4%降至7.3%)。
-
小卷积核的优越性:
在相同感受野的情况下,堆叠小卷积核相比使用大卷积核具有更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,可使决策函数更加具有辨别能力;此外,3x3比7x7就足以捕获细节特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化;3个3x3堆叠近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,网络容量更大,对于不同类别的区分能力更强。
-
-
强大的特征提取能力
-
分层特征学习:
-
浅层(Block1-2)学习边缘、纹理等低级特征。
-
中层(Block3-4)学习物体部件等中级特征。
-
深层(Block5-FC)学习语义等高级特征。
-
-
特征泛用性强:预训练模型(尤其VGG16/19)的卷积层特征被广泛用于迁移学习(如目标检测、图像分割)。
-
3.2 显著缺点
-
参数量巨大,计算成本高昂
-
参数分布:
层类型 参数量(VGG16) 占比 卷积层 ≈14.7M 10.6% 全连接层 ≈123.6M 89.4% 总计 ≈138.3M 100% -
计算开销:
-
训练需大量GPU资源(如VGG19训练耗时约2-3周,单卡V100)。
-
推理速度慢(224×224图像在V100上约100ms,远低于MobileNet)。
-
-
-
全连接层(FC)的致命缺陷
-
参数冗余:FC层占90%参数,但贡献有限(后续研究表明可用全局平均池化替代)。
-
空间限制:FC层要求固定输入尺寸(如224×224),需对图像裁剪/缩放,可能丢失信息。
-
过拟合风险:FC层参数多,在小型数据集上易过拟合(需强正则化如Dropout)。
-
-
内存与存储瓶颈
-
显存占用高:训练时需存储大量中间特征图(如Block5输出512×7×7,需≈10MB显存)。
-
模型体积大:VGG16模型文件超500MB,不适合移动端/嵌入式部署。
-
-
用多个 3×3卷积代替大卷积,会增加网络深度,深度过大可能带来梯度消失或梯度爆炸问题。
-
解决方案:
-
使用 Batch Normalization(BN) 进行归一化。
-
采用 ResNet 残差连接,保证梯度有效传播。
-
-
-
结构僵化,缺乏创新性
-
无多尺度处理:未采用Inception的多分支结构或ResNet的残差连接,特征融合能力弱。
-
通道设计保守:通道数仅按2倍增长(64→128→256→512),未探索更高效的通道分配策略。
-
总结:VGG是深度学习史上的“功勋模型”,其简洁设计和深度探索为后续发展铺平道路。尽管因参数冗余、计算低效逐渐退出主流,但其特征提取能力和设计思想仍具重要参考价值。在资源充足或需要强特征的任务中,VGG仍是可靠选择;但对效率敏感的场景,需选择更现代的轻量架构。
4 基于Pytorch实现
以下项目实现了 VGG 网络,并在 CIFAR10 上验证了该网络的有效性,项目目录如下:
VGG_CIFAR10/│├── model/ # 存放模型定义│ ├── __init__.py│ └── VGG.py # VGG模型定义│├── data/ # 存放数据集(CIFAR-10会自动下载)│├── utils/ # 工具函数│ ├── __init__.py│ ├── transforms.py # 数据预处理│ └── visualization.py # 可视化工具│├── train.py # 训练脚本├── test.py # 测试脚本└── config.py # 配置文件配置文件
# config.pyimport torch# 训练参数class Config:# 数据参数data_dir = './data'batch_size = 128num_workers = 4# 模型参数num_classes = 10model_name = 'vgg16'# 训练参数num_epochs = 50learning_rate = 0.01momentum = 0.9weight_decay = 5e-4lr_step_size = 30lr_gamma = 0.1# 其他device = 'cuda' if torch.cuda.is_available() else 'cpu'save_path = './checkpoints/'log_interval = 100模型定义
# VGG.pyimport torchimport torch.nn as nnclass VGG(nn.Module):def __init__(self, num_classes=10, init_weights=True):super(VGG, self).__init__()# 特征提取部分(卷积层)self.features = nn.Sequential(# Block 1nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64), # 添加批归一化nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 2nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 3nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 4nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 5nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))# 分类器部分(全连接层)self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(0.5), # 增加Dropout率nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(4096, num_classes))if init_weights:self._initialize_weights()def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)def vgg16(num_classes=10):return VGG(num_classes=num_classes)工具函数
# transforms.pyimport torchvision.transforms as transformsdef get_train_transform():return transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15), # 添加随机旋转transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), # 颜色抖动transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])def get_test_transform():return transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),]) # visualization.pyimport matplotlib.pyplot as pltimport numpy as npimport torch'''用于训练可视化'''def plot_results(train_losses, train_accs, test_losses, test_accs):plt.figure(figsize=(12, 4))# 绘制损失曲线plt.subplot(1, 2, 1)plt.plot(train_losses, label='Train Loss')plt.plot(test_losses, label='Test Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.title('Training and Test Loss')# 绘制准确率曲线plt.subplot(1, 2, 2)plt.plot(train_accs, label='Train Accuracy')plt.plot(test_accs, label='Test Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.title('Training and Test Accuracy')plt.tight_layout()plt.savefig('results.png')plt.show()'''用于测试可视化'''def visualize_predictions(model, device, test_loader, classes, num_samples=8):# 获取一批测试数据dataiter = iter(test_loader)images, labels = next(dataiter)# 选择前num_samples个样本images = images[:num_samples]labels = labels[:num_samples]# 将图像移至设备images = images.to(device)# 获取模型预测outputs = model(images)_, predicted = torch.max(outputs, 1)# 将预测和标签移回CPUpredicted = predicted.cpu().numpy()labels = labels.numpy()# 显示图像plt.figure(figsize=(12, 6))for i in range(num_samples):plt.subplot(2, 4, i + 1)# 反归一化img = images[i].cpu().numpy().transpose(1, 2, 0)mean = np.array([0.4914, 0.4822, 0.4465])std = np.array([0.2023, 0.1994, 0.2010])img = std * img + meanimg = np.clip(img, 0, 1)plt.imshow(img)plt.title(f"True: {classes[labels[i]]}\nPred: {classes[predicted[i]]}")plt.axis('off')plt.tight_layout()plt.savefig('predictions.png')plt.show()模型训练
# train.pyimport torchimport torch.optim as optimimport torch.nn.functional as Ffrom torch.utils.data import DataLoaderfrom torchvision import datasetsimport osimport timefrom tqdm import tqdmfrom model.VGG import vgg16from utils.transforms import get_train_transform, get_test_transformfrom utils.visualization import plot_resultsfrom config import Configdef train(model, device, train_loader, optimizer, epoch, config):model.train()running_loss = 0.0correct = 0total = 0progress_bar = tqdm(train_loader, desc=f'Epoch {epoch}/{config.num_epochs}')for batch_idx, (inputs, targets) in enumerate(progress_bar):inputs, targets = inputs.to(device), targets.to(device)# 前向传播outputs = model(inputs)loss = F.cross_entropy(outputs, targets)# 反向传播与优化optimizer.zero_grad()loss.backward()optimizer.step()# 统计信息running_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# 更新进度条progress_bar.set_postfix({'Loss': running_loss / (batch_idx + 1),'Acc': 100. * correct / total})train_loss = running_loss / len(train_loader)train_acc = 100. * correct / totalreturn train_loss, train_accdef test(model, device, test_loader):model.eval()test_loss = 0correct = 0total = 0with torch.no_grad():for inputs, targets in test_loader:inputs, targets = inputs.to(device), targets.to(device)outputs = model(inputs)test_loss += F.cross_entropy(outputs, targets, reduction='sum').item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()test_loss /= len(test_loader.dataset)test_acc = 100. * correct / totalreturn test_loss, test_accdef main():config = Config()# 创建保存目录os.makedirs(config.save_path, exist_ok=True)# 加载数据集train_set = datasets.CIFAR10(root=config.data_dir, train=True, download=True, transform=get_train_transform())test_set = datasets.CIFAR10(root=config.data_dir, train=False, download=True, transform=get_test_transform())train_loader = DataLoader(train_set, batch_size=config.batch_size, shuffle=True, num_workers=config.num_workers)test_loader = DataLoader(test_set, batch_size=config.batch_size, shuffle=False, num_workers=config.num_workers)# 创建模型model = vgg16(num_classes=config.num_classes).to(config.device)# 打印模型结构print(model)# 定义优化器和损失函数optimizer = optim.SGD(model.parameters(),lr=config.learning_rate,momentum=config.momentum,weight_decay=config.weight_decay)scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=config.lr_step_size, gamma=config.lr_gamma)# 训练记录train_losses = []train_accs = []test_losses = []test_accs = []best_acc = 0.0# 训练循环for epoch in range(1, config.num_epochs + 1):start_time = time.time()# 训练train_loss, train_acc = train(model, config.device, train_loader, optimizer, epoch, config)# 测试test_loss, test_acc = test(model, config.device, test_loader)# 学习率调整scheduler.step()# 记录train_losses.append(train_loss)train_accs.append(train_acc)test_losses.append(test_loss)test_accs.append(test_acc)# 保存最佳模型if test_acc > best_acc:best_acc = test_acctorch.save(model.state_dict(), os.path.join(config.save_path, 'best_model.pth'))# 打印信息elapsed_time = time.time() - start_timeprint(f'Epoch {epoch}/{config.num_epochs} - Time: {elapsed_time:.2f}s')print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%')print(f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')print(f'Best Test Acc: {best_acc:.2f}%\n')# 绘制结果plot_results(train_losses, train_accs, test_losses, test_accs)print(f'Training completed. Best test accuracy: {best_acc:.2f}%')if __name__ == '__main__':main()模型测试
# test.py
import torchfrom torch.utils.data import DataLoaderfrom torchvision import datasetsimport osfrom model.VGG import vgg16from utils.transforms import get_test_transformfrom utils.visualization import visualize_predictionsfrom config import Configdef main():config = Config()# 加载测试数据集test_set = datasets.CIFAR10(root=config.data_dir, train=False, download=True, transform=get_test_transform())test_loader = DataLoader(test_set, batch_size=config.batch_size, shuffle=False, num_workers=config.num_workers)# 加载模型model = vgg16(num_classes=config.num_classes).to(config.device)model.load_state_dict(torch.load(os.path.join(config.save_path, 'best_model.pth')))model.eval()# 类别标签classes = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')# 可视化预测结果visualize_predictions(model, config.device, test_loader, classes)if __name__ == '__main__':main()

)








)


 的兼容性问题)




