
近年来,工业异常检测(Anomaly Detection)在智能制造、质量监控等领域扮演着越来越重要的角色。传统方法通常依赖大量正常样本进行训练,而在实际生产中,异常样本稀少甚至不存在,能否仅凭少量正常样本就实现精准的异常检测,成为了一项重要挑战。
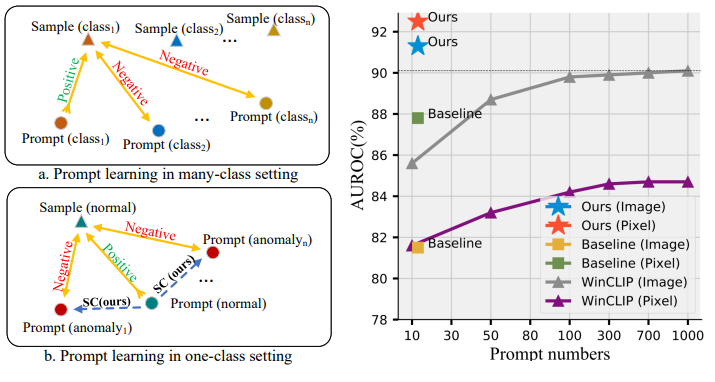
PromptAD 方法首次将提示学习(Prompt Learning) 引入单类别异常检测任务中,仅使用正常样本就能自动学习有效的提示词,在多个标准数据集上取得了领先性能。
少样本异常检测的难点
异常检测本质上是一个单类别分类(One-Class Classification, OCC) 问题:训练时只有正常样本,测试时则需要识别出异常。
现有的基于视觉-语言模型(如CLIP)的方法(例如WinCLIP)虽然效果显著,但依赖大量人工设计的提示词(Prompt Ensemble),需要组合成百上千个文本提示才能达到理想效果。这不仅费时费力,还难以自动化部署。
更遗憾的是,传统的多类别提示学习方法(如CoOp)在异常检测任务上表现不佳,因为它们缺乏负样本(异常样本)的对比信息。
总结而言异常样本太少、异常千奇百怪、人工成本高。
PromptAD创新方案
PromptAD 之所以能够在 “只看正常样本” 的情况下依旧精准检测异常,关键在于它提出了三大创新:
语义拼接(Semantic Concatenation,SC)
在小样本异常检测中,训练集通常只包含正常样本,没有异常样本可供学习。
而传统的 Prompt 学习依赖“对比学习”(Contrastive Learning):正常和异常要互相对比,模型才能学会区分。
但如果没有异常样本,这个“对比”就无法进行。
核心思路
研究者提出了一种巧妙的方法:通过语言构造虚拟异常。
给正常的提示词加上“异常后缀”,从而生成异常提示词。
举例:
正常提示词:“a photo of cable”(一张电缆的照片)
异常提示词:“a photo of cable with flaw”(一张有缺陷的电缆照片)
这样,哪怕没有真实异常图像,模型也能通过这些“虚拟异常描述”来建立对比关系,从而学会区分正常和异常。
技术细节
手工异常后缀(MAP):利用数据集里的标签信息(如 crack、stain、hole 等),拼接成异常提示词。
可学习异常后缀(LAP):在手工后缀之外,再增加一组可学习的“异常符号”,不断训练,让模型自己去探索更丰富的异常语义。
结果:正常提示词(NP)与异常提示词(MAP/LAP)共同参与训练,形成有效的对比学习。
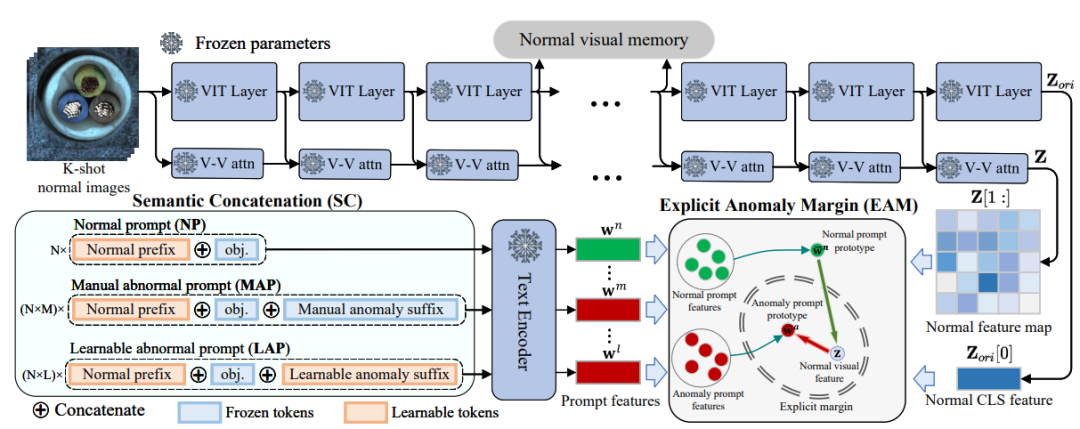
显式异常边界(Explicit Anomaly Margin,EAM)
即使通过语义拼接生成了异常提示词,仍然有一个问题:
这些异常提示词并不来自真实异常样本,模型无法自动判断“正常”和“异常”之间该保持多大的差距。
核心思路
研究者提出了显式异常边界的概念:
在训练过程中,引入一个超参数,强制约束:
正常样本与正常提示词的距离要比正常样本与异常提示词的距离更小。
换句话说,在特征空间里画一条“安全边界”,让正常与异常的分布明显分开。
技术细节
使用了正则化损失函数,使得模型在学习时不断维持这个边界。
为了让可学习的异常提示(LAP)更贴近真实语义,还引入了一个“对齐机制”,让 LAP 的分布与 MAP 保持一致。
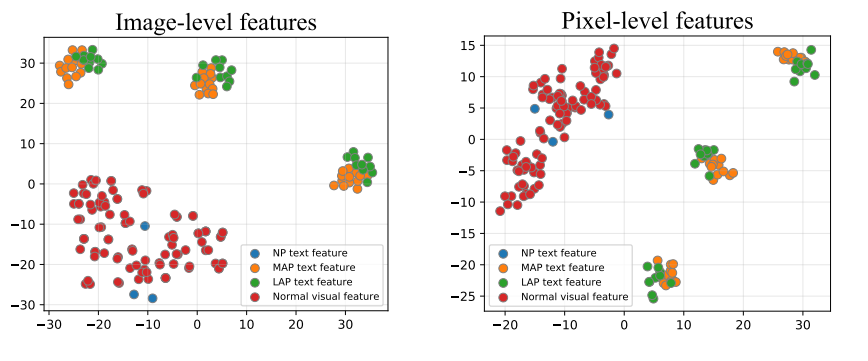
双重检测机制:Prompt + Vision
异常检测既需要整体判断(这张图是否异常?),又需要局部定位(异常具体在哪?)。
单靠 Prompt 引导(语义信息)或单靠图像特征(视觉信息)都不够全面。
核心思路
PromptAD 结合了两种机制:
Prompt-guided AD (PAD)
利用语义信息(Prompt)来判断正常 vs 异常。
擅长 图像级别 的分类。
Vision-guided AD (VAD)
在训练阶段记忆“正常样本”的局部特征,在测试时对比差异。
擅长像素级别的定位。
融合
两者结果通过调和平均进行融合,既保证整体判断,又能精确圈出异常区域。
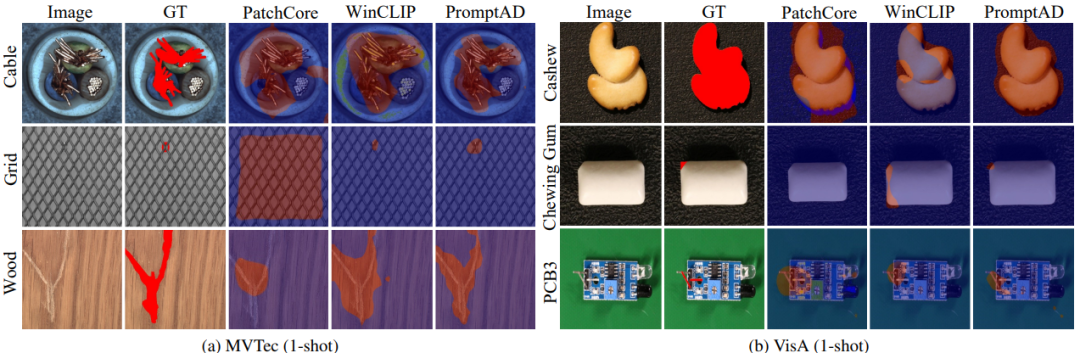
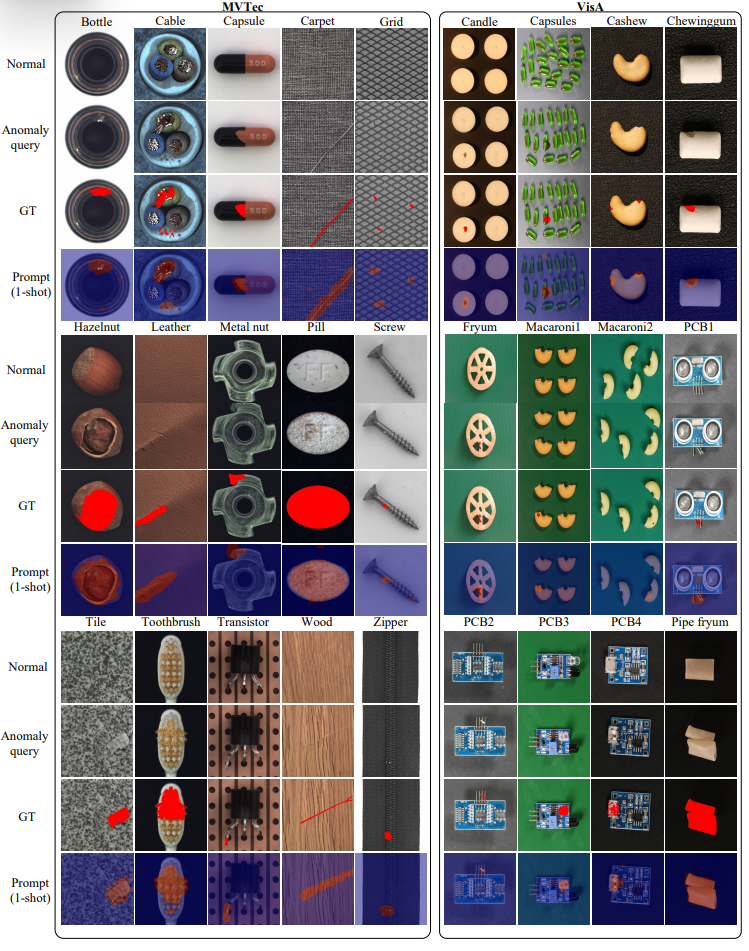
效果如何?
团队在两个经典工业数据集(MVTec 和 VisA)上做了测试:
在 11/12 个少样本场景中拿下第一。
在 仅有 1 张正常样本的条件下,PromptAD 图像级检测 AUROC 达 94.6%,比 WinCLIP 提高了 1.3%。
在 4 张样本条件下,AUROC 达 96.6%,几乎接近全监督方法的表现。







顶级父类与它的重要方法equals())
实现时间序列预测:从数据到闭环预测全解析)


)




(按键设置及中断设置)

IMX6ULL 按键控制(轮询 + 中断)优化工程)

