作者:来自 Elastic Josh Long, Philipp Krenn 及 Laura Trotta
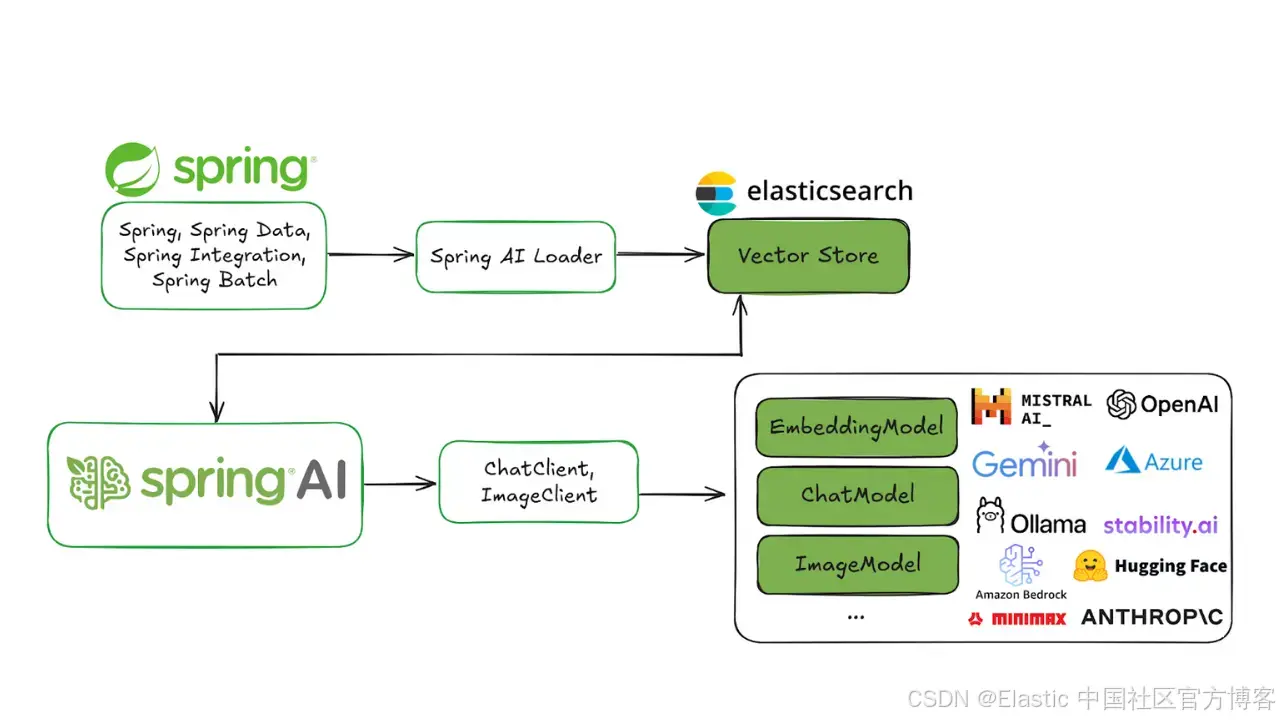
使用 Spring AI 和 Elasticsearch 构建一个完整的 AI 应用程序。
Elasticsearch 原生集成了业界领先的生成式 AI 工具和服务提供商。查看我们关于超越 RAG 基础或使用 Elastic 向量数据库构建生产级应用的网络研讨会。
为了为你的用例构建最佳搜索解决方案,现在就开始免费云试用,或者在本地机器上尝试 Elastic。
Spring AI 现在已正式发布,第一个稳定版本 1.0 已可在 Maven Central 下载。让我们马上开始使用它,结合你喜欢的 LLM 和我们最喜欢的向量数据库,构建一个完整的 AI 应用程序。
什么是 Spring AI?
Spring AI 1.0 是一个面向 Java 的全面 AI 工程解决方案,经过一段时间的开发并受到 AI 领域快速发展的推动,如今正式发布。这个版本为 AI 工程师带来了许多关键的新功能。
Java 和 Spring 正处于迎接 AI 浪潮的有利位置。很多公司都在使用 Spring Boot,这使得将 AI 集成到现有系统中变得非常简单。你基本上可以毫不费力地将业务逻辑和数据直接连接到那些 AI 模型上。
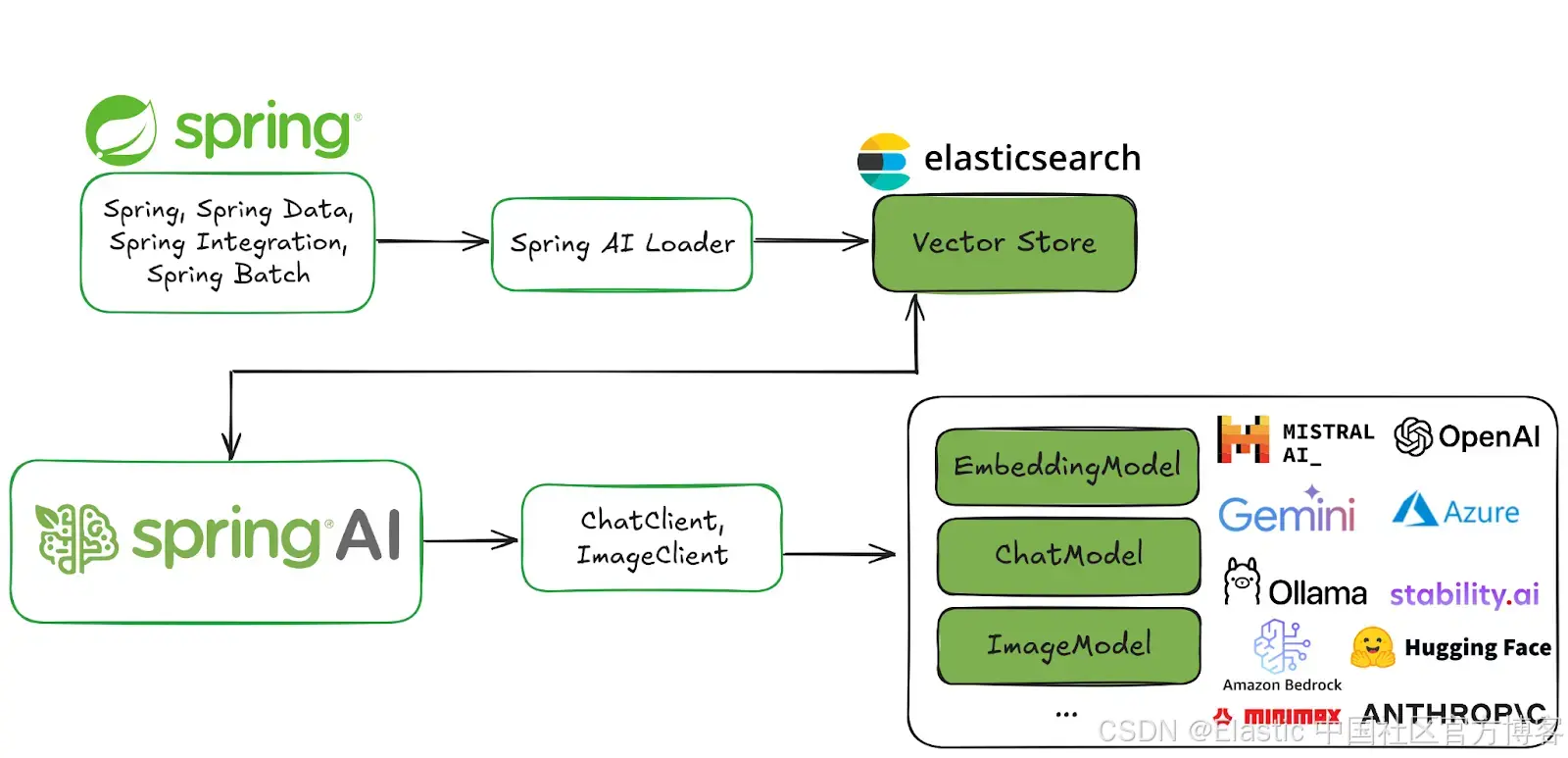
Spring AI 支持多种 AI 模型和技术,例如:
- 图像模型:根据文本提示生成图像。
- 转录模型:将音频源转换为文本。
- 嵌入模型:将任意数据转换为向量,这是一种针对语义相似性搜索优化的数据类型。
- 聊天模型:这些你应该很熟悉!你肯定在哪儿已经和其中一个简单聊过几句了。
聊天模型是当前 AI 领域最受关注的部分,而且确实如此,它们非常强大!你可以让它们帮你修改文档或者写一首诗。(只是暂时别让它们讲笑话……)它们很厉害,但也确实存在一些问题。
Spring AI 应对 AI 挑战的解决方案
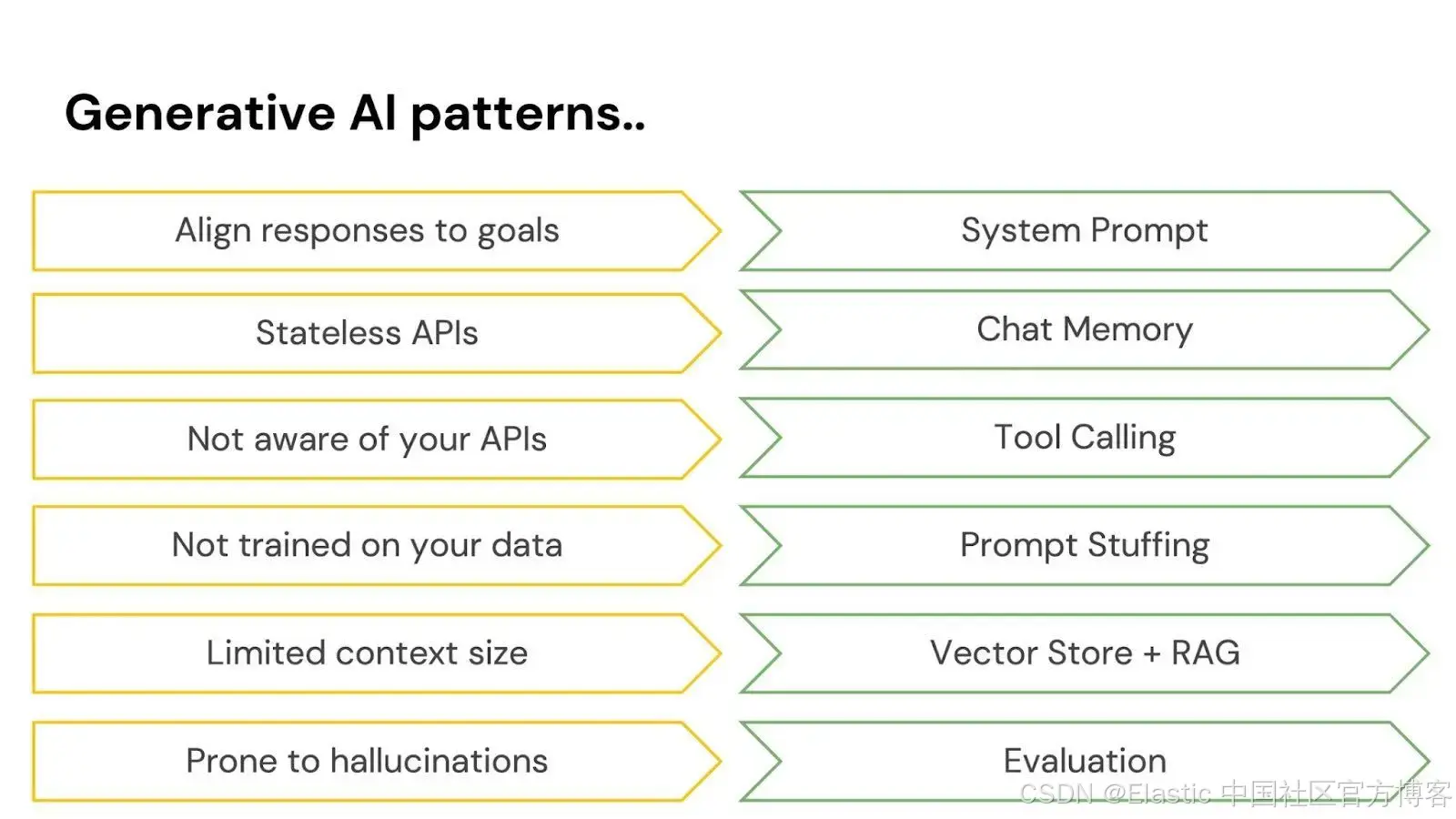
让我们来看看这些问题以及 Spring AI 中的解决方案。
| 问题 | 解决方案 | |
|---|---|---|
| 一致性 | 聊天模型思想开放,容易分心 | 你可以给它们一个 system prompt 来控制它们整体的行为和结构 |
| 内存 | AI 模型没有记忆,所以它们无法将同一个用户的多条消息关联起来 | 你可以给它们一个记忆系统来存储对话中相关的部分 |
| 隔离 | AI 模型生活在隔离的小沙盒中,但如果你给它们访问工具的权限——当它们认为有必要时可以调用的函数,它们可以做非常惊人的事情。 | Spring AI 支持工具调用,这让你可以告诉 AI 模型它环境中的工具,之后它可以请求你调用这些工具。这种多轮交互会为你透明地处理。 |
| 私有数据 | AI 模型很智能,但它们不是无所不知!它们不知道你专有数据库中的内容 —— 而且我们也认为你不会想让它们知道! | 你需要通过填充 prompts 来指导它们的回答 —— 基本上是用强大的字符串拼接操作符,在模型查看问题之前,把文本放进请求里。可以看作是背景信息。你怎么决定什么该发送,什么不该发送?用 vector store 选择只有相关的数据,再发送给模型。这叫做检索增强生成,或者 RAG。 |
| 幻觉 | AI chat 模型喜欢聊天!有时候它们非常自信,以至于会编造内容。 | 你需要使用评估 —— 用一个模型验证另一个模型的输出——来确认结果是否合理。 |
当然,没有哪个 AI 应用是孤立的。现代 AI 系统和服务在与其他系统和服务集成时表现最佳。Model Context Protocol (MCP) 使你能够将 AI 应用连接到其他基于 MCP 的服务,无论它们使用什么语言编写。你可以将这些组合成推动更大目标的 agentic 工作流。
最棒的是?你可以在熟悉的 Spring Boot 习惯用法和抽象基础上完成这一切:Spring Initializr 上几乎所有功能都有方便的 starter 依赖。
Spring AI 提供方便的 Spring Boot 自动配置,让你享受约定优于配置的体验。Spring AI 还支持通过 Spring Boot 的 Actuator 和 Micrometer 项目进行可观察性。它还能很好地兼容 GraalVM 和虚拟线程,帮助你构建超快、高效且可扩展的 AI 应用。
为什么选择 Elasticsearch
Elasticsearch 是一个全文搜索引擎,你可能已经知道了。那么为什么我们用它来做这个项目?因为它也是一个向量存储!而且非常不错,数据和全文本紧密存放。其他显著优点:
-
超级容易设置
-
开源
-
横向可扩展
-
你们组织的大部分自由格式数据可能已经存在 Elasticsearch 集群中
-
功能完善的搜索引擎能力
-
完全集成在 Spring AI 中!
综合考虑,Elasticsearch 满足作为优秀向量存储的所有条件,所以让我们开始设置并构建应用吧!
开始使用 Elasticsearch
我们需要 Elasticsearch 和 Kibana,Kibana 是你用来与数据库中数据交互的 UI 控制台。
多亏了 Docker 镜像和 Elastic.co 首页的便利,你可以在本地机器上试用所有东西。去那里,向下滚动找到 curl 命令,运行它并直接输入你的终端:
curl -fsSL https://elastic.co/start-local | sh ______ _ _ _ | ____| | | | (_) | |__ | | __ _ ___| |_ _ ___ | __| | |/ _` / __| __| |/ __|| |____| | (_| \__ \ |_| | (__ |______|_|\__,_|___/\__|_|\___|
-------------------------------------------------
🚀 Run Elasticsearch and Kibana for local testing
-------------------------------------------------
ℹ️ Do not use this script in a production environment
⌛️ Setting up Elasticsearch and Kibana v9.0.0...
- Generated random passwords
- Created the elastic-start-local folder containing the files:- .env, with settings- docker-compose.yml, for Docker services- start/stop/uninstall commands
- Running docker compose up --wait
[+] Running 25/26✔ kibana_settings Pulled 16.7s ✔ kibana Pulled 26.8s ✔ elasticsearch Pulled 17.4s
[+] Running 6/6✔ Network elastic-start-local_default Created 0.0s ✔ Volume "elastic-start-local_dev-elasticsearch" Created 0.0s ✔ Volume "elastic-start-local_dev-kibana" Created 0.0s ✔ Container es-local-dev Healthy 12.9s ✔ Container kibana_settings Exited 11.9s ✔ Container kibana-local-dev Healthy 21.8s
🎉 Congrats, Elasticsearch and Kibana are installed and running in Docker!
🌐 Open your browser at http://localhost:5601Username: elasticPassword: w1GB15uQ
🔌 Elasticsearch API endpoint: http://localhost:9200
🔑 API key: SERqaGlKWUJLNVJDODc1UGxjLWE6WFdxSTNvMU5SbVc5NDlKMEhpMzJmZw==
Learn more at https://github.com/elastic/start-local
➜ ~ 这将会拉取并配置 Elasticsearch 和 Kibana 的 Docker 镜像,几分钟后你就可以在本地机器上运行它们,连接凭据也会一起提供。
你还会得到两个不同的 URL 用来与你的 Elasticsearch 实例交互。按照提示操作,打开浏览器访问 http://localhost:5601。
注意:控制台上打印的用户名 elastic 和密码:你登录时需要用到它们(在上面的示例输出中,用户名和密码分别是 elastic 和 w1GB15uQ)。
整合应用
访问 Spring Initializr 页面,生成一个包含以下依赖项的新 Spring AI 项目:
-
Elasticsearch Vector Store
-
Spring Boot Actuator
-
GraalVM
-
OpenAI
-
Web
确保选择最新版本的 Java(理想是 Java 24 —— 写本文时是这个版本 —— 或更高)以及你选择的构建工具。这里的示例使用 Apache Maven。
点击 Generate,下载并解压项目,然后导入到你喜欢的 IDE 中。(我们用的是 IntelliJ IDEA。)
首先,指定 Spring Boot 应用的连接详情。在 application.properties 中写入以下内容:
spring.elasticsearch.uris=http://localhost:9200
spring.elasticsearch.username=elastic
spring.elasticsearch.password=w1GB15uQ我们还会使用 Spring AI 的 vector store 功能来初始化 Elasticsearch 端所需的数据结构,所以请指定:
spring.ai.vectorstore.elasticsearch.initialize-schema=true在这个演示中我们将使用 OpenAI,具体是 Embedding Model 和 Chat Model(你可以使用任何 Spring AI 支持的服务)。
Embedding Model 用于在将数据存入 Elasticsearch 之前创建数据的向量。要使用 OpenAI,我们需要指定 API key:
spring.ai.openai.api-key=...你可以将它定义为环境变量,比如 SPRING_AI_OPENAI_API_KEY,避免将凭证写入源代码。
我们要上传文件,所以一定要自定义允许上传到 servlet 容器的数据大小:
spring.servlet.multipart.max-file-size=20MB
spring.servlet.multipart.max-request-size=20M快完成了!在我们开始写代码之前,先预览一下这个流程。
我们在机器上下载了一个文件(一个棋盘游戏规则列表),重命名为 test.pdf,放在 ~/Downloads/test.pdf。
该文件将发送到 /rag/ingest 端点(根据你的本地设置替换路径):
http --form POST http://localhost:8080/rag/ingest path@/Users/jlong/Downloads/test.pdf这可能需要几秒钟……
在后台,数据被发送到 OpenAI,OpenAI 会为数据创建 embeddings;然后这些数据,包括向量和原始文本,都写入到 Elasticsearch。
这些数据和所有的 embeddings 就是魔法所在。然后我们可以通过 VectorStore 接口查询 Elasticsearch。
完整流程如下:
- HTTP 客户端将你选择的 PDF 上传到 Spring 应用。
- Spring AI 负责从 PDF 提取文本,并将每页分成 800 字符的块。
- OpenAI 为每个块生成向量表示。
- 分块文本和向量都会存储到 Elasticsearch。
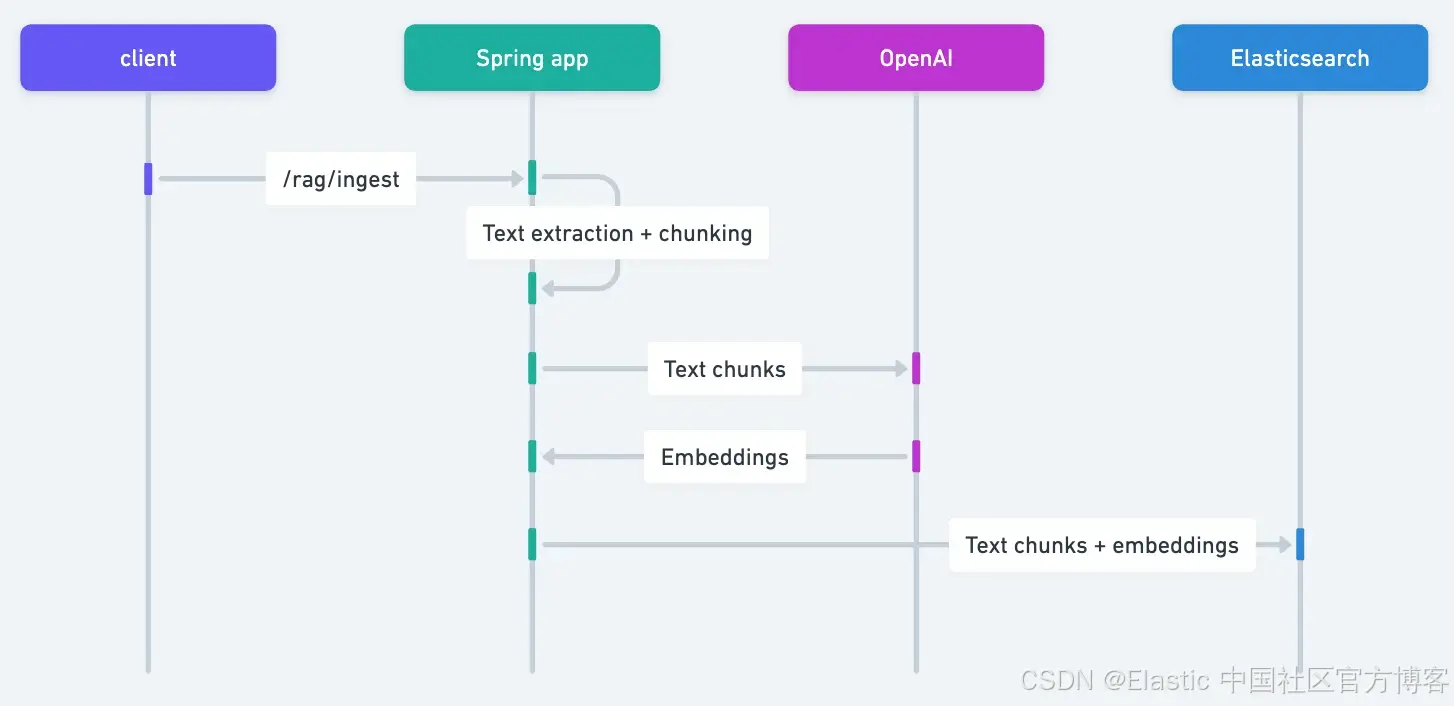
最后,我们将发出一个查询:
http :8080/rag/query question=="where do you place the reward card after obtaining it?" 然后我们会得到一个相关的答案:
After obtaining a Reward card, you place it facedown under the Hero card of the hero who received it.
Found at page: 28 of the manual不错!这整个过程是怎么工作的?
- HTTP 客户端把问题提交给 Spring 应用。
- Spring AI 从 OpenAI 获取问题的向量表示。
- 利用这个向量,它在 Elasticsearch 中存储的文本块里搜索相似文档,并检索最相似的文档。
- 然后 Spring AI 把问题和检索到的上下文发送给 OpenAI,生成大语言模型(LLM)的答案。
- 最后,它返回生成的答案和检索到的上下文引用。
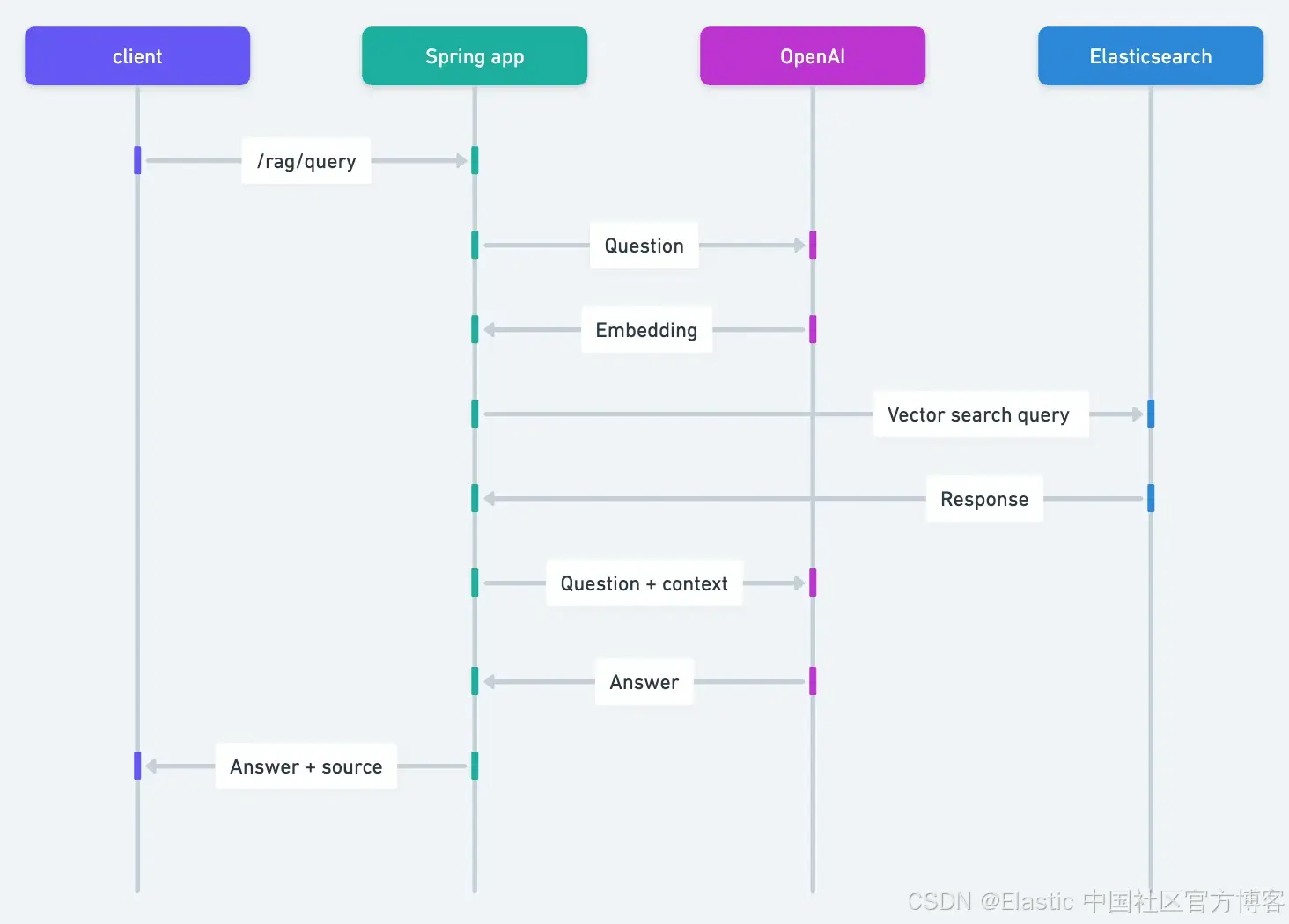
让我们深入看看 Java 代码,了解它到底是怎么工作的。
首先是 Main 类:它是任何普通 Spring Boot 应用的标准主类。
@SpringBootApplication
public class DemoApplication {public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args);}
}没什么特别的。继续...
接下来,是一个基础的 HTTP 控制器:
@RestController
class RagController {private final RagService rag;RagController(RagService rag) {this.rag = rag;}@PostMapping("/rag/ingest")ResponseEntity<?> ingestPDF(@RequestBody MultipartFile path) {rag.ingest(path.getResource());return ResponseEntity.ok().body("Done!");}@GetMapping("/rag/query")ResponseEntity<?> query(@RequestParam String question) {String response = rag.directRag(question);return ResponseEntity.ok().body(response);}
}控制器只是调用了我们构建的一个服务,用来处理文件的摄取并写入 Elasticsearch 向量存储,然后方便地对同一个向量存储进行查询。
我们来看一下这个服务:
@Service
class RagService {private final ElasticsearchVectorStore vectorStore;private final ChatClient ai;RagService(ElasticsearchVectorStore vectorStore, ChatClient.Builder clientBuilder) {this.vectorStore = vectorStore;this.ai = clientBuilder.build();}void ingest(Resource path) {PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(path);List<Document> batch = new TokenTextSplitter().apply(pdfReader.read());vectorStore.add(batch);}// TBD
}这段代码处理所有的摄取:给定一个 Spring Framework 的 Resource,它是一个字节容器,我们使用 Spring AI 的 PagePdfDocumentReader 读取 PDF 数据(假设是 .PDF 文件——确保在接受任意输入之前尽量验证!),然后用 Spring AI 的 TokenTextSplitter 进行分词,最后将得到的 List 添加到向量存储实现 ElasticsearchVectorStore 中。
你可以通过 Kibana 确认:在发送文件到 /rag/ingest 端点后,打开浏览器访问 localhost:5601,然后在左侧菜单中导航到 Dev Tools。在那里你可以发出查询,和 Elasticsearch 实例中的数据交互。
现在是有趣的部分:我们如何根据用户查询把数据取回来?
下面是在名为 directRag 的方法中对查询的初步实现。
String directRag(String question) {// Query the vector store for documents related to the questionList<Document> vectorStoreResult =vectorStore.doSimilaritySearch(SearchRequest.builder().query(question).topK(5).similarityThreshold(0.7).build());// Merging the documents into a single stringString documents = vectorStoreResult.stream().map(Document::getText).collect(Collectors.joining(System.lineSeparator()));// Exit if the vector search didn't find any resultsif (documents.isEmpty()) {return "No relevant context found. Please change your question.";}// Setting the prompt with the contextString prompt = """You're assisting with providing the rules of the tabletop game Runewars.Use the information from the DOCUMENTS section to provide accurate answers to thequestion in the QUESTION section.If unsure, simply state that you don't know.DOCUMENTS:""" + documents+ """QUESTION:""" + question;// Calling the chat model with the questionString response = ai.prompt().user(prompt).call().content();return response +System.lineSeparator() +"Found at page: " +// Retrieving the first ranked page number from the document metadatavectorStoreResult.getFirst().getMetadata().get(PagePdfDocumentReader.METADATA_START_PAGE_NUMBER) +" of the manual";}代码很简单,但我们分几步来看:
-
用 VectorStore 执行相似度搜索。
-
从所有结果中,获取底层的 Spring AI Documents 并提取它们的文本,全部拼接成一个结果。
-
把 VectorStore 的结果连同指示模型如何处理它们的提示语和用户的问题一起发给模型。等待响应并返回。
这就是 RAG(检索增强生成)。意思是我们用向量库中的数据来辅助模型的处理和分析。现在你知道怎么做了,希望你永远不需要亲自写!至少不用像这样写:Spring AI 的 Advisors 可以让这个过程更简单。
Advisors 允许你对模型的请求做前处理和后处理,同时为你的应用和向量库之间提供抽象层。在构建文件中添加以下依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>在类里添加另一个方法,叫 advisedRag(String question):
String advisedRag(String question) {return this.ai.prompt().user(question).advisors(new QuestionAnswerAdvisor(vectorStore)).call().content();
}所有的 RAG 模式逻辑都封装在 QuestionAnswerAdvisor 中。其他的就像对 ChatModel 的任何请求一样!很棒!
结论
在这个演示中,我们使用了 Docker 镜像,并且在本地机器上完成了所有操作,但目标是构建适合生产环境的 AI 系统和服务。你可以做很多事情来实现这个目标。
首先,你可以添加 Spring Boot Actuator 来监控 token 的消耗。token 是衡量模型请求复杂度(有时也是成本)的代理指标。
你已经在类路径上添加了 Spring Boot Actuator,只需指定以下属性来显示所有指标(由出色的 Micrometer.io 项目捕获):
management.endpoints.web.exposure.include=*重启你的应用。发起一次查询,然后访问:http://localhost:8080/actuator/metrics。搜索 “token”,你会看到应用使用的 token 信息。一定要关注这些信息。当然,你也可以使用 Micrometer 对 Elasticsearch 的集成,将这些指标推送过去,让 Elasticsearch 成为你的时间序列数据库!
你还应该考虑,每次请求像 Elasticsearch、OpenAI 或其他网络服务时,都是 IO 操作,并且这些 IO 通常会阻塞执行的线程。Java 21 及以后版本带来了非阻塞的虚拟线程,大幅提升了可扩展性。用以下方式启用:
spring.threads.virtual.enabled=true最后,你会想把你的应用和数据托管在一个能让它们茁壮成长和扩展的地方。我们相信你可能已经考虑过在哪里运行你的应用,但你的数据会托管在哪里?我们推荐 Elastic Cloud。它安全、私密、可扩展且功能丰富。我们最喜欢的部分是,如果你愿意,可以选择无服务器版本,由 Elastic 来负责报警,而不是你!
原文:Spring AI and Elasticsearch as your vector database - Elasticsearch Labs

)






询问笔录发问提纲)








)

