前面我们准备好了COCO格式的数据集:将YOLO格式的数据集转换为mmdetection格式-CSDN博客![]() https://blog.csdn.net/qq_54708219/article/details/148224187?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_54708219/article/details/148224187?spm=1001.2014.3001.5501
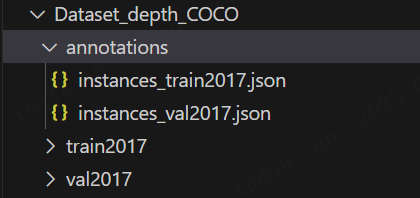
下面我们使用MMdetection开始训练。
1.创建新的数据集类
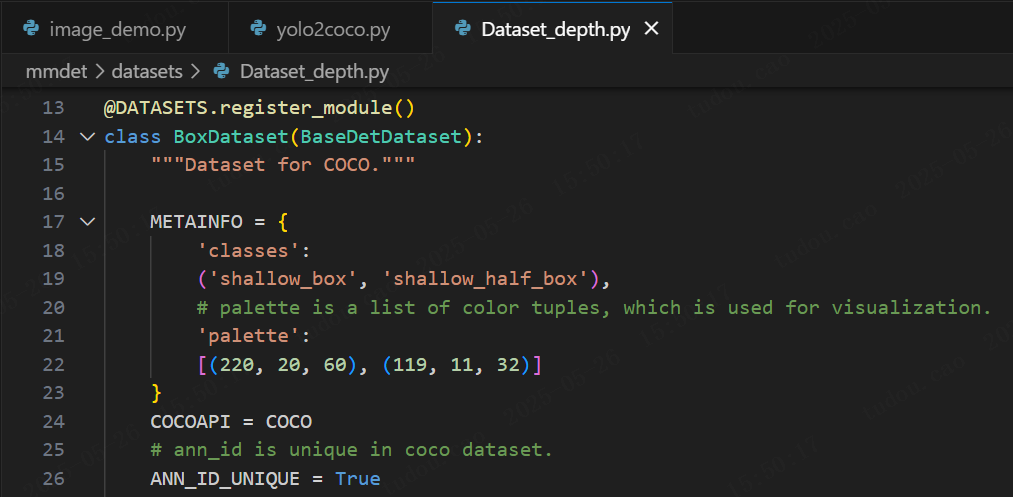
首先,在mmdet/datasets里,创建属于自己的数据集文件。因为数据集是coco格式,可直接复制coco.py,文件名更改为Dataset_depth.py,然后把里面的标签改掉。我们需要把coco.py中的类名、数据集中的类别和标注的颜色换成自己的数据集的类名。这里,类名我修改为BoxDataset,数据集只有两个类别:'shallow_box'和'shallow_half_box',下面的palette是调色板,保持和classes长度一样即可,里面的颜色可以填成自己喜欢的,这里是直接保留了前两个后面全部删除:
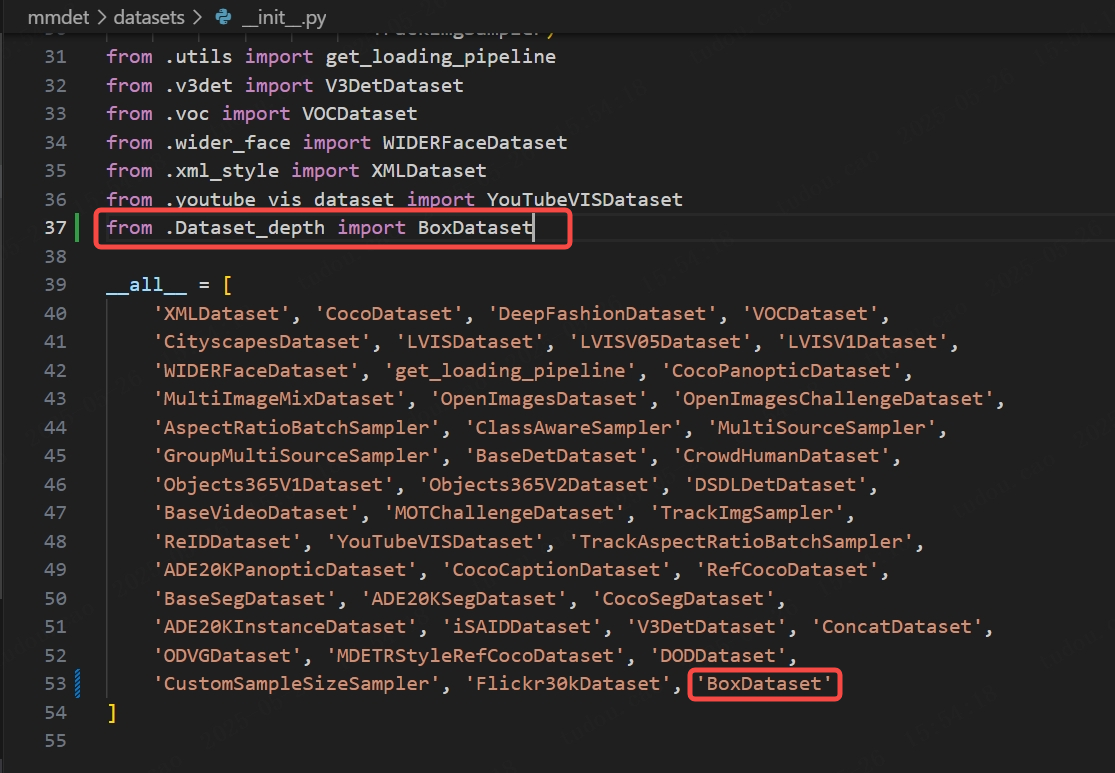
2.录入数据集
在mmdet/datasets/init.py中仿照coco的格式把刚才创建的数据集类进行录入:
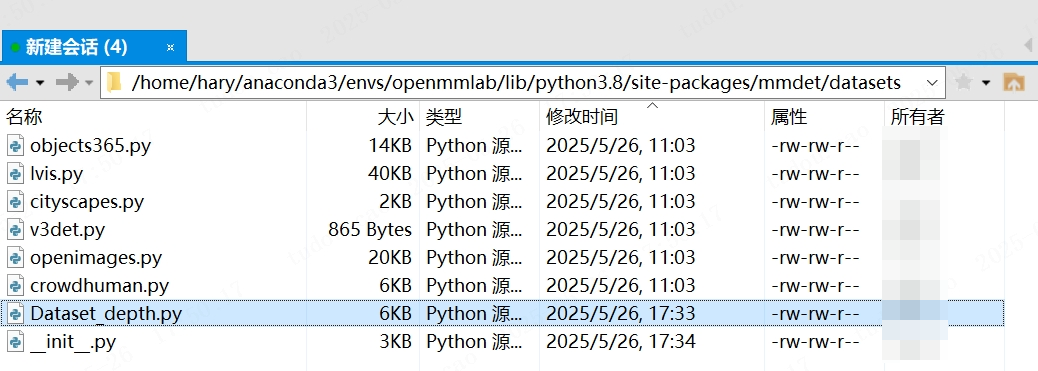
注意:如果注册完成训练仍然报KeyError,看一下报错的文件路径,可能是导入数据集类的时候一直是conda虚拟环境上的,而不是自己修改后的。解决方案就是顺着报错路径(conda环境路径)重新注册一遍数据集:
3.生成完整的配置文件
在configs文件夹下选择你想训练的模型,例如,我这里选择configs/deformable_detr/deformable-detr_r50_16xb2-50e_coco.py,然后在终端运行以下命令:
python tools/train.py <你所选择的模型路径>python tools/train.py configs/deformable_detr/deformable-detr_r50_16xb2-50e_coco.py此时运行会报错,因为他会自动寻找coco数据集而不是自己的(我自己没有下载coco数据集):
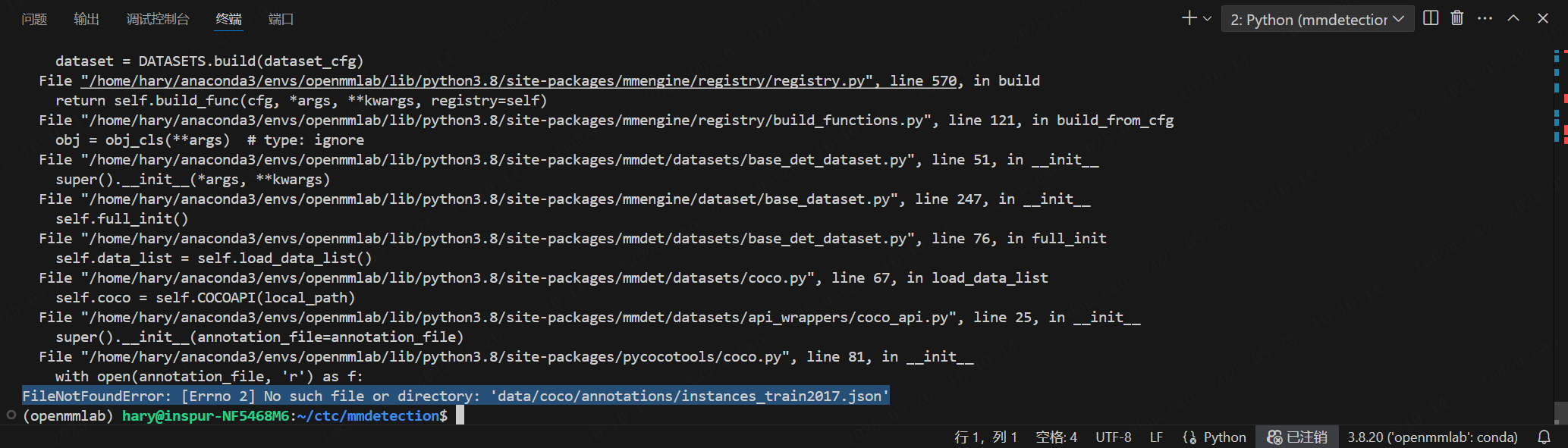
但是在当前目录下会生成work_dir文件夹,里面包含了完整的模型配置文件work_dirs/deformable-detr_r50_16xb2-50e_coco/deformable-detr_r50_16xb2-50e_coco.py:
4.修改生成的配置文件
接下来对work_dirs/deformable-detr_r50_16xb2-50e_coco/deformable-detr_r50_16xb2-50e_coco.py进行修改:
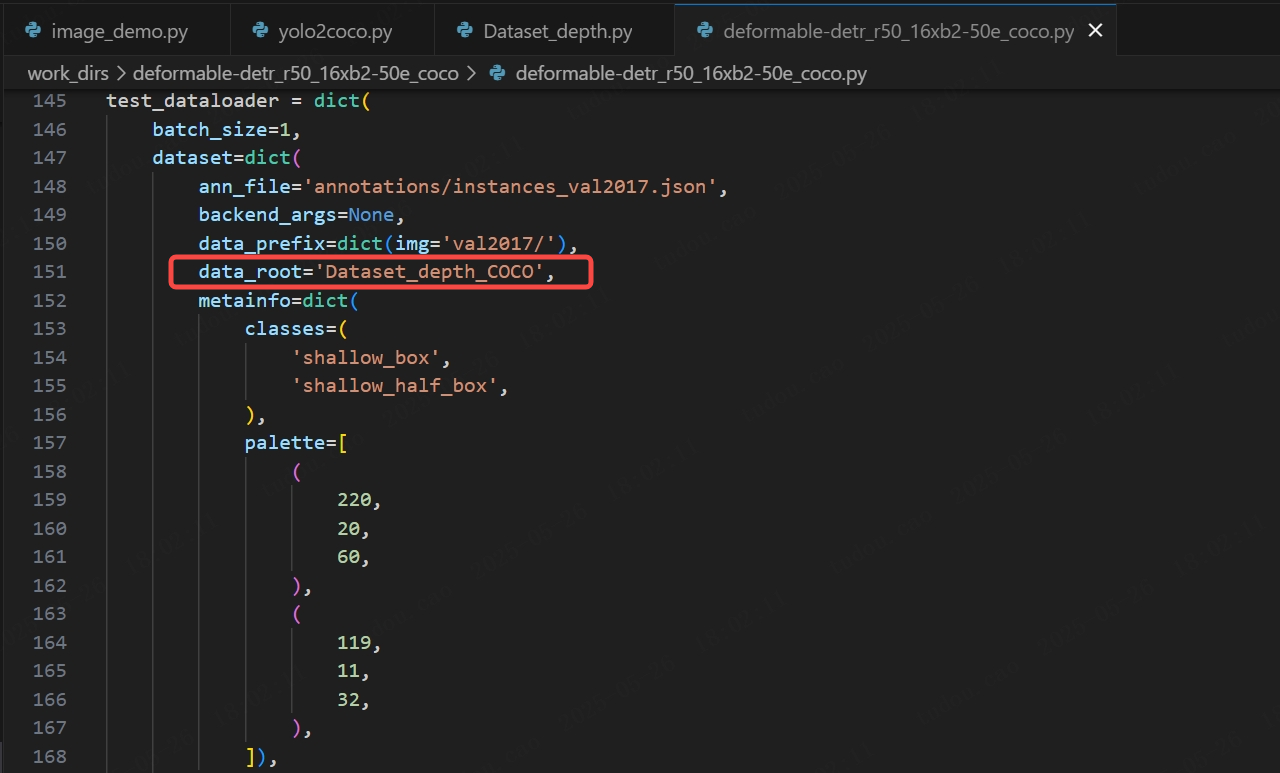
(1)数据集位置和数据集类:修改data_root(数据集相对路径)和dataset_type(之前注册的数据集类名):

同时在train_dataloader,test_dataloader,val_dataloader中修改data_root和type:
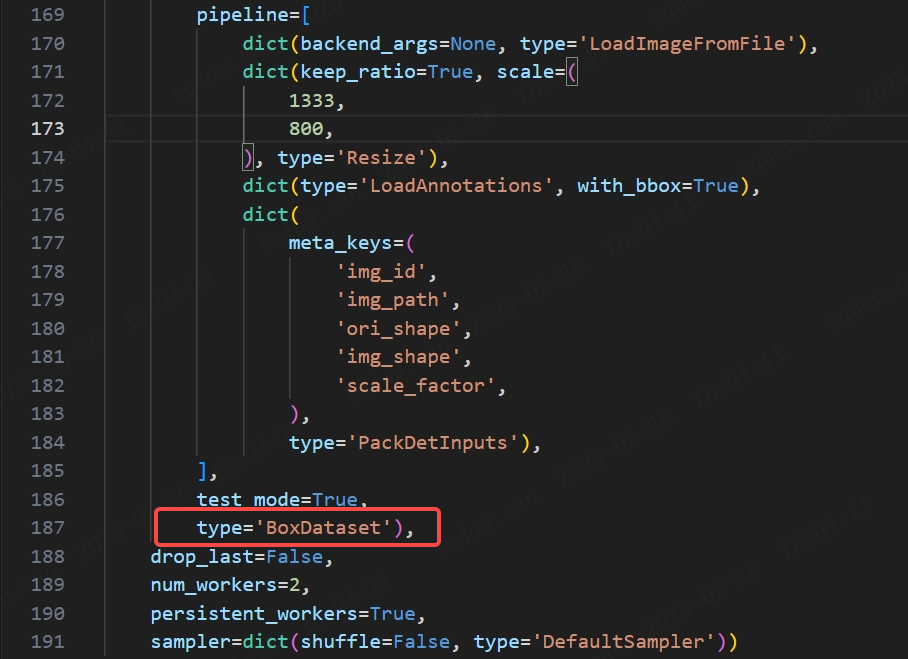
同时还修改一下val_evaluator和test_evaluator的ann_file:

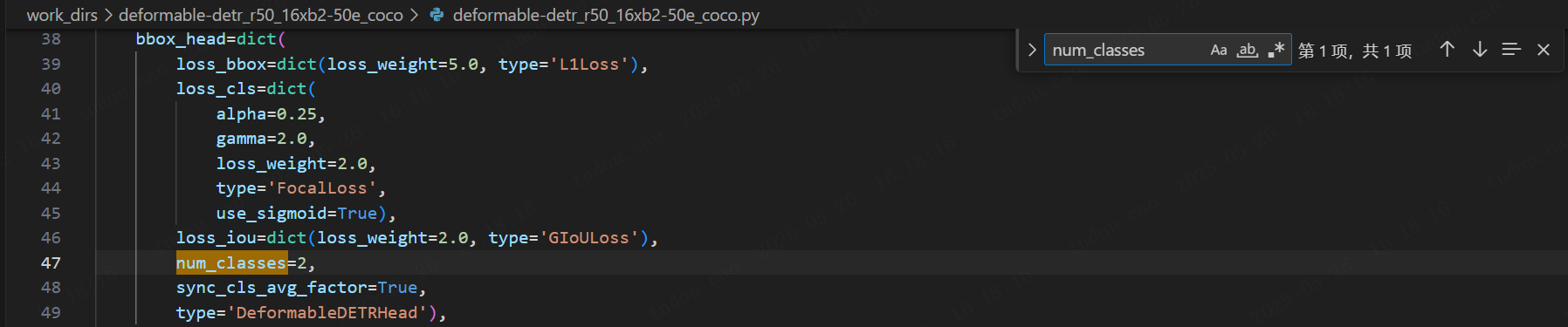
(2)修改数据集类别数:ctrl+F召唤出搜索框,输入num_classes,把coco数据集的80类改为自己的数据集类别个数(我的是2类):
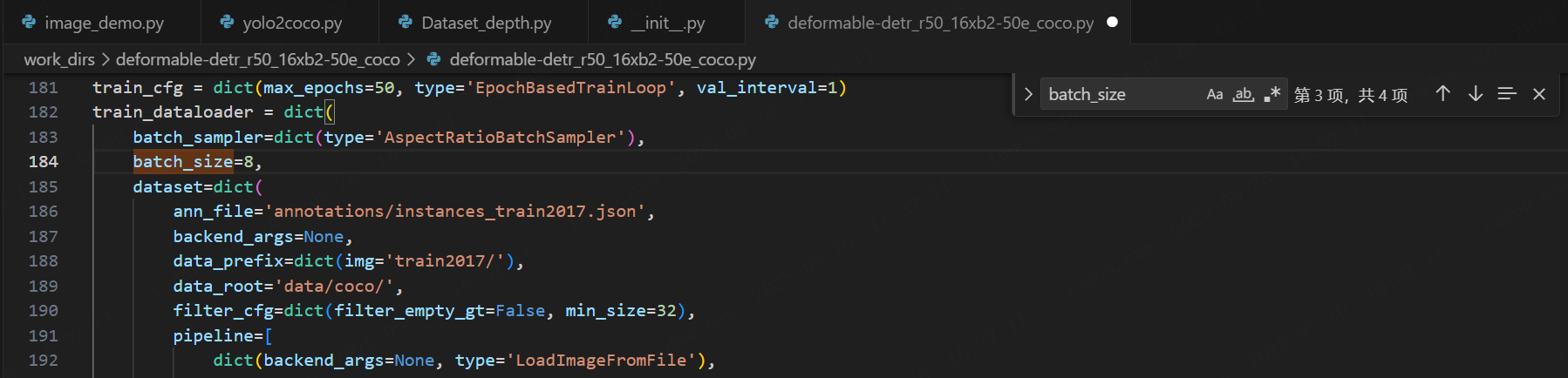
(3)修改batch_size
ctrl+F召唤出搜索框,输入batch_size,根据显卡算力设置train_dataloader,test_dataloader和val_dataloader的批量大小:
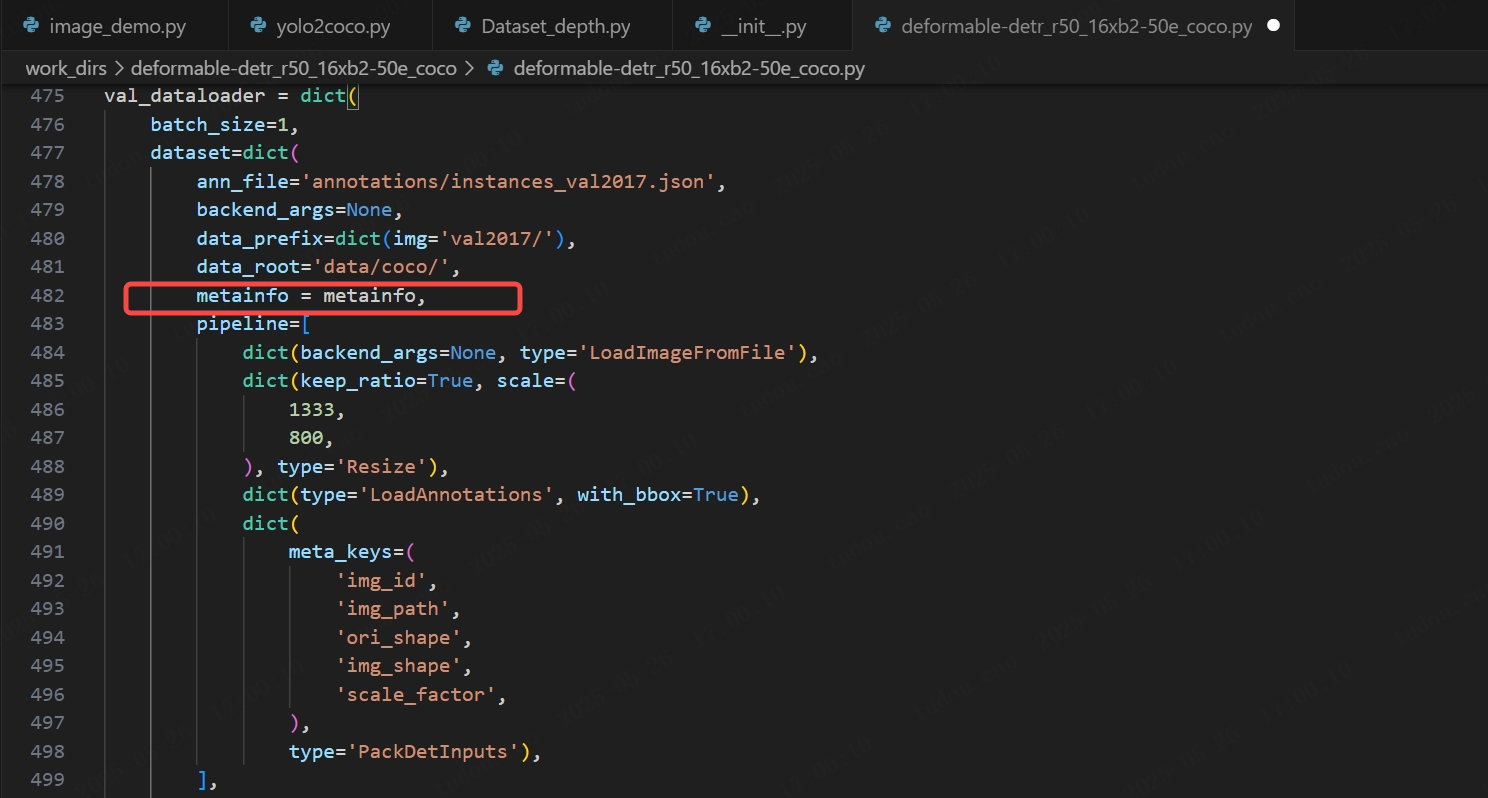
(4)注册数据集的metainfo
参考第一步,在配置文件中注册以下信息:
metainfo = dict(classes=('shallow_box', 'shallow_half_box'),palette=[(220, 20, 60), (119, 11, 32)]
)然后在train_dataloader,test_dataloader,val_dataloader中都写入:
(5)修改训练轮数:ctrl+F召唤出搜索框,输入max_epochs,这个模型默认的训练轮数是50

5.训练
然后把3中的命令改为修改后的配置文件路径:
python tools/train.py <你所修改的模型配置文件路径>python tools/train.py work_dirs/deformable-detr_r50_16xb2-50e_coco/deformable-detr_r50_16xb2-50e_coco.py看到以下界面说明正常运行:
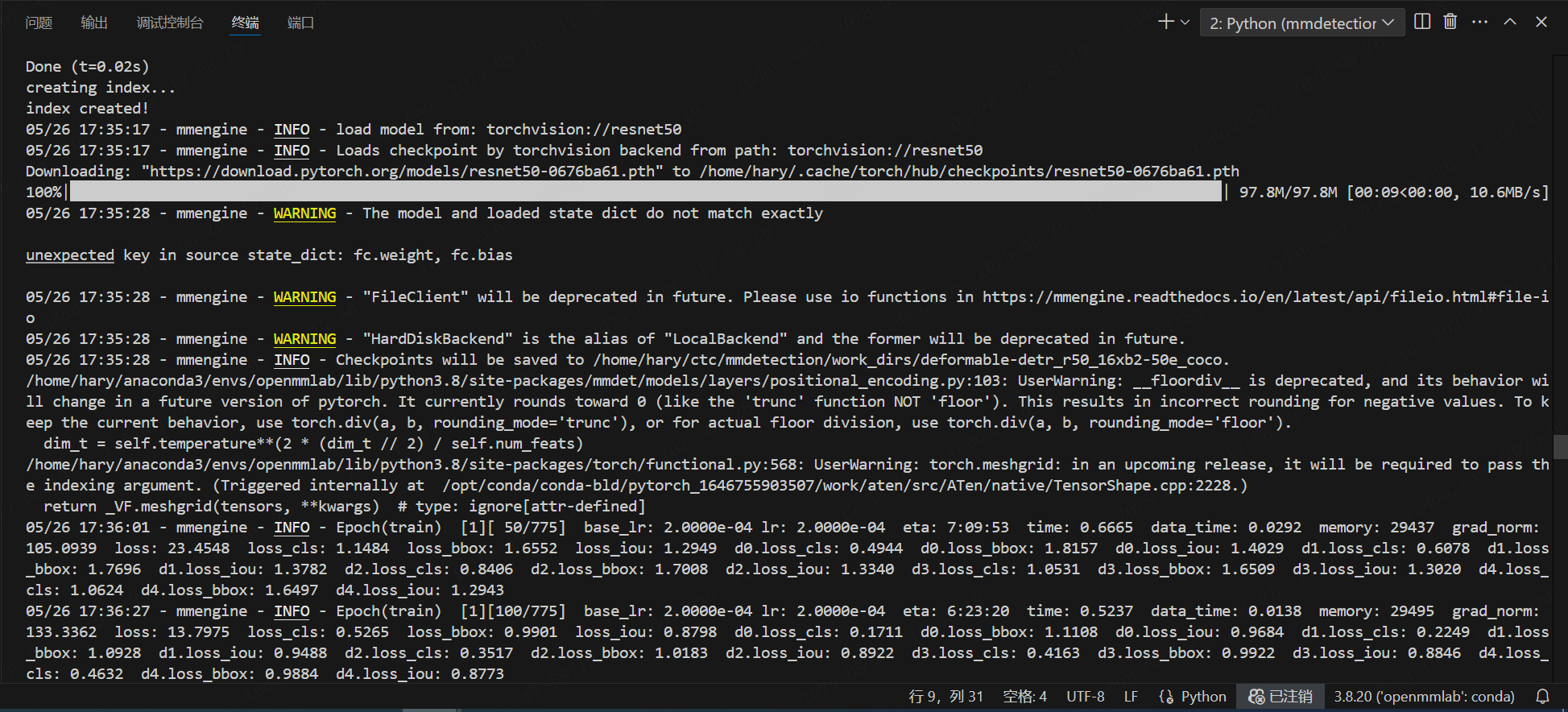
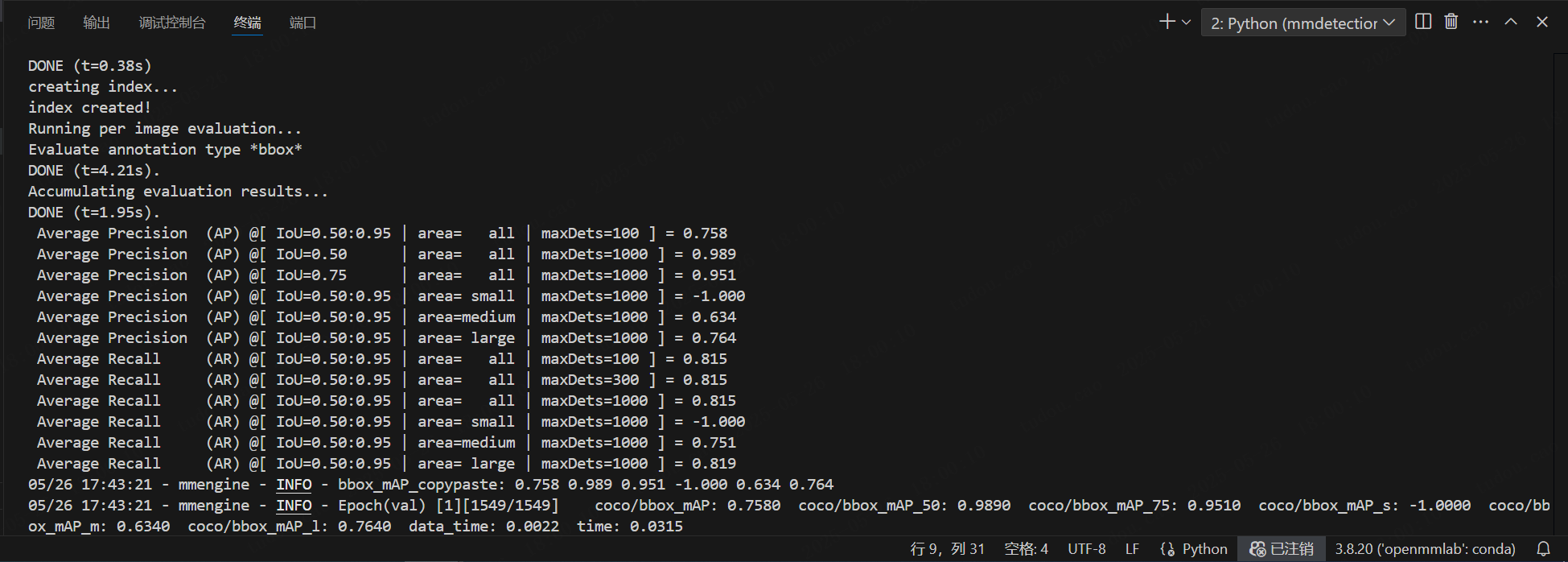
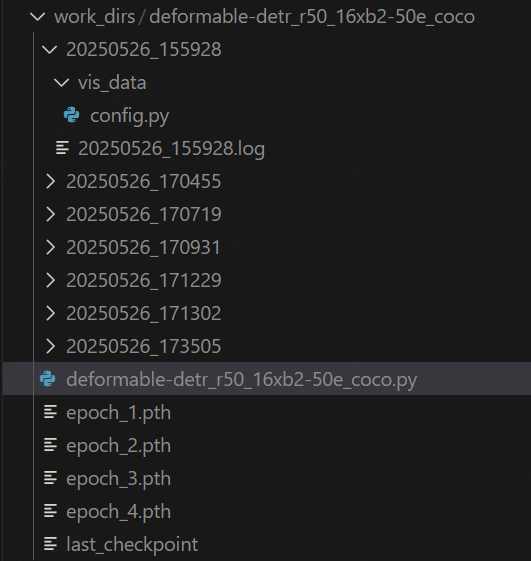
这个时候模型也会自动保存每一轮的权重文件:

医学图像的配准全过程文档及程序)
基础使用)

中播放)
)








的路径规划(附ROS C++/Python仿真))




