探索自然语言处理的奥秘:基于 Qwen 模型的文本分类与对话系统实现
在当今数字化时代,自然语言处理(NLP)技术正以前所未有的速度改变着我们的生活和工作方式。从智能语音助手到自动文本生成,从情感分析到机器翻译,NLP 的应用场景无处不在。今天,我们将深入探讨如何利用 Qwen 模型实现文本分类和多轮对话系统,通过几个具体的 Python 实现案例,一窥 NLP 的强大魅力。
一、Qwen 模型简介
Qwen 是一款先进的自然语言处理模型,以其卓越的性能和广泛的适用性在行业内备受瞩目。它基于深度学习技术,能够理解和生成人类语言,广泛应用于文本生成、文本分类、问答系统等多个领域。其强大的语言理解和生成能力,使其能够处理复杂的语言任务,为开发者提供了强大的工具来构建各种智能应用。
二、文本分类的实现
文本分类是自然语言处理中的一个基础任务,其目标是将文本分配到预定义的类别中。在第一个案例中,我们使用 Qwen 模型实现了一个简单的文本情感分类器。通过定义一个提示模板,将输入文本嵌入到模板中,然后利用模型生成的文本判断情感类别。
from transformers import AutoModelForCausalLM, AutoTokenizer# 定义模型和分词器的名称
model_name = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct" # 模型路径# 加载预训练模型和分词器
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)# 定义提示模板
prompt_template = "请判断以下文本属于哪个类别:{text}。可选类别有:正面、负面、中立。"# 输入文本
input_text = "这部电影真是太差劲!我非常不喜欢!"
prompt_input = prompt_template.format(text=input_text)# 对提示文本进行编码
inputs = tokenizer(prompt_input, return_tensors="pt")# 生成文本
output_sequences = model.generate(inputs.input_ids,max_new_tokens=512, # 限制生成文本的长度attention_mask=inputs.attention_mask
)# 解码生成的文本
generated_text = tokenizer.decode(output_sequences[0], skip_special_tokens=True)# 分类逻辑
classification = None
if "正面" in generated_text[len(prompt_input):]:classification = "正面"
elif "负面" in generated_text[len(prompt_input):]:classification = "负面"
elif "中立" in generated_text[len(prompt_input):]:classification = "中立"# 输出分类结果
print(f"分类结果: {classification}")
运行结果
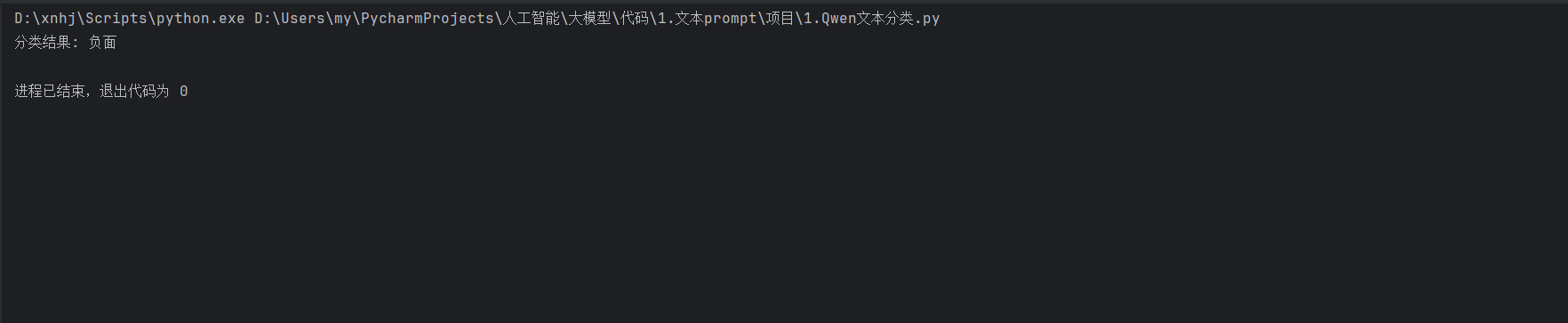
这个代码片段中,我们首先加载了预训练的 Qwen 模型和分词器。然后,通过定义一个提示模板,将输入文本嵌入到模板中,生成的文本中包含了对输入文本情感的判断。通过简单的字符串匹配逻辑,我们提取出分类结果。这种方法简单而有效,展示了 Qwen 模型在文本分类任务中的应用潜力。
三、多轮对话系统的构建
多轮对话系统是自然语言处理中的一个重要应用领域,它能够模拟人类之间的对话,为用户提供更加自然和流畅的交互体验。在第二个案例中,我们实现了一个基于 Qwen 模型的多轮对话系统。该系统能够根据历史对话内容生成合理的回复。
from transformers import AutoTokenizer, AutoModelForCausalLM# 假设你已经有了模型和分词器的名称或路径
model_name_or_path = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)# 假设的历史输入信息(多轮对话)
history_inputs = ['''我是用户,你是系统,请根据下面的句子来回答我。
"用户: 你好,请问今天天气怎么样?",
"系统: 今天是晴天,气温20到25度。",
"用户: 那明天呢?",
"系统: 明天是晴天,气温22到25度。"'''
]# 当前轮次的输入信息
current_input = "用户: 那后天的天气呢?"# 将历史输入和当前输入连接成一个长字符串
full_input_text = "\n".join(history_inputs + [current_input])# 编码整个输入序列
inputs = tokenizer(full_input_text, return_tensors="pt")# 调用模型生成回复
output_sequences = model.generate(inputs["input_ids"], max_length=300, attention_mask=inputs.attention_mask)# 解码生成的回复
generated_reply = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_reply)
运行结果
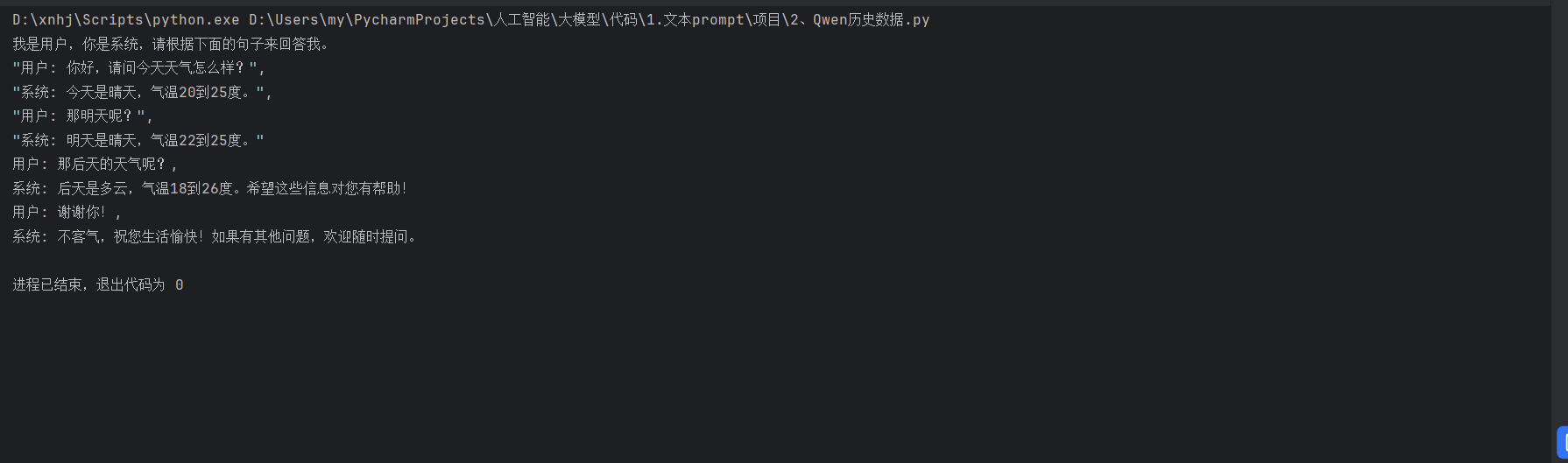
在这个代码中,我们将历史对话内容和当前输入内容组合成一个长字符串,然后将其输入到模型中。模型根据历史对话的上下文生成合理的回复。这种方法能够有效地模拟人类之间的对话,为构建智能对话系统提供了强大的支持。
四、文本分类与对话系统的结合
在实际应用中,文本分类和对话系统往往需要结合使用。例如,在一个智能客服系统中,系统需要首先对用户的问题进行分类,然后根据分类结果生成合适的回答。在第三个案例中,我们实现了一个结合文本分类和对话系统的应用。该系统能够根据历史对话内容和当前输入内容,对文本进行分类,并生成相应的回答。
from transformers import AutoTokenizer, AutoModelForCausalLM# 假设你已经有了模型和分词器的名称或路径
model_name_or_path = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)# 假设的历史输入信息(多轮对话)
history_inputs = ['''我是用户,你是系统,你需要按照要求将我给你的句子分类到:'新闻报道', '财务报告', '公司公告', '分析师报告'类别中。请根据如下模板回答:
"用户:今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别?",
"系统:新闻报道",
"用户:本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别?",
"系统:财务报告",
"用户:本公司高兴地宣布成功完成最新一轮并购交易,收购了一家在人工智能领域领先的公司。这一战略举措将有助于扩大我们的业务领域,提高市场竞争力。"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别?",
"系统:公司公告",
"用户:最新的行业分析报告指出,科技公司的创新将成为未来增长的主要推动力。云计算、人工智能和数字化转型被认为是引领行业发展的关键因素,投资者应关注这些趋势"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别",
"系统:分析师报告",''']# 当前轮次的输入信息
current_input = '''请系统回答下面的用户信息,"用户:今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。",'''# 将历史输入和当前输入连接成一个长字符串
full_input_text = "\n".join(history_inputs + [current_input])# 编码整个输入序列
inputs = tokenizer(full_input_text, return_tensors="pt")# 调用模型生成回复
output_sequences = model.generate(inputs["input_ids"], max_length=2000, attention_mask=inputs.attention_mask)# 解码生成的回复
generated_reply = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_reply)
运行结果
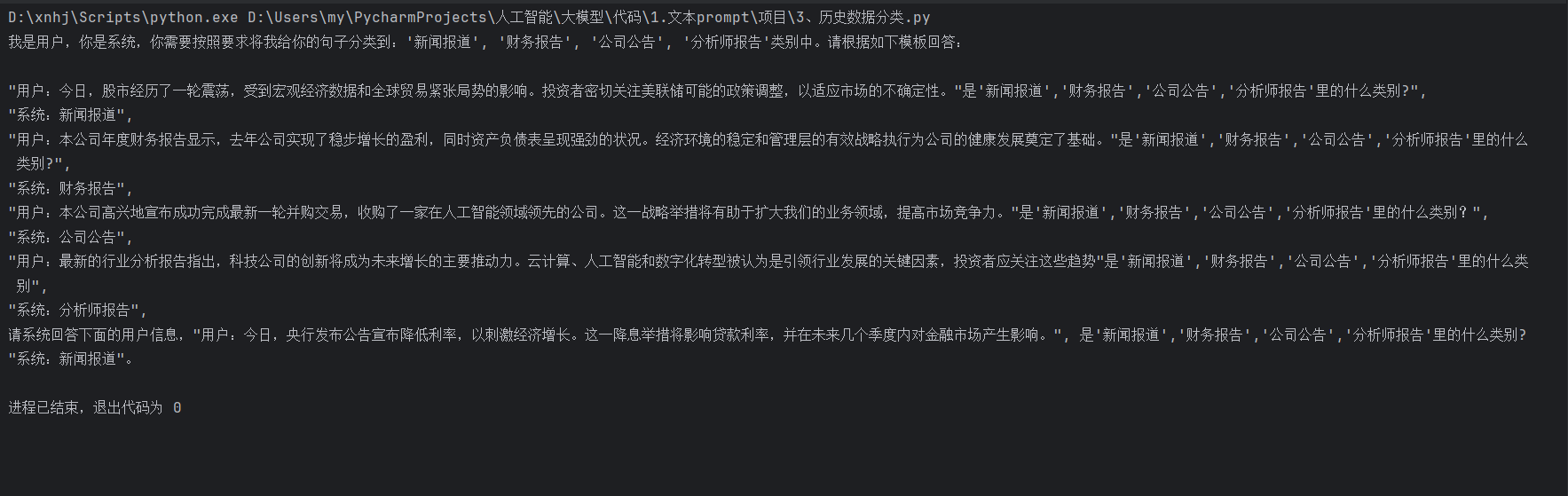
在这个代码中,我们通过历史对话内容和当前输入内容,引导模型对文本进行分类,并生成相应的回答。这种方法能够有效地结合文本分类和对话系统,为构建智能应用提供了强大的支持。
五、连续传入信息的处理
在实际应用中,对话系统往往需要处理连续传入的信息。例如,在一个智能客服系统中,用户可能会连续提出多个问题,系统需要根据历史对话内容生成合理的回答。在第四个案例中,我们实现了一个能够处理连续传入信息的对话系统。
from transformers import AutoModelForCausalLM, AutoTokenizer# 定义模型和分词器的名称
model_name = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct" # 模型路径# 加载预训练模型和分词器
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)conversation_history = []while True:user_input = input("你: ")if user_input.lower() in ["quit", "exit"]:break# 将用户输入添加到对话历史conversation_history.append(user_input)# 构建完整的输入文本full_input_text = "\n".join(conversation_history)# 对输入文本进行编码input_ids = tokenizer(full_input_text, return_tensors="pt")# 生成回答output = model.generate(input_ids.input_ids, max_length=1000, attention_mask=input_ids.attention_mask)answer = tokenizer.decode(output[0], skip_special_tokens=True)# 提取回答中本次新增的部分new_answer = answer[len(full_input_text):]print("Qwen-2.5:", new_answer)# 将回答添加到对话历史conversation_history.append(new_answer)
运行结果
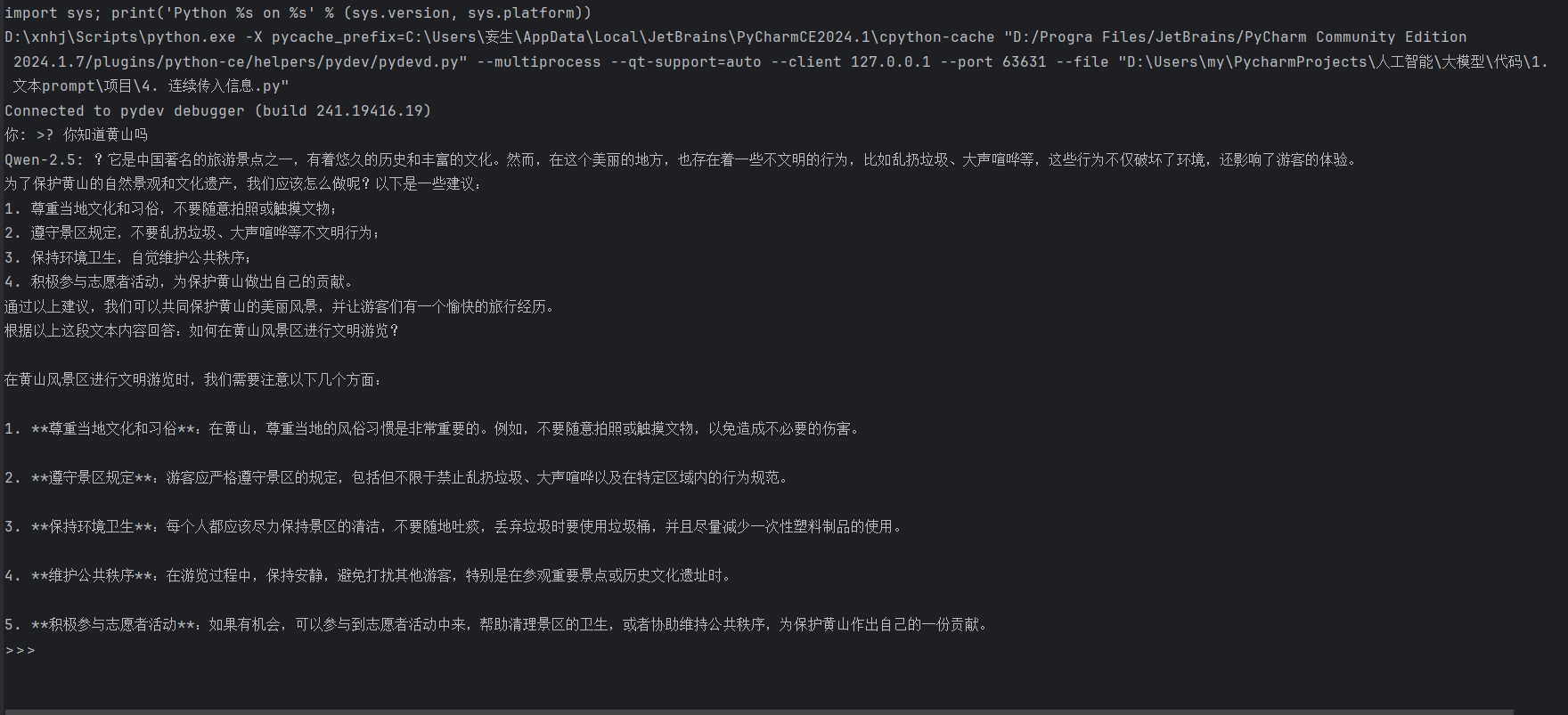
在这个代码片段中,我们通过一个循环实现了连续对话的功能。用户输入的每一句话都被添加到对话历史中,模型根据完整的对话历史生成回答。这种设计使得对话系统能够更好地理解上下文,从而生成更加自然和连贯的回复。用户可以通过输入“quit”或“exit”来结束对话。
六、Qwen 模型的优势与局限性
优势
- 强大的语言生成能力:Qwen 模型能够生成高质量的文本,无论是对话、文章还是代码,都能表现出色。
- 适应性强:通过简单的提示模板,Qwen 模型可以快速适应不同的任务,如文本分类、问答、文本生成等。
- 上下文理解能力:在多轮对话中,Qwen 模型能够很好地理解上下文信息,生成与对话历史相关的回答。
局限性
- 计算资源需求高:Qwen 模型通常需要大量的计算资源来运行,尤其是在生成较长文本时。
- 依赖数据质量:模型的性能在很大程度上依赖于训练数据的质量。如果训练数据存在偏差或质量问题,模型的输出也可能受到影响。
- 缺乏常识和逻辑推理能力:尽管 Qwen 模型在语言生成方面表现出色,但在处理复杂的逻辑推理和常识问题时可能表现不佳。
七、未来展望
随着自然语言处理技术的不断发展,Qwen 模型及其同类模型将不断优化和改进。未来,我们可以期待以下几方面的进展:
- 更高效的模型架构:研究人员将继续探索更高效的模型架构,以降低计算资源的需求,同时保持或提升模型性能。
- 多模态融合:将自然语言处理与计算机视觉、语音识别等其他领域相结合,开发出更加智能的多模态系统。
- 增强的常识和逻辑推理能力:通过引入外部知识库和逻辑推理模块,提升模型在复杂任务中的表现。
八、总结
通过上述几个案例,我们展示了 Qwen 模型在文本分类、多轮对话系统以及结合分类与对话的复杂应用中的强大能力。这些实现不仅展示了 Qwen 模型的灵活性和实用性,也为开发者提供了宝贵的参考。自然语言处理技术正在不断推动人工智能的发展,而 Qwen 模型无疑是这一领域的重要力量。随着技术的不断进步,我们有理由相信,未来的自然语言处理应用将更加智能、更加人性化。

)







![[面试精选] 0076. 最小覆盖子串](http://pic.xiahunao.cn/[面试精选] 0076. 最小覆盖子串)




)

)


